 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A baseline on continual learning methods for video action recognition
Apr 26, 2023
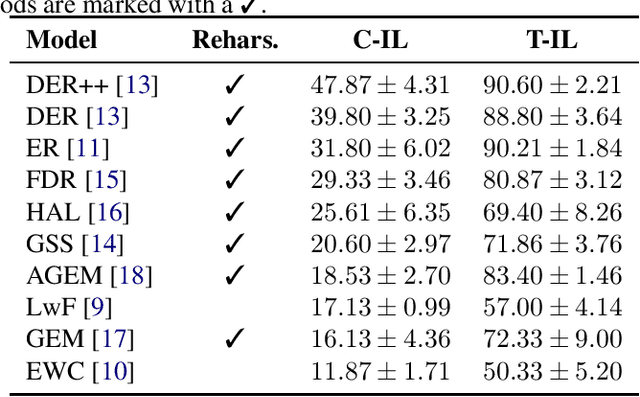
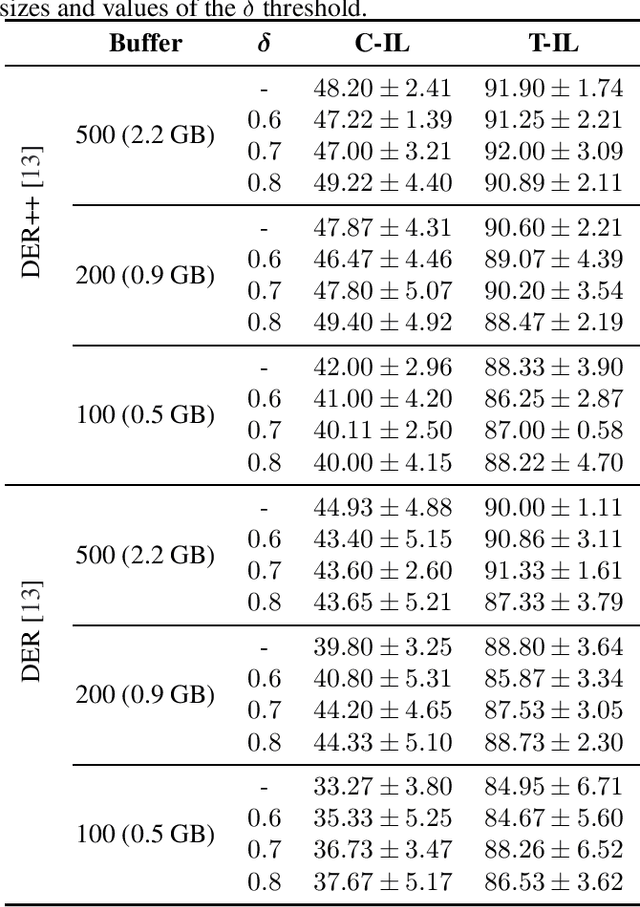
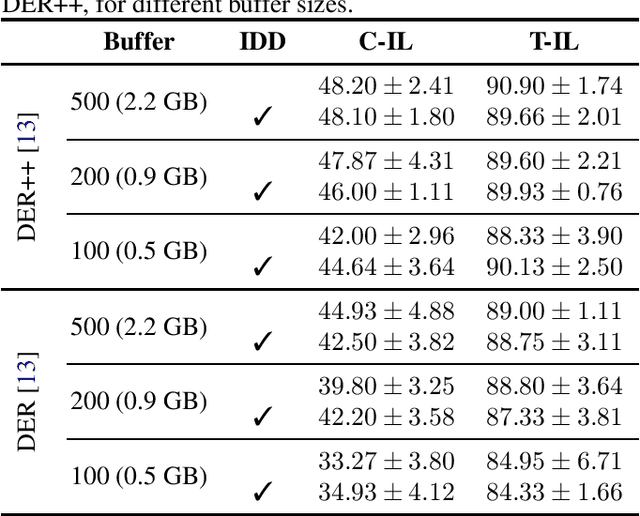
Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
Shades of meaning: Uncovering the geometry of ambiguous word representations through contextualised language models
Apr 26, 2023
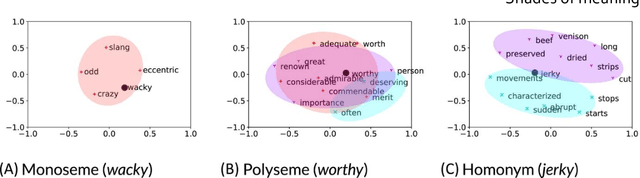
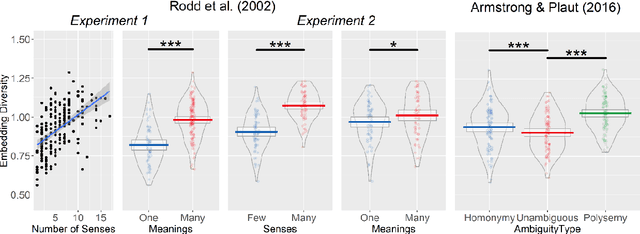
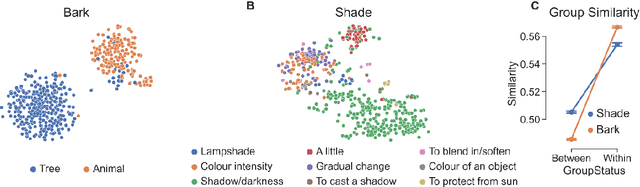
Lexical ambiguity presents a profound and enduring challenge to the language sciences. Researchers for decades have grappled with the problem of how language users learn, represent and process words with more than one meaning. Our work offers new insight into psychological understanding of lexical ambiguity through a series of simulations that capitalise on recent advances