 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
GeneGPT: Teaching Large Language Models to Use NCBI Web APIs
Apr 19, 2023

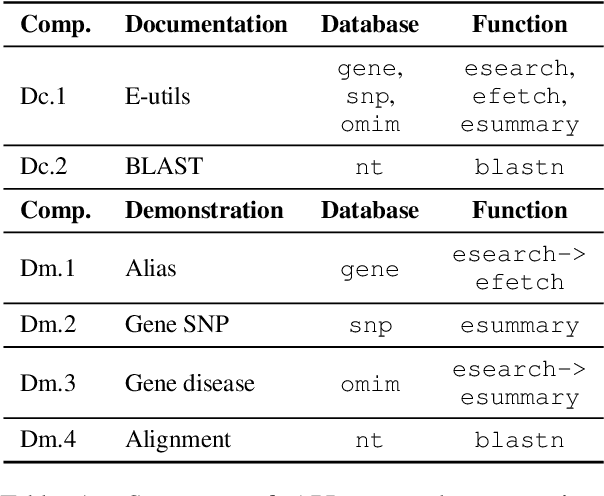
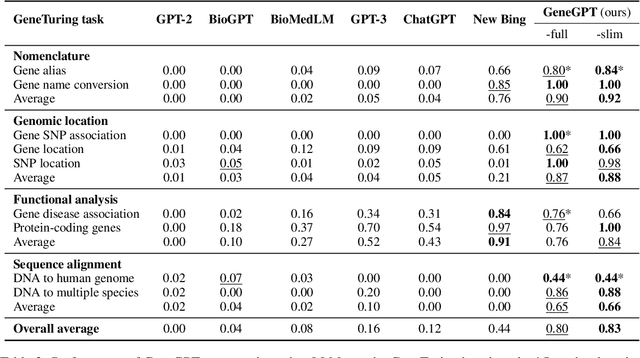

In this paper, we present GeneGPT, a novel method for teaching large language models (LLMs) to use the Web Application Programming Interfaces (APIs) of the National Center for Biotechnology Information (NCBI) and answer genomics questions. Specifically, we prompt Codex (code-davinci-002) to solve the GeneTuring tests with few-shot URL requests of NCBI API calls as demonstrations for in-context learning. During inference, we stop the decoding once a call request is detected and make the API call with the generated URL. We then append the raw execution results returned by NCBI APIs to the generated texts and continue the generation until the answer is found or another API call is detected. Our preliminary results show that GeneGPT achieves state-of-the-art results on three out of four one-shot tasks and four out of five zero-shot tasks in the GeneTuring dataset. Overall, GeneGPT achieves a macro-average score of 0.76, which is much higher than retrieval-augmented LLMs such as the New Bing (0.44), biomedical LLMs such as BioMedLM (0.08) and BioGPT (0.04), as well as other LLMs such as GPT-3 (0.16) and ChatGPT (0.12).
ASM: Adaptive Skinning Model for High-Quality 3D Face Modeling
Apr 19, 2023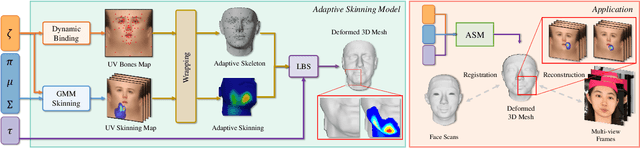
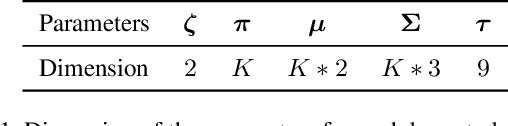
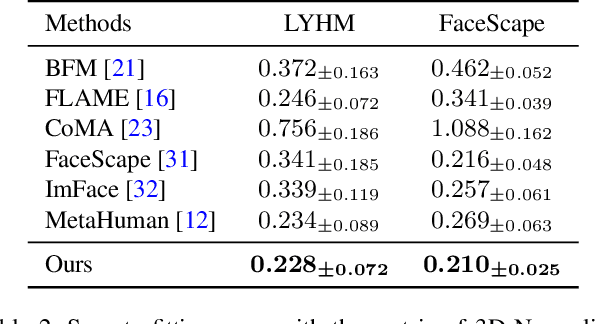
The research fields of parametric face models and 3D face reconstruction have been extensively studied. However, a critical question remains unanswered: how to tailor the face model for specific reconstruction settings. We argue that reconstruction with multi-view uncalibrated images demands a new model with stronger capacity. Our study shifts attention from data-dependent 3D Morphable Models (3DMM) to an understudied human-designed skinning model. We propose Adaptive Skinning Model (ASM), which redefines the skinning model with more compact and fully tunable parameters. With extensive experiments, we demonstrate that ASM achieves significantly improved capacity than 3DMM, with the additional advantage of model size and easy implementation for new topology. We achieve state-of-the-art performance with ASM for multi-view reconstruction on the Florence MICC Coop benchmark. Our quantitative analysis demonstrates the importance of a high-capacity model for fully exploiting abundant information from multi-view input in reconstruction. Furthermore, our model with physical-semantic parameters can be directly utilized for real-world applications, such as in-game avatar creation. As a result, our work opens up new research directions for the parametric face models and facilitates future research on multi-view reconstruction.
