 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
FlightBERT++: A Non-autoregressive Multi-Horizon Flight Trajectory Prediction Framework
May 02, 2023
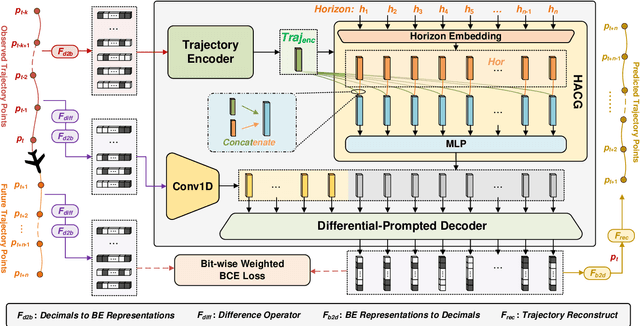
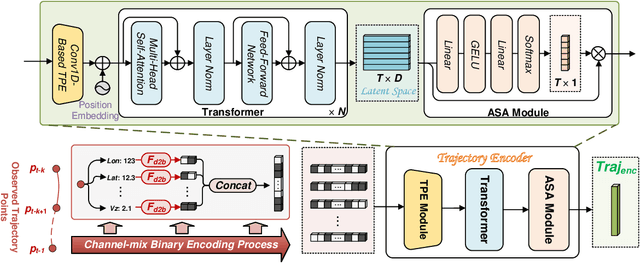
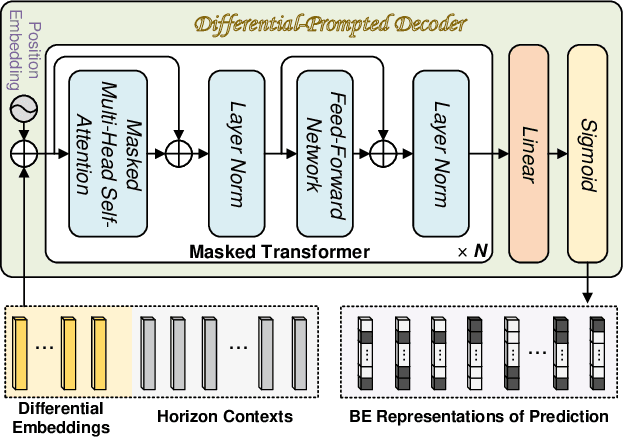
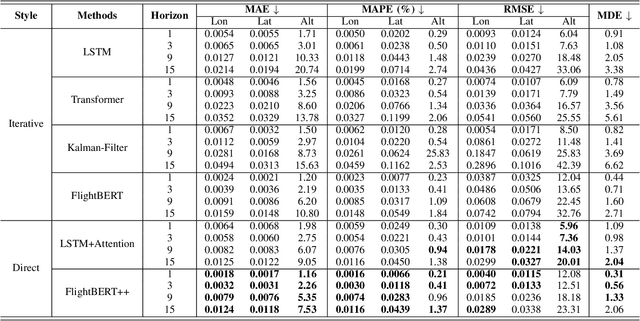
Flight Trajectory Prediction (FTP) is an essential task in Air Traffic Control (ATC), which can assist air traffic controllers to manage airspace more safely and efficiently. Existing approaches generally perform multi-horizon FTP tasks in an autoregressive manner, which is prone to suffer from error accumulation and low-efficiency problems. In this paper, a novel framework, called FlightBERT++, is proposed to i) forecast multi-horizon flight trajectories directly in a non-autoregressive way, and ii) improved the limitation of the binary encoding (BE) representation in the FlightBERT framework. Specifically, the proposed framework is implemented by a generalized Encoder-Decoder architecture, in which the encoder learns the temporal-spatial patterns from historical observations and the decoder predicts the flight status for the future time steps. Compared to conventional architecture, an extra horizon-aware contexts generator (HACG) is dedicatedly designed to consider the prior horizon information that enables us to perform multi-horizon non-autoregressive prediction. Additionally, a differential prediction strategy is designed by well considering both the stationarity of the differential sequence and the high-bits errors of the BE representation. Moreover, the Bit-wise Weighted Binary Cross Entropy loss function is proposed to optimize the proposed framework that can further constrain the high-bits errors of the predictions. Finally, the proposed framework is validated on a real-world flight trajectory dataset. The experimental results show that the proposed framework outperformed the competitive baselines.
