 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SViTT: Temporal Learning of Sparse Video-Text Transformers
Apr 18, 2023
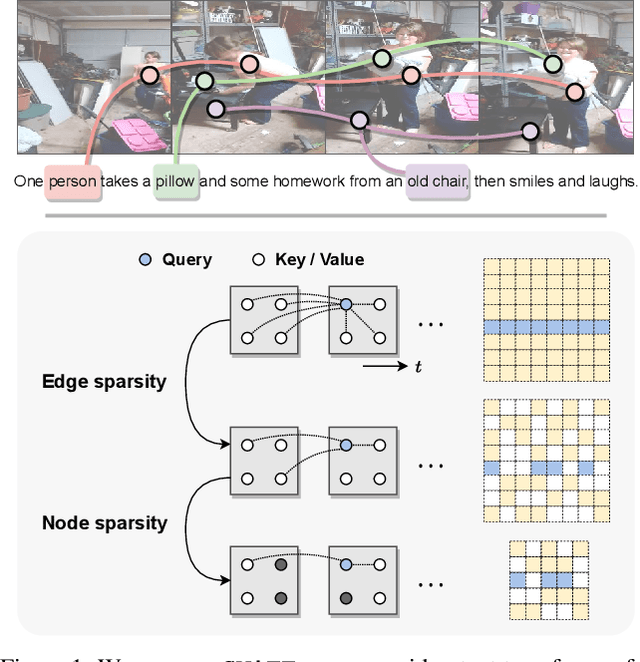
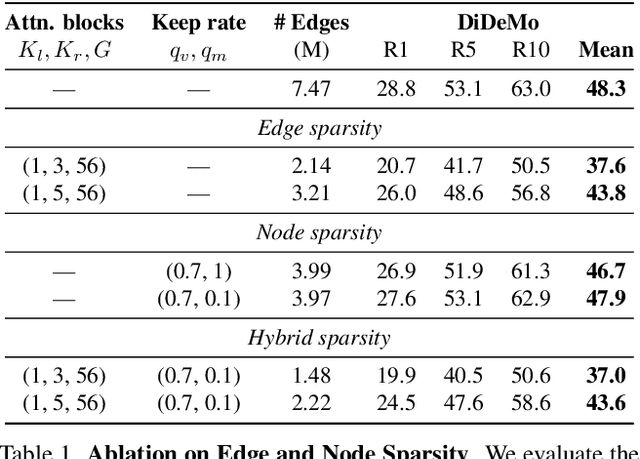
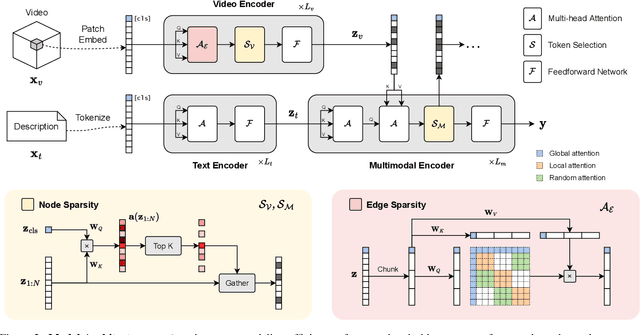
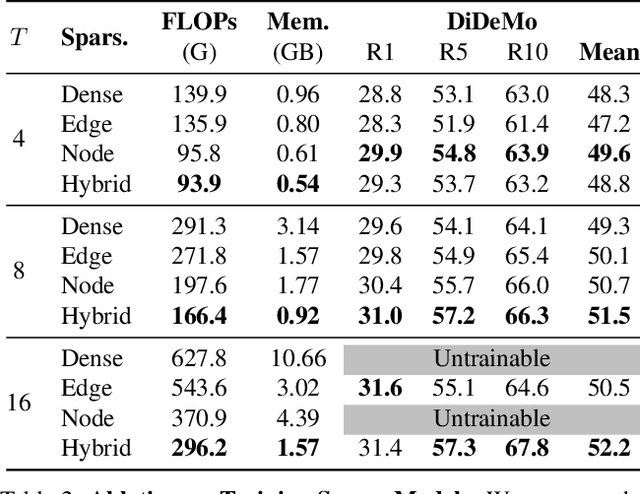
Do video-text transformers learn to model temporal relationships across frames? Despite their immense capacity and the abundance of multimodal training data, recent work has revealed the strong tendency of video-text models towards frame-based spatial representations, while temporal reasoning remains largely unsolved. In this work, we identify several key challenges in temporal learning of video-text transformers: the spatiotemporal trade-off from limited network size; the curse of dimensionality for multi-frame modeling; and the diminishing returns of semantic information by extending clip length. Guided by these findings, we propose SViTT, a sparse video-text architecture that performs multi-frame reasoning with significantly lower cost than naive transformers with dense attention. Analogous to graph-based networks, SViTT employs two forms of sparsity: edge sparsity that limits the query-key communications between tokens in self-attention, and node sparsity that discards uninformative visual tokens. Trained with a curriculum which increases model sparsity with the clip length, SViTT outperforms dense transformer baselines on multiple video-text retrieval and question answering benchmarks, with a fraction of computational cost. Project page: http://svcl.ucsd.edu/projects/svitt.
