 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Useful Compact Representations for Data-Fitting
Mar 18, 2024
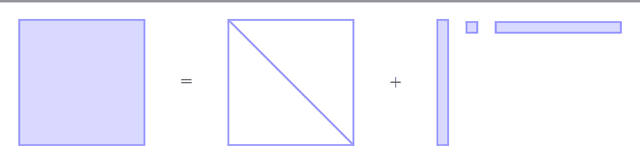
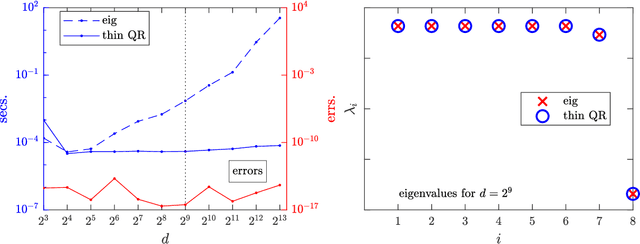
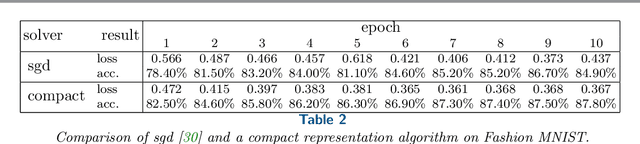
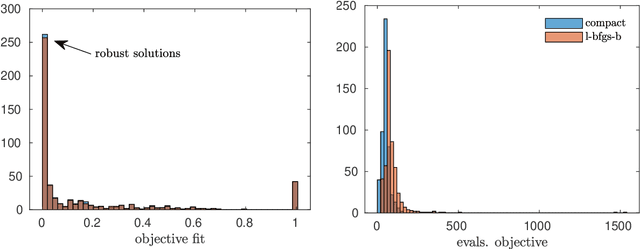
For minimization problems without 2nd derivative information, methods that estimate Hessian matrices can be very effective. However, conventional techniques generate dense matrices that are prohibitive for large problems. Limited-memory compact representations express the dense arrays in terms of a low rank representation and have become the state-of-the-art for software implementations on large deterministic problems. We develop new compact representations that are parameterized by a choice of vectors and that reduce to existing well known formulas for special choices. We demonstrate effectiveness of the compact representations for large eigenvalue computations, tensor factorizations and nonlinear regressions.
Enhancing Information Maximization with Distance-Aware Contrastive Learning for Source-Free Cross-Domain Few-Shot Learning
Mar 04, 2024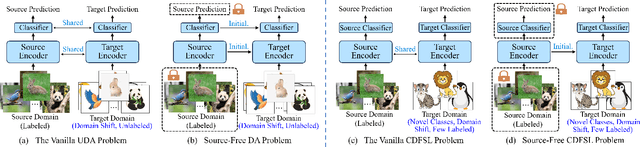
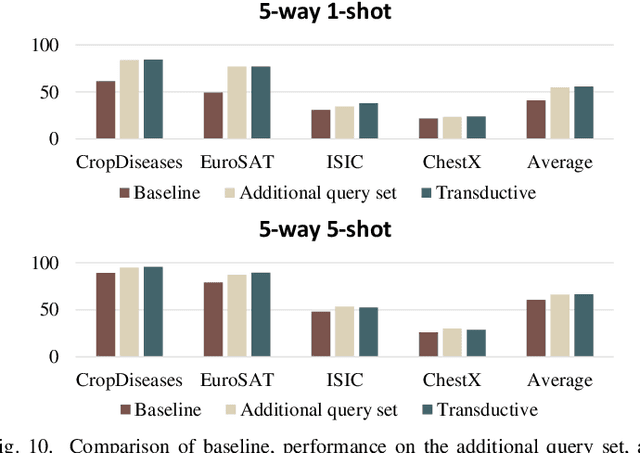
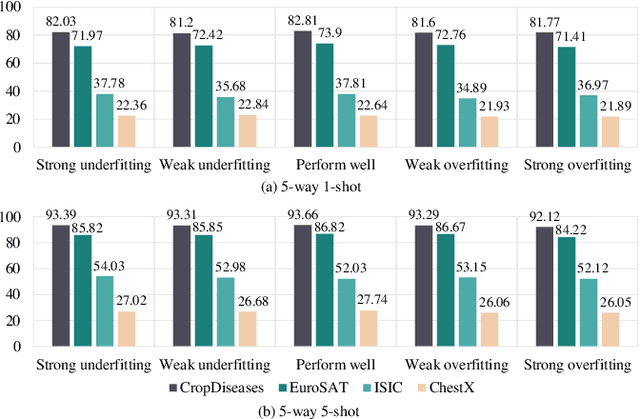
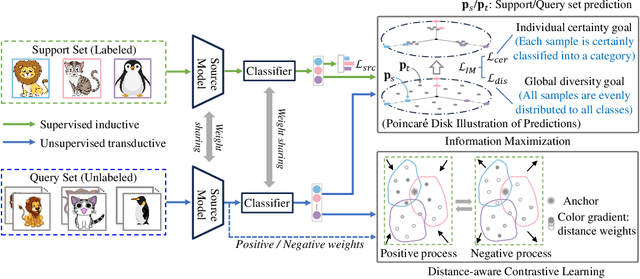
Existing Cross-Domain Few-Shot Learning (CDFSL) methods require access to source domain data to train a model in the pre-training phase. However, due to increasing concerns about data privacy and the desire to reduce data transmission and training costs, it is necessary to develop a CDFSL solution without accessing source data. For this reason, this paper explores a Source-Free CDFSL (SF-CDFSL) problem, in which CDFSL is addressed through the use of existing pretrained models instead of training a model with source data, avoiding accessing source data. This paper proposes an Enhanced Information Maximization with Distance-Aware Contrastive Learning (IM-DCL) method to address these challenges. Firstly, we introduce the transductive mechanism for learning the query set. Secondly, information maximization (IM) is explored to map target samples into both individual certainty and global diversity predictions, helping the source model better fit the target data distribution. However, IM fails to learn the decision boundary of the target task. This motivates us to introduce a novel approach called Distance-Aware Contrastive Learning (DCL), in which we consider the entire feature set as both positive and negative sets, akin to Schrodinger's concept of a dual state. Instead of a rigid separation between positive and negative sets, we employ a weighted distance calculation among features to establish a soft classification of the positive and negative sets for the entire feature set. Furthermore, we address issues related to IM by incorporating contrastive constraints between object features and their corresponding positive and negative sets. Evaluations of the 4 datasets in the BSCD-FSL benchmark indicate that the proposed IM-DCL, without accessing the source domain, demonstrates superiority over existing methods, especially in the distant domain task.
Approximations to the Fisher Information Metric of Deep Generative Models for Out-Of-Distribution Detection
Mar 03, 2024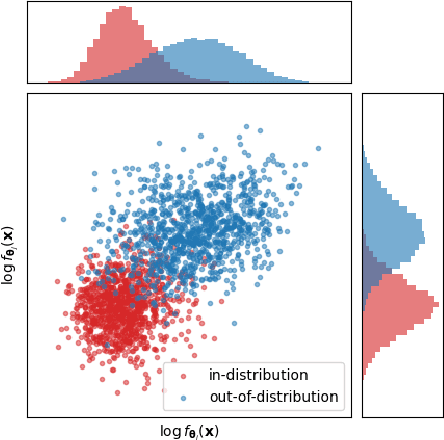
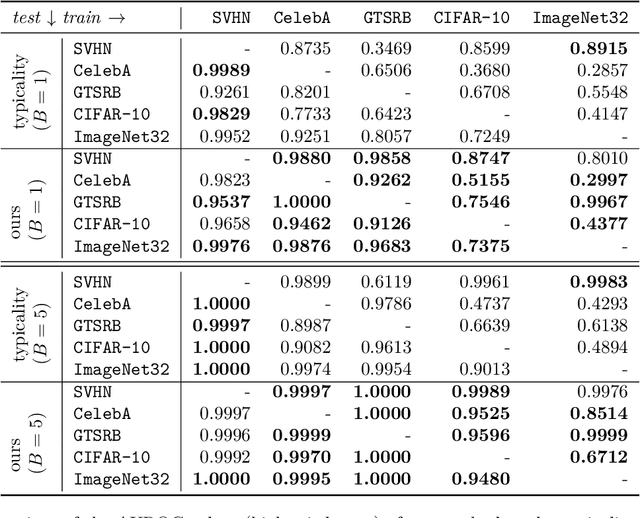
