 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Joint Client Assignment and UAV Route Planning for Indirect-Communication Federated Learning
Apr 24, 2023
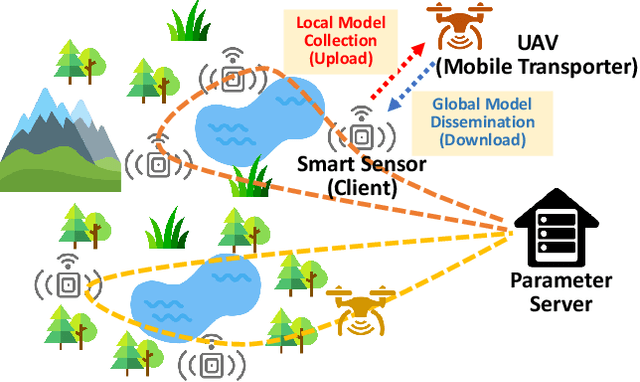
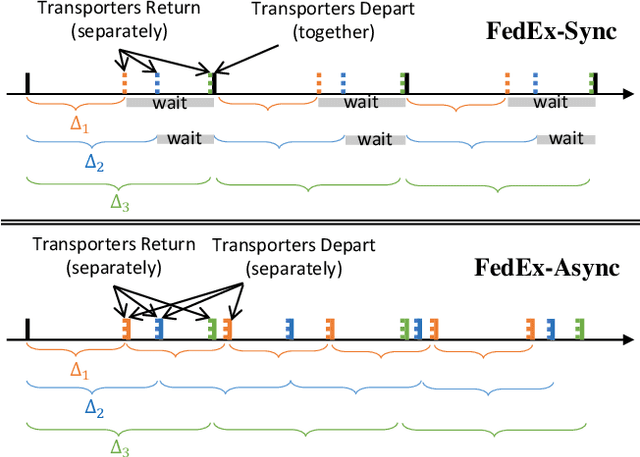

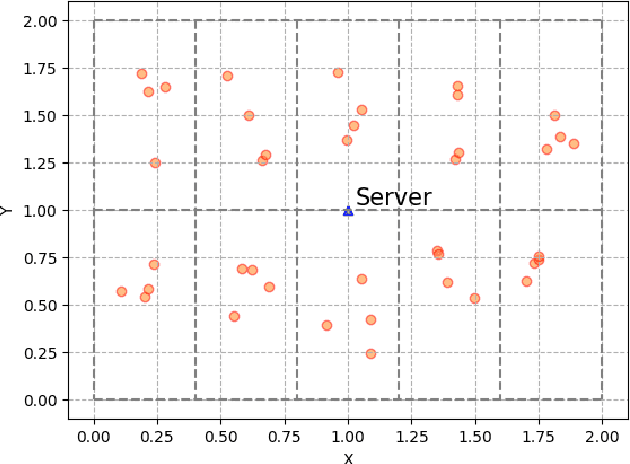
Federated Learning (FL) is a machine learning approach that enables the creation of shared models for powerful applications while allowing data to remain on devices. This approach provides benefits such as improved data privacy, security, and reduced latency. However, in some systems, direct communication between clients and servers may not be possible, such as remote areas without proper communication infrastructure. To overcome this challenge, a new framework called FedEx (Federated Learning via Model Express Delivery) is proposed. This framework employs mobile transporters, such as UAVs, to establish indirect communication channels between the server and clients. These transporters act as intermediaries and allow for model information exchange. The use of indirect communication presents new challenges for convergence analysis and optimization, as the delay introduced by the transporters' movement creates issues for both global model dissemination and local model collection. To address this, two algorithms, FedEx-Sync and FedEx-Async, are proposed for synchronized and asynchronized learning at the transporter level. Additionally, a bi-level optimization algorithm is proposed to solve the joint client assignment and route planning problem. Experimental validation using two public datasets in a simulated network demonstrates consistent results with the theory, proving the efficacy of FedEx.