in contextual language models. These models have no grounded understanding of the meanings of words at all; they simply learn to predict words based on the surrounding context provided by other words. Yet, our analyses show that their representations capture fine-grained meaningful distinctions between unambiguous, homonymous, and polysemous words that align with lexicographic classifications and psychological theorising. These findings provide quantitative support for modern psychological conceptualisations of lexical ambiguity and raise new challenges for understanding of the way that contextual information shapes the meanings of words across different timescales.
Source-Filter-Based Generative Adversarial Neural Vocoder for High Fidelity Speech Synthesis
Apr 26, 2023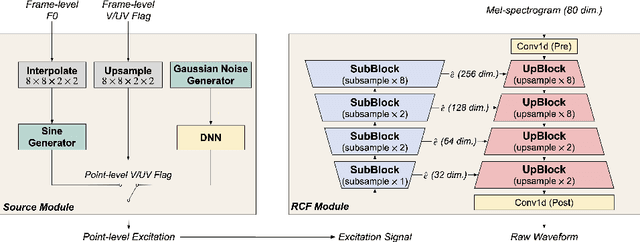
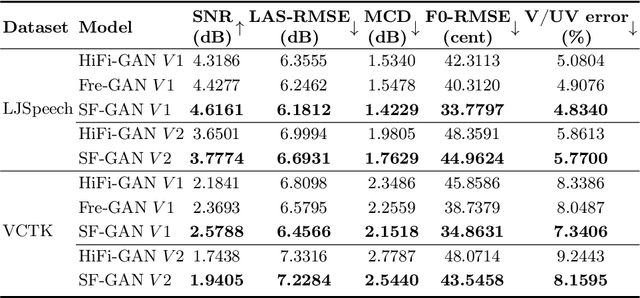
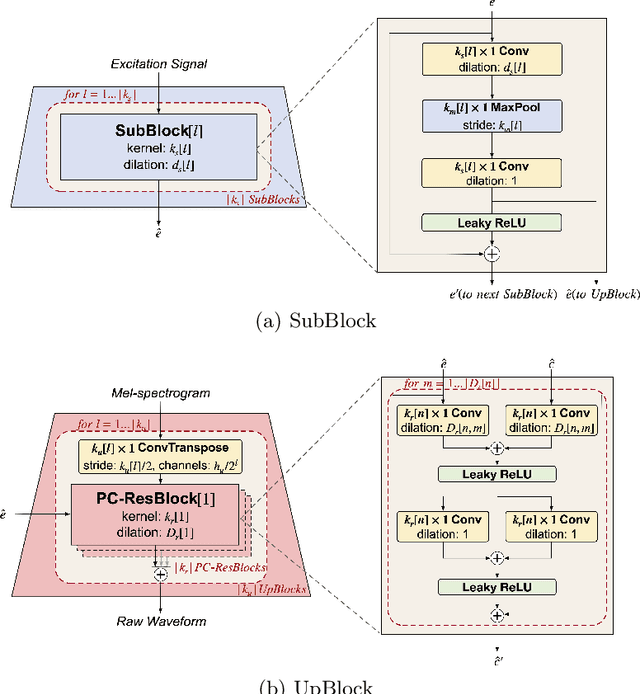
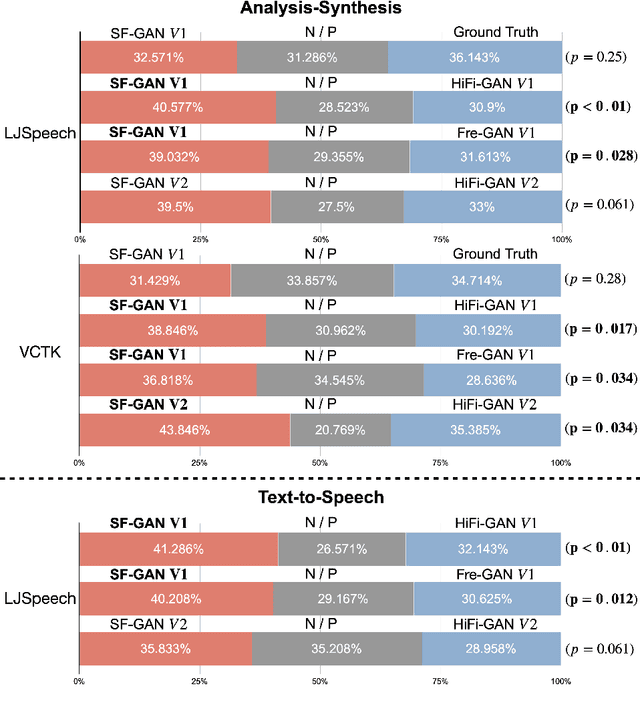
This paper proposes a source-filter-based generative adversarial neural vocoder named SF-GAN, which achieves high-fidelity waveform generation from input acoustic features by introducing F0-based source excitation signals to a neural filter framework. The SF-GAN vocoder is composed of a source module and a resolution-wise conditional filter module and is trained based on generative adversarial strategies. The source module produces an excitation signal from the F0 information, then the resolution-wise convolutional filter module combines the excitation signal with processed acoustic features at various temporal resolutions and finally reconstructs the raw waveform. The experimental results show that our proposed SF-GAN vocoder outperforms the state-of-the-art HiFi-GAN and Fre-GAN in both analysis-synthesis (AS) and text-to-speech (TTS) tasks, and the synthesized speech quality of SF-GAN is comparable to the ground-truth audio.
