 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CSI-Based Data-driven Localization Frameworking using Small-scale Training Datasets in Single-site MIMO Systems
Apr 22, 2023
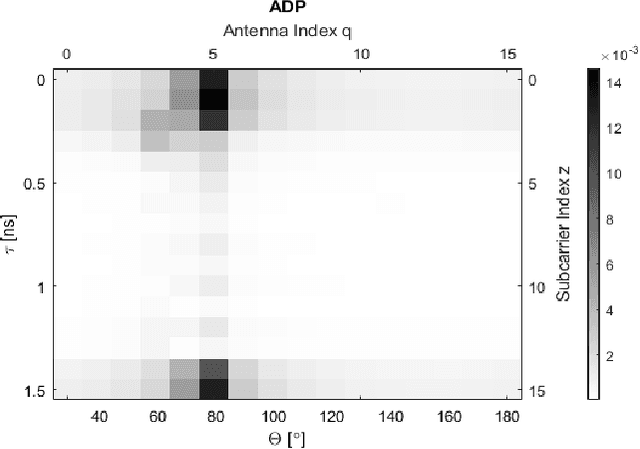
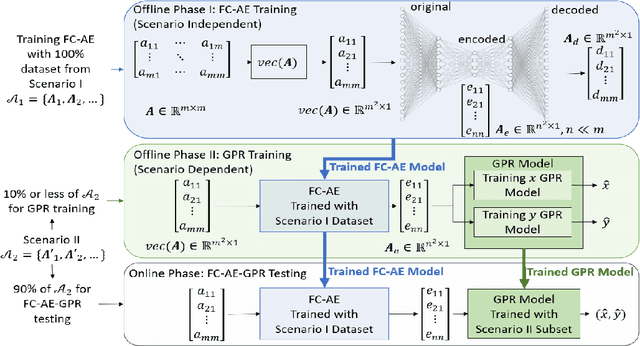
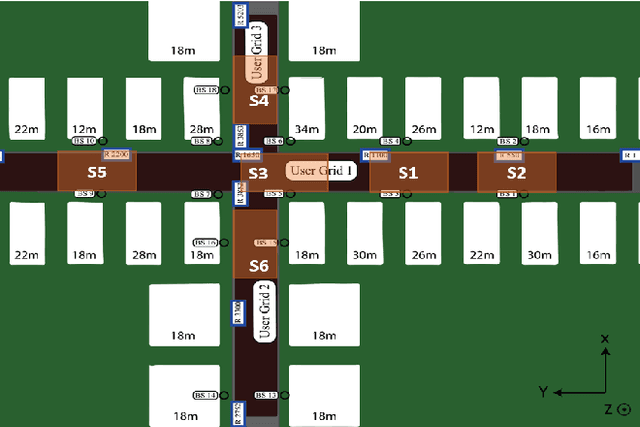
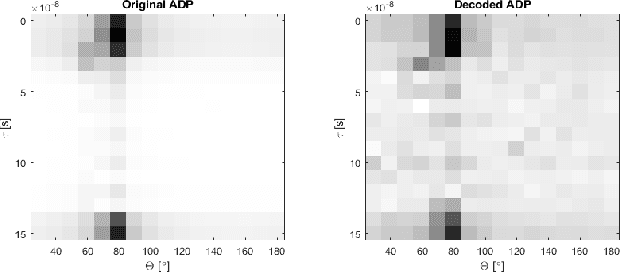
This work presents a date-driven user localization framework for single-site massive Multiple-Input-Multiple-Output (MIMO) systems. The framework is trained on a geo-tagged Channel State Information (CSI) dataset. Unlike the state-of-the-art Convolutional Neural Network (CNN) models, which require large training datasets to perform well, our method is specifically designed to operate with small-scale training datasets. This makes our approach more practical for real-world scenarios, where collecting a large amount of data can be challenging. Our proposed FC-AE-GPR framework combines two components: a Fully-Connected Auto-Encoder (FC-AE) and a Gaussian Process Regression (GPR) model. Our results show that the GPR model outperforms the CNN model when presented with small training datasets. However, the training complexity of GPR models can become an issue when the input sample size is large. To address this, we propose using the FC-AE to reduce the sample size by encoding the CSI before training the GPR model. Although the FC-AE model may require a larger training dataset initially, we demonstrate that the FC-AE is scenario independent. This means that it can be utilized in new and unseen scenarios without prior retraining. Therefore, adapting the FC-AE-GPR model to a new scenario requires only retraining the GPR model with a small training dataset.
