 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exact recovery for the non-uniform Hypergraph Stochastic Block Model
Apr 25, 2023
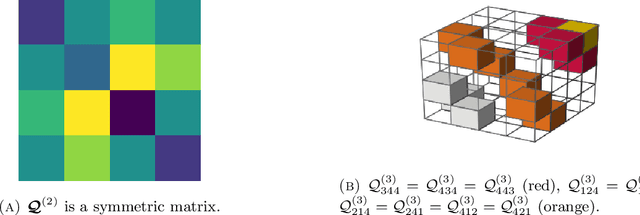
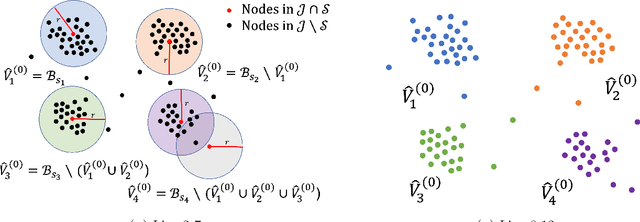
Consider the community detection problem in random hypergraphs under the non-uniform hypergraph stochastic block model (HSBM), where each hyperedge appears independently with some given probability depending only on the labels of its vertices. We establish, for the first time in the literature, a sharp threshold for exact recovery under this non-uniform case, subject to minor constraints; in particular, we consider the model with $K$ classes as well as the symmetric binary model ($K=2$). One crucial point here is that by aggregating information from all the uniform layers, we may obtain exact recovery even in cases when this may appear impossible if each layer were considered alone. Two efficient algorithms that successfully achieve exact recovery above the threshold are provided. The theoretical analysis of our algorithms relies on the concentration and regularization of the adjacency matrix for non-uniform random hypergraphs, which could be of independent interest. We also address some open problems regarding parameter knowledge and estimation.
User-Centric Federated Learning: Trading off Wireless Resources for Personalization
Apr 25, 2023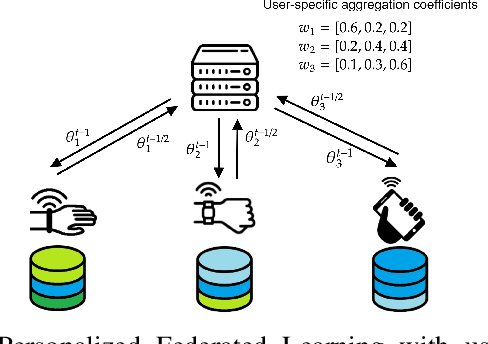
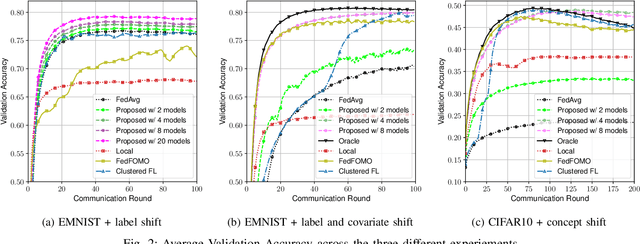
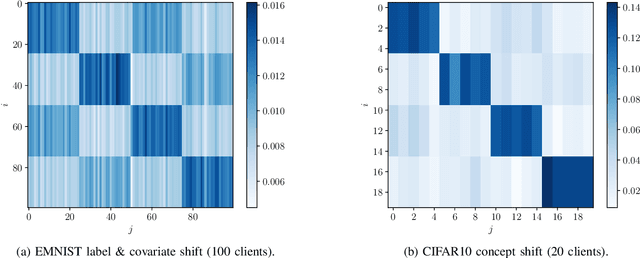
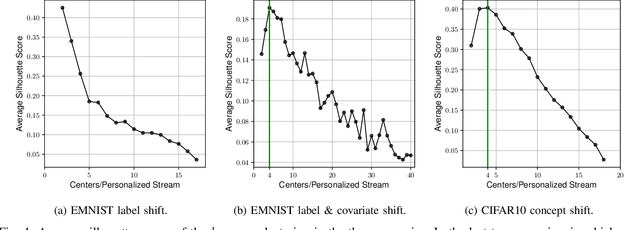
Statistical heterogeneity across clients in a Federated Learning (FL) system increases the algorithm convergence time and reduces the generalization performance, resulting in a large communication overhead in return for a poor model. To tackle the above problems without violating the privacy constraints that FL imposes, personalized FL methods have to couple statistically similar clients without directly accessing their data in order to guarantee a privacy-preserving transfer. In this work, we design user-centric aggregation rules at the parameter server (PS) that are based on readily available gradient information and are capable of producing personalized models for each FL client. The proposed aggregation rules are inspired by an upper bound of the weighted aggregate empirical risk minimizer. Secondly, we derive a communication-efficient variant based on user clustering which greatly enhances its applicability to communication-constrained systems. Our algorithm outperforms popular personalized FL baselines in terms of average accuracy, worst node performance, and training communication overhead.
