 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Toward Auto-evaluation with Confidence-based Category Relation-aware Regression
Apr 17, 2023

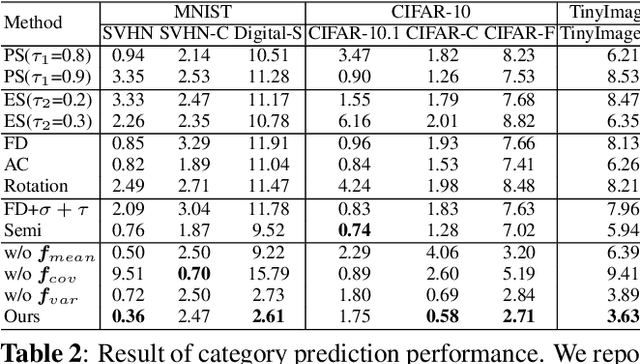
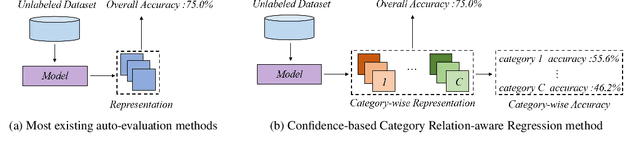
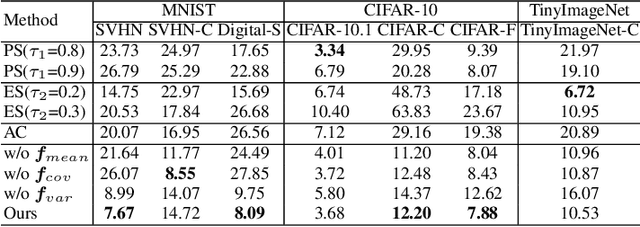
Auto-evaluation aims to automatically evaluate a trained model on any test dataset without human annotations. Most existing methods utilize global statistics of features extracted by the model as the representation of a dataset. This ignores the influence of the classification head and loses category-wise confusion information of the model. However, ratios of instances assigned to different categories together with their confidence scores reflect how many instances in which categories are difficult for the model to classify, which contain significant indicators for both overall and category-wise performances. In this paper, we propose a Confidence-based Category Relation-aware Regression ($C^2R^2$) method. $C^2R^2$ divides all instances in a meta-set into different categories according to their confidence scores and extracts the global representation from them. For each category, $C^2R^2$ encodes its local confusion relations to other categories into a local representation. The overall and category-wise performances are regressed from global and local representations, respectively. Extensive experiments show the effectiveness of our method.
Secret-Keeping in Question Answering
Mar 16, 2023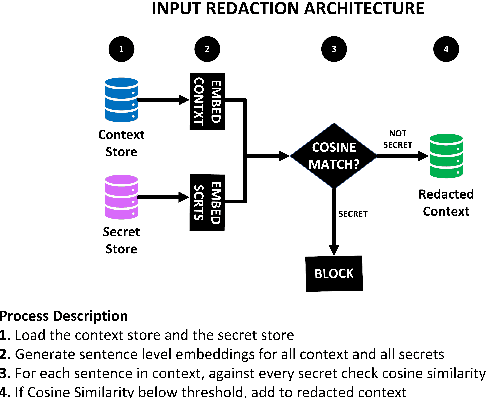
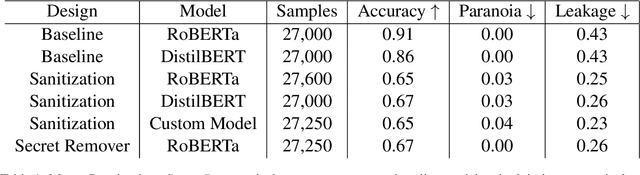
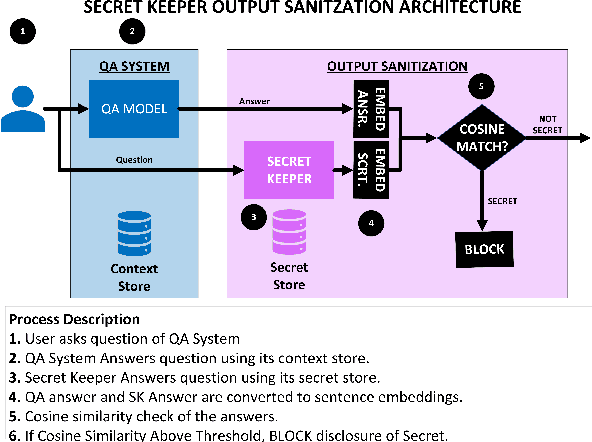
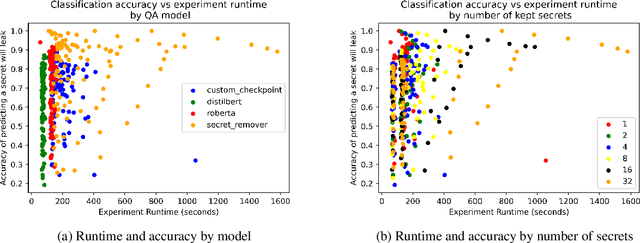
Existing question-answering research focuses on unanswerable questions in the context of always providing an answer when a system can\dots but what about cases where a system {\bf should not} answer a question. This can either be to protect sensitive users or sensitive information. Many models expose sensitive information under interrogation by an adversarial user. We seek to determine if it is possible to teach a question-answering system to keep a specific fact secret. We design and implement a proof-of-concept architecture and through our evaluation determine that while possible, there are numerous directions for future research to reduce system paranoia (false positives), information leakage (false negatives) and extend the implementation of the work to more complex problems with preserving secrecy in the presence of information aggregation.
