 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DPAF: Image Synthesis via Differentially Private Aggregation in Forward Phase
Apr 20, 2023
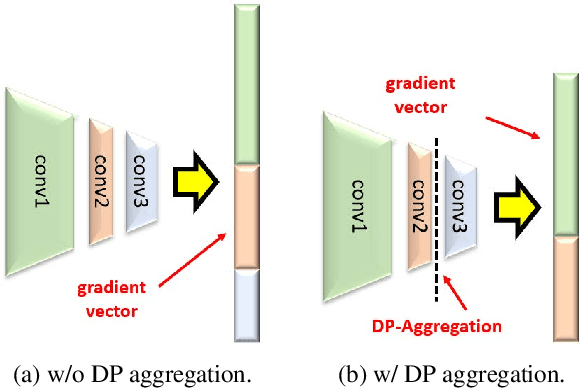
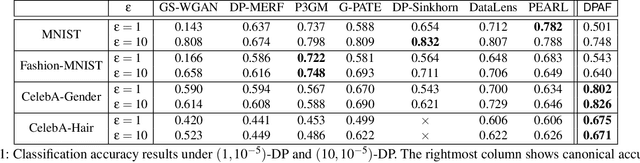
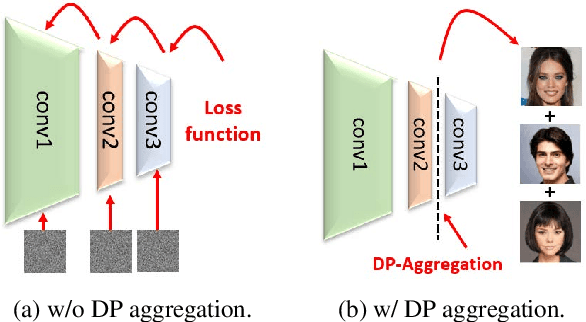
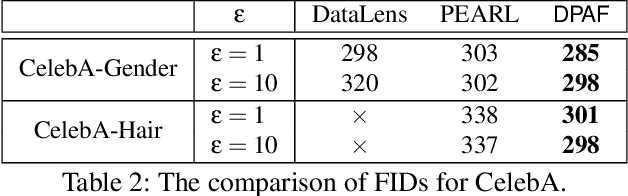
Differentially private synthetic data is a promising alternative for sensitive data release. Many differentially private generative models have been proposed in the literature. Unfortunately, they all suffer from the low utility of the synthetic data, particularly for images of high resolutions. Here, we propose DPAF, an effective differentially private generative model for high-dimensional image synthesis. Different from the prior private stochastic gradient descent-based methods that add Gaussian noises in the backward phase during the model training, DPAF adds a differentially private feature aggregation in the forward phase, bringing advantages, including the reduction of information loss in gradient clipping and low sensitivity for the aggregation. Moreover, as an improper batch size has an adverse impact on the utility of synthetic data, DPAF also tackles the problem of setting a proper batch size by proposing a novel training strategy that asymmetrically trains different parts of the discriminator. We extensively evaluate different methods on multiple image datasets (up to images of 128x128 resolution) to demonstrate the performance of DPAF.
