 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Enhancing Depth Completion with Multi-View Monitored Distillation
Mar 29, 2023
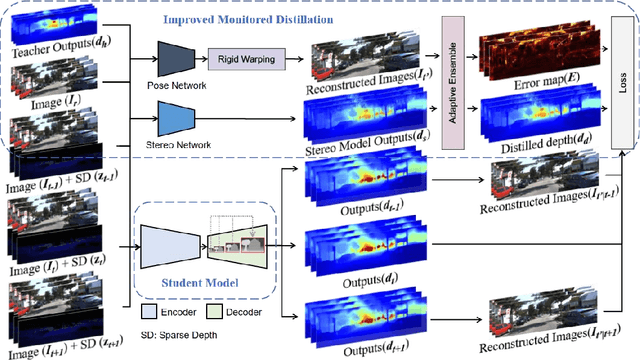
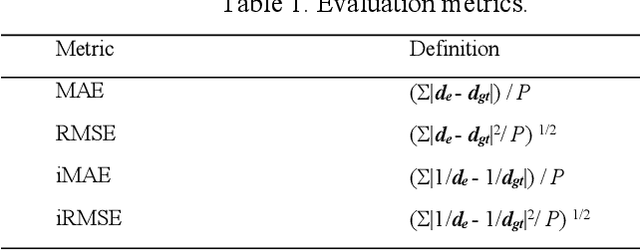
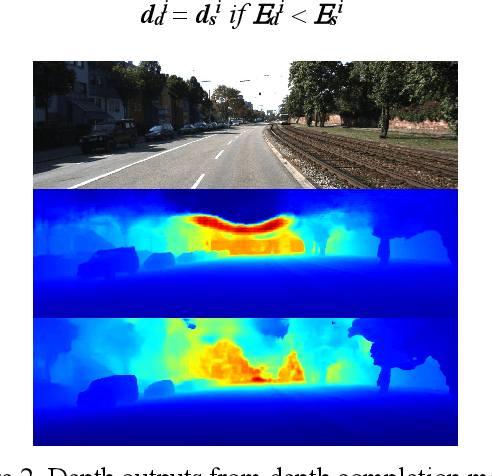
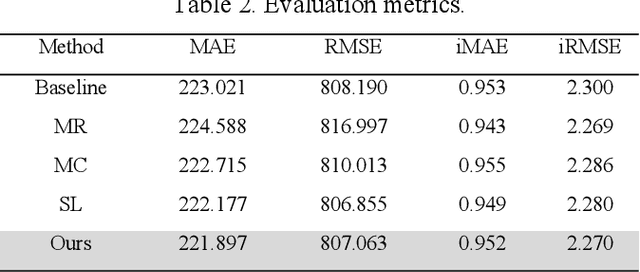
This paper presents a novel method for depth completion, which leverages multi-view improved monitored distillation to generate more precise depth maps. Our approach builds upon the state-of-the-art ensemble distillation method, in which we introduce a stereo-based model as a teacher model to improve the accuracy of the student model for depth completion. By minimizing the reconstruction error for a given image during ensemble distillation, we can avoid learning inherent error modes of completion-based teachers. To provide self-supervised information, we also employ multi-view depth consistency and multi-scale minimum reprojection. These techniques utilize existing structural constraints to yield supervised signals for student model training, without requiring costly ground truth depth information. Our extensive experimental evaluation demonstrates that our proposed method significantly improves the accuracy of the baseline monitored distillation method.
