 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Image-text Retrieval via preserving main Semantics of Vision
Apr 20, 2023
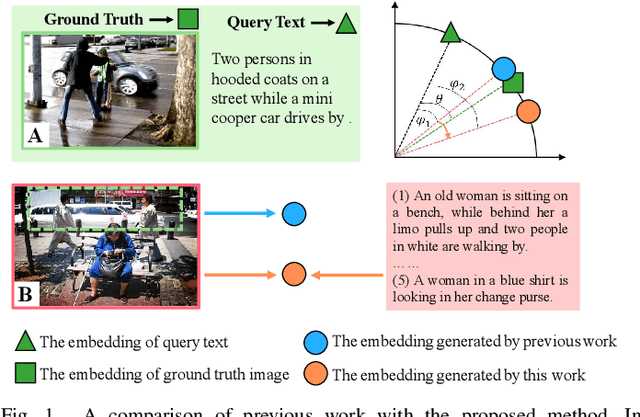
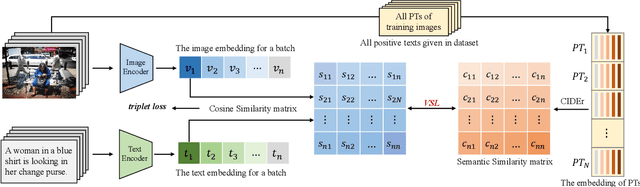

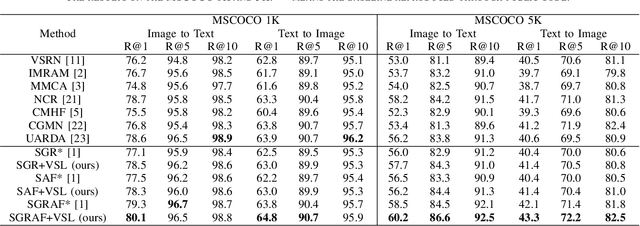
Image-text retrieval is one of the major tasks of cross-modal retrieval. Several approaches for this task map images and texts into a common space to create correspondences between the two modalities. However, due to the content (semantics) richness of an image, redundant secondary information in an image may cause false matches. To address this issue, this paper presents a semantic optimization approach, implemented as a Visual Semantic Loss (VSL), to assist the model in focusing on an image's main content. This approach is inspired by how people typically annotate the content of an image by describing its main content. Thus, we leverage the annotated texts corresponding to an image to assist the model in capturing the main content of the image, reducing the negative impact of secondary content. Extensive experiments on two benchmark datasets (MSCOCO and Flickr30K) demonstrate the superior performance of our method. The code is available at: https://github.com/ZhangXu0963/VSL.
Emergence of Symbols in Neural Networks for Semantic Understanding and Communication
Apr 20, 2023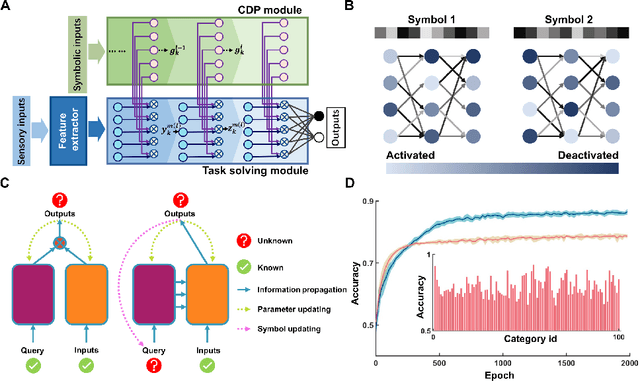
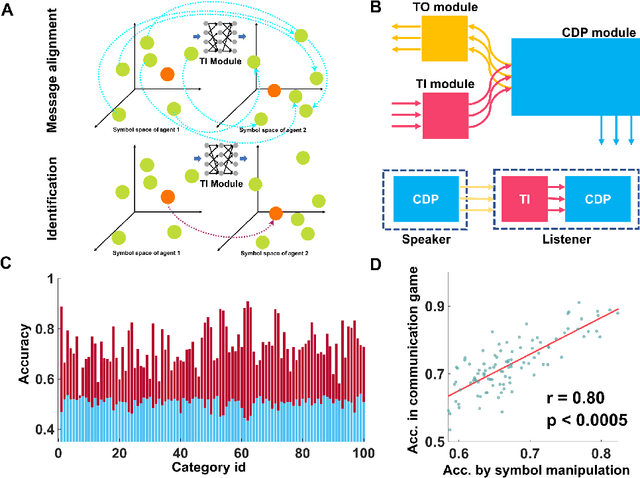
Being able to create meaningful symbols and proficiently use them for higher cognitive functions such as communication, reasoning, planning, etc., is essential and unique for human intelligence. Current deep neural networks are still far behind human's ability to create symbols for such higher cognitive functions. Here we propose a solution, named SEA-net, to endow neural networks with ability of symbol creation, semantic understanding and communication. SEA-net generates symbols that dynamically configure the network to perform specific tasks. These symbols capture compositional semantic information that enables the system to acquire new functions purely by symbolic manipulation or communication. In addition, we found that these self-generated symbols exhibit an intrinsic structure resembling that of natural language, suggesting a common framework underlying the generation and understanding of symbols in both human brains and artificial neural networks. We hope that it will be instrumental in producing more capable systems in the future that can synergize the strengths of connectionist and symbolic approaches for AI.
