 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Online Information Retrieval Evaluation using the STELLA Framework
Oct 24, 2022
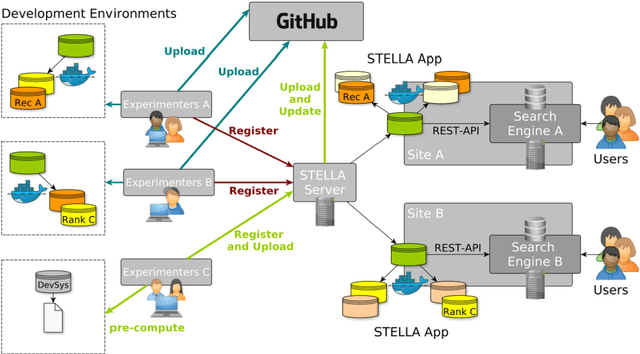
Involving users in early phases of software development has become a common strategy as it enables developers to consider user needs from the beginning. Once a system is in production, new opportunities to observe, evaluate and learn from users emerge as more information becomes available. Gathering information from users to continuously evaluate their behavior is a common practice for commercial software, while the Cranfield paradigm remains the preferred option for Information Retrieval (IR) and recommendation systems in the academic world. Here we introduce the Infrastructures for Living Labs STELLA project which aims to create an evaluation infrastructure allowing experimental systems to run along production web-based academic search systems with real users. STELLA combines user interactions and log files analyses to enable large-scale A/B experiments for academic search.
* arXiv admin note: text overlap with arXiv:2203.05430
Estimating the Density Ratio between Distributions with High Discrepancy using Multinomial Logistic Regression
May 01, 2023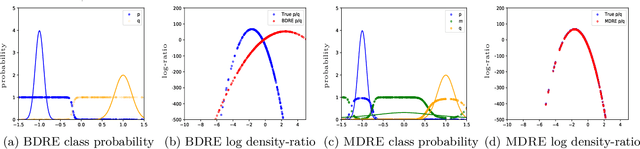

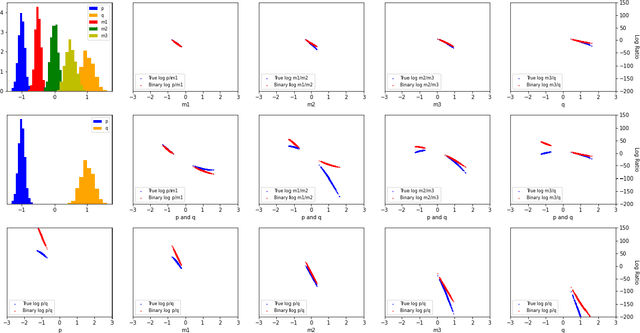
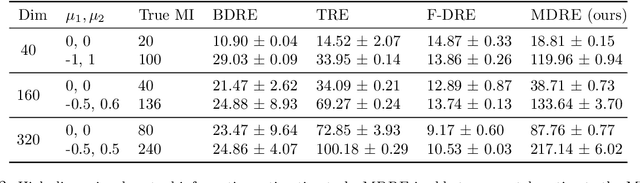
Functions of the ratio of the densities $p/q$ are widely used in machine learning to quantify the discrepancy between the two distributions $p$ and $q$. For high-dimensional distributions, binary classification-based density ratio estimators have shown great promise. However, when densities are well separated, estimating the density ratio with a binary classifier is challenging. In this work, we show that the state-of-the-art density ratio estimators perform poorly on well-separated cases and demonstrate that this is due to distribution shifts between training and evaluation time. We present an alternative method that leverages multi-class classification for density ratio estimation and does not suffer from distribution shift issues. The method uses a set of auxiliary densities $\{m_k\}_{k=1}^K$ and trains a multi-class logistic regression to classify the samples from $p, q$, and $\{m_k\}_{k=1}^K$ into $K+2$ classes. We show that if these auxiliary densities are constructed such that they overlap with $p$ and $q$, then a multi-class logistic regression allows for estimating $\log p/q$ on the domain of any of the $K+2$ distributions and resolves the distribution shift problems of the current state-of-the-art methods. We compare our method to state-of-the-art density ratio estimators on both synthetic and real datasets and demonstrate its superior performance on the tasks of density ratio estimation, mutual information estimation, and representation learning. Code: https://www.blackswhan.com/mdre/
Semantic-Aware Sensing Information Transmission for Metaverse: A Contest Theoretic Approach
Nov 23, 2022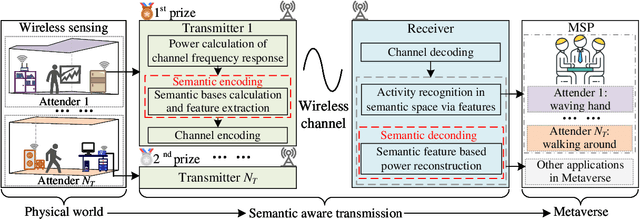
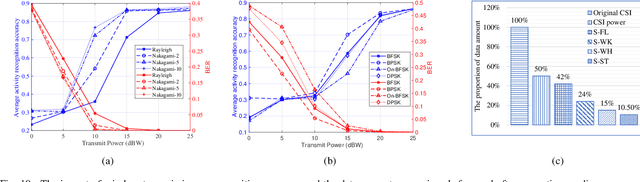
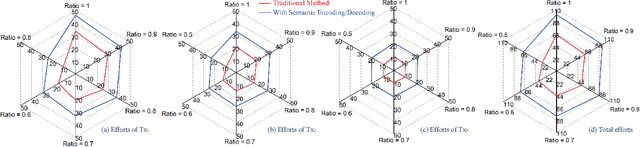
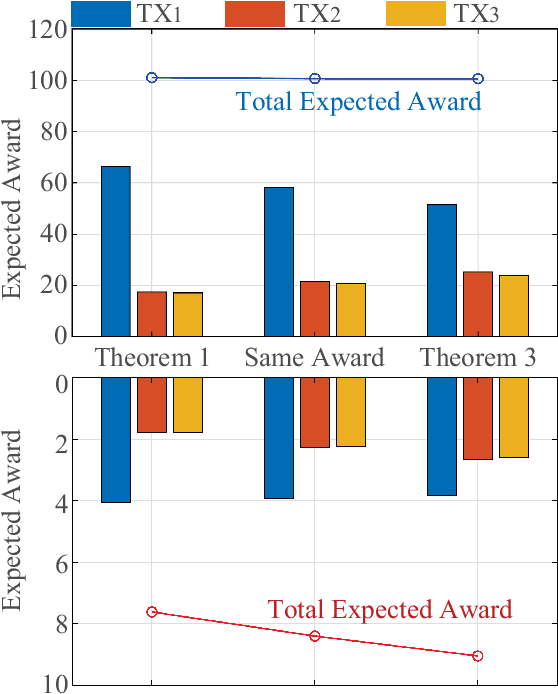
With the advancement of network and computer technologies, virtual cyberspace keeps evolving, and Metaverse is the main representative. As an irreplaceable technology that supports Metaverse, the sensing information transmission from the physical world to Metaverse is vital. Inspired by emerging semantic communication, in this paper, we propose a semantic transmission framework for transmitting sensing information from the physical world to Metaverse. Leveraging the in-depth understanding of sensing information, we define the semantic bases, through which the semantic encoding of sensing data is achieved for the first time. Consequently, the amount of sensing data that needs to be transmitted is dramatically reduced. Unlike conventional methods that undergo data degradation and require data recovery, our approach achieves the sensing goal without data recovery while maintaining performance. To further improve Metaverse service quality, we introduce contest theory to create an incentive mechanism that motivates users to upload data more frequently. Experimental results show that the average data amount after semantic encoding is reduced to about 27.87% of that before encoding, while ensuring the sensing performance. Additionally, the proposed contest theoretic based incentive mechanism increases the sum of data uploading frequency by 27.47% compared to the uniform award scheme.
