 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Disentangled Contrastive Collaborative Filtering
May 04, 2023
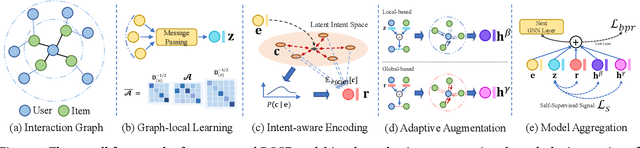
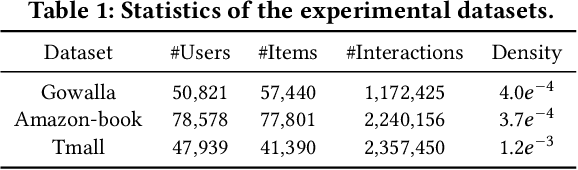
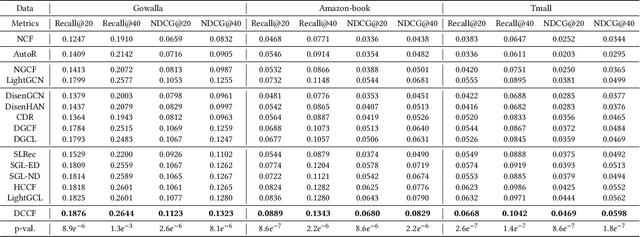
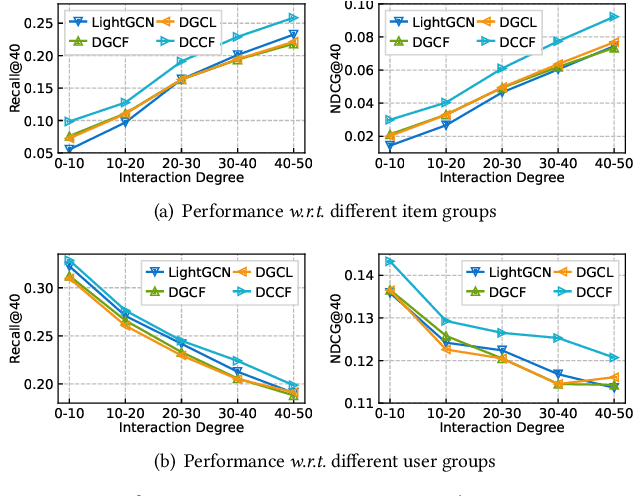
Recent studies show that graph neural networks (GNNs) are prevalent to model high-order relationships for collaborative filtering (CF). Towards this research line, graph contrastive learning (GCL) has exhibited powerful performance in addressing the supervision label shortage issue by learning augmented user and item representations. While many of them show their effectiveness, two key questions still remain unexplored: i) Most existing GCL-based CF models are still limited by ignoring the fact that user-item interaction behaviors are often driven by diverse latent intent factors (e.g., shopping for family party, preferred color or brand of products); ii) Their introduced non-adaptive augmentation techniques are vulnerable to noisy information, which raises concerns about the model's robustness and the risk of incorporating misleading self-supervised signals. In light of these limitations, we propose a Disentangled Contrastive Collaborative Filtering framework (DCCF) to realize intent disentanglement with self-supervised augmentation in an adaptive fashion. With the learned disentangled representations with global context, our DCCF is able to not only distill finer-grained latent factors from the entangled self-supervision signals but also alleviate the augmentation-induced noise. Finally, the cross-view contrastive learning task is introduced to enable adaptive augmentation with our parameterized interaction mask generator. Experiments on various public datasets demonstrate the superiority of our method compared to existing solutions. Our model implementation is released at the link https://github.com/HKUDS/DCCF.
