 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distributed Gesture Controlled Systems for Human-Machine Interface
Apr 12, 2023
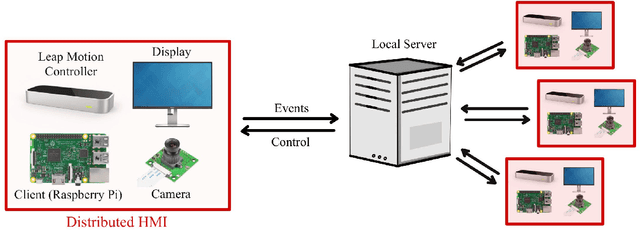
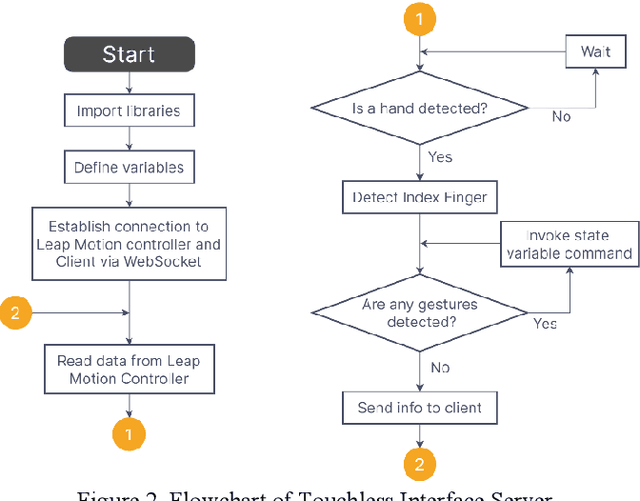
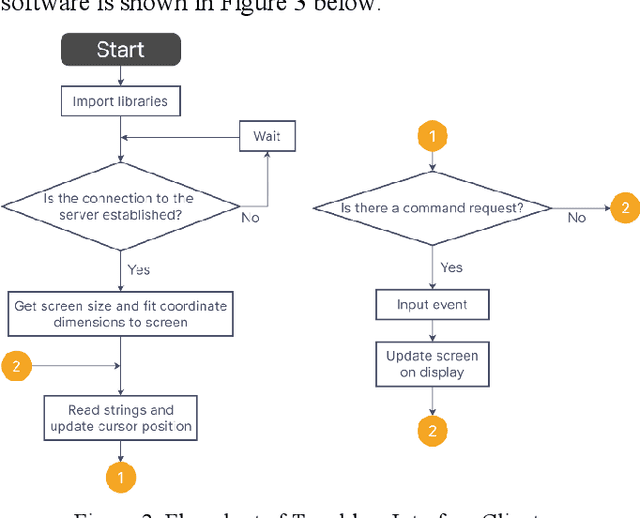
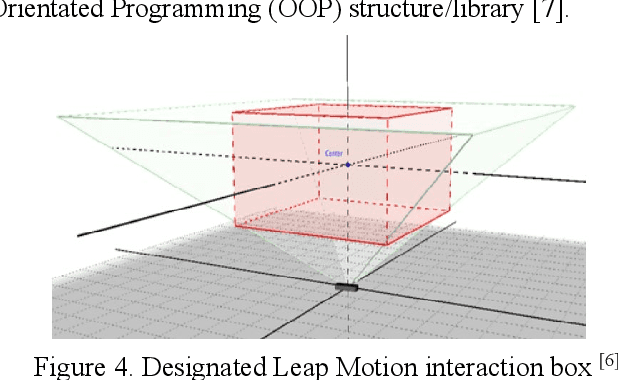
This paper presents the design flow of an IoT human machine touchless interface. The device uses embedded computing in conjunction with the Leap Motion Controller to provide an accurate and intuitive touchless interface. Its main function is to augment current touchscreen devices in public spaces through a combination of computer vision technology, event driven programming, and machine learning. Especially following the COVID 19 pandemic, this technology is important for hygiene and sanitation purposes for public devices such as airports, food, and ATM kiosks where hundreds or even thousands of people may touch these devices in a single day. A prototype of the touchless interface was designed with a Leap Motion Controller housed on a Windows PC exchanging information with a Raspberry Pi microcontroller via internet connection.
