 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Monotonic Representation of Numeric Properties in Language Models
Mar 15, 2024
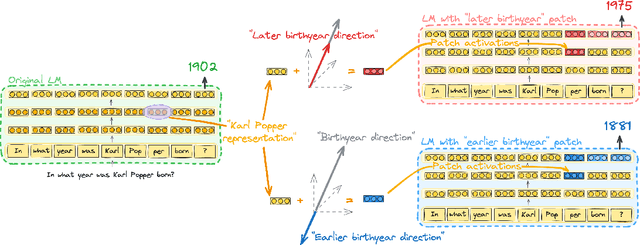

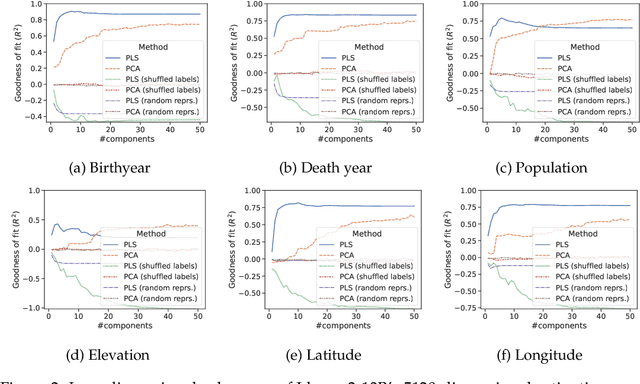
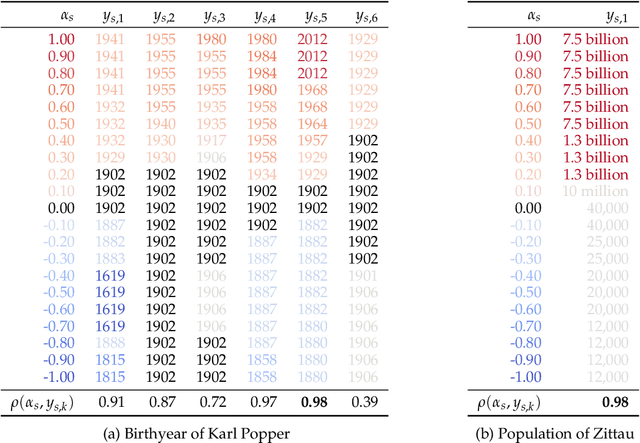
Language models (LMs) can express factual knowledge involving numeric properties such as Karl Popper was born in 1902. However, how this information is encoded in the model's internal representations is not understood well. Here, we introduce a simple method for finding and editing representations of numeric properties such as an entity's birth year. Empirically, we find low-dimensional subspaces that encode numeric properties monotonically, in an interpretable and editable fashion. When editing representations along directions in these subspaces, LM output changes accordingly. For example, by patching activations along a "birthyear" direction we can make the LM express an increasingly late birthyear: Karl Popper was born in 1929, Karl Popper was born in 1957, Karl Popper was born in 1968. Property-encoding directions exist across several numeric properties in all models under consideration, suggesting the possibility that monotonic representation of numeric properties consistently emerges during LM pretraining. Code: https://github.com/bheinzerling/numeric-property-repr
