 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Two-Memory Reinforcement Learning
Apr 23, 2023
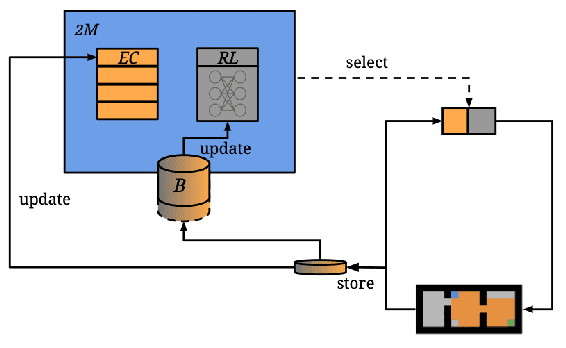

While deep reinforcement learning has shown important empirical success, it tends to learn relatively slow due to slow propagation of rewards information and slow update of parametric neural networks. Non-parametric episodic memory, on the other hand, provides a faster learning alternative that does not require representation learning and uses maximum episodic return as state-action values for action selection. Episodic memory and reinforcement learning both have their own strengths and weaknesses. Notably, humans can leverage multiple memory systems concurrently during learning and benefit from all of them. In this work, we propose a method called Two-Memory reinforcement learning agent (2M) that combines episodic memory and reinforcement learning to distill both of their strengths. The 2M agent exploits the speed of the episodic memory part and the optimality and the generalization capacity of the reinforcement learning part to complement each other. Our experiments demonstrate that the 2M agent is more data efficient and outperforms both pure episodic memory and pure reinforcement learning, as well as a state-of-the-art memory-augmented RL agent. Moreover, the proposed approach provides a general framework that can be used to combine any episodic memory agent with other off-policy reinforcement learning algorithms.
Query-specific Variable Depth Pooling via Query Performance Prediction towards Reducing Relevance Assessment Effort
Apr 23, 2023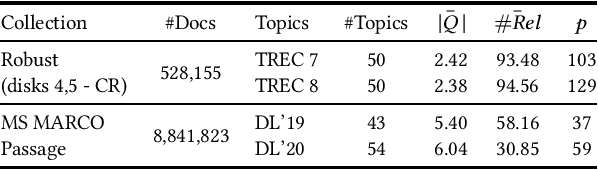
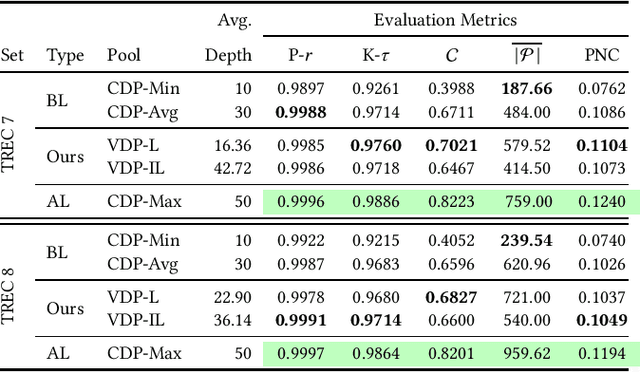
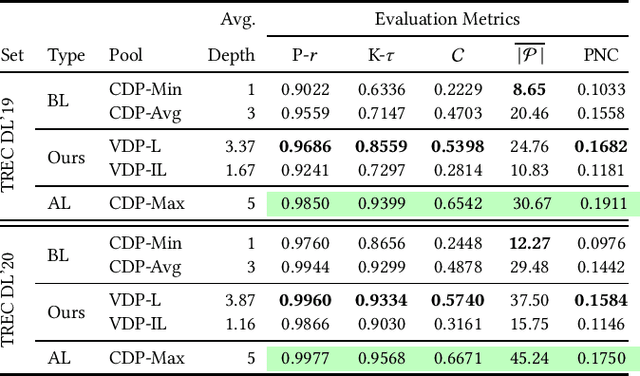
Due to the massive size of test collections, a standard practice in IR evaluation is to construct a 'pool' of candidate relevant documents comprised of the top-k documents retrieved by a wide range of different retrieval systems - a process called depth-k pooling. A standard practice is to set the depth (k) to a constant value for each query constituting the benchmark set. However, in this paper we argue that the annotation effort can be substantially reduced if the depth of the pool is made a variable quantity for each query, the rationale being that the number of documents relevant to the information need can widely vary across queries. Our hypothesis is that a lower depth for the former class of queries and a higher depth for the latter can potentially reduce the annotation effort without a significant change in retrieval effectiveness evaluation. We make use of standard query performance prediction (QPP) techniques to estimate the number of potentially relevant documents for each query, which is then used to determine the depth of the pool. Our experiments conducted on standard test collections demonstrate that this proposed method of employing query-specific variable depths is able to adequately reflect the relative effectiveness of IR systems with a substantially smaller annotation effort.