MoniLog: An Automated Log-Based Anomaly Detection System for Cloud Computing Infrastructures
Apr 24, 2023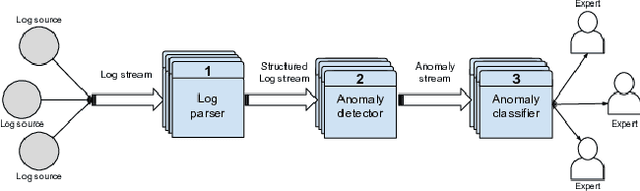
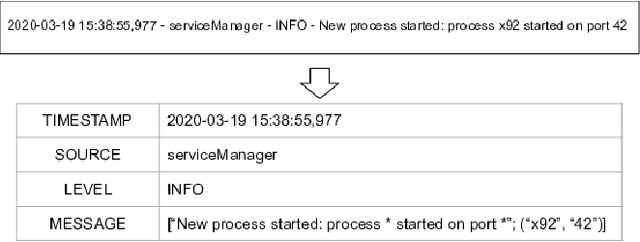
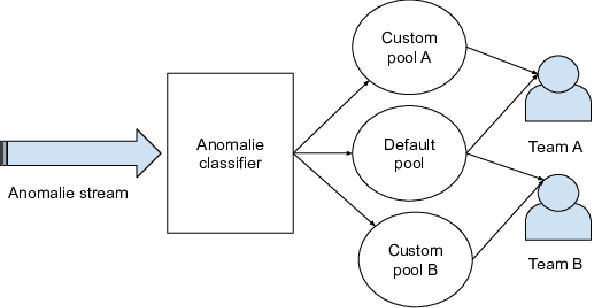

Within today's large-scale systems, one anomaly can impact millions of users. Detecting such events in real-time is essential to maintain the quality of services. It allows the monitoring team to prevent or diminish the impact of a failure. Logs are a core part of software development and maintenance, by recording detailed information at runtime. Such log data are universally available in nearly all computer systems. They enable developers as well as system maintainers to monitor and dissect anomalous events. For Cloud computing companies and large online platforms in general, growth is linked to the scaling potential. Automatizing the anomaly detection process is a promising way to ensure the scalability of monitoring capacities regarding the increasing volume of logs generated by modern systems. In this paper, we will introduce MoniLog, a distributed approach to detect real-time anomalies within large-scale environments. It aims to detect sequential and quantitative anomalies within a multi-source log stream. MoniLog is designed to structure a log stream and perform the monitoring of anomalous sequences. Its output classifier learns from the administrator's actions to label and evaluate the criticality level of anomalies.
Nearest-Neighbor Sampling Based Conditional Independence Testing
Apr 09, 2023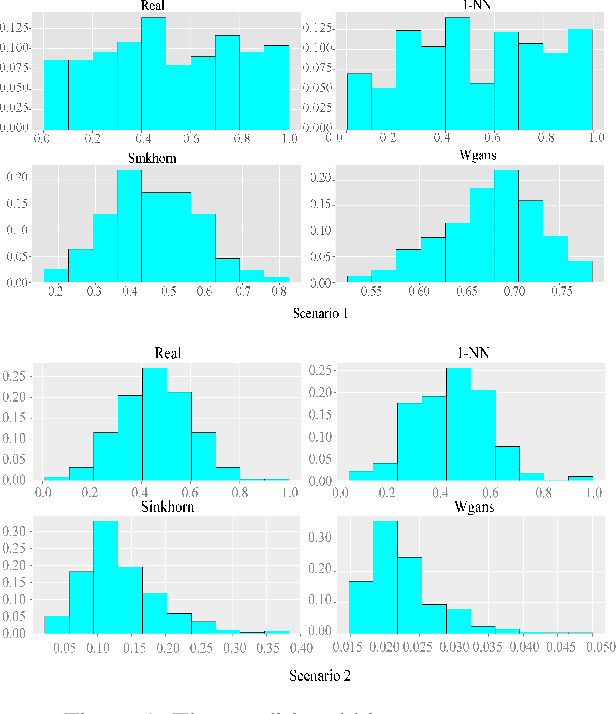

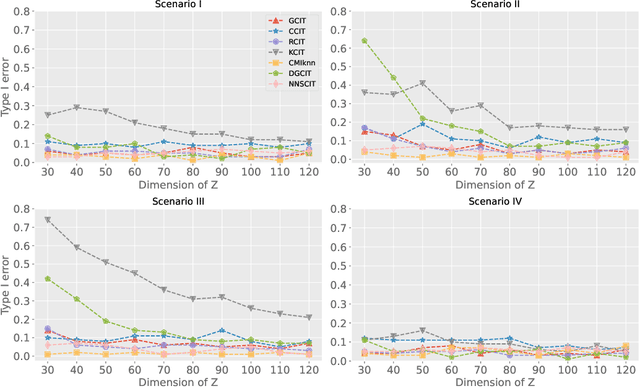
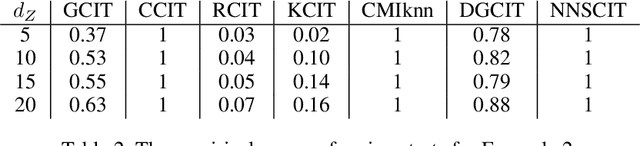
The conditional randomization test (CRT) was recently proposed to test whether two random variables X and Y are conditionally independent given random variables Z. The CRT assumes that the conditional distribution of X given Z is known under the null hypothesis and then it is compared to the distribution of the observed samples of the original data. The aim of this paper is to develop a novel alternative of CRT by using nearest-neighbor sampling without assuming the exact form of the distribution of X given Z. Specifically, we utilize the computationally efficient 1-nearest-neighbor to approximate the conditional distribution