Dynamic Transfer Learning across Graphs
May 02, 2023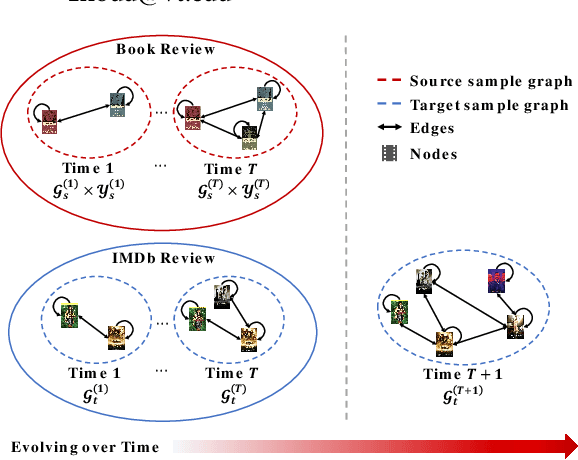

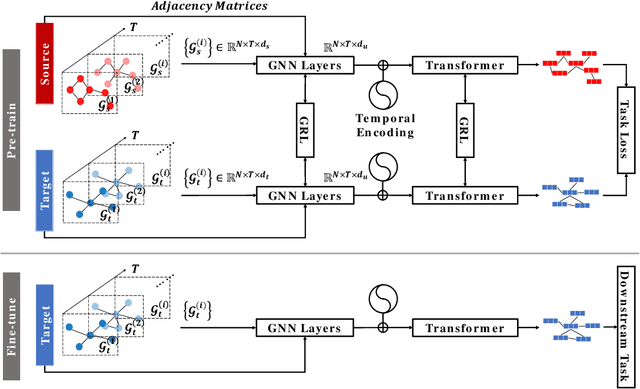
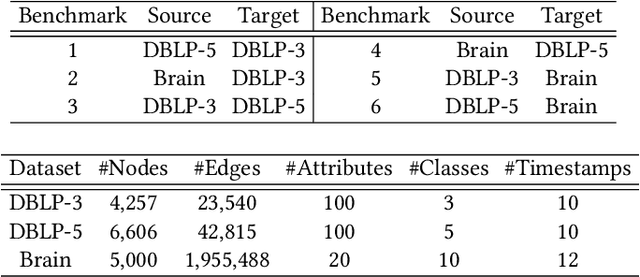
Transferring knowledge across graphs plays a pivotal role in many high-stake domains, ranging from transportation networks to e-commerce networks, from neuroscience to finance. To date, the vast majority of existing works assume both source and target domains are sampled from a universal and stationary distribution. However, many real-world systems are intrinsically dynamic, where the underlying domains are evolving over time. To bridge the gap, we propose to shift the problem to the dynamic setting and ask: given the label-rich source graphs and the label-scarce target graphs observed in previous T timestamps, how can we effectively characterize the evolving domain discrepancy and optimize the generalization performance of the target domain at the incoming T+1 timestamp? To answer the question, for the first time, we propose a generalization bound under the setting of dynamic transfer learning across graphs, which implies the generalization performance is dominated by domain evolution and domain discrepancy between source and target domains. Inspired by the theoretical results, we propose a novel generic framework DyTrans to improve knowledge transferability across dynamic graphs. In particular, we start with a transformer-based temporal encoding module to model temporal information of the evolving domains; then, we further design a dynamic domain unification module to efficiently learn domain-invariant representations across the source and target domains. Finally, extensive experiments on various real-world datasets demonstrate the effectiveness of DyTrans in transferring knowledge from dynamic source domains to dynamic target domains.
