 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Time Series Representation Learning with Supervised Contrastive Temporal Transformer
Mar 16, 2024
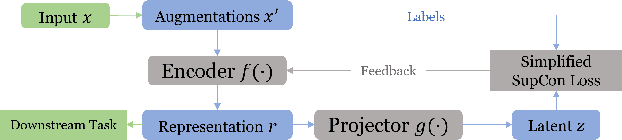
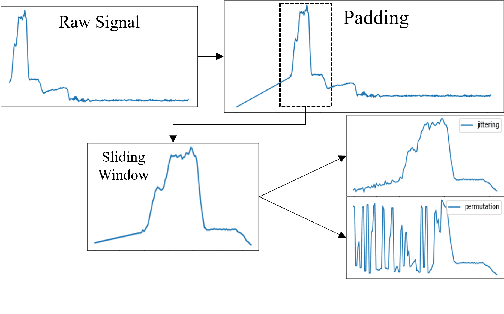
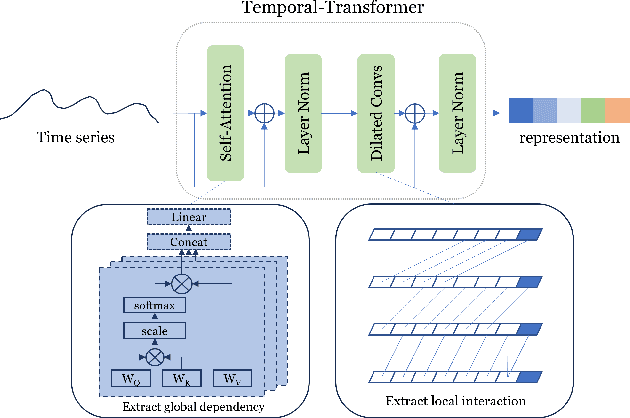
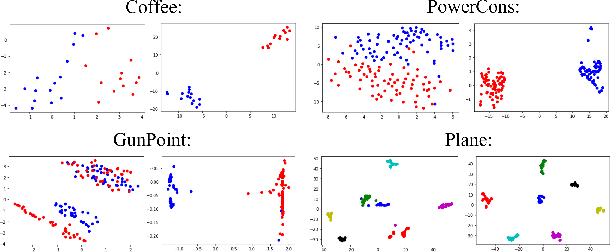
Finding effective representations for time series data is a useful but challenging task. Several works utilize self-supervised or unsupervised learning methods to address this. However, there still remains the open question of how to leverage available label information for better representations. To answer this question, we exploit pre-existing techniques in time series and representation learning domains and develop a simple, yet novel fusion model, called: \textbf{S}upervised \textbf{CO}ntrastive \textbf{T}emporal \textbf{T}ransformer (SCOTT). We first investigate suitable augmentation methods for various types of time series data to assist with learning change-invariant representations. Secondly, we combine Transformer and Temporal Convolutional Networks in a simple way to efficiently learn both global and local features. Finally, we simplify Supervised Contrastive Loss for representation learning of labelled time series data. We preliminarily evaluate SCOTT on a downstream task, Time Series Classification, using 45 datasets from the UCR archive. The results show that with the representations learnt by SCOTT, even a weak classifier can perform similar to or better than existing state-of-the-art models (best performance on 23/45 datasets and highest rank against 9 baseline models). Afterwards, we investigate SCOTT's ability to address a real-world task, online Change Point Detection (CPD), on two datasets: a human activity dataset and a surgical patient dataset. We show that the model performs with high reliability and efficiency on the online CPD problem ($\sim$98\% and $\sim$97\% area under precision-recall curve respectively). Furthermore, we demonstrate the model's potential in tackling early detection and show it performs best compared to other candidates.