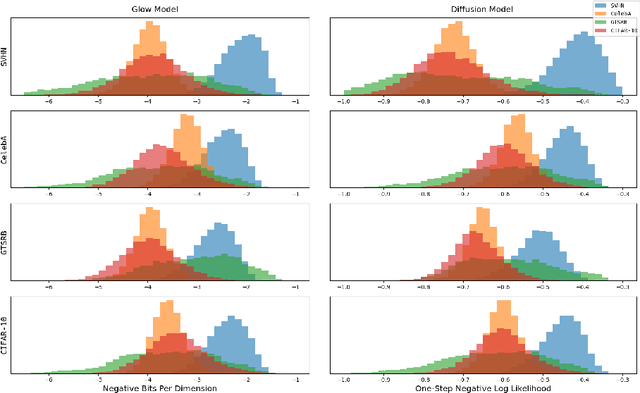
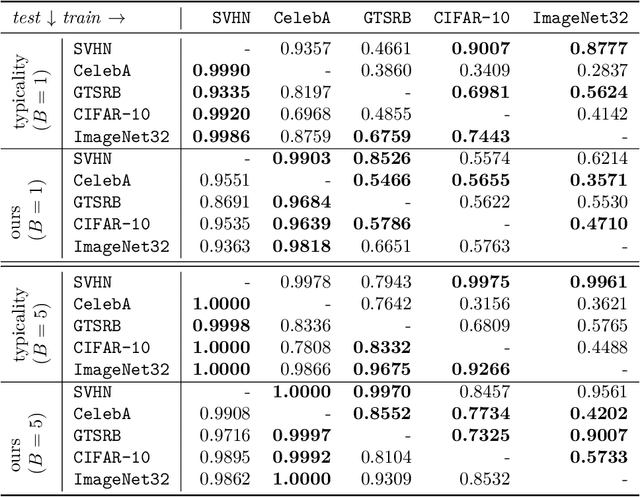
Likelihood-based deep generative models such as score-based diffusion models and variational autoencoders are state-of-the-art machine learning models approximating high-dimensional distributions of data such as images, text, or audio. One of many downstream tasks they can be naturally applied to is out-of-distribution (OOD) detection. However, seminal work by Nalisnick et al. which we reproduce showed that deep generative models consistently infer higher log-likelihoods for OOD data than data they were trained on, marking an open problem. In this work, we analyse using the gradient of a data point with respect to the parameters of the deep generative model for OOD detection, based on the simple intuition that OOD data should have larger gradient norms than training data. We formalise measuring the size of the gradient as approximating the Fisher information metric. We show that the Fisher information matrix (FIM) has large absolute diagonal values, motivating the use of chi-square distributed, layer-wise gradient norms as features. We combine these features to make a simple, model-agnostic and hyperparameter-free method for OOD detection which estimates the joint density of the layer-wise gradient norms for a given data point. We find that these layer-wise gradient norms are weakly correlated, rendering their combined usage informative, and prove that the layer-wise gradient norms satisfy the principle of (data representation) invariance. Our empirical results indicate that this method outperforms the Typicality test for most deep generative models and image dataset pairings.
