 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Potential of Visual ChatGPT For Remote Sensing
Apr 25, 2023
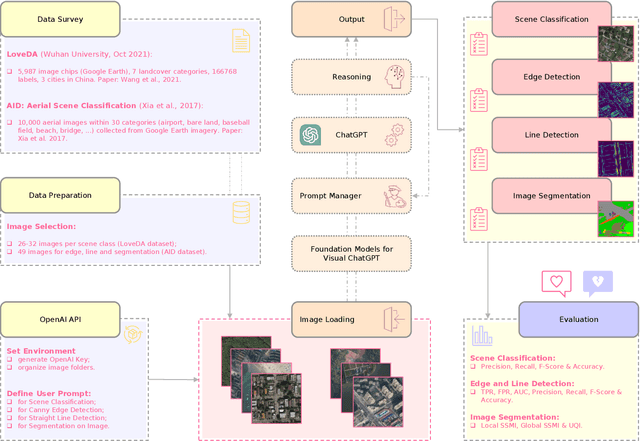
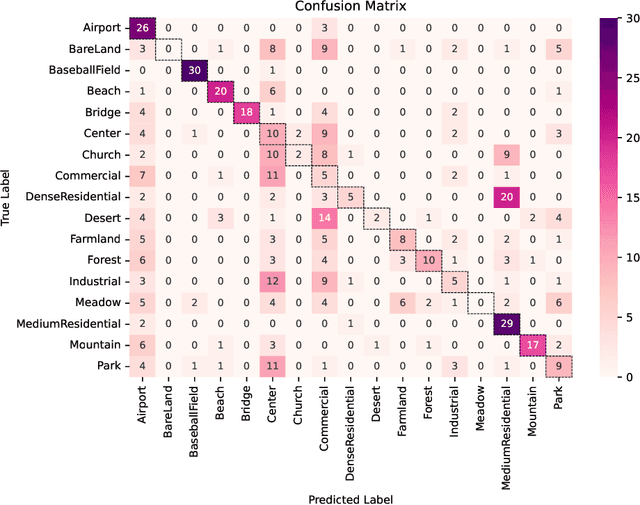
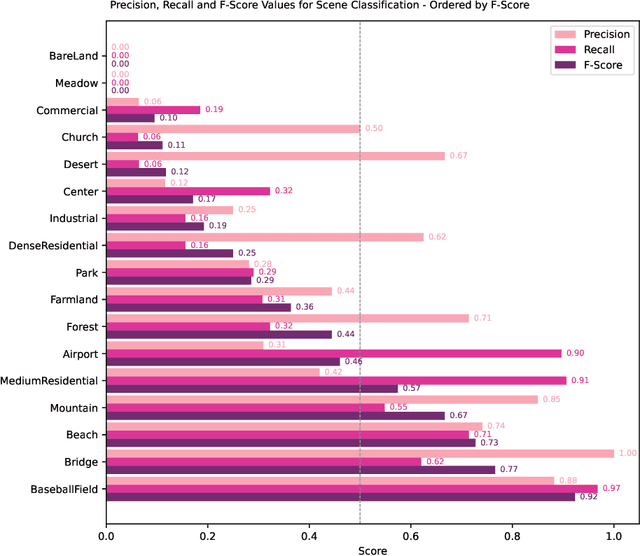

Recent advancements in Natural Language Processing (NLP), particularly in Large Language Models (LLMs), associated with deep learning-based computer vision techniques, have shown substantial potential for automating a variety of tasks. One notable model is Visual ChatGPT, which combines ChatGPT's LLM capabilities with visual computation to enable effective image analysis. The model's ability to process images based on textual inputs can revolutionize diverse fields. However, its application in the remote sensing domain remains unexplored. This is the first paper to examine the potential of Visual ChatGPT, a cutting-edge LLM founded on the GPT architecture, to tackle the aspects of image processing related to the remote sensing domain. Among its current capabilities, Visual ChatGPT can generate textual descriptions of images, perform canny edge and straight line detection, and conduct image segmentation. These offer valuable insights into image content and facilitate the interpretation and extraction of information. By exploring the applicability of these techniques within publicly available datasets of satellite images, we demonstrate the current model's limitations in dealing with remote sensing images, highlighting its challenges and future prospects. Although still in early development, we believe that the combination of LLMs and visual models holds a significant potential to transform remote sensing image processing, creating accessible and practical application opportunities in the field.