Improving Code Example Recommendations on Informal Documentation Using BERT and Query-Aware LSH: A Comparative Study
May 04, 2023
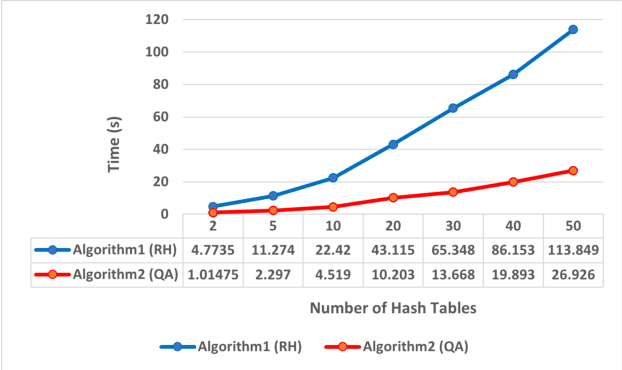
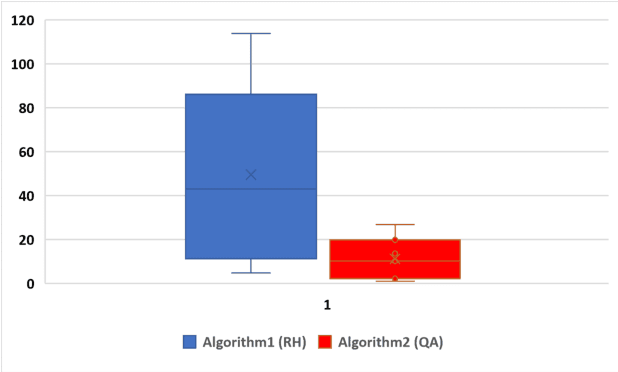
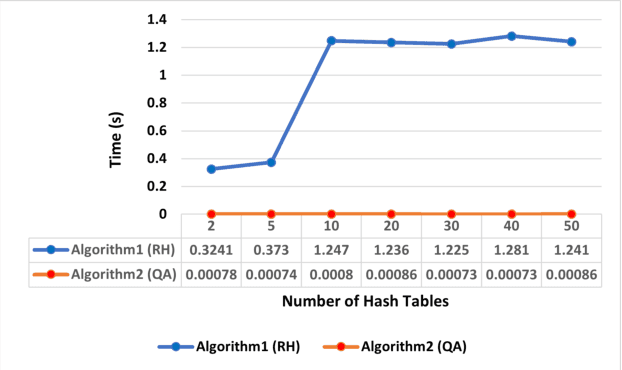
The study of code example recommendation has been conducted extensively in the past and recently in order to assist developers in their software development tasks. This is because developers often spend significant time searching for relevant code examples on the internet, utilizing open-source projects and informal documentation. For finding useful code examples, informal documentation, such as Stack Overflow discussions and forums, can be invaluable. We have focused our research on Stack Overflow, which is a popular resource for discussing different topics among software developers. For increasing the quality of the recommended code examples, we have collected and recommended the best code examples in the Java programming language. We have utilized BERT in our approach, which is a Large Language Model (LLM) for text representation that can effectively extract semantic information from textual data. Our first step involved using BERT to convert code examples into numerical vectors. Subsequently, we applied LSH to identify Approximate Nearest Neighbors (ANN). Our research involved the implementation of two variants of this approach, namely the Random Hyperplane-based LSH and the Query-Aware LSH. Our study compared two algorithms using four parameters: HitRate, Mean Reciprocal Rank (MRR), Average Execution Time, and Relevance. The results of our analysis revealed that the Query- Aware (QA) approach outperformed the Random Hyperplane-based (RH) approach in terms of HitRate. Specifically, the QA approach achieved a HitRate improvement of 20% to 35% for query pairs compared to the RH approach. Creating hashing tables and assigning data samples to buckets using the QA approach is at least four times faster than the RH approach. The QA approach returns code examples within milliseconds, while it takes several seconds (sec) for the RH approach to recommend code examples.
