 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MoniLog: An Automated Log-Based Anomaly Detection System for Cloud Computing Infrastructures
Apr 24, 2023
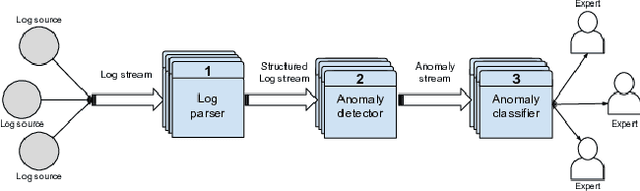
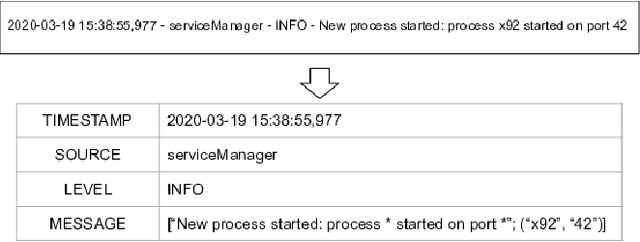
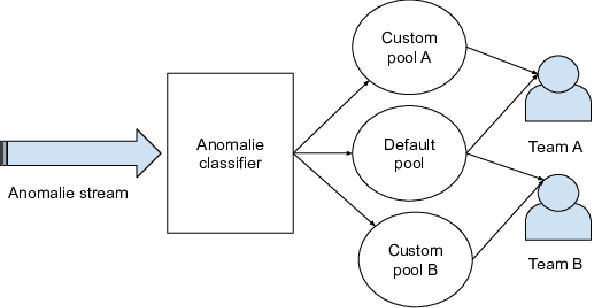

Within today's large-scale systems, one anomaly can impact millions of users. Detecting such events in real-time is essential to maintain the quality of services. It allows the monitoring team to prevent or diminish the impact of a failure. Logs are a core part of software development and maintenance, by recording detailed information at runtime. Such log data are universally available in nearly all computer systems. They enable developers as well as system maintainers to monitor and dissect anomalous events. For Cloud computing companies and large online platforms in general, growth is linked to the scaling potential. Automatizing the anomaly detection process is a promising way to ensure the scalability of monitoring capacities regarding the increasing volume of logs generated by modern systems. In this paper, we will introduce MoniLog, a distributed approach to detect real-time anomalies within large-scale environments. It aims to detect sequential and quantitative anomalies within a multi-source log stream. MoniLog is designed to structure a log stream and perform the monitoring of anomalous sequences. Its output classifier learns from the administrator's actions to label and evaluate the criticality level of anomalies.