Sampling-based Path Planning Algorithms: A Survey
Apr 23, 2023

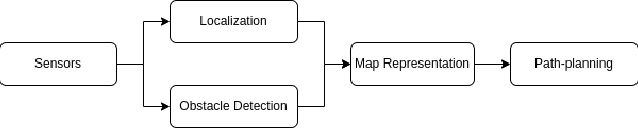

Path planning is a classic problem for autonomous robots. To ensure safe and efficient point-to-point navigation an appropriate algorithm should be chosen keeping the robot's dimensions and its classification in mind. Autonomous robots use path-planning algorithms to safely navigate a dynamic, dense, and unknown environment. A few metrics for path planning algorithms to be taken into account are safety, efficiency, lowest-cost path generation, and obstacle avoidance. Before path planning can take place we need map representation which can be discretized or open configuration space. Discretized configuration space provides node/connectivity information from one point to another. While in open/free configuration space it is up to the algorithm to create a list of nodes and then find a feasible path. Both types of maps are populated by obstacle positions using perception obstacle detection techniques to represent current obstacles from the perspective of the robot. For open configuration spaces, sampling-based planning algorithms are used. This paper aims to explore various types of Sampling-based path-planning algorithms such as Probabilistic RoadMap (PRM), and Rapidly-exploring Random Trees (RRT). These two algorithms also have optimized versions - PRM* and RRT* and this paper discusses how that optimization is achieved and is beneficial.
GamutMLP: A Lightweight MLP for Color Loss Recovery
Apr 23, 2023
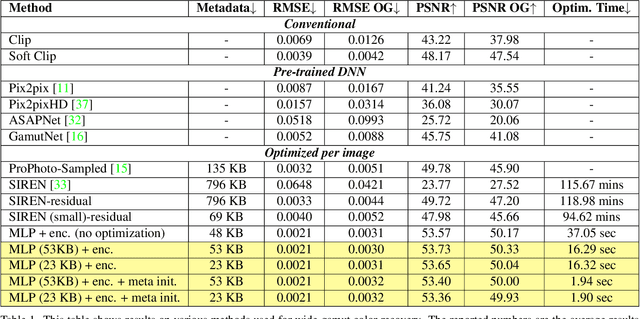
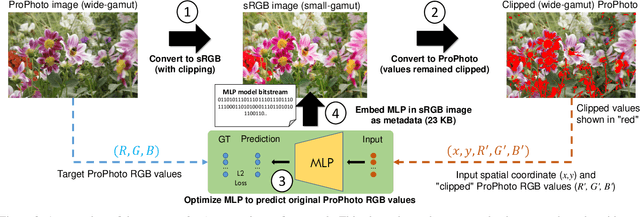
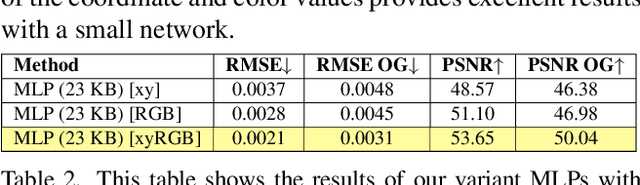
Cameras and image-editing software often process images in the wide-gamut ProPhoto color space, encompassing 90% of all visible colors. However, when images are encoded for sharing, this color-rich representation is transformed and clipped to fit within the small-gamut standard RGB (sRGB) color space, representing only 30% of visible colors. Recovering the lost color information is challenging due to the clipping procedure. Inspired by neural implicit representations for 2D images, we propose a method that optimizes a lightweight multi-layer-perceptron (MLP) model during the gamut reduction step to predict the clipped values. GamutMLP takes approximately 2 seconds to optimize and requires only 23 KB of storage. The small memory footprint allows our GamutMLP model to be saved as metadata in the sRGB image -- the model can be extracted when needed to restore wide-gamut color values. We demonstrate the effectiveness of our approach for color recovery and compare it with alternative strategies, including pre-trained DNN-based gamut expansion networks and other implicit neural representation methods. As part of this effort, we introduce a new color gamut dataset of 2200 wide-gamut/small-gamut images for training and testing. Our code and dataset can be found on the project website: https://gamut-mlp.github.io.