Evaluating Verifiability in Generative Search Engines
Apr 19, 2023


Generative search engines directly generate responses to user queries, along with in-line citations. A prerequisite trait of a trustworthy generative search engine is verifiability, i.e., systems should cite comprehensively (high citation recall; all statements are fully supported by citations) and accurately (high citation precision; every cite supports its associated statement). We conduct human evaluation to audit four popular generative search engines -- Bing Chat, NeevaAI, perplexity.ai, and YouChat -- across a diverse set of queries from a variety of sources (e.g., historical Google user queries, dynamically-collected open-ended questions on Reddit, etc.). We find that responses from existing generative search engines are fluent and appear informative, but frequently contain unsupported statements and inaccurate citations: on average, a mere 51.5% of generated sentences are fully supported by citations and only 74.5% of citations support their associated sentence. We believe that these results are concerningly low for systems that may serve as a primary tool for information-seeking users, especially given their facade of trustworthiness. We hope that our results further motivate the development of trustworthy generative search engines and help researchers and users better understand the shortcomings of existing commercial systems.
Introducing Construct Theory as a Standard Methodology for Inclusive AI Models
Apr 19, 2023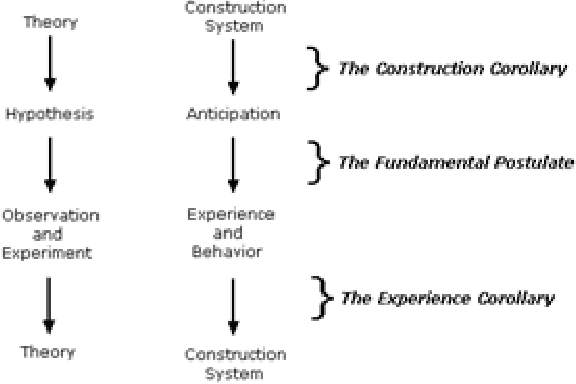

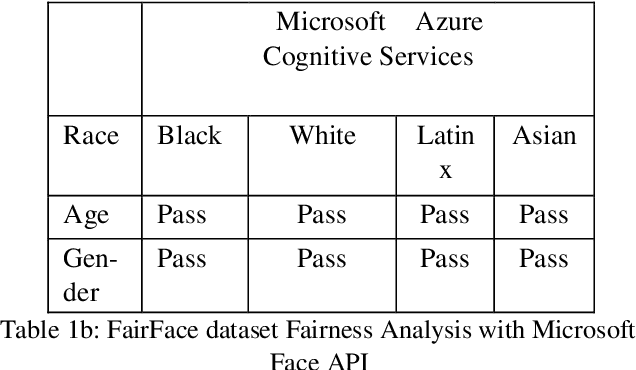
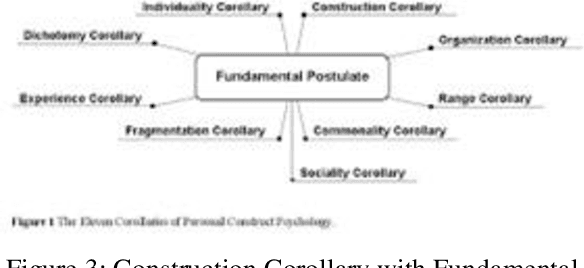
Construct theory in social psychology, developed by George Kelly are mental constructs to predict and anticipate events. Constructs are how humans interpret, curate, predict and validate data; information. AI today is biased because it is trained with a narrow construct as defined by the training data labels. Machine Learning algorithms for facial recognition discriminate against darker skin colors and in the ground breaking research papers (Buolamwini, Joy and Timnit Gebru. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. FAT (2018), the inclusion of phenotypic labeling is proposed as a viable solution. In Construct theory, phenotype is just one of the many subelements that make up the construct of a face. In this paper, we present 15 main elements of the construct of face, with 50 subelements and tested Google Cloud Vision API and Microsoft Cognitive Services API using FairFace dataset that currently has data for 7 races, genders and ages, and we retested against FairFace Plus dataset curated by us. Our results show exactly where they have gaps for inclusivity. Based on our experiment results, we propose that validated, inclusive constructs become industry standards for AI ML models going forward.