Robust Non-Linear Feedback Coding via Power-Constrained Deep Learning
Apr 25, 2023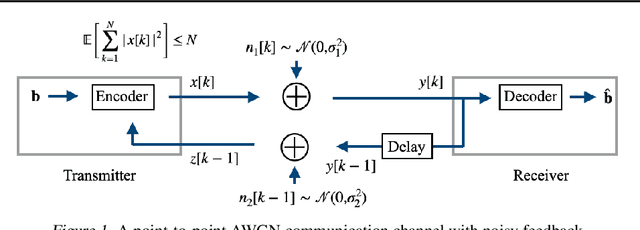
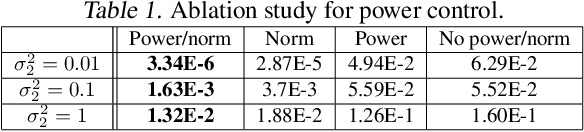
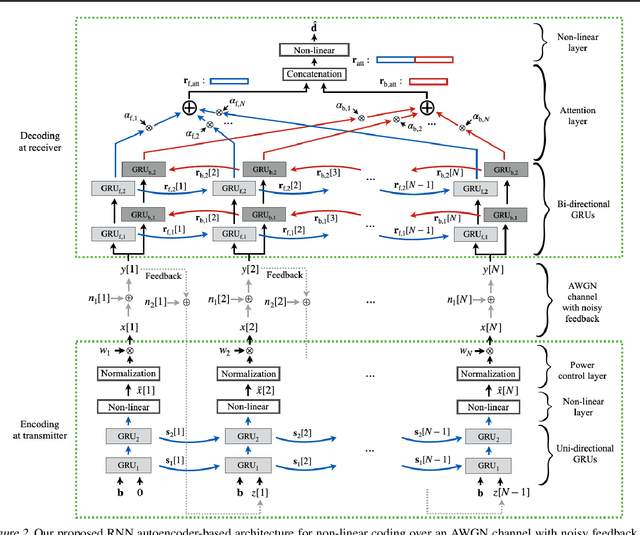
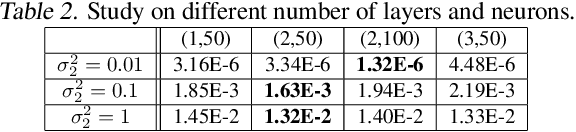
The design of codes for feedback-enabled communications has been a long-standing open problem. Recent research on non-linear, deep learning-based coding schemes have demonstrated significant improvements in communication reliability over linear codes, but are still vulnerable to the presence of forward and feedback noise over the channel. In this paper, we develop a new family of non-linear feedback codes that greatly enhance robustness to channel noise. Our autoencoder-based architecture is designed to learn codes based on consecutive blocks of bits, which obtains de-noising advantages over bit-by-bit processing to help overcome the physical separation between the encoder and decoder over a noisy channel. Moreover, we develop a power control layer at the encoder to explicitly incorporate hardware constraints into the learning optimization, and prove that the resulting average power constraint is satisfied asymptotically. Numerical experiments demonstrate that our scheme outperforms state-of-the-art feedback codes by wide margins over practical forward and feedback noise regimes, and provide information-theoretic insights on the behavior of our non-linear codes. Moreover, we observe that, in a long blocklength regime, canonical error correction codes are still preferable to feedback codes when the feedback noise becomes high.