Learning Sim-to-Real Dense Object Descriptors for Robotic Manipulation
Apr 18, 2023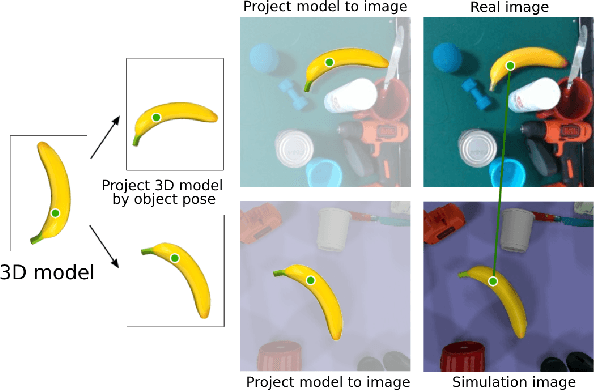
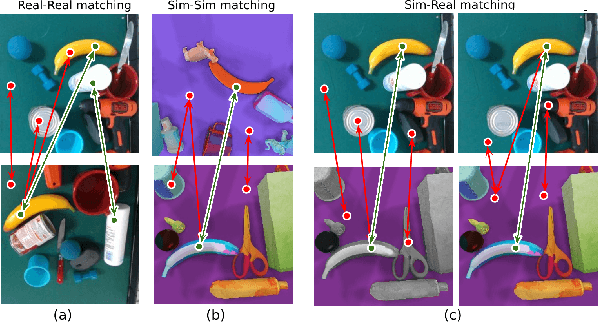
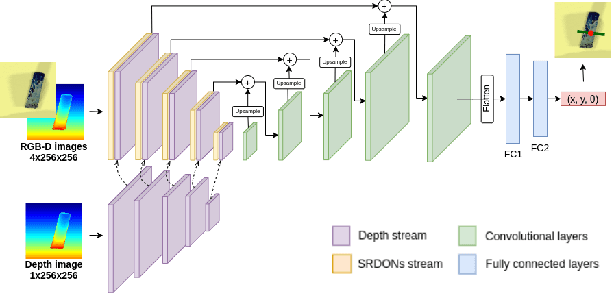

It is crucial to address the following issues for ubiquitous robotics manipulation applications: (a) vision-based manipulation tasks require the robot to visually learn and understand the object with rich information like dense object descriptors; and (b) sim-to-real transfer in robotics aims to close the gap between simulated and real data. In this paper, we present Sim-to-Real Dense Object Nets (SRDONs), a dense object descriptor that not only understands the object via appropriate representation but also maps simulated and real data to a unified feature space with pixel consistency. We proposed an object-to-object matching method for image pairs from different scenes and different domains. This method helps reduce the effort of training data from real-world by taking advantage of public datasets, such as GraspNet. With sim-to-real object representation consistency, our SRDONs can serve as a building block for a variety of sim-to-real manipulation tasks. We demonstrate in experiments that pre-trained SRDONs significantly improve performances on unseen objects and unseen visual environments for various robotic tasks with zero real-world training.
