 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
What Do Self-Supervised Vision Transformers Learn?
May 01, 2023
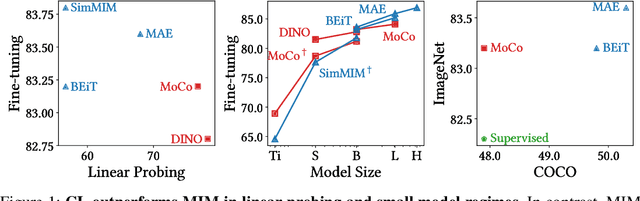
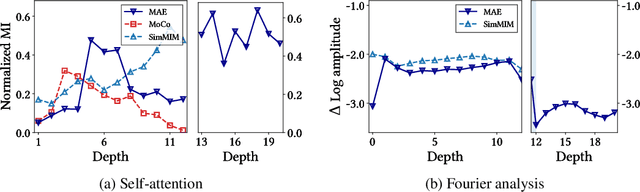
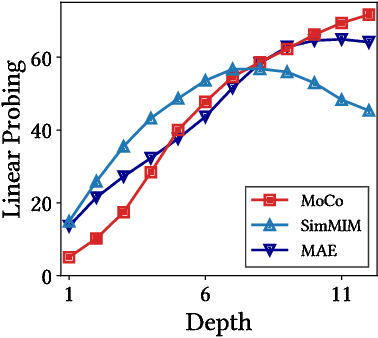
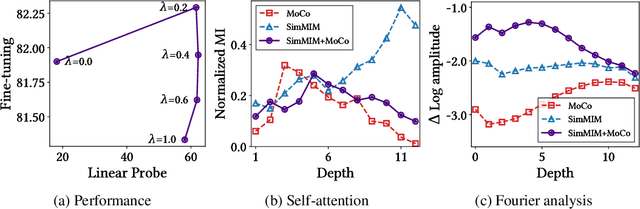
We present a comparative study on how and why contrastive learning (CL) and masked image modeling (MIM) differ in their representations and in their performance of downstream tasks. In particular, we demonstrate that self-supervised Vision Transformers (ViTs) have the following properties: (1) CL trains self-attentions to capture longer-range global patterns than MIM, such as the shape of an object, especially in the later layers of the ViT architecture. This CL property helps ViTs linearly separate images in their representation spaces. However, it also makes the self-attentions collapse into homogeneity for all query tokens and heads. Such homogeneity of self-attention reduces the diversity of representations, worsening scalability and dense prediction performance. (2) CL utilizes the low-frequency signals of the representations, but MIM utilizes high-frequencies. Since low- and high-frequency information respectively represent shapes and textures, CL is more shape-oriented and MIM more texture-oriented. (3) CL plays a crucial role in the later layers, while MIM mainly focuses on the early layers. Upon these analyses, we find that CL and MIM can complement each other and observe that even the simplest harmonization can help leverage the advantages of both methods. The code is available at https://github.com/naver-ai/cl-vs-mim.
PRSeg: A Lightweight Patch Rotate MLP Decoder for Semantic Segmentation
May 01, 2023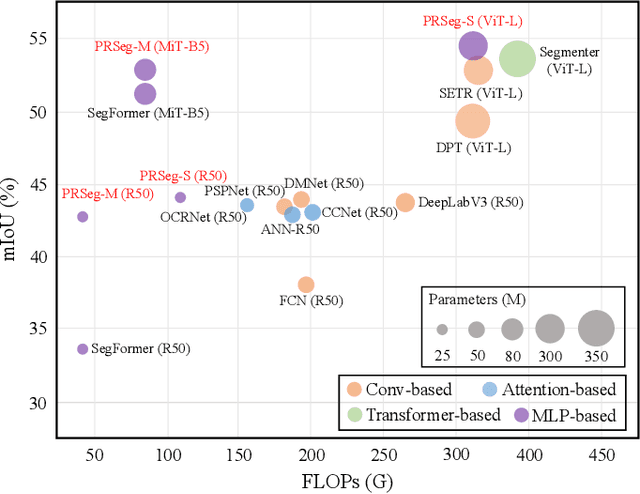
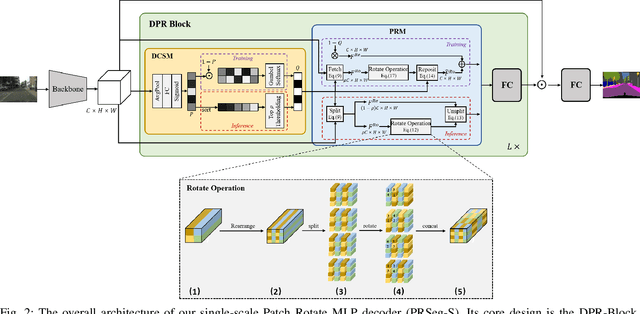
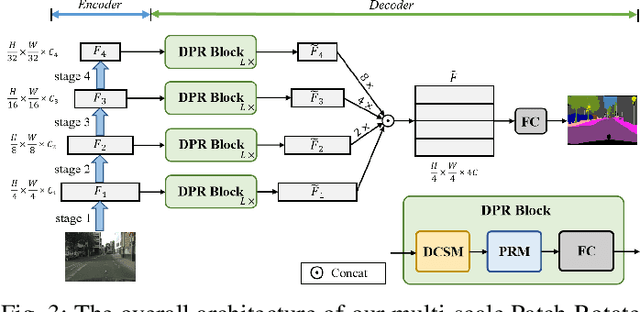

The lightweight MLP-based decoder has become increasingly promising for semantic segmentation. However, the channel-wise MLP cannot expand the receptive fields, lacking the context modeling capacity, which is critical to semantic segmentation. In this paper, we propose a parametric-free patch rotate operation to reorganize the pixels spatially. It first divides the feature map into multiple groups and then rotates the patches within each group. Based on the proposed patch rotate operation, we design a novel