that encodes the null hypothesis. Then, theoretically, we show that the distribution of the generated samples is very close to the true conditional distribution in terms of total variation distance. Furthermore, we take the classifier-based conditional mutual information estimator as our test statistic. The test statistic as an empirical fundamental information theoretic quantity is able to well capture the conditional-dependence feature. We show that our proposed test is computationally very fast, while controlling type I and II errors quite well. Finally, we demonstrate the efficiency of our proposed test in both synthetic and real data analyses.
A Fast and Lightweight Network for Low-Light Image Enhancement
Apr 06, 2023
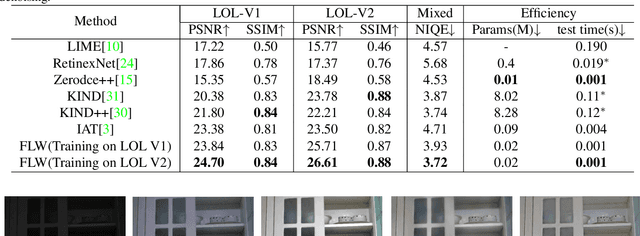
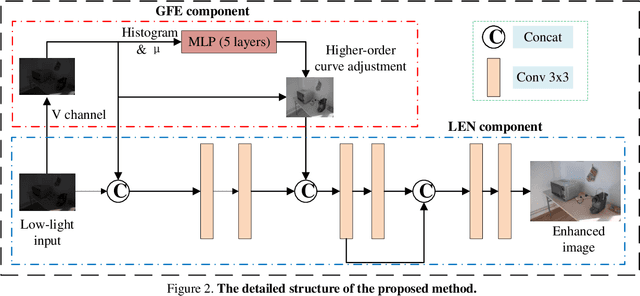
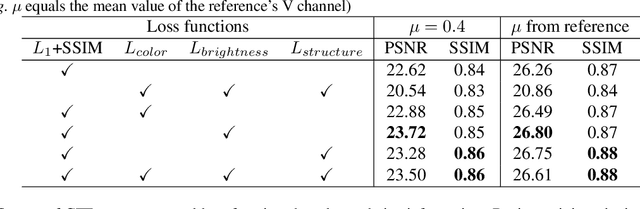
Low-light images often suffer from severe noise, low brightness, low contrast, and color deviation. While several low-light image enhancement methods have been proposed, there remains a lack of efficient methods that can simultaneously solve all of these problems. In this paper, we introduce FLW-Net, a Fast and LightWeight Network for low-light image enhancement that significantly improves processing speed and overall effect. To achieve efficient low-light image enhancement, we recognize the challenges of the lack of an absolute reference and the need for a large receptive field to obtain global contrast. Therefore, we propose an efficient global feature information extraction component and design loss functions based on relative information to overcome these challenges. Finally, we conduct comparative experiments to demonstrate the effectiveness of the proposed method, and the results confirm that FLW-Net can significantly reduce the complexity of supervised low-light image enhancement networks while improving processing effect. Code is available at https://github.com/hitzhangyu/FLW-Net
Exploiting the Complementarity of 2D and 3D Networks to Address Domain-Shift in 3D Semantic Segmentation
Apr 06, 2023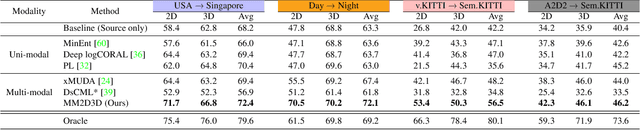
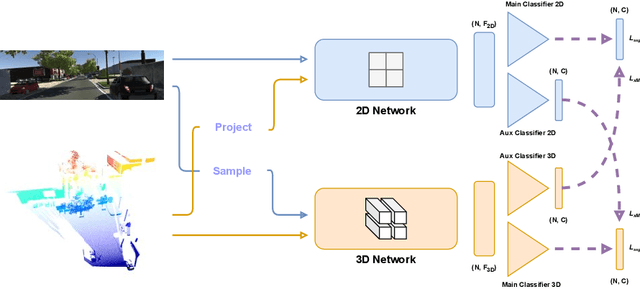