Tempo vs. Pitch: understanding self-supervised tempo estimation
Apr 14, 2023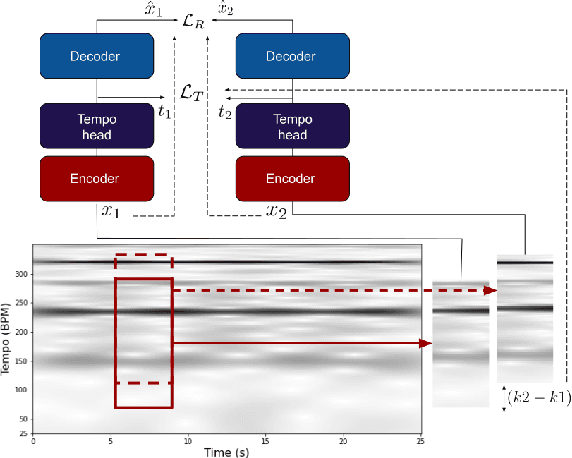
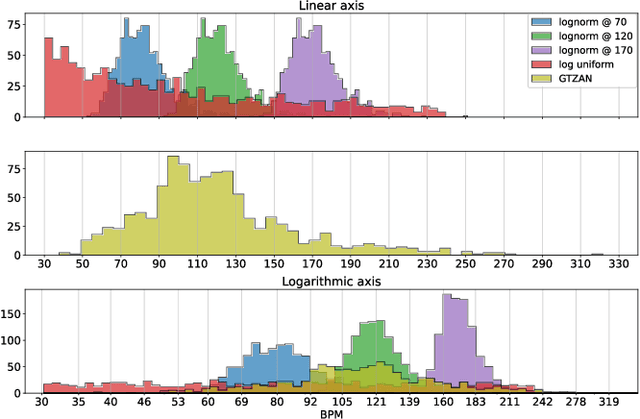
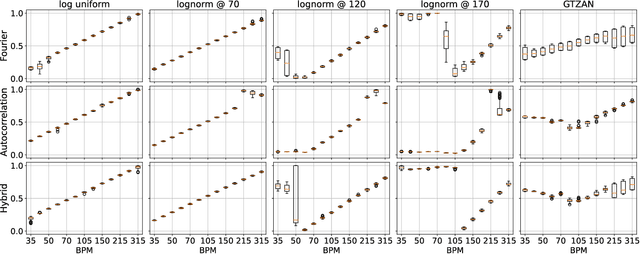
Self-supervision methods learn representations by solving pretext tasks that do not require human-generated labels, alleviating the need for time-consuming annotations. These methods have been applied in computer vision, natural language processing, environmental sound analysis, and recently in music information retrieval, e.g. for pitch estimation. Particularly in the context of music, there are few insights about the fragility of these models regarding different distributions of data, and how they could be mitigated. In this paper, we explore these questions by dissecting a self-supervised model for pitch estimation adapted for tempo estimation via rigorous experimentation with synthetic data. Specifically, we study the relationship between the input representation and data distribution for self-supervised tempo estimation.
Can Shadows Reveal Biometric Information?
Oct 04, 2022
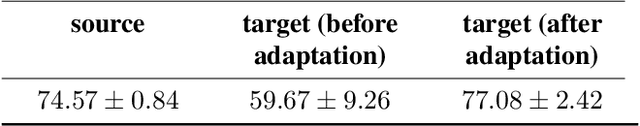


We study the problem of extracting biometric information of individuals by looking at shadows of objects cast on diffuse surfaces. We show that the biometric information leakage from shadows can be sufficient for reliable identity inference under representative scenarios via a maximum likelihood analysis. We then develop a learning-based method that demonstrates this phenomenon in real settings, exploiting the subtle cues in the shadows that are the source of the leakage without requiring any labeled real data. In particular, our approach relies on building synthetic scenes composed of 3D face models obtained from a single photograph of each identity. We transfer what we learn from the synthetic data to the real data using domain adaptation in a completely unsupervised way. Our model is able to generalize well to the real domain and is robust to several variations in the scenes. We report high classification accuracies in an identity classification task that takes place in a scene with unknown geometry and occluding objects.