Distributed Information-based Source Seeking
Sep 20, 2022

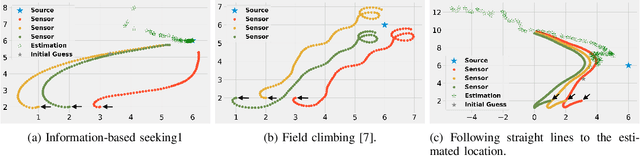
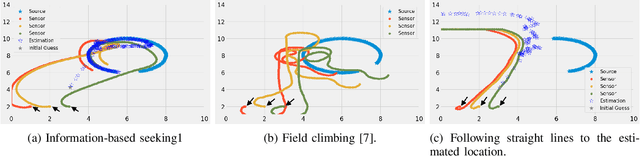
In this paper, we design an information-based multi-robot source seeking algorithm where a group of mobile sensors localizes and moves close to a single source using only local range-based measurements. In the algorithm, the mobile sensors perform source identification/localization to estimate the source location; meanwhile, they move to new locations to maximize the Fisher information about the source contained in the sensor measurements. In doing so, they improve the source location estimate and move closer to the source. Our algorithm is superior in convergence speed compared with traditional field climbing algorithms, is flexible in the measurement model and the choice of information metric, and is robust to measurement model errors. Moreover, we provide a fully distributed version of our algorithm, where each sensor decides its own actions and only shares information with its neighbors through a sparse communication network. We perform intensive simulation experiments to test our algorithms on large-scale systems and physical experiments on small ground vehicles with light sensors, demonstrating success in seeking a light source.
Improved Static Hand Gesture Classification on Deep Convolutional Neural Networks using Novel Sterile Training Technique
May 03, 2023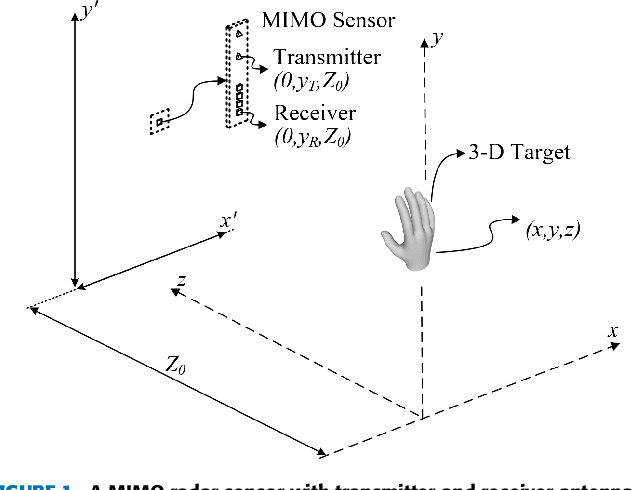

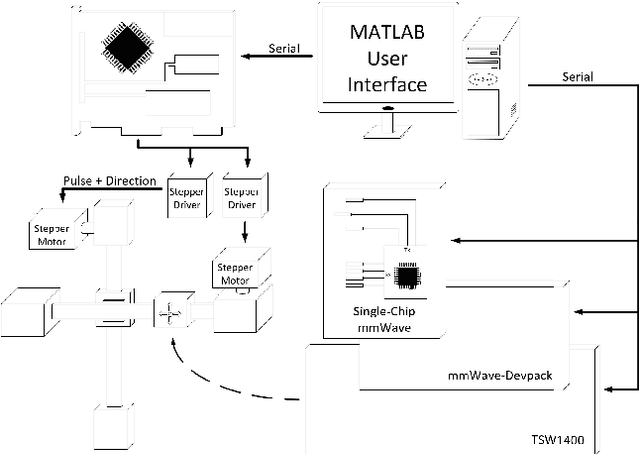

In this paper, we investigate novel data collection and training techniques towards improving classification accuracy of non-moving (static) hand gestures using a convolutional neural network (CNN) and frequency-modulated-continuous-wave (FMCW) millimeter-wave (mmWave) radars. Recently, non-contact hand pose and static gesture recognition have received considerable attention in many applications ranging from human-computer interaction (HCI), augmented/virtual reality (AR/VR), and even therapeutic range of motion for medical applications. While most current solutions rely on optical or depth cameras, these methods require ideal lighting and temperature conditions. mmWave radar devices have recently emerged as a promising alternative offering low-cost system-on-chip sensors whose output signals contain precise spatial information even in non-ideal imaging conditions. Additionally, deep convolutional neural networks have been employed extensively in image recognition by learning both feature extraction and classification simultaneously. However, little work has been done towards static gesture recognition using mmWave radars and CNNs due to the difficulty involved in extracting meaningful features from the radar return signal, and the results are inferior compared with dynamic gesture classification. This article presents an efficient data collection approach and a novel technique for deep CNN training by introducing ``sterile'' images which aid in distinguishing distinct features among the static gestures and subsequently improve the classification accuracy. Applying the proposed data collection and training methods yields an increase in classification rate of static hand gestures from $85\%$ to $93\%$ and $90\%$ to $95\%$ for range and range-angle profiles, respectively.