From Words to Code: Harnessing Data for Program Synthesis from Natural Language
May 03, 2023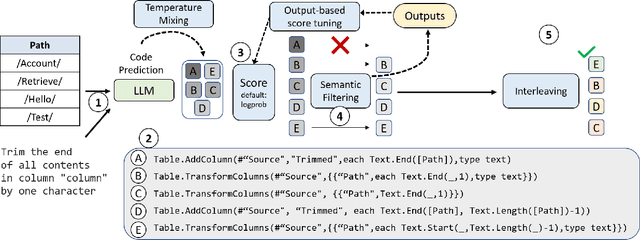
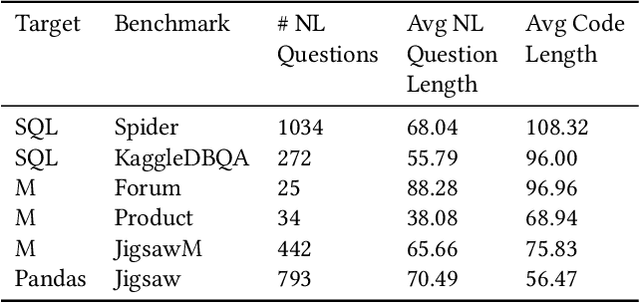
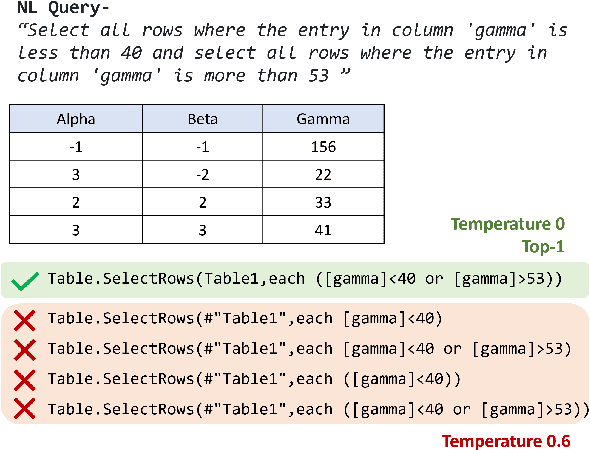
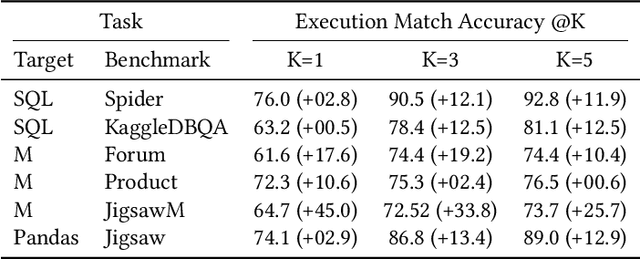
Creating programs to correctly manipulate data is a difficult task, as the underlying programming languages and APIs can be challenging to learn for many users who are not skilled programmers. Large language models (LLMs) demonstrate remarkable potential for generating code from natural language, but in the data manipulation domain, apart from the natural language (NL) description of the intended task, we also have the dataset on which the task is to be performed, or the "data context". Existing approaches have utilized data context in a limited way by simply adding relevant information from the input data into the prompts sent to the LLM. In this work, we utilize the available input data to execute the candidate programs generated by the LLMs and gather their outputs. We introduce semantic reranking, a technique to rerank the programs generated by LLMs based on three signals coming the program outputs: (a) semantic filtering and well-formedness based score tuning: do programs even generate well-formed outputs, (b) semantic interleaving: how do the outputs from different candidates compare to each other, and (c) output-based score tuning: how do the outputs compare to outputs predicted for the same task. We provide theoretical justification for semantic interleaving. We also introduce temperature mixing, where we combine samples generated by LLMs using both high and low temperatures. We extensively evaluate our approach in three domains, namely databases (SQL), data science (Pandas) and business intelligence (Excel's Power Query M) on a variety of new and existing benchmarks. We observe substantial gains across domains, with improvements of up to 45% in top-1 accuracy and 34% in top-3 accuracy.