An Offline Metric for the Debiasedness of Click Models
Apr 19, 2023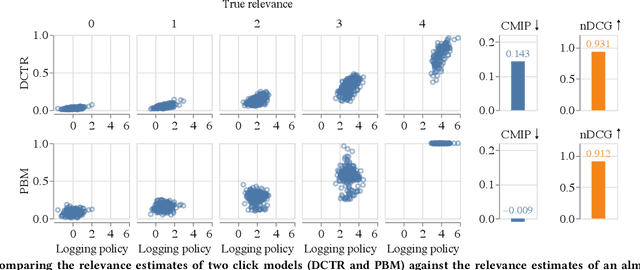
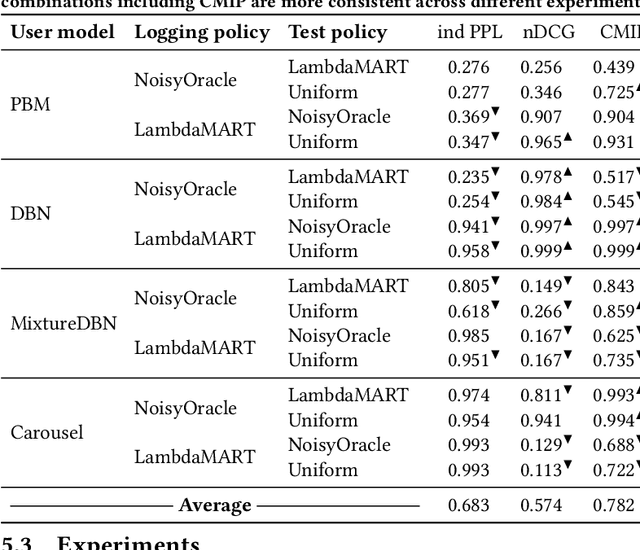
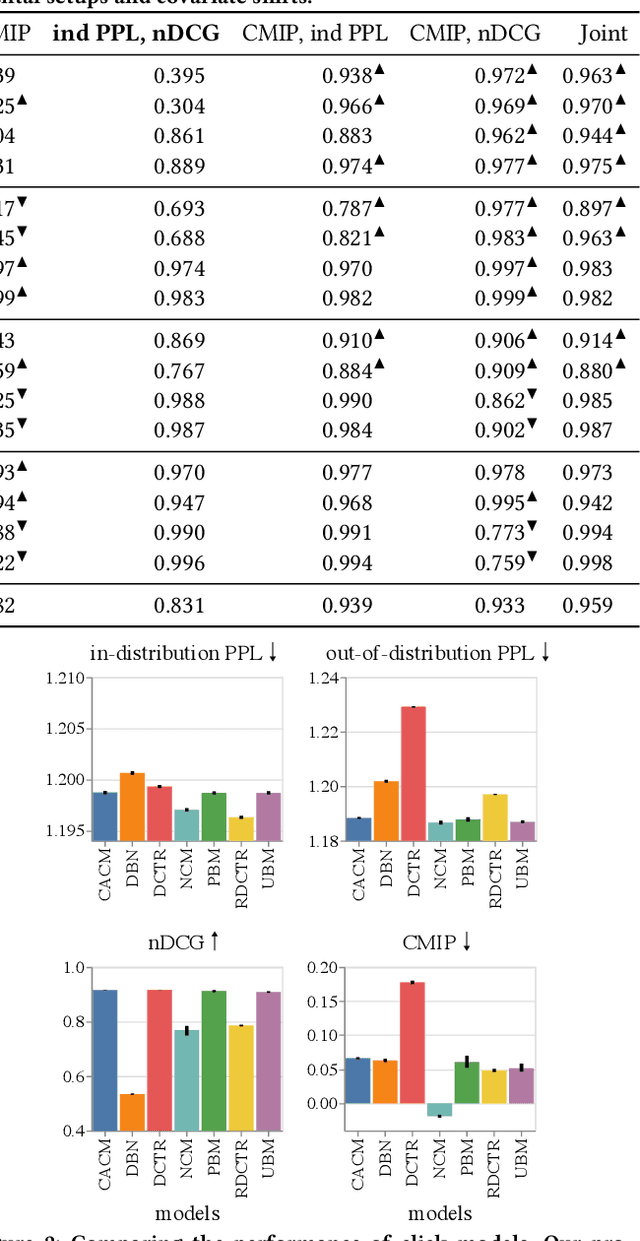
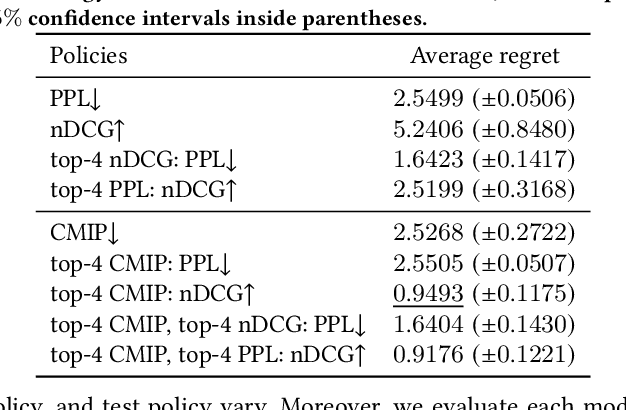
A well-known problem when learning from user clicks are inherent biases prevalent in the data, such as position or trust bias. Click models are a common method for extracting information from user clicks, such as document relevance in web search, or to estimate click biases for downstream applications such as counterfactual learning-to-rank, ad placement, or fair ranking. Recent work shows that the current evaluation practices in the community fail to guarantee that a well-performing click model generalizes well to downstream tasks in which the ranking distribution differs from the training distribution, i.e., under covariate shift. In this work, we propose an evaluation metric based on conditional independence testing to detect a lack of robustness to covariate shift in click models. We introduce the concept of debiasedness and a metric for measuring it. We prove that debiasedness is a necessary condition for recovering unbiased and consistent relevance scores and for the invariance of click prediction under covariate shift. In extensive semi-synthetic experiments, we show that our proposed metric helps to predict the downstream performance of click models under covariate shift and is useful in an off-policy model selection setting.