rFaceNet: An End-to-End Network for Enhanced Physiological Signal Extraction through Identity-Specific Facial Contours
Mar 14, 2024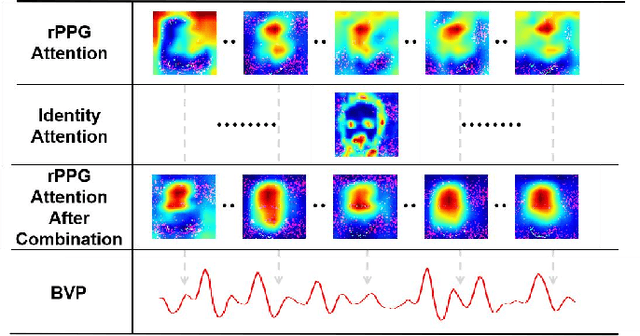
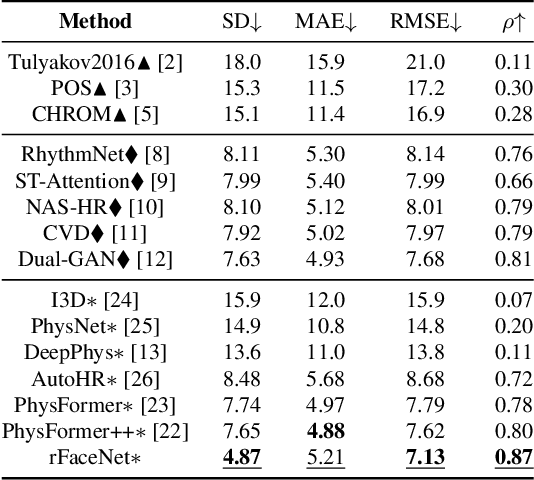
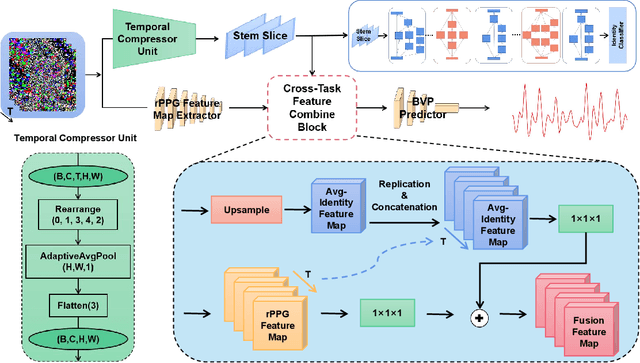
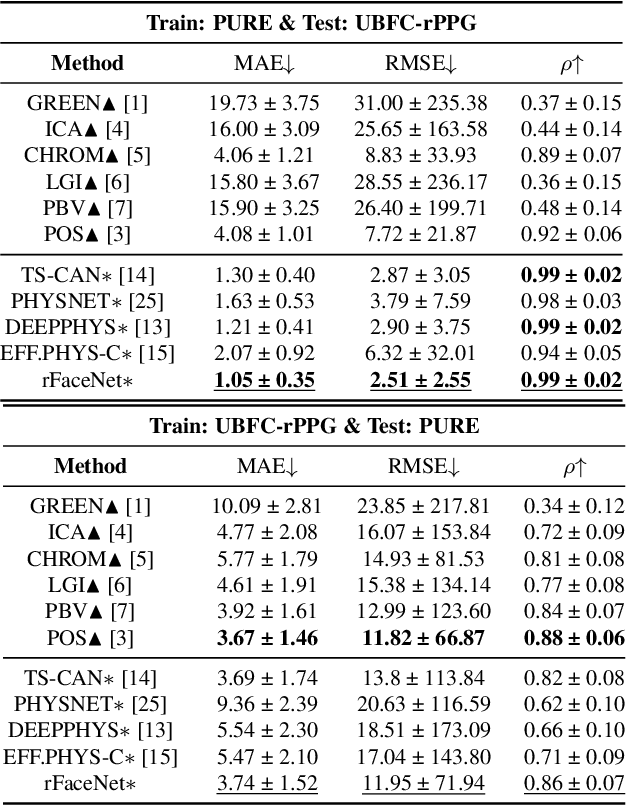
Remote photoplethysmography (rPPG) technique extracts blood volume pulse (BVP) signals from subtle pixel changes in video frames. This study introduces rFaceNet, an advanced rPPG method that enhances the extraction of facial BVP signals with a focus on facial contours. rFaceNet integrates identity-specific facial contour information and eliminates redundant data. It efficiently extracts facial contours from temporally normalized frame inputs through a Temporal Compressor Unit (TCU) and steers the model focus to relevant facial regions by using the Cross-Task Feature Combiner (CTFC). Through elaborate training, the quality and interpretability of facial physiological signals extracted by rFaceNet are greatly improved compared to previous methods. Moreover, our novel approach demonstrates superior performance than SOTA methods in various heart rate estimation benchmarks.