Secret-Keeping in Question Answering
Mar 16, 2023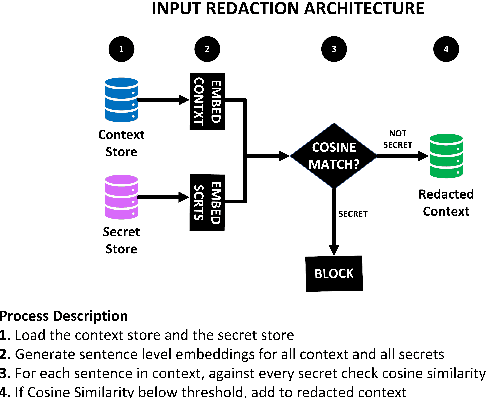
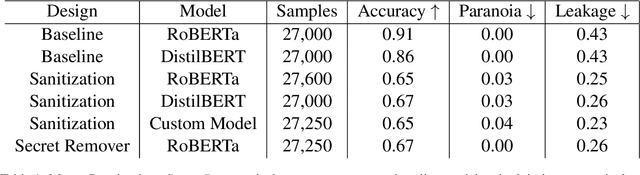
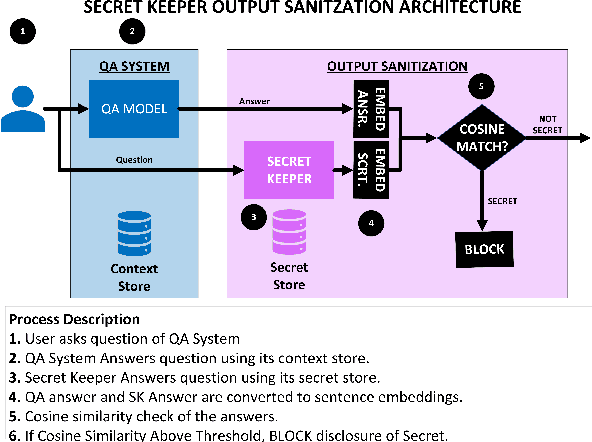
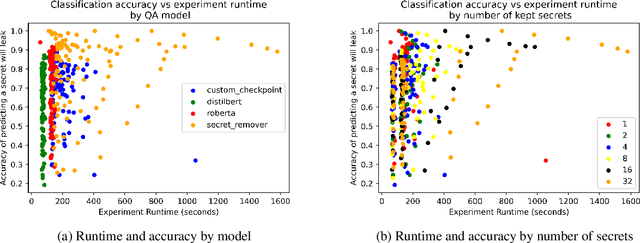
Existing question-answering research focuses on unanswerable questions in the context of always providing an answer when a system can\dots but what about cases where a system {\bf should not} answer a question. This can either be to protect sensitive users or sensitive information. Many models expose sensitive information under interrogation by an adversarial user. We seek to determine if it is possible to teach a question-answering system to keep a specific fact secret. We design and implement a proof-of-concept architecture and through our evaluation determine that while possible, there are numerous directions for future research to reduce system paranoia (false positives), information leakage (false negatives) and extend the implementation of the work to more complex problems with preserving secrecy in the presence of information aggregation.
An ontology-aided, natural language-based approach for multi-constraint BIM model querying
Mar 27, 2023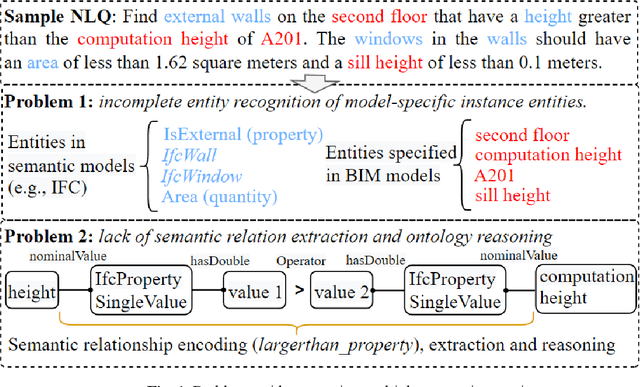
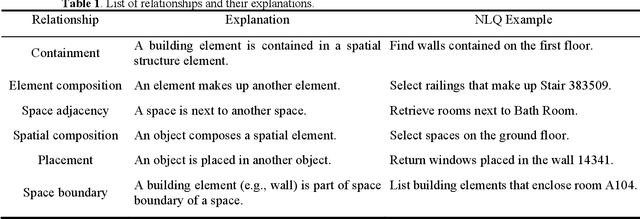
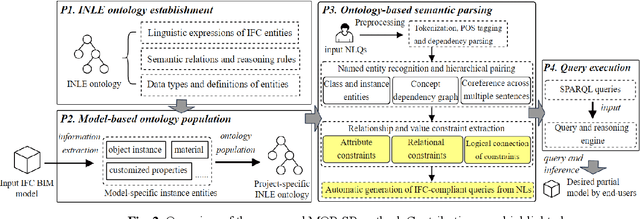
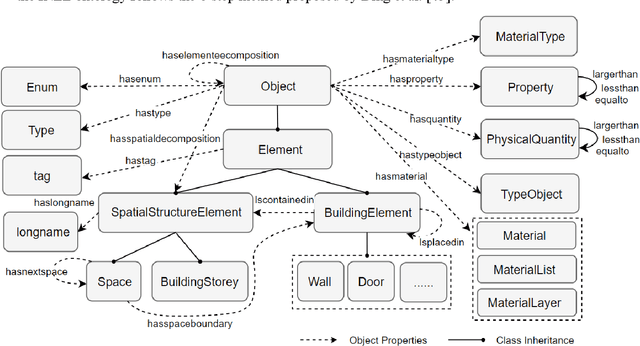
Being able to efficiently retrieve the required building information is critical for construction project stakeholders to carry out their engineering and management activities. Natural language interface (NLI) systems are emerging as a time and cost-effective way to query Building Information Models (BIMs). However, the existing methods cannot logically combine different constraints to perform fine-grained queries, dampening the usability of natural language (NL)-based BIM queries. This paper presents a novel ontology-aided semantic parser to automatically map natural language queries (NLQs) that contain different attribute and relational constraints into computer-readable codes for querying complex BIM models. First, a modular ontology