SwinFSR: Stereo Image Super-Resolution using SwinIR and Frequency Domain Knowledge
Apr 25, 2023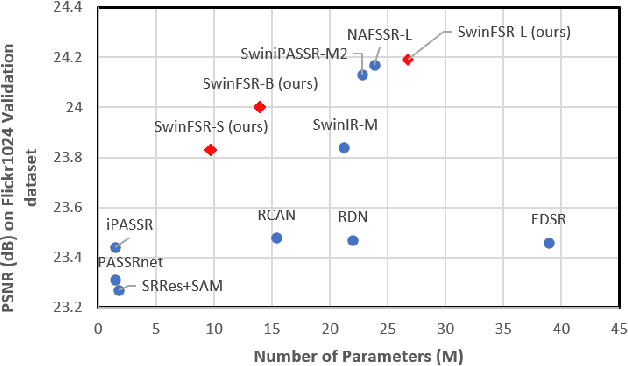
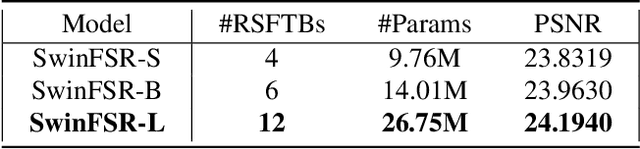
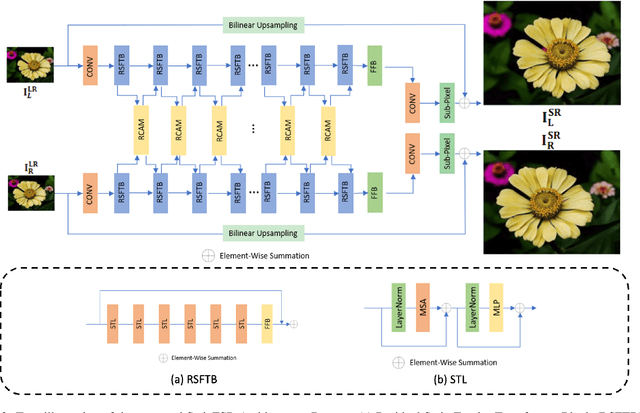
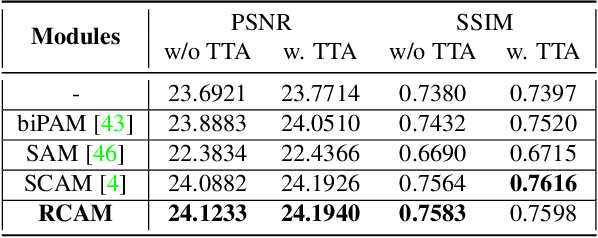
Stereo Image Super-Resolution (stereoSR) has attracted significant attention in recent years due to the extensive deployment of dual cameras in mobile phones, autonomous vehicles and robots. In this work, we propose a new StereoSR method, named SwinFSR, based on an extension of SwinIR, originally designed for single image restoration, and the frequency domain knowledge obtained by the Fast Fourier Convolution (FFC). Specifically, to effectively gather global information, we modify the Residual Swin Transformer blocks (RSTBs) in SwinIR by explicitly incorporating the frequency domain knowledge using the FFC and employing the resulting residual Swin Fourier Transformer blocks (RSFTBs) for feature extraction. Besides, for the efficient and accurate fusion of stereo views, we propose a new cross-attention module referred to as RCAM, which achieves highly competitive performance while requiring less computational cost than the state-of-the-art cross-attention modules. Extensive experimental results and ablation studies demonstrate the effectiveness and efficiency of our proposed SwinFSR.