segmentation network, named PRSeg, which includes an off-the-shelf backbone and a lightweight Patch Rotate MLP decoder containing multiple Dynamic Patch Rotate Blocks (DPR-Blocks). In each DPR-Block, the fully connected layer is performed following a Patch Rotate Module (PRM) to exchange spatial information between pixels. Specifically, in PRM, the feature map is first split into the reserved part and rotated part along the channel dimension according to the predicted probability of the Dynamic Channel Selection Module (DCSM), and our proposed patch rotate operation is only performed on the rotated part. Extensive experiments on ADE20K, Cityscapes and COCO-Stuff 10K datasets prove the effectiveness of our approach. We expect that our PRSeg can promote the development of MLP-based decoder in semantic segmentation.
RISnet: A Scalable Approach for Reconfigurable Intelligent Surface Optimization with Partial CSI
May 01, 2023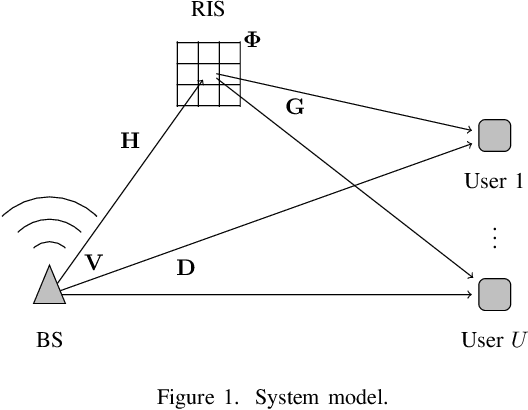


The reconfigurable intelligent surface (RIS) is a promising technology that enables wireless communication systems to achieve improved performance by intelligently manipulating wireless channels. In this paper, we consider the sum-rate maximization problem in a downlink multi-user multi-input-single-output (MISO) channel via space-division multiple access (SDMA). Two major challenges of this problem are the high dimensionality due to the large number of RIS elements and the difficulty to obtain the full channel state information (CSI), which is assumed known in many algorithms proposed in the literature. Instead, we propose a hybrid machine learning approach using the weighted minimum mean squared error (WMMSE) precoder at the base station (BS) and a dedicated neural network (NN) architecture, RISnet, for RIS configuration. The RISnet has a good scalability to optimize 1296 RIS elements and requires partial CSI of only 16 RIS elements as input. We show it achieves a high performance with low requirement for channel estimation for geometric channel models obtained with ray-tracing simulation. The unsupervised learning lets the RISnet find an optimized RIS configuration by itself. Numerical results show that a trained model configures the RIS with low computational effort, considerably outperforms the baselines, and can work with discrete phase shifts.