MvCo-DoT:Multi-View Contrastive Domain Transfer Network for Medical Report Generation
Apr 15, 2023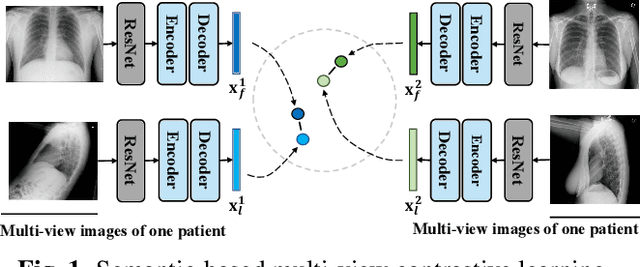
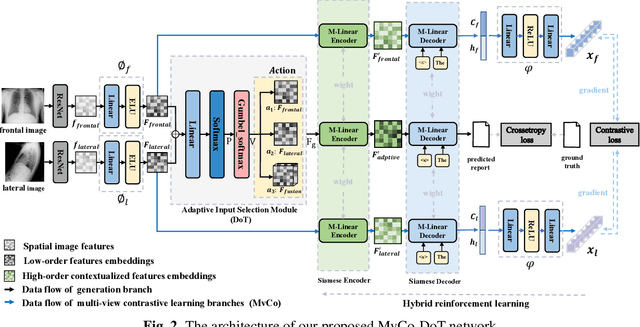
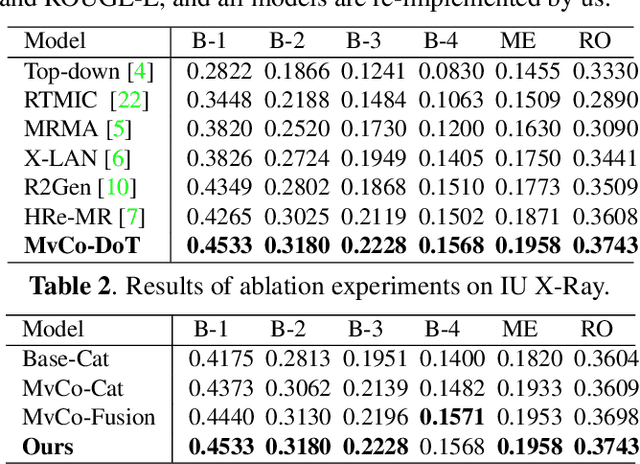

In clinical scenarios, multiple medical images with different views are usually generated at the same time, and they have high semantic consistency. However, the existing medical report generation methods cannot exploit the rich multi-view mutual information of medical images. Therefore, in this work, we propose the first multi-view medical report generation model, called MvCo-DoT. Specifically, MvCo-DoT first propose a multi-view contrastive learning (MvCo) strategy to help the deep reinforcement learning based model utilize the consistency of multi-view inputs for better model learning. Then, to close the performance gaps of using multi-view and single-view inputs, a domain transfer network is further proposed to ensure MvCo-DoT achieve almost the same performance as multi-view inputs using only single-view inputs.Extensive experiments on the IU X-Ray public dataset show that MvCo-DoT outperforms the SOTA medical report generation baselines in all metrics.