A Novel Bioinspired Neuromorphic Vision-based Tactile Sensor for Fast Tactile Perception
Mar 15, 2024
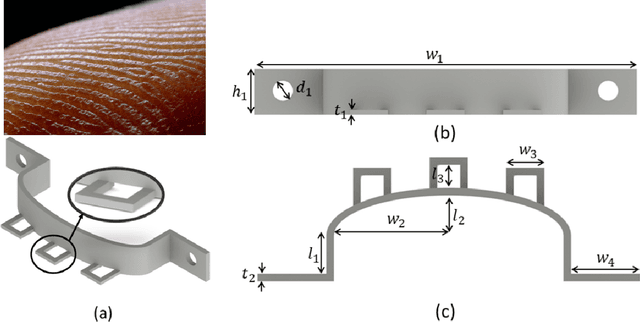
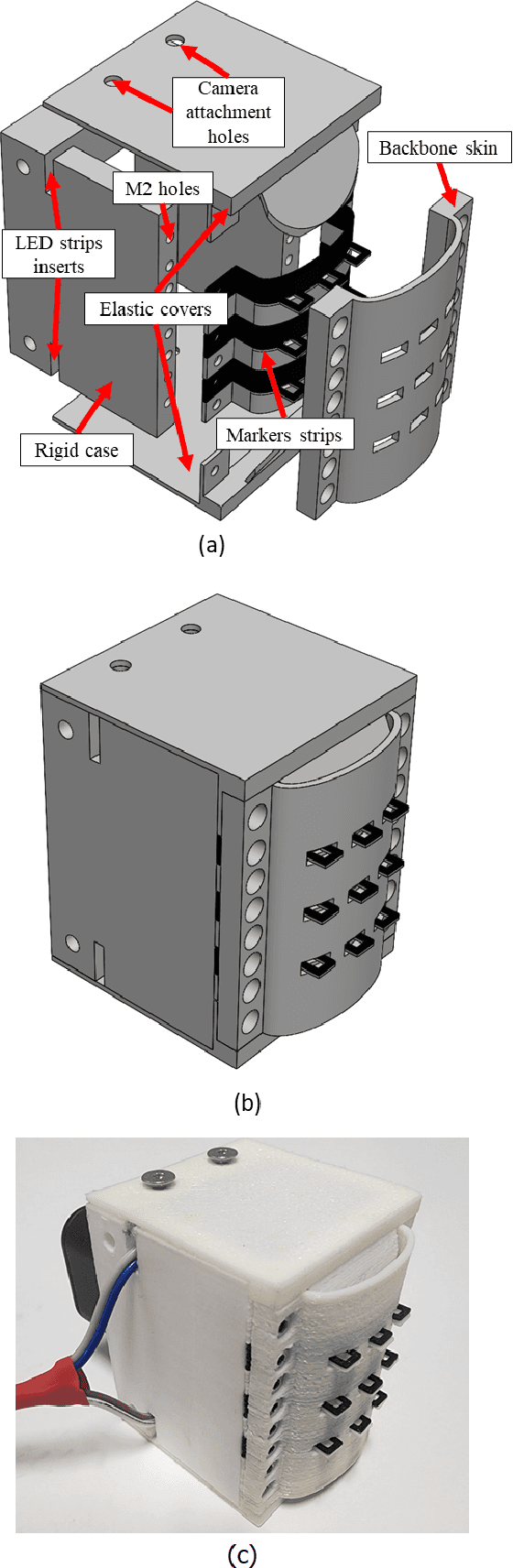

Tactile sensing represents a crucial technique that can enhance the performance of robotic manipulators in various tasks. This work presents a novel bioinspired neuromorphic vision-based tactile sensor that uses an event-based camera to quickly capture and convey information about the interactions between robotic manipulators and their environment. The camera in the sensor observes the deformation of a flexible skin manufactured from a cheap and accessible 3D printed material, whereas a 3D printed rigid casing houses the components of the sensor together. The sensor is tested in a grasping stage classification task involving several objects using a data-driven learning-based approach. The results show that the proposed approach enables the sensor to detect pressing and slip incidents within a speed of 2 ms. The fast tactile perception properties of the proposed sensor makes it an ideal candidate for safe grasping of different objects in industries that involve high-speed pick-and-place operations.