AutoVRL: A High Fidelity Autonomous Ground Vehicle Simulator for Sim-to-Real Deep Reinforcement Learning
Apr 22, 2023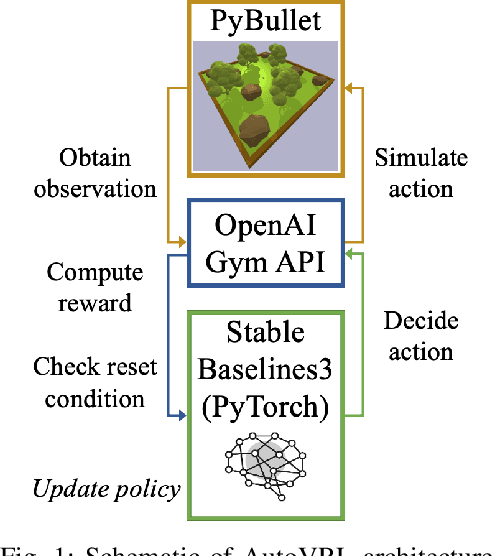
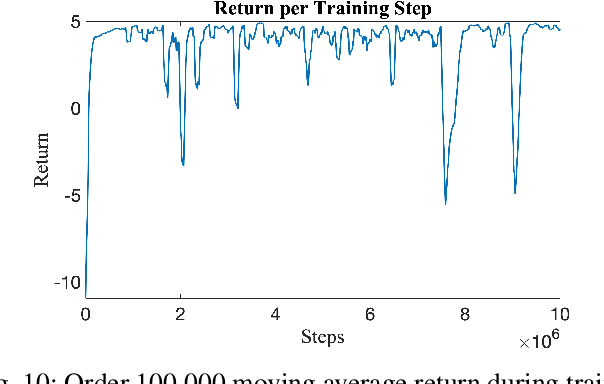
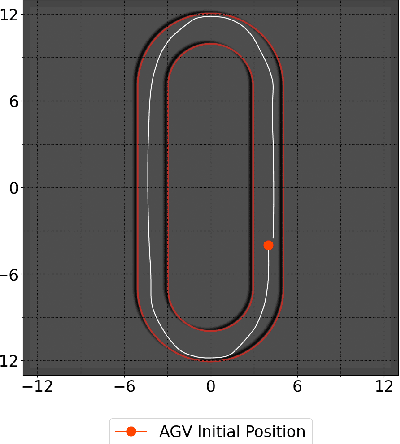

Deep Reinforcement Learning (DRL) enables cognitive Autonomous Ground Vehicle (AGV) navigation utilizing raw sensor data without a-priori maps or GPS, which is a necessity in hazardous, information poor environments such as regions where natural disasters occur, and extraterrestrial planets. The substantial training time required to learn an optimal DRL policy, which can be days or weeks for complex tasks, is a major hurdle to real-world implementation in AGV applications. Training entails repeated collisions with the surrounding environment over an extended time period, dependent on the complexity of the task, to reinforce positive exploratory, application specific behavior that is expensive, and time consuming in the real-world. Effectively bridging the simulation to real-world gap is a requisite for successful implementation of DRL in complex AGV applications, enabling learning of cost-effective policies. We present AutoVRL, an open-source high fidelity simulator built upon the Bullet physics engine utilizing OpenAI Gym and Stable Baselines3 in PyTorch to train AGV DRL agents for sim-to-real policy transfer. AutoVRL is equipped with sensor implementations of GPS, IMU, LiDAR and camera, actuators for AGV control, and realistic environments, with extensibility for new environments and AGV models. The simulator provides access to state-of-the-art DRL algorithms, utilizing a python interface for simple algorithm and environment customization, and simulation execution.