Structured Epipolar Matcher for Local Feature Matching
Apr 13, 2023
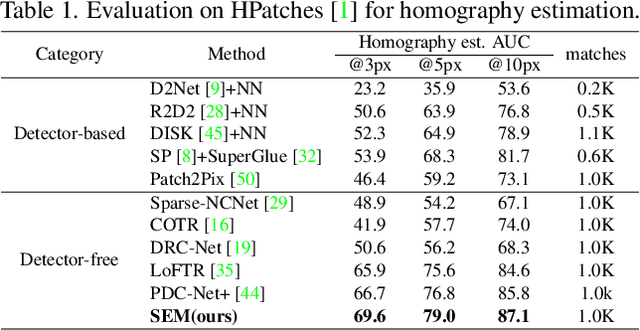

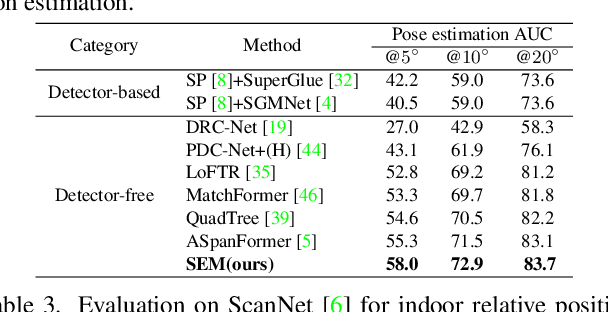
Local feature matching is challenging due to textureless and repetitive patterns. Existing methods focus on using appearance features and global interaction and matching, while the importance of geometry priors in local feature matching has not been fully exploited. Different from these methods, in this paper, we delve into the importance of geometry prior and propose Structured Epipolar Matcher (SEM) for local feature matching, which can leverage the geometric information in an iterative matching way. The proposed model enjoys several merits. First, our proposed Structured Feature Extractor can model the relative positional relationship between pixels and high-confidence anchor points. Second, our proposed Epipolar Attention and Matching can filter out irrelevant areas by utilizing the epipolar constraint. Extensive experimental results on five standard benchmarks demonstrate the superior performance of our SEM compared to state-of-the-art methods. Project page: https://sem2023.github.io.
counterfactuals: An R Package for Counterfactual Explanation Methods
Apr 13, 2023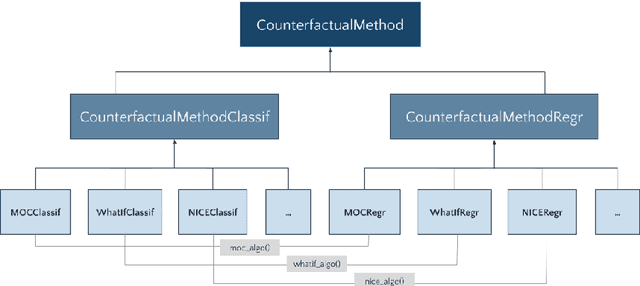

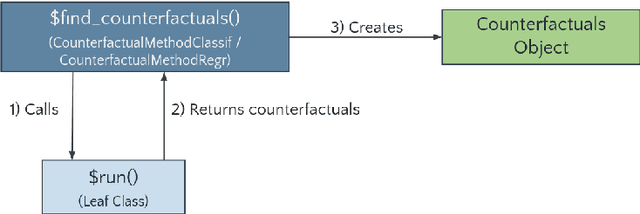

Counterfactual explanation methods provide information on how feature values of individual observations must be changed to obtain a desired prediction. Despite the increasing amount of proposed methods in research, only a few implementations exist whose interfaces and requirements vary widely. In this work, we introduce the counterfactuals R package, which provides a modular and unified R6-based interface for counterfactual explanation methods. We implemented three existing counterfactual explanation methods and propose some optional methodological extensions to generalize these methods to different scenarios and to make them more comparable. We explain the structure and workflow of the package using real use cases and show how to integrate additional counterfactual explanation methods into the package. In addition, we compared the implemented methods for a variety of models and datasets with regard to the quality of their counterfactual explanations and their runtime behavior.