A High-Frequency Focused Network for Lightweight Single Image Super-Resolution
Mar 21, 2023
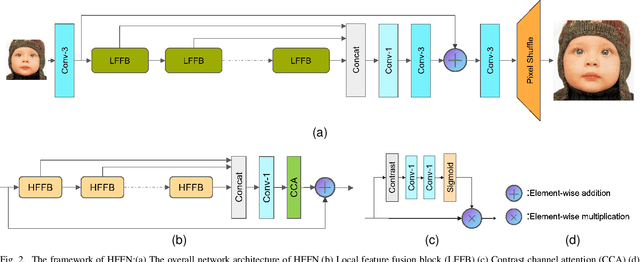
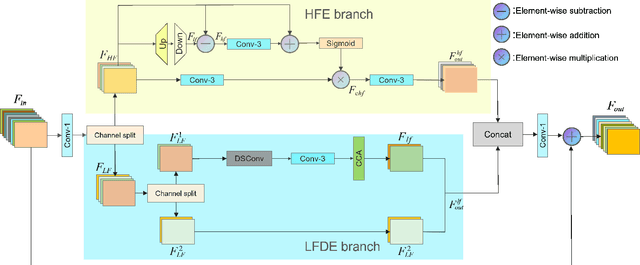

Lightweight neural networks for single-image super-resolution (SISR) tasks have made substantial breakthroughs in recent years. Compared to low-frequency information, high-frequency detail is much more difficult to reconstruct. Most SISR models allocate equal computational resources for low-frequency and high-frequency information, which leads to redundant processing of simple low-frequency information and inadequate recovery of more challenging high-frequency information. We propose a novel High-Frequency Focused Network (HFFN) through High-Frequency Focused Blocks (HFFBs) that selectively enhance high-frequency information while minimizing redundant feature computation of low-frequency information. The HFFB effectively allocates more computational resources to the more challenging reconstruction of high-frequency information. Moreover, we propose a Local Feature Fusion Block (LFFB) effectively fuses features from multiple HFFBs in a local region, utilizing complementary information across layers to enhance feature representativeness and reduce artifacts in reconstructed images. We assess the efficacy of our proposed HFFN on five benchmark datasets and show that it significantly enhances the super-resolution performance of the network. Our experimental results demonstrate state-of-the-art performance in reconstructing high-frequency information while using a low number of parameters.
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 24, 2023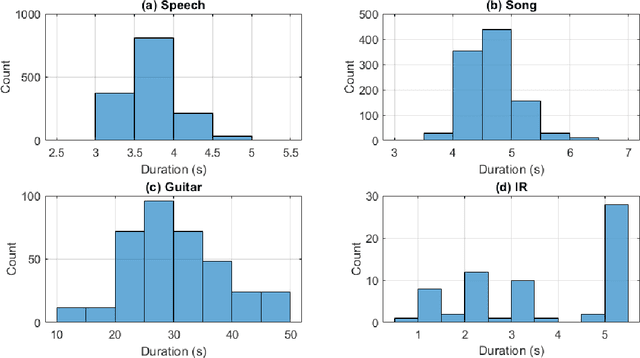
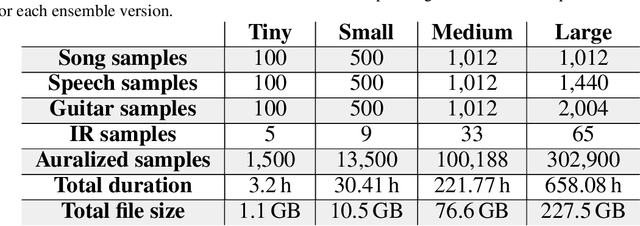
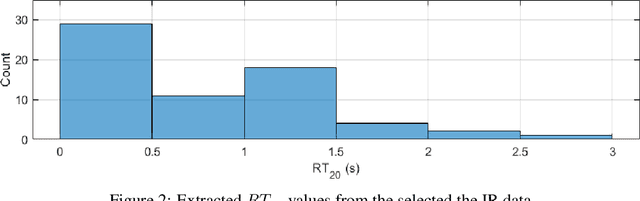
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
LaMP: When Large Language Models Meet Personalization
Apr 22, 2023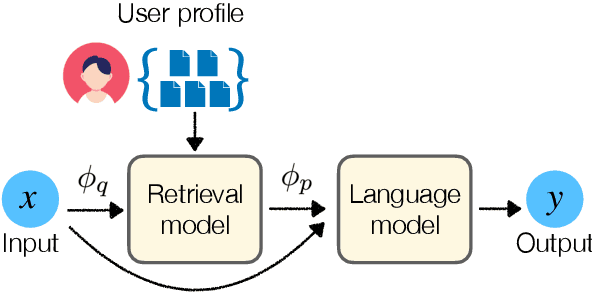