Ground-to-UAV Integrated Network: Low Latency Communication over Interference Channel
May 03, 2023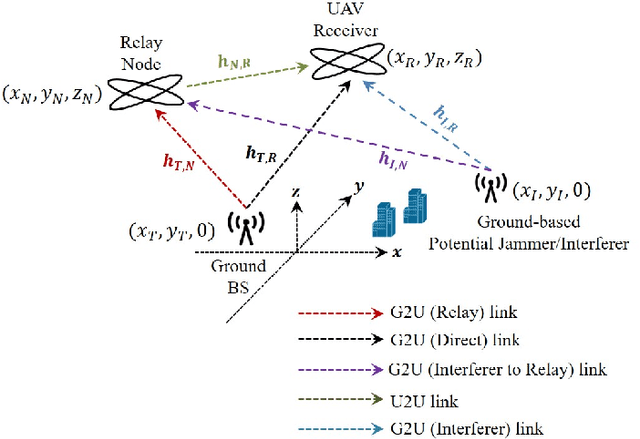
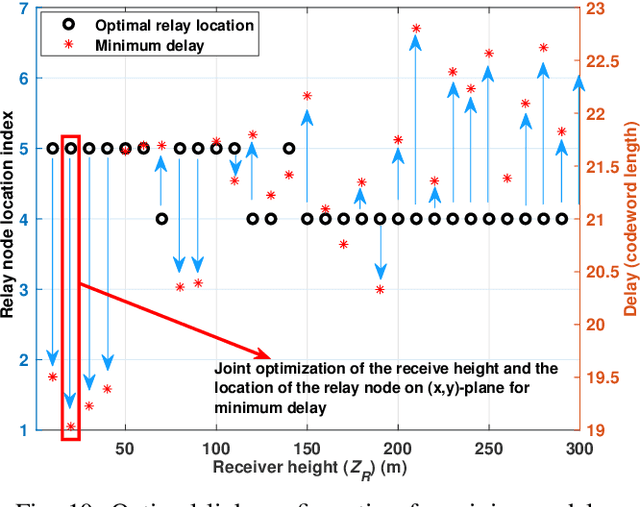
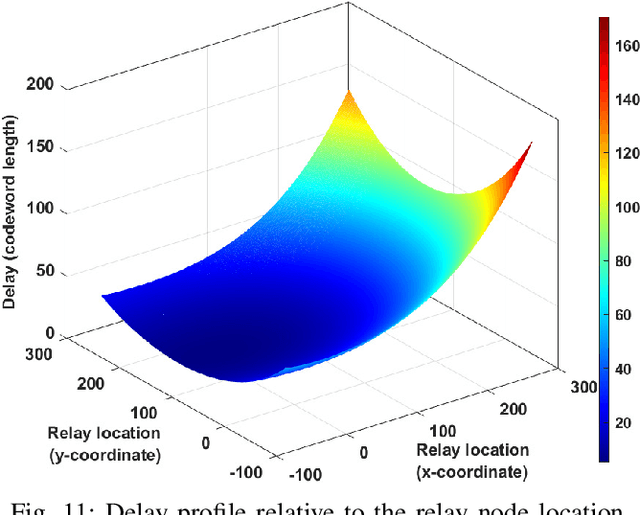
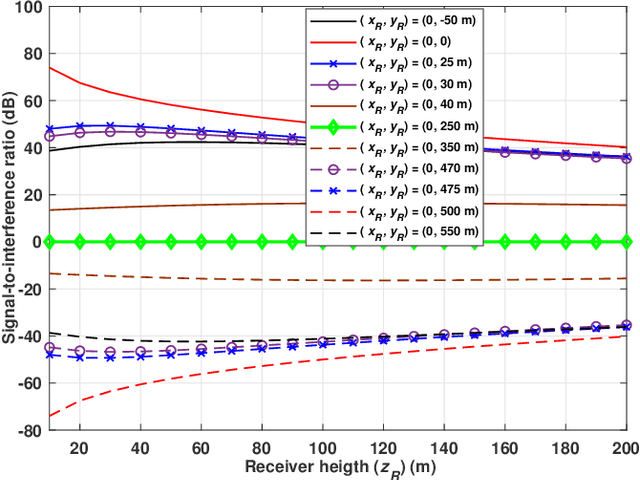
We present a novel and first-of-its-kind information-theoretic framework for the key design consideration and implementation of a ground-to-UAV (G2U) communication network to minimize end-to-end transmission delay in the presence of interference. The proposed framework is useful as it describes the minimum transmission latency for an uplink ground-to-UAV communication must satisfy while achieving a given level of reliability. To characterize the transmission delay, we utilize Fano's inequality and derive the tight upper bound for the capacity for the G2U uplink channel in the presence of interference, noise, and potential jamming. Subsequently, given the reliability constraint, the error exponent is obtained for the given channel. Furthermore, a relay UAV in the dual-hop relay mode, with amplify-and-forward (AF) protocol, is considered, for which we jointly obtain the optimal positions of the relay and the receiver UAVs in the presence of interference. Interestingly, in our study, we find that for both the point-to-point and relayed links, increasing the transmit power may not always be an optimal solution for delay minimization problems. Moreover, we prove that there exists an optimal height that minimizes the end-to-end transmission delay in the presence of interference. The proposed framework can be used in practice by a network controller as a system parameters selection criteria, where among a set of parameters, the parameters leading to the lowest transmission latency can be incorporated into the transmission. The based analysis further set the baseline assessment when applying Command and Control (C2) standards to mission-critical G2U and UAV-to-UAV(U2U) services.