Adaptive coded illumination Fourier ptychography microscopy based on physical neural network
Apr 20, 2023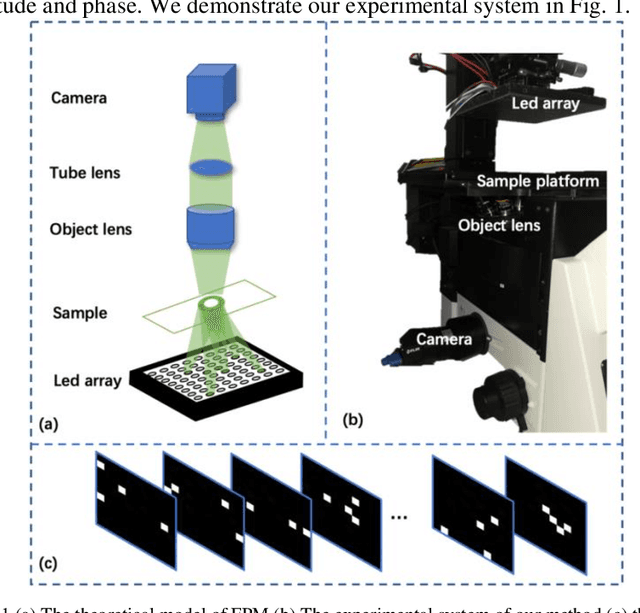
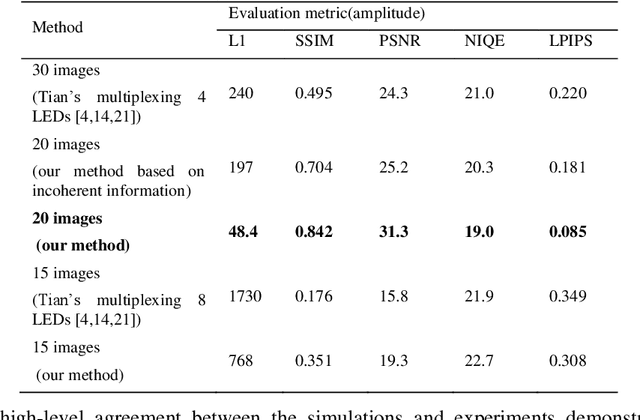
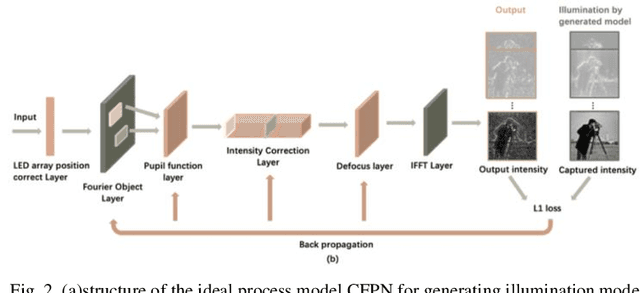

Fourier Ptychographic Microscopy (FPM) is a computational technique that achieves a large space-bandwidth product imaging. It addresses the challenge of balancing a large field of view and high resolution by fusing information from multiple images taken with varying illumination angles. Nevertheless, conventional FPM framework always suffers from long acquisition time and a heavy computational burden. In this paper, we propose a novel physical neural network that generates an adaptive illumination mode by incorporating temporally-encoded illumination modes as a distinct layer, aiming to improve the acquisition and calculation efficiency. Both simulations and experiments have been conducted to validate the feasibility and effectiveness of the proposed method. It is worth mentioning that, unlike previous works that obtain the intensity of a multiplexed illumination by post-combination of each sequentially illuminated and obtained low-resolution images, our experimental data is captured directly by turning on multiple LEDs with a coded illumination pattern. Our method has exhibited state-of-the-art performance in terms of both detail fidelity and imaging velocity when assessed through a multitude of evaluative aspects.
Cyber Security in Smart Manufacturing (Threats, Landscapes Challenges)
Apr 20, 2023
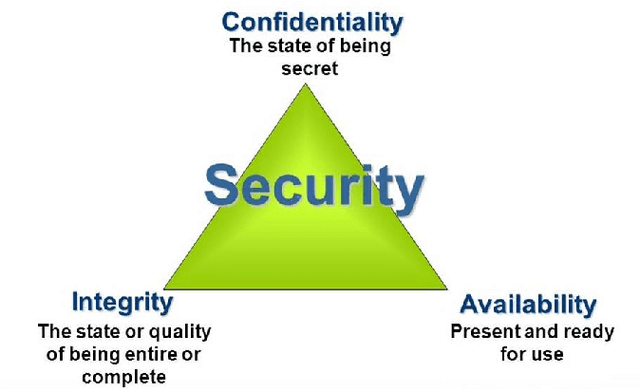
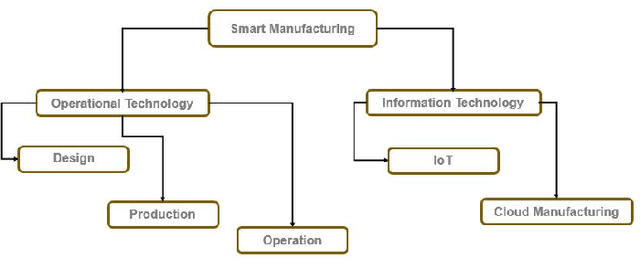
Industry 4.0 is a blend of the hyper-connected digital industry within two world of Information Technology (IT) and Operational Technology (OT). With this amalgamate opportunity, smart manufacturing involves production assets with the manufacturing equipment having its own intelligence, while the system-wide intelligence is provided by the cyber layer. However Smart manufacturing now becomes one of the prime targets of cyber threats due to vulnerabilities in the existing process of operation. Since smart manufacturing covers a vast area of production industries from cyber physical system to additive manufacturing, to autonomous vehicles, to cloud based IIoT (Industrial IoT), to robotic production, cyber threat stands out with this regard questioning about how to connect manufacturing resources by network, how to integrate a whole process chain for a factory production etc. Cybersecurity confidentiality, integrity and availability expose their essential existence for the proper operational thread model known as digital thread ensuring secure manufacturing. In this work, a literature survey is presented from the existing threat models, attack vectors and future challenges over the digital thread of smart manufacturing.