IMP: Iterative Matching and Pose Estimation with Adaptive Pooling
Apr 28, 2023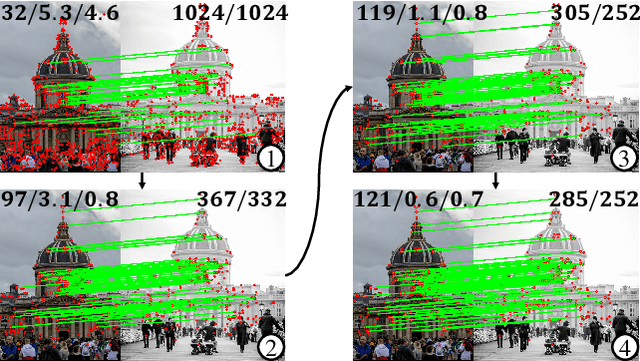
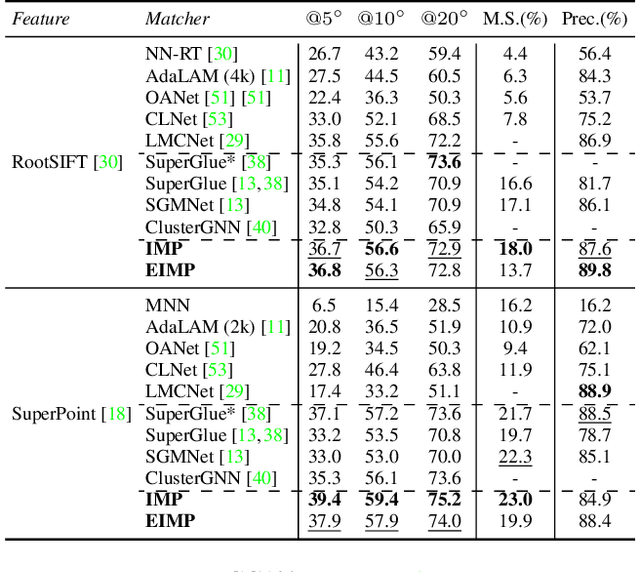
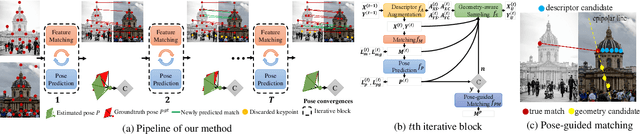
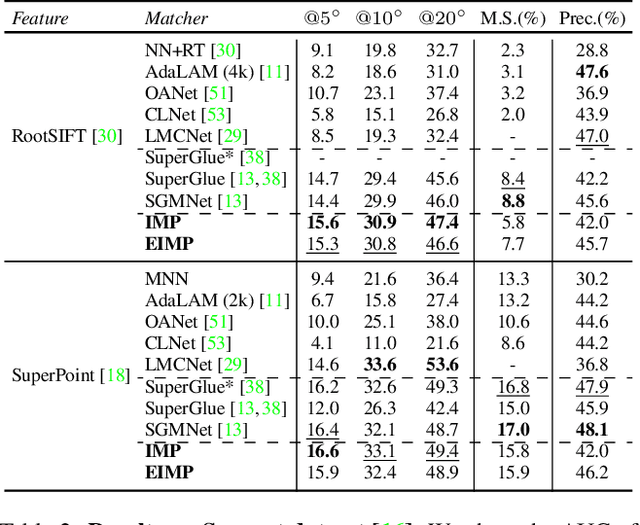
Previous methods solve feature matching and pose estimation using a two-stage process by first finding matches and then estimating the pose. As they ignore the geometric relationships between the two tasks, they focus on either improving the quality of matches or filtering potential outliers, leading to limited efficiency or accuracy. In contrast, we propose an iterative matching and pose estimation framework (IMP) leveraging the geometric connections between the two tasks: a few good matches are enough for a roughly accurate pose estimation; a roughly accurate pose can be used to guide the matching by providing geometric constraints. To this end, we implement a geometry-aware recurrent attention-based module which jointly outputs sparse matches and camera poses. Specifically, for each iteration, we first implicitly embed geometric information into the module via a pose-consistency loss, allowing it to predict geometry-aware matches progressively. Second, we introduce an \textbf{e}fficient IMP, called EIMP, to dynamically discard keypoints without potential matches, avoiding redundant updating and significantly reducing the quadratic time complexity of attention computation in transformers. Experiments on YFCC100m, Scannet, and Aachen Day-Night datasets demonstrate that the proposed method outperforms previous approaches in terms of accuracy and efficiency.
