 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Extracting Structured Seed-Mediated Gold Nanorod Growth Procedures from Literature with GPT-3
Apr 26, 2023
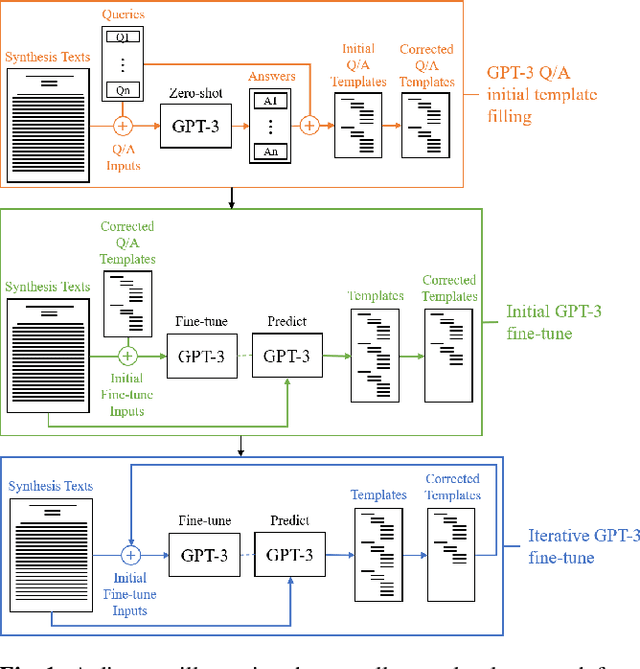
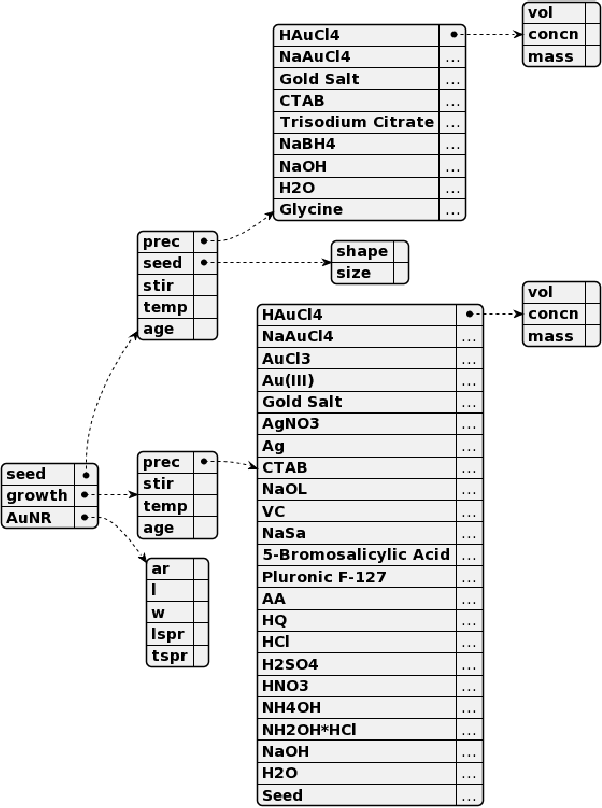
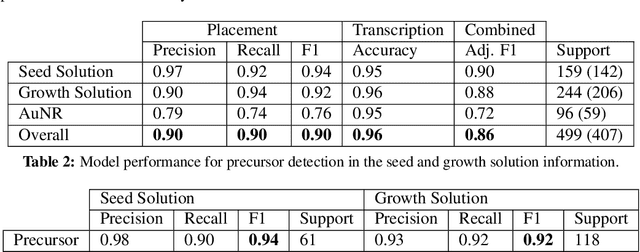

Although gold nanorods have been the subject of much research, the pathways for controlling their shape and thereby their optical properties remain largely heuristically understood. Although it is apparent that the simultaneous presence of and interaction between various reagents during synthesis control these properties, computational and experimental approaches for exploring the synthesis space can be either intractable or too time-consuming in practice. This motivates an alternative approach leveraging the wealth of synthesis information already embedded in the body of scientific literature by developing tools to extract relevant structured data in an automated, high-throughput manner. To that end, we present an approach using the powerful GPT-3 language model to extract structured multi-step seed-mediated growth procedures and outcomes for gold nanorods from unstructured scientific text. GPT-3 prompt completions are fine-tuned to predict synthesis templates in the form of JSON documents from unstructured text input with an overall accuracy of $86\%$. The performance is notable, considering the model is performing simultaneous entity recognition and relation extraction. We present a dataset of 11,644 entities extracted from 1,137 papers, resulting in 268 papers with at least one complete seed-mediated gold nanorod growth procedure and outcome for a total of 332 complete procedures.