* Accepted to IEEE Access
Revisiting Table Detection Datasets for Visually Rich Documents
May 04, 2023
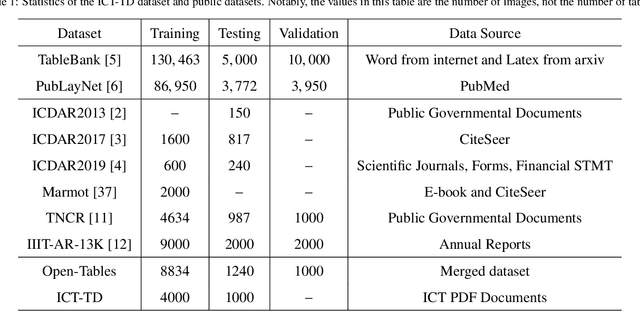
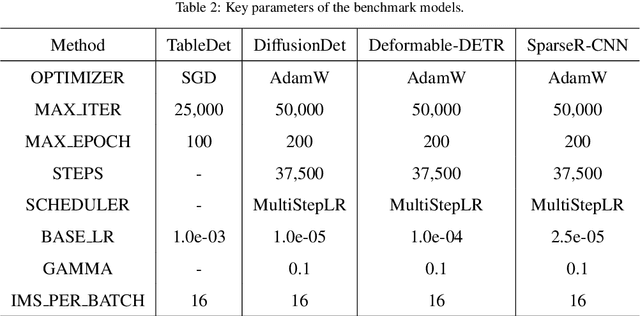
Table Detection has become a fundamental task for visually rich document understanding with the surging number of electronic documents. There have been some open datasets widely used in many studies. However, popular available datasets have some inherent limitations, including the noisy and inconsistent samples, and the limit number of training samples, and the limit number of data-sources. These limitations make these datasets unreliable to evaluate the model performance and cannot reflect the actual capacity of models. Therefore, in this paper, we revisit some open datasets with high quality of annotations, identify and clean the noise, and align the annotation definitions of these datasets to merge a larger dataset, termed with Open-Tables. Moreover, to enrich the data sources, we propose a new dataset, termed with ICT-TD, using the PDF files of Information and communication technologies (ICT) commodities which is a different domain containing unique samples that hardly appear in open datasets. To ensure the label quality of the dataset, we annotated the dataset manually following the guidance of a domain expert. The proposed dataset has a larger intra-variance and smaller inter-variance, making it more challenging and can be a sample of actual cases in the business context. We built strong baselines using various state-of-the-art object detection models and also built the baselines in the cross-domain setting. Our experimental results show that the domain difference among existing open datasets are small, even they have different data-sources. Our proposed Open-tables and ICT-TD are more suitable for the cross domain setting, and can provide more reliable evaluation for model because of their high quality and consistent annotations.
Modeling What-to-ask and How-to-ask for Answer-unaware Conversational Question Generation