Analysis of information cascading and propagation barriers across distinctive news events
Dec 15, 2022News reporting on events that occur in our society can have different styles and structures as well as different dynamics of news spreading over time. News publishers have the potential to spread their news and reach out to a large number of readers worldwide. In this paper we would like to understand how well they are doing it and which kind of obstacles the news may encounter when spreading. The news to be spread wider cross multiple barriers such as linguistic (the most evident one as they get published in other natural languages), economic, geographical, political, time zone, and cultural barriers. Observing potential differences between spreading of news on different events published by multiple publishers can bring insights into what may influence the differences in the spreading patterns. There are multiple reasons, possibly many hidden, influencing the speed and geographical spread of news. This paper studies information cascading and propagation barriers, applying the proposed methodology on three distinctive kinds of events: Global Warming, earthquakes, and FIFA World Cup.
High Dynamic Range Imaging with Context-aware Transformer
Apr 21, 2023
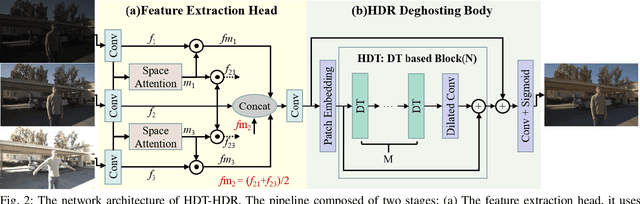
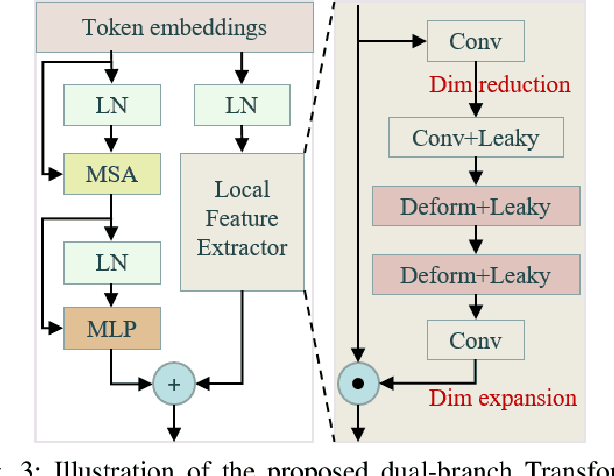

Avoiding the introduction of ghosts when synthesising LDR images as high dynamic range (HDR) images is a challenging task. Convolutional neural networks (CNNs) are effective for HDR ghost removal in general, but are challenging to deal with the LDR images if there are large movements or oversaturation/undersaturation. Existing dual-branch methods combining CNN and Transformer omit part of the information from non-reference images, while the features extracted by the CNN-based branch are bound to the kernel size with small receptive field, which are detrimental to the deblurring and the recovery of oversaturated/undersaturated regions. In this paper, we propose a novel hierarchical dual Transformer method for ghost-free HDR (HDT-HDR) images generation, which extracts global features and local features