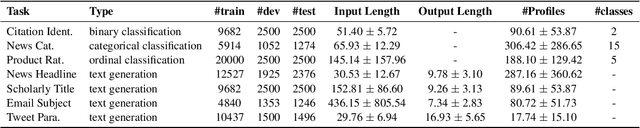
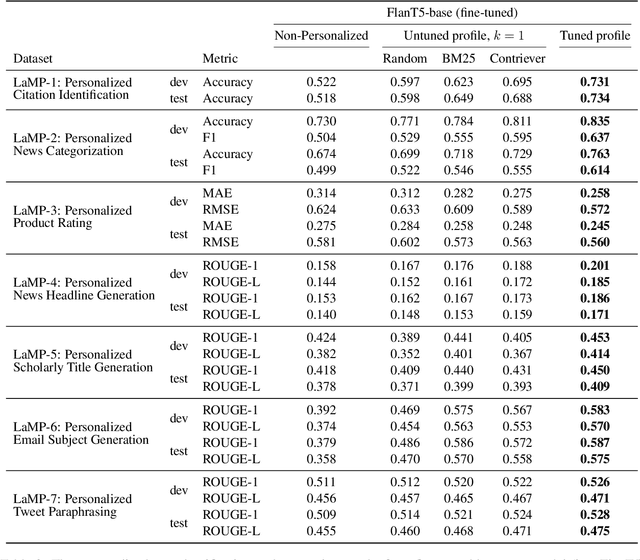

This paper highlights the importance of personalization in the current state of natural language understanding and generation and introduces the LaMP benchmark -- a novel benchmark for training and evaluating language models for producing personalized outputs. LaMP offers a comprehensive evaluation framework with diverse language tasks and multiple entries for each user profile. It consists of seven personalized tasks, spanning three classification and four text generation tasks. We also propose a retrieval augmentation approach that retrieves personalized items from user profiles to construct personalized prompts for large language models. Our baseline zero-shot and fine-tuned model results indicate that LMs utilizing profile augmentation outperform their counterparts that do not factor in profile information.
Modality-Aware Negative Sampling for Multi-modal Knowledge Graph Embedding
Apr 23, 2023
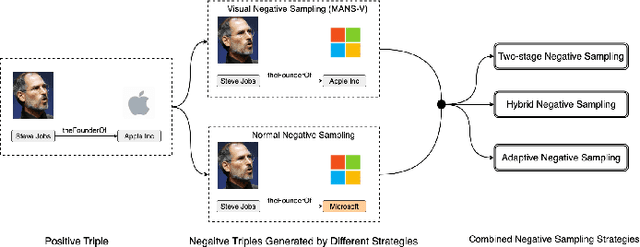
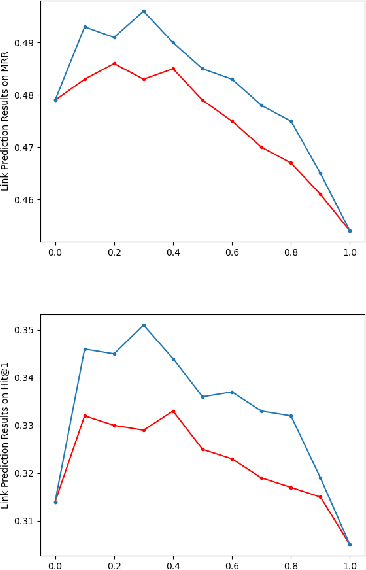
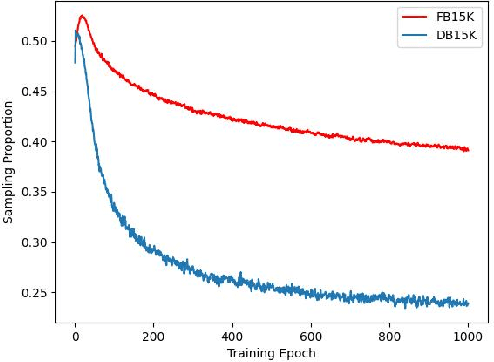
Negative sampling (NS) is widely used in knowledge graph embedding (KGE), which aims to generate negative triples to make a positive-negative contrast during training. However, existing NS methods are unsuitable when multi-modal information is considered in KGE models. They are also inefficient due to their complex design. In this paper, we propose Modality-Aware Negative Sampling (MANS) for multi-modal knowledge graph embedding (MMKGE) to address the mentioned problems. MANS could align structural and visual embeddings for entities in KGs and learn meaningful embeddings to perform better in multi-modal KGE while keeping lightweight and efficient. Empirical results on two benchmarks demonstrate that MANS outperforms existing NS methods. Meanwhile, we make further explorations about MANS to confirm its effectiveness.