Learning Task-Specific Strategies for Accelerated MRI
Apr 25, 2023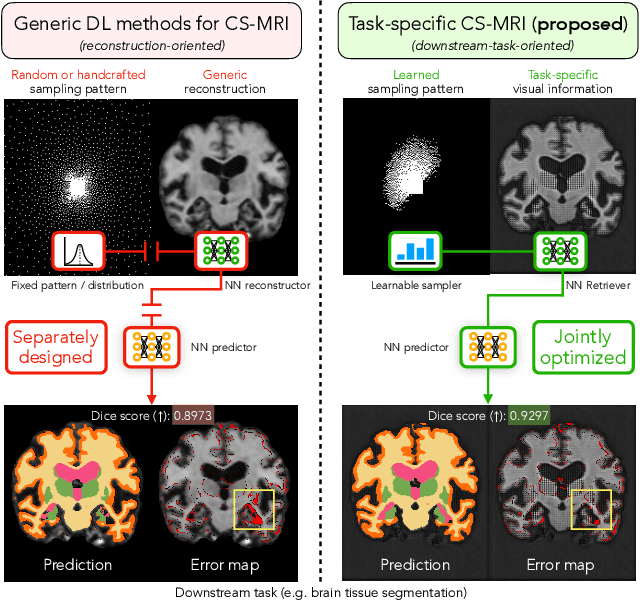
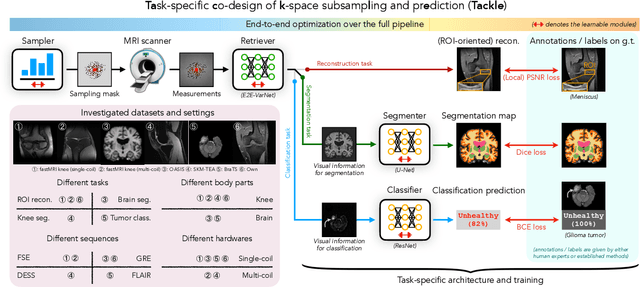

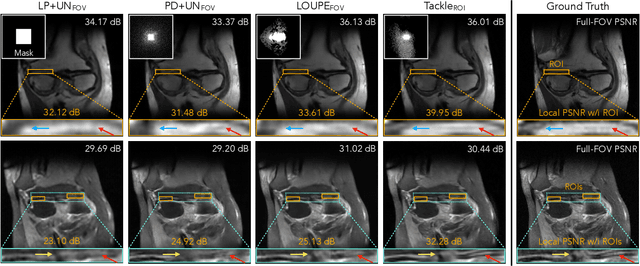
Compressed sensing magnetic resonance imaging (CS-MRI) seeks to recover visual information from subsampled measurements for diagnostic tasks. Traditional CS-MRI methods often separately address measurement subsampling, image reconstruction, and task prediction, resulting in suboptimal end-to-end performance. In this work, we propose TACKLE as a unified framework for designing CS-MRI systems tailored to specific tasks. Leveraging recent co-design techniques, TACKLE jointly optimizes subsampling, reconstruction, and prediction strategies to enhance the performance on the downstream task. Our results on multiple public MRI datasets show that the proposed framework achieves improved performance on various tasks over traditional CS-MRI methods. We also evaluate the generalization ability of TACKLE by experimentally collecting a new dataset using different acquisition setups from the training data. Without additional fine-tuning, TACKLE functions robustly and leads to both numerical and visual improvements.
An Information-Theoretic Approach to Transferability in Task Transfer Learning
Dec 20, 2022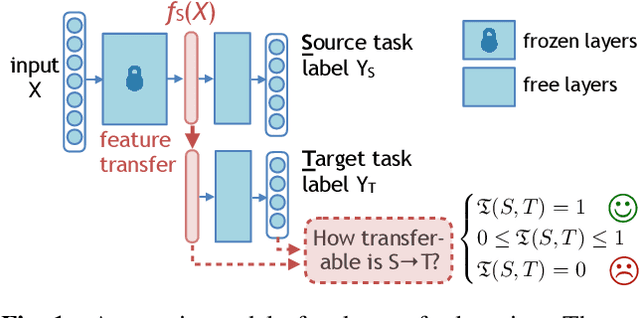
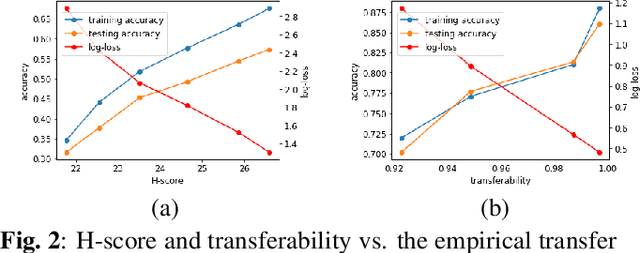
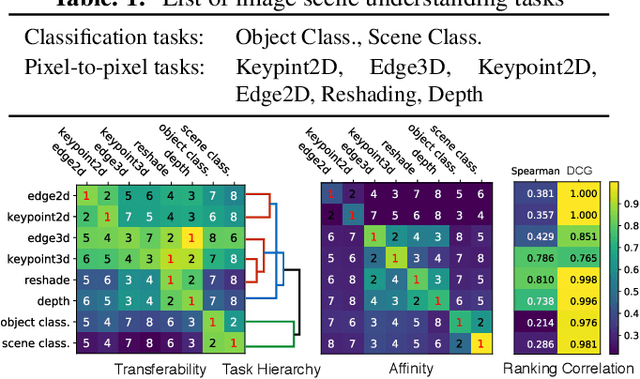