Learning to Transmit with Provable Guarantees in Wireless Federated Learning
Apr 18, 2023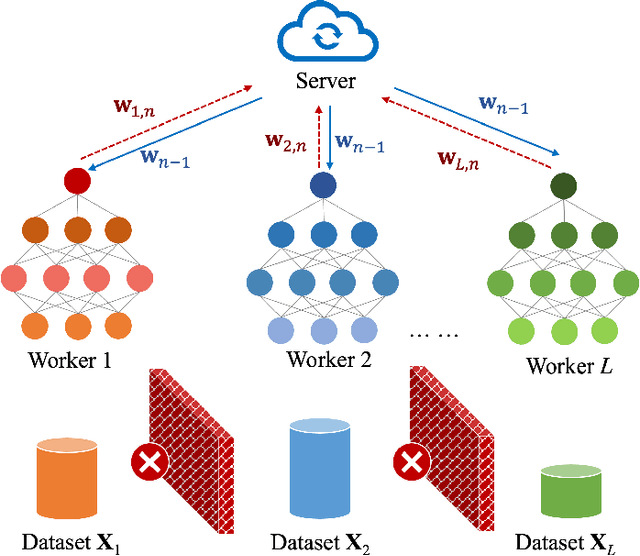
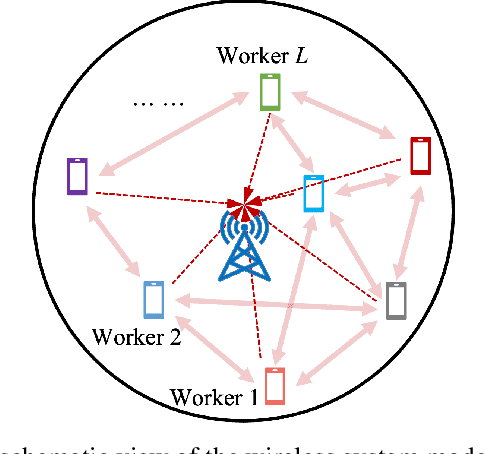
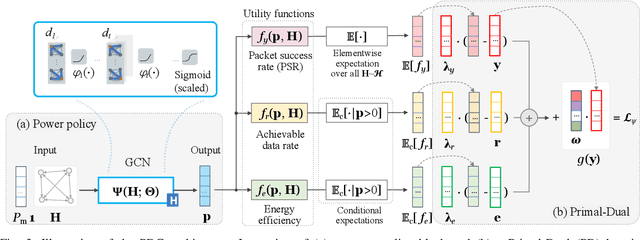
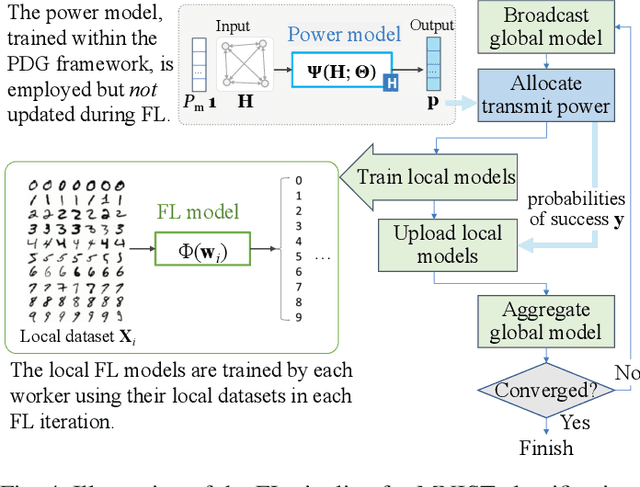
We propose a novel data-driven approach to allocate transmit power for federated learning (FL) over interference-limited wireless networks. The proposed method is useful in challenging scenarios where the wireless channel is changing during the FL training process and when the training data are not independent and identically distributed (non-i.i.d.) on the local devices. Intuitively, the power policy is designed to optimize the information received at the server end during the FL process under communication constraints. Ultimately, our goal is to improve the accuracy and efficiency of the global FL model being trained. The proposed power allocation policy is parameterized using a graph convolutional network and the associated constrained optimization problem is solved through a primal-dual (PD) algorithm. Theoretically, we show that the formulated problem has zero duality gap and, once the power policy is parameterized, optimality depends on how expressive this parameterization is. Numerically, we demonstrate that the proposed method outperforms existing baselines under different wireless channel settings and varying degrees of data heterogeneity.