BrainNPT: Pre-training of Transformer networks for brain network classification
May 04, 2023
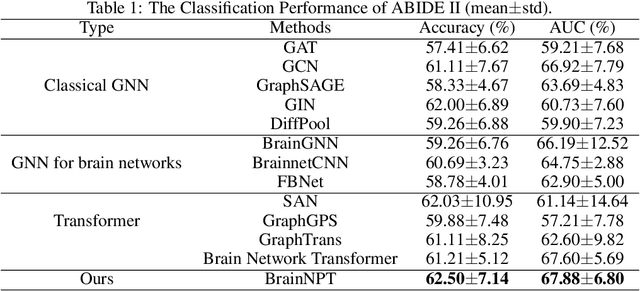
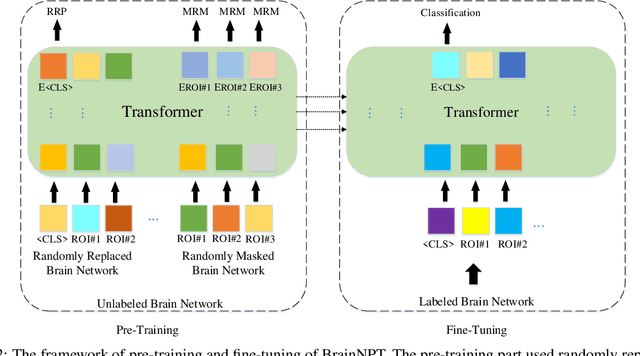

Deep learning methods have advanced quickly in brain imaging analysis over the past few years, but they are usually restricted by the limited labeled data. Pre-trained model on unlabeled data has presented promising improvement in feature learning in many domains, including natural language processing and computer vision. However, this technique is under-explored in brain network analysis. In this paper, we focused on pre-training methods with Transformer networks to leverage existing unlabeled data for brain functional network classification. First, we proposed a Transformer-based neural network, named as BrainNPT, for brain functional network classification. The proposed method leveraged <cls> token as a classification embedding vector for the Transformer model to effectively capture the representation of brain network. Second, We proposed a pre-training architecture with two pre-training strategies for BrainNPT model to leverage unlabeled brain network data to learn the structure information of brain networks. The results of classification experiments demonstrated the BrainNPT model without pre-training achieved the best performance with the state-of-the-art models, and the BrainNPT model with pre-training strongly outperformed the state-of-the-art models. The pre-training BrainNPT model improved 8.75% of accuracy compared with the model without pre-training. We further compared the pre-training strategies, analyzed the influence of the parameters of the model, and interpreted the fine-tuned model.
Self-Supervised 3D Scene Flow Estimation Guided by Superpoints