A New Class of Explanations for Classifiers with Non-Binary Features
Apr 28, 2023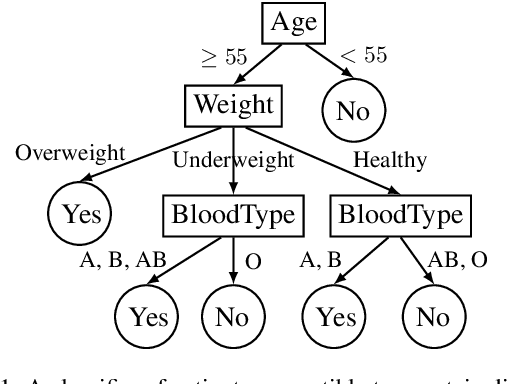
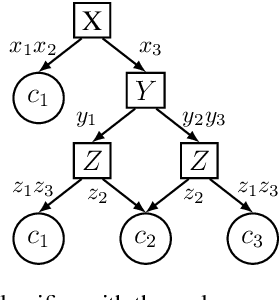
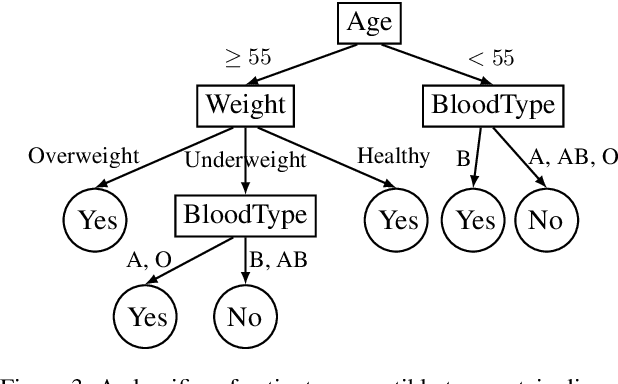
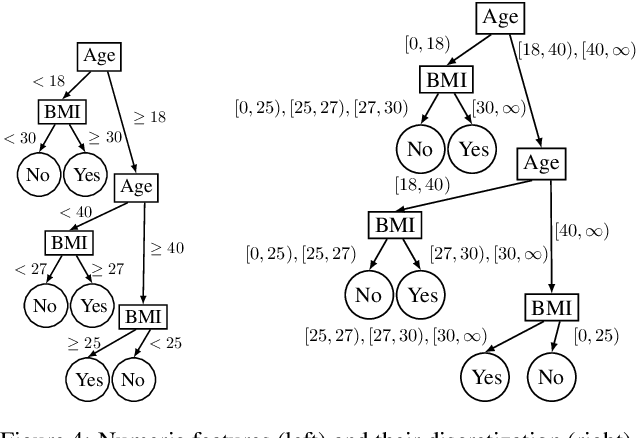
Two types of explanations have received significant attention in the literature recently when analyzing the decisions made by classifiers. The first type explains why a decision was made and is known as a sufficient reason for the decision, also an abductive or PI-explanation. The second type explains why some other decision was not made and is known as a necessary reason for the decision, also a contrastive or counterfactual explanation. These explanations were defined for classifiers with binary, discrete and, in some cases, continuous features. We show that these explanations can be significantly improved in the presence of non-binary features, leading to a new class of explanations that relay more information about decisions and the underlying classifiers. Necessary and sufficient reasons were also shown to be the prime implicates and implicants of the complete reason for a decision, which can be obtained using a quantification operator. We show that our improved notions of necessary and sufficient reasons are also prime implicates and implicants but for an improved notion of complete reason obtained by a new quantification operator that we define and study in this paper.
Enhancing Supply Chain Resilience: A Machine Learning Approach for Predicting Product Availability Dates Under Disruption
Apr 28, 2023The COVID 19 pandemic and ongoing political and regional conflicts have a highly detrimental impact on the global supply chain, causing significant delays in logistics operations and international shipments. One of the most pressing concerns is the uncertainty surrounding the availability dates of products, which is critical information for companies to generate effective logistics and shipment plans. Therefore, accurately predicting availability dates plays a pivotal role in executing successful logistics operations, ultimately minimizing total transportation and inventory costs. We investigate the prediction of product availability dates for General Electric (GE) Gas Power's inbound shipments for gas and steam turbine service and manufacturing operations, utilizing both numerical and categorical features. We evaluate several regression models, including Simple Regression, Lasso Regression, Ridge Regression, Elastic Net, Random Forest (RF), Gradient Boosting Machine (GBM), and Neural Network models. Based on real world data, our experiments demonstrate that the tree based algorithms (i.e., RF and GBM) provide the best generalization error and outperforms all other regression models tested. We anticipate that our prediction models will assist companies in managing supply chain disruptions and reducing supply chain risks on a broader scale.