NTIRE 2023 Challenge on Light Field Image Super-Resolution: Dataset, Methods and Results
Apr 20, 2023
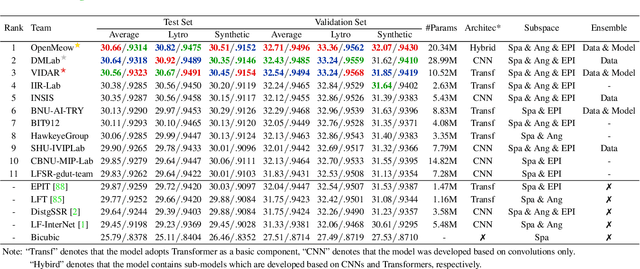
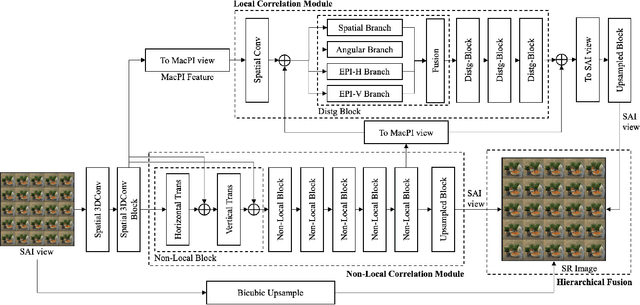
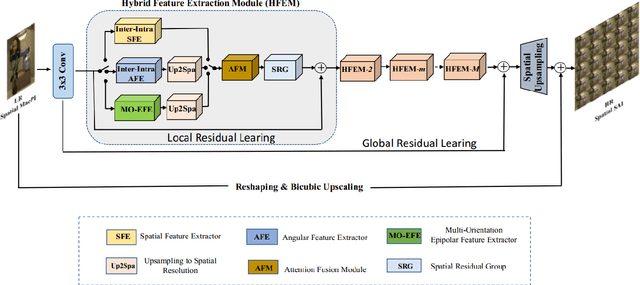
In this report, we summarize the first NTIRE challenge on light field (LF) image super-resolution (SR), which aims at super-resolving LF images under the standard bicubic degradation with a magnification factor of 4. This challenge develops a new LF dataset called NTIRE-2023 for validation and test, and provides a toolbox called BasicLFSR to facilitate model development. Compared with single image SR, the major challenge of LF image SR lies in how to exploit complementary angular information from plenty of views with varying disparities. In total, 148 participants have registered the challenge, and 11 teams have successfully submitted results with PSNR scores higher than the baseline method LF-InterNet \cite{LF-InterNet}. These newly developed methods have set new state-of-the-art in LF image SR, e.g., the winning method achieves around 1 dB PSNR improvement over the existing state-of-the-art method DistgSSR \cite{DistgLF}. We report the solutions proposed by the participants, and summarize their common trends and useful tricks. We hope this challenge can stimulate future research and inspire new ideas in LF image SR.
