 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Deep Learning Framework for Traffic Data Imputation Considering Spatiotemporal Dependencies
Apr 18, 2023
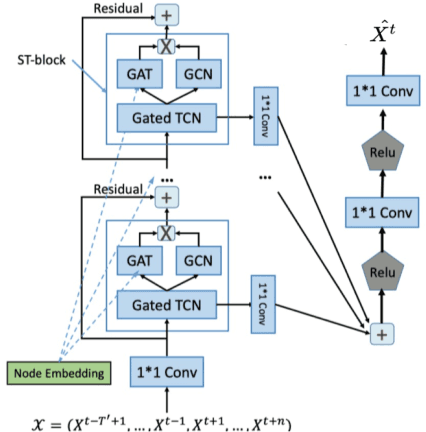
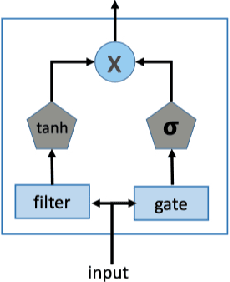

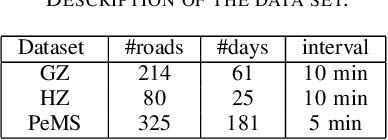
Spatiotemporal (ST) data collected by sensors can be represented as multi-variate time series, which is a sequence of data points listed in an order of time. Despite the vast amount of useful information, the ST data usually suffer from the issue of missing or incomplete data, which also limits its applications. Imputation is one viable solution and is often used to prepossess the data for further applications. However, in practice, n practice, spatiotemporal data imputation is quite difficult due to the complexity of spatiotemporal dependencies with dynamic changes in the traffic network and is a crucial prepossessing task for further applications. Existing approaches mostly only capture the temporal dependencies in time series or static spatial dependencies. They fail to directly model the spatiotemporal dependencies, and the representation ability of the models is relatively limited.
Creating Large Language Model Resistant Exams: Guidelines and Strategies
Apr 18, 2023The proliferation of Large Language Models (LLMs), such as ChatGPT, has raised concerns about their potential impact on academic integrity, prompting the need for LLM-resistant exam designs. This article investigates the performance of LLMs on exams and their implications for assessment, focusing on ChatGPT's abilities and limitations. We propose guidelines for creating LLM-resistant exams, including content moderation, deliberate inaccuracies, real-world scenarios beyond the model's knowledge base, effective distractor options, evaluating soft skills, and incorporating non-textual information. The article also highlights the significance of adapting assessments to modern tools and promoting essential skills development in students. By adopting these strategies, educators can maintain academic integrity while ensuring that assessments accurately reflect contemporary professional settings and address the challenges and opportunities posed by artificial intelligence in education.
Instance Neural Radiance Field
Apr 10, 2023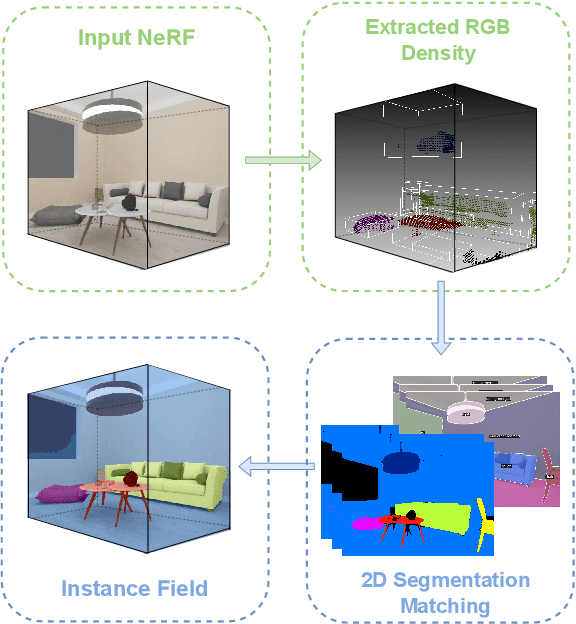
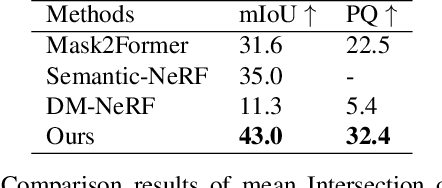
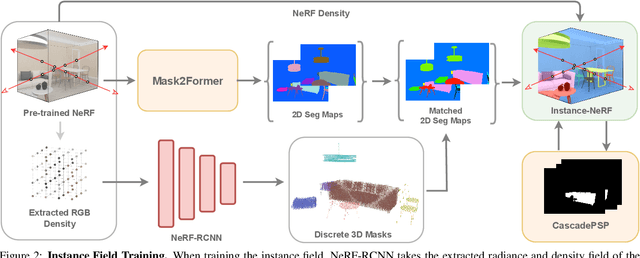
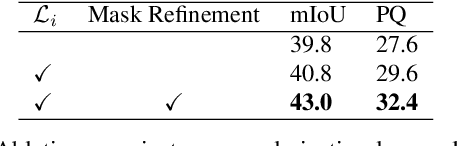