Classification of news spreading barriers
Apr 10, 2023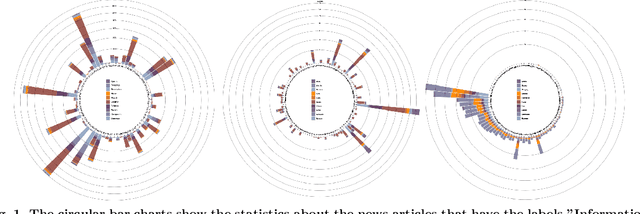
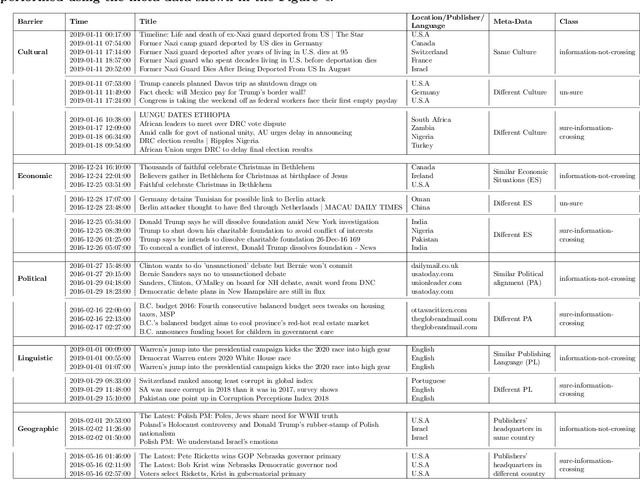
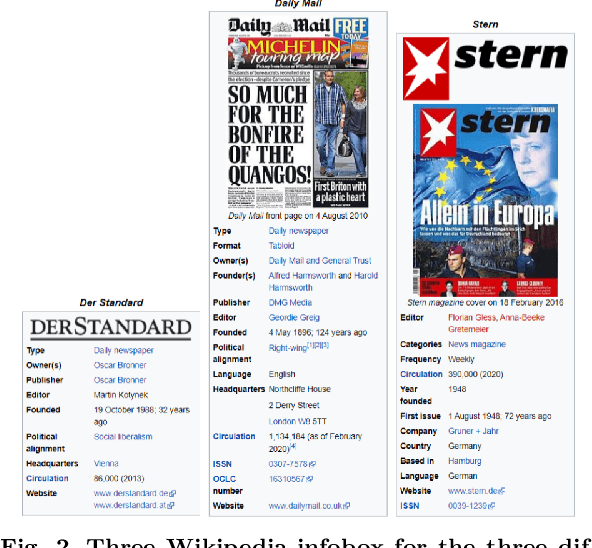
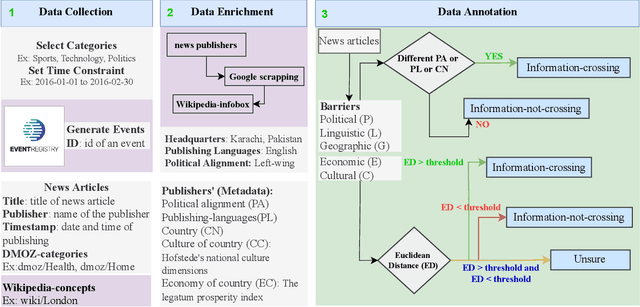
News media is one of the most effective mechanisms for spreading information internationally, and many events from different areas are internationally relevant. However, news coverage for some news events is limited to a specific geographical region because of information spreading barriers, which can be political, geographical, economic, cultural, or linguistic. In this paper, we propose an approach to barrier classification where we infer the semantics of news articles through Wikipedia concepts. To that end, we collected news articles and annotated them for different kinds of barriers using the metadata of news publishers. Then, we utilize the Wikipedia concepts along with the body text of news articles as features to infer the news-spreading barriers. We compare our approach to the classical text classification methods, deep learning, and transformer-based methods. The results show that the proposed approach using Wikipedia concepts based semantic knowledge offers better performance than the usual for classifying the news-spreading barriers.