DropDim: A Regularization Method for Transformer Networks
Apr 20, 2023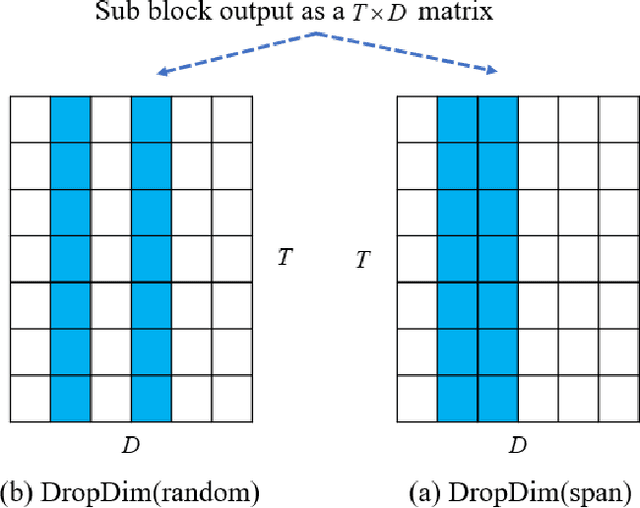
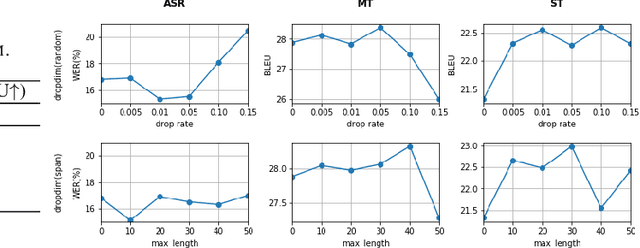
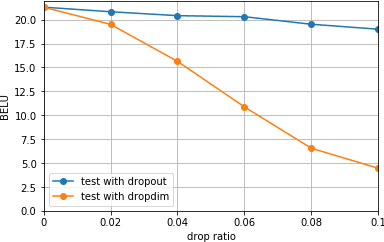
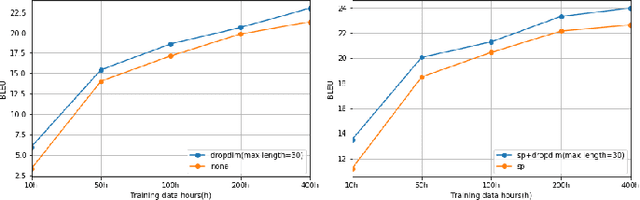
We introduceDropDim, a structured dropout method designed for regularizing the self-attention mechanism, which is a key component of the transformer. In contrast to the general dropout method, which randomly drops neurons, DropDim drops part of the embedding dimensions. In this way, the semantic information can be completely discarded. Thus, the excessive coadapting between different embedding dimensions can be broken, and the self-attention is forced to encode meaningful featureswith a certain number of embedding dimensions erased. Experiments on a wide range of tasks executed on the MUST-C English-Germany dataset show that DropDim can effectively improve model performance, reduce over-fitting, and show complementary effects with other regularization methods. When combined with label smoothing, the WER can be reduced from 19.1% to 15.1% on the ASR task, and the BLEU value can be increased from26.90 to 28.38 on the MT task. On the ST task, the model can reach a BLEU score of 22.99, an increase by 1.86 BLEU points compared to the strong baseline.