was developed to represent NL expressions of Industry Foundation Classes (IFC) concepts and relationships, and was then populated with entities from target BIM models to assimilate project-specific information. Hereafter, the ontology-aided semantic parser progressively extracts concepts, relationships, and value restrictions from NLQs to fully identify constraint conditions, resulting in standard SPARQL queries with reasoning rules to successfully retrieve IFC-based BIM models. The approach was evaluated based on 225 NLQs collected from BIM users, with a 91% accuracy rate. Finally, a case study about the design-checking of a real-world residential building demonstrates the practical value of the proposed approach in the construction industry.
Unfolded Self-Reconstruction LSH: Towards Machine Unlearning in Approximate Nearest Neighbour Search
Apr 06, 2023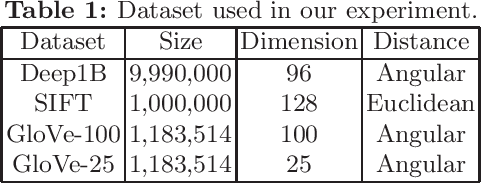
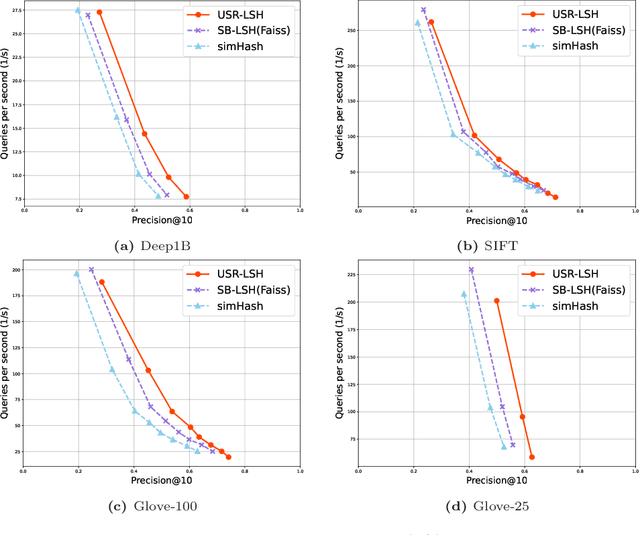
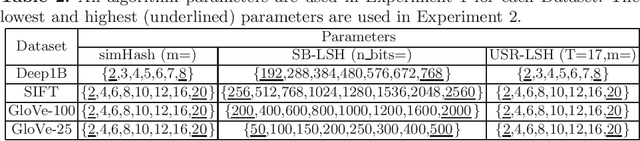
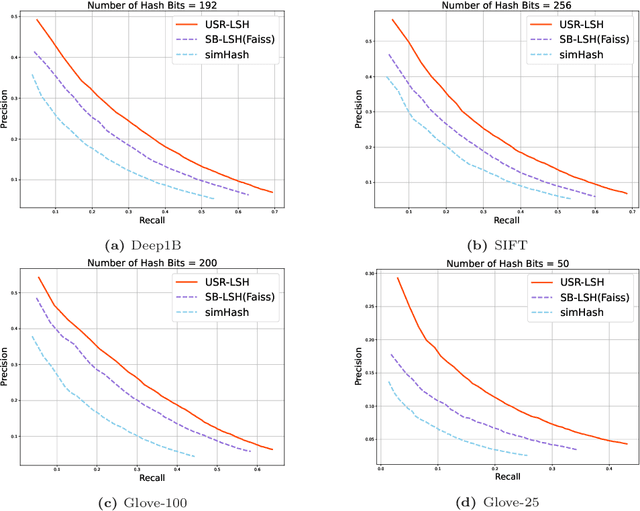
Approximate nearest neighbour (ANN) search is an essential component of search engines, recommendation systems, etc. Many recent works focus on learning-based data-distribution-dependent hashing and achieve good retrieval performance. However, due to increasing demand for users' privacy and security, we often need to remove users' data information from Machine Learning (ML) models to satisfy specific privacy and security requirements. This need requires the ANN search algorithm to support fast online data deletion and insertion. Current learning-based hashing methods need retraining the hash function, which is prohibitable due to the vast time-cost of large-scale data. To address this problem, we propose a novel data-dependent hashing method named unfolded self-reconstruction locality-sensitive hashing (USR-LSH). Our USR-LSH unfolded the optimization update for instance-wise data reconstruction, which is better for preserving data information than data-independent LSH. Moreover, our USR-LSH supports fast online data deletion and