This paper presents one of the first learning-based NeRF 3D instance segmentation pipelines, dubbed as Instance Neural Radiance Field, or Instance NeRF. Taking a NeRF pretrained from multi-view RGB images as input, Instance NeRF can learn 3D instance segmentation of a given scene, represented as an instance field component of the NeRF model. To this end, we adopt a 3D proposal-based mask prediction network on the sampled volumetric features from NeRF, which generates discrete 3D instance masks. The coarse 3D mask prediction is then projected to image space to match 2D segmentation masks from different views generated by existing panoptic segmentation models, which are used to supervise the training of the instance field. Notably, beyond generating consistent 2D segmentation maps from novel views, Instance NeRF can query instance information at any 3D point, which greatly enhances NeRF object segmentation and manipulation. Our method is also one of the first to achieve such results without ground-truth instance information during inference. Experimented on synthetic and real-world NeRF datasets with complex indoor scenes, Instance NeRF surpasses previous NeRF segmentation works and competitive 2D segmentation methods in segmentation performance on unseen views. See the demo video at https://youtu.be/wW9Bme73coI.
FAN: Fatigue-Aware Network for Click-Through Rate Prediction in E-commerce Recommendation
Apr 10, 2023

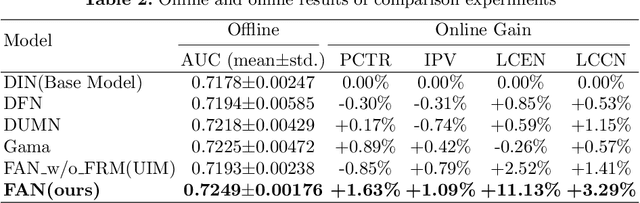
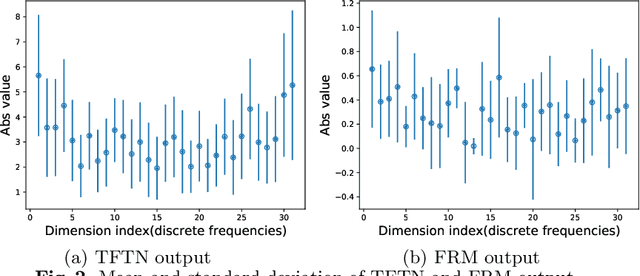
Since clicks usually contain heavy noise, increasing research efforts have been devoted to modeling implicit negative user behaviors (i.e., non-clicks). However, they either rely on explicit negative user behaviors (e.g., dislikes) or simply treat non-clicks as negative feedback, failing to learn negative user interests comprehensively. In such situations, users may experience fatigue because of seeing too many similar recommendations. In this paper, we propose Fatigue-Aware Network (FAN), a novel CTR model that directly perceives user fatigue from non-clicks. Specifically, we first apply Fourier Transformation to the time series generated from non-clicks, obtaining its frequency spectrum which contains comprehensive information about user fatigue. Then the frequency spectrum is modulated by category information of the target item to model the bias that both the upper bound of fatigue and users' patience is different for different categories. Moreover, a gating network is adopted to model the confidence of user fatigue and an auxiliary task is designed to guide the learning of user fatigue, so we can obtain a well-learned fatigue representation and combine it with user interests for the final CTR prediction. Experimental results on real-world datasets validate the superiority of FAN and online A/B tests also show FAN outperforms representative CTR models significantly.