May 04, 2023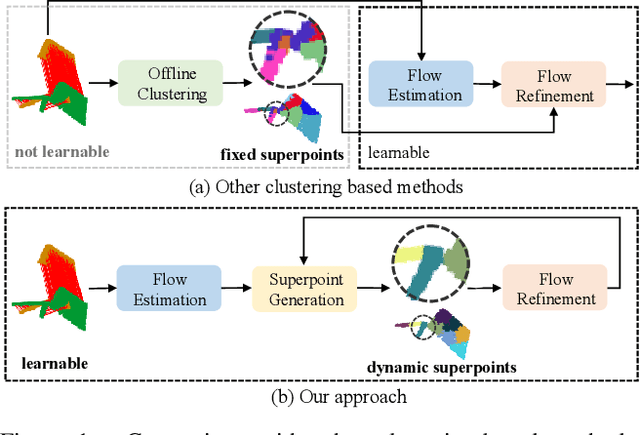
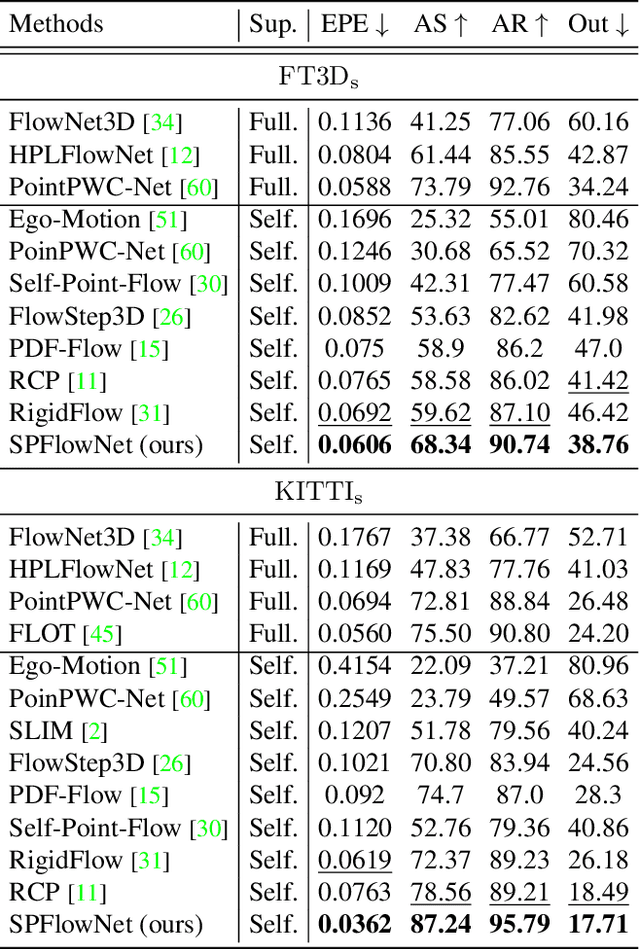
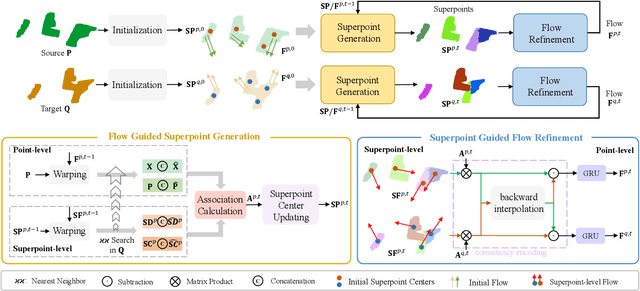
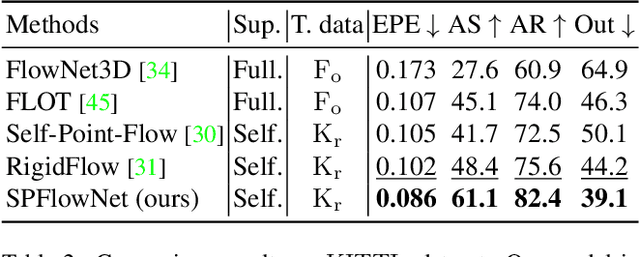
3D scene flow estimation aims to estimate point-wise motions between two consecutive frames of point clouds. Superpoints, i.e., points with similar geometric features, are usually employed to capture similar motions of local regions in 3D scenes for scene flow estimation. However, in existing methods, superpoints are generated with the offline clustering methods, which cannot characterize local regions with similar motions for complex 3D scenes well, leading to inaccurate scene flow estimation. To this end, we propose an iterative end-to-end superpoint based scene flow estimation framework, where the superpoints can be dynamically updated to guide the point-level flow prediction. Specifically, our framework consists of a flow guided superpoint generation module and a superpoint guided flow refinement module. In our superpoint generation module, we utilize the bidirectional flow information at the previous iteration to obtain the matching points of points and superpoint centers for soft point-to-superpoint association construction, in which the superpoints are generated for pairwise point clouds. With the generated superpoints, we first reconstruct the flow for each point by adaptively aggregating the superpoint-level flow, and then encode the consistency between the reconstructed flow of pairwise point clouds. Finally, we feed the consistency encoding along with the reconstructed flow into GRU to refine point-level flow. Extensive experiments on several different datasets show that our method can achieve promising performance.