ALR-GAN: Adaptive Layout Refinement for Text-to-Image Synthesis
Apr 13, 2023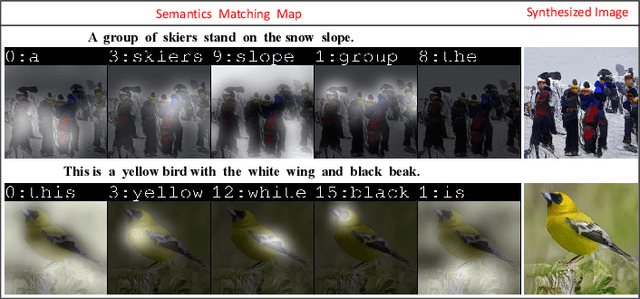
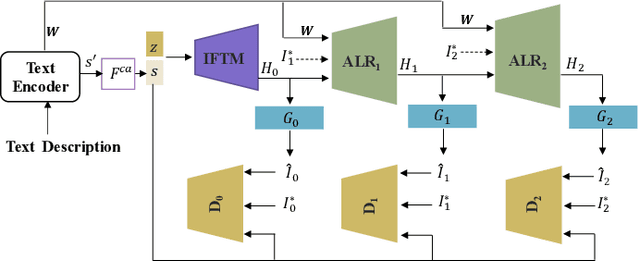
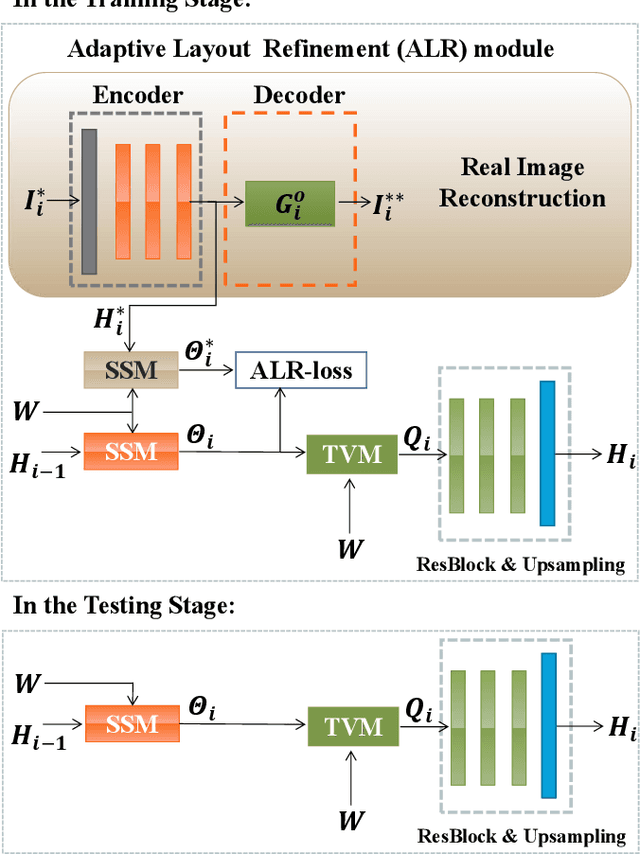

We propose a novel Text-to-Image Generation Network, Adaptive Layout Refinement Generative Adversarial Network (ALR-GAN), to adaptively refine the layout of synthesized images without any auxiliary information. The ALR-GAN includes an Adaptive Layout Refinement (ALR) module and a Layout Visual Refinement (LVR) loss. The ALR module aligns the layout structure (which refers to locations of objects and background) of a synthesized image with that of its corresponding real image. In ALR module, we proposed an Adaptive Layout Refinement (ALR) loss to balance the matching of hard and easy features, for more efficient layout structure matching. Based on the refined layout structure, the LVR loss further refines the visual representation within the layout area. Experimental results on two widely-used datasets show that ALR-GAN performs competitively at the Text-to-Image generation task.