Unsupervised Story Discovery from Continuous News Streams via Scalable Thematic Embedding
Apr 22, 2023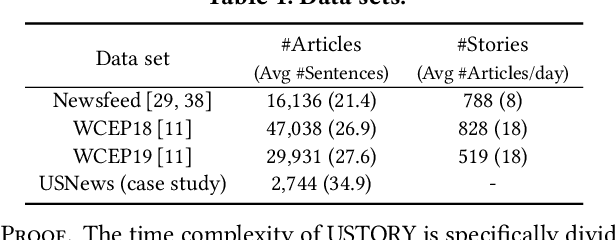
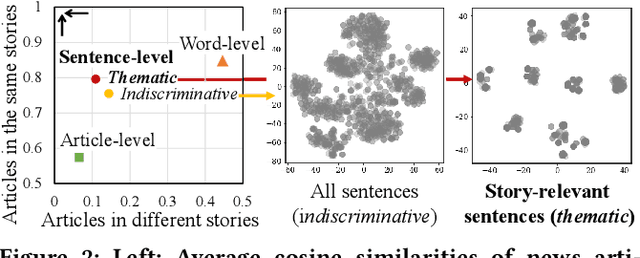
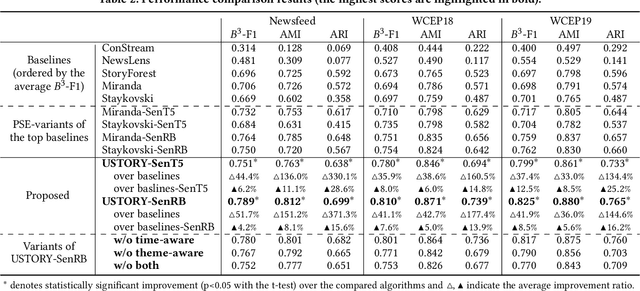
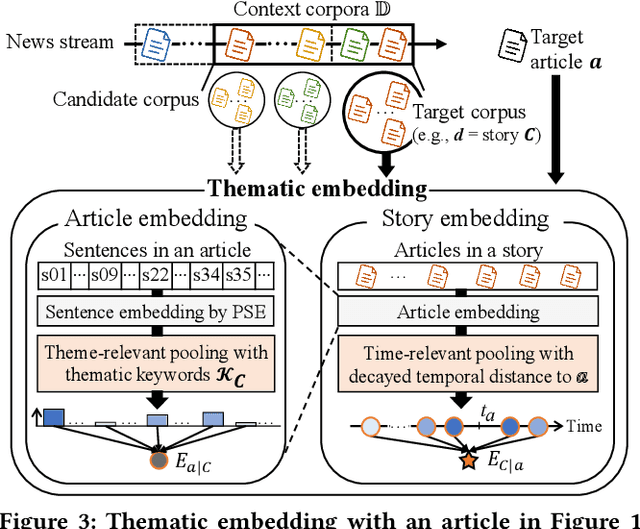
Unsupervised discovery of stories with correlated news articles in real-time helps people digest massive news streams without expensive human annotations. A common approach of the existing studies for unsupervised online story discovery is to represent news articles with symbolic- or graph-based embedding and incrementally cluster them into stories. Recent large language models are expected to improve the embedding further, but a straightforward adoption of the models by indiscriminately encoding all information in articles is ineffective to deal with text-rich and evolving news streams. In this work, we propose a novel thematic embedding with an off-the-shelf pretrained sentence encoder to dynamically represent articles and stories by considering their shared temporal themes. To realize the idea for unsupervised online story discovery, a scalable framework USTORY is introduced with two main techniques, theme- and time-aware dynamic embedding and novelty-aware adaptive clustering, fueled by lightweight story summaries. A thorough evaluation with real news data sets demonstrates that USTORY achieves higher story discovery performances than baselines while being robust and scalable to various streaming settings.