Rethinking matching-based few-shot action recognition
Mar 28, 2023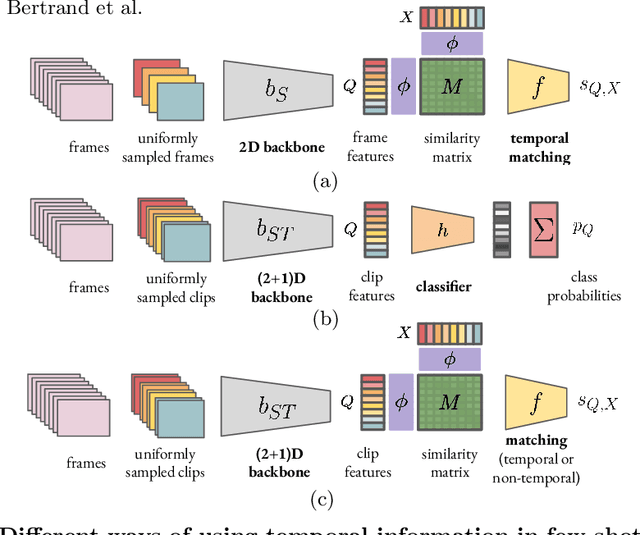
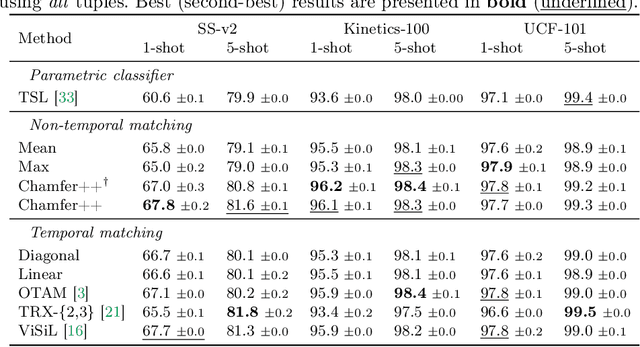
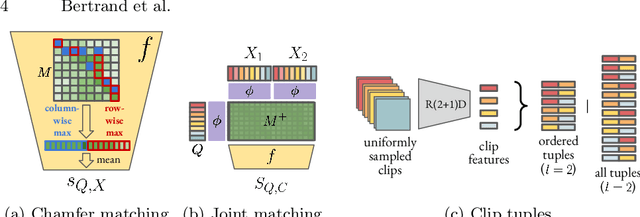
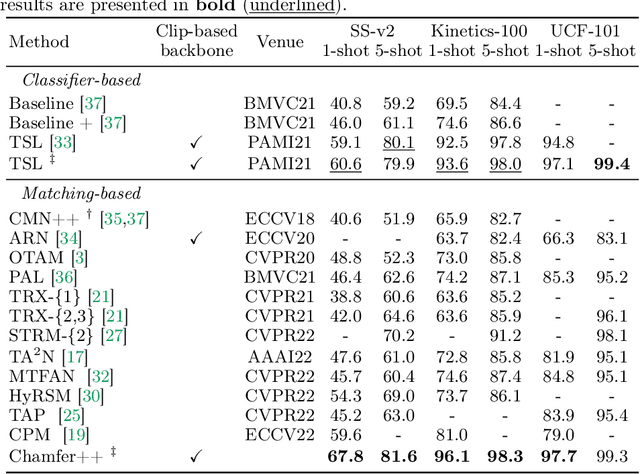
Few-shot action recognition, i.e. recognizing new action classes given only a few examples, benefits from incorporating temporal information. Prior work either encodes such information in the representation itself and learns classifiers at test time, or obtains frame-level features and performs pairwise temporal matching. We first evaluate a number of matching-based approaches using features from spatio-temporal backbones, a comparison missing from the literature, and show that the gap in performance between simple baselines and more complicated methods is significantly reduced. Inspired by this, we propose Chamfer++, a non-temporal matching function that achieves state-of-the-art results in few-shot action recognition. We show that, when starting from temporal features, our parameter-free and interpretable approach can outperform all other matching-based and classifier methods for one-shot action recognition on three common datasets without using temporal information in the matching stage. Project page: https://jbertrand89.github.io/matching-based-fsar
Performance Analysis of Free-Space Information Sharing in Full-Duplex Semantic Communications
Nov 27, 2022

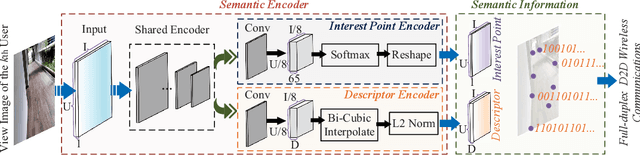
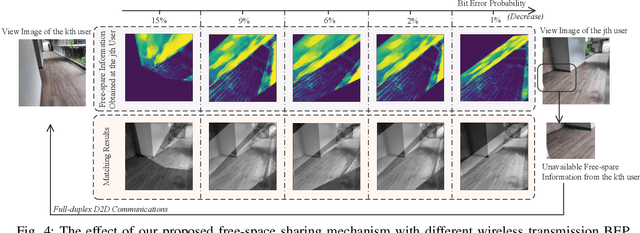
In next-generation Internet services, such as Metaverse, the mixed reality (MR) technique plays a vital role. Yet the limited computing capacity of the user-side MR headset-mounted device (HMD) prevents its further application, especially in scenarios that require a lot of computation. One way out of this dilemma is to design an efficient information sharing scheme among users to replace the heavy and repetitive computation. In this paper, we propose a free-space information sharing mechanism based on full-duplex device-to-device (D2D) semantic communications. Specifically, the view images of MR users in the same real-world scenario may be analogous. Therefore, when one user (i.e., a device) completes some computation