What's in a Name? Evaluating Assembly-Part Semantic Knowledge in Language Models through User-Provided Names in CAD Files
Apr 25, 2023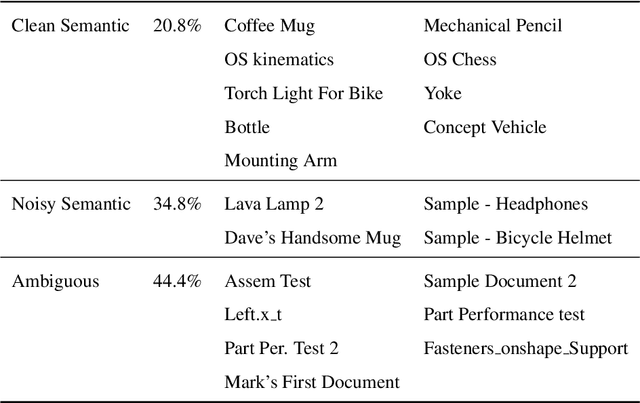
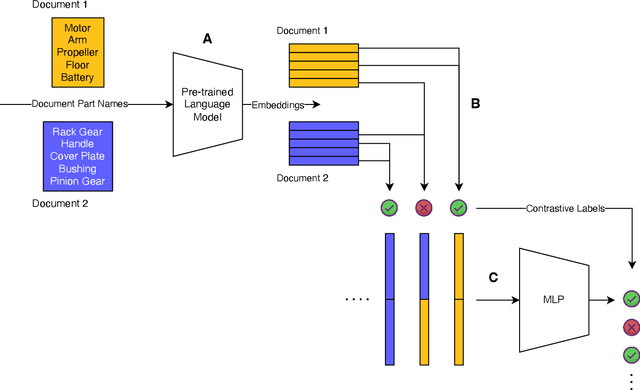
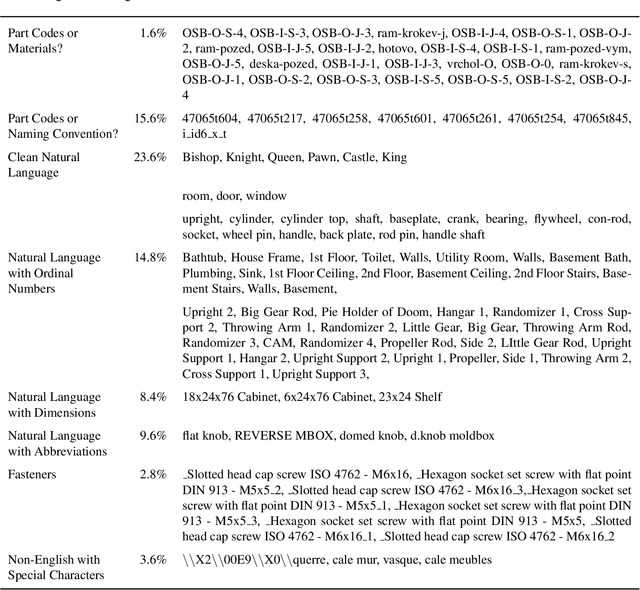
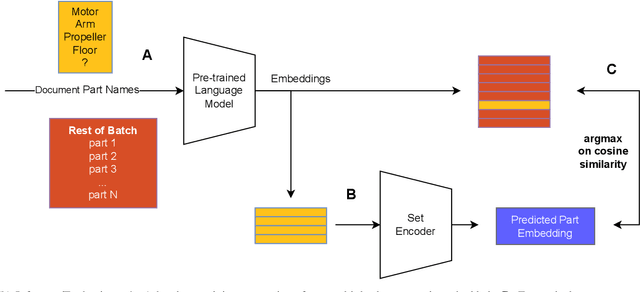
Semantic knowledge of part-part and part-whole relationships in assemblies is useful for a variety of tasks from searching design repositories to the construction of engineering knowledge bases. In this work we propose that the natural language names designers use in Computer Aided Design (CAD) software are a valuable source of such knowledge, and that Large Language Models (LLMs) contain useful domain-specific information for working with this data as well as other CAD and engineering-related tasks. In particular we extract and clean a large corpus of natural language part, feature and document names and use this to quantitatively demonstrate that a pre-trained language model can outperform numerous benchmarks on three self-supervised tasks, without ever having seen this data before. Moreover, we show that fine-tuning on the text data corpus further boosts the performance on all tasks, thus demonstrating the value of the text data which until now has been largely ignored. We also identify key limitations to using LLMs with text data alone, and our findings provide a strong motivation for further work into multi-modal text-geometry models. To aid and encourage further work in this area we make all our data and code publicly available.