ANetQA: A Large-scale Benchmark for Fine-grained Compositional Reasoning over Untrimmed Videos
May 04, 2023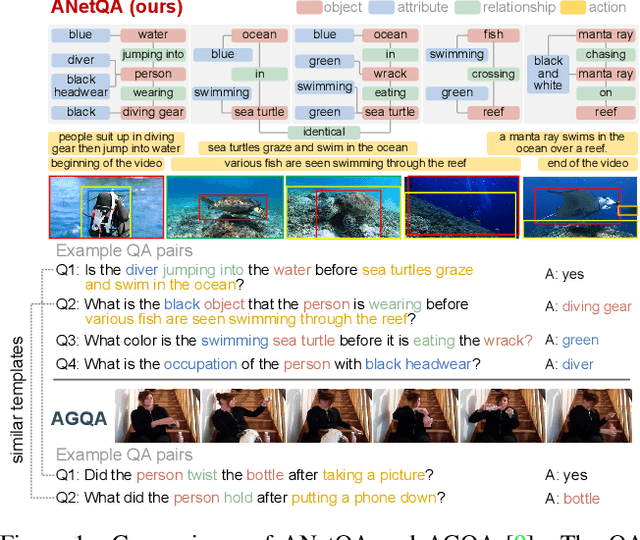

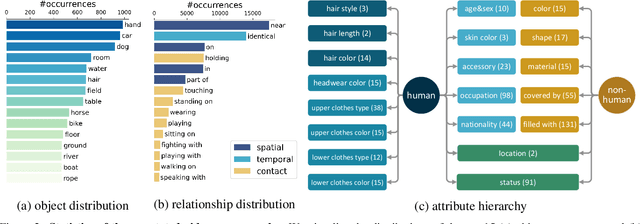
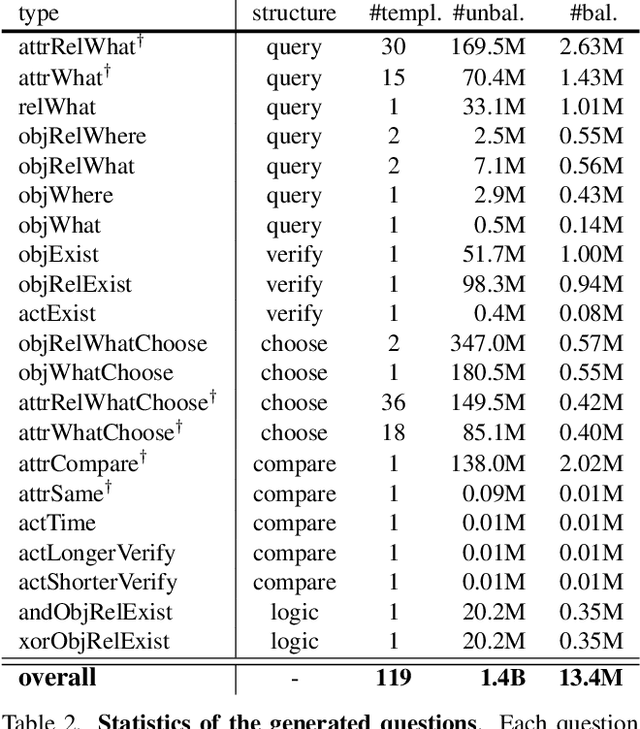
Building benchmarks to systemically analyze different capabilities of video question answering (VideoQA) models is challenging yet crucial. Existing benchmarks often use non-compositional simple questions and suffer from language biases, making it difficult to diagnose model weaknesses incisively. A recent benchmark AGQA poses a promising paradigm to generate QA pairs automatically from pre-annotated scene graphs, enabling it to measure diverse reasoning abilities with granular control. However, its questions have limitations in reasoning about the fine-grained semantics in videos as such information is absent in its scene graphs. To this end, we present ANetQA, a large-scale benchmark that supports fine-grained compositional reasoning over the challenging untrimmed videos from ActivityNet. Similar to AGQA, the QA pairs in ANetQA are automatically generated from annotated video scene graphs. The fine-grained properties of ANetQA are reflected in the following: (i) untrimmed videos with fine-grained semantics; (ii) spatio-temporal scene graphs with fine-grained taxonomies; and (iii) diverse questions generated from fine-grained templates. ANetQA attains 1.4 billion unbalanced and 13.4 million balanced QA pairs, which is an order of magnitude larger than AGQA with a similar number of videos. Comprehensive experiments are performed for state-of-the-art methods. The best model achieves 44.5% accuracy while human performance tops out at 84.5%, leaving sufficient room for improvement.