Word Sense Induction with Knowledge Distillation from BERT
Apr 20, 2023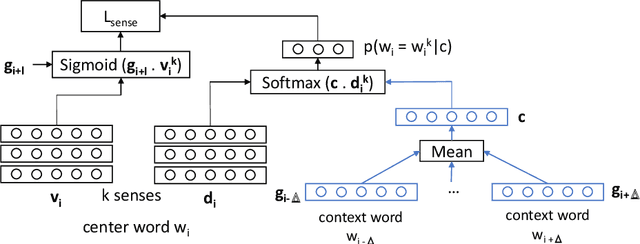
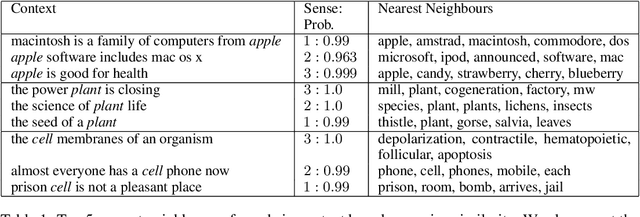
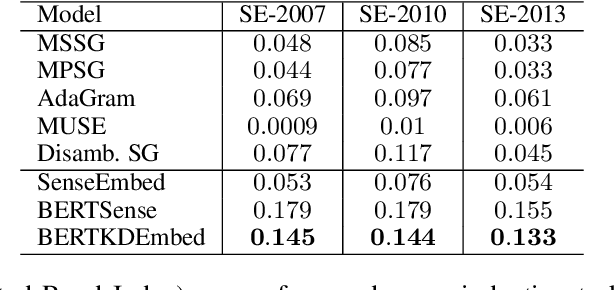
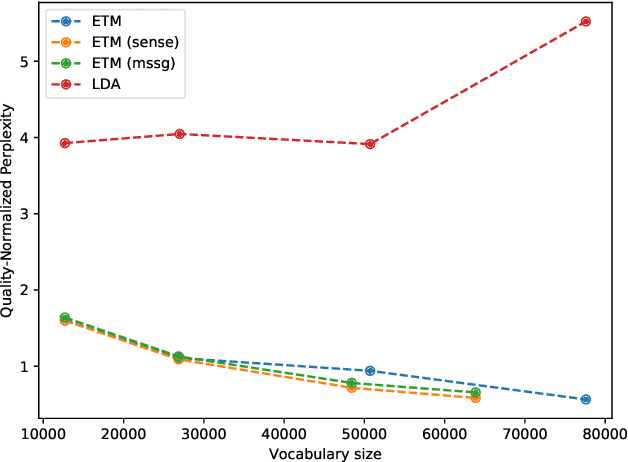
Pre-trained contextual language models are ubiquitously employed for language understanding tasks, but are unsuitable for resource-constrained systems. Noncontextual word embeddings are an efficient alternative in these settings. Such methods typically use one vector to encode multiple different meanings of a word, and incur errors due to polysemy. This paper proposes a two-stage method to distill multiple word senses from a pre-trained language model (BERT) by using attention over the senses of a word in a context and transferring this sense information to fit multi-sense embeddings in a skip-gram-like framework. We demonstrate an effective approach to training the sense disambiguation mechanism in our model with a distribution over word senses extracted from the output layer embeddings of BERT. Experiments on the contextual word similarity and sense induction tasks show that this method is superior to or competitive with state-of-the-art multi-sense embeddings on multiple benchmark data sets, and experiments with an embedding-based topic model (ETM) demonstrates the benefits of using this multi-sense embedding in a downstream application.