STNet: Spatial and Temporal feature fusion network for change detection in remote sensing images
Apr 22, 2023
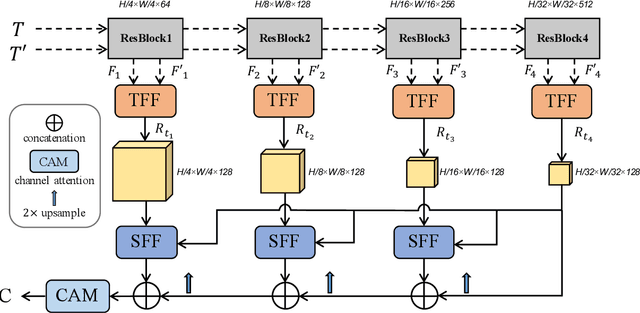
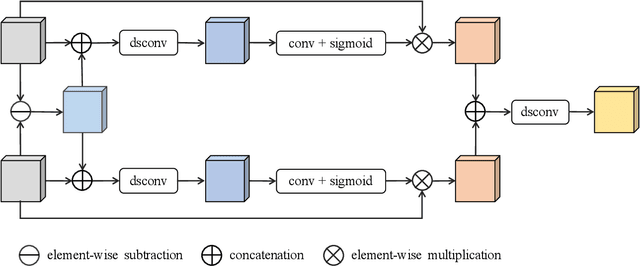
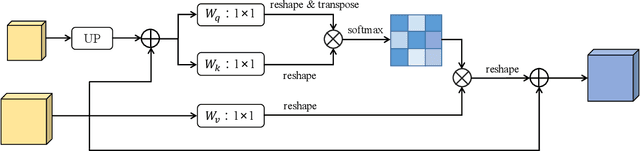
As an important task in remote sensing image analysis, remote sensing change detection (RSCD) aims to identify changes of interest in a region from spatially co-registered multi-temporal remote sensing images, so as to monitor the local development. Existing RSCD methods usually formulate RSCD as a binary classification task, representing changes of interest by merely feature concatenation or feature subtraction and recovering the spatial details via densely connected change representations, whose performances need further improvement. In this paper, we propose STNet, a RSCD network based on spatial and temporal feature fusions. Specifically, we design a temporal feature fusion (TFF) module to combine bi-temporal features using a cross-temporal gating mechanism for emphasizing changes of interest; a spatial feature fusion module is deployed to capture fine-grained information using a cross-scale attention mechanism for recovering the spatial details of change representations. Experimental results on three benchmark datasets for RSCD demonstrate that the proposed method achieves the state-of-the-art performance. Code is available at https://github.com/xwmaxwma/rschange.
Domain Adaptive and Generalizable Network Architectures and Training Strategies for Semantic Image Segmentation