Application of attention-based Siamese composite neural network in medical image recognition
Apr 20, 2023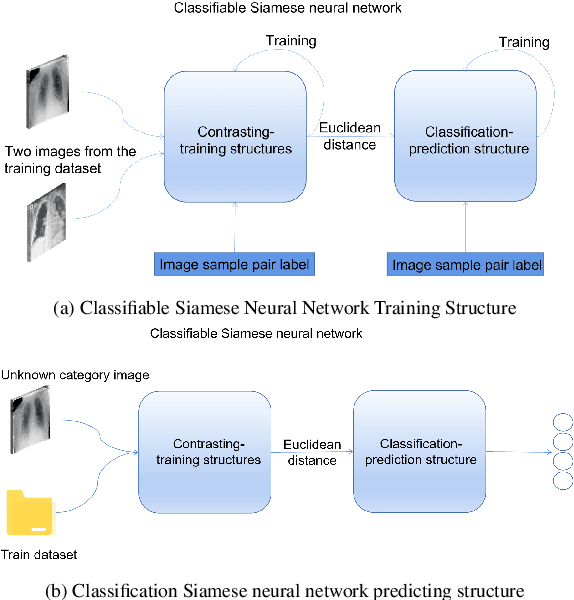
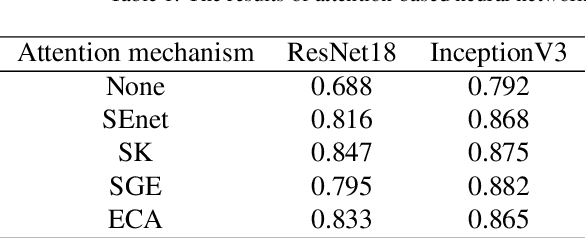
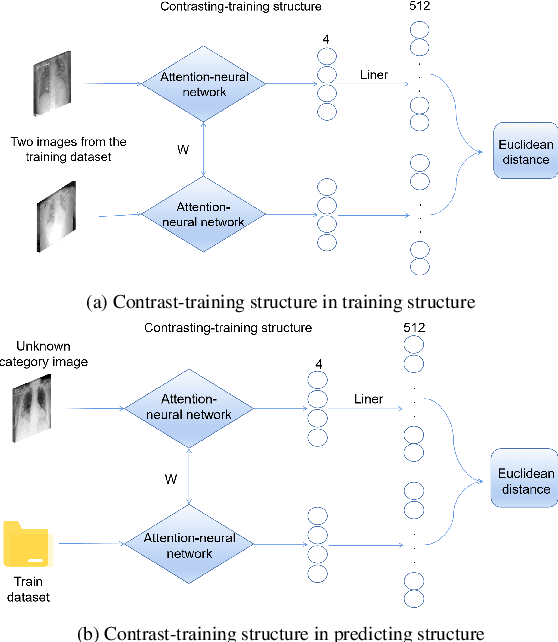
Medical image recognition often faces the problem of insufficient data in practical applications. Image recognition and processing under few-shot conditions will produce overfitting, low recognition accuracy, low reliability and insufficient robustness. It is often the case that the difference of characteristics is subtle, and the recognition is affected by perspectives, background, occlusion and other factors, which increases the difficulty of recognition. Furthermore, in fine-grained images, the few-shot problem leads to insufficient useful feature information in the images. Considering the characteristics of few-shot and fine-grained image recognition, this study has established a recognition model based on attention and Siamese neural network. Aiming at the problem of few-shot samples, a Siamese neural network suitable for classification model is proposed. The Attention-Based neural network is used as the main network to improve the classification effect. Covid- 19 lung samples have been selected for testing the model. The results show that the less the number of image samples are, the more obvious the advantage shows than the ordinary neural network.
Learning Neural Duplex Radiance Fields for Real-Time View Synthesis
Apr 20, 2023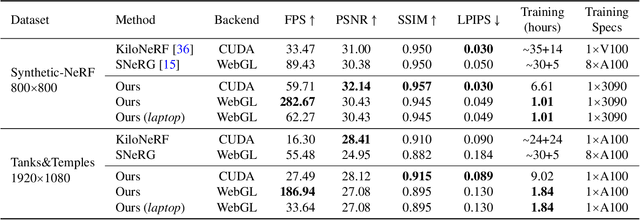
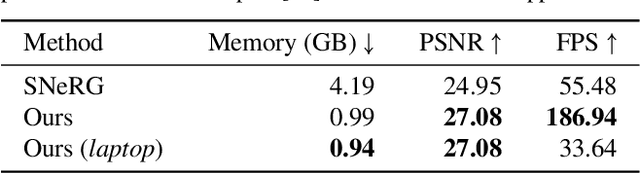

Neural radiance fields (NeRFs) enable novel view synthesis with unprecedented visual quality. However, to render photorealistic images, NeRFs require hundreds of deep multilayer perceptron (MLP) evaluations - for each pixel. This is prohibitively expensive and makes real-time rendering infeasible, even on powerful modern GPUs. In this paper, we propose a novel approach to distill and bake NeRFs into highly efficient mesh-based neural representations that are fully compatible with the massively parallel graphics rendering pipeline. We represent scenes as neural radiance features encoded on a two-layer duplex mesh, which effectively overcomes the inherent inaccuracies in 3D surface reconstruction by learning the aggregated radiance information from a reliable interval of ray-surface intersections. To exploit local geometric relationships of nearby pixels, we leverage screen-space convolutions instead of the MLPs used in NeRFs to achieve high-quality appearance. Finally, the performance of the whole framework is further boosted by a novel multi-view distillation optimization strategy. We demonstrate the effectiveness and superiority of our approach via extensive experiments on a range of standard datasets.