EPG-MGCN: Ego-Planning Guided Multi-Graph Convolutional Network for Heterogeneous Agent Trajectory Prediction
Mar 29, 2023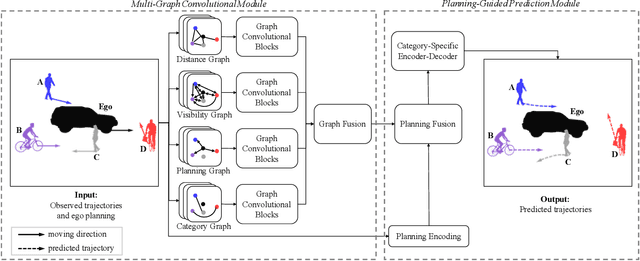
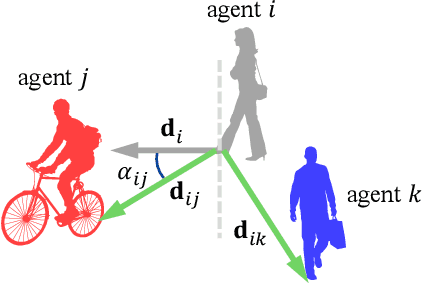
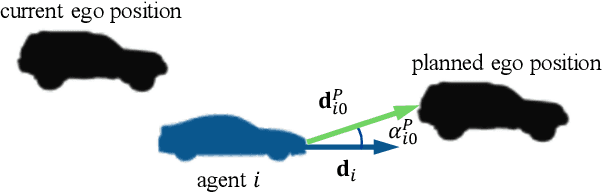
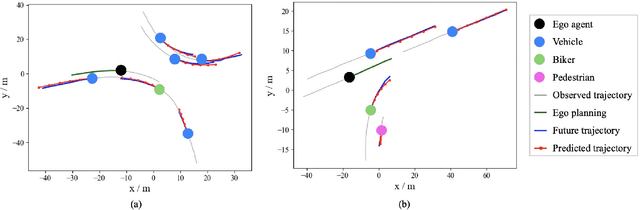
To drive safely in complex traffic environments, autonomous vehicles need to make an accurate prediction of the future trajectories of nearby heterogeneous traffic agents (i.e., vehicles, pedestrians, bicyclists, etc). Due to the interactive nature, human drivers are accustomed to infer what the future situations will become if they are going to execute different maneuvers. To fully exploit the impacts of interactions, this paper proposes a ego-planning guided multi-graph convolutional network (EPG-MGCN) to predict the trajectories of heterogeneous agents using both historical trajectory information and ego vehicle's future planning information. The EPG-MGCN first models the social interactions by employing four graph topologies, i.e., distance graphs, visibility graphs, planning graphs and category graphs. Then, the planning information of the ego vehicle is encoded by both the planning graph and the subsequent planning-guided prediction module to reduce uncertainty in the trajectory prediction. Finally, a category-specific gated recurrent unit (CS-GRU) encoder-decoder is designed to generate future trajectories for each specific type of agents. Our network is evaluated on two real-world trajectory datasets: ApolloScape and NGSIM. The experimental results show that the proposed EPG-MGCN achieves state-of-the-art performance compared to existing methods.