Ignore Me But Don't Replace Me: Utilizing Non-Linguistic Elements for Pretraining on the Cybersecurity Domain
Mar 15, 2024
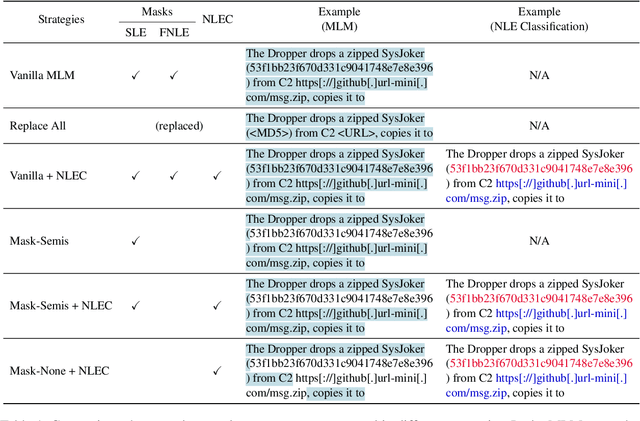
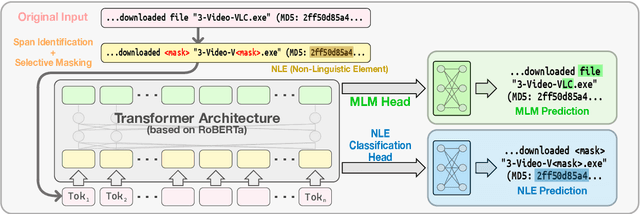
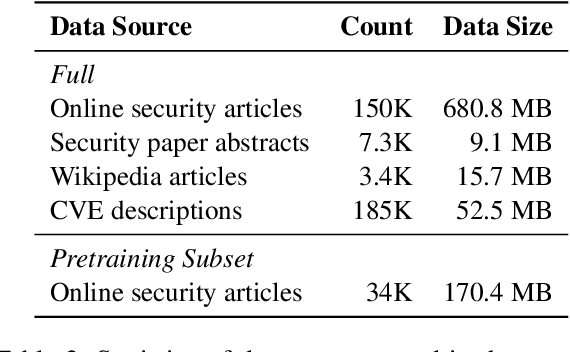
Cybersecurity information is often technically complex and relayed through unstructured text, making automation of cyber threat intelligence highly challenging. For such text domains that involve high levels of expertise, pretraining on in-domain corpora has been a popular method for language models to obtain domain expertise. However, cybersecurity texts often contain non-linguistic elements (such as URLs and hash values) that could be unsuitable with the established pretraining methodologies. Previous work in other domains have removed or filtered such text as noise, but the effectiveness of these methods have not been investigated, especially in the cybersecurity domain. We propose different pretraining methodologies and evaluate their effectiveness through downstream tasks and probing tasks. Our proposed strategy (selective MLM and jointly training NLE token classification) outperforms the commonly taken approach of replacing non-linguistic elements (NLEs). We use our domain-customized methodology to train CyBERTuned, a cybersecurity domain language model that outperforms other cybersecurity PLMs on most tasks.
Towards Adversarially Robust Dataset Distillation by Curvature Regularization
Mar 15, 2024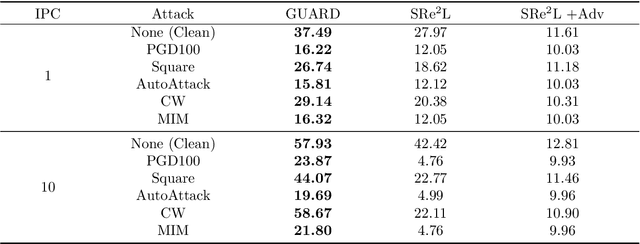

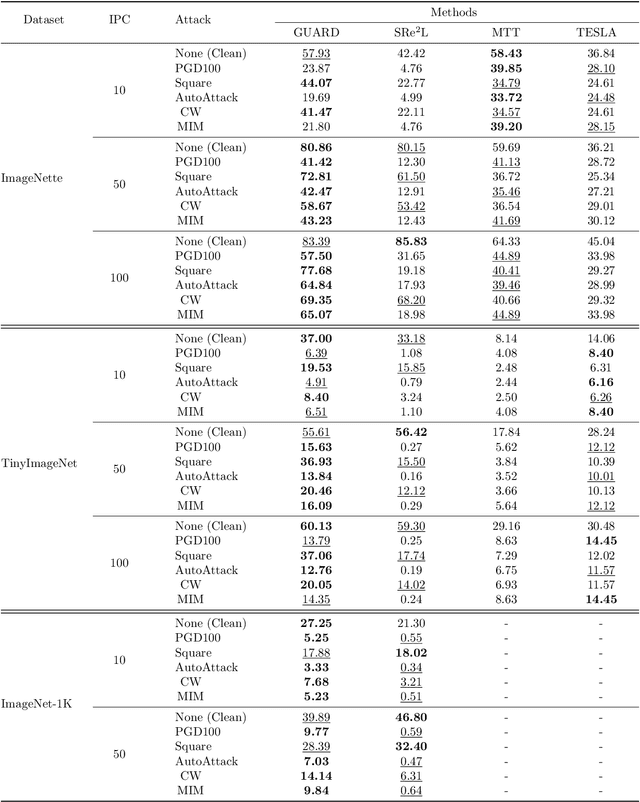
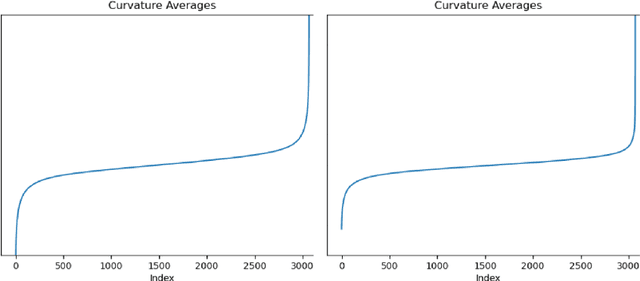
Dataset distillation (DD) allows datasets to be distilled to fractions of their original size while preserving the rich distributional information so that models trained on the distilled datasets can achieve a comparable accuracy while saving significant computational loads. Recent research in this area has been focusing on improving the accuracy of models trained on distilled datasets. In this paper, we aim to explore a new perspective of DD. We study how to embed adversarial robustness in distilled datasets, so that models trained on these datasets maintain the high accuracy and meanwhile