Multi-Modal Recommendation System with Auxiliary Information
Oct 13, 2022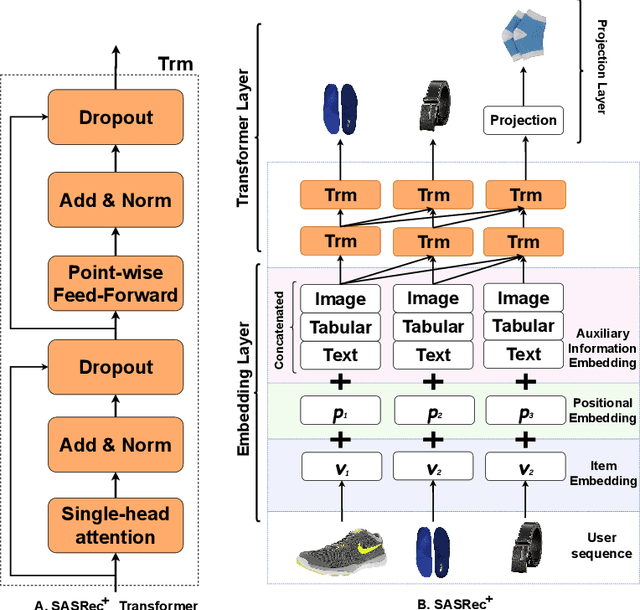
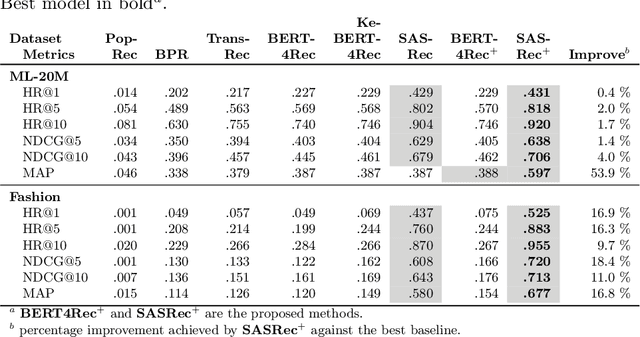
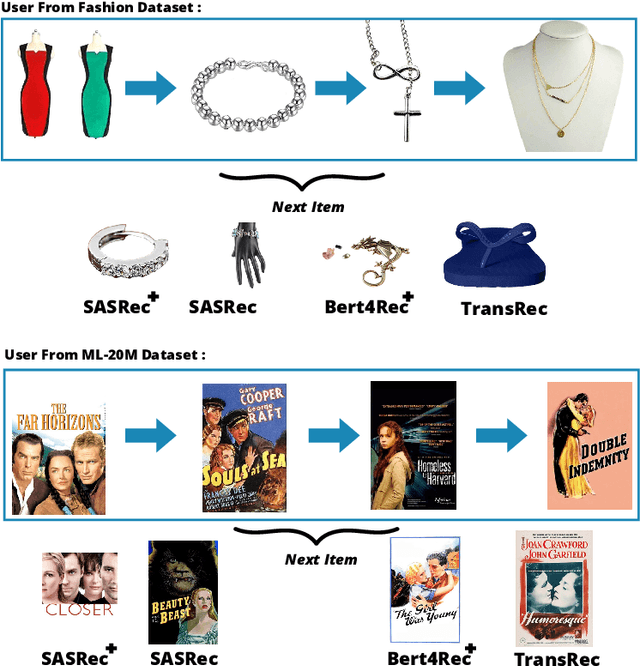

Context-aware recommendation systems improve upon classical recommender systems by including, in the modelling, a user's behaviour. Research into context-aware recommendation systems has previously only considered the sequential ordering of items as contextual information. However, there is a wealth of unexploited additional multi-modal information available in auxiliary knowledge related to items. This study extends the existing research by evaluating a multi-modal recommendation system that exploits the inclusion of comprehensive auxiliary knowledge related to an item. The empirical results explore extracting vector representations (embeddings) from unstructured and structured data using data2vec. The fused embeddings are then used to train several state-of-the-art transformer architectures for sequential user-item representations. The analysis of the experimental results shows a statistically significant improvement in prediction accuracy, which confirms the effectiveness of including auxiliary information in a context-aware recommendation system. We report a 4% and 11% increase in the NDCG score for long and short user sequence datasets, respectively.