H2CGL: Modeling Dynamics of Citation Network for Impact Prediction
Apr 16, 2023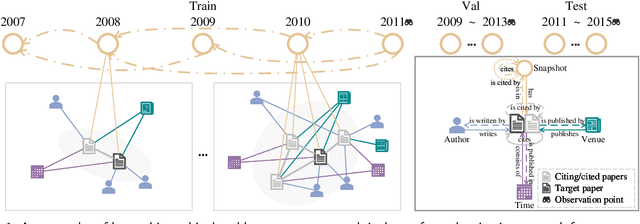
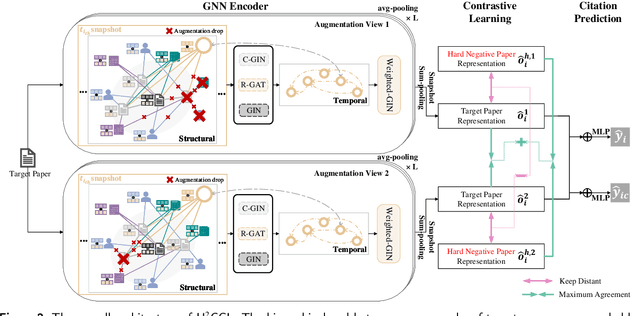

The potential impact of a paper is often quantified by how many citations it will receive. However, most commonly used models may underestimate the influence of newly published papers over time, and fail to encapsulate this dynamics of citation network into the graph. In this study, we construct hierarchical and heterogeneous graphs for target papers with an annual perspective. The constructed graphs can record the annual dynamics of target papers' scientific context information. Then, a novel graph neural network, Hierarchical and Heterogeneous Contrastive Graph Learning Model (H2CGL), is proposed to incorporate heterogeneity and dynamics of the citation network. H2CGL separately aggregates the heterogeneous information for each year and prioritizes the highly-cited papers and relationships among references, citations, and the target paper. It then employs a weighted GIN to capture dynamics between heterogeneous subgraphs over years. Moreover, it leverages contrastive learning to make the graph representations more sensitive to potential citations. Particularly, co-cited or co-citing papers of the target paper with large citation gap are taken as hard negative samples, while randomly dropping low-cited papers could generate positive samples. Extensive experimental results on two scholarly datasets demonstrate that the proposed H2CGL significantly outperforms a series of baseline approaches for both previously and freshly published papers. Additional analyses highlight the significance of the proposed modules. Our codes and settings have been released on Github (https://github.com/ECNU-Text-Computing/H2CGL)
Form-NLU: Dataset for the Form Language Understanding
Apr 05, 2023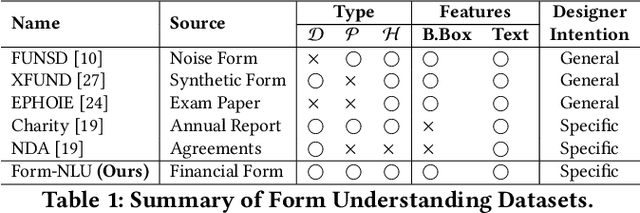
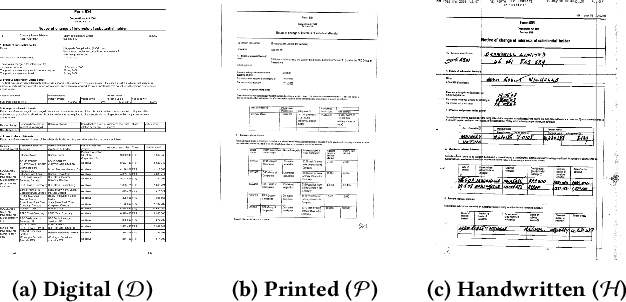

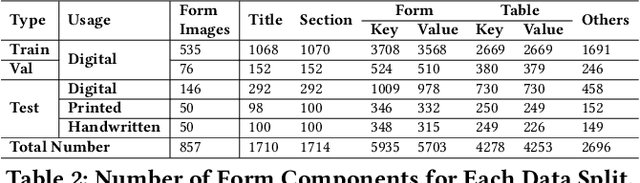