Multi-target multi-camera vehicle tracking using transformer-based camera link model and spatial-temporal information
Jan 18, 2023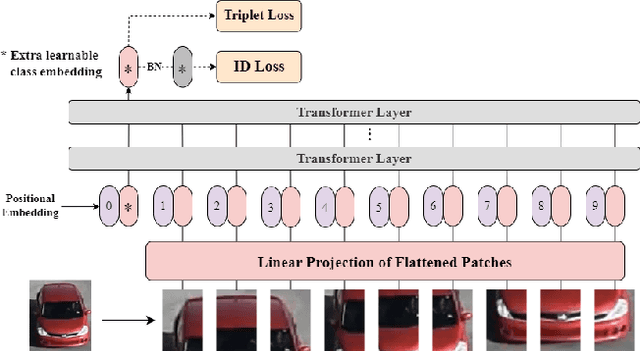
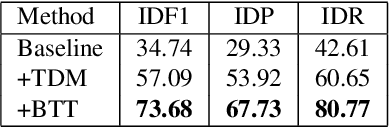

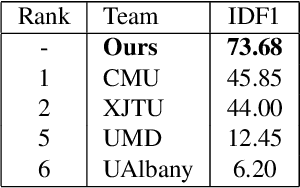
Multi-target multi-camera tracking (MTMCT) of vehicles, i.e. tracking vehicles across multiple cameras, is a crucial application for the development of smart city and intelligent traffic system. The main challenges of MTMCT of vehicles include the intra-class variability of the same vehicle and inter-class similarity between different vehicles and how to associate the same vehicle accurately across different cameras under large search space. Previous methods for MTMCT usually use hierarchical clustering of trajectories to conduct cross camera association. However, the search space can be large and does not take spatial and temporal information into consideration. In this paper, we proposed a transformer-based camera link model with spatial and temporal filtering to conduct cross camera tracking. Achieving 73.68% IDF1 on the Nvidia Cityflow V2 dataset test set, showing the effectiveness of our camera link model on multi-target multi-camera tracking.
Hyperspectral Image Super-Resolution via Dual-domain Network Based on Hybrid Convolution
Apr 11, 2023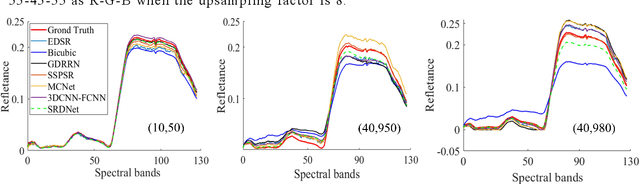
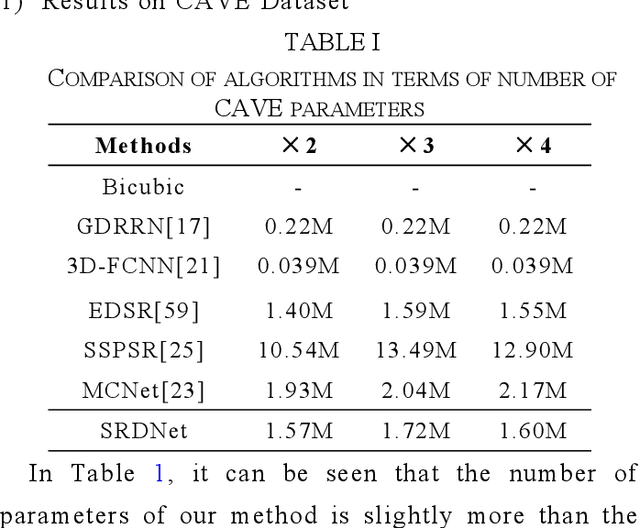
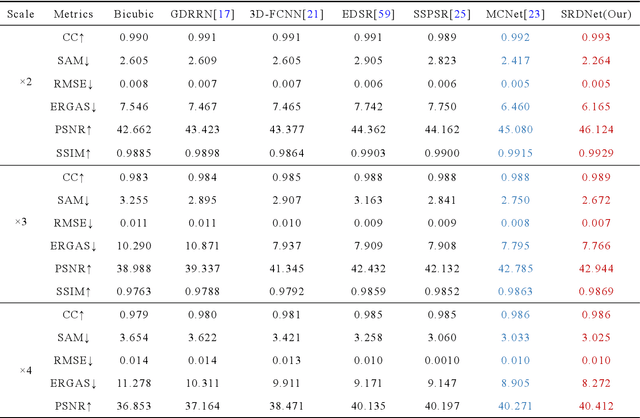
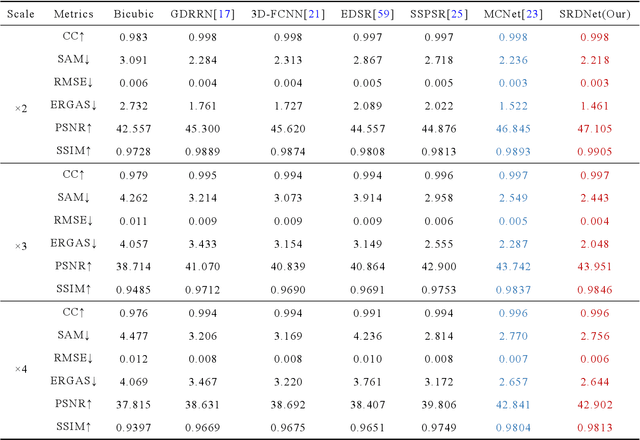
Since the number of incident energies is limited, it is difficult to directly acquire hyperspectral images (HSI) with high spatial resolution. Considering the high dimensionality and correlation of HSI, super-resolution (SR) of HSI remains a challenge in the absence of auxiliary high-resolution images. Furthermore, it is very important to extract the spatial features effectively and make full use of the spectral information. This paper proposes a novel HSI super-resolution algorithm, termed dual-domain network based on hybrid convolution (SRDNet). Specifically, a dual-domain network is designed to fully exploit the spatial-spectral and frequency information among the hyper-spectral data. To capture inter-spectral self-similarity, a self-attention learning mechanism (HSL) is devised in the spatial domain. Meanwhile the pyramid structure is applied to increase the