CitePrompt: Using Prompts to Identify Citation Intent in Scientific Papers
Apr 25, 2023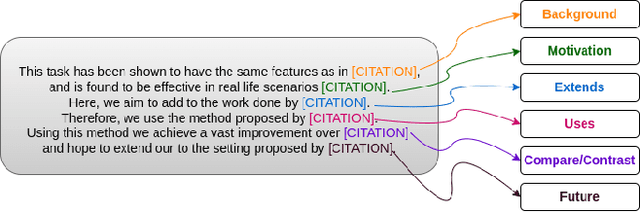
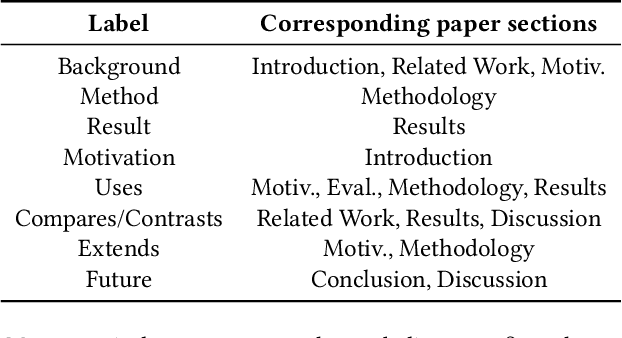
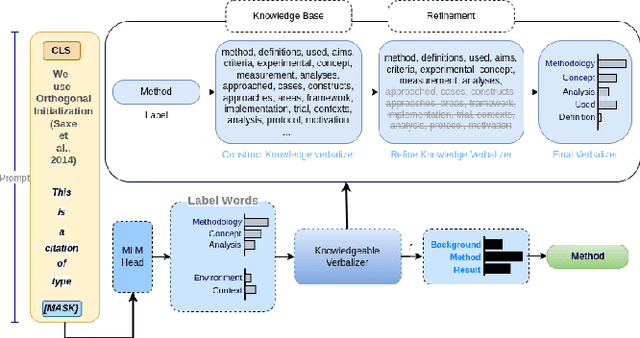

Citations in scientific papers not only help us trace the intellectual lineage but also are a useful indicator of the scientific significance of the work. Citation intents prove beneficial as they specify the role of the citation in a given context. In this paper, we present CitePrompt, a framework which uses the hitherto unexplored approach of prompt-based learning for citation intent classification. We argue that with the proper choice of the pretrained language model, the prompt template, and the prompt verbalizer, we can not only get results that are better than or comparable to those obtained with the state-of-the-art methods but also do it with much less exterior information about the scientific document. We report state-of-the-art results on the ACL-ARC dataset, and also show significant improvement on the SciCite dataset over all baseline models except one. As suitably large labelled datasets for citation intent classification can be quite hard to find, in a first, we propose the conversion of this task to the few-shot and zero-shot settings. For the ACL-ARC dataset, we report a 53.86% F1 score for the zero-shot setting, which improves to 63.61% and 66.99% for the 5-shot and 10-shot settings, respectively.