StyleGenes: Discrete and Efficient Latent Distributions for GANs
Apr 30, 2023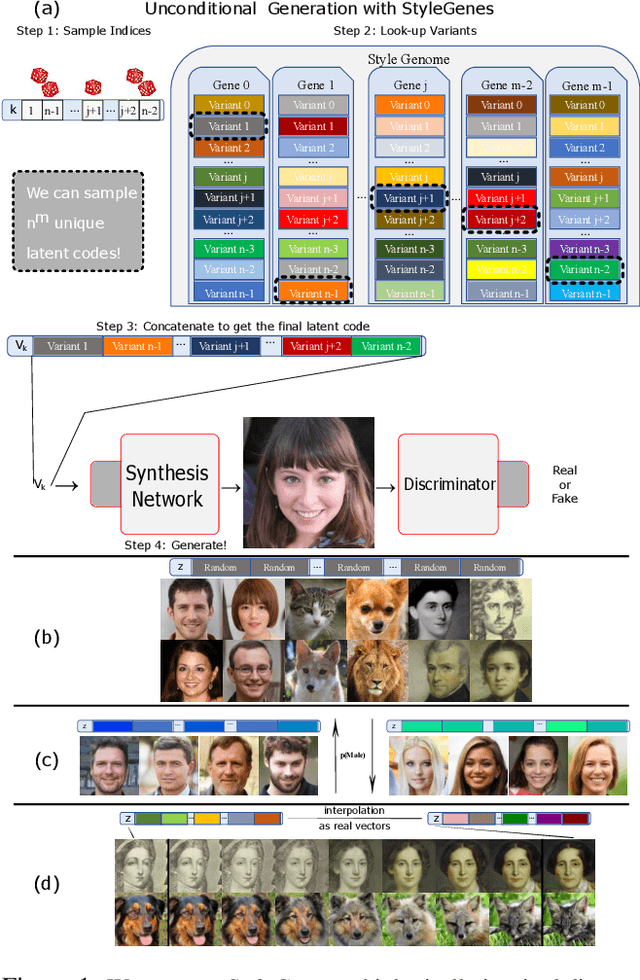


We propose a discrete latent distribution for Generative Adversarial Networks (GANs). Instead of drawing latent vectors from a continuous prior, we sample from a finite set of learnable latents. However, a direct parametrization of such a distribution leads to an intractable linear increase in memory in order to ensure sufficient sample diversity. We address this key issue by taking inspiration from the encoding of information in biological organisms. Instead of learning a separate latent vector for each sample, we split the latent space into a set of genes. For each gene, we train a small bank of gene variants. Thus, by independently sampling a variant for each gene and combining them into the final latent vector, our approach can represent a vast number of unique latent samples from a compact set of learnable parameters. Interestingly, our gene-inspired latent encoding allows for new and intuitive approaches to latent-space exploration, enabling conditional sampling from our unconditionally trained model. Moreover, our approach preserves state-of-the-art photo-realism while achieving better disentanglement than the widely-used StyleMapping network.
Object-Centric Voxelization of Dynamic Scenes via Inverse Neural Rendering
Apr 30, 2023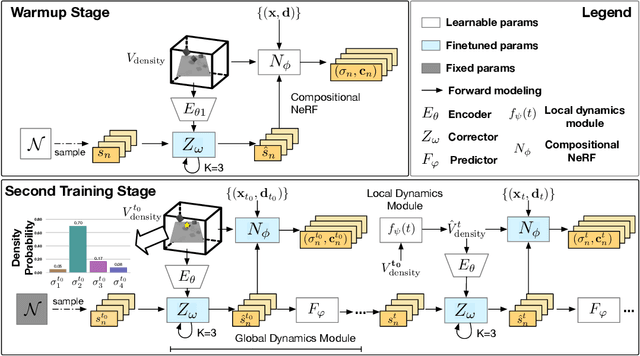
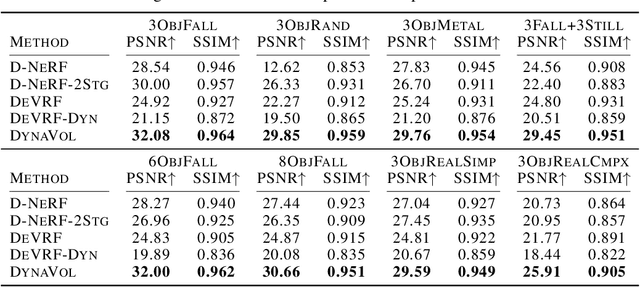
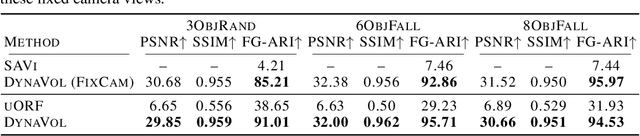
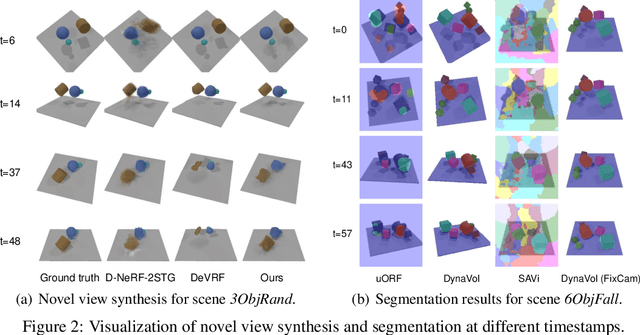
Understanding the compositional dynamics of the world in unsupervised 3D scenarios is challenging. Existing approaches either fail to make effective use of time cues or ignore the multi-view consistency of scene decomposition. In this paper, we propose DynaVol, an inverse neural rendering framework that provides a pilot study for learning time-varying volumetric representations for dynamic scenes with multiple entities (like objects). It has two main contributions. First, it maintains a