acceptance field of attention, which further reinforces the feature representation ability of the network. Moreover, to further improve the perceptual quality of HSI, a frequency loss(HFL) is introduced to optimize the model in the frequency domain. The dynamic weighting mechanism drives the network to gradually refine the generated frequency and excessive smoothing caused by spatial loss. Finally, In order to better fully obtain the mapping relationship between high-resolution space and low-resolution space, a hybrid module of 2D and 3D units with progressive upsampling strategy is utilized in our method. Experiments on a widely used benchmark dataset illustrate that the proposed SRDNet method enhances the texture information of HSI and is superior to state-of-the-art methods.
Mutual Information Learned Classifiers: an Information-theoretic Viewpoint of Training Deep Learning Classification Systems
Sep 21, 2022


Deep learning systems have been reported to achieve state-of-the-art performances in many applications, and a key is the existence of well trained classifiers on benchmark datasets. As a main-stream loss function, the cross entropy can easily lead us to find models which demonstrate severe overfitting behavior. In this paper, we show that the existing cross entropy loss minimization problem essentially learns the label conditional entropy (CE) of the underlying data distribution of the dataset. However, the CE learned in this way does not characterize well the information shared by the label and the input. In this paper, we propose a mutual information learning framework where we train deep neural network classifiers via learning the mutual information between the label and the input. Theoretically, we give the population classification error lower bound in terms of the mutual information. In addition, we derive the mutual information lower and upper bounds for a concrete binary classification data model in $\mathbb{R}^n$, and also the error probability lower bound in this scenario. Empirically, we conduct extensive experiments on several benchmark datasets to support our theory. The mutual information learned classifiers (MILCs) achieve far better generalization performances than the conditional entropy learned classifiers (CELCs) with an improvement which can exceed more than 10\% in testing accuracy.