Proto-Value Networks: Scaling Representation Learning with Auxiliary Tasks
Apr 25, 2023
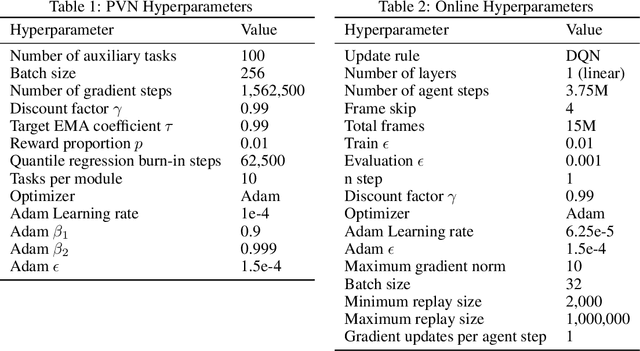
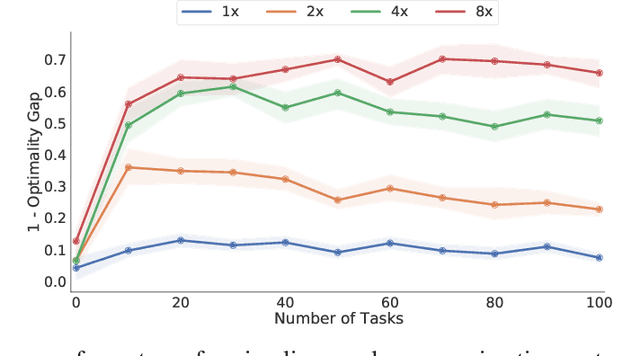

Auxiliary tasks improve the representations learned by deep reinforcement learning agents. Analytically, their effect is reasonably well understood; in practice, however, their primary use remains in support of a main learning objective, rather than as a method for learning representations. This is perhaps surprising given that many auxiliary tasks are defined procedurally, and hence can be treated as an essentially infinite source of information about the environment. Based on this observation, we study the effectiveness of auxiliary tasks for learning rich representations, focusing on the setting where the number of tasks and the size of the agent's network are simultaneously increased. For this purpose, we derive a new family of auxiliary tasks based on the successor measure. These tasks are easy to implement and have appealing theoretical properties. Combined with a suitable off-policy learning rule, the result is a representation learning algorithm that can be understood as extending Mahadevan & Maggioni (2007)'s proto-value functions to deep reinforcement learning -- accordingly, we call the resulting object proto-value networks. Through a series of experiments on the Arcade Learning Environment, we demonstrate that proto-value networks produce rich features that may be used to obtain performance comparable to established algorithms, using only linear approximation and a small number (~4M) of interactions with the environment's reward function.
An Instance Segmentation Dataset of Yeast Cells in Microstructures
Apr 15, 2023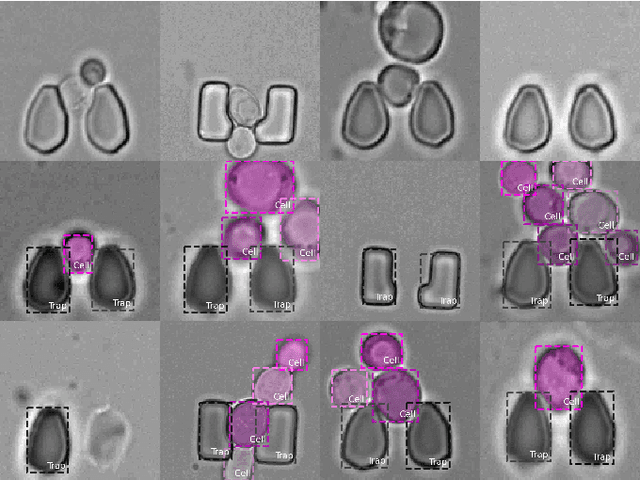
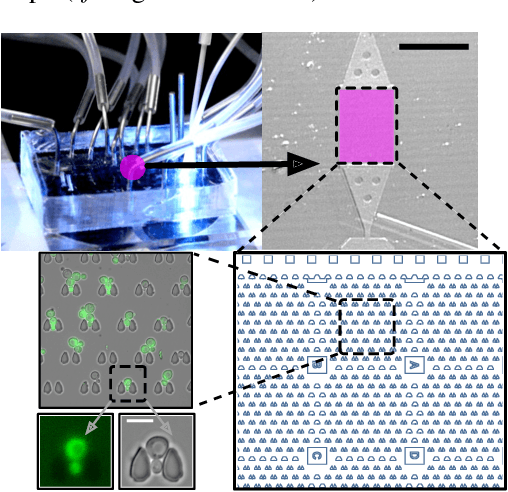
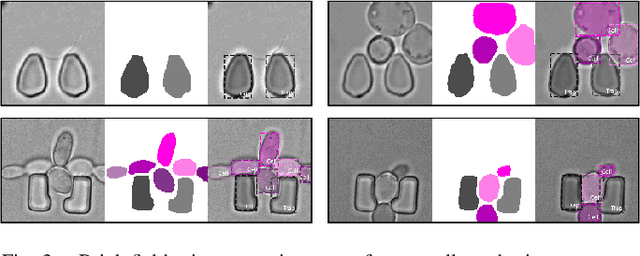
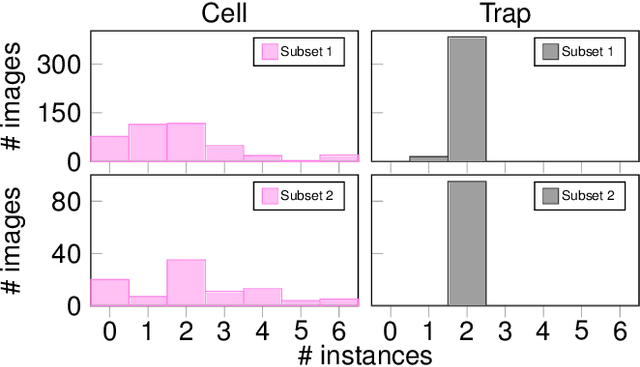