simultaneously. First, we use a CNN-based head with spatial attention mechanisms to extract features from all the LDR images. Second, the LDR features are delivered to the Hierarchical Dual Transformer (HDT). In each Dual Transformer (DT), the global features are extracted by the window-based Transformer, while the local details are extracted using the channel attention mechanism with deformable CNNs. Finally, the ghost free HDR image is obtained by dimensional mapping on the HDT output. Abundant experiments demonstrate that our HDT-HDR achieves the state-of-the-art performance among existing HDR ghost removal methods.
Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm
Apr 21, 2023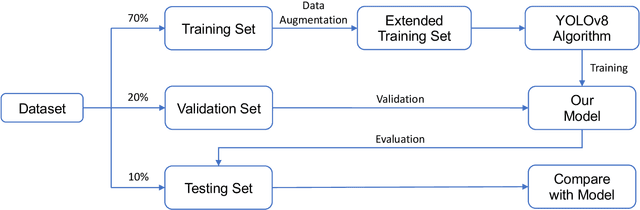
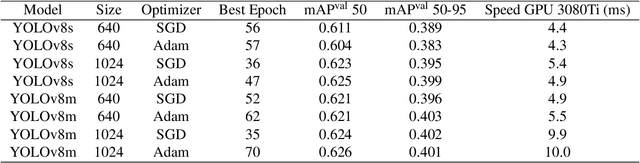
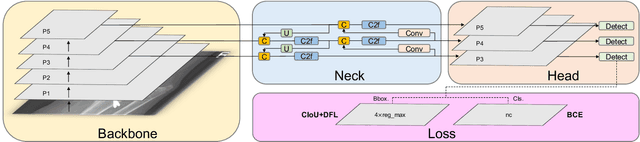
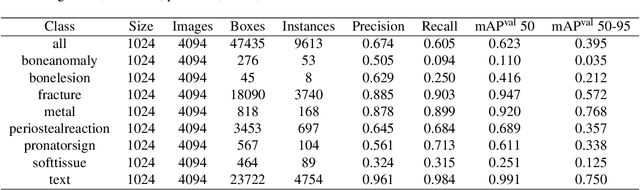
Hospital emergency departments frequently receive lots of bone fracture cases, with pediatric wrist trauma fracture accounting for the majority of them. Before pediatric surgeons perform surgery, they need to ask patients how the fracture occurred and analyze the fracture situation by interpreting X-ray images. The interpretation of X-ray images often requires a combination of techniques from radiologists and surgeons, which requires time-consuming specialized training. With the rise of deep learning in the field of computer vision, network models applying for fracture detection has become an important research topic. In this paper, YOLOv8 algorithm is used to train models on the GRAZPEDWRI-DX dataset, which includes X-ray images from 6,091 pediatric patients with wrist trauma. The experimental results show that YOLOv8 algorithm models have different advantages for different model sizes, with YOLOv8l model achieving the highest mean average precision (mAP 50) of 63.6%, and YOLOv8n model achieving the inference time of 67.4ms per X-ray image on one single CPU with low computing power. This work demonstrates that YOLOv8 algorithm has good generalizability and creates the "Fracture Detection Using YOLOv8 App" to assist surgeons in interpreting fractures in X-ray images, reducing the probability of error, and providing more useful information for fracture surgery. Our implementation code is released at https://github.com/RuiyangJu/Bone_Fracture_Detection_YOLOv8.