REV: Information-Theoretic Evaluation of Free-Text Rationales
Oct 10, 2022

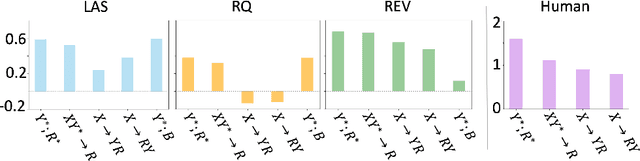
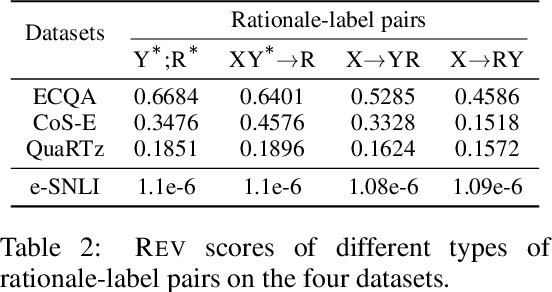
Free-text rationales are a promising step towards explainable AI, yet their evaluation remains an open research problem. While existing metrics have mostly focused on measuring the direct association between the rationale and a given label, we argue that an ideal metric should also be able to focus on the new information uniquely provided in the rationale that is otherwise not provided in the input or the label. We investigate this research problem from an information-theoretic perspective using the conditional V-information. More concretely, we propose a metric called REV (Rationale Evaluation with conditional V-information), that can quantify the new information in a rationale supporting a given label beyond the information already available in the input or the label. Experiments on reasoning tasks across four benchmarks, including few-shot prompting with GPT-3, demonstrate the effectiveness of REV in evaluating different types of rationale-label pairs, compared to existing metrics. Through several quantitative comparisons, we demonstrate the capability of REV in providing more sensitive measurements of new information in free-text rationales with respect to a label. Furthermore, REV is consistent with human judgments on rationale evaluations. Overall, when used alongside traditional performance metrics, REV provides deeper insights into a models' reasoning and prediction processes.
Exploring Multimodal Sentiment Analysis via CBAM Attention and Double-layer BiLSTM Architecture
Mar 26, 2023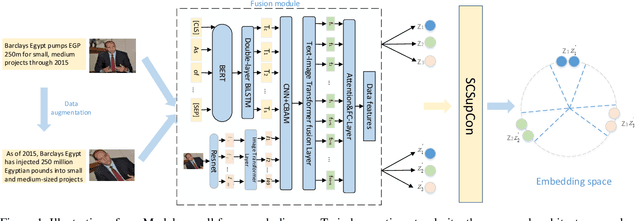
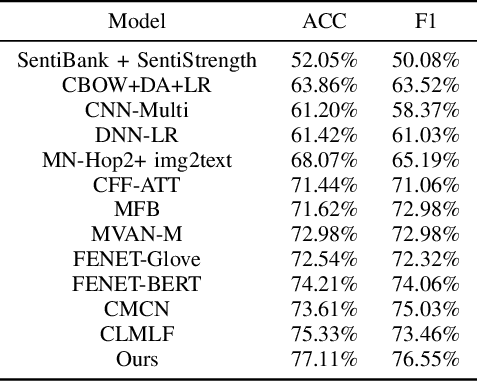
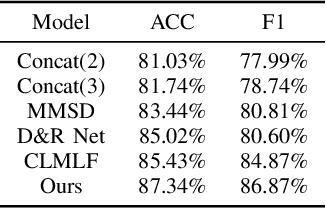
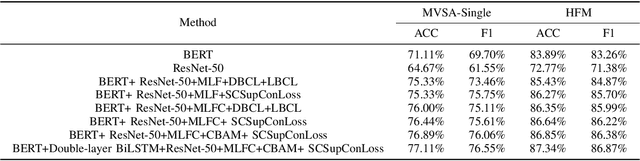
Because multimodal data contains more modal information, multimodal sentiment analysis has become a recent research hotspot. However, redundant information is easily involved in feature fusion after feature extraction, which has a certain impact on the feature representation after fusion. Therefore, in this papaer, we propose a new multimodal sentiment analysis model. In our model, we use BERT + BiLSTM as new feature extractor to capture the long-distance dependencies in sentences and consider the position information of input sequences to obtain richer text features. To remove redundant information and make the network pay more attention to the correlation between image and text features, CNN and CBAM attention are added after splicing text features and picture features, to improve the feature representation ability. On the MVSA-single dataset and HFM dataset, compared with the baseline model, the ACC of our model is improved by 1.78% and 1.91%, and the F1 value is enhanced by 3.09% and 2.0%, respectively. The experimental results show that our model achieves a sound effect, similar to the advanced model.