tasks, the user can send his own calculation results and the semantic features extracted from the user's own view image to nearby users (i.e., other devices). On this basis, other users can use the received semantic features to obtain the spatial matching of the computational results under their own view images without repeating the computation. Using generalized small-scale fading models, we analyze the key performance indicators of full-duplex D2D communications, including channel capacity and bit error probability, which directly affect the transmission of semantic information. Finally, the numerical analysis experiment proves the effectiveness of our proposed methods.
Diffusion Model for GPS Trajectory Generation
Apr 23, 2023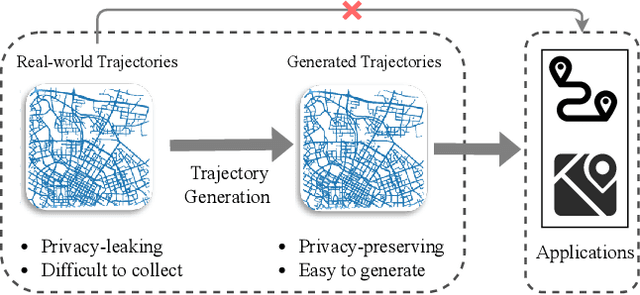
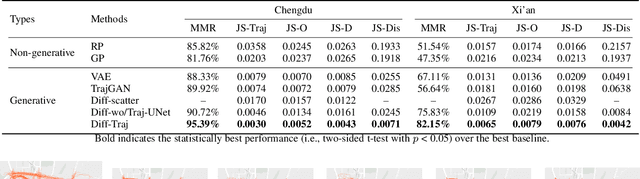
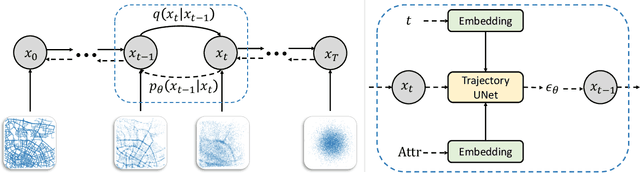

With the deployment of GPS-enabled devices and data acquisition technology, the massively generated GPS trajectory data provide a core support for advancing spatial-temporal data mining research. Nonetheless, GPS trajectories comprise personal geo-location information, rendering inevitable privacy concerns on plain data. One promising solution to this problem is trajectory generation, replacing the original data with the generated privacy-free ones. However, owing to the complex and stochastic behavior of human activities, generating high-quality trajectories is still in its infancy. To achieve the objective, we propose a diffusion-based trajectory generation (Diff-Traj) framework, effectively integrating the generation capability of the diffusion model and learning from the spatial-temporal features of trajectories. Specifically, we gradually convert real trajectories to noise through a forward trajectory noising process. Then, Diff-Traj reconstructs forged trajectories from the noise by a reverse trajectory denoising process. In addition, we design a trajectory UNet (Traj-UNet) structure to extract trajectory features for noise level prediction during the reverse process. Experiments on two real-world datasets show that Diff-Traj can be intuitively applied to generate high-quality trajectories while retaining the original distribution.