Conflict-Averse Gradient Optimization of Ensembles for Effective Offline Model-Based Optimization
Mar 31, 2023Data-driven offline model-based optimization (MBO) is an established practical approach to black-box computational design problems for which the true objective function is unknown and expensive to query. However, the standard approach which optimizes designs against a learned proxy model of the ground truth objective can suffer from distributional shift. Specifically, in high-dimensional design spaces where valid designs lie on a narrow manifold, the standard approach is susceptible to producing out-of-distribution, invalid designs that "fool" the learned proxy model into outputting a high value. Using an ensemble rather than a single model as the learned proxy can help mitigate distribution shift, but naive formulations for combining gradient information from the ensemble, such as minimum or mean gradient, are still suboptimal and often hampered by non-convergent behavior. In this work, we explore alternate approaches for combining gradient information from the ensemble that are robust to distribution shift without compromising optimality of the produced designs. More specifically, we explore two functions, formulated as convex optimization problems, for combining gradient information: multiple gradient descent algorithm (MGDA) and conflict-averse gradient descent (CAGrad). We evaluate these algorithms on a diverse set of five computational design tasks. We compare performance of ensemble MBO with MGDA and ensemble MBO with CAGrad with three naive baseline algorithms: (a) standard single-model MBO, (b) ensemble MBO with mean gradient, and (c) ensemble MBO with minimum gradient. Our results suggest that MGDA and CAGrad strike a desirable balance between conservatism and optimality and can help robustify data-driven offline MBO without compromising optimality of designs.
Minimizing the Age of Information Over an Erasure Channel for Random Packet Arrivals With a Storage Option at the Transmitter
Jan 10, 2023
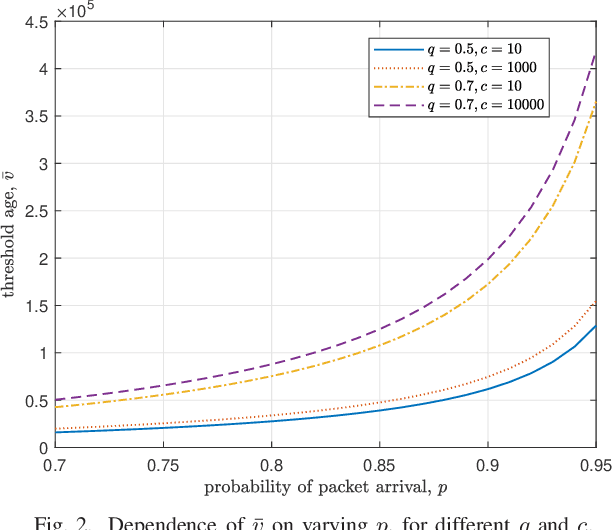
We consider a time slotted communication system consisting of a base station (BS) and a user. At each time slot an update packet arrives at the BS with probability $p$, and the BS successfully transmits the update packet with probability $q$ over an erasure channel. We assume that the BS has a unit size buffer where it can store an update packet upon paying a storage cost $c$. There is a trade-off between the age of information and the storage cost. We formulate this trade-off as a Markov decision process and find an optimal switching type storage policy.