May 04, 2023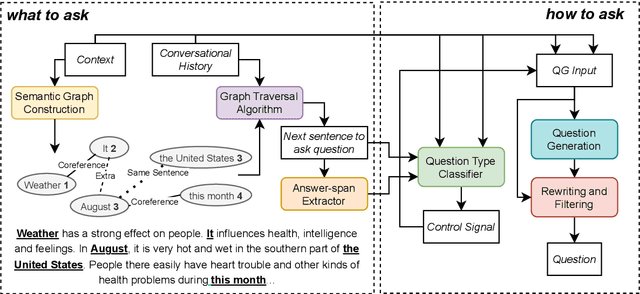

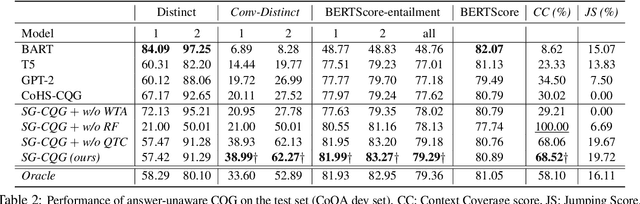
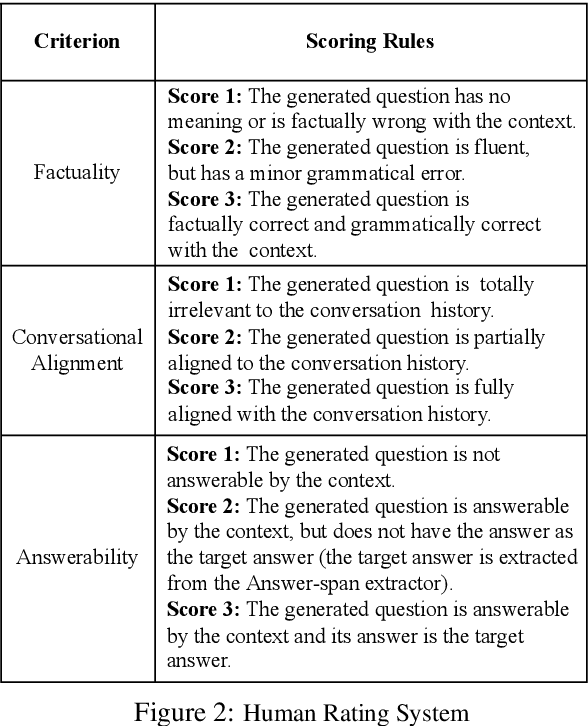
Conversational Question Generation (CQG) is a critical task for machines to assist humans in fulfilling their information needs through conversations. The task is generally cast into two different settings: answer-aware and answer-unaware. While the former facilitates the models by exposing the expected answer, the latter is more realistic and receiving growing attentions recently. What-to-ask and how-to-ask are the two main challenges in the answer-unaware setting. To address the first challenge, existing methods mainly select sequential sentences in context as the rationales. We argue that the conversation generated using such naive heuristics may not be natural enough as in reality, the interlocutors often talk about the relevant contents that are not necessarily sequential in context. Additionally, previous methods decide the type of question to be generated (boolean/span-based) implicitly. Modeling the question type explicitly is crucial as the answer, which hints the models to generate a boolean or span-based question, is unavailable. To this end, we present SG-CQG, a two-stage CQG framework. For the what-to-ask stage, a sentence is selected as the rationale from a semantic graph that we construct, and extract the answer span from it. For the how-to-ask stage, a classifier determines the target answer type of the question via two explicit control signals before generating and filtering. In addition, we propose Conv-Distinct, a novel evaluation metric for CQG, to evaluate the diversity of the generated conversation from a context. Compared with the existing answer-unaware CQG models, the proposed SG-CQG achieves state-of-the-art performance.
Transferability of coVariance Neural Networks and Application to Interpretable Brain Age Prediction using Anatomical Features
May 04, 2023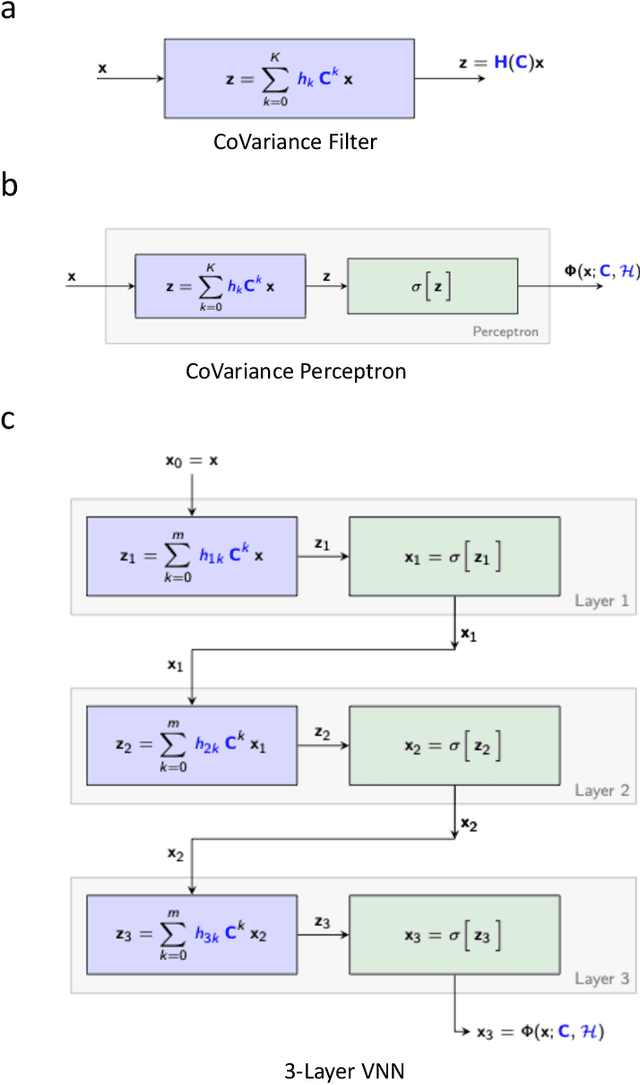