time-dependent 3D grid, which dynamically and flexibly binds the spatial locations to different entities, thus encouraging the separation of information at a representational level. Second, our approach jointly learns grid-level local dynamics, object-level global dynamics, and the compositional neural radiance fields in an end-to-end architecture, thereby enhancing the spatiotemporal consistency of object-centric scene voxelization. We present a two-stage training scheme for DynaVol and validate its effectiveness on various benchmarks with multiple objects, diverse dynamics, and real-world shapes and textures. We present visualization at https://sites.google.com/view/dynavol-visual.
StyleLipSync: Style-based Personalized Lip-sync Video Generation
Apr 30, 2023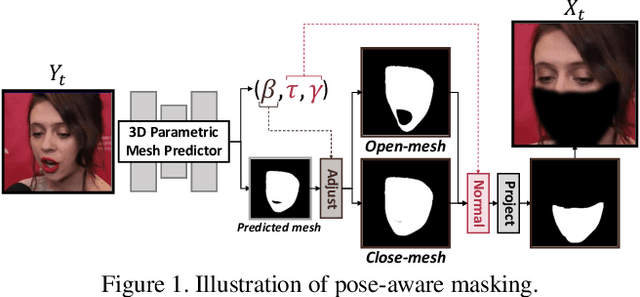
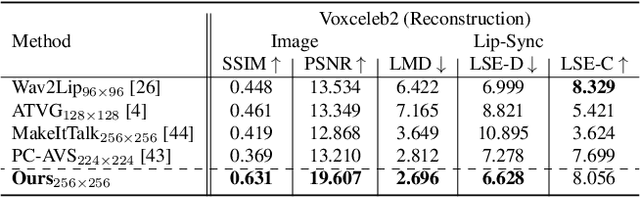
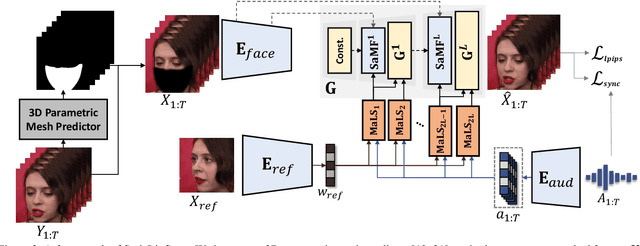
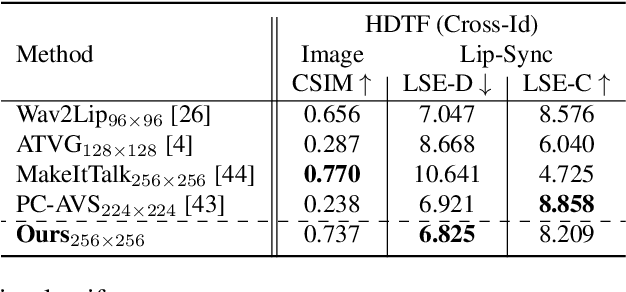
In this paper, we present StyleLipSync, a style-based personalized lip-sync video generative model that can generate identity-agnostic lip-synchronizing video from arbitrary audio. To generate a video of arbitrary identities, we leverage expressive lip prior from the semantically rich latent space of a pre-trained StyleGAN, where we can also design a video consistency with a linear transformation. In contrast to the previous lip-sync methods, we introduce pose-aware masking that dynamically locates the mask to improve the naturalness over frames by utilizing a 3D parametric mesh predictor frame by frame. Moreover, we propose a few-shot lip-sync adaptation method for an arbitrary person by introducing a sync regularizer that preserves lips-sync generalization while enhancing the person-specific visual information. Extensive experiments demonstrate that our model can generate accurate lip-sync videos even with the zero-shot setting and enhance characteristics of an unseen face using a few seconds of target video through the proposed adaptation method. Please refer to our project page.