TTIDA: Controllable Generative Data Augmentation via Text-to-Text and Text-to-Image Models
Apr 18, 2023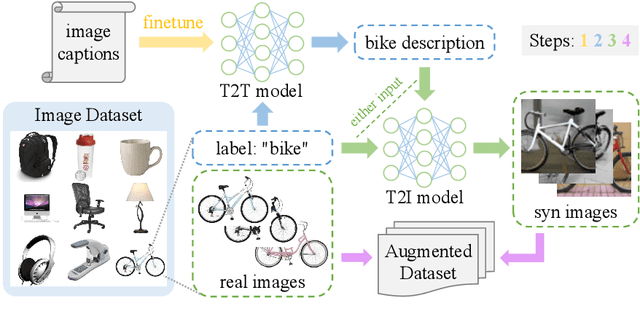
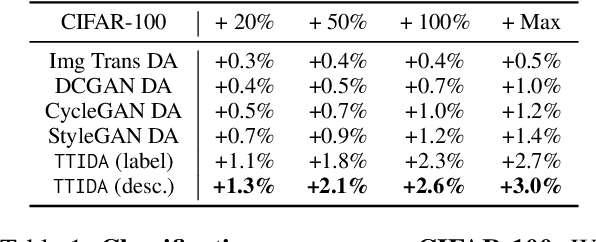
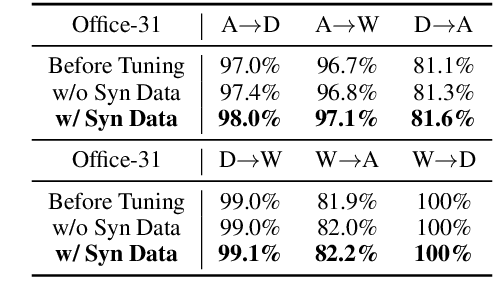
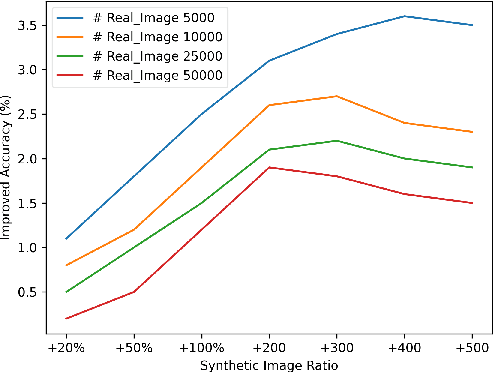
Data augmentation has been established as an efficacious approach to supplement useful information for low-resource datasets. Traditional augmentation techniques such as noise injection and image transformations have been widely used. In addition, generative data augmentation (GDA) has been shown to produce more diverse and flexible data. While generative adversarial networks (GANs) have been frequently used for GDA, they lack diversity and controllability compared to text-to-image diffusion models. In this paper, we propose TTIDA (Text-to-Text-to-Image Data Augmentation) to leverage the capabilities of large-scale pre-trained Text-to-Text (T2T) and Text-to-Image (T2I) generative models for data augmentation. By conditioning the T2I model on detailed descriptions produced by T2T models, we are able to generate photo-realistic labeled images in a flexible and controllable manner. Experiments on in-domain classification, cross-domain classification, and image captioning tasks show consistent improvements over other data augmentation baselines. Analytical studies in varied settings, including few-shot, long-tail, and adversarial, further reinforce the effectiveness of TTIDA in enhancing performance and increasing robustness.