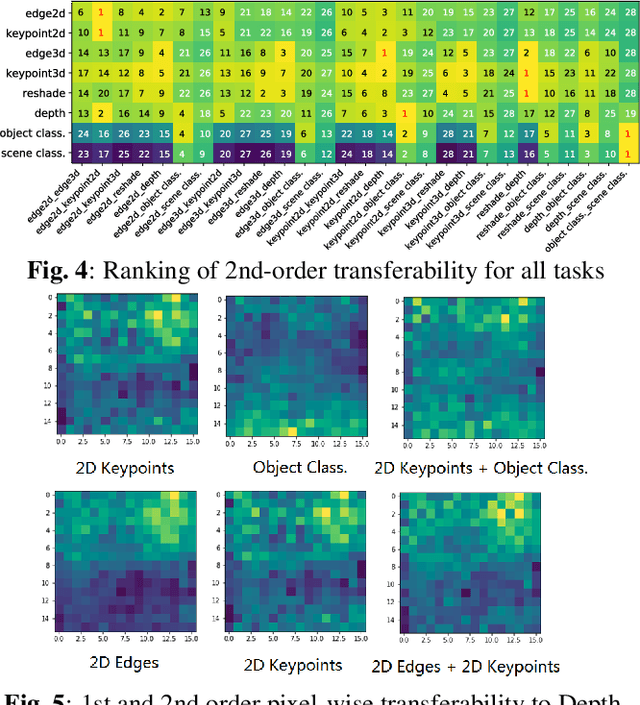
Task transfer learning is a popular technique in image processing applications that uses pre-trained models to reduce the supervision cost of related tasks. An important question is to determine task transferability, i.e. given a common input domain, estimating to what extent representations learned from a source task can help in learning a target task. Typically, transferability is either measured experimentally or inferred through task relatedness, which is often defined without a clear operational meaning. In this paper, we present a novel metric, H-score, an easily-computable evaluation function that estimates the performance of transferred representations from one task to another in classification problems using statistical and information theoretic principles. Experiments on real image data show that our metric is not only consistent with the empirical transferability measurement, but also useful to practitioners in applications such as source model selection and task transfer curriculum learning.
Contextual information integration for stance detection via cross-attention
Nov 03, 2022
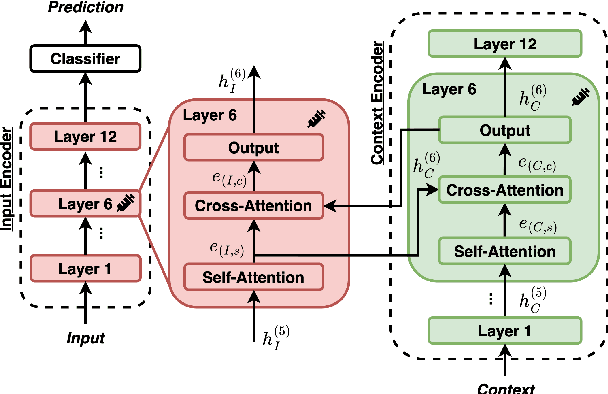
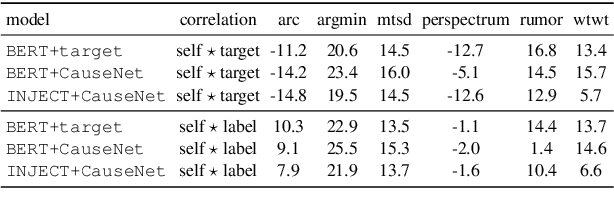
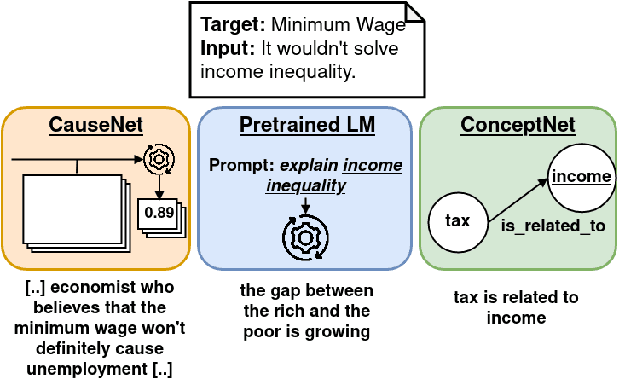