Fully Convolutional Networks for Dense Water Flow Intensity Prediction in Swedish Catchment Areas
Apr 04, 2023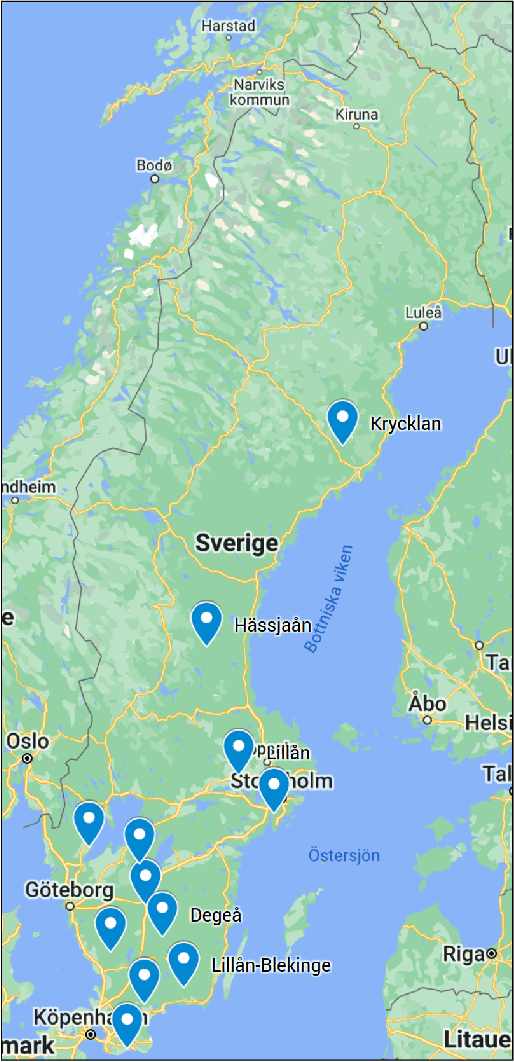
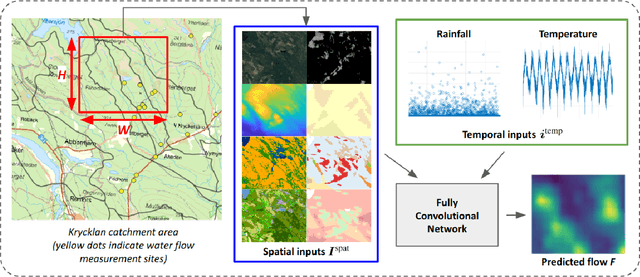
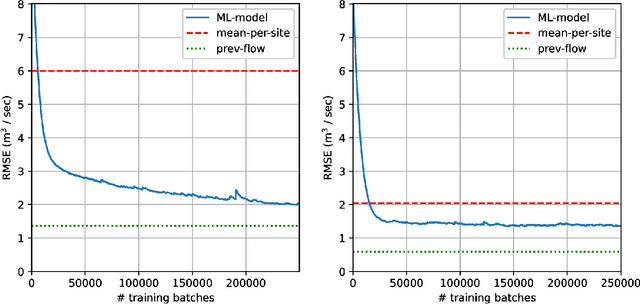
Intensifying climate change will lead to more extreme weather events, including heavy rainfall and drought. Accurate stream flow prediction models which are adaptable and robust to new circumstances in a changing climate will be an important source of information for decisions on climate adaptation efforts, especially regarding mitigation of the risks of and damages associated with flooding. In this work we propose a machine learning-based approach for predicting water flow intensities in inland watercourses based on the physical characteristics of the catchment areas, obtained from geospatial data (including elevation and soil maps, as well as satellite imagery), in addition to temporal information about past rainfall quantities and temperature variations. We target the one-day-ahead regime, where a fully convolutional neural network model receives spatio-temporal inputs and predicts the water flow intensity in every coordinate of the spatial input for the subsequent day. To the best of our knowledge, we are the first to tackle the task of dense water flow intensity prediction; earlier works have considered predicting flow intensities at a sparse set of locations at a time. An extensive set of model evaluations and ablations are performed, which empirically justify our various design choices. Code and preprocessed data have been made publicly available at https://github.com/aleksispi/fcn-water-flow.