A baseline on continual learning methods for video action recognition
Apr 20, 2023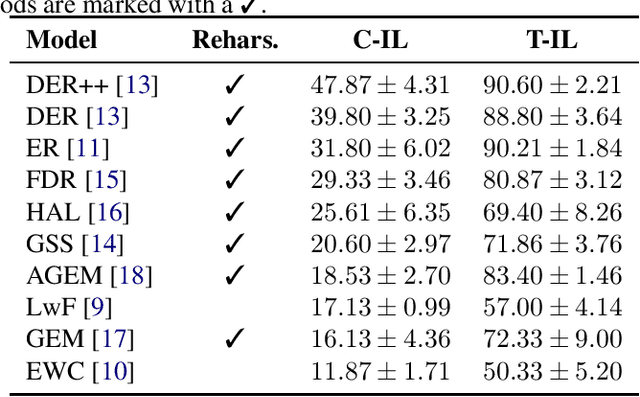
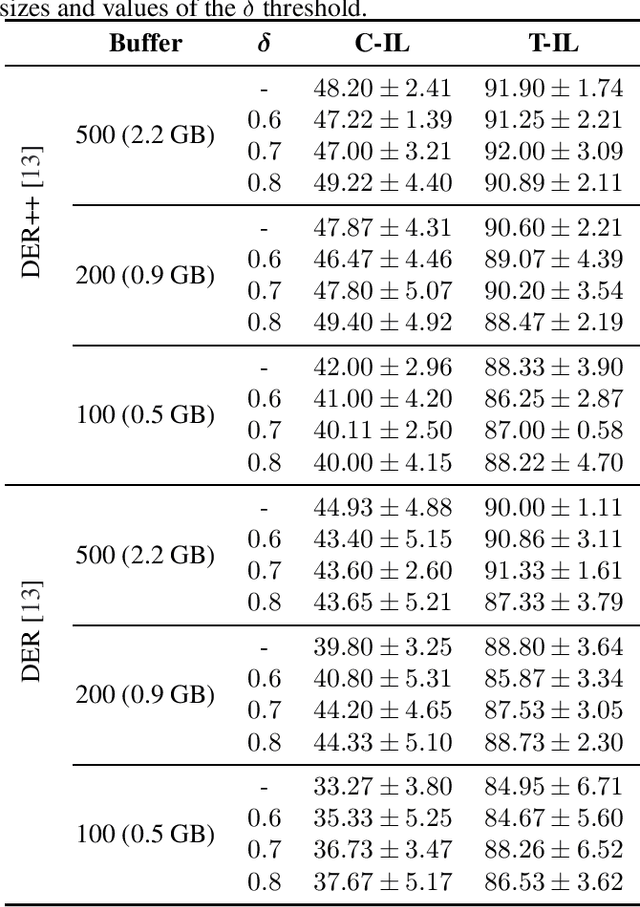
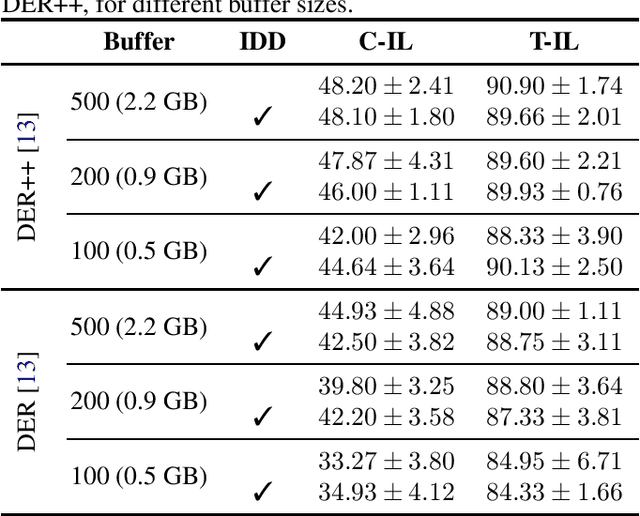
Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
Dark-field and directional dark-field on low coherence X-ray sources with random mask modulations: validation with SAXS anisotropy measurements
Apr 20, 2023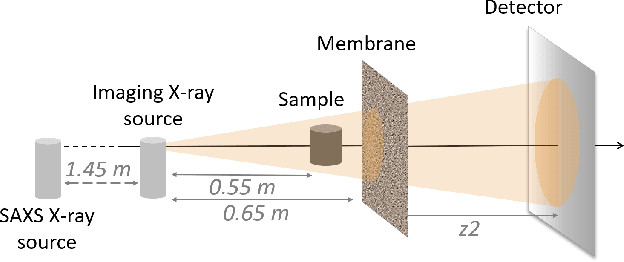
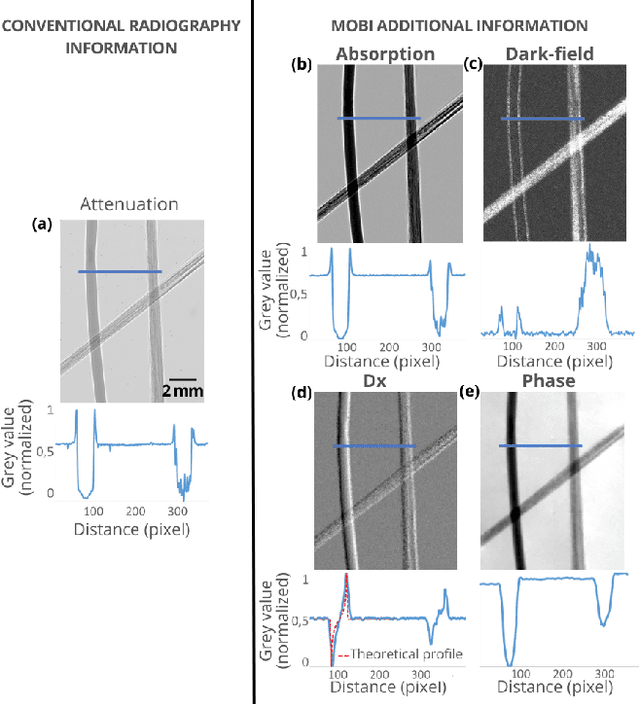
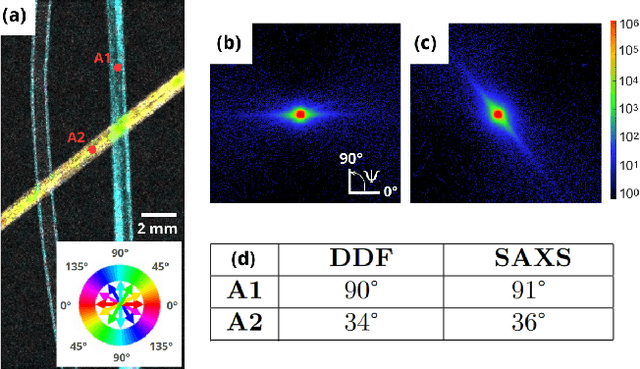

Phase Contrast Imaging (PCI), Dark-Field (DF) and Directional Dark-Field (DDF) imaging are recent X-ray imaging modalities that have demonstrated their interest by providing access to information and contrasts different from those provided by conventional absorption X-ray imaging. However, access to these two types of images is currently limited because the acquisitions require the use of coherent sources such as synchrotron radiation or complicated optical setups to exploit the coherence requirements. This work demonstrates the possibility of efficiently performing phase contrast, dark-field and directional dark-field imaging on a low-coherence laboratory system equipped with a conventional X-ray tube, using a simple, fast and robust single-mask technique. The transfer to a low spatial coherence laboratory system was made possible by using random modulation based imaging (MoBI) and extending the low coherence system algorithm to retrieve dark-field and directional dark-field.