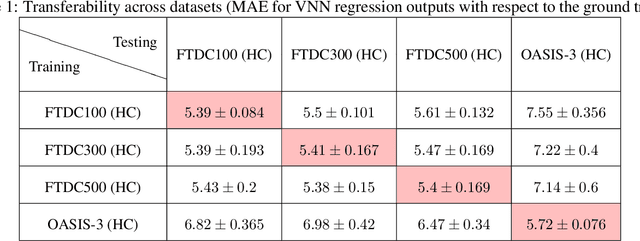
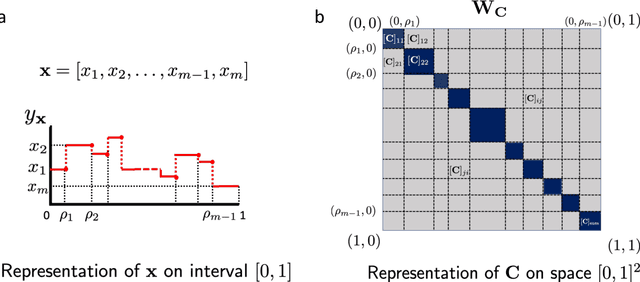
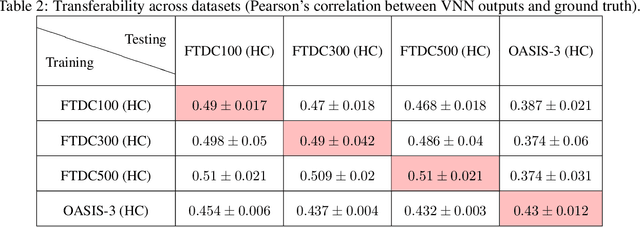
Graph convolutional networks (GCN) leverage topology-driven graph convolutional operations to combine information across the graph for inference tasks. In our recent work, we have studied GCNs with covariance matrices as graphs in the form of coVariance neural networks (VNNs) that draw similarities with traditional PCA-driven data analysis approaches while offering significant advantages over them. In this paper, we first focus on theoretically characterizing the transferability of VNNs. The notion of transferability is motivated from the intuitive expectation that learning models could generalize to "compatible" datasets (possibly of different dimensionalities) with minimal effort. VNNs inherit the scale-free data processing architecture from GCNs and here, we show that VNNs exhibit transferability of performance over datasets whose covariance matrices converge to a limit object. Multi-scale neuroimaging datasets enable the study of the brain at multiple scales and hence, can validate the theoretical results on the transferability of VNNs. To gauge the advantages offered by VNNs in neuroimaging data analysis, we focus on the task of "brain age" prediction using cortical thickness features. In clinical neuroscience, there has been an increased interest in machine learning algorithms which provide estimates of "brain age" that deviate from chronological age. We leverage the architecture of VNNs to extend beyond the coarse metric of brain age gap in Alzheimer's disease (AD) and make two important observations: (i) VNNs can assign anatomical interpretability to elevated brain age gap in AD, and (ii) the interpretability offered by VNNs is contingent on their ability to exploit specific principal components of the anatomical covariance matrix. We further leverage the transferability of VNNs to cross validate the above observations across different datasets.