Not Only Generative Art: Stable Diffusion for Content-Style Disentanglement in Art Analysis
Apr 20, 2023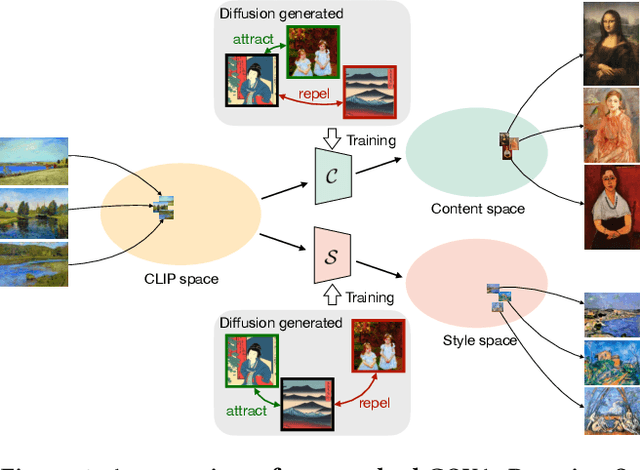
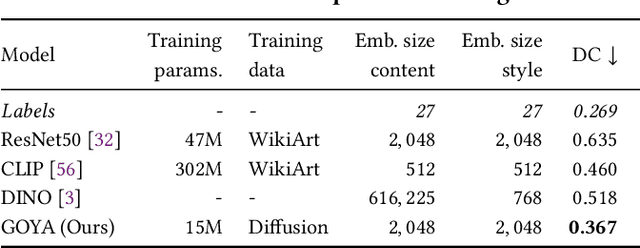
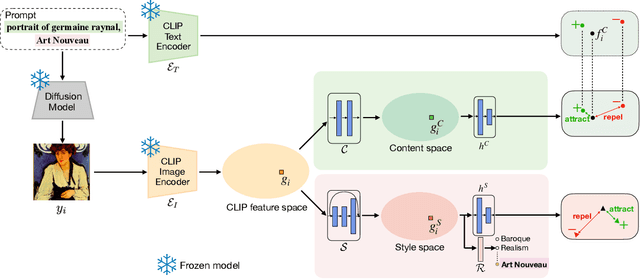
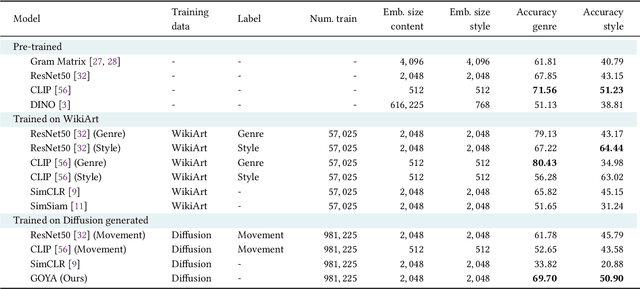
The duality of content and style is inherent to the nature of art. For humans, these two elements are clearly different: content refers to the objects and concepts in the piece of art, and style to the way it is expressed. This duality poses an important challenge for computer vision. The visual appearance of objects and concepts is modulated by the style that may reflect the author's emotions, social trends, artistic movement, etc., and their deep comprehension undoubtfully requires to handle both. A promising step towards a general paradigm for art analysis is to disentangle content and style, whereas relying on human annotations to cull a single aspect of artworks has limitations in learning semantic concepts and the visual appearance of paintings. We thus present GOYA, a method that distills the artistic knowledge captured in a recent generative model to disentangle content and style. Experiments show that synthetically generated images sufficiently serve as a proxy of the real distribution of artworks, allowing GOYA to separately represent the two elements of art while keeping more information than existing methods.