Gradient Imitation Reinforcement Learning for General Low-Resource Information Extraction
Nov 14, 2022
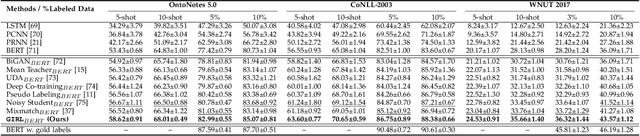
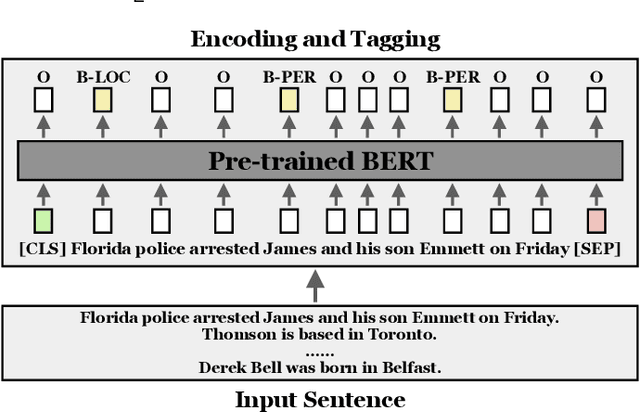
Information Extraction (IE) aims to extract structured information from heterogeneous sources. IE from natural language texts include sub-tasks such as Named Entity Recognition (NER), Relation Extraction (RE), and Event Extraction (EE). Most IE systems require comprehensive understandings of sentence structure, implied semantics, and domain knowledge to perform well; thus, IE tasks always need adequate external resources and annotations. However, it takes time and effort to obtain more human annotations. Low-Resource Information Extraction (LRIE) strives to use unsupervised data, reducing the required resources and human annotation. In practice, existing systems either utilize self-training schemes to generate pseudo labels that will cause the gradual drift problem, or leverage consistency regularization methods which inevitably possess confirmation bias. To alleviate confirmation bias due to the lack of feedback loops in existing LRIE learning paradigms, we develop a Gradient Imitation Reinforcement Learning (GIRL) method to encourage pseudo-labeled data to imitate the gradient descent direction on labeled data, which can force pseudo-labeled data to achieve better optimization capabilities similar to labeled data. Based on how well the pseudo-labeled data imitates the instructive gradient descent direction obtained from labeled data, we design a reward to quantify the imitation process and bootstrap the optimization capability of pseudo-labeled data through trial and error. In addition to learning paradigms, GIRL is not limited to specific sub-tasks, and we leverage GIRL to solve all IE sub-tasks (named entity recognition, relation extraction, and event extraction) in low-resource settings (semi-supervised IE and few-shot IE).
Rotating without Seeing: Towards In-hand Dexterity through Touch
Mar 27, 2023


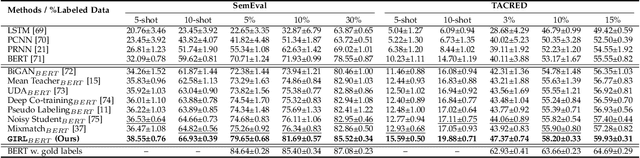
Tactile information plays a critical role in human dexterity. It reveals useful contact information that may not be inferred directly from vision. In fact, humans can even perform in-hand dexterous manipulation without using vision. Can we enable the same ability for the multi-finger robot hand? In this paper, we present Touch Dexterity, a new system that can perform in-hand object rotation using only touching without seeing the object. Instead of relying on precise tactile sensing in a small region, we introduce a new system design using dense binary force sensors (touch or no touch) overlaying one side of the whole robot hand (palm, finger links, fingertips). Such a design is low-cost, giving a larger coverage of the object, and minimizing the Sim2Real gap at the same time. We train an in-hand rotation policy using Reinforcement Learning on diverse objects in simulation. Relying on touch-only sensing, we can directly deploy the policy in a real robot hand and rotate novel objects that are not presented in training. Extensive ablations are performed on how tactile information help in-hand manipulation.Our project is available at https://touchdexterity.github.io.