A CTC Alignment-based Non-autoregressive Transformer for End-to-end Automatic Speech Recognition
Apr 15, 2023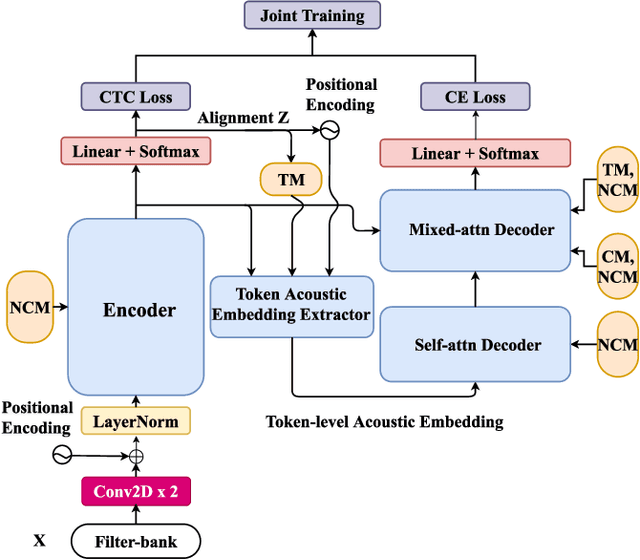
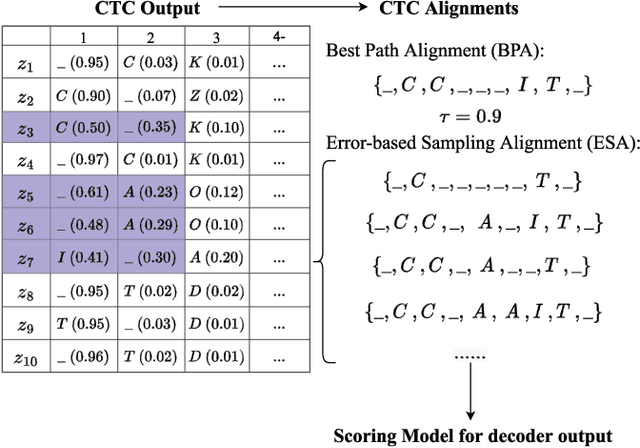
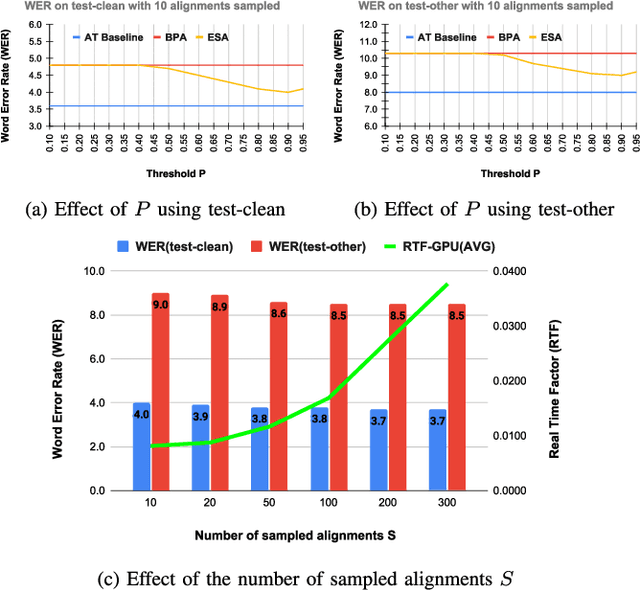
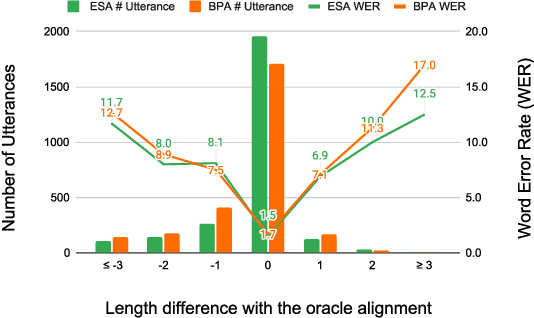
Recently, end-to-end models have been widely used in automatic speech recognition (ASR) systems. Two of the most representative approaches are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. Autoregressive transformers, variants of AED, adopt an autoregressive mechanism for token generation and thus are relatively slow during inference. In this paper, we present a comprehensive study of a CTC Alignment-based Single-Step Non-Autoregressive Transformer (CASS-NAT) for end-to-end ASR. In CASS-NAT, word embeddings in the autoregressive transformer (AT) are substituted with token-level acoustic embeddings (TAE) that are extracted from encoder outputs with the acoustical boundary information offered by the CTC alignment. TAE can be obtained in parallel, resulting in a parallel generation of output tokens. During training, Viterbi-alignment is used for TAE generation, and multiple training strategies are further explored to improve the word error rate (WER) performance. During inference, an error-based alignment sampling method is investigated in depth to reduce the alignment mismatch in the training and testing processes. Experimental