A Static Analysis of Informed Down-Samples
Apr 17, 2023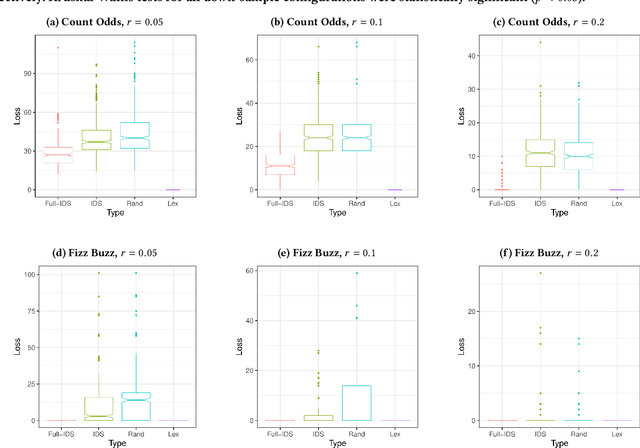
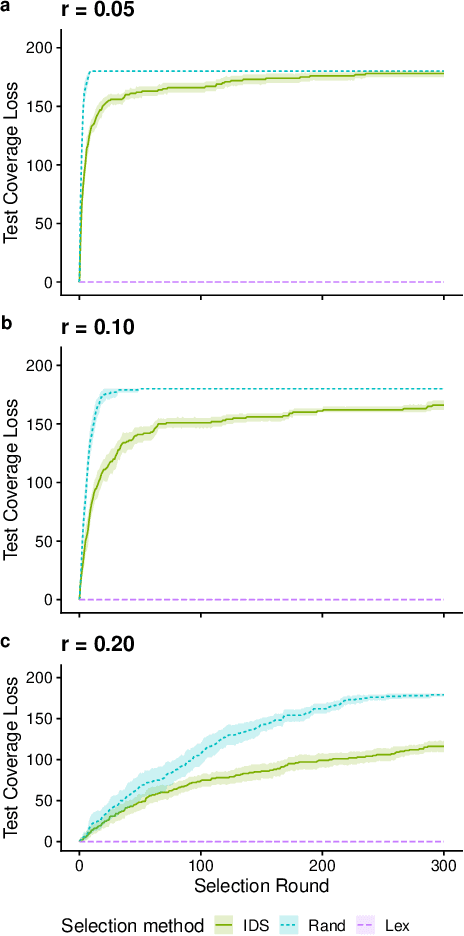
We present an analysis of the loss of population-level test coverage induced by different down-sampling strategies when combined with lexicase selection. We study recorded populations from the first generation of genetic programming runs, as well as entirely synthetic populations. Our findings verify the hypothesis that informed down-sampling better maintains population-level test coverage when compared to random down-sampling. Additionally, we show that both forms of down-sampling cause greater test coverage loss than standard lexicase selection with no down-sampling. However, given more information about the population, we found that informed down-sampling can further reduce its test coverage loss. We also recommend wider adoption of the static population analyses we present in this work.