3D semantic segmentation is a critical task in many real-world applications, such as autonomous driving, robotics, and mixed reality. However, the task is extremely challenging due to ambiguities coming from the unstructured, sparse, and uncolored nature of the 3D point clouds. A possible solution is to combine the 3D information with others coming from sensors featuring a different modality, such as RGB cameras. Recent multi-modal 3D semantic segmentation networks exploit these modalities relying on two branches that process the 2D and 3D information independently, striving to maintain the strength of each modality. In this work, we first explain why this design choice is effective and then show how it can be improved to make the multi-modal semantic segmentation more robust to domain shift. Our surprisingly simple contribution achieves state-of-the-art performances on four popular multi-modal unsupervised domain adaptation benchmarks, as well as better results in a domain generalization scenario.
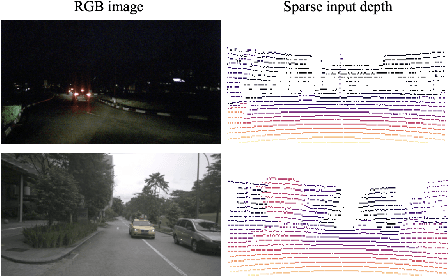
DeLiRa: Self-Supervised Depth, Light, and Radiance Fields
Apr 06, 2023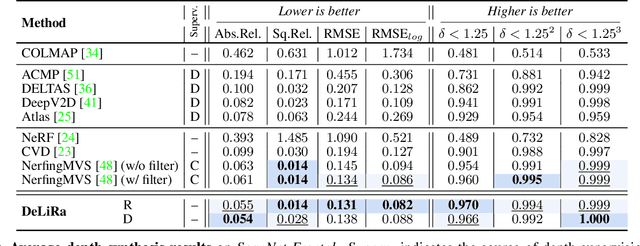
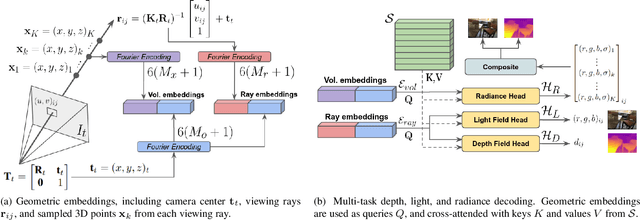
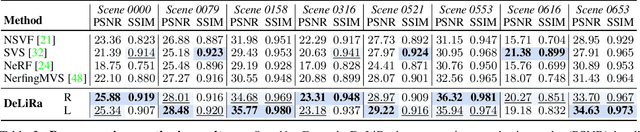
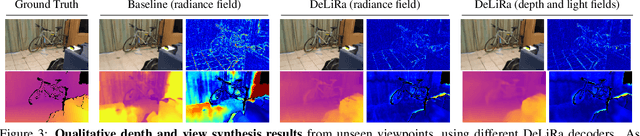
Differentiable volumetric rendering is a powerful paradigm for 3D reconstruction and novel view synthesis. However, standard volume rendering approaches struggle with degenerate geometries in the case of limited viewpoint diversity, a common scenario in robotics applications. In this work, we propose to use the multi-view photometric objective from the self-supervised depth estimation literature as a geometric regularizer for volumetric rendering, significantly improving novel view synthesis without requiring additional information. Building upon this insight, we explore the explicit modeling of scene geometry using a generalist Transformer, jointly learning a radiance field as well as depth and light fields with a set of shared latent codes. We demonstrate that sharing geometric information across tasks is mutually beneficial, leading to improvements over single-task learning without an increase in network complexity. Our DeLiRa architecture achieves state-of-the-art results on the ScanNet benchmark, enabling high quality volumetric rendering as well as real-time novel view and depth synthesis in the limited viewpoint diversity setting.