Improving Identity-Robustness for Face Models
Apr 07, 2023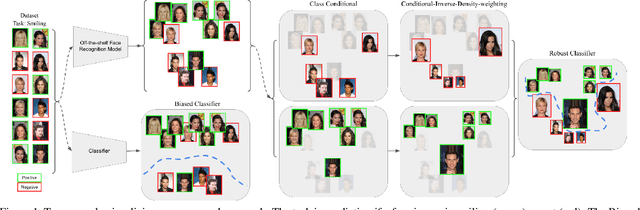
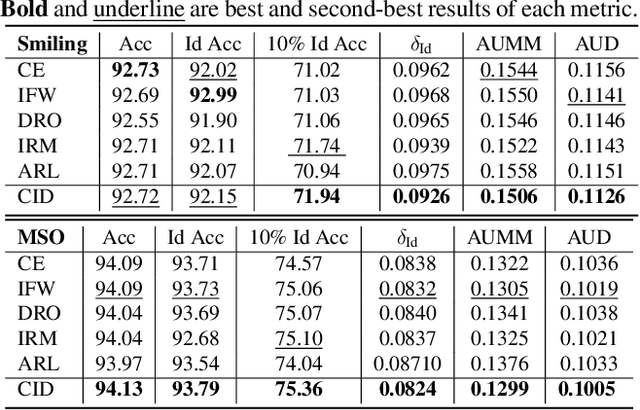
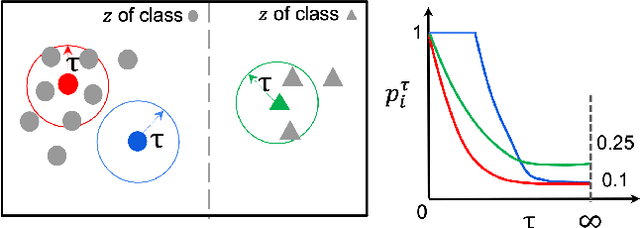
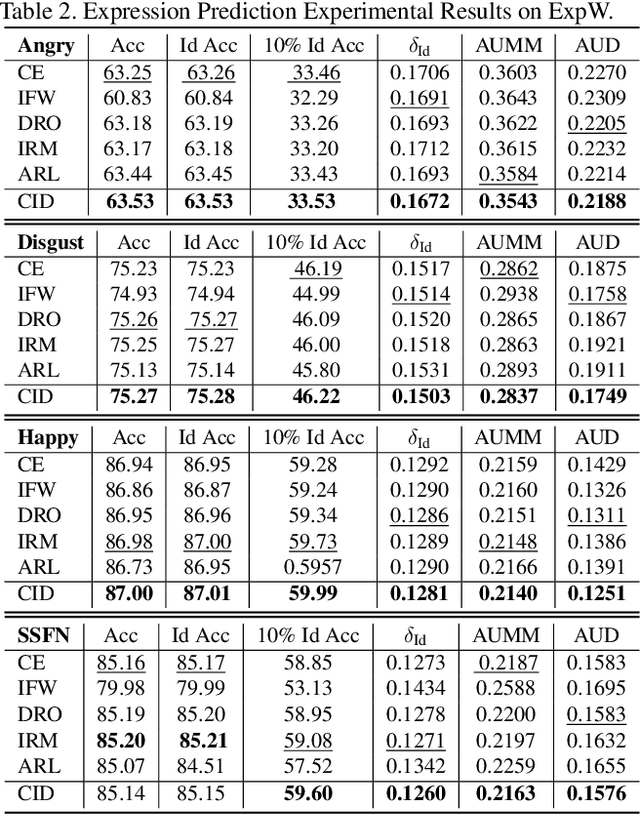
Despite the success of deep-learning models in many tasks, there have been concerns about such models learning shortcuts, and their lack of robustness to irrelevant confounders. When it comes to models directly trained on human faces, a sensitive confounder is that of human identities. Many face-related tasks should ideally be identity-independent, and perform uniformly across different individuals (i.e. be fair). One way to measure and enforce such robustness and performance uniformity is through enforcing it during training, assuming identity-related information is available at scale. However, due to privacy concerns and also the cost of collecting such information, this is often not the case, and most face datasets simply contain input images and their corresponding task-related labels. Thus, improving identity-related robustness without the need for such annotations is of great importance. Here, we explore using face-recognition embedding vectors, as proxies for identities, to enforce such robustness. We propose to use the structure in the face-recognition embedding space, to implicitly emphasize rare samples within each class. We do so by weighting samples according to their conditional inverse density (CID) in the proxy embedding space. Our experiments suggest that such a simple sample weighting scheme, not only improves the training robustness, it often improves the overall performance as a result of such robustness. We also show that employing such constraints during training results in models that are significantly less sensitive to different levels of bias in the dataset.