acquire better adversarial robustness. We propose a new method that achieves this goal by incorporating curvature regularization into the distillation process with much less computational overhead than standard adversarial training. Extensive empirical experiments suggest that our method not only outperforms standard adversarial training on both accuracy and robustness with less computation overhead but is also capable of generating robust distilled datasets that can withstand various adversarial attacks.
LLMvsSmall Model? Large Language Model Based Text Augmentation Enhanced Personality Detection Model
Mar 12, 2024
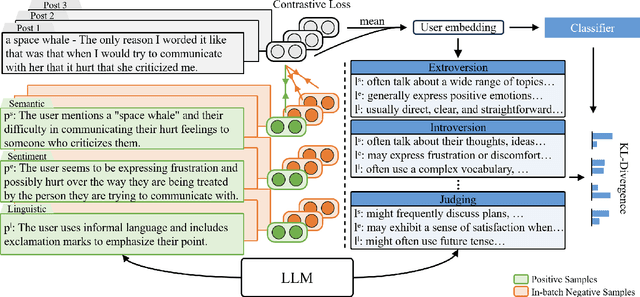
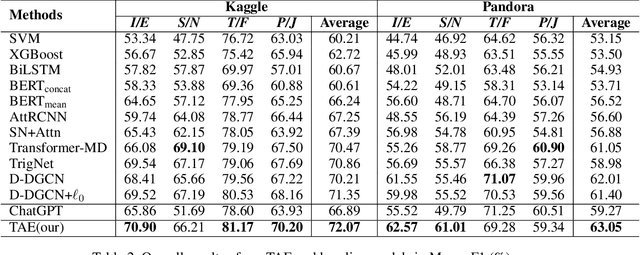
Personality detection aims to detect one's personality traits underlying in social media posts. One challenge of this task is the scarcity of ground-truth personality traits which are collected from self-report questionnaires. Most existing methods learn post features directly by fine-tuning the pre-trained language models under the supervision of limited personality labels. This leads to inferior quality of post features and consequently affects the performance. In addition, they treat personality traits as one-hot classification labels, overlooking the semantic information within them. In this paper, we propose a large language model (LLM) based text augmentation enhanced personality detection model, which distills the LLM's knowledge to enhance the small model for personality detection, even when the LLM fails in this task. Specifically, we enable LLM to generate post analyses (augmentations) from the aspects of semantic, sentiment, and linguistic, which are critical for personality detection. By using contrastive learning to pull them together in the embedding space, the post encoder can better capture the psycho-linguistic information within the post representations, thus improving personality detection. Furthermore, we utilize the LLM to enrich the information of personality labels for enhancing the detection performance. Experimental results on the benchmark datasets demonstrate that our model outperforms the state-of-the-art methods on personality detection.