results show that the CASS-NAT has a WER that is close to AT on various ASR tasks, while providing a ~24x inference speedup. With and without self-supervised learning, we achieve new state-of-the-art results for non-autoregressive models on several datasets. We also analyze the behavior of the CASS-NAT decoder to explain why it can perform similarly to AT. We find that TAEs have similar functionality to word embeddings for grammatical structures, which might indicate the possibility of learning some semantic information from TAEs without a language model.
Uncoordinated Interference Avoidance Between Terrestrial and Non-Terrestrial Communications
Apr 14, 2023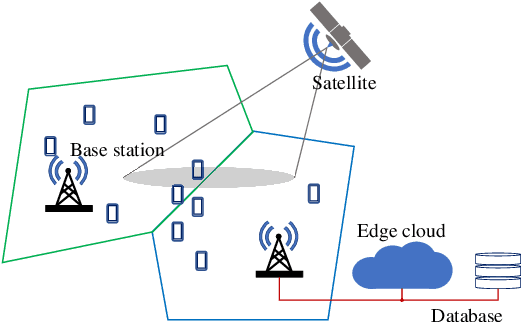

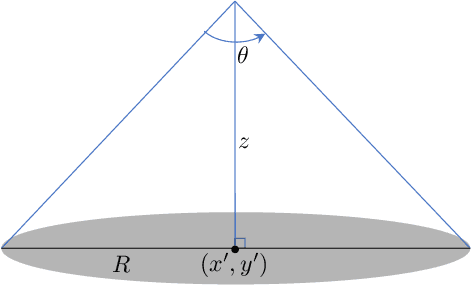
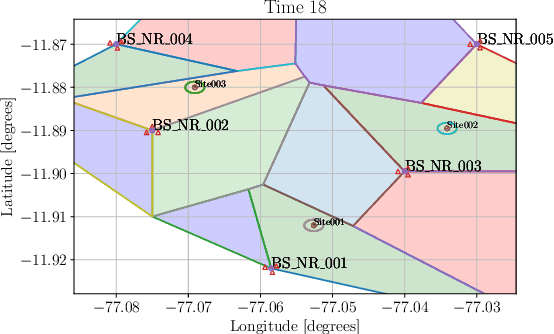
This paper proposes an algorithm that uses geospatial analytics and the muting of physical resources in next-generation base stations (BSs) to avoid interference between cellular (or terrestrial) and satellite communication systems as non-terrestrial systems. The information exchange between satellite and terrestrial links is very limited, but a hybrid edge cloud node with access to satellite trajectories can enable these BSs to take proactive measures. We show simulation results to validate the superiority of our proposed algorithm over a conventional method. Our algorithm runs in polynomial time, making it suitable for real-time interference avoidance.