HyperThumbnail: Real-time 6K Image Rescaling with Rate-distortion Optimization
Apr 03, 2023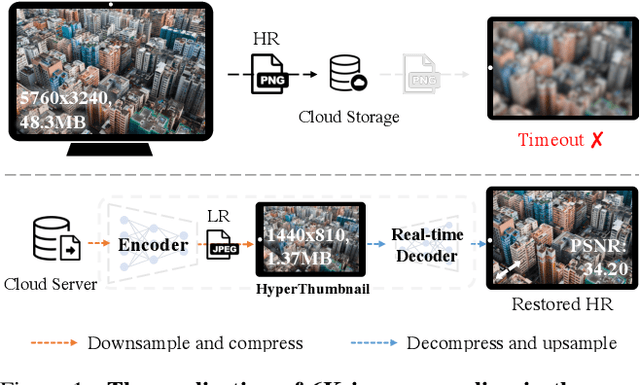
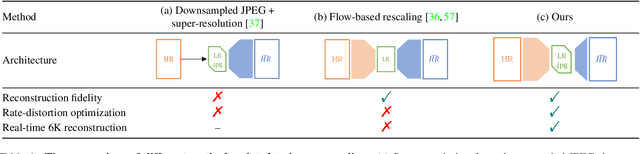
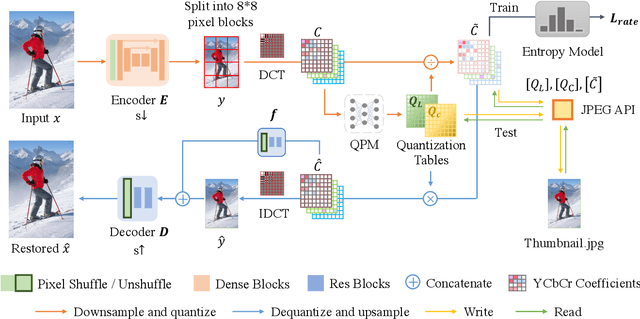
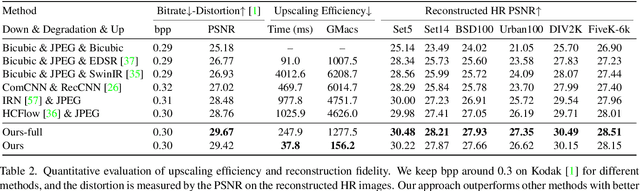
Contemporary image rescaling aims at embedding a high-resolution (HR) image into a low-resolution (LR) thumbnail image that contains embedded information for HR image reconstruction. Unlike traditional image super-resolution, this enables high-fidelity HR image restoration faithful to the original one, given the embedded information in the LR thumbnail. However, state-of-the-art image rescaling methods do not optimize the LR image file size for efficient sharing and fall short of real-time performance for ultra-high-resolution (e.g., 6K) image reconstruction. To address these two challenges, we propose a novel framework (HyperThumbnail) for real-time 6K rate-distortion-aware image rescaling. Our framework first embeds an HR image into a JPEG LR thumbnail by an encoder with our proposed quantization prediction module, which minimizes the file size of the embedding LR JPEG thumbnail while maximizing HR reconstruction quality. Then, an efficient frequency-aware decoder reconstructs a high-fidelity HR image from the LR one in real time. Extensive experiments demonstrate that our framework outperforms previous image rescaling baselines in rate-distortion performance and can perform 6K image reconstruction in real time.