Compared to general document analysis tasks, form document structure understanding and retrieval are challenging. Form documents are typically made by two types of authors; A form designer, who develops the form structure and keys, and a form user, who fills out form values based on the provided keys. Hence, the form values may not be aligned with the form designer's intention (structure and keys) if a form user gets confused. In this paper, we introduce Form-NLU, the first novel dataset for form structure understanding and its key and value information extraction, interpreting the form designer's intent and the alignment of user-written value on it. It consists of 857 form images, 6k form keys and values, and 4k table keys and values. Our dataset also includes three form types: digital, printed, and handwritten, which cover diverse form appearances and layouts. We propose a robust positional and logical relation-based form key-value information extraction framework. Using this dataset, Form-NLU, we first examine strong object detection models for the form layout understanding, then evaluate the key information extraction task on the dataset, providing fine-grained results for different types of forms and keys. Furthermore, we examine it with the off-the-shelf pdf layout extraction tool and prove its feasibility in real-world cases.
Shape-Erased Feature Learning for Visible-Infrared Person Re-Identification
Apr 09, 2023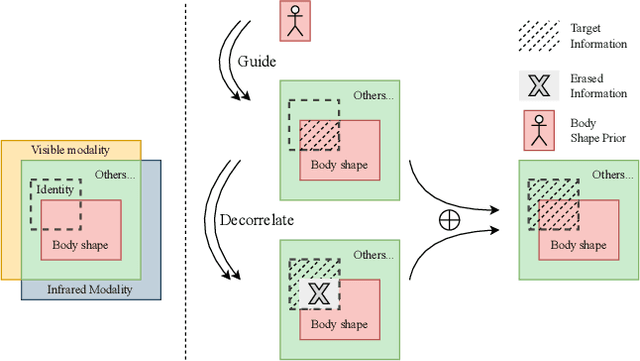
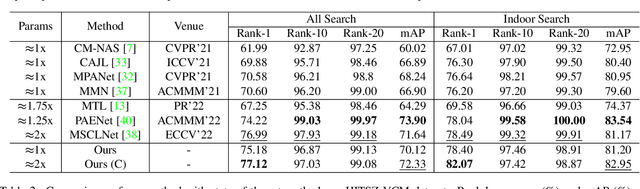
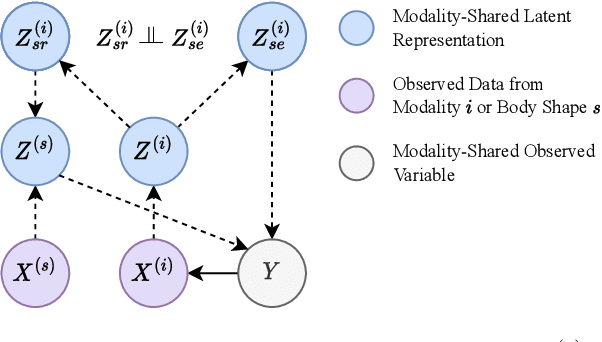
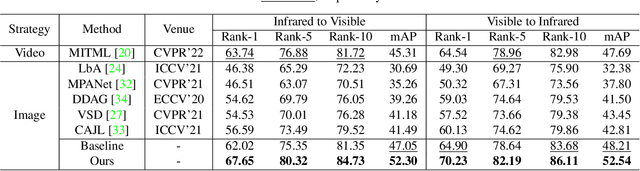
Due to the modality gap between visible and infrared images with high visual ambiguity, learning \textbf{diverse} modality-shared semantic concepts for visible-infrared person re-identification (VI-ReID) remains a challenging problem. Body shape is one of the significant modality-shared cues for VI-ReID. To dig more diverse modality-shared cues, we expect that erasing body-shape-related semantic