HUGS: Holistic Urban 3D Scene Understanding via Gaussian Splatting
Mar 19, 2024
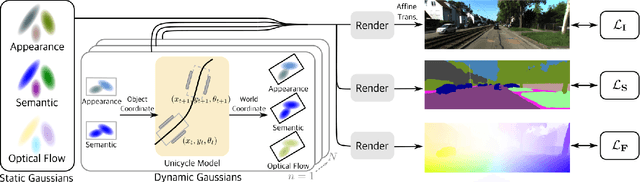
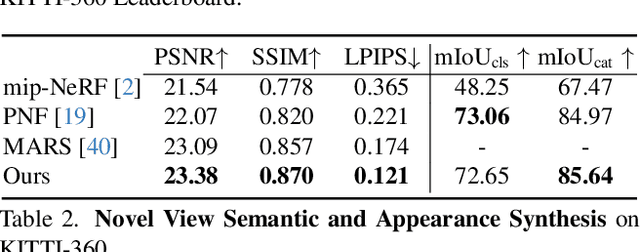

Holistic understanding of urban scenes based on RGB images is a challenging yet important problem. It encompasses understanding both the geometry and appearance to enable novel view synthesis, parsing semantic labels, and tracking moving objects. Despite considerable progress, existing approaches often focus on specific aspects of this task and require additional inputs such as LiDAR scans or manually annotated 3D bounding boxes. In this paper, we introduce a novel pipeline that utilizes 3D Gaussian Splatting for holistic urban scene understanding. Our main idea involves the joint optimization of geometry, appearance, semantics, and motion using a combination of static and dynamic 3D Gaussians, where moving object poses are regularized via physical constraints. Our approach offers the ability to render new viewpoints in real-time, yielding 2D and 3D semantic information with high accuracy, and reconstruct dynamic scenes, even in scenarios where 3D bounding box detection are highly noisy. Experimental results on KITTI, KITTI-360, and Virtual KITTI 2 demonstrate the effectiveness of our approach.
Selective Domain-Invariant Feature for Generalizable Deepfake Detection
Mar 19, 2024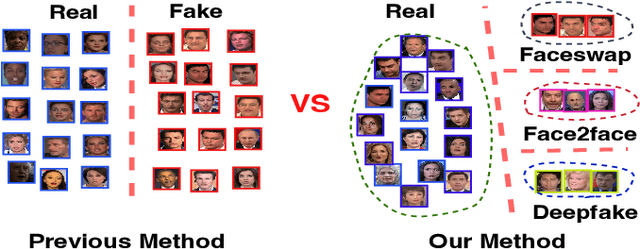
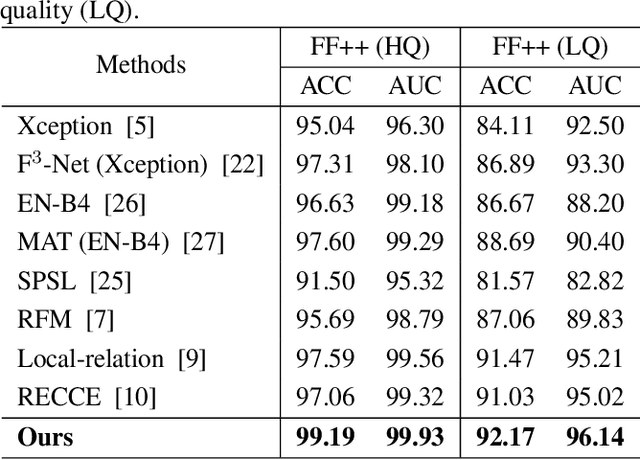
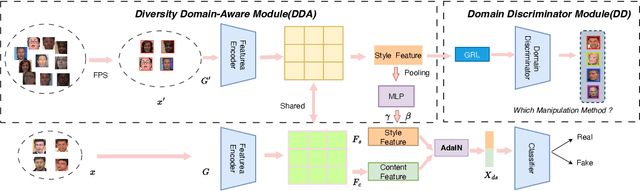
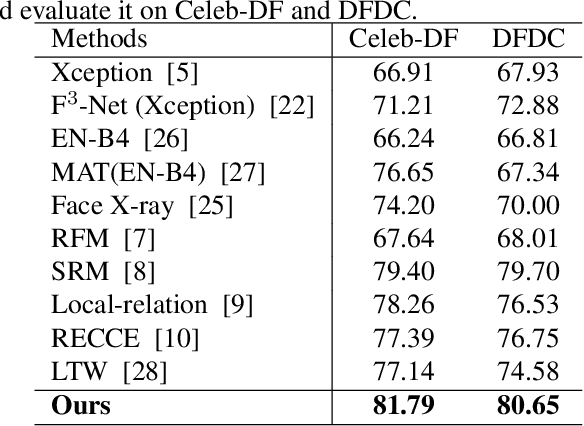
With diverse presentation forgery methods emerging continually, detecting the authenticity of images has drawn growing attention. Although existing methods have achieved impressive accuracy in training dataset detection, they still perform poorly in the unseen domain and suffer from forgery of irrelevant information such as background and identity, affecting generalizability. To solve this problem, we proposed a novel framework Selective Domain-Invariant Feature (SDIF), which reduces the