Apr 26, 2023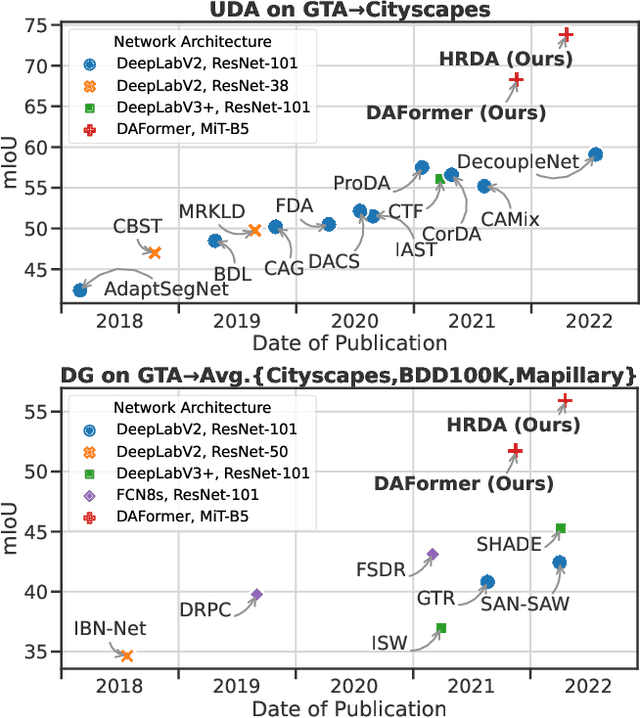
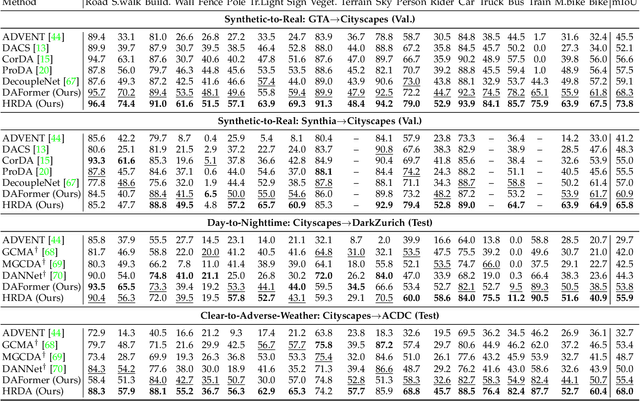

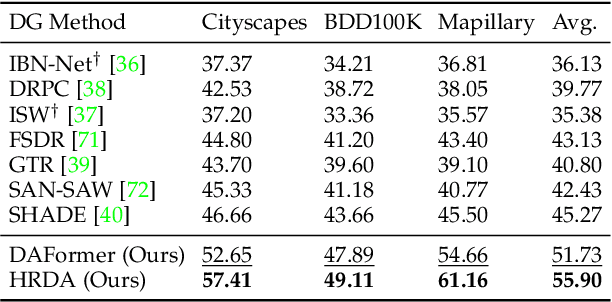
Unsupervised domain adaptation (UDA) and domain generalization (DG) enable machine learning models trained on a source domain to perform well on unlabeled or even unseen target domains. As previous UDA&DG semantic segmentation methods are mostly based on outdated networks, we benchmark more recent architectures, reveal the potential of Transformers, and design the DAFormer network tailored for UDA&DG. It is enabled by three training strategies to avoid overfitting to the source domain: While (1) Rare Class Sampling mitigates the bias toward common source domain classes, (2) a Thing-Class ImageNet Feature Distance and (3) a learning rate warmup promote feature transfer from ImageNet pretraining. As UDA&DG are usually GPU memory intensive, most previous methods downscale or crop images. However, low-resolution predictions often fail to preserve fine details while models trained with cropped images fall short in capturing long-range, domain-robust context information. Therefore, we propose HRDA, a multi-resolution framework for UDA&DG, that combines the strengths of small high-resolution crops to preserve fine segmentation details and large low-resolution crops to capture long-range context dependencies with a learned scale attention. DAFormer and HRDA significantly improve the state-of-the-art UDA&DG by more than 10 mIoU on 5 different benchmarks. The implementation is available at https://github.com/lhoyer/HRDA.