Hierarchically Structured Matrix Recovery-Based Channel Estimation for RIS-Aided Communications
Apr 14, 2023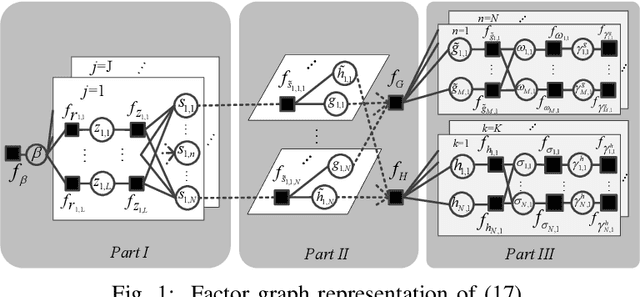
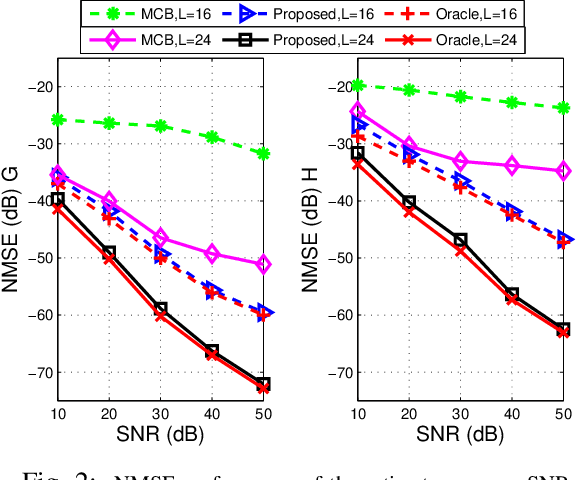
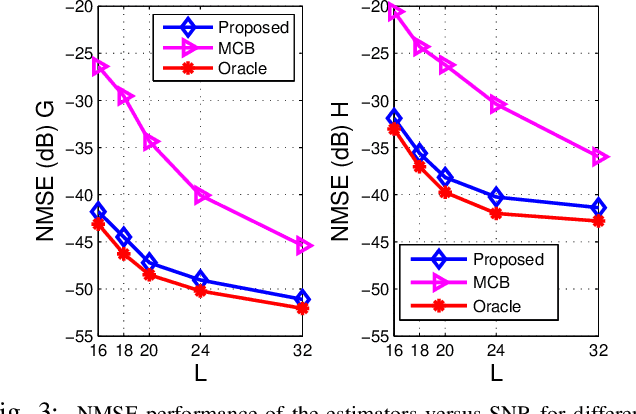

Reconfigurable intelligent surface (RIS) has emerged as a promising technology for improving capacity and extending coverage of wireless networks. In this work, we consider RIS-aided millimeter wave (mmWave) multiple-input and multiple-output (MIMO) communications, where acquiring accurate channel state information is challenging due to the high dimensionality of channels. To fully exploit the structures of the channels, we formulate the channel estimation as a hierarchically structured matrix recovery problem, and design a low-complexity message passing algorithm to solve it. Simulation results demonstrate the superiority of the proposed algorithm and its performance close to the oracle bound.