Dehazing-NeRF: Neural Radiance Fields from Hazy Images
Apr 22, 2023


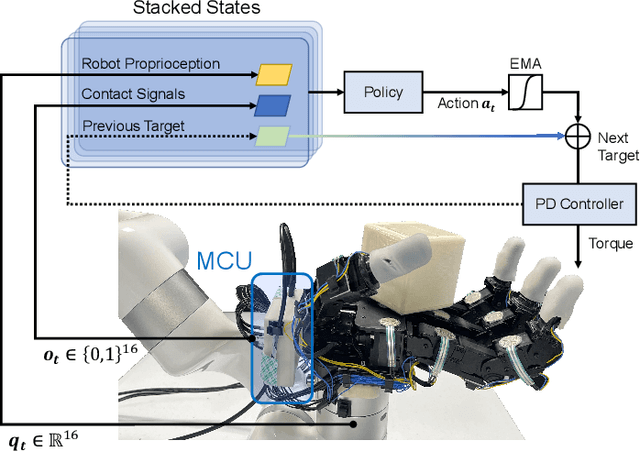
Neural Radiance Field (NeRF) has received much attention in recent years due to the impressively high quality in 3D scene reconstruction and novel view synthesis. However, image degradation caused by the scattering of atmospheric light and object light by particles in the atmosphere can significantly decrease the reconstruction quality when shooting scenes in hazy conditions. To address this issue, we propose Dehazing-NeRF, a method that can recover clear NeRF from hazy image inputs. Our method simulates the physical imaging process of hazy images using an atmospheric scattering model, and jointly learns the atmospheric scattering model and a clean NeRF model for both image dehazing and novel view synthesis. Different from previous approaches, Dehazing-NeRF is an unsupervised method with only hazy images as the input, and also does not rely on hand-designed dehazing priors. By jointly combining the depth estimated from the NeRF 3D scene with the atmospheric scattering model, our proposed model breaks through the ill-posed problem of single-image dehazing while maintaining geometric consistency. Besides, to alleviate the degradation of image quality caused by information loss, soft margin consistency regularization, as well as atmospheric consistency and contrast discriminative loss, are addressed during the model training process. Extensive experiments demonstrate that our method outperforms the simple combination of single-image dehazing and NeRF on both image dehazing and novel view image synthesis.
Unsupervised CD in satellite image time series by contrastive learning and feature tracking
Apr 22, 2023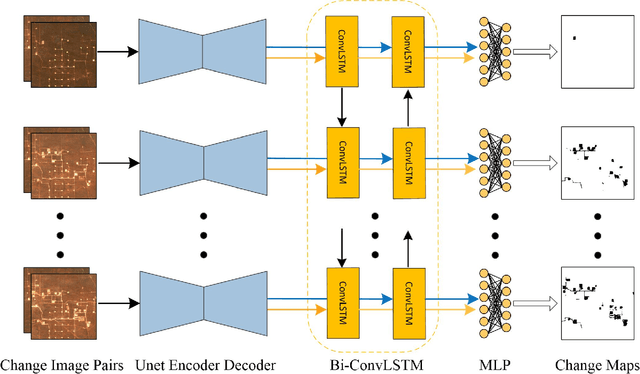

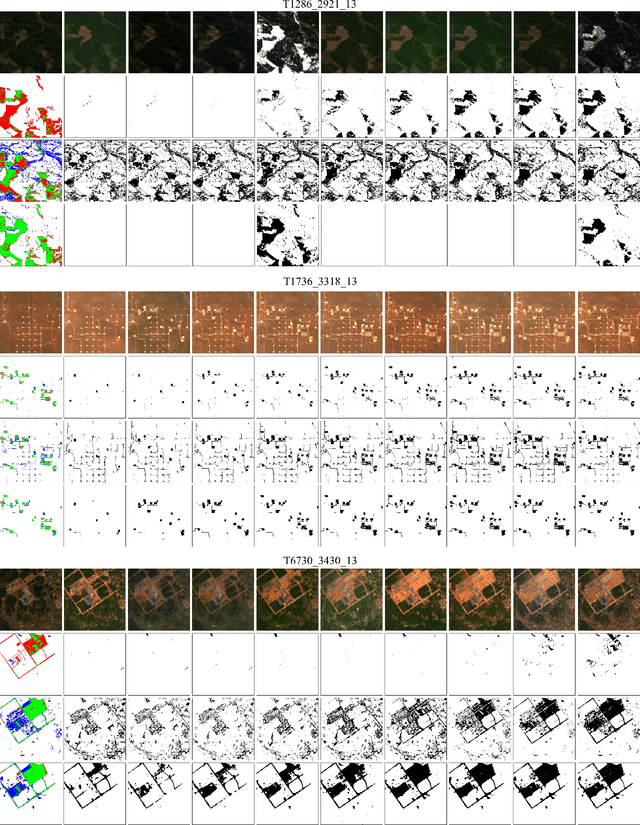

While unsupervised change detection using contrastive learning has been significantly improved the performance of literature techniques, at present, it only focuses on the bi-temporal change detection scenario. Previous state-of-the-art models for image time-series change detection often use features obtained by learning for clustering or training a model from scratch using pseudo labels tailored to each scene. However, these approaches fail to exploit the spatial-temporal information of image time-series or generalize to unseen scenarios. In this work, we propose a two-stage approach to unsupervised change detection