Reliable Spatial-Temporal Voxels For Multi-Modal Test-Time Adaptation
Mar 15, 2024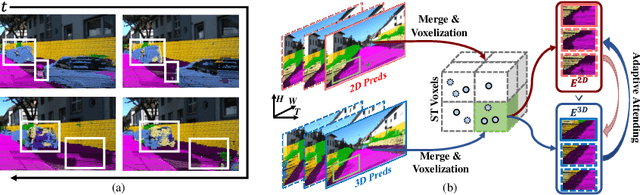
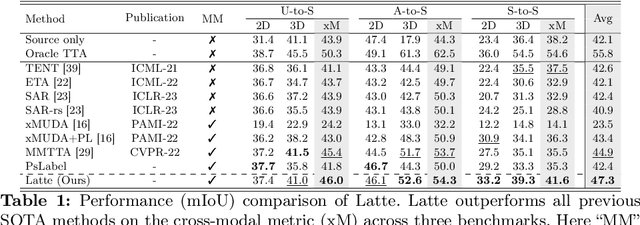
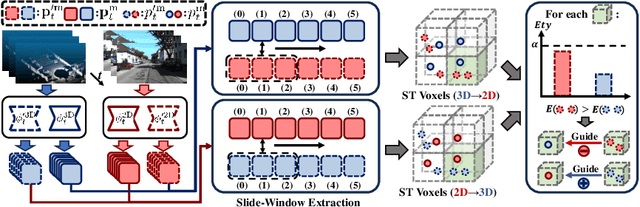
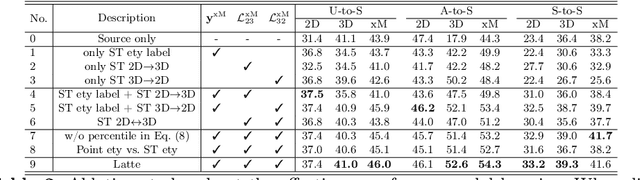
Multi-modal test-time adaptation (MM-TTA) is proposed to adapt models to an unlabeled target domain by leveraging the complementary multi-modal inputs in an online manner. Previous MM-TTA methods rely on predictions of cross-modal information in each input frame, while they ignore the fact that predictions of geometric neighborhoods within consecutive frames are highly correlated, leading to unstable predictions across time. To fulfill this gap, we propose ReLiable Spatial-temporal Voxels (Latte), an MM-TTA method that leverages reliable cross-modal spatial-temporal correspondences for multi-modal 3D segmentation. Motivated by the fact that reliable predictions should be consistent with their spatial-temporal correspondences, Latte aggregates consecutive frames in a slide window manner and constructs ST voxel to capture temporally local prediction consistency for each modality. After filtering out ST voxels with high ST entropy, Latte conducts cross-modal learning for each point and pixel by attending to those with reliable and consistent predictions among both spatial and temporal neighborhoods. Experimental results show that Latte achieves state-of-the-art performance on three different MM-TTA benchmarks compared to previous MM-TTA or TTA methods.
A Novel Framework for Multi-Person Temporal Gaze Following and Social Gaze Prediction
Mar 15, 2024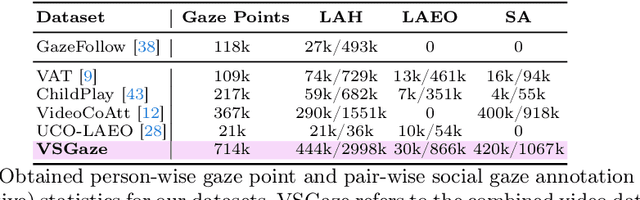
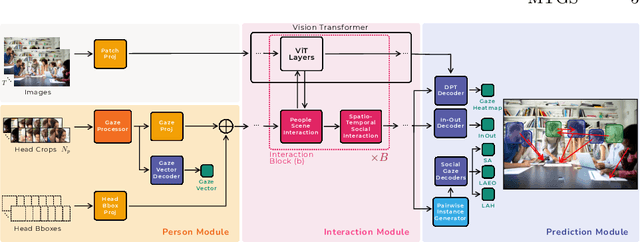
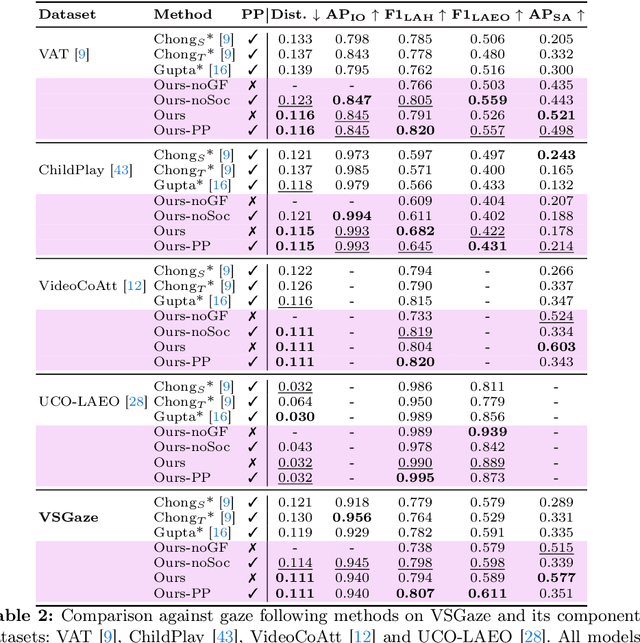
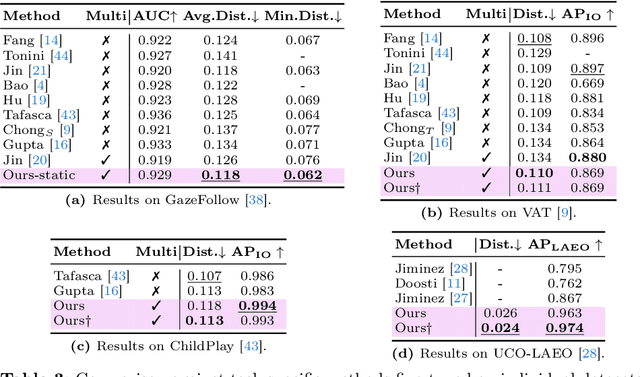