Information-guided pixel augmentation for pixel-wise contrastive learning
Nov 14, 2022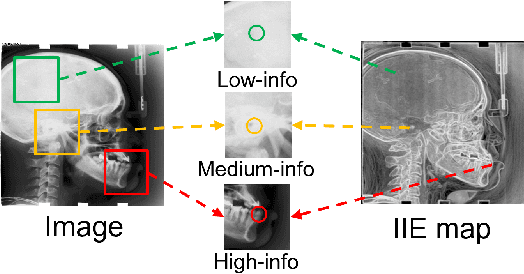
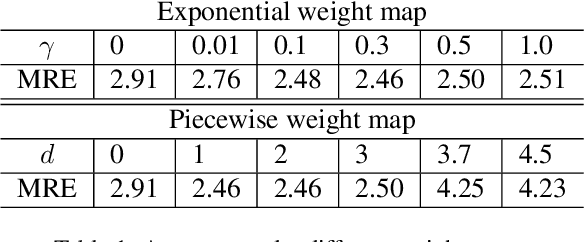
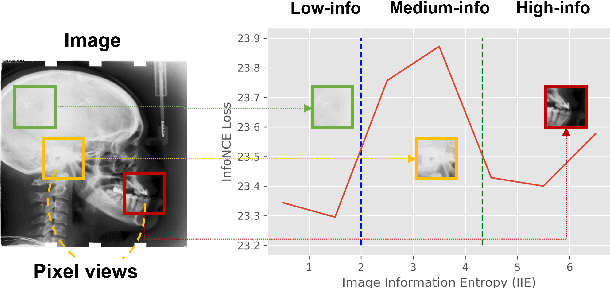

Contrastive learning (CL) is a form of self-supervised learning and has been widely used for various tasks. Different from widely studied instance-level contrastive learning, pixel-wise contrastive learning mainly helps with pixel-wise tasks such as medical landmark detection. The counterpart to an instance in instance-level CL is a pixel, along with its neighboring context, in pixel-wise CL. Aiming to build better feature representation, there is a vast literature about designing instance augmentation strategies for instance-level CL; but there is little similar work on pixel augmentation for pixel-wise CL with a pixel granularity. In this paper, we attempt to bridge this gap. We first classify a pixel into three categories, namely low-, medium-, and high-informative, based on the information quantity the pixel contains. Inspired by the ``InfoMin" principle, we then design separate augmentation strategies for each category in terms of augmentation intensity and sampling ratio. Extensive experiments validate that our information-guided pixel augmentation strategy succeeds in encoding more discriminative representations and surpassing other competitive approaches in unsupervised local feature matching. Furthermore, our pretrained model improves the performance of both one-shot and fully supervised models. To the best of our knowledge, we are the first to propose a pixel augmentation method with a pixel granularity for enhancing unsupervised pixel-wise contrastive learning.
Keep the Conversation Going: Fixing 162 out of 337 bugs for $0.42 each using ChatGPT
Apr 01, 2023
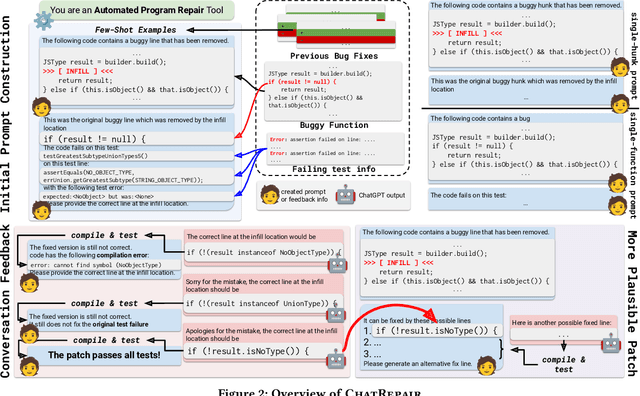
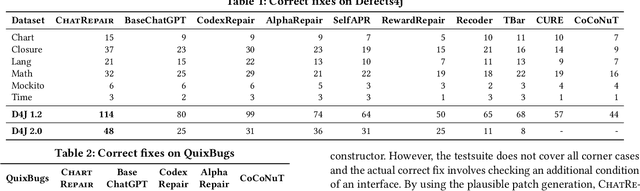
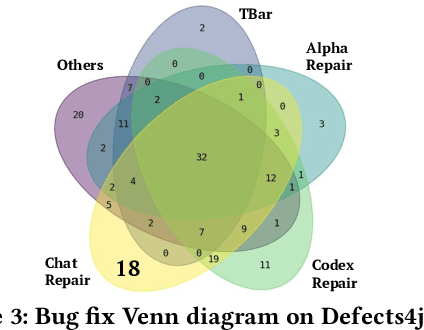
Automated Program Repair (APR) aims to automatically generate patches for buggy programs. Recent APR work has been focused on leveraging modern Large Language Models (LLMs) to directly generate patches for APR. Such LLM-based APR tools work by first constructing an input prompt built using the original buggy code and then queries the LLM to generate patches. While the LLM-based APR tools are able to achieve state-of-the-art results, it still follows the classic Generate and Validate repair paradigm of first generating lots of patches and then validating each one afterwards. This not only leads to many repeated patches that are incorrect but also miss the crucial information in test failures as well as in plausible patches. To address these limitations, we propose ChatRepair, the first fully automated conversation-driven APR approach that interleaves patch generation with instant feedback to perform APR in a conversational style. ChatRepair first feeds the LLM with relevant test failure information to start with, and then learns from both failures and successes of earlier patching attempts of the same bug for more powerful APR. For earlier patches that failed to pass all tests, we combine the incorrect patches with their corresponding relevant test failure information to construct a new prompt for the LLM to generate the next patch. In this way, we can avoid making the same mistakes. For earlier patches that passed all the tests, we further ask the LLM to generate alternative variations of the original plausible patches. In this way, we can further build on and learn from earlier successes to generate more plausible patches to increase the chance of having correct patches. While our approach is general, we implement ChatRepair using state-of-the-art dialogue-based LLM -- ChatGPT. By calculating the cost of accessing ChatGPT, we can fix 162 out of 337 bugs for \$0.42 each!