Unleashing Infinite-Length Input Capacity for Large-scale Language Models with Self-Controlled Memory System
Apr 26, 2023
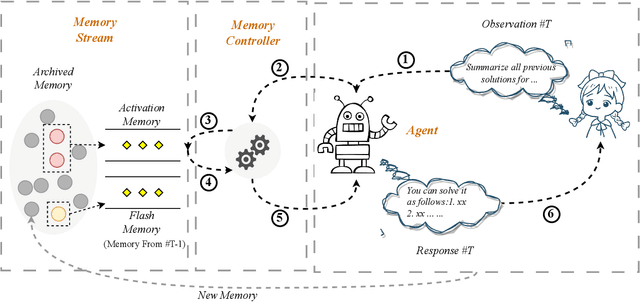
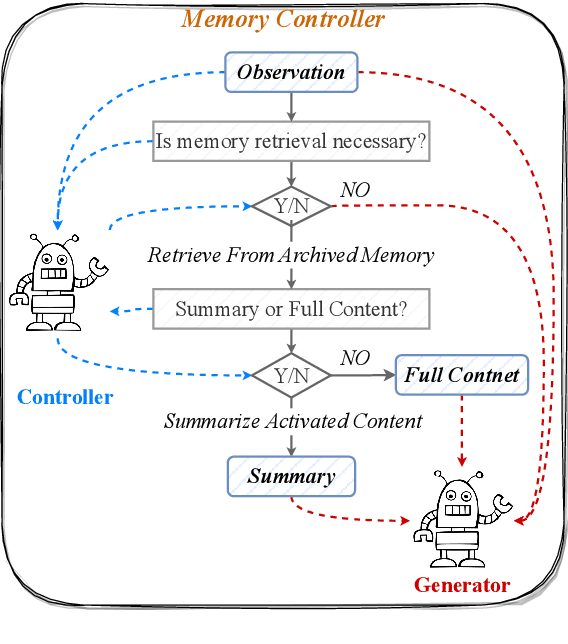

Large-scale Language Models (LLMs) are constrained by their inability to process lengthy inputs. To address this limitation, we propose the Self-Controlled Memory (SCM) system to unleash infinite-length input capacity for large-scale language models. Our SCM system is composed of three key modules: the language model agent, the memory stream, and the memory controller. The language model agent iteratively processes ultra-long inputs and stores all historical information in the memory stream. The memory controller provides the agent with both long-term memory (archived memory) and short-term memory (flash memory) to generate precise and coherent responses. The controller determines which memories from archived memory should be activated and how to incorporate them into the model input. Our SCM system can be integrated with any LLMs to enable them to process ultra-long texts without any modification or fine-tuning. Experimental results show that our SCM system enables LLMs, which are not optimized for multi-turn dialogue, to achieve multi-turn dialogue capabilities that are comparable to ChatGPT, and to outperform ChatGPT in scenarios involving ultra-long document summarization or long-term conversations. Additionally, we will supply a test set, which covers common long-text input scenarios, for evaluating the abilities of LLMs in processing long documents.~\footnote{Working in progress.}\footnote{\url{https://github.com/wbbeyourself/SCM4LLMs}}
Solar Photovoltaic Systems Metadata Inference and Differentially Private Publication
Apr 07, 2023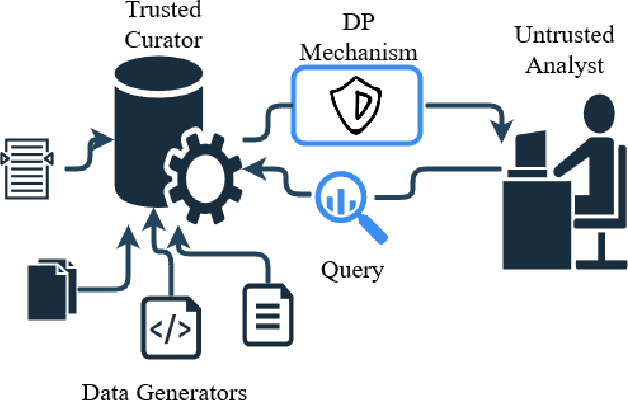
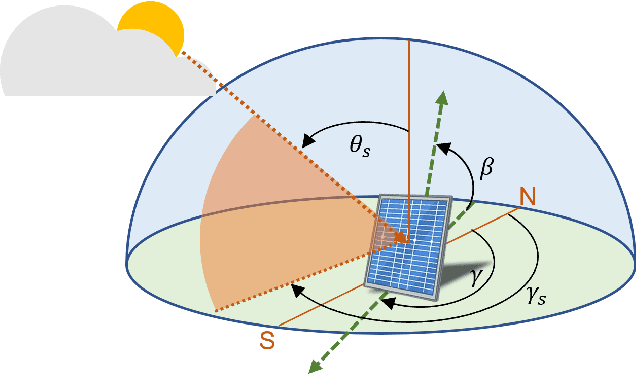
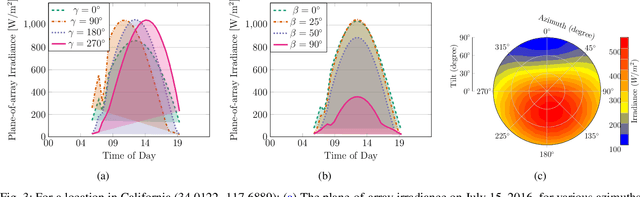
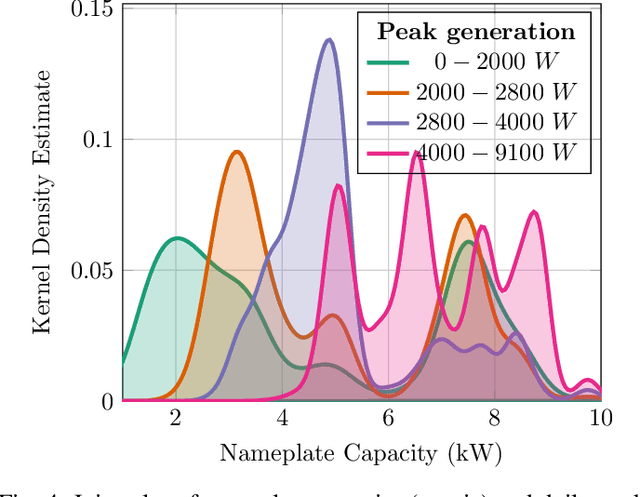
Stakeholders in electricity delivery infrastructure are amassing data about their system demand, use, and operations. Still, they are reluctant to share them, as even sharing aggregated or anonymized electric grid data risks the disclosure of sensitive information. This paper highlights how applying differential privacy to distributed energy resource production data can preserve the usefulness of that data for operations, planning, and research purposes without