Gaze following and social gaze prediction are fundamental tasks providing insights into human communication behaviors, intent, and social interactions. Most previous approaches addressed these tasks separately, either by designing highly specialized social gaze models that do not generalize to other social gaze tasks or by considering social gaze inference as an ad-hoc post-processing of the gaze following task. Furthermore, the vast majority of gaze following approaches have proposed static models that can handle only one person at a time, therefore failing to take advantage of social interactions and temporal dynamics. In this paper, we address these limitations and introduce a novel framework to jointly predict the gaze target and social gaze label for all people in the scene. The framework comprises of: (i) a temporal, transformer-based architecture that, in addition to image tokens, handles person-specific tokens capturing the gaze information related to each individual; (ii) a new dataset, VSGaze, that unifies annotation types across multiple gaze following and social gaze datasets. We show that our model trained on VSGaze can address all tasks jointly, and achieves state-of-the-art results for multi-person gaze following and social gaze prediction.
Learning Physical Dynamics for Object-centric Visual Prediction
Mar 15, 2024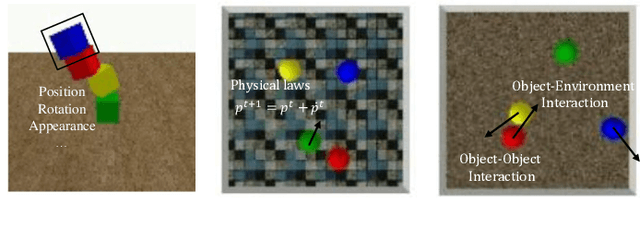
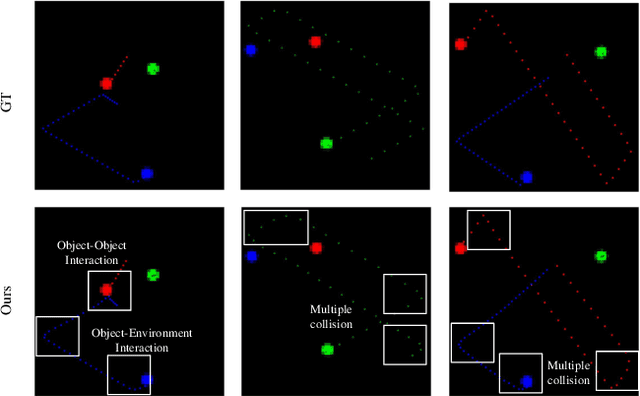
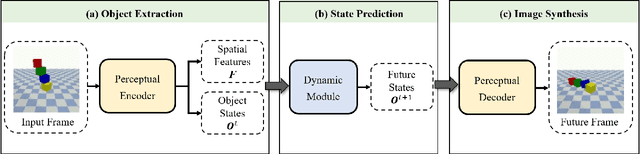
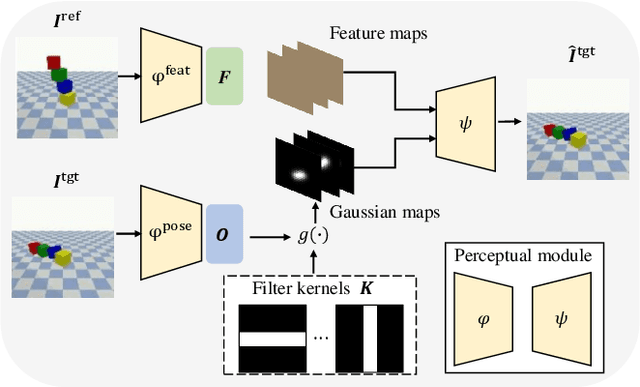
The ability to model the underlying dynamics of visual scenes and reason about the future is central to human intelligence. Many attempts have been made to empower intelligent systems with such physical understanding and prediction abilities. However, most existing methods focus on pixel-to-pixel prediction, which suffers from heavy computational costs while lacking a deep understanding of the physical dynamics behind videos. Recently, object-centric prediction methods have emerged and attracted increasing interest. Inspired by it, this paper proposes an unsupervised object-centric prediction model that makes future predictions by learning visual dynamics between objects. Our model consists of two modules, perceptual, and