Emergency Response Inference Mapping (ERIMap): A Bayesian Network-based Method for Dynamic Observation Processing in Spatially Distributed Emergencies
Mar 11, 2024

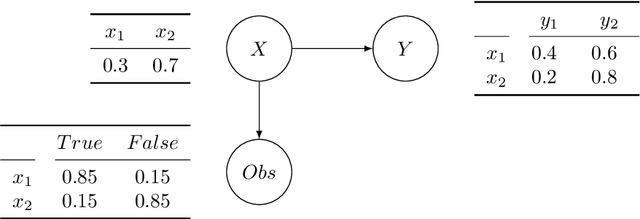

In emergencies, high stake decisions often have to be made under time pressure and strain. In order to support such decisions, information from various sources needs to be collected and processed rapidly. The information available tends to be temporally and spatially variable, uncertain, and sometimes conflicting, leading to potential biases in decisions. Currently, there is a lack of systematic approaches for information processing and situation assessment which meet the particular demands of emergency situations. To address this gap, we present a Bayesian network-based method called ERIMap that is tailored to the complex information-scape during emergencies. The method enables the systematic and rapid processing of heterogeneous and potentially uncertain observations and draws inferences about key variables of an emergency. It thereby reduces complexity and cognitive load for decision makers. The output of the ERIMap method is a dynamically evolving and spatially resolved map of beliefs about key variables of an emergency that is updated each time a new observation becomes available. The method is illustrated in a case study in which an emergency response is triggered by an accident causing a gas leakage on a chemical plant site.
EfficientMorph: Parameter-Efficient Transformer-Based Architecture for 3D Image Registration
Mar 16, 2024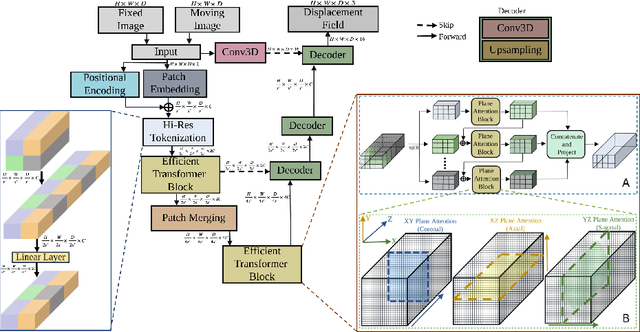
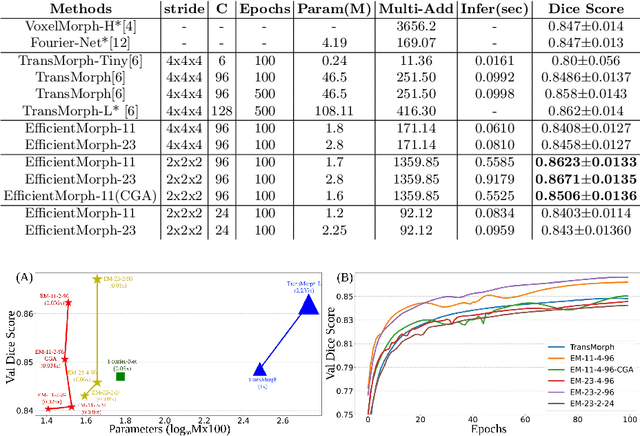
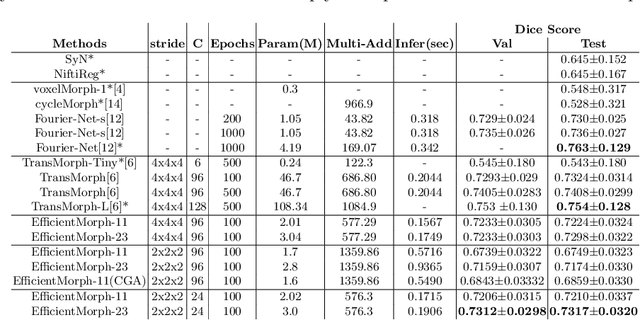
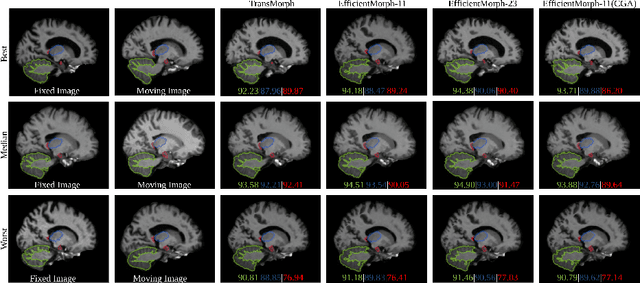
Transformers have emerged as the state-of-the-art architecture in medical image registration, outperforming convolutional neural networks (CNNs) by addressing their limited receptive fields and overcoming gradient instability in deeper models. Despite their success, transformer-based models require substantial resources for training, including data, memory, and computational power, which may restrict their applicability for end users with limited resources. In particular, existing transformer-based 3D image registration architectures face three critical gaps that challenge their efficiency and effectiveness. Firstly, while mitigating the quadratic complexity of full attention by focusing on local regions, window-based attention mechanisms often fail to adequately integrate local and global information. Secondly, feature