Multi-crop Contrastive Learning for Unsupervised Image-to-Image Translation
Apr 24, 2023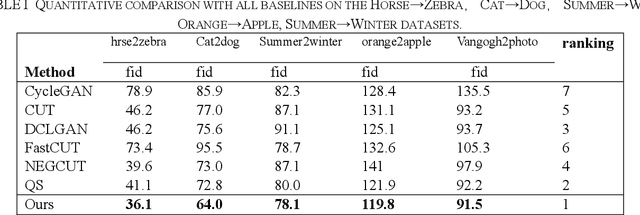
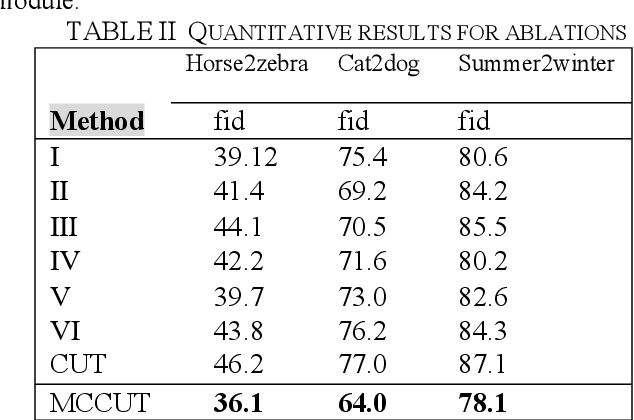
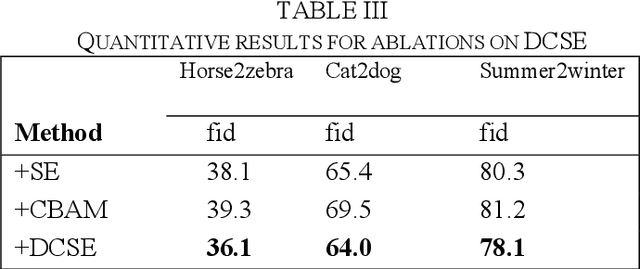
Recently, image-to-image translation methods based on contrastive learning achieved state-of-the-art results in many tasks. However, the negatives are sampled from the input feature spaces in the previous work, which makes the negatives lack diversity. Moreover, in the latent space of the embedings,the previous methods ignore domain consistency between the generated image and the real images of target domain. In this paper, we propose a novel contrastive learning framework for unpaired image-to-image translation, called MCCUT. We utilize the multi-crop views to generate the negatives via the center-crop and the random-crop, which can improve the diversity of negatives and meanwhile increase the quality of negatives. To constrain the embedings in the deep feature space,, we formulate a new domain consistency loss function, which encourages the generated images to be close to the real images in the embedding space of same domain. Furthermore, we present a dual coordinate channel attention network by embedding positional information into SENet, which called DCSE module. We employ the DCSE module in the design of generator, which makes the generator pays more attention to channels with greater weight. In many image-to-image translation tasks, our method achieves state-of-the-art results, and the advantages of our method have been proved through extensive comparison experiments and ablation research.
Immunohistochemistry Biomarkers-Guided Image Search for Histopathology
Apr 24, 2023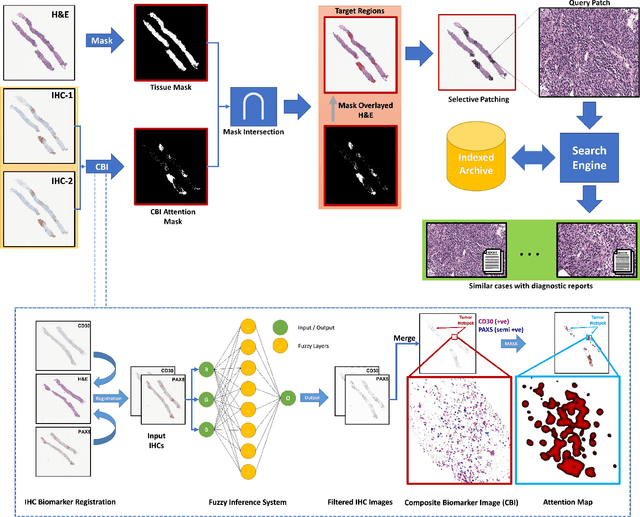
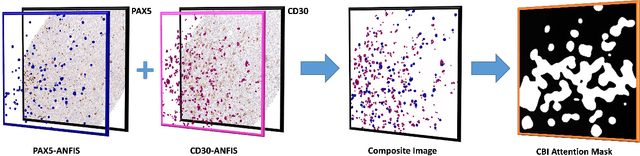
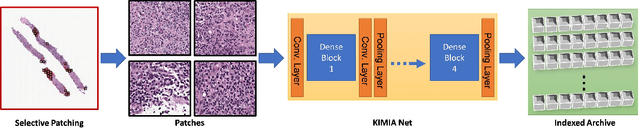
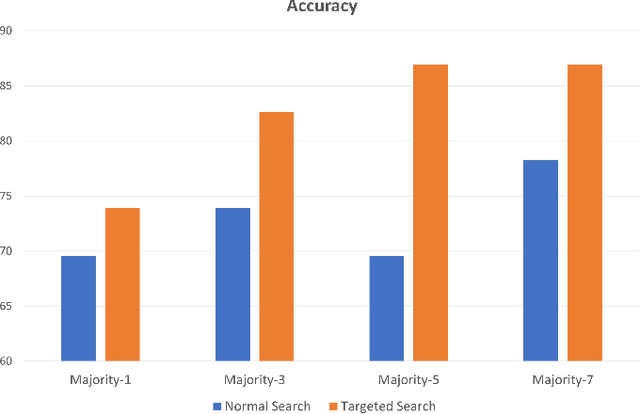
Medical practitioners use a number of diagnostic tests to make a reliable diagnosis. Traditionally, Haematoxylin and Eosin (H&E) stained glass slides have been used for cancer diagnosis and tumor detection. However, recently a variety of immunohistochemistry (IHC) stained slides can be requested by pathologists to examine and confirm diagnoses for determining the subtype of a tumor when this is difficult using H&E slides only. Deep learning (DL) has received a lot of interest recently for image search engines to extract features from tissue