dynamic module. The perceptual module is utilized to decompose images into several objects and synthesize images with a set of object-centric representations. The dynamic module fuses contextual information, takes environment-object and object-object interaction into account, and predicts the future trajectory of objects. Extensive experiments are conducted to validate the effectiveness of the proposed method. Both quantitative and qualitative experimental results demonstrate that our model generates higher visual quality and more physically reliable predictions compared to the state-of-the-art methods.
HawkEye: Training Video-Text LLMs for Grounding Text in Videos
Mar 15, 2024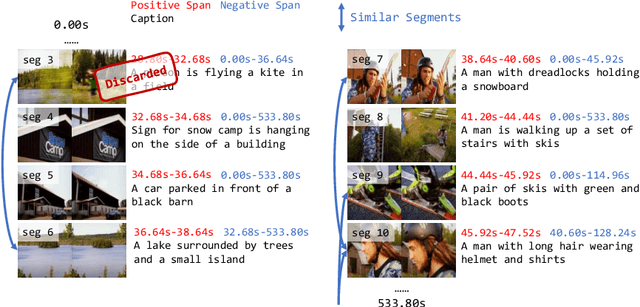
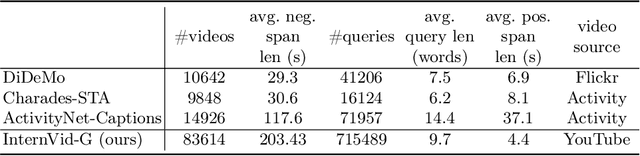
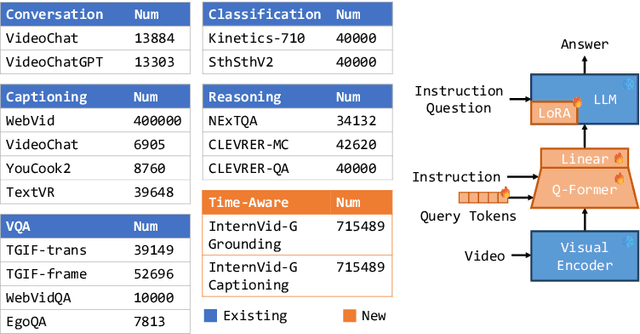

Video-text Large Language Models (video-text LLMs) have shown remarkable performance in answering questions and holding conversations on simple videos. However, they perform almost the same as random on grounding text queries in long and complicated videos, having little ability to understand and reason about temporal information, which is the most fundamental difference between videos and images. In this paper, we propose HawkEye, one of the first video-text LLMs that can perform temporal video grounding in a fully text-to-text manner. To collect training data that is applicable for temporal video grounding, we construct InternVid-G, a large-scale video-text corpus with segment-level captions and negative spans, with which we introduce two new time-aware training objectives to video-text LLMs. We also propose a coarse-grained method of representing segments in videos, which is more robust and easier for LLMs to learn and follow than other alternatives. Extensive experiments show that HawkEye is better at temporal video grounding and comparable on other video-text tasks with existing video-text LLMs, which verifies its superior video-text multi-modal understanding abilities.