CT Multi-Task Learning with a Large Image-Text (LIT) Model
Apr 03, 2023Large language models (LLM) not only empower multiple language tasks but also serve as a general interface across different spaces. Up to now, it has not been demonstrated yet how to effectively translate the successes of LLMs in the computer vision field to the medical imaging field which involves high-dimensional and multi-modal medical images. In this paper, we report a feasibility study of building a multi-task CT large image-text (LIT) model for lung cancer diagnosis by combining an LLM and a large image model (LIM). Specifically, the LLM and LIM are used as encoders to perceive multi-modal information under task-specific text prompts, which synergizes multi-source information and task-specific and patient-specific priors for optimized diagnostic performance. The key components of our LIT model and associated techniques are evaluated with an emphasis on 3D lung CT analysis. Our initial results show that the LIT model performs multiple medical tasks well, including lung segmentation, lung nodule detection, and lung cancer classification. Active efforts are in progress to develop large image-language models for superior medical imaging in diverse applications and optimal patient outcomes.
Data-efficient End-to-end Information Extraction for Statistical Legal Analysis
Nov 03, 2022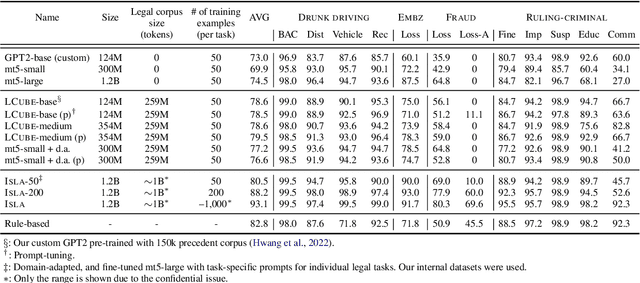
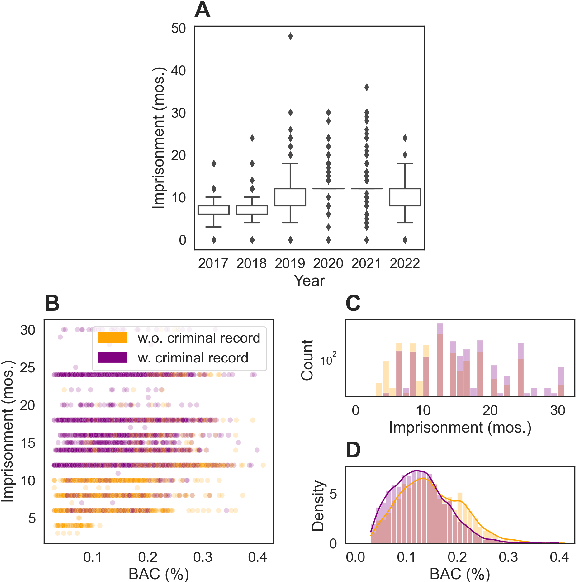
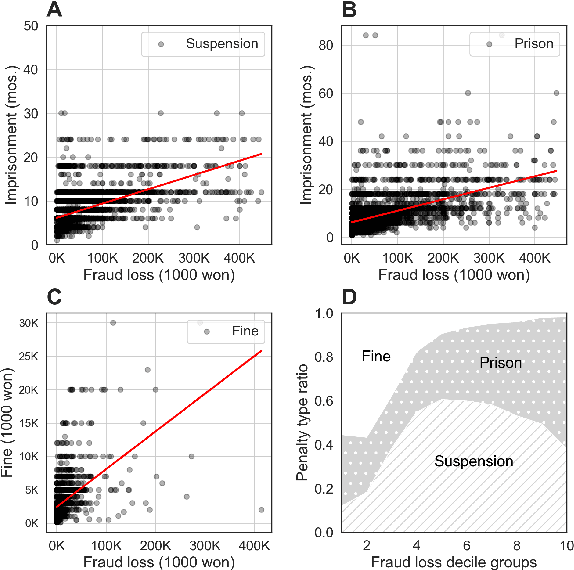

Legal practitioners often face a vast amount of documents. Lawyers, for instance, search for appropriate precedents favorable to their clients, while the number of legal precedents is ever-growing. Although legal search engines can assist finding individual target documents and narrowing down the number of candidates, retrieved information is often presented as unstructured text and users have to examine each document thoroughly which could lead to information overloading. This