sensitivity to face forgery by fusing content features and styles. Specifically, we first use a Farthest-Point Sampling (FPS) training strategy to construct a task-relevant style sample representation space for fusing with content features. Then, we propose a dynamic feature extraction module to generate features with diverse styles to improve the performance and effectiveness of the feature extractor. Finally, a domain separation strategy is used to retain domain-related features to help distinguish between real and fake faces. Both qualitative and quantitative results in existing benchmarks and proposals demonstrate the effectiveness of our approach.
Improving Generalizability of Extracting Social Determinants of Health Using Large Language Models through Prompt-tuning
Mar 19, 2024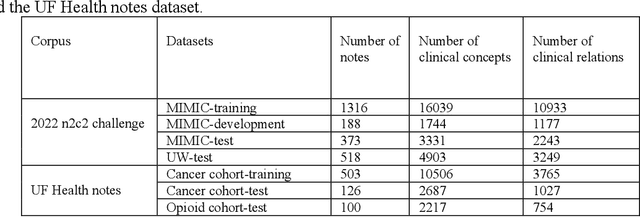
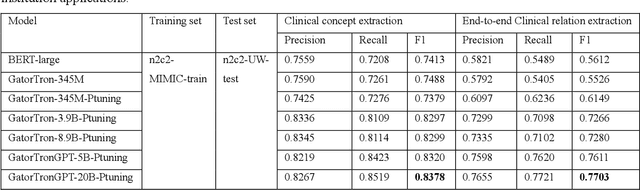
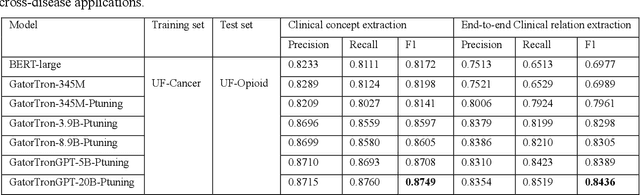
The progress in natural language processing (NLP) using large language models (LLMs) has greatly improved patient information extraction from clinical narratives. However, most methods based on the fine-tuning strategy have limited transfer learning ability for cross-domain applications. This study proposed a novel approach that employs a soft prompt-based learning architecture, which introduces trainable prompts to guide LLMs toward desired outputs. We examined two types of LLM architectures, including encoder-only GatorTron and decoder-only GatorTronGPT, and evaluated their performance for the extraction of social determinants of health (SDoH) using a cross-institution dataset from the 2022 n2c2 challenge and a cross-disease dataset from the University of Florida (UF) Health. The results show that decoder-only LLMs with prompt tuning achieved better performance in cross-domain applications. GatorTronGPT achieved the best F1 scores for both datasets, outperforming traditional fine-tuned GatorTron by 8.9% and 21.8% in a cross-institution setting, and 5.5% and 14.5% in a cross-disease setting.