HS-Pose: Hybrid Scope Feature Extraction for Category-level Object Pose Estimation
Mar 28, 2023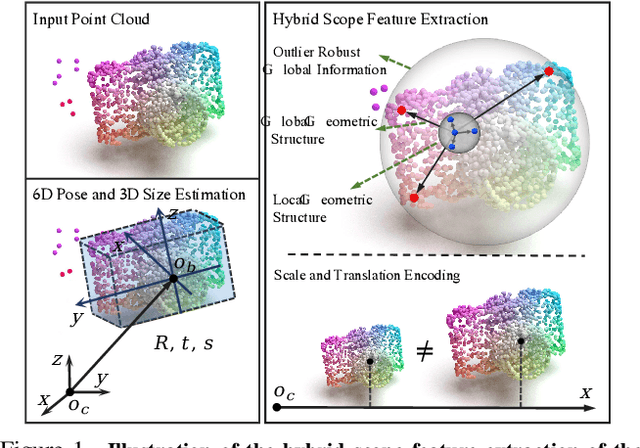
In this paper, we focus on the problem of category-level object pose estimation, which is challenging due to the large intra-category shape variation. 3D graph convolution (3D-GC) based methods have been widely used to extract local geometric features, but they have limitations for complex shaped objects and are sensitive to noise. Moreover, the scale and translation invariant properties of 3D-GC restrict the perception of an object's size and translation information. In this paper, we propose a simple network structure, the HS-layer, which extends 3D-GC to extract hybrid scope latent features from point cloud data for category-level object pose estimation tasks. The proposed HS-layer: 1) is able to perceive local-global geometric structure and global information, 2) is robust to noise, and 3) can encode size and translation information. Our experiments show that the simple replacement of the 3D-GC layer with the proposed HS-layer on the baseline method (GPV-Pose) achieves a significant improvement, with the performance increased by 14.5% on 5d2cm metric and 10.3% on IoU75. Our method outperforms the state-of-the-art methods by a large margin (8.3% on 5d2cm, 6.9% on IoU75) on the REAL275 dataset and runs in real-time (50 FPS).
A Lightweight Recurrent Learning Network for Sustainable Compressed Sensing
Apr 23, 2023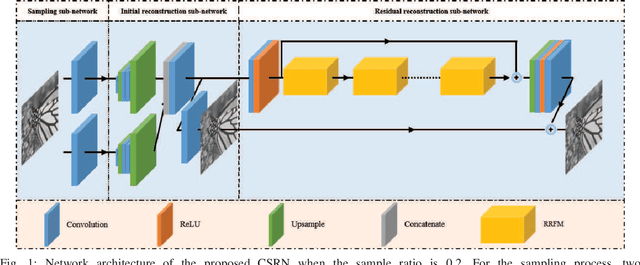
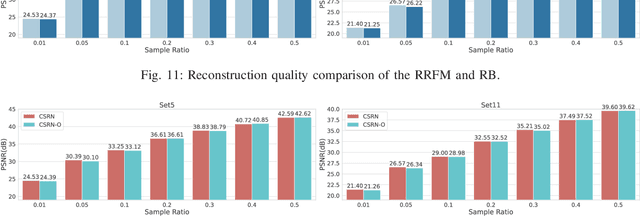
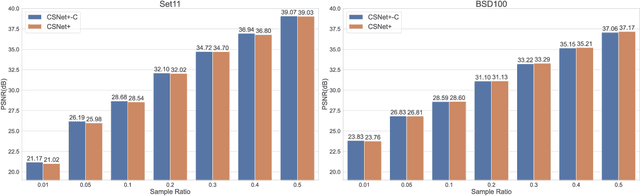
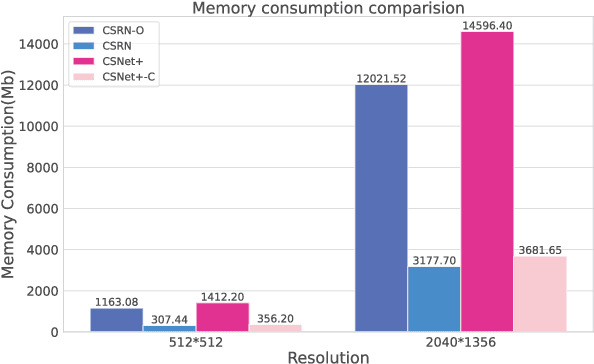
Recently, deep learning-based compressed sensing (CS) has achieved great success in reducing the sampling and computational cost of sensing systems and improving the reconstruction quality. These approaches, however, largely overlook the issue of the computational cost; they rely on complex structures and task-specific operator designs, resulting in extensive storage and high energy consumption in CS imaging systems. In this paper, we propose a lightweight but effective deep neural network based on recurrent learning to achieve a sustainable CS system; it requires a smaller number of parameters but obtains high-quality reconstructions. Specifically, our proposed network consists of an initial reconstruction sub-network and a residual reconstruction sub-network. While the