insertion without retraining. To the best of our knowledge, we are the first to address the machine unlearning of retrieval problems. Empirically, we demonstrate that USR-LSH outperforms the state-of-the-art data-distribution-independent LSH in ANN tasks in terms of precision and recall. We also show that USR-LSH has significantly faster data deletion and insertion time than learning-based data-dependent hashing.
$R^{2}$Former: Unified $R$etrieval and $R$eranking Transformer for Place Recognition
Apr 06, 2023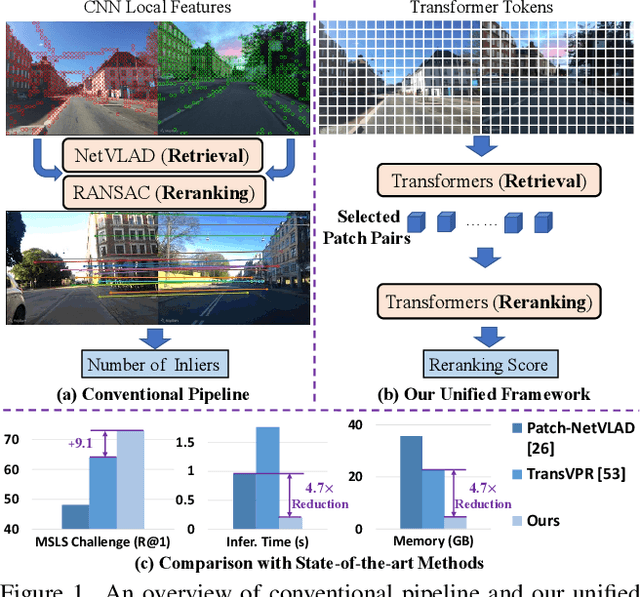
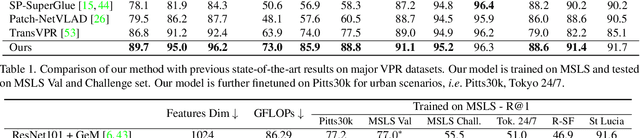
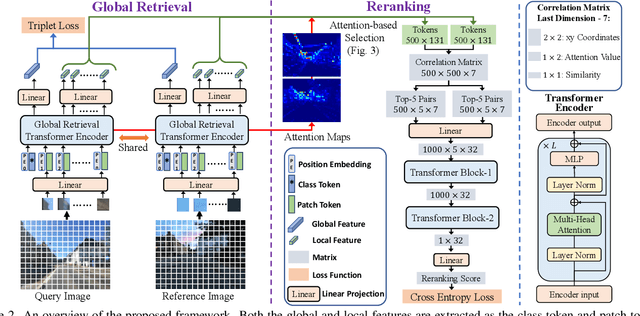

Visual Place Recognition (VPR) estimates the location of query images by matching them with images in a reference database. Conventional methods generally adopt aggregated CNN features for global retrieval and RANSAC-based geometric verification for reranking. However, RANSAC only employs geometric information but ignores other possible information that could be useful for reranking, e.g. local feature correlations, and attention values. In this paper, we propose a unified place recognition framework that handles both retrieval and reranking with a novel transformer model, named $R^{2}$Former. The proposed reranking module takes feature correlation, attention value, and xy coordinates into account, and learns to determine whether the image pair is from the same location. The whole pipeline is end-to-end trainable and the reranking module alone can also be adopted on other CNN or transformer backbones as a generic component. Remarkably, $R^{2}$Former significantly outperforms state-of-the-art methods on major VPR datasets with much less inference time and memory consumption. It also achieves the state-of-the-art on the hold-out MSLS challenge set and could serve as a simple yet strong solution for real-world large-scale applications. Experiments also show vision transformer tokens are comparable and sometimes better than CNN local features on local matching. The code is released at https://github.com/Jeff-Zilence/R2Former.