Embodied LLM Agents Learn to Cooperate in Organized Teams
Mar 19, 2024
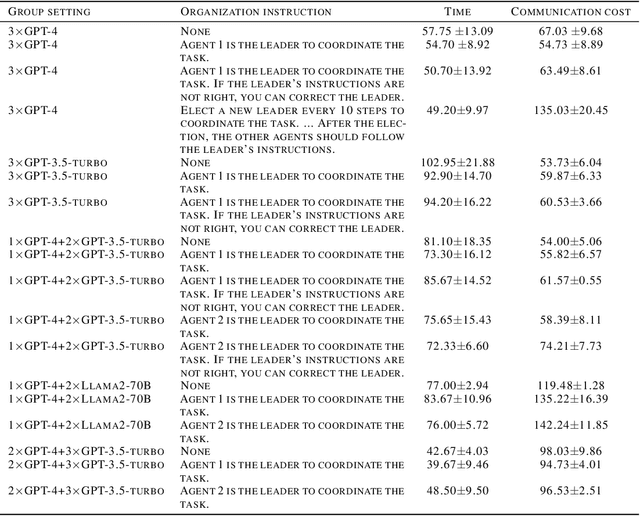
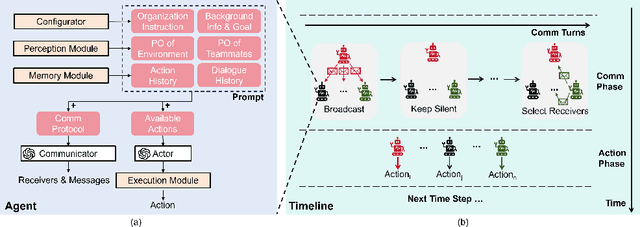
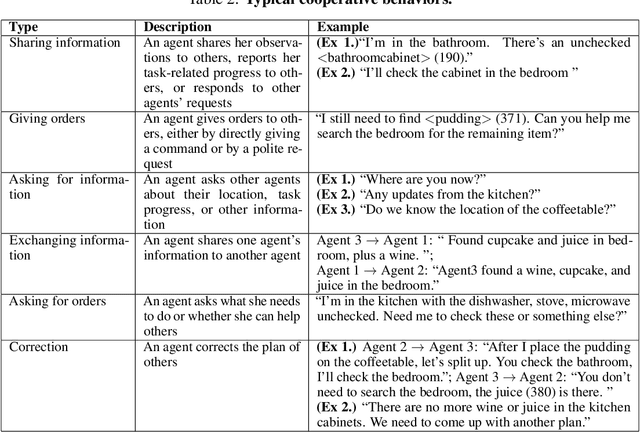
Large Language Models (LLMs) have emerged as integral tools for reasoning, planning, and decision-making, drawing upon their extensive world knowledge and proficiency in language-related tasks. LLMs thus hold tremendous potential for natural language interaction within multi-agent systems to foster cooperation. However, LLM agents tend to over-report and comply with any instruction, which may result in information redundancy and confusion in multi-agent cooperation. Inspired by human organizations, this paper introduces a framework that imposes prompt-based organization structures on LLM agents to mitigate these problems. Through a series of experiments with embodied LLM agents and human-agent collaboration, our results highlight the impact of designated leadership on team efficiency, shedding light on the leadership qualities displayed by LLM agents and their spontaneous cooperative behaviors. Further, we harness the potential of LLMs to propose enhanced organizational prompts, via a Criticize-Reflect process, resulting in novel organization structures that reduce communication costs and enhance team efficiency.