similarities across attention heads that were recently found in multi-head attention architectures indicate a significant computational redundancy, suggesting that the capacity of the network could be better utilized to enhance performance. Lastly, the granularity of tokenization, a key factor in registration accuracy, presents a trade-off; smaller tokens improve detail capture at the cost of higher computational complexity, increased memory demands, and a risk of overfitting. Here, we propose EfficientMorph, a transformer-based architecture for unsupervised 3D image registration. It optimizes the balance between local and global attention through a plane-based attention mechanism, reduces computational redundancy via cascaded group attention, and captures fine details without compromising computational efficiency, thanks to a Hi-Res tokenization strategy complemented by merging operations. Notably, EfficientMorph sets a new benchmark for performance on the OASIS dataset with 16-27x fewer parameters.
StreamingDialogue: Prolonged Dialogue Learning via Long Context Compression with Minimal Losses
Mar 13, 2024
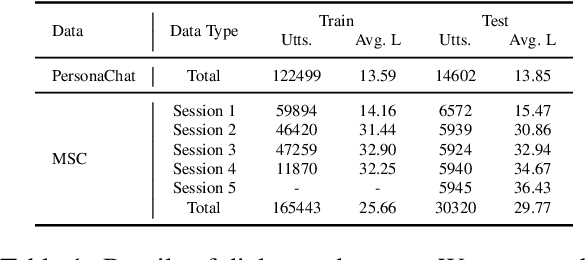
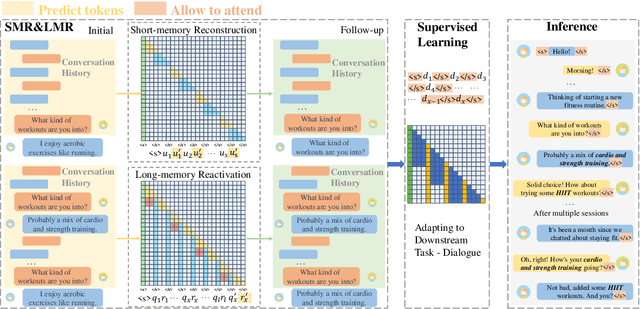
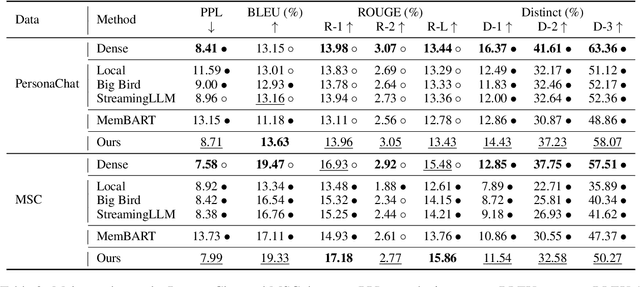
Standard Large Language Models (LLMs) struggle with handling dialogues with long contexts due to efficiency and consistency issues. According to our observation, dialogue contexts are highly structured, and the special token of \textit{End-of-Utterance} (EoU) in dialogues has the potential to aggregate information. We refer to the EoU tokens as ``conversational attention sinks'' (conv-attn sinks). Accordingly, we introduce StreamingDialogue, which compresses long dialogue history into conv-attn sinks with minimal losses, and thus reduces computational complexity quadratically with the number of sinks (i.e., the number of utterances). Current LLMs already demonstrate the ability to handle long context window, e.g., a window size of 200k or more. To this end, by compressing utterances into EoUs, our method has the potential to handle more than 200k of utterances, resulting in a prolonged dialogue learning. In order to minimize information losses from reconstruction after compression, we design two learning strategies of short-memory reconstruction (SMR) and long-memory reactivation (LMR). Our method outperforms strong baselines in dialogue tasks and achieves a 4 $\times$ speedup while reducing memory usage by 18 $\times$ compared to dense attention recomputation.