SurvRNC: Learning Ordered Representations for Survival Prediction using Rank-N-Contrast
Mar 15, 2024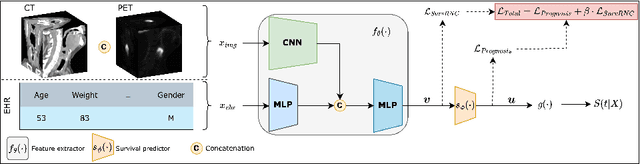
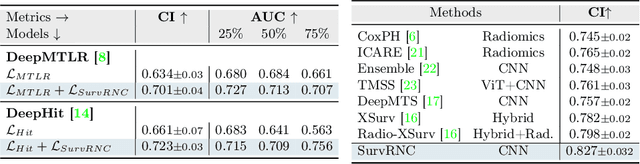
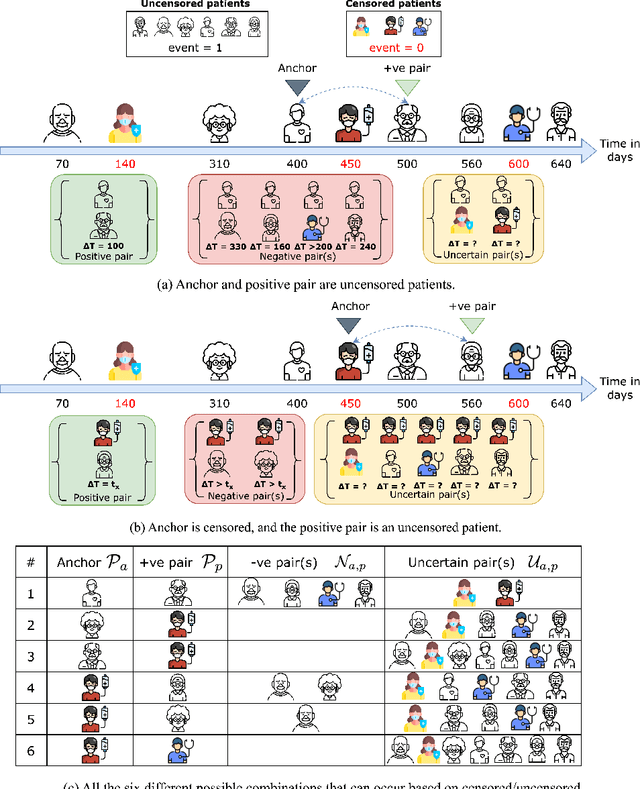
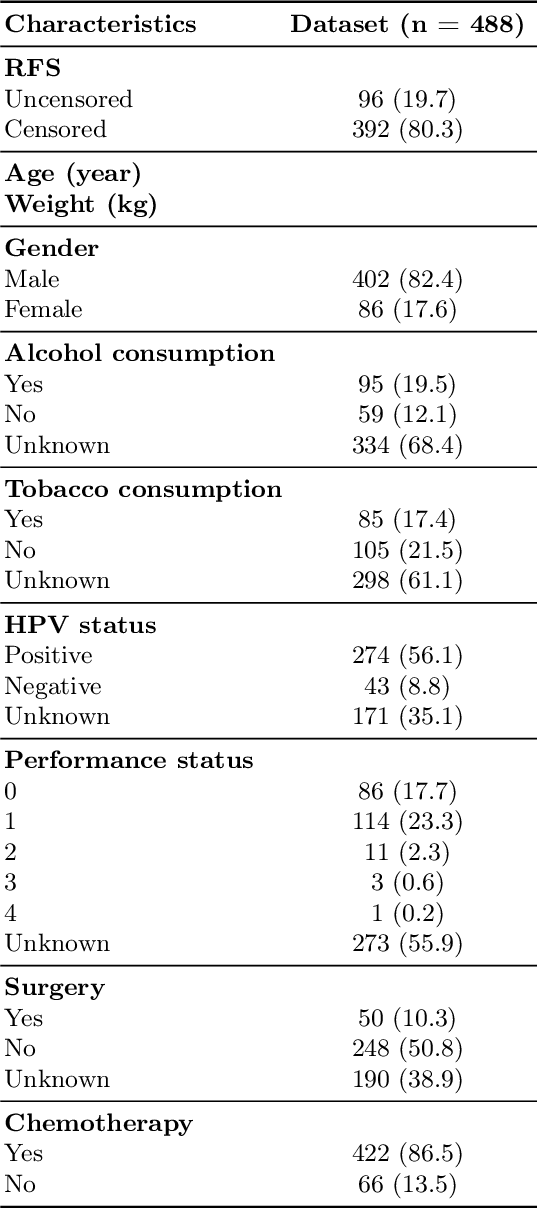
Predicting the likelihood of survival is of paramount importance for individuals diagnosed with cancer as it provides invaluable information regarding prognosis at an early stage. This knowledge enables the formulation of effective treatment plans that lead to improved patient outcomes. In the past few years, deep learning models have provided a feasible solution for assessing medical images, electronic health records, and genomic data to estimate cancer risk scores. However, these models often fall short of their potential because they struggle to learn regression-aware feature representations. In this study, we propose Survival Rank-N Contrast (SurvRNC) method, which introduces a loss function as a regularizer to obtain an ordered representation based on the survival times. This function can handle censored data and can be incorporated into any survival model to ensure that the learned representation is ordinal. The model was extensively evaluated on a HEad \& NeCK TumOR (HECKTOR) segmentation and the outcome-prediction task dataset. We demonstrate that using the SurvRNC method for training can achieve higher performance on different deep survival models. Additionally, it outperforms state-of-the-art methods by 3.6% on the concordance index. The code is publicly available on https://github.com/numanai/SurvRNC