Contextual Response Interpretation for Automated Structured Interviews: A Case Study in Market Research
Apr 30, 2023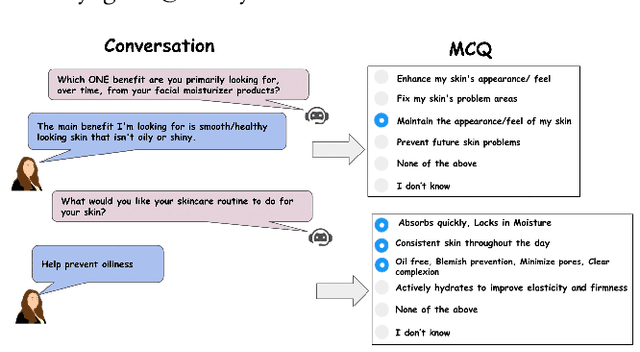
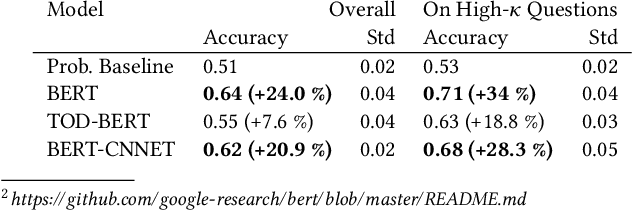
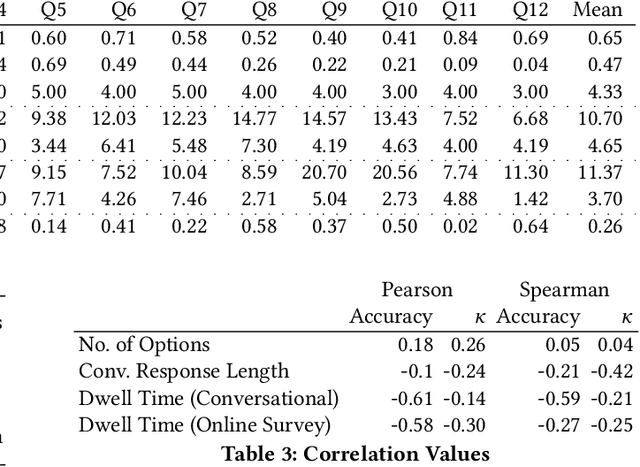
Structured interviews are used in many settings, importantly in market research on topics such as brand perception, customer habits, or preferences, which are critical to product development, marketing, and e-commerce at large. Such interviews generally consist of a series of questions that are asked to a participant. These interviews are typically conducted by skilled interviewers, who interpret the responses from the participants and can adapt the interview accordingly. Using automated conversational agents to conduct such interviews would enable reaching a much larger and potentially more diverse group of participants than currently possible. However, the technical challenges involved in building such a conversational system are relatively unexplored. To learn more about these challenges, we convert a market research multiple-choice questionnaire to a conversational format and conduct a user study. We address the key task of conducting structured interviews, namely interpreting the participant's response, for example, by matching it to one or more predefined options. Our findings can be applied to improve response interpretation for the information elicitation phase of conversational recommender systems.