Enhancing Intra-class Information Extraction for Heterophilous Graphs: One Neural Architecture Search Approach
Nov 20, 2022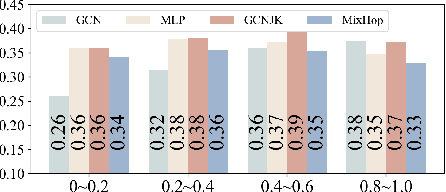
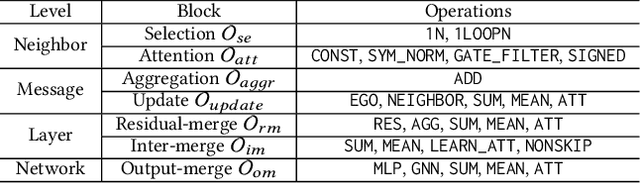
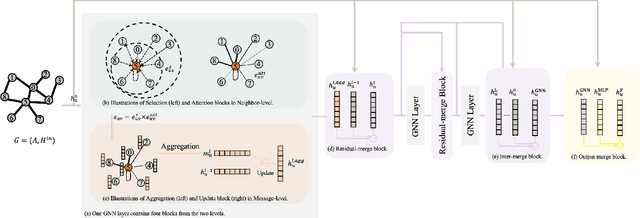
In recent years, Graph Neural Networks (GNNs) have been popular in graph representation learning which assumes the homophily property, i.e., the connected nodes have the same label or have similar features. However, they may fail to generalize into the heterophilous graphs which in the low/medium level of homophily. Existing methods tend to address this problem by enhancing the intra-class information extraction, i.e., either by designing better GNNs to improve the model effectiveness, or re-designing the graph structures to incorporate more potential intra-class nodes from distant hops. Despite the success, we observe two aspects that can be further improved: (a) enhancing the ego feature information extraction from node itself which is more reliable in extracting the intra-class information; (b) designing node-wise GNNs can better adapt to the nodes with different homophily ratios. In this paper, we propose a novel method IIE-GNN (Intra-class Information Enhanced Graph Neural Networks) to achieve two improvements. A unified framework is proposed based on the literature, in which the intra-class information from the node itself and neighbors can be extracted based on seven carefully designed blocks. With the help of neural architecture search (NAS), we propose a novel search space based on the framework, and then provide an architecture predictor to design GNNs for each node. We further conduct experiments to show that IIE-GNN can improve the model performance by designing node-wise GNNs to enhance intra-class information extraction.
Graph Mixture of Experts: Learning on Large-Scale Graphs with Explicit Diversity Modeling
Apr 06, 2023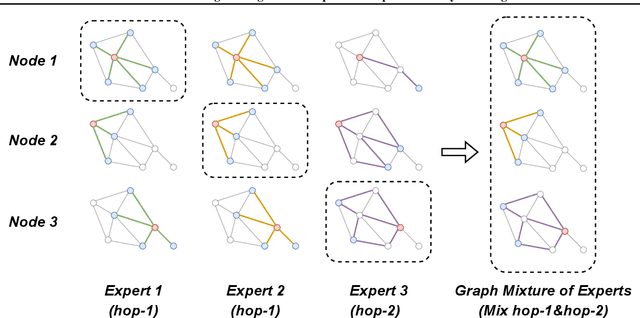

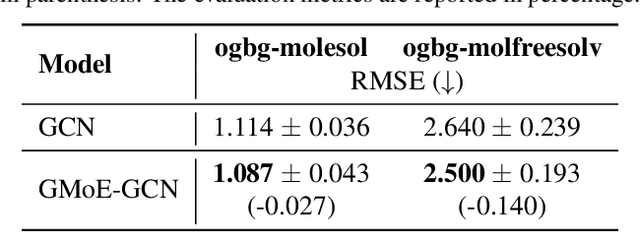
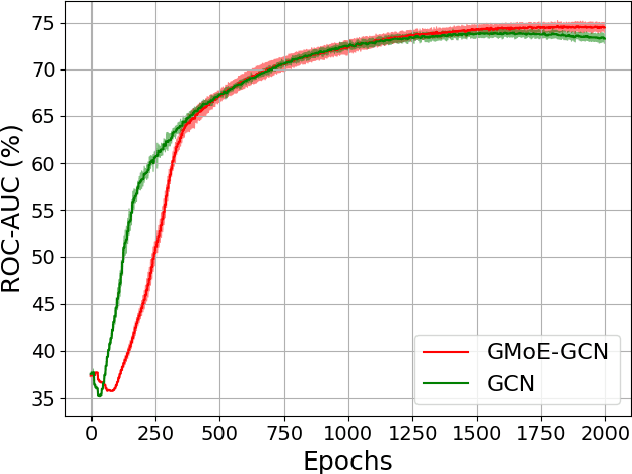
Graph neural networks (GNNs) have been widely applied to learning over graph data. Yet, real-world graphs commonly exhibit diverse graph structures and contain heterogeneous nodes and edges. Moreover, to enhance the generalization ability of GNNs, it has become common practice to further increase the diversity of training graph structures by incorporating graph augmentations and/or performing large-scale pre-training on more graphs. Therefore, it becomes essential for a GNN to simultaneously model diverse graph structures. Yet, naively increasing the GNN model capacity will suffer from both higher inference costs and the notorious trainability issue of GNNs. This paper introduces the Mixture-of-Expert (MoE) idea to GNNs, aiming to enhance their ability to accommodate the diversity of training graph structures, without incurring computational overheads. Our new Graph Mixture of Expert (GMoE) model enables each node in the graph to dynamically select its own optimal \textit{information aggregation experts}. These experts are trained to model different subgroups of graph structures in the training set. Additionally, GMoE includes information aggregation experts with varying aggregation hop sizes, where the experts with larger hop sizes are specialized in capturing information over longer ranges. The effectiveness of GMoE is verified through experimental results on a large variety of graph, node, and link prediction tasks in the OGB benchmark. For instance, it enhances ROC-AUC by $1.81\%$ in ogbg-molhiv and by $1.40\%$ in ogbg-molbbbp, as compared to the non-MoE baselines. Our code is available at https://github.com/VITA-Group/Graph-Mixture-of-Experts.