Stance detection deals with the identification of an author's stance towards a target and is applied on various text domains like social media and news. In many cases, inferring the stance is challenging due to insufficient access to contextual information. Complementary context can be found in knowledge bases but integrating the context into pretrained language models is non-trivial due to their graph structure. In contrast, we explore an approach to integrate contextual information as text which aligns better with transformer architectures. Specifically, we train a model consisting of dual encoders which exchange information via cross-attention. This architecture allows for integrating contextual information from heterogeneous sources. We evaluate context extracted from structured knowledge sources and from prompting large language models. Our approach is able to outperform competitive baselines (1.9pp on average) on a large and diverse stance detection benchmark, both (1) in-domain, i.e. for seen targets, and (2) out-of-domain, i.e. for targets unseen during training. Our analysis shows that it is able to regularize for spurious label correlations with target-specific cue words.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 01, 2023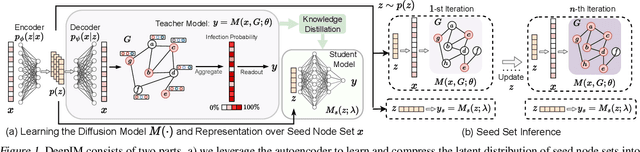
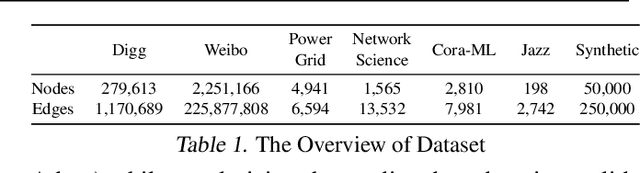
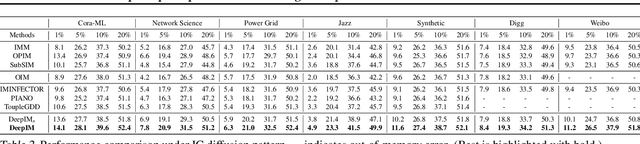
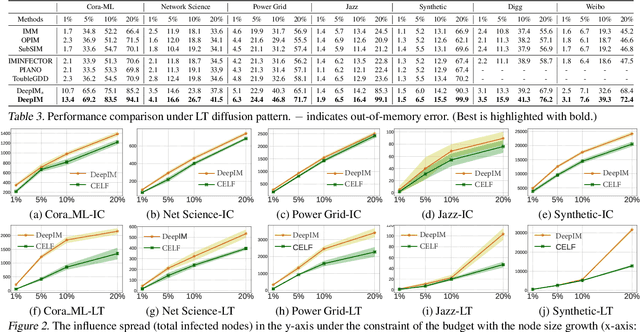
Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.
What Do Self-Supervised Vision Transformers Learn?