Transfer Learning for Low-Resource Sentiment Analysis
Apr 10, 2023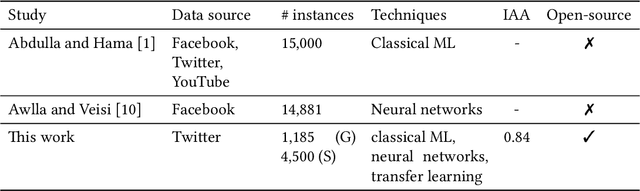

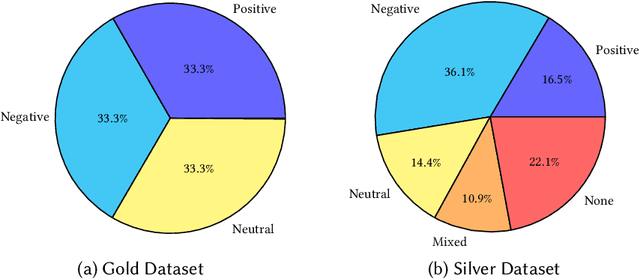
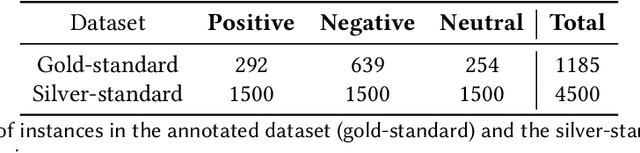
Sentiment analysis is the process of identifying and extracting subjective information from text. Despite the advances to employ cross-lingual approaches in an automatic way, the implementation and evaluation of sentiment analysis systems require language-specific data to consider various sociocultural and linguistic peculiarities. In this paper, the collection and annotation of a dataset are described for sentiment analysis of Central Kurdish. We explore a few classical machine learning and neural network-based techniques for this task. Additionally, we employ an approach in transfer learning to leverage pretrained models for data augmentation. We demonstrate that data augmentation achieves a high F$_1$ score and accuracy despite the difficulty of the task.
DNeRV: Modeling Inherent Dynamics via Difference Neural Representation for Videos
Apr 13, 2023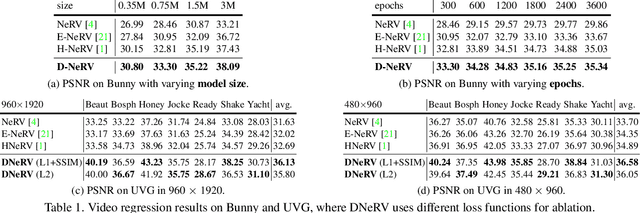

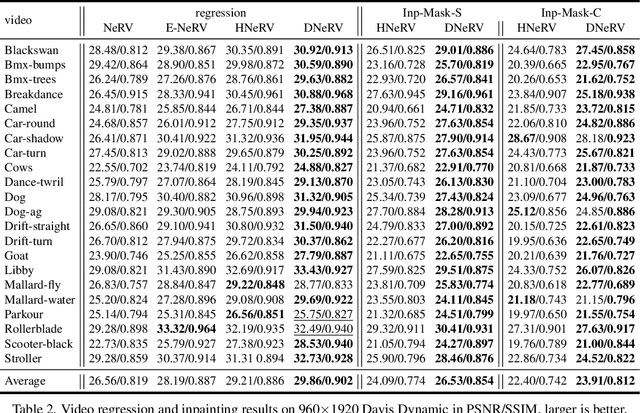
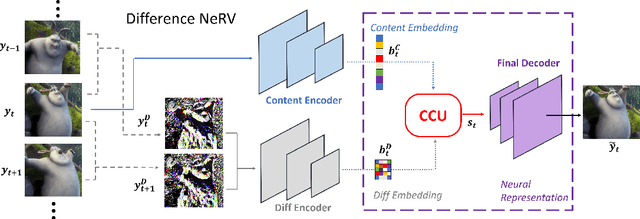
Existing implicit neural representation (INR) methods do not fully exploit spatiotemporal redundancies in videos. Index-based INRs ignore the content-specific spatial features and hybrid INRs ignore the contextual dependency on adjacent frames, leading to poor modeling capability for scenes with large motion or dynamics. We analyze this limitation from the perspective of function fitting and reveal the importance of frame difference. To use explicit motion information, we propose Difference Neural Representation for Videos (DNeRV), which consists of two streams for content and frame difference. We also introduce a collaborative content unit for effective feature fusion. We test DNeRV for video compression, inpainting, and interpolation. DNeRV achieves competitive results against the state-of-the-art neural compression approaches and outperforms existing implicit methods on downstream inpainting and interpolation for $960 \times 1920$ videos.