regions, which may or may not be the target region for diagnosis. This approach generally fails to capture high-level patterns corresponding to the malignant or abnormal content of histopathology images. In this work, we are proposing a targeted image search approach, inspired by the pathologists workflow, which may use information from multiple IHC biomarker images when available. These IHC images could be aligned, filtered, and merged together to generate a composite biomarker image (CBI) that could eventually be used to generate an attention map to guide the search engine for localized search. In our experiments, we observed that an IHC-guided image search engine can retrieve relevant data more accurately than a conventional (i.e., H&E-only) search engine without IHC guidance. Moreover, such engines are also able to accurately conclude the subtypes through majority votes.
RusTitW: Russian Language Text Dataset for Visual Text in-the-Wild Recognition
Mar 29, 2023


Information surrounds people in modern life. Text is a very efficient type of information that people use for communication for centuries. However, automated text-in-the-wild recognition remains a challenging problem. The major limitation for a DL system is the lack of training data. For the competitive performance, training set must contain many samples that replicate the real-world cases. While there are many high-quality datasets for English text recognition; there are no available datasets for Russian language. In this paper, we present a large-scale human-labeled dataset for Russian text recognition in-the-wild. We also publish a synthetic dataset and code to reproduce the generation process
Modeling Information Change in Science Communication with Semantically Matched Paraphrases
Oct 24, 2022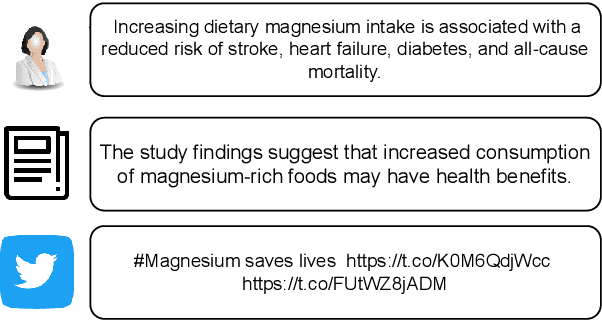


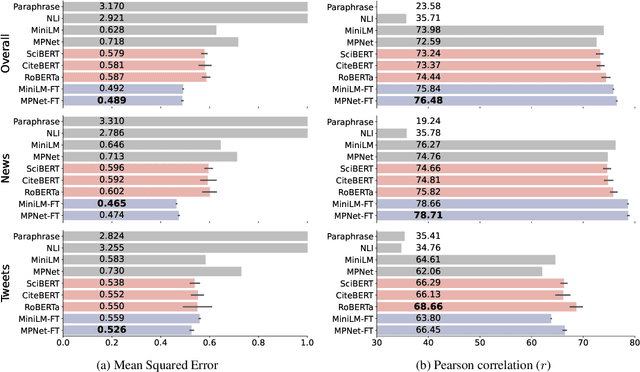
Whether the media faithfully communicate scientific information has long been a core issue to the science community. Automatically identifying paraphrased scientific findings could enable large-scale tracking and analysis of information changes in the science communication process, but this requires systems to understand the similarity between scientific information across multiple domains. To this end, we present the SCIENTIFIC PARAPHRASE AND INFORMATION CHANGE DATASET (SPICED), the first paraphrase dataset of scientific findings annotated for degree