initial reconstruction sub-network has a hierarchical structure to progressively recover the image, reducing the number of parameters, the residual reconstruction sub-network facilitates recurrent residual feature extraction via recurrent learning to perform both feature fusion and deep reconstructions across different scales. In addition, we also demonstrate that, after the initial reconstruction, feature maps with reduced sizes are sufficient to recover the residual information, and thus we achieved a significant reduction in the amount of memory required. Extensive experiments illustrate that our proposed model can achieve a better reconstruction quality than existing state-of-the-art CS algorithms, and it also has a smaller number of network parameters than these algorithms. Our source codes are available at: https://github.com/C66YU/CSRN.
COVID-19 Spreading Prediction and Impact Analysis by Using Artificial Intelligence for Sustainable Global Health Assessment
Apr 23, 2023The COVID-19 pandemic is considered as the most alarming global health calamity of this century. COVID-19 has been confirmed to be mutated from coronavirus family. As stated by the records of The World Health Organization (WHO at April 18 2020), the present epidemic of COVID-19, has influenced more than 2,164,111 persons and killed more than 146,198 folks in over 200 countries across the globe and billions had confronted impacts in lifestyle because of this virus outbreak. The ongoing overall outbreak of the COVID-19 opened up new difficulties to the research sectors. Artificial intelligence (AI) driven strategies can be valuable to predict the parameters, hazards, and impacts of such an epidemic in a cost-efficient manner. The fundamental difficulties of AI in this situation is the limited availability of information and the uncertain nature of the disease. Here in this article, we have tried to integrate AI to predict the infection outbreak and along with this, we have also tried to test whether AI with help deep learning can recognize COVID-19 infected chest X-Rays or not. The global outbreak of the virus posed enormous economic, ecological and societal challenges into the human population and with help of this paper, we have tried to give a message that AI can help us to identify certain features of the disease outbreak that could prove to be essential to protect the humanity from this deadly disease.