Extracting single-cell information from microscopy data requires accurate instance-wise segmentations. Obtaining pixel-wise segmentations from microscopy imagery remains a challenging task, especially with the added complexity of microstructured environments. This paper presents a novel dataset for segmenting yeast cells in microstructures. We offer pixel-wise instance segmentation labels for both cells and trap microstructures. In total, we release 493 densely annotated microscopy images. To facilitate a unified comparison between novel segmentation algorithms, we propose a standardized evaluation strategy for our dataset. The aim of the dataset and evaluation strategy is to facilitate the development of new cell segmentation approaches. The dataset is publicly available at https://christophreich1996.github.io/yeast_in_microstructures_dataset/ .
AIRCADE: an Anechoic and IR Convolution-based Auralization Data-compilation Ensemble
Apr 18, 2023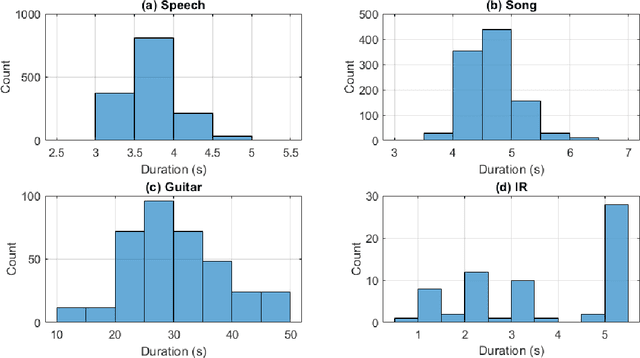
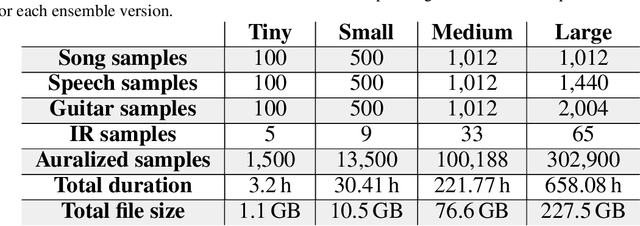
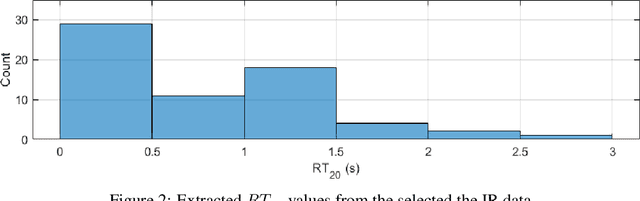
In this paper, we introduce a data-compilation ensemble, primarily intended to serve as a resource for researchers in the field of dereverberation, particularly for data-driven approaches. It comprises speech and song samples, together with acoustic guitar sounds, with original annotations pertinent to emotion recognition and Music Information Retrieval (MIR). Moreover, it includes a selection of impulse response (IR) samples with varying Reverberation Time (RT) values, providing a wide range of conditions for evaluation. This data-compilation can be used together with provided Python scripts, for generating auralized data ensembles in different sizes: tiny, small, medium and large. Additionally, the provided metadata annotations also allow for further analysis and investigation of the performance of dereverberation algorithms under different conditions. All data is licensed under Creative Commons Attribution 4.0 International License.