EasyNER: A Customizable Easy-to-Use Pipeline for Deep Learning- and Dictionary-based Named Entity Recognition from Medical Text
Apr 16, 2023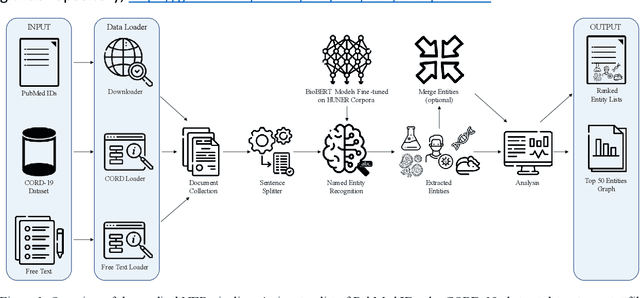
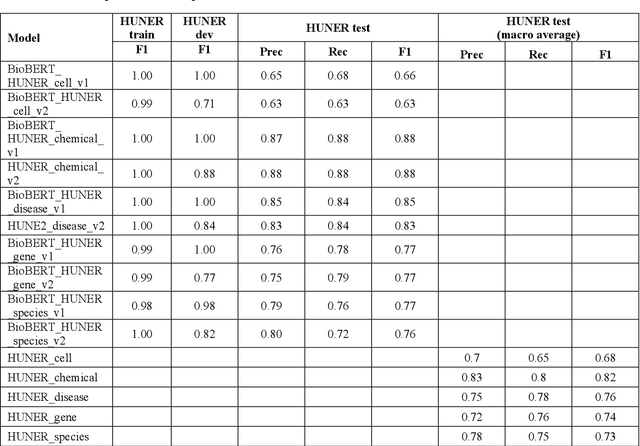
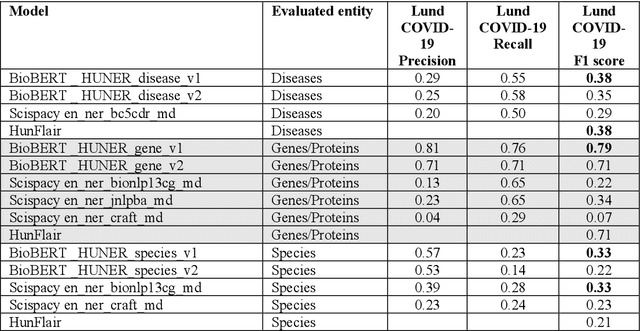
Medical research generates a large number of publications with the PubMed database already containing >35 million research articles. Integration of the knowledge scattered across this large body of literature could provide key insights into physiological mechanisms and disease processes leading to novel medical interventions. However, it is a great challenge for researchers to utilize this information in full since the scale and complexity of the data greatly surpasses human processing abilities. This becomes especially problematic in cases of extreme urgency like the COVID-19 pandemic. Automated text mining can help extract and connect information from the large body of medical research articles. The first step in text mining is typically the identification of specific classes of keywords (e.g., all protein or disease names), so called Named Entity Recognition (NER). Here we present an end-to-end pipeline for NER of typical entities found in medical research articles, including diseases, cells, chemicals, genes/proteins, and species. The pipeline can access and process large medical research article collections (PubMed, CORD-19) or raw text and incorporates a series of deep learning models fine-tuned on the HUNER corpora collection. In addition, the pipeline can perform dictionary-based NER related to COVID-19 and other medical topics. Users can also load their own NER models and dictionaries to include additional entities. The output consists of publication-ready ranked lists and graphs of detected entities and files containing the annotated texts. An associated script allows rapid inspection of the results for specific entities of interest. As model use cases, the pipeline was deployed on two collections of autophagy-related abstracts from PubMed and on the CORD19 dataset, a collection of 764 398 research article abstracts related to COVID-19.
Emotion fusion for mental illness detection from social media: A survey
Apr 19, 2023
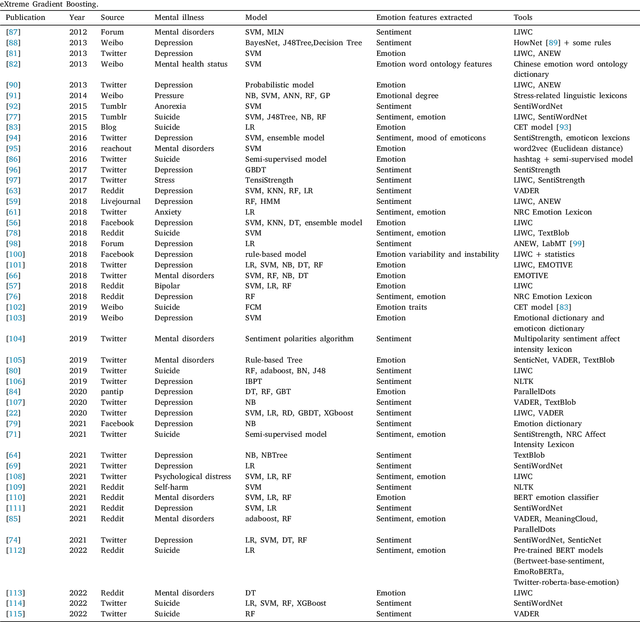