Bi-Level Attention Graph Neural Networks
Apr 23, 2023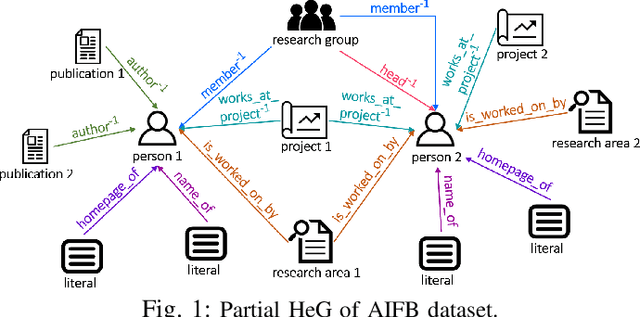
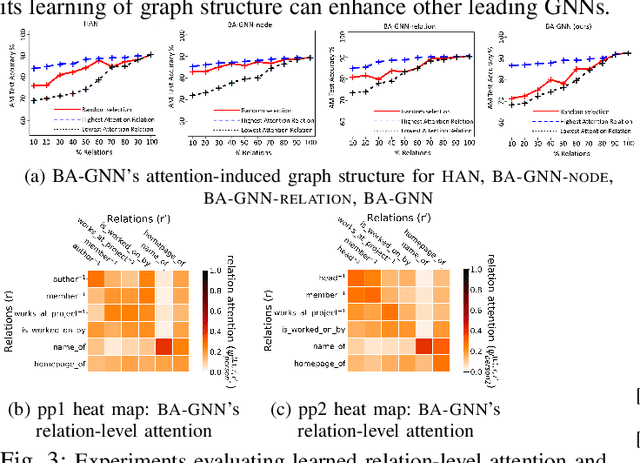
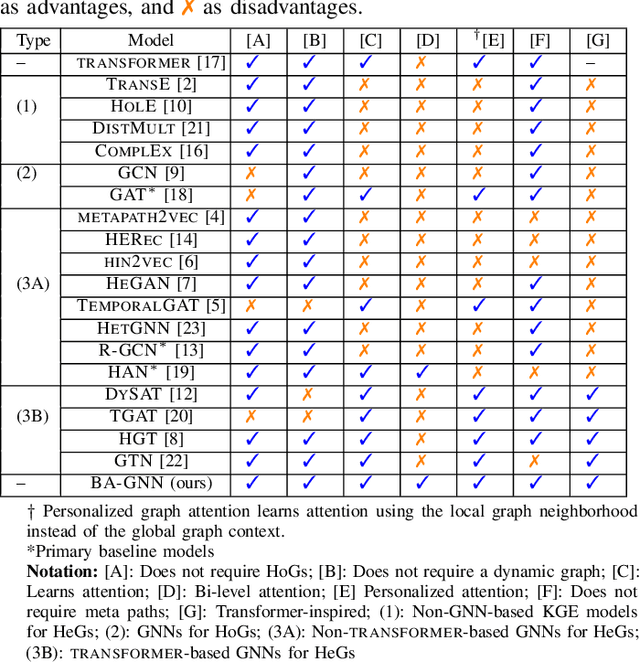
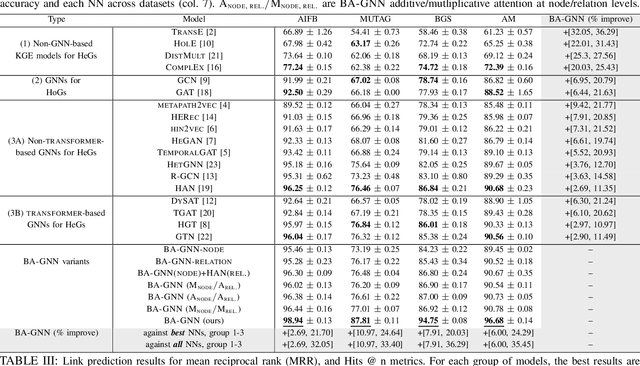
Recent graph neural networks (GNNs) with the attention mechanism have historically been limited to small-scale homogeneous graphs (HoGs). However, GNNs handling heterogeneous graphs (HeGs), which contain several entity and relation types, all have shortcomings in handling attention. Most GNNs that learn graph attention for HeGs learn either node-level or relation-level attention, but not both, limiting their ability to predict both important entities and relations in the HeG. Even the best existing method that learns both levels of attention has the limitation of assuming graph relations are independent and that its learned attention disregards this dependency association. To effectively model both multi-relational and multi-entity large-scale HeGs, we present Bi-Level Attention Graph Neural Networks (BA-GNN), scalable neural networks (NNs) that use a novel bi-level graph attention mechanism. BA-GNN models both node-node and relation-relation interactions in a personalized way, by hierarchically attending to both types of information from local neighborhood contexts instead of the global graph context. Rigorous experiments on seven real-world HeGs show BA-GNN consistently outperforms all baselines, and demonstrate quality and transferability of its learned relation-level attention to improve performance of other GNNs.