Deep Learning-Based CSI Feedback for RIS-Aided Massive MIMO Systems with Time Correlation
Mar 19, 2024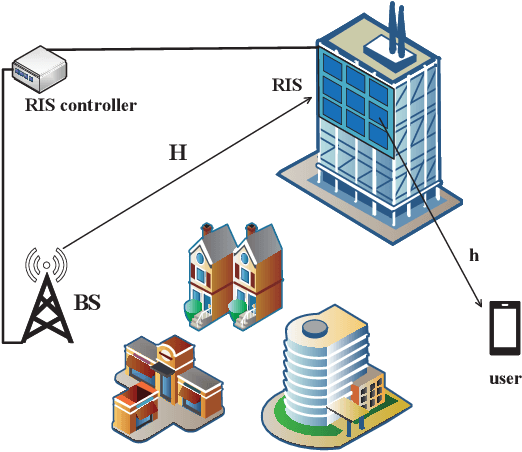
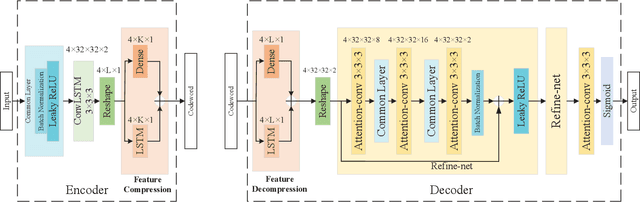
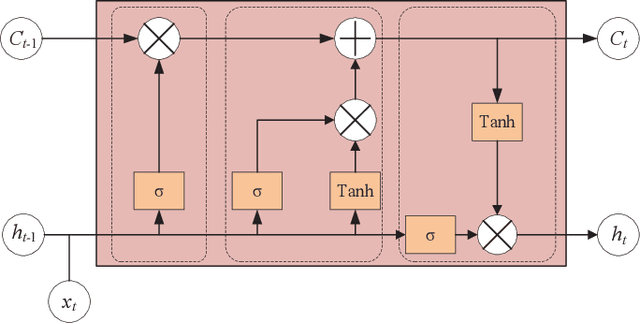
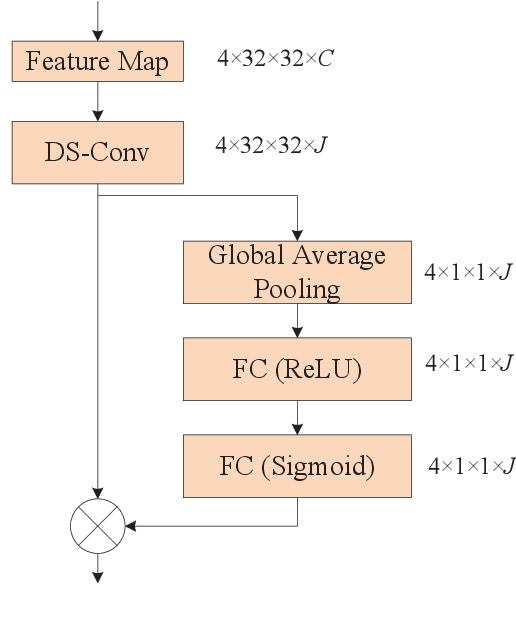
In this paper, we consider an reconfigurable intelligent surface (RIS)-aided frequency division duplex (FDD) massive multiple-input multiple-output (MIMO) downlink system.In the FDD systems, the downlink channel state information (CSI) should be sent to the base station through the feedback link. However, the overhead of CSI feedback occupies substantial uplink bandwidth resources in RIS-aided communication systems. In this work, we propose a deep learning (DL)-based scheme to reduce the overhead of CSI feedback by compressing the cascaded CSI. In the practical RIS-aided communication systems, the cascaded channel at the adjacent slots inevitably has time correlation. We use long short-term memory to learn time correlation, which can help the neural network to improve the recovery quality of the compressed CSI. Moreover, the attention mechanism is introduced to further improve the CSI recovery quality. Simulation results demonstrate that our proposed DLbased scheme can significantly outperform other DL-based methods in terms of the CSI recovery quality
Decoding Continuous Character-based Language from Non-invasive Brain Recordings
Mar 19, 2024Deciphering natural language from brain activity through non-invasive devices remains a formidable challenge. Previous non-invasive decoders either require multiple experiments with identical stimuli to pinpoint cortical regions and enhance signal-to-noise ratios in brain activity, or they are limited to discerning basic linguistic elements such as letters and words. We propose a novel approach to decoding continuous language from single-trial non-invasive fMRI recordings, in which a three-dimensional convolutional network augmented with information bottleneck is developed to automatically identify responsive voxels to stimuli, and a character-based decoder is designed for the semantic reconstruction of continuous language characterized by inherent character structures. The resulting decoder can produce intelligible textual sequences that faithfully capture the meaning of perceived speech both within and across subjects, while existing decoders exhibit significantly inferior performance in cross-subject contexts. The ability to decode continuous language from single trials across subjects demonstrates the promising applications of non-invasive language brain-computer interfaces in both healthcare and neuroscience.