Dark-field and directional dark-field on low coherence X-ray sources with random mask modulations: validation with SAXS anisotropy measurements
Apr 20, 2023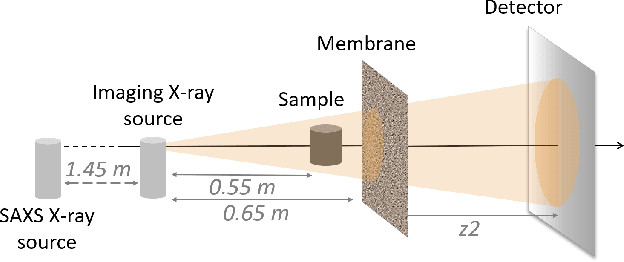
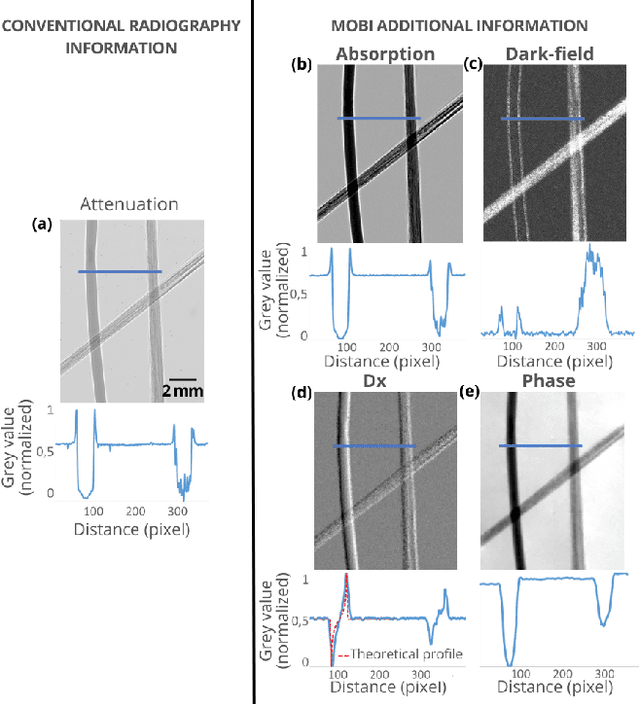
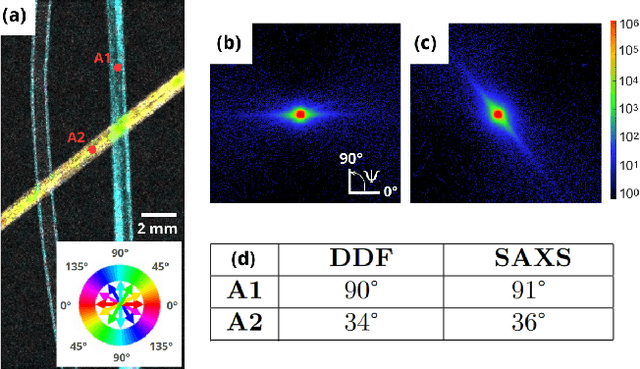

Phase Contrast Imaging (PCI), Dark-Field (DF) and Directional Dark-Field (DDF) imaging are recent X-ray imaging modalities that have demonstrated their interest by providing access to information and contrasts different from those provided by conventional absorption X-ray imaging. However, access to these two types of images is currently limited because the acquisitions require the use of coherent sources such as synchrotron radiation or complicated optical setups to exploit the coherence requirements. This work demonstrates the possibility of efficiently performing phase contrast, dark-field and directional dark-field imaging on a low-coherence laboratory system equipped with a conventional X-ray tube, using a simple, fast and robust single-mask technique. The transfer to a low spatial coherence laboratory system was made possible by using random modulation based imaging (MoBI) and extending the low coherence system algorithm to retrieve dark-field and directional dark-field.