Machine learning framework for end-to-end implementation of Incident duration prediction
Apr 23, 2023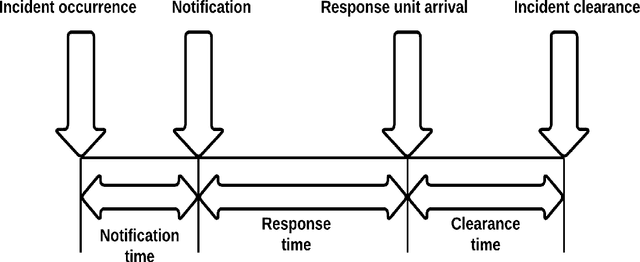
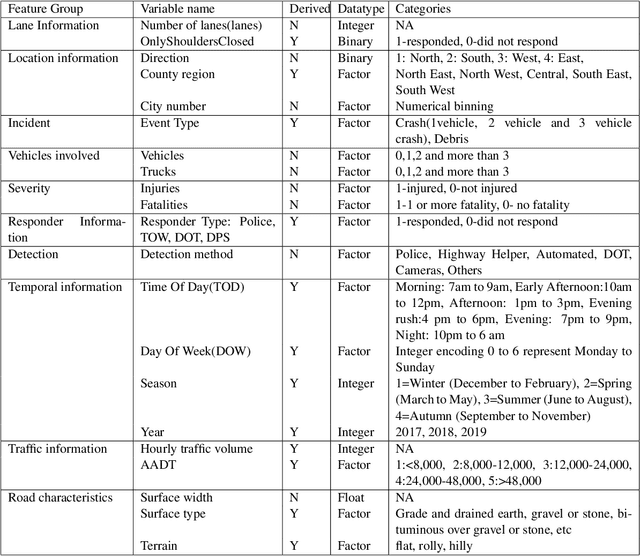
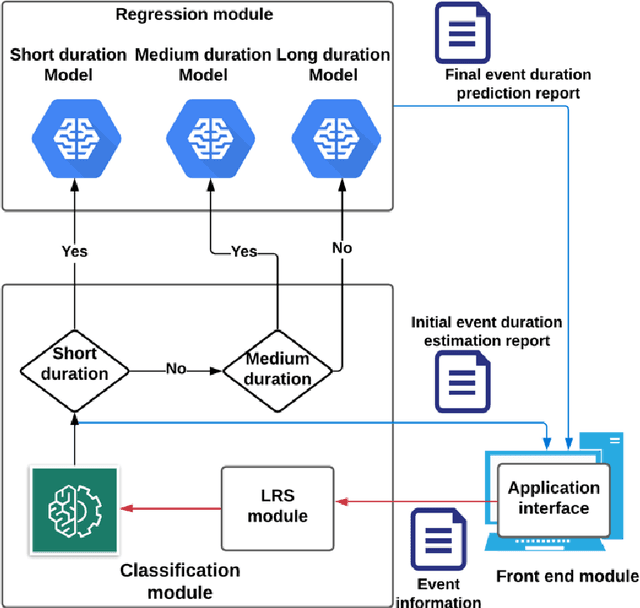
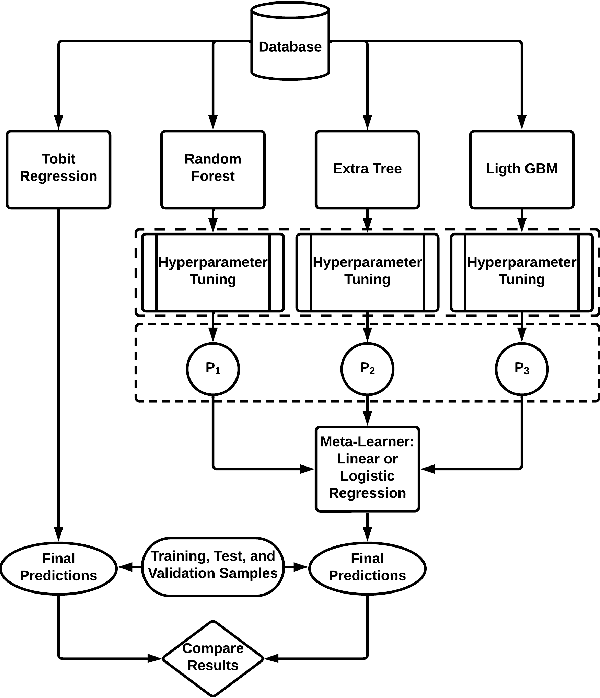
Traffic congestion caused by non-recurring incidents such as vehicle crashes and debris is a key issue for Traffic Management Centers (TMCs). Clearing incidents in a timely manner is essential for improving safety and reducing delays and emissions for the traveling public. However, TMCs and other responders face a challenge in predicting the duration of incidents (until the roadway is clear), making decisions of what resources to deploy difficult. To address this problem, this research developed an analytical framework and end-to-end machine-learning solution for predicting incident duration based on information available as soon as an incident report is received. Quality predictions of incident duration can help TMCs and other responders take a proactive approach in deploying responder services such as tow trucks, maintenance crews or activating alternative routes. The predictions use a combination of classification and regression machine learning modules. The performance of the developed solution has been evaluated based on the Mean Absolute Error (MAE), or deviation from the actual incident duration as well as Area Under the Curve (AUC) and Mean Absolute Percentage Error (MAPE). The results showed that the framework significantly improved incident duration prediction compared to methods from previous research.