* Advances in Environment Engineering and Management. Year 2021. Springer Proceedings in Earth and Environmental Sciences. Springer, Cham. https://doi.org/10.1007/978-3-030-79065-3_30
Learning Energy-Based Representations of Quantum Many-Body States
Apr 08, 2023
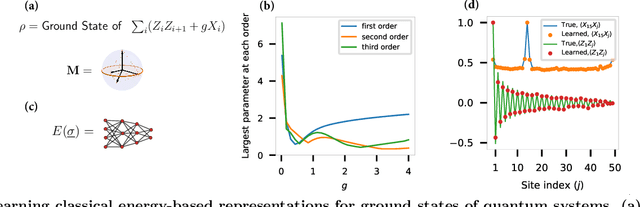
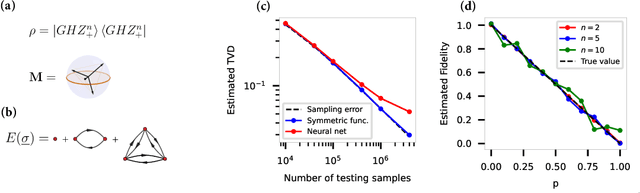
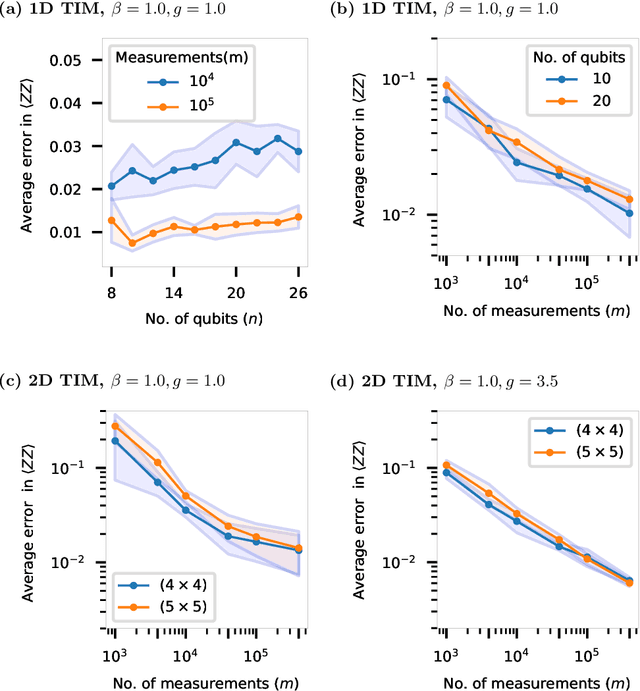
Efficient representation of quantum many-body states on classical computers is a problem of enormous practical interest. An ideal representation of a quantum state combines a succinct characterization informed by the system's structure and symmetries, along with the ability to predict the physical observables of interest. A number of machine learning approaches have been recently used to construct such classical representations [1-6] which enable predictions of observables [7] and account for physical symmetries [8]. However, the structure of a quantum state gets typically lost unless a specialized ansatz is employed based on prior knowledge of the system [9-12]. Moreover, most such approaches give no information about what states are easier to learn in comparison to others. Here, we propose a new generative energy-based representation of quantum many-body states derived from Gibbs distributions used for modeling the thermal states of classical spin systems. Based on the prior information on a family of quantum states, the energy function can be specified by a small number of parameters using an explicit low-degree polynomial or a generic parametric family such as neural nets, and can naturally include the known symmetries of the system. Our results show that such a representation can be efficiently learned from data using exact algorithms in a form that enables the prediction of expectation values of physical observables. Importantly, the structure of the learned energy function provides a natural explanation for the hardness of learning for a given class of quantum states.
Semantics-Aware Remote Estimation via Information Bottleneck-Inspired Type Based Multiple Access
Dec 19, 2022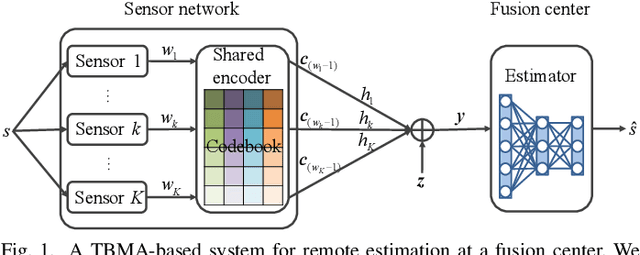
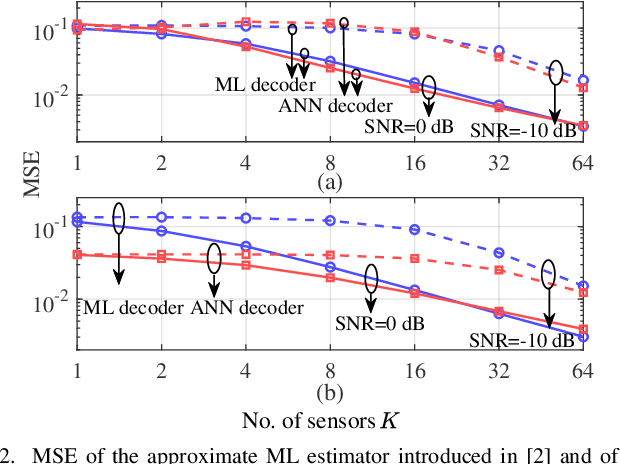
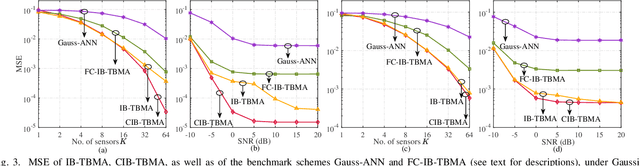