A baseline on continual learning methods for video action recognition
Apr 20, 2023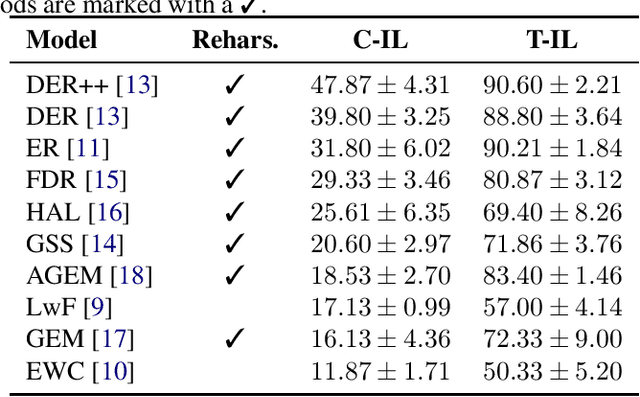
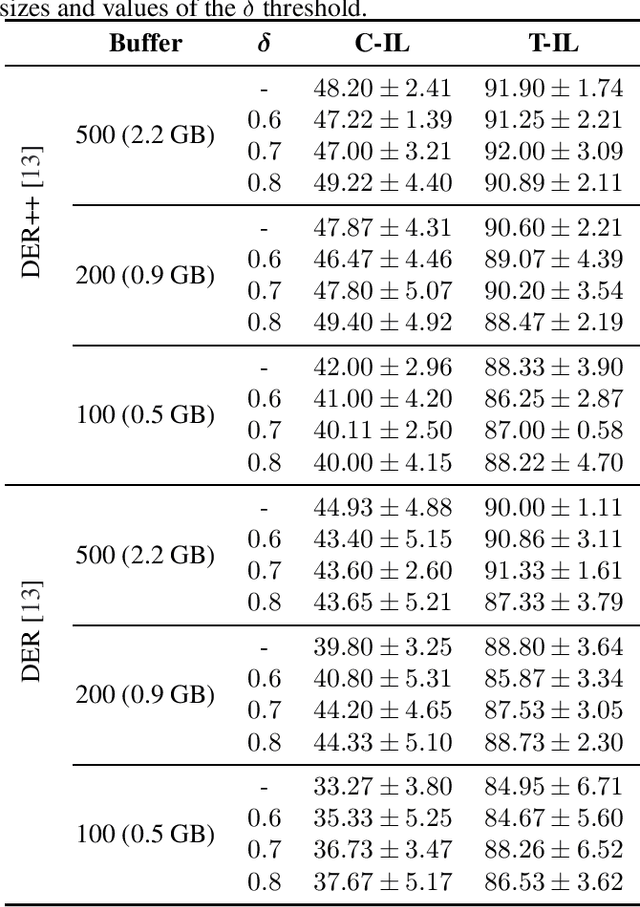
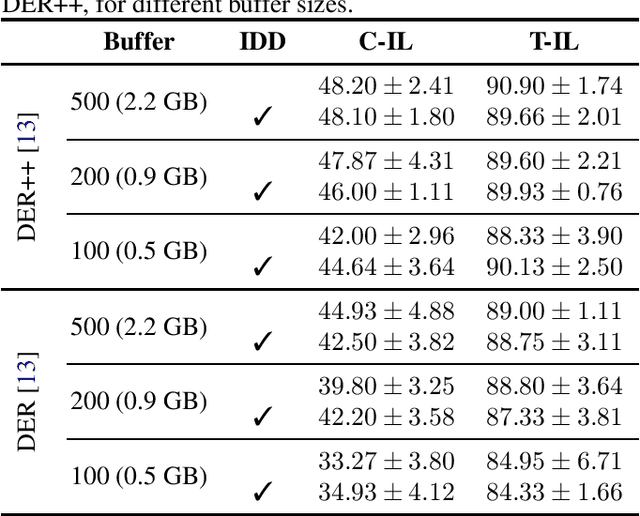
Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
Preventing Dimensional Collapse of Incomplete Multi-View Clustering via Direct Contrastive Learning
Mar 22, 2023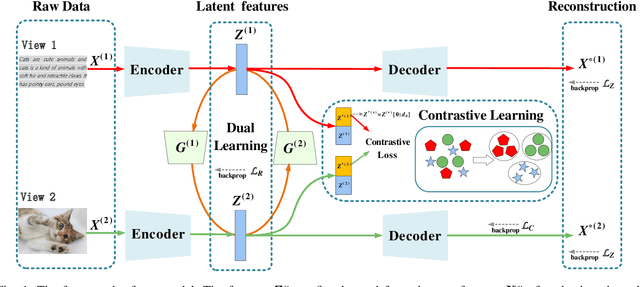
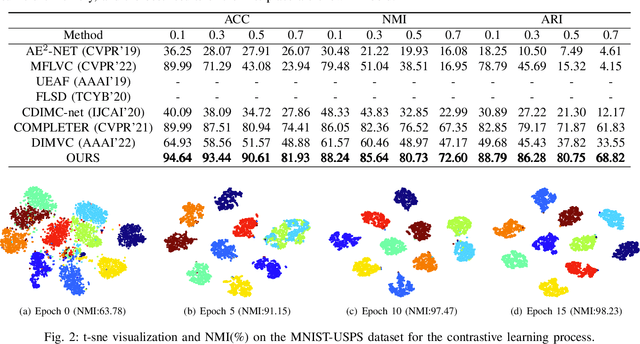

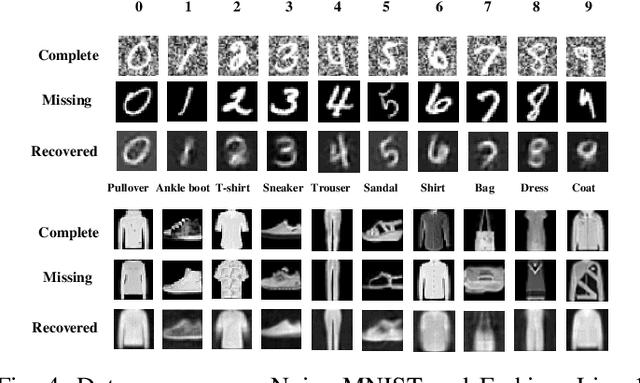
Incomplete multi-view clustering (IMVC) is an unsupervised approach, among which IMVC via contrastive learning has received attention due to its excellent performance. The previous methods have the following problems: 1) Over-reliance on additional projection heads when solving the dimensional collapse problem in which latent features are only valid in lower-dimensional subspaces during clustering. However, many parameters in the projection heads are unnecessary. 2) The recovered view contain inconsistent private information and useless private information will mislead the learning of common semantics due to consistent learning and reconstruction learning on the same feature. To address the above issues, we propose a novel incomplete multi-view contrastive clustering framework. This framework directly optimizes the latent feature subspace, utilizes the learned feature vectors and their sub-vectors for reconstruction learning and consistency learning, thereby effectively avoiding dimensional collapse without relying on projection heads. Since reconstruction loss and contrastive loss are performed on different features, the adverse effect of useless private information is reduced. For the incomplete data, the missing information is recovered by the cross-view prediction mechanism and the inconsistent information from different views is discarded by the minimum conditional entropy to further avoid the influence of private information. Extensive experimental results of the method on 5 public datasets show that the method achieves state-of-the-art clustering results.