also makes their statistical analysis challenging. Here, we present an end-to-end information extraction (IE) system for legal documents. By formulating IE as a generation task, our system can be easily applied to various tasks without domain-specific engineering effort. The experimental results of four IE tasks on Korean precedents shows that our IE system can achieve competent scores (-2.3 on average) compared to the rule-based baseline with as few as 50 training examples per task and higher score (+5.4 on average) with 200 examples. Finally, our statistical analysis on two case categories--drunk driving and fraud--with 35k precedents reveals the resulting structured information from our IE system faithfully reflects the macroscopic features of Korean legal system.
TiDy-PSFs: Computational Imaging with Time-Averaged Dynamic Point-Spread-Functions
Mar 30, 2023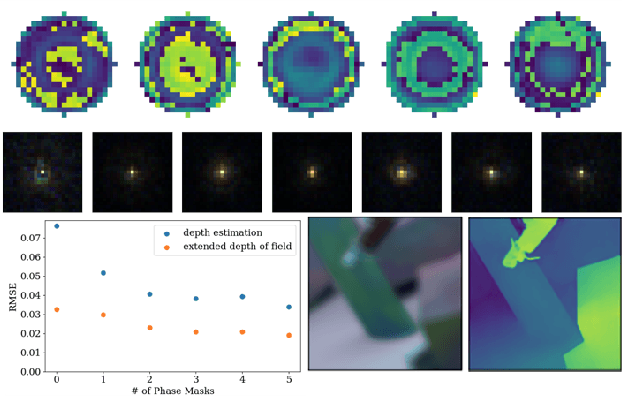
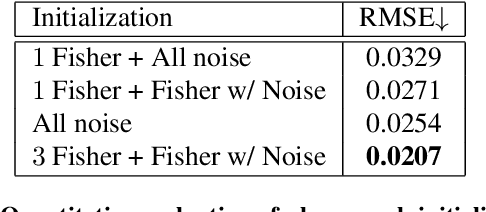

Point-spread-function (PSF) engineering is a powerful computational imaging techniques wherein a custom phase mask is integrated into an optical system to encode additional information into captured images. Used in combination with deep learning, such systems now offer state-of-the-art performance at monocular depth estimation, extended depth-of-field imaging, lensless imaging, and other tasks. Inspired by recent advances in spatial light modulator (SLM) technology, this paper answers a natural question: Can one encode additional information and achieve superior performance by changing a phase mask dynamically over time? We first prove that the set of PSFs described by static phase masks is non-convex and that, as a result, time-averaged PSFs generated by dynamic phase masks are fundamentally more expressive. We then demonstrate, in simulation, that time-averaged dynamic (TiDy) phase masks can offer substantially improved monocular depth estimation and extended depth-of-field imaging performance.