Incremental Image Labeling via Iterative Refinement
Apr 18, 2023Data quality is critical for multimedia tasks, while various types of systematic flaws are found in image benchmark datasets, as discussed in recent work. In particular, the existence of the semantic gap problem leads to a many-to-many mapping between the information extracted from an image and its linguistic description. This unavoidable bias further leads to poor performance on current computer vision tasks. To address this issue, we introduce a Knowledge Representation (KR)-based methodology to provide guidelines driving the labeling process, thereby indirectly introducing intended semantics in ML models. Specifically, an iterative refinement-based annotation method is proposed to optimize data labeling by organizing objects in a classification hierarchy according to their visual properties, ensuring that they are aligned with their linguistic descriptions. Preliminary results verify the effectiveness of the proposed method.
A Deep Learning Framework for Traffic Data Imputation Considering Spatiotemporal Dependencies
Apr 18, 2023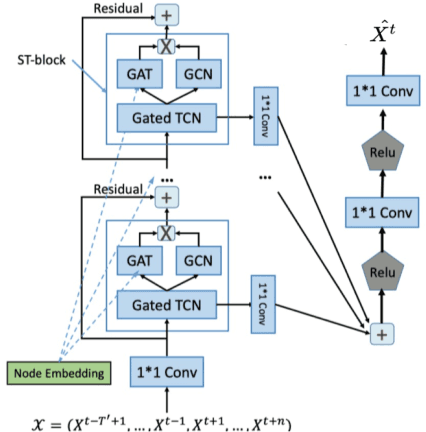
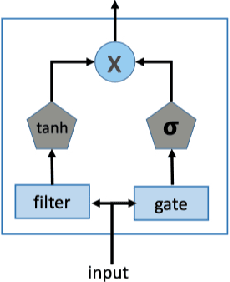

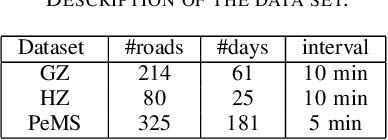
Spatiotemporal (ST) data collected by sensors can be represented as multi-variate time series, which is a sequence of data points listed in an order of time. Despite the vast amount of useful information, the ST data usually suffer from the issue of missing or incomplete data, which also limits its applications. Imputation is one viable solution and is often used to prepossess the data for further applications. However, in practice, n practice, spatiotemporal data imputation is quite difficult due to the complexity of spatiotemporal dependencies with dynamic changes in the traffic network and is a crucial prepossessing task for further applications. Existing approaches mostly only capture the temporal dependencies in time series or static spatial dependencies. They fail to directly model the spatiotemporal dependencies, and the representation ability of the models is relatively limited.
Creating Large Language Model Resistant Exams: Guidelines and Strategies
Apr 18, 2023The proliferation of Large Language Models (LLMs), such as ChatGPT, has raised concerns about their potential impact on academic integrity, prompting the need for LLM-resistant exam designs. This article investigates the performance of LLMs on exams and their implications for assessment, focusing on ChatGPT's abilities and limitations. We propose guidelines for creating LLM-resistant exams, including content moderation, deliberate inaccuracies, real-world scenarios beyond the model's knowledge base, effective distractor options, evaluating soft skills, and incorporating non-textual information. The article also highlights the significance of adapting assessments to modern tools and promoting essential skills development in students. By adopting these strategies, educators can maintain academic integrity while ensuring that assessments accurately reflect contemporary professional settings and address the challenges and opportunities posed by artificial intelligence in education.