TSGCNeXt: Dynamic-Static Multi-Graph Convolution for Efficient Skeleton-Based Action Recognition with Long-term Learning Potential
Apr 23, 2023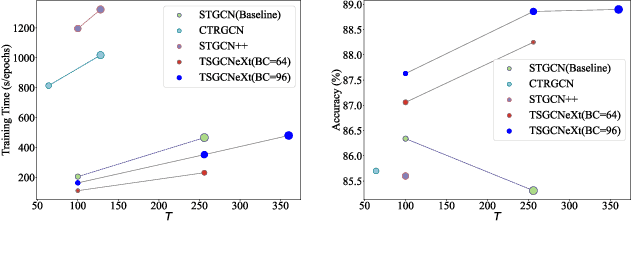
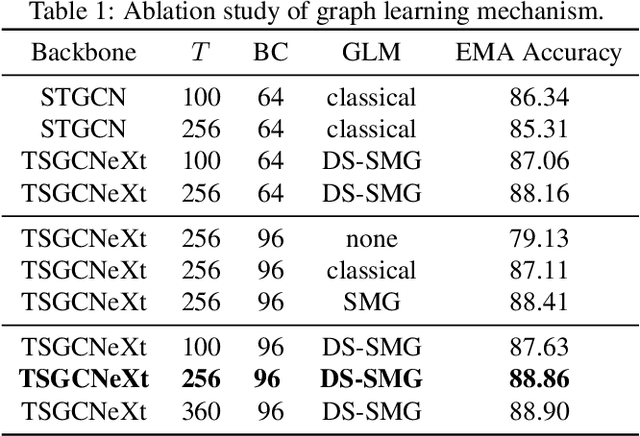
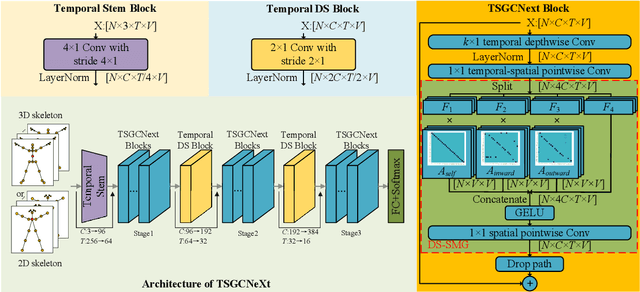
Skeleton-based action recognition has achieved remarkable results in human action recognition with the development of graph convolutional networks (GCNs). However, the recent works tend to construct complex learning mechanisms with redundant training and exist a bottleneck for long time-series. To solve these problems, we propose the Temporal-Spatio Graph ConvNeXt (TSGCNeXt) to explore efficient learning mechanism of long temporal skeleton sequences. Firstly, a new graph learning mechanism with simple structure, Dynamic-Static Separate Multi-graph Convolution (DS-SMG) is proposed to aggregate features of multiple independent topological graphs and avoid the node information being ignored during dynamic convolution. Next, we construct a graph convolution training acceleration mechanism to optimize the back-propagation computing of dynamic graph learning with 55.08\% speed-up. Finally, the TSGCNeXt restructure the overall structure of GCN with three Spatio-temporal learning modules,efficiently modeling long temporal features. In comparison with existing previous methods on large-scale datasets NTU RGB+D 60 and 120, TSGCNeXt outperforms on single-stream networks. In addition, with the ema model introduced into the multi-stream fusion, TSGCNeXt achieves SOTA levels. On the cross-subject and cross-set of the NTU 120, accuracies reach 90.22% and 91.74%.