Normalizing Flow-based Neural Process for Few-Shot Knowledge Graph Completion
Apr 17, 2023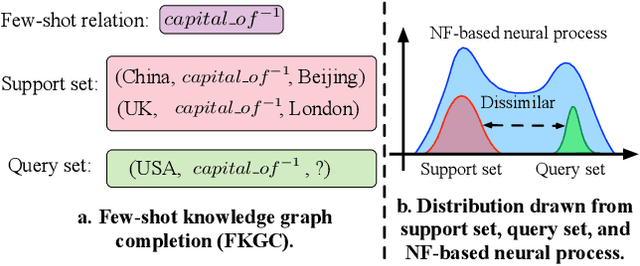
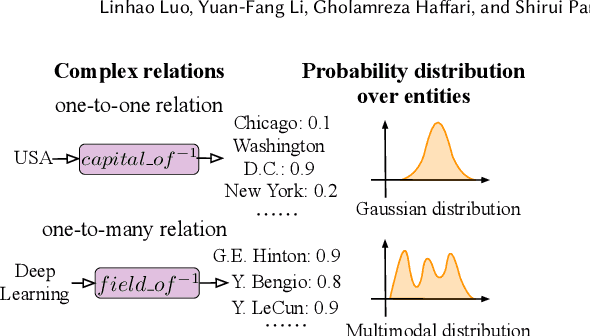
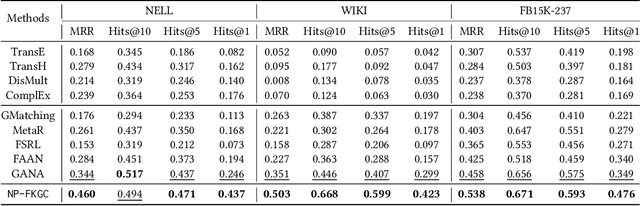
Knowledge graphs (KGs), as a structured form of knowledge representation, have been widely applied in the real world. Recently, few-shot knowledge graph completion (FKGC), which aims to predict missing facts for unseen relations with few-shot associated facts, has attracted increasing attention from practitioners and researchers. However, existing FKGC methods are based on metric learning or meta-learning, which often suffer from the out-of-distribution and overfitting problems. Meanwhile, they are incompetent at estimating uncertainties in predictions, which is critically important as model predictions could be very unreliable in few-shot settings. Furthermore, most of them cannot handle complex relations and ignore path information in KGs, which largely limits their performance. In this paper, we propose a normalizing flow-based neural process for few-shot knowledge graph completion (NP-FKGC). Specifically, we unify normalizing flows and neural processes to model a complex distribution of KG completion functions. This offers a novel way to predict facts for few-shot relations while estimating the uncertainty. Then, we propose a stochastic ManifoldE decoder to incorporate the neural process and handle complex relations in few-shot settings. To further improve performance, we introduce an attentive relation path-based graph neural network to capture path information in KGs. Extensive experiments on three public datasets demonstrate that our method significantly outperforms the existing FKGC methods and achieves state-of-the-art performance. Code is available at https://github.com/RManLuo/NP-FKGC.git.
* Accepted by SIGIR2023
Constructing Deep Spiking Neural Networks from Artificial Neural Networks with Knowledge Distillation
Apr 17, 2023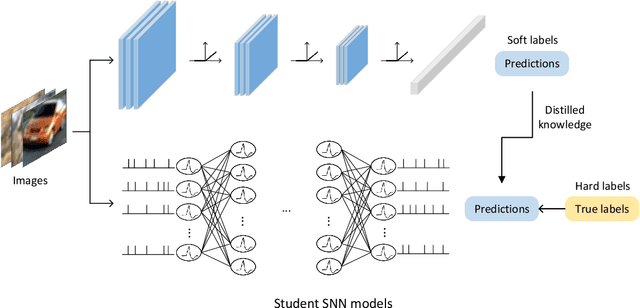
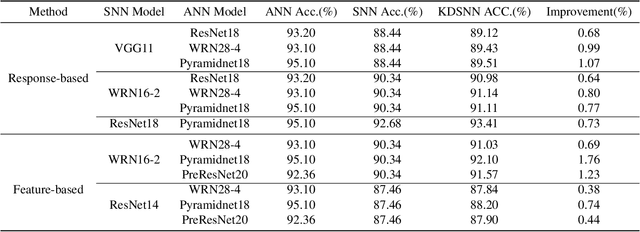


Spiking neural networks (SNNs) are well known as the brain-inspired models with high computing efficiency, due to a key component that they utilize spikes as information units, close to the biological neural systems. Although spiking based models are energy efficient by taking advantage of discrete spike signals, their performance is limited by current network structures and their training methods. As discrete signals, typical SNNs cannot apply the gradient descent rules directly into parameters adjustment as artificial neural networks (ANNs). Aiming at this limitation, here we propose a novel method of constructing deep SNN models with knowledge distillation (KD) that uses ANN as teacher model and SNN as student model. Through ANN-SNN joint training algorithm, the student SNN model can learn rich feature information from the teacher ANN model through the KD method, yet it avoids training SNN from scratch when communicating with non-differentiable spikes. Our method can not only build a more efficient deep spiking structure feasibly and reasonably, but use few time steps to train whole model compared to direct training or ANN to SNN methods. More importantly, it has a superb ability of noise immunity for various types of artificial noises and natural signals. The proposed novel method provides efficient ways to improve the performance of SNN through constructing deeper structures in a high-throughput fashion, with potential usage for light and efficient brain-inspired computing of practical scenarios.