SARF: Aliasing Relation Assisted Self-Supervised Learning for Few-shot Relation Reasoning
Apr 20, 2023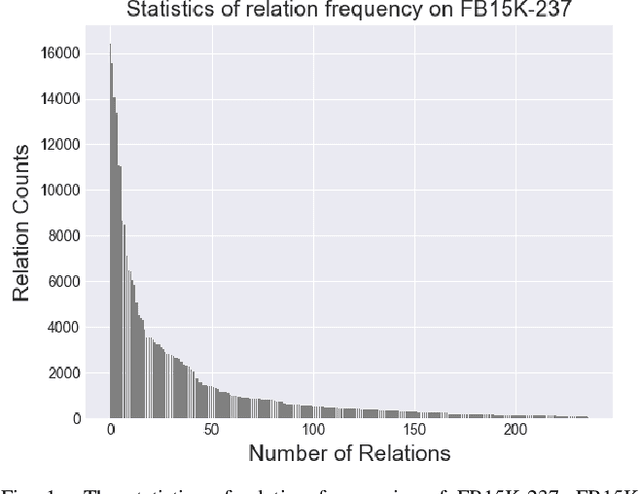
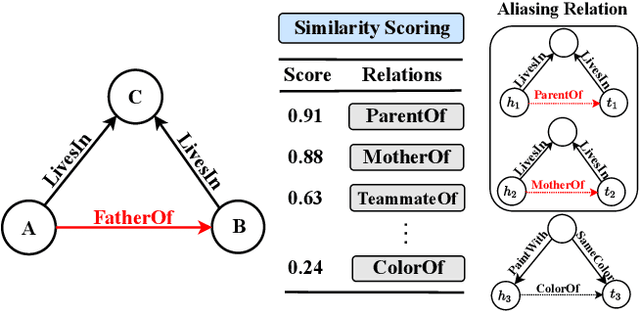
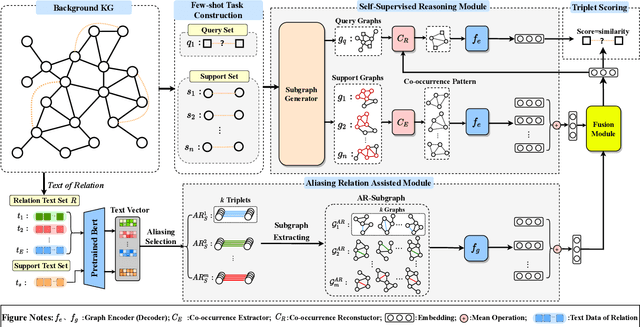
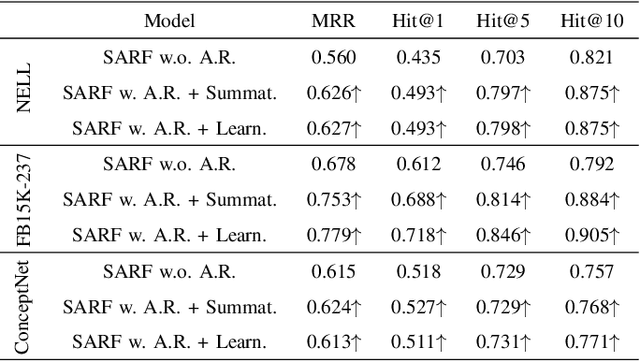
Few-shot relation reasoning on knowledge graphs (FS-KGR) aims to infer long-tail data-poor relations, which has drawn increasing attention these years due to its practicalities. The pre-training of previous methods needs to manually construct the meta-relation set, leading to numerous labor costs. Self-supervised learning (SSL) is treated as a solution to tackle the issue, but still at an early stage for FS-KGR task. Moreover, most of the existing methods ignore leveraging the beneficial information from aliasing relations (AR), i.e., data-rich relations with similar contextual semantics to the target data-poor relation. Therefore, we proposed a novel Self-Supervised Learning model by leveraging Aliasing Relations to assist FS-KGR, termed SARF. Concretely, four main components are designed in our model, i.e., SSL reasoning module, AR-assisted mechanism, fusion module, and scoring function. We first generate the representation of the co-occurrence patterns in a generative manner. Meanwhile, the representations of aliasing relations are learned to enhance reasoning in the AR-assist mechanism. Besides, multiple strategies, i.e., simple summation and learnable fusion, are offered for representation fusion. Finally, the generated representation is used for scoring. Extensive experiments on three few-shot benchmarks demonstrate that SARF achieves state-of-the-art performance compared with other methods in most cases.