ActionDiffusion: An Action-aware Diffusion Model for Procedure Planning in Instructional Videos
Mar 13, 2024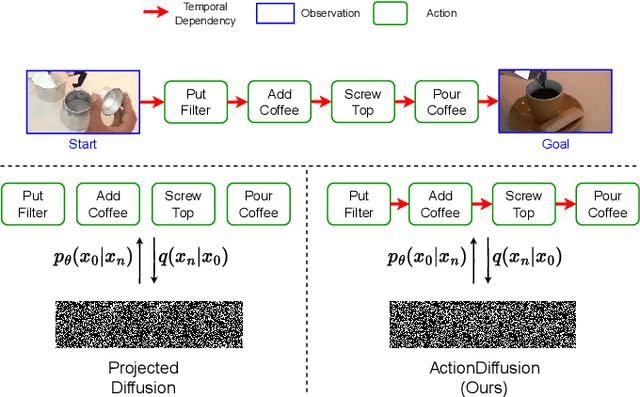
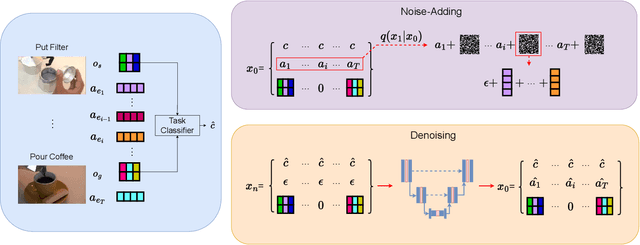
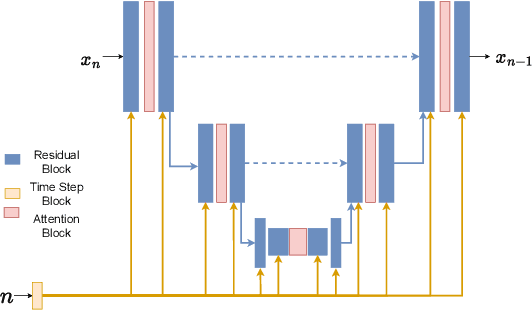
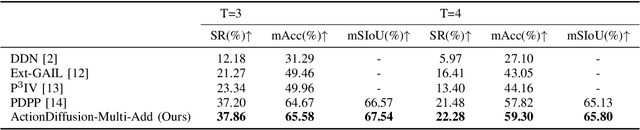
We present ActionDiffusion -- a novel diffusion model for procedure planning in instructional videos that is the first to take temporal inter-dependencies between actions into account in a diffusion model for procedure planning. This approach is in stark contrast to existing methods that fail to exploit the rich information content available in the particular order in which actions are performed. Our method unifies the learning of temporal dependencies between actions and denoising of the action plan in the diffusion process by projecting the action information into the noise space. This is achieved 1) by adding action embeddings in the noise masks in the noise-adding phase and 2) by introducing an attention mechanism in the noise prediction network to learn the correlations between different action steps. We report extensive experiments on three instructional video benchmark datasets (CrossTask, Coin, and NIV) and show that our method outperforms previous state-of-the-art methods on all metrics on CrossTask and NIV and all metrics except accuracy on Coin dataset. We show that by adding action embeddings into the noise mask the diffusion model can better learn action temporal dependencies and increase the performances on procedure planning.