May 01, 2023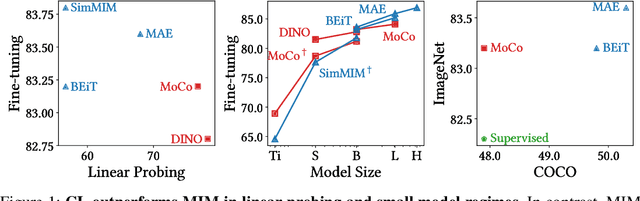
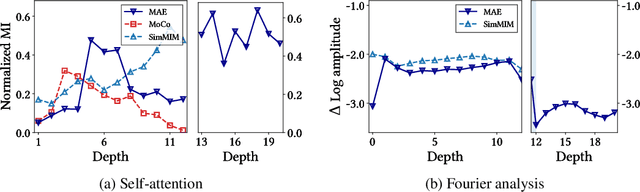
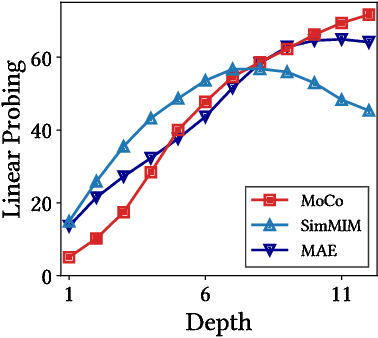
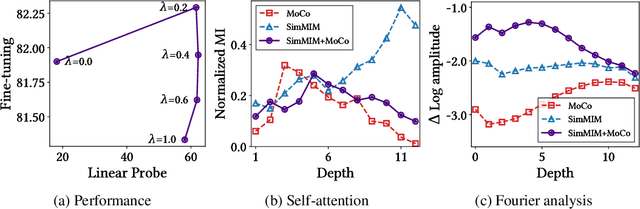
We present a comparative study on how and why contrastive learning (CL) and masked image modeling (MIM) differ in their representations and in their performance of downstream tasks. In particular, we demonstrate that self-supervised Vision Transformers (ViTs) have the following properties: (1) CL trains self-attentions to capture longer-range global patterns than MIM, such as the shape of an object, especially in the later layers of the ViT architecture. This CL property helps ViTs linearly separate images in their representation spaces. However, it also makes the self-attentions collapse into homogeneity for all query tokens and heads. Such homogeneity of self-attention reduces the diversity of representations, worsening scalability and dense prediction performance. (2) CL utilizes the low-frequency signals of the representations, but MIM utilizes high-frequencies. Since low- and high-frequency information respectively represent shapes and textures, CL is more shape-oriented and MIM more texture-oriented. (3) CL plays a crucial role in the later layers, while MIM mainly focuses on the early layers. Upon these analyses, we find that CL and MIM can complement each other and observe that even the simplest harmonization can help leverage the advantages of both methods. The code is available at https://github.com/naver-ai/cl-vs-mim.
PRSeg: A Lightweight Patch Rotate MLP Decoder for Semantic Segmentation
May 01, 2023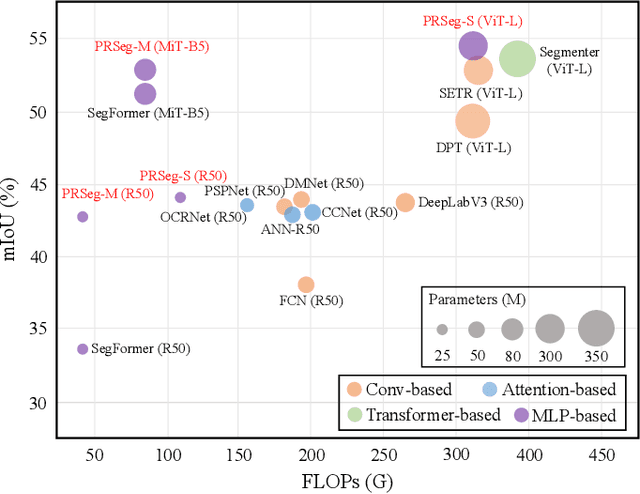
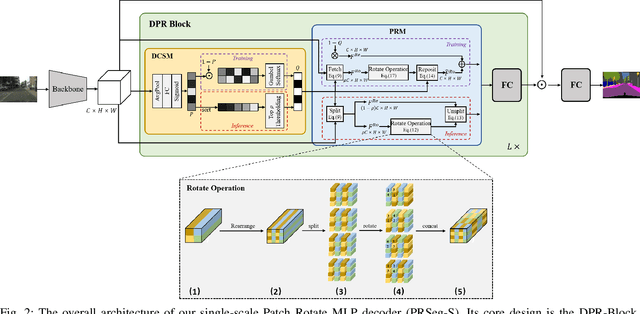
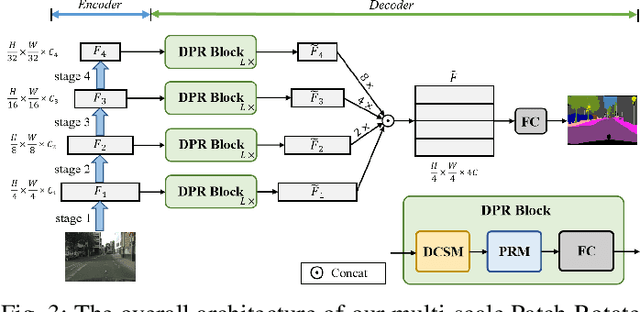

The lightweight MLP-based decoder has become increasingly promising for semantic segmentation. However, the channel-wise MLP cannot expand the receptive fields, lacking the context modeling capacity, which is critical to semantic segmentation. In this paper, we propose a parametric-free patch rotate operation to reorganize the pixels spatially. It first divides the feature map into multiple groups and then rotates the patches within each group. Based on the proposed patch rotate operation, we design a novel segmentation network, named PRSeg, which includes