Get Rid Of Your Trail: Remotely Erasing Backdoors in Federated Learning
Apr 20, 2023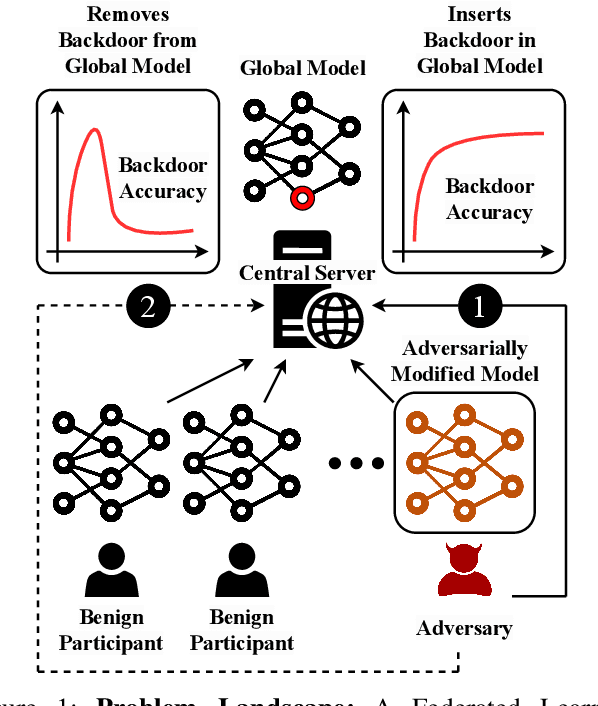
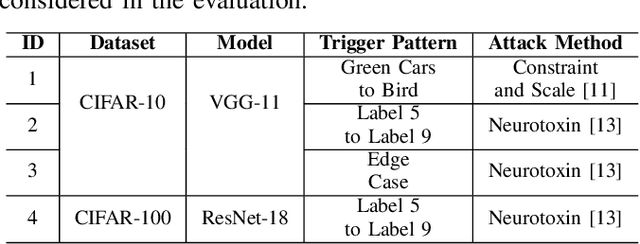
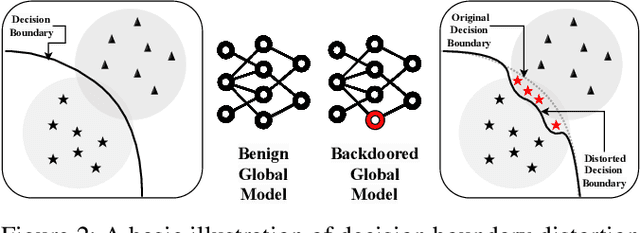
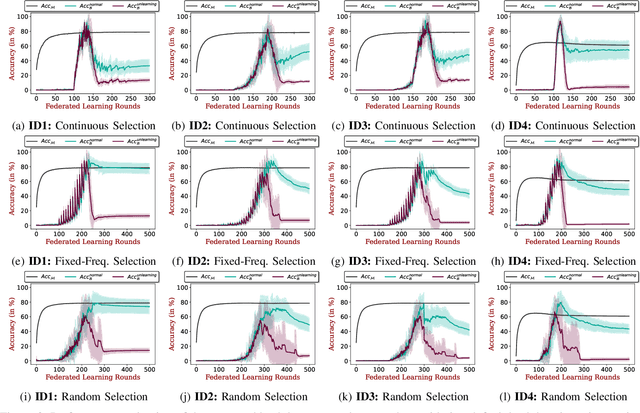
Federated Learning (FL) enables collaborative deep learning training across multiple participants without exposing sensitive personal data. However, the distributed nature of FL and the unvetted participants' data makes it vulnerable to backdoor attacks. In these attacks, adversaries inject malicious functionality into the centralized model during training, leading to intentional misclassifications for specific adversary-chosen inputs. While previous research has demonstrated successful injections of persistent backdoors in FL, the persistence also poses a challenge, as their existence in the centralized model can prompt the central aggregation server to take preventive measures to penalize the adversaries. Therefore, this paper proposes a methodology that enables adversaries to effectively remove backdoors from the centralized model upon achieving their objectives or upon suspicion of possible detection. The proposed approach extends the concept of machine unlearning and presents strategies to preserve the performance of the centralized model and simultaneously prevent over-unlearning of information unrelated to backdoor patterns, making the adversaries stealthy while removing backdoors. To the best of our knowledge, this is the first work that explores machine unlearning in FL to remove backdoors to the benefit of adversaries. Exhaustive evaluation considering image classification scenarios demonstrates the efficacy of the proposed method in efficient backdoor removal from the centralized model, injected by state-of-the-art attacks across multiple configurations.