Dark-field and directional dark-field on low coherence X-ray sources with random mask modulations: validation with SAXS anisotropy measurements
Apr 24, 2023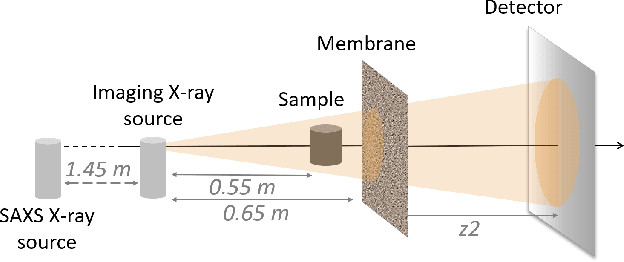
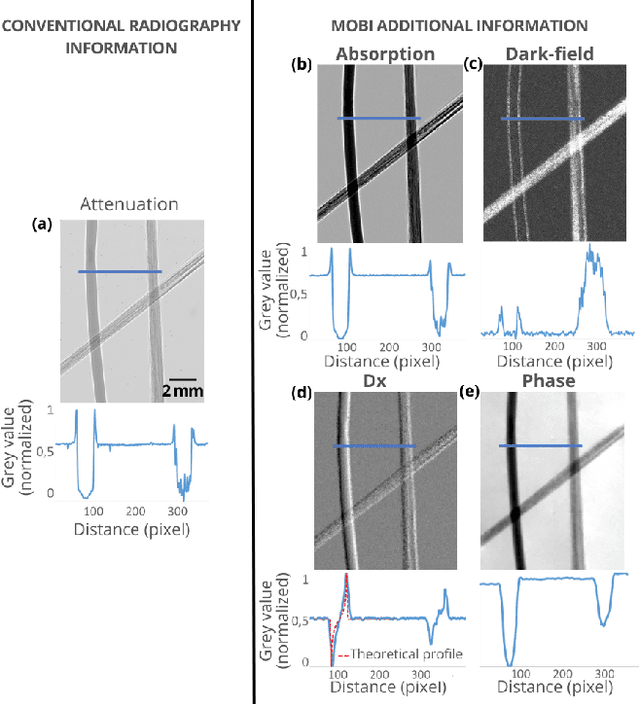
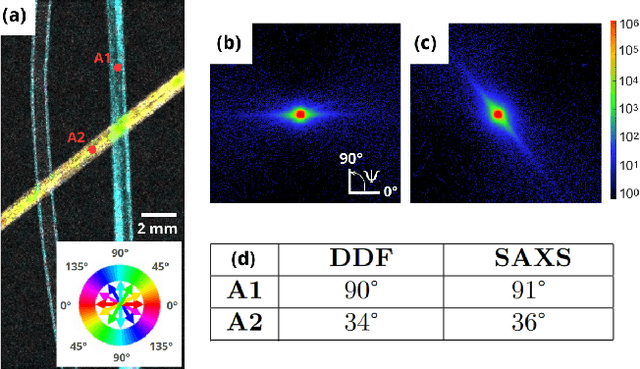

Phase Contrast Imaging (PCI), Dark-Field (DF) and Directional Dark-Field (DDF) imaging are recent X-ray imaging modalities that have demonstrated their interest by providing access to information and contrasts different from those provided by conventional absorption X-ray imaging. However, access to these two types of images is currently limited because the acquisitions require the use of coherent sources such as synchrotron radiation or complicated optical setups to exploit the coherence requirements. This work demonstrates the possibility of efficiently performing phase contrast, dark-field and directional dark-field imaging on a low-coherence laboratory system equipped with a conventional X-ray tube, using a simple, fast and robust single-mask technique. The transfer to a low spatial coherence laboratory system was made possible by using random modulation based imaging (MoBI) and extending the low coherence system algorithm to retrieve dark-field and directional dark-field.