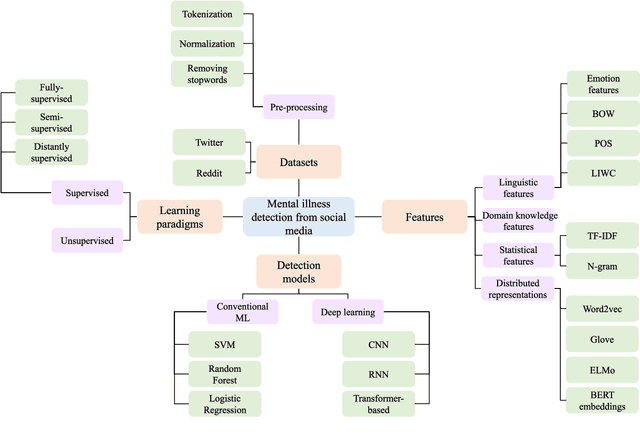
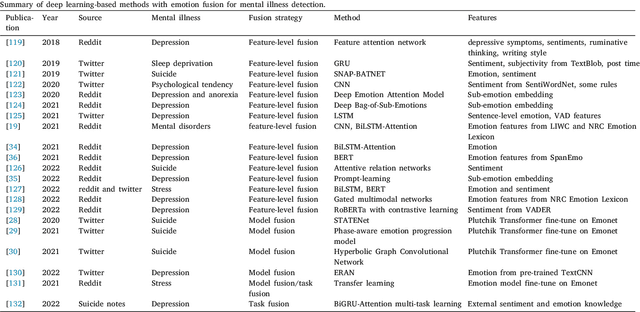
Mental illnesses are one of the most prevalent public health problems worldwide, which negatively influence people's lives and society's health. With the increasing popularity of social media, there has been a growing research interest in the early detection of mental illness by analysing user-generated posts on social media. According to the correlation between emotions and mental illness, leveraging and fusing emotion information has developed into a valuable research topic. In this article, we provide a comprehensive survey of approaches to mental illness detection in social media that incorporate emotion fusion. We begin by reviewing different fusion strategies, along with their advantages and disadvantages. Subsequently, we discuss the major challenges faced by researchers working in this area, including issues surrounding the availability and quality of datasets, the performance of algorithms and interpretability. We additionally suggest some potential directions for future research.
* Accepted manuscript
PDFVQA: A New Dataset for Real-World VQA on PDF Documents
Apr 19, 2023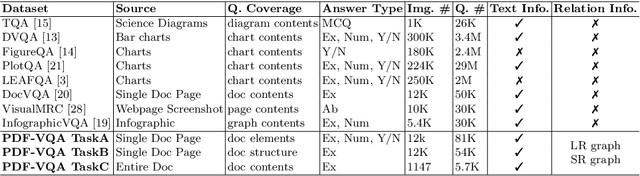
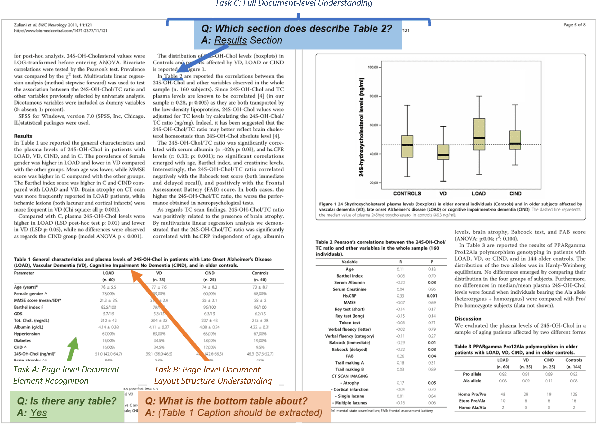
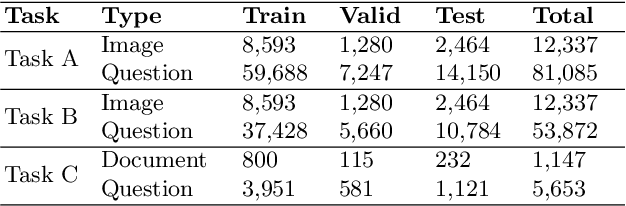
Document-based Visual Question Answering examines the document understanding of document images in conditions of natural language questions. We proposed a new document-based VQA dataset, PDF-VQA, to comprehensively examine the document understanding from various aspects, including document element recognition, document layout structural understanding as well as contextual understanding and key information extraction. Our PDF-VQA dataset extends the current scale of document understanding that limits on the single document page to the new scale that asks questions over the full document of multiple pages. We also propose a new graph-based VQA model that explicitly integrates the spatial and hierarchically structural relationships between different document elements to boost the document structural understanding. The performances are compared with several baselines over different question types and tasks\footnote{The full dataset will be released after paper acceptance.