Jedi: Entropy-based Localization and Removal of Adversarial Patches
Apr 20, 2023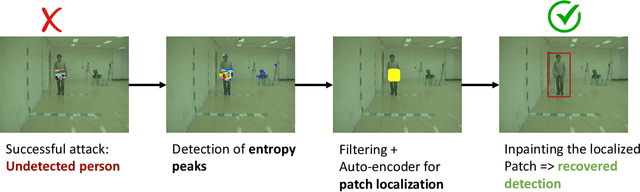
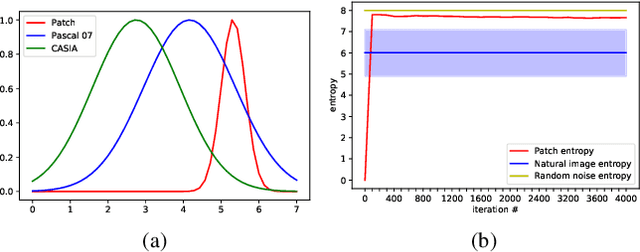
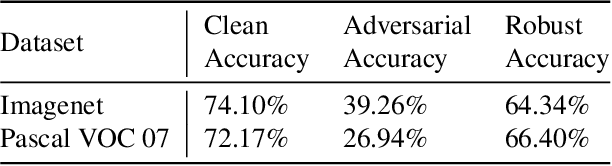
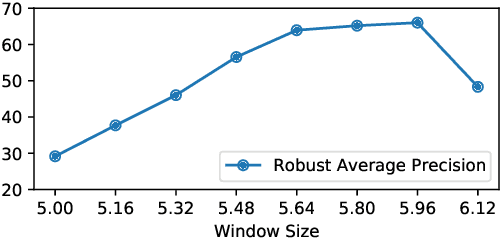
Real-world adversarial physical patches were shown to be successful in compromising state-of-the-art models in a variety of computer vision applications. Existing defenses that are based on either input gradient or features analysis have been compromised by recent GAN-based attacks that generate naturalistic patches. In this paper, we propose Jedi, a new defense against adversarial patches that is resilient to realistic patch attacks. Jedi tackles the patch localization problem from an information theory perspective; leverages two new ideas: (1) it improves the identification of potential patch regions using entropy analysis: we show that the entropy of adversarial patches is high, even in naturalistic patches; and (2) it improves the localization of adversarial patches, using an autoencoder that is able to complete patch regions from high entropy kernels. Jedi achieves high-precision adversarial patch localization, which we show is critical to successfully repair the images. Since Jedi relies on an input entropy analysis, it is model-agnostic, and can be applied on pre-trained off-the-shelf models without changes to the training or inference of the protected models. Jedi detects on average 90% of adversarial patches across different benchmarks and recovers up to 94% of successful patch attacks (Compared to 75% and 65% for LGS and Jujutsu, respectively).