SMILE: Single-turn to Multi-turn Inclusive Language Expansion via ChatGPT for Mental Health Support
Apr 30, 2023
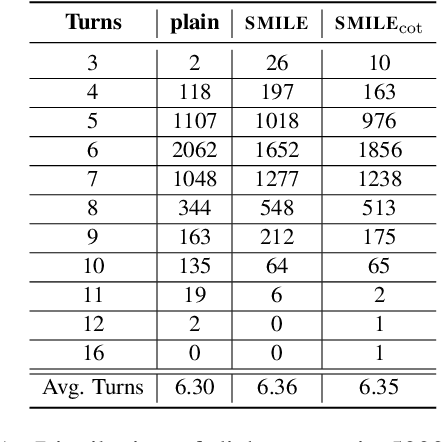


There has been an increasing research interest in developing specialized dialogue systems that can offer mental health support. However, gathering large-scale and real-life multi-turn conversations for mental health support poses challenges due to the sensitivity of personal information, as well as the time and cost involved. To address these issues, we introduce the SMILE approach, an inclusive language expansion technique that employs ChatGPT to extend public single-turn dialogues into multi-turn ones. Our research first presents a preliminary exploratory study that validates the effectiveness of the SMILE approach. Furthermore, we conduct a comprehensive and systematic contrastive analysis of datasets generated with and without the SMILE approach, demonstrating that the SMILE method results in a large-scale, diverse, and close-to-real-life multi-turn mental health support conversation corpus, including dialog topics, lexical and semantic features. Finally, we use the collected corpus (SMILECHAT) to develop a more effective dialogue system that offers emotional support and constructive suggestions in multi-turn conversations for mental health support.
PIE-QG: Paraphrased Information Extraction for Unsupervised Question Generation from Small Corpora
Jan 03, 2023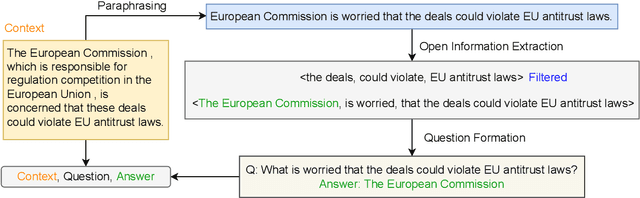
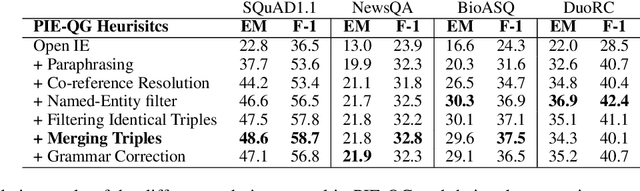
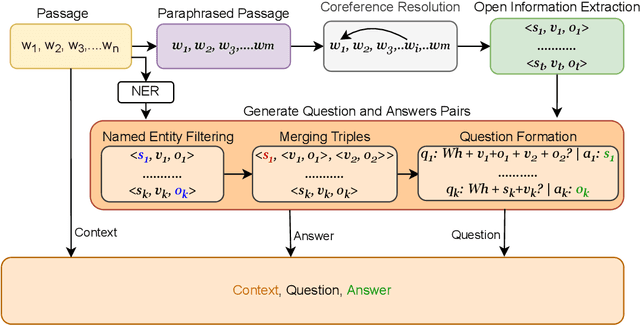
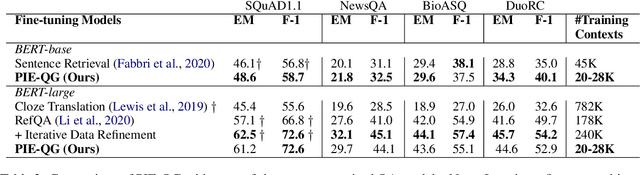
Supervised Question Answering systems (QA systems) rely on domain-specific human-labeled data for training. Unsupervised QA systems generate their own question-answer training pairs, typically using secondary knowledge sources to achieve this outcome. Our approach (called PIE-QG) uses Open Information Extraction (OpenIE) to generate synthetic training questions from paraphrased passages and uses the question-answer pairs as training data for a language model for a state-of-the-art QA system based on BERT. Triples in the form of <subject, predicate, object> are extracted from each passage, and questions are formed with subjects (or objects) and predicates while objects (or subjects) are considered as answers. Experimenting on five extractive QA datasets demonstrates that our technique achieves on-par performance with existing state-of-the-art QA systems with the benefit of being trained on an order of magnitude fewer documents and without any recourse to external reference data sources.