CPA-Enhancer: Chain-of-Thought Prompted Adaptive Enhancer for Object Detection under Unknown Degradations
Mar 19, 2024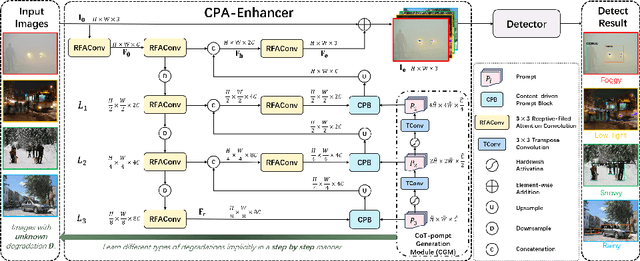
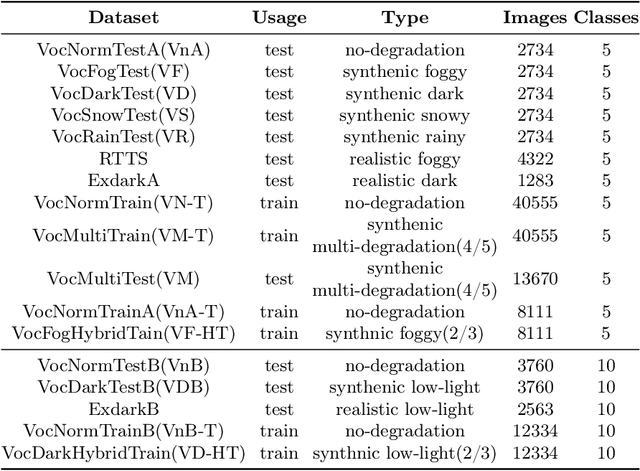
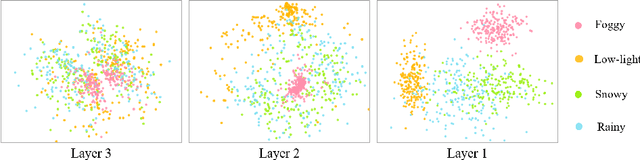
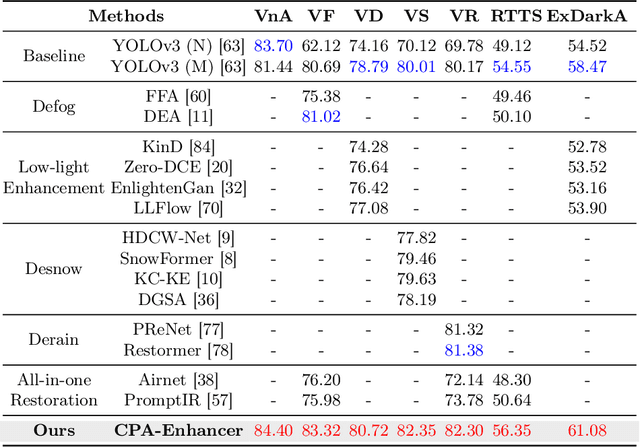
Object detection methods under known single degradations have been extensively investigated. However, existing approaches require prior knowledge of the degradation type and train a separate model for each, limiting their practical applications in unpredictable environments. To address this challenge, we propose a chain-of-thought (CoT) prompted adaptive enhancer, CPA-Enhancer, for object detection under unknown degradations. Specifically, CPA-Enhancer progressively adapts its enhancement strategy under the step-by-step guidance of CoT prompts, that encode degradation-related information. To the best of our knowledge, it's the first work that exploits CoT prompting for object detection tasks. Overall, CPA-Enhancer is a plug-and-play enhancement model that can be integrated into any generic detectors to achieve substantial gains on degraded images, without knowing the degradation type priorly. Experimental results demonstrate that CPA-Enhancer not only sets the new state of the art for object detection but also boosts the performance of other downstream vision tasks under unknown degradations.