in satellite image time-series using contrastive learning with feature tracking. By deriving pseudo labels from pre-trained models and using feature tracking to propagate them among the image time-series, we improve the consistency of our pseudo labels and address the challenges of seasonal changes in long-term remote sensing image time-series. We adopt the self-training algorithm with ConvLSTM on the obtained pseudo labels, where we first use supervised contrastive loss and contrastive random walks to further improve the feature correspondence in space-time. Then a fully connected layer is fine-tuned on the pre-trained multi-temporal features for generating the final change maps. Through comprehensive experiments on two datasets, we demonstrate consistent improvements in accuracy on fitting and inference scenarios.
CSI-Based Data-driven Localization Frameworking using Small-scale Training Datasets in Single-site MIMO Systems
Apr 22, 2023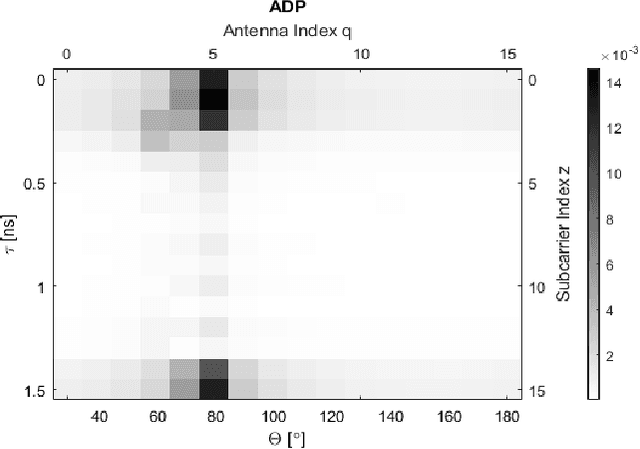
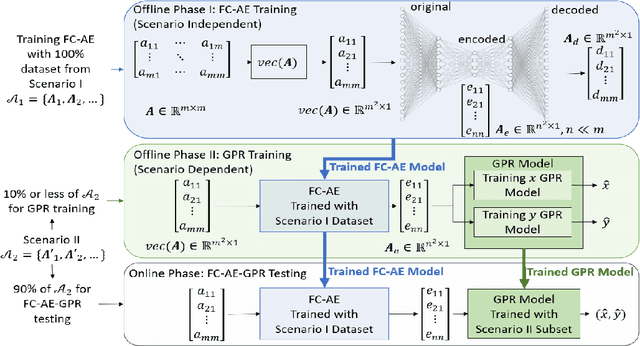
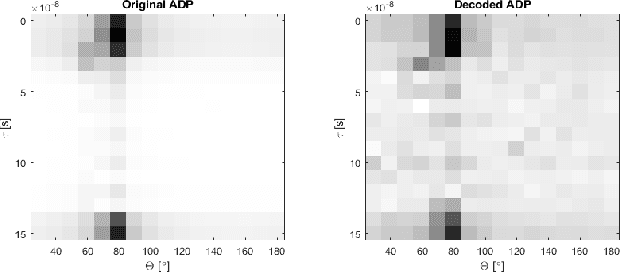
This work presents a date-driven user localization framework for single-site massive Multiple-Input-Multiple-Output (MIMO) systems. The framework is trained on a geo-tagged Channel State Information (CSI) dataset. Unlike the state-of-the-art Convolutional Neural Network (CNN) models, which require large training datasets to perform well, our method is specifically designed to operate with small-scale training datasets. This makes our approach more practical for real-world scenarios, where collecting a large amount of data can be challenging. Our proposed FC-AE-GPR framework combines two components: a Fully-Connected Auto-Encoder (FC-AE) and a Gaussian Process Regression (GPR) model. Our results show that the GPR model outperforms the CNN model when presented with small training datasets. However, the training complexity of GPR models can become an issue when the input sample size is large. To address this, we propose using the FC-AE to reduce the sample size by encoding the CSI before training the GPR model. Although the FC-AE model may require a larger training dataset initially, we demonstrate that the FC-AE is scenario independent. This means that it can be utilized in new and unseen scenarios without prior retraining. Therefore, adapting the FC-AE-GPR model to a new scenario requires only retraining the GPR model with a small training dataset.