A CTC Alignment-based Non-autoregressive Transformer for End-to-end Automatic Speech Recognition
Apr 15, 2023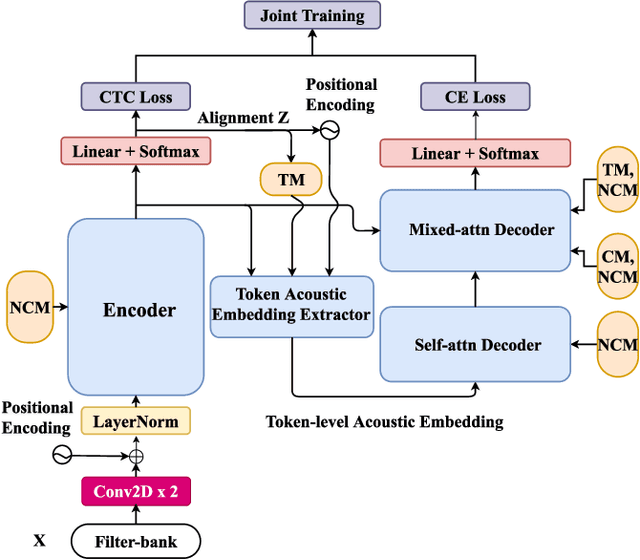
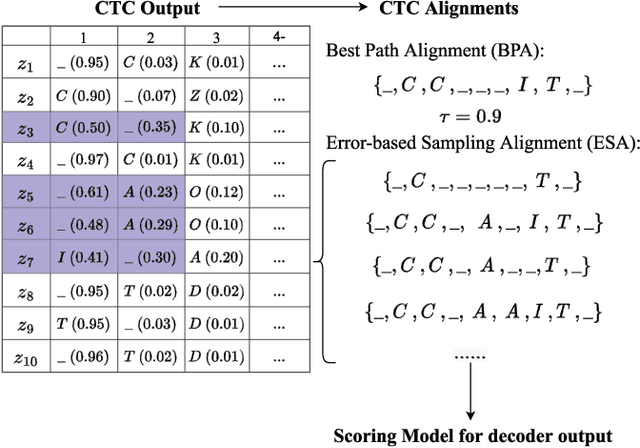
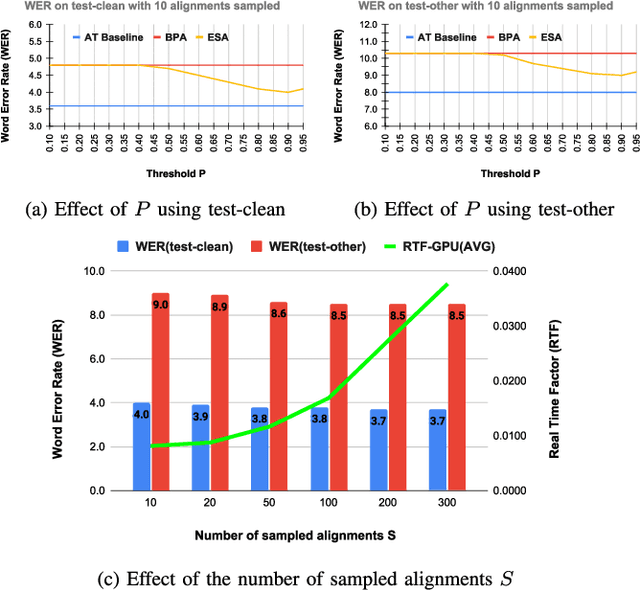
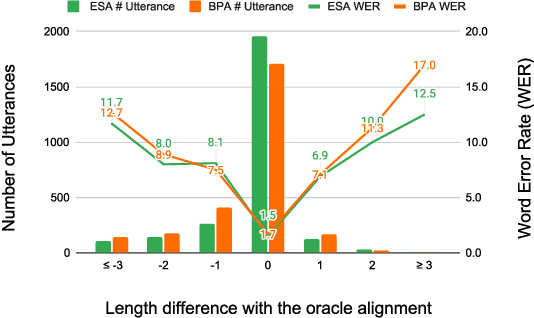
Recently, end-to-end models have been widely used in automatic speech recognition (ASR) systems. Two of the most representative approaches are connectionist temporal classification (CTC) and attention-based encoder-decoder (AED) models. Autoregressive transformers, variants of AED, adopt an autoregressive mechanism for token generation and thus are relatively slow during inference. In this paper, we present a comprehensive study of a CTC Alignment-based Single-Step Non-Autoregressive Transformer (CASS-NAT) for end-to-end ASR. In CASS-NAT, word embeddings in the autoregressive transformer (AT) are substituted with token-level acoustic embeddings (TAE) that are extracted from encoder outputs with the acoustical boundary information offered by the CTC alignment. TAE can be obtained in parallel, resulting in a parallel generation of output tokens. During training, Viterbi-alignment is used for TAE generation, and multiple training strategies are further explored to improve the word error rate (WER) performance. During inference, an error-based alignment sampling method is investigated in depth to reduce the alignment mismatch in the training and testing processes. Experimental results show that the CASS-NAT has a WER that is close to AT on various ASR tasks, while providing a ~24x inference speedup. With and without self-supervised learning, we achieve new state-of-the-art results for non-autoregressive models on several datasets. We also analyze the behavior of the CASS-NAT decoder to explain why it can perform similarly to AT. We find that TAEs have similar functionality to word embeddings for grammatical structures, which might indicate the possibility of learning some semantic information from TAEs without a language model.