Classification of news spreading barriers
Apr 10, 2023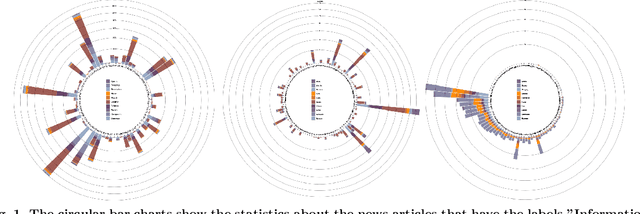
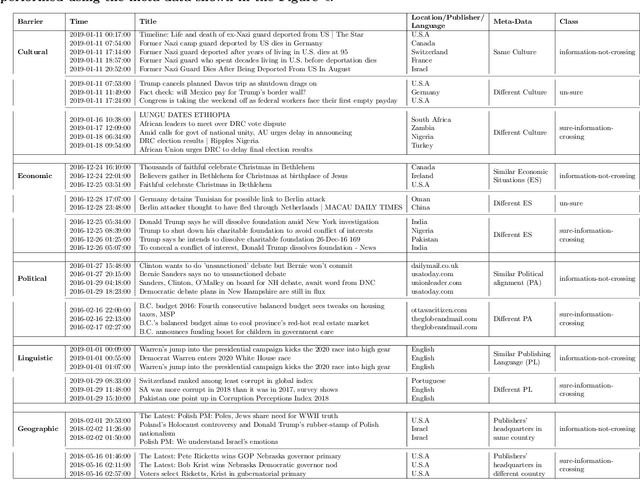
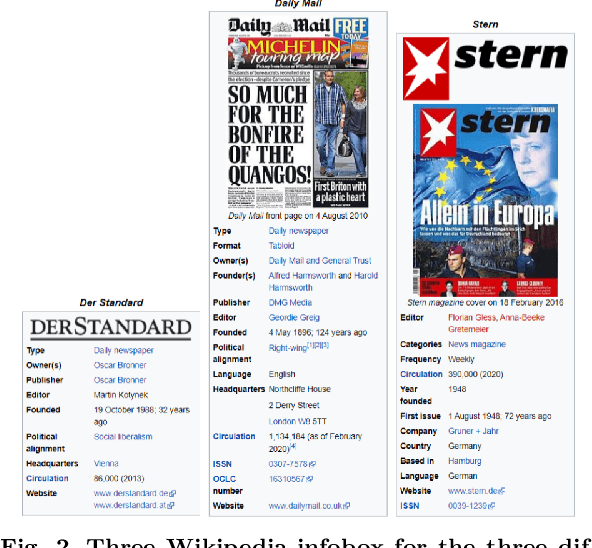
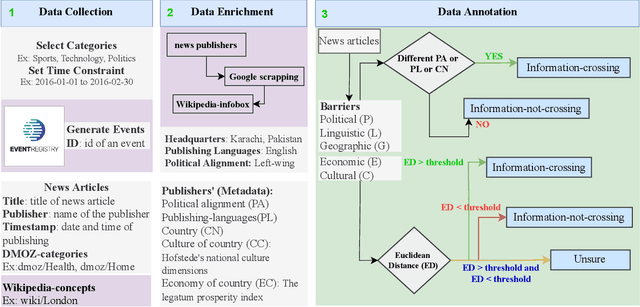
News media is one of the most effective mechanisms for spreading information internationally, and many events from different areas are internationally relevant. However, news coverage for some news events is limited to a specific geographical region because of information spreading barriers, which can be political, geographical, economic, cultural, or linguistic. In this paper, we propose an approach to barrier classification where we infer the semantics of news articles through Wikipedia concepts. To that end, we collected news articles and annotated them for different kinds of barriers using the metadata of news publishers. Then, we utilize the Wikipedia concepts along with the body text of news articles as features to infer the news-spreading barriers. We compare our approach to the classical text classification methods, deep learning, and transformer-based methods. The results show that the proposed approach using Wikipedia concepts based semantic knowledge offers better performance than the usual for classifying the news-spreading barriers.