an off-the-shelf backbone and a lightweight Patch Rotate MLP decoder containing multiple Dynamic Patch Rotate Blocks (DPR-Blocks). In each DPR-Block, the fully connected layer is performed following a Patch Rotate Module (PRM) to exchange spatial information between pixels. Specifically, in PRM, the feature map is first split into the reserved part and rotated part along the channel dimension according to the predicted probability of the Dynamic Channel Selection Module (DCSM), and our proposed patch rotate operation is only performed on the rotated part. Extensive experiments on ADE20K, Cityscapes and COCO-Stuff 10K datasets prove the effectiveness of our approach. We expect that our PRSeg can promote the development of MLP-based decoder in semantic segmentation.
RISnet: A Scalable Approach for Reconfigurable Intelligent Surface Optimization with Partial CSI
May 01, 2023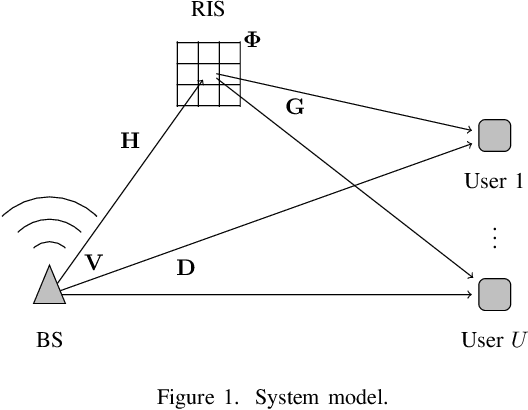


The reconfigurable intelligent surface (RIS) is a promising technology that enables wireless communication systems to achieve improved performance by intelligently manipulating wireless channels. In this paper, we consider the sum-rate maximization problem in a downlink multi-user multi-input-single-output (MISO) channel via space-division multiple access (SDMA). Two major challenges of this problem are the high dimensionality due to the large number of RIS elements and the difficulty to obtain the full channel state information (CSI), which is assumed known in many algorithms proposed in the literature. Instead, we propose a hybrid machine learning approach using the weighted minimum mean squared error (WMMSE) precoder at the base station (BS) and a dedicated neural network (NN) architecture, RISnet, for RIS configuration. The RISnet has a good scalability to optimize 1296 RIS elements and requires partial CSI of only 16 RIS elements as input. We show it achieves a high performance with low requirement for channel estimation for geometric channel models obtained with ray-tracing simulation. The unsupervised learning lets the RISnet find an optimized RIS configuration by itself. Numerical results show that a trained model configures the RIS with low computational effort, considerably outperforms the baselines, and can work with discrete phase shifts.