AutoVRL: A High Fidelity Autonomous Ground Vehicle Simulator for Sim-to-Real Deep Reinforcement Learning
Apr 22, 2023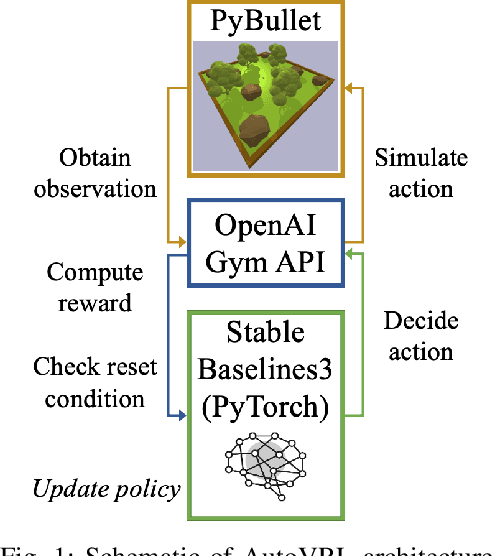
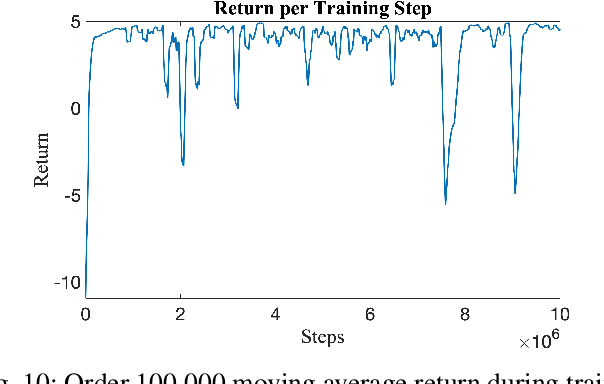

Deep Reinforcement Learning (DRL) enables cognitive Autonomous Ground Vehicle (AGV) navigation utilizing raw sensor data without a-priori maps or GPS, which is a necessity in hazardous, information poor environments such as regions where natural disasters occur, and extraterrestrial planets. The substantial training time required to learn an optimal DRL policy, which can be days or weeks for complex tasks, is a major hurdle to real-world implementation in AGV applications. Training entails repeated collisions with the surrounding environment over an extended time period, dependent on the complexity of the task, to reinforce positive exploratory, application specific behavior that is expensive, and time consuming in the real-world. Effectively bridging the simulation to real-world gap is a requisite for successful implementation of DRL in complex AGV applications, enabling learning of cost-effective policies. We present AutoVRL, an open-source high fidelity simulator built upon the Bullet physics engine utilizing OpenAI Gym and Stable Baselines3 in PyTorch to train AGV DRL agents for sim-to-real policy transfer. AutoVRL is equipped with sensor implementations of GPS, IMU, LiDAR and camera, actuators for AGV control, and realistic environments, with extensibility for new environments and AGV models. The simulator provides access to state-of-the-art DRL algorithms, utilizing a python interface for simple algorithm and environment customization, and simulation execution.