Type-based multiple access (TBMA) is a semantics-aware multiple access protocol for remote inference. In TBMA, codewords are reused across transmitting sensors, with each codeword being assigned to a different observation value. Existing TBMA protocols are based on fixed shared codebooks and on conventional maximum-likelihood or Bayesian decoders, which require knowledge of the distributions of observations and channels. In this letter, we propose a novel design principle for TBMA based on the information bottleneck (IB). In the proposed IB-TBMA protocol, the shared codebook is jointly optimized with a decoder based on artificial neural networks (ANNs), so as to adapt to source, observations, and channel statistics based on data only. We also introduce the Compressed IB-TBMA (CB-TBMA) protocol, which improves IB-TBMA by enabling a reduction in the number of codewords via an IB-inspired clustering phase. Numerical results demonstrate the importance of a joint design of codebook and neural decoder, and validate the benefits of codebook compression.
Large language models can rate news outlet credibility
Apr 01, 2023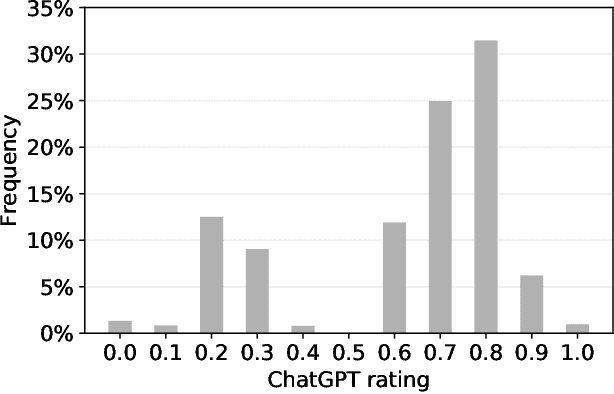
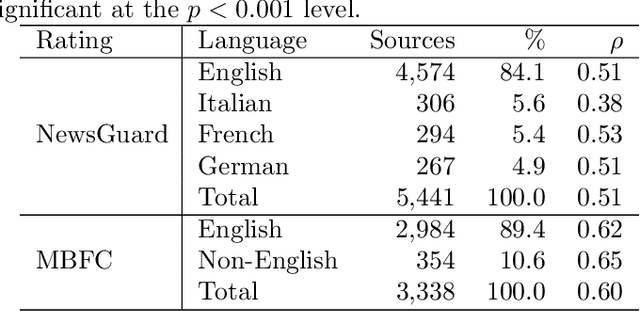
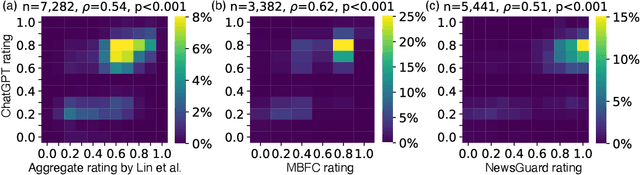
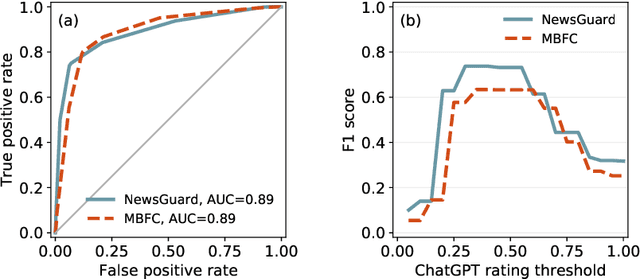
Although large language models (LLMs) have shown exceptional performance in various natural language processing tasks, they are prone to hallucinations. State-of-the-art chatbots, such as the new Bing, attempt to mitigate this issue by gathering information directly from the internet to ground their answers. In this setting, the capacity to distinguish trustworthy sources is critical for providing appropriate accuracy contexts to users. Here we assess whether ChatGPT, a prominent LLM, can evaluate the credibility of news outlets. With appropriate instructions, ChatGPT can provide ratings for a diverse set of news outlets, including those in non-English languages and satirical sources, along with contextual explanations. Our results show that these ratings correlate with those from human experts (Spearmam's $\rho=0.54, p<0.001$). These findings suggest that LLMs could be an affordable reference for credibility ratings in fact-checking applications. Future LLMs should enhance their alignment with human expert judgments of source credibility to improve information accuracy.