Towards hypergraph cognitive networks as feature-rich models of knowledge
Apr 13, 2023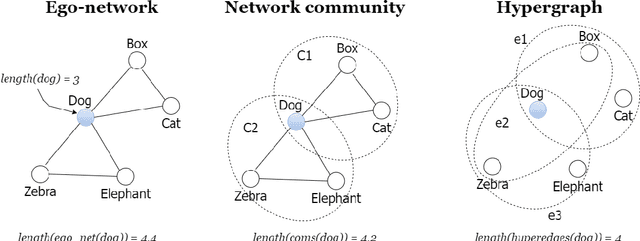
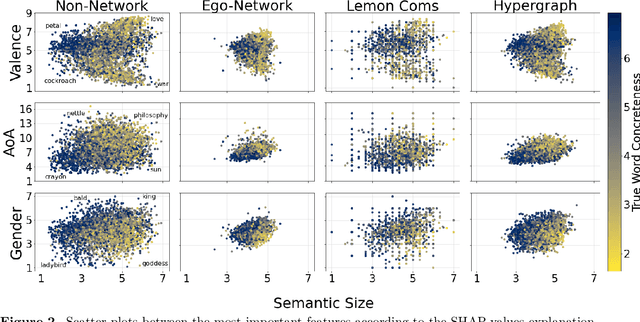
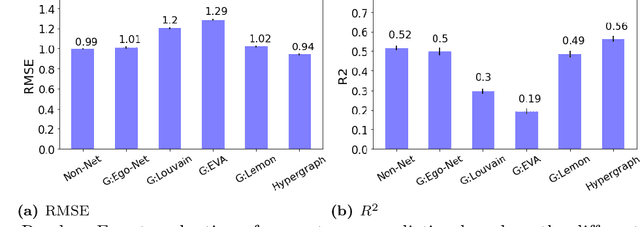
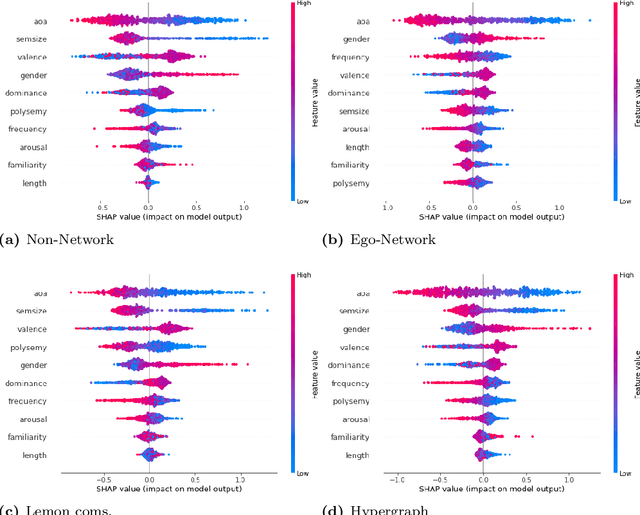
Semantic networks provide a useful tool to understand how related concepts are retrieved from memory. However, most current network approaches use pairwise links to represent memory recall patterns. Pairwise connections neglect higher-order associations, i.e. relationships between more than two concepts at a time. These higher-order interactions might covariate with (and thus contain information about) how similar concepts are along psycholinguistic dimensions like arousal, valence, familiarity, gender and others. We overcome these limits by introducing feature-rich cognitive hypergraphs as quantitative models of human memory where: (i) concepts recalled together can all engage in hyperlinks involving also more than two concepts at once (cognitive hypergraph aspect), and (ii) each concept is endowed with a vector of psycholinguistic features (feature-rich aspect). We build hypergraphs from word association data and use evaluation methods from machine learning features to predict concept concreteness. Since concepts with similar concreteness tend to cluster together in human memory, we expect to be able to leverage this structure. Using word association data from the Small World of Words dataset, we compared a pairwise network and a hypergraph with N=3586 concepts/nodes. Interpretable artificial intelligence models trained on (1) psycholinguistic features only, (2) pairwise-based feature aggregations, and on (3) hypergraph-based aggregations show significant differences between pairwise and hypergraph links. Specifically, our results show that higher-order and feature-rich hypergraph models contain richer information than pairwise networks leading to improved prediction of word concreteness. The relation with previous studies about conceptual clustering and compartmentalisation in associative knowledge and human memory are discussed.