Prompt Pre-Training with Twenty-Thousand Classes for Open-Vocabulary Visual Recognition
Apr 10, 2023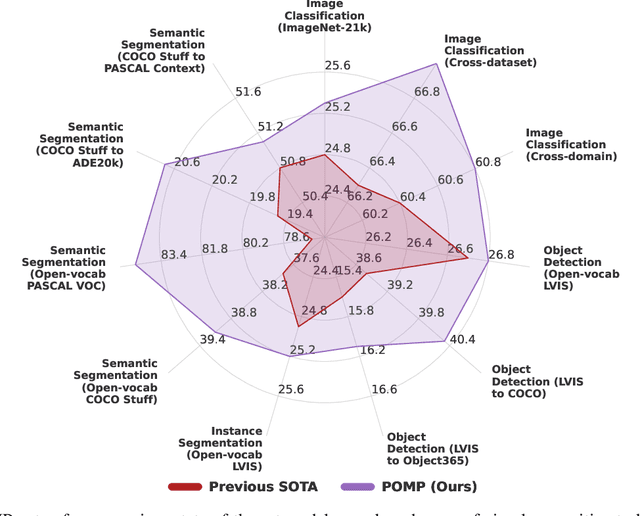
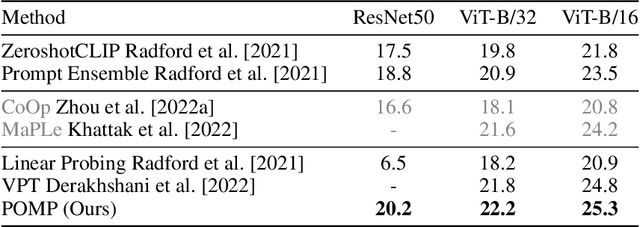
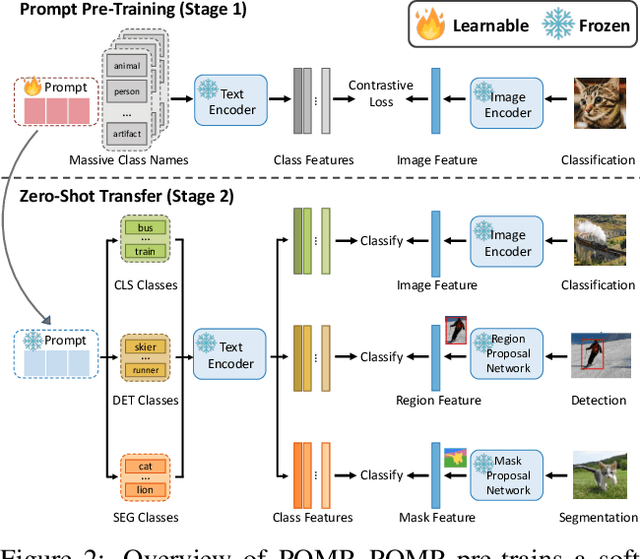
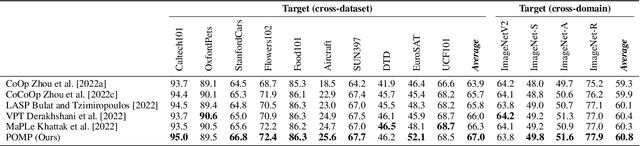
This work proposes POMP, a prompt pre-training method for vision-language models. Being memory and computation efficient, POMP enables the learned prompt to condense semantic information for a rich set of visual concepts with over twenty-thousand classes. Once pre-trained, the prompt with a strong transferable ability can be directly plugged into a variety of visual recognition tasks including image classification, semantic segmentation, and object detection, to boost recognition performances in a zero-shot manner. Empirical evaluation shows that POMP achieves state-of-the-art performances on 21 downstream datasets, e.g., 67.0% average accuracy on 10 classification dataset (+3.1% compared to CoOp) and 84.4 hIoU on open-vocabulary Pascal VOC segmentation (+6.9 compared to ZSSeg).