Multi-Channel Time-Series Person and Soft-Biometric Identification
Apr 04, 2023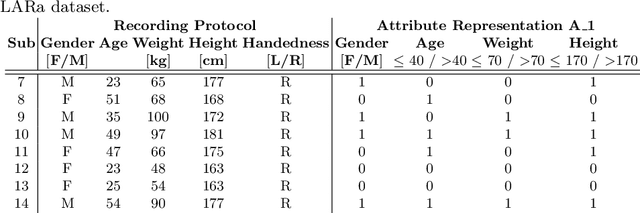
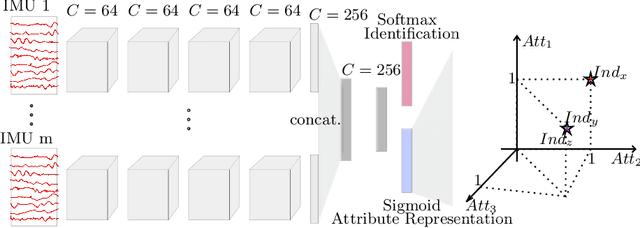
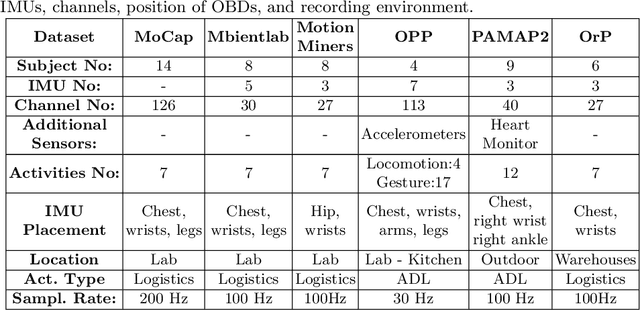
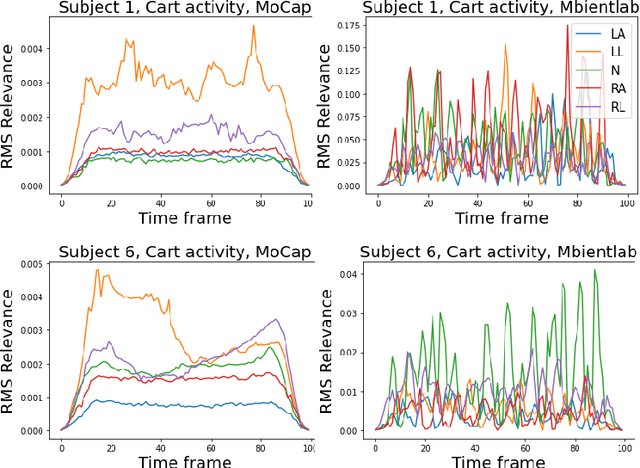
Multi-channel time-series datasets are popular in the context of human activity recognition (HAR). On-body device (OBD) recordings of human movements are often preferred for HAR applications not only for their reliability but as an approach for identity protection, e.g., in industrial settings. Contradictory, the gait activity is a biometric, as the cyclic movement is distinctive and collectable. In addition, the gait cycle has proven to contain soft-biometric information of human groups, such as age and height. Though general human movements have not been considered a biometric, they might contain identity information. This work investigates person and soft-biometrics identification from OBD recordings of humans performing different activities using deep architectures. Furthermore, we propose the use of attribute representation for soft-biometric identification. We evaluate the method on four datasets of multi-channel time-series HAR, measuring the performance of a person and soft-biometrics identification and its relation concerning performed activities. We find that person identification is not limited to gait activity. The impact of activities on the identification performance was found to be training and dataset specific. Soft-biometric based attribute representation shows promising results and emphasis the necessity of larger datasets.