The Future of ChatGPT-enabled Labor Market: A Preliminary Study
Apr 20, 2023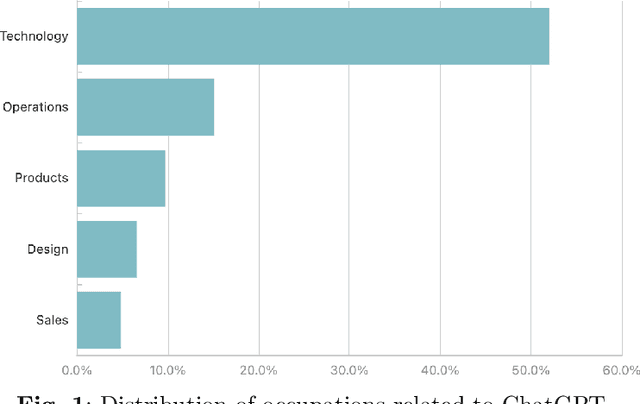

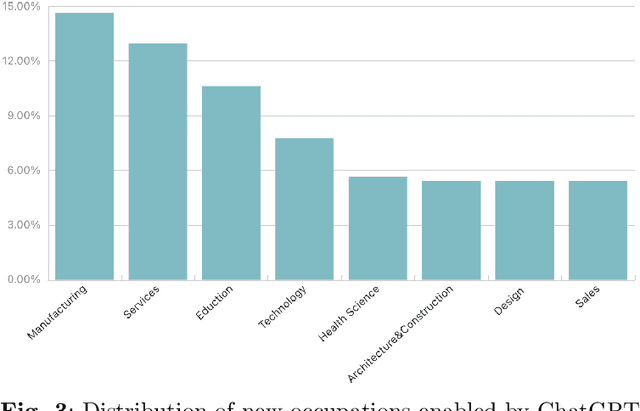
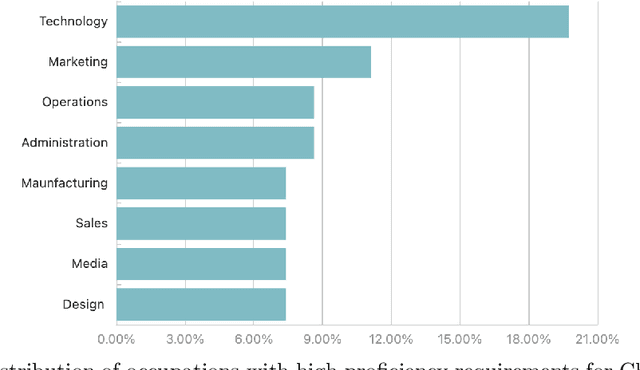
As a phenomenal large language model, ChatGPT has achieved unparalleled success in various real-world tasks and increasingly plays an important role in our daily lives and work. However, extensive concerns are also raised about the potential ethical issues, especially about whether ChatGPT-like artificial general intelligence (AGI) will replace human jobs. To this end, in this paper, we introduce a preliminary data-driven study on the future of ChatGPT-enabled labor market from the view of Human-AI Symbiosis instead of Human-AI Confrontation. To be specific, we first conduct an in-depth analysis of large-scale job posting data in BOSS Zhipin, the largest online recruitment platform in China. The results indicate that about 28% of occupations in the current labor market require ChatGPT-related skills. Furthermore, based on a large-scale occupation-centered knowledge graph, we develop a semantic information enhanced collaborative filtering algorithm to predict the future occupation-skill relations in the labor market. As a result, we find that additional 45% occupations in the future will require ChatGPT-related skills. In particular, industries related to technology, products, and operations are expected to have higher proficiency requirements for ChatGPT-related skills, while the manufacturing, services, education, and health science related industries will have lower requirements for ChatGPT-related skills.
LA3: Efficient Label-Aware AutoAugment
Apr 20, 2023Automated augmentation is an emerging and effective technique to search for data augmentation policies to improve generalizability of deep neural network training. Most existing work focuses on constructing a unified policy applicable to all data samples in a given dataset, without considering sample or class variations. In this paper, we propose a novel two-stage data augmentation algorithm, named Label-Aware AutoAugment (LA3), which takes advantage of the label information, and learns augmentation policies separately for samples of different labels. LA3 consists of two learning stages, where in the first stage, individual augmentation methods are evaluated and ranked for each label via Bayesian Optimization aided by a neural predictor, which allows us to identify effective augmentation techniques for each label under a low search cost. And in the second stage, a composite augmentation policy is constructed out of a selection of effective as well as complementary augmentations, which produces significant performance boost and can be easily deployed in typical model training. Extensive experiments demonstrate that LA3 achieves excellent performance matching or surpassing existing methods on CIFAR-10 and CIFAR-100, and achieves a new state-of-the-art ImageNet accuracy of 79.97% on ResNet-50 among auto-augmentation methods, while maintaining a low computational cost.