MedInsight: A Multi-Source Context Augmentation Framework for Generating Patient-Centric Medical Responses using Large Language Models
Mar 13, 2024
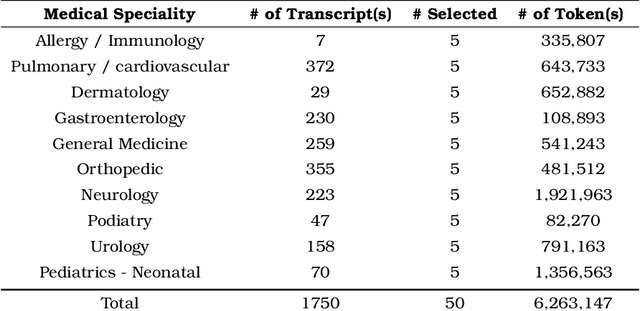
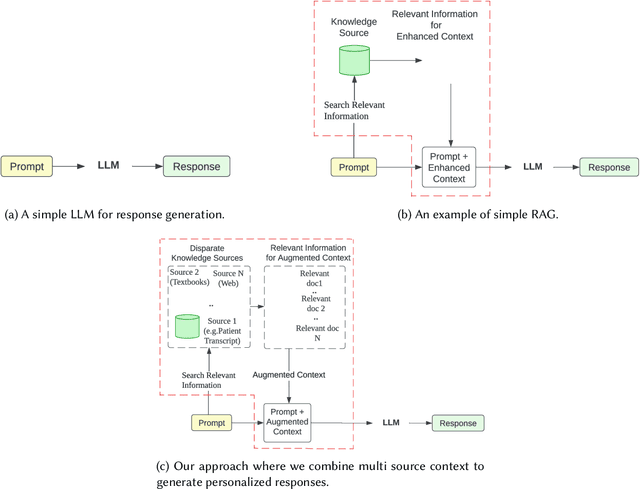
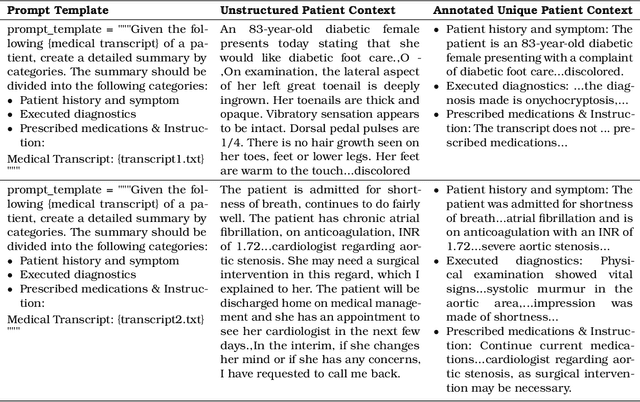
Large Language Models (LLMs) have shown impressive capabilities in generating human-like responses. However, their lack of domain-specific knowledge limits their applicability in healthcare settings, where contextual and comprehensive responses are vital. To address this challenge and enable the generation of patient-centric responses that are contextually relevant and comprehensive, we propose MedInsight:a novel retrieval augmented framework that augments LLM inputs (prompts) with relevant background information from multiple sources. MedInsight extracts pertinent details from the patient's medical record or consultation transcript. It then integrates information from authoritative medical textbooks and curated web resources based on the patient's health history and condition. By constructing an augmented context combining the patient's record with relevant medical knowledge, MedInsight generates enriched, patient-specific responses tailored for healthcare applications such as diagnosis, treatment recommendations, or patient education. Experiments on the MTSamples dataset validate MedInsight's effectiveness in generating contextually appropriate medical responses. Quantitative evaluation using the Ragas metric and TruLens for answer similarity and answer correctness demonstrates the model's efficacy. Furthermore, human evaluation studies involving Subject Matter Expert (SMEs) confirm MedInsight's utility, with moderate inter-rater agreement on the relevance and correctness of the generated responses.