hist2RNA: An efficient deep learning architecture to predict gene expression from breast cancer histopathology images
Apr 24, 2023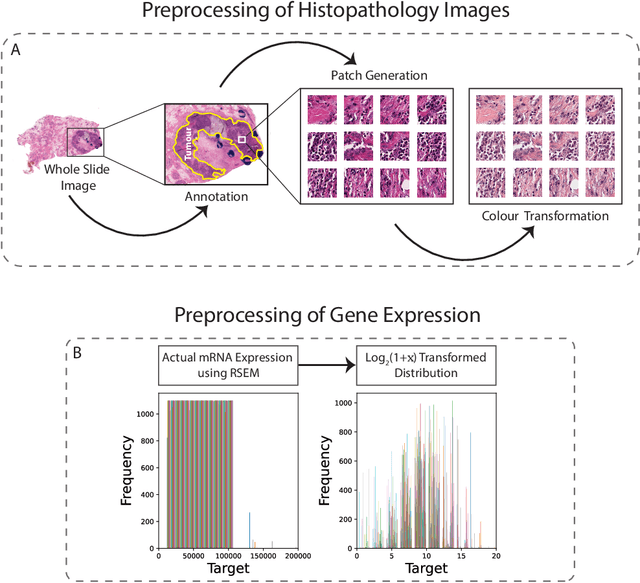

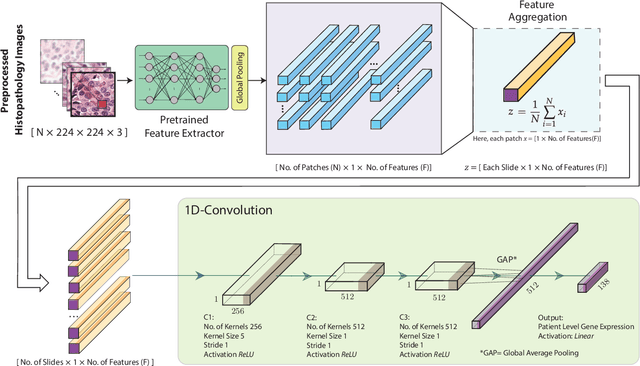

Gene expression can be used to subtype breast cancer with improved prediction of risk of recurrence and treatment responsiveness over that obtained using routine immunohistochemistry (IHC). However, in the clinic, molecular profiling is primarily used for ER+ cancer and is costly and tissue destructive, requires specialized platforms and takes several weeks to obtain a result. Deep learning algorithms can effectively extract morphological patterns in digital histopathology images to predict molecular phenotypes quickly and cost-effectively. We propose a new, computationally efficient approach called hist2RNA inspired by bulk RNA-sequencing techniques to predict the expression of 138 genes (incorporated from six commercially available molecular profiling tests), including luminal PAM50 subtype, from hematoxylin and eosin (H&E) stained whole slide images (WSIs). The training phase involves the aggregation of extracted features for each patient from a pretrained model to predict gene expression at the patient level using annotated H&E images from The Cancer Genome Atlas (TCGA, n=335). We demonstrate successful gene prediction on a held-out test set (n=160, corr=0.82 across patients, corr=0.29 across genes) and perform exploratory analysis on an external tissue microarray (TMA) dataset (n=498) with known IHC and survival information. Our model is able to predict gene expression and luminal PAM50 subtype (Luminal A versus Luminal B) on the TMA dataset with prognostic significance for overall survival in univariate analysis (c-index=0.56, hazard ratio=2.16 (95% CI 1.12-3.06), p<5x10-3), and independent significance in multivariate analysis incorporating standard clinicopathological variables (c-index=0.65, hazard ratio=1.85 (95% CI 1.30-2.68), p<5x10-3).