S3LLM: Large-Scale Scientific Software Understanding with LLMs using Source, Metadata, and Document
Mar 15, 2024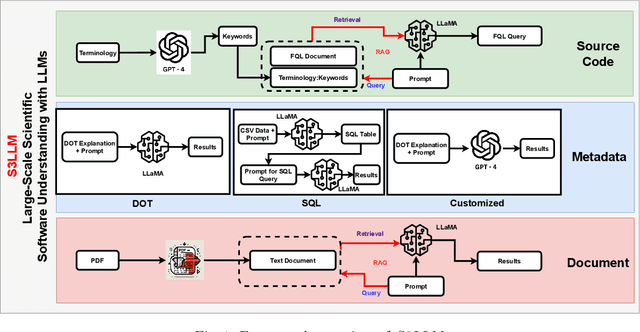

The understanding of large-scale scientific software poses significant challenges due to its diverse codebase, extensive code length, and target computing architectures. The emergence of generative AI, specifically large language models (LLMs), provides novel pathways for understanding such complex scientific codes. This paper presents S3LLM, an LLM-based framework designed to enable the examination of source code, code metadata, and summarized information in conjunction with textual technical reports in an interactive, conversational manner through a user-friendly interface. S3LLM leverages open-source LLaMA-2 models to enhance code analysis through the automatic transformation of natural language queries into domain-specific language (DSL) queries. Specifically, it translates these queries into Feature Query Language (FQL), enabling efficient scanning and parsing of entire code repositories. In addition, S3LLM is equipped to handle diverse metadata types, including DOT, SQL, and customized formats. Furthermore, S3LLM incorporates retrieval augmented generation (RAG) and LangChain technologies to directly query extensive documents. S3LLM demonstrates the potential of using locally deployed open-source LLMs for the rapid understanding of large-scale scientific computing software, eliminating the need for extensive coding expertise, and thereby making the process more efficient and effective. S3LLM is available at https://github.com/ResponsibleAILab/s3llm.