of information change. SPICED contains 6,000 scientific finding pairs extracted from news stories, social media discussions, and full texts of original papers. We demonstrate that SPICED poses a challenging task and that models trained on SPICED improve downstream performance on evidence retrieval for fact checking of real-world scientific claims. Finally, we show that models trained on SPICED can reveal large-scale trends in the degrees to which people and organizations faithfully communicate new scientific findings. Data, code, and pre-trained models are available at http://www.copenlu.com/publication/2022_emnlp_wright/.
Differential Privacy via Distributionally Robust Optimization
Apr 25, 2023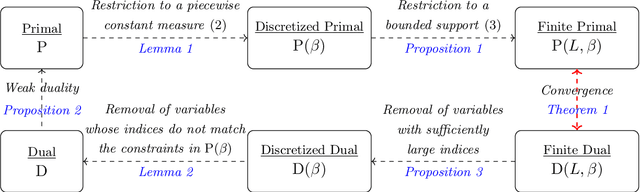
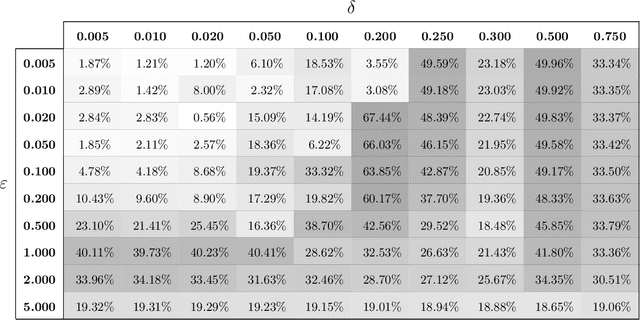
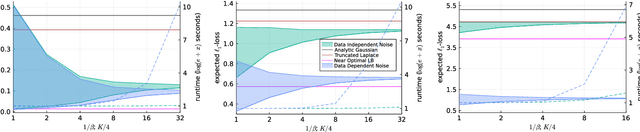
In recent years, differential privacy has emerged as the de facto standard for sharing statistics of datasets while limiting the disclosure of private information about the involved individuals. This is achieved by randomly perturbing the statistics to be published, which in turn leads to a privacy-accuracy trade-off: larger perturbations provide stronger privacy guarantees, but they result in less accurate statistics that offer lower utility to the recipients. Of particular interest are therefore optimal mechanisms that provide the highest accuracy for a pre-selected level of privacy. To date, work in this area has focused on specifying families of perturbations a priori and subsequently proving their asymptotic and/or best-in-class optimality. In this paper, we develop a class of mechanisms that enjoy non-asymptotic and unconditional optimality guarantees. To this end, we formulate the mechanism design problem as an infinite-dimensional distributionally robust optimization problem. We show that the problem affords a strong dual, and we exploit this duality to develop converging hierarchies of finite-dimensional upper and lower bounding problems. Our upper (primal) bounds correspond to implementable perturbations whose suboptimality can be bounded by our lower (dual) bounds. Both bounding problems can be solved within seconds via cutting plane techniques that exploit the inherent problem structure. Our numerical experiments demonstrate that our perturbations can outperform the previously best results from the literature on artificial as well as standard benchmark problems.