Relational Context Learning for Human-Object Interaction Detection
Apr 11, 2023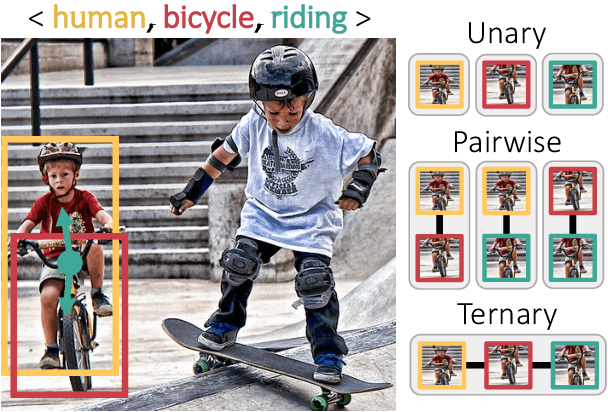
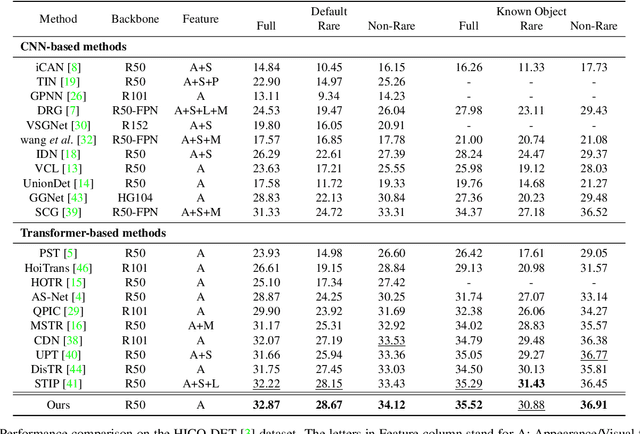
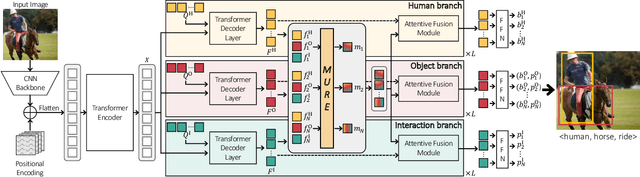
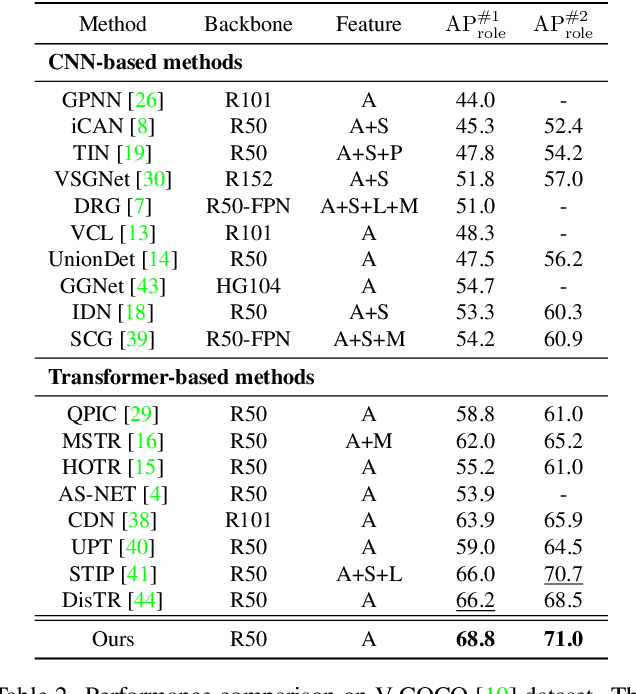
Recent state-of-the-art methods for HOI detection typically build on transformer architectures with two decoder branches, one for human-object pair detection and the other for interaction classification. Such disentangled transformers, however, may suffer from insufficient context exchange between the branches and lead to a lack of context information for relational reasoning, which is critical in discovering HOI instances. In this work, we propose the multiplex relation network (MUREN) that performs rich context exchange between three decoder branches using unary, pairwise, and ternary relations of human, object, and interaction tokens. The proposed method learns comprehensive relational contexts for discovering HOI instances, achieving state-of-the-art performance on two standard benchmarks for HOI detection, HICO-DET and V-COCO.