concepts in the learned features can force the ReID model to extract more and other modality-shared features for identification. To this end, we propose shape-erased feature learning paradigm that decorrelates modality-shared features in two orthogonal subspaces. Jointly learning shape-related feature in one subspace and shape-erased features in the orthogonal complement achieves a conditional mutual information maximization between shape-erased feature and identity discarding body shape information, thus enhancing the diversity of the learned representation explicitly. Extensive experiments on SYSU-MM01, RegDB, and HITSZ-VCM datasets demonstrate the effectiveness of our method.
Using Multiple RDF Knowledge Graphs for Enriching ChatGPT Responses
Apr 12, 2023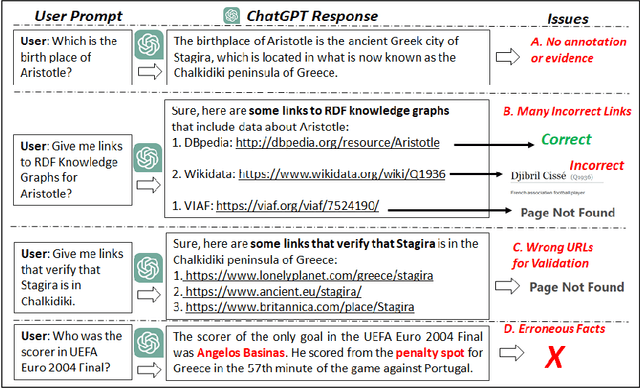
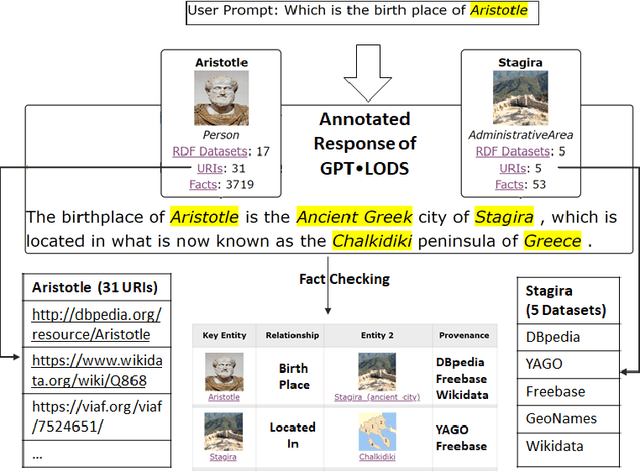
There is a recent trend for using the novel Artificial Intelligence ChatGPT chatbox, which provides detailed responses and articulate answers across many domains of knowledge. However, in many cases it returns plausible-sounding but incorrect or inaccurate responses, whereas it does not provide evidence. Therefore, any user has to further search for checking the accuracy of the answer or/and for finding more information about the entities of the response. At the same time there is a high proliferation of RDF Knowledge Graphs (KGs) over any real domain, that offer high quality structured data. For enabling the combination of ChatGPT and RDF KGs, we present a research prototype, called GPToLODS, which is able to enrich any ChatGPT response with more information from hundreds of RDF KGs. In particular, it identifies and annotates each entity of the response with statistics and hyperlinks to LODsyndesis KG (which contains integrated data from 400 RDF KGs and over 412 million entities). In this way, it is feasible to enrich the content of entities and to perform fact checking and validation for the facts of the response at real time.