FocusMAE: Gallbladder Cancer Detection from Ultrasound Videos with Focused Masked Autoencoders
Mar 13, 2024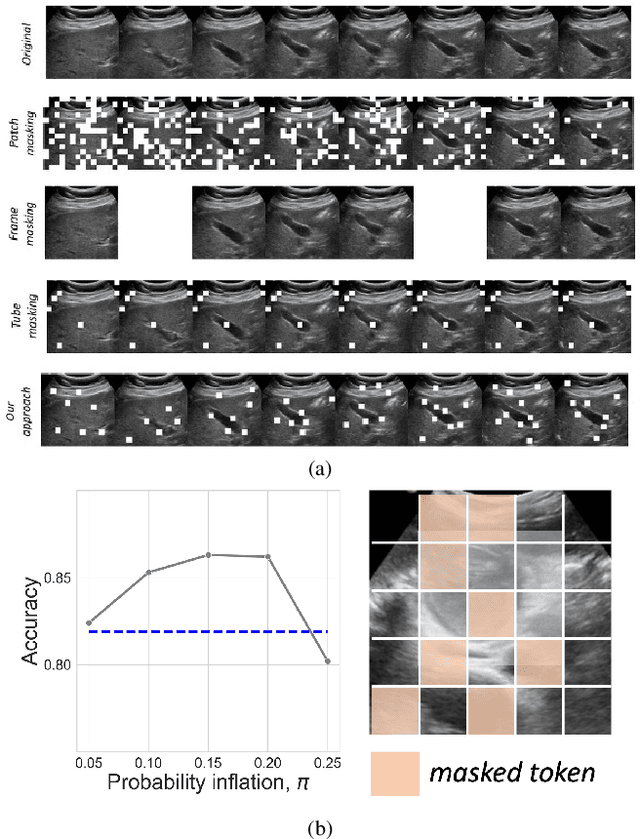
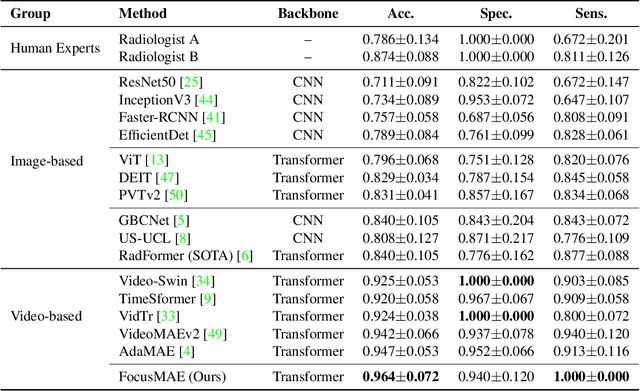
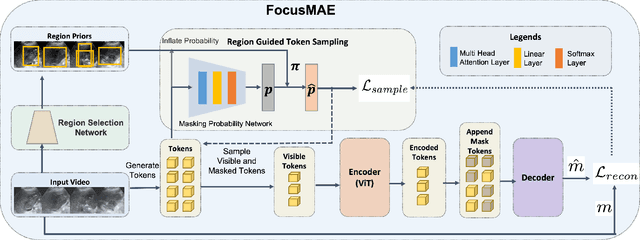
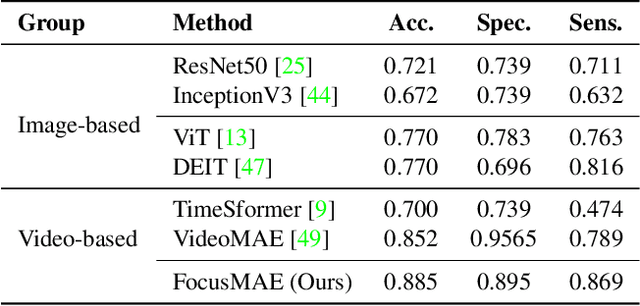
In recent years, automated Gallbladder Cancer (GBC) detection has gained the attention of researchers. Current state-of-the-art (SOTA) methodologies relying on ultrasound sonography (US) images exhibit limited generalization, emphasizing the need for transformative approaches. We observe that individual US frames may lack sufficient information to capture disease manifestation. This study advocates for a paradigm shift towards video-based GBC detection, leveraging the inherent advantages of spatiotemporal representations. Employing the Masked Autoencoder (MAE) for representation learning, we address shortcomings in conventional image-based methods. We propose a novel design called FocusMAE to systematically bias the selection of masking tokens from high-information regions, fostering a more refined representation of malignancy. Additionally, we contribute the most extensive US video dataset for GBC detection. We also note that, this is the first study on US video-based GBC detection. We validate the proposed methods on the curated dataset, and report a new state-of-the-art (SOTA) accuracy of 96.4% for the GBC detection problem, against an accuracy of 84% by current Image-based SOTA - GBCNet, and RadFormer, and 94.7% by Video-based SOTA - AdaMAE. We further demonstrate the generality of the proposed FocusMAE on a public CT-based Covid detection dataset, reporting an improvement in accuracy by 3.3% over current baselines. The source code and pretrained models are available at: https://github.com/sbasu276/FocusMAE.
Knowledge of Pretrained Language Models on Surface Information of Tokens
Feb 22, 2024Do pretrained language models have knowledge regarding the surface information of tokens? We examined the surface information stored in word or subword embeddings acquired by pretrained language models from the perspectives of token length, substrings, and token constitution. Additionally, we evaluated the ability of models to generate knowledge regarding token surfaces. We focused on 12 pretrained language models that were mainly trained on English and Japanese corpora. Experimental results demonstrate that pretrained language models have knowledge regarding token length and substrings but not token constitution. Additionally, the results imply that there is a bottleneck on the decoder side in terms of effectively utilizing acquired knowledge.