violating privacy constraints. Differentially private mechanisms can be optimized for queries of interest in the energy sector, with provable privacy and accuracy trade-offs, and can help design differentially private databases for further analysis and research. In this paper, we consider the problem of inference and publication of solar photovoltaic systems' metadata. Metadata such as nameplate capacity, surface azimuth and surface tilt may reveal personally identifiable information regarding the installation behind-the-meter. We describe a methodology to infer the metadata and propose a mechanism based on Bayesian optimization to publish the inferred metadata in a differentially private manner. The proposed mechanism is numerically validated using real-world solar power generation data.
Performance Analysis of Free-Space Information Sharing in Full-Duplex Semantic Communications
Nov 27, 2022

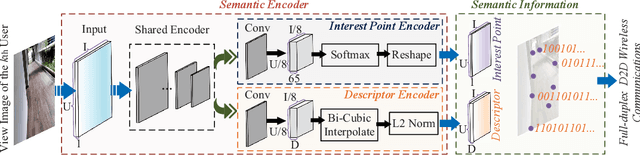
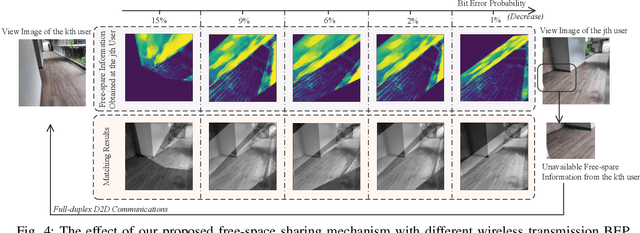
In next-generation Internet services, such as Metaverse, the mixed reality (MR) technique plays a vital role. Yet the limited computing capacity of the user-side MR headset-mounted device (HMD) prevents its further application, especially in scenarios that require a lot of computation. One way out of this dilemma is to design an efficient information sharing scheme among users to replace the heavy and repetitive computation. In this paper, we propose a free-space information sharing mechanism based on full-duplex device-to-device (D2D) semantic communications. Specifically, the view images of MR users in the same real-world scenario may be analogous. Therefore, when one user (i.e., a device) completes some computation tasks, the user can send his own calculation results and the semantic features extracted from the user's own view image to nearby users (i.e., other devices). On this basis, other users can use the received semantic features to obtain the spatial matching of the computational results under their own view images without repeating the computation. Using generalized small-scale fading models, we analyze the key performance indicators of full-duplex D2D communications, including channel capacity and bit error probability, which directly affect the transmission of semantic information. Finally, the numerical analysis experiment proves the effectiveness of our proposed methods.