Towards preserving word order importance through Forced Invalidation
Apr 11, 2023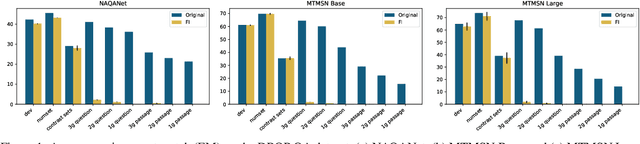
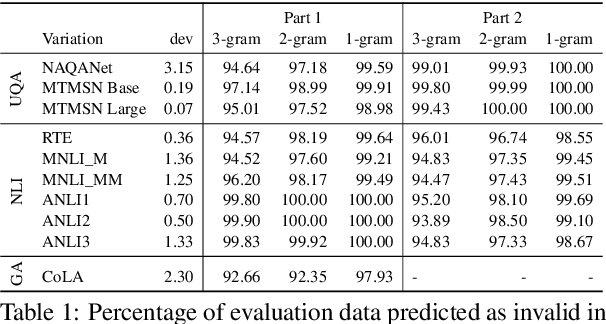
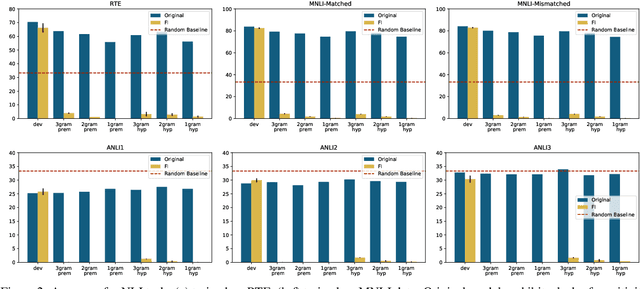
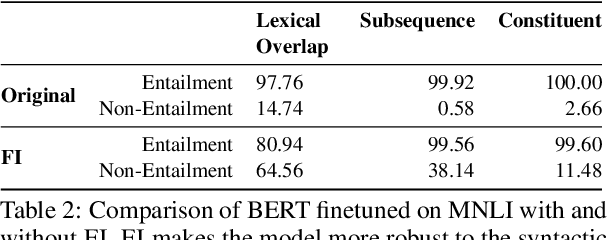
Large pre-trained language models such as BERT have been widely used as a framework for natural language understanding (NLU) tasks. However, recent findings have revealed that pre-trained language models are insensitive to word order. The performance on NLU tasks remains unchanged even after randomly permuting the word of a sentence, where crucial syntactic information is destroyed. To help preserve the importance of word order, we propose a simple approach called Forced Invalidation (FI): forcing the model to identify permuted sequences as invalid samples. We perform an extensive evaluation of our approach on various English NLU and QA based tasks over BERT-based and attention-based models over word embeddings. Our experiments demonstrate that Forced Invalidation significantly improves the sensitivity of the models to word order.