A Latent Space Theory for Emergent Abilities in Large Language Models
Apr 24, 2023
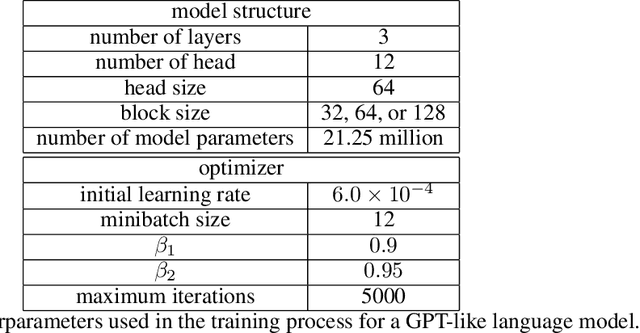
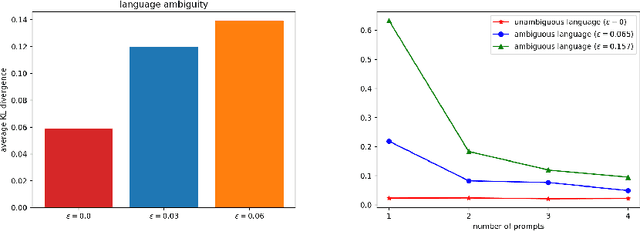
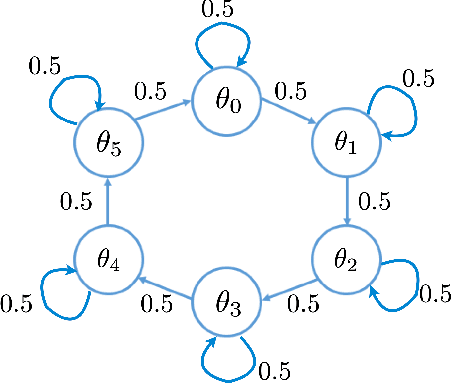
Languages are not created randomly but rather to communicate information. There is a strong association between languages and their underlying meanings, resulting in a sparse joint distribution that is heavily peaked according to their correlations. Moreover, these peak values happen to match with the marginal distribution of languages due to the sparsity. With the advent of LLMs trained on big data and large models, we can now precisely assess the marginal distribution of languages, providing a convenient means of exploring the sparse structures in the joint distribution for effective inferences. In this paper, we categorize languages as either unambiguous or {\epsilon}-ambiguous and present quantitative results to demonstrate that the emergent abilities of LLMs, such as language understanding, in-context learning, chain-of-thought prompting, and effective instruction fine-tuning, can all be attributed to Bayesian inference on the sparse joint distribution of languages.
Development of a Trust-Aware User Simulator for Statistical Proactive Dialog Modeling in Human-AI Teams
Apr 24, 2023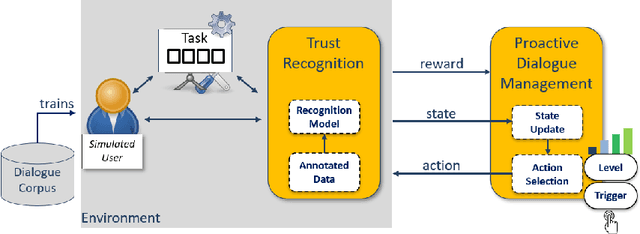
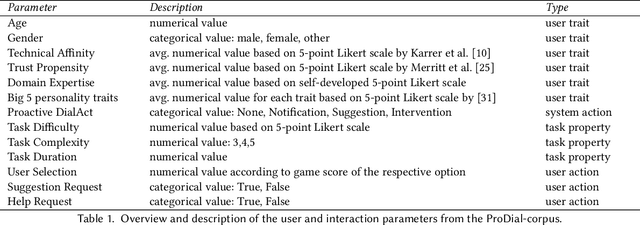
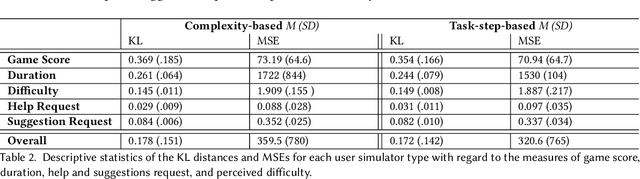
The concept of a Human-AI team has gained increasing attention in recent years. For effective collaboration between humans and AI teammates, proactivity is crucial for close coordination and effective communication. However, the design of adequate proactivity for AI-based systems to support humans is still an open question and a challenging topic. In this paper, we present the development of a corpus-based user simulator for training and testing proactive dialog policies. The simulator incorporates informed knowledge about proactive dialog and its effect on user trust and simulates user behavior and personal information, including socio-demographic features and personality traits. Two different simulation approaches were compared, and a task-step-based approach yielded better overall results due to enhanced modeling of sequential dependencies. This research presents a promising avenue for exploring and evaluating appropriate proactive strategies in a dialog game setting for improving Human-AI teams.