A Cross-Scale Hierarchical Transformer with Correspondence-Augmented Attention for inferring Bird's-Eye-View Semantic Segmentation
Apr 07, 2023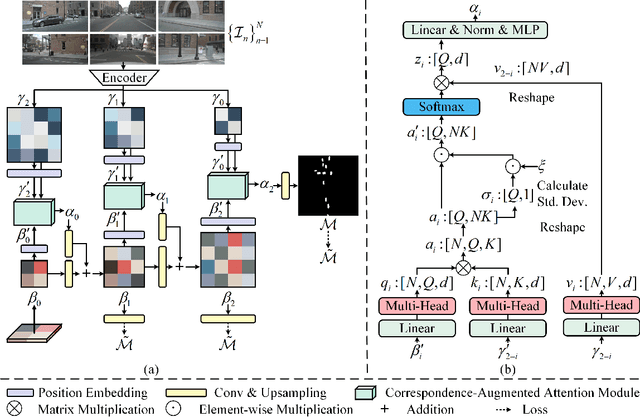
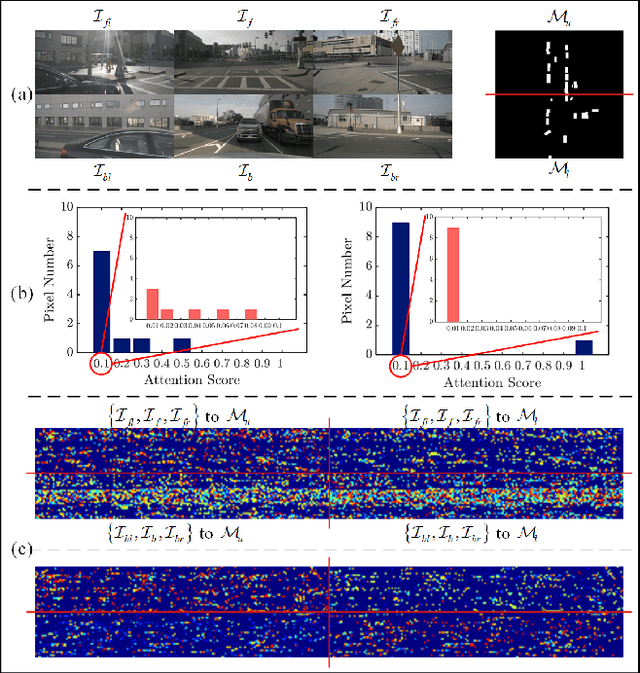

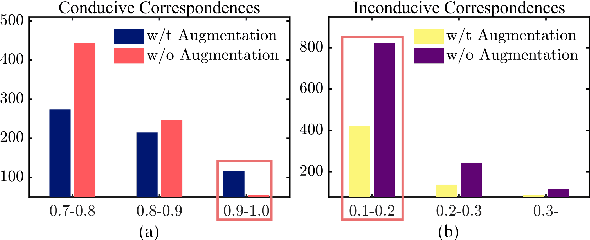
As bird's-eye-view (BEV) semantic segmentation is simple-to-visualize and easy-to-handle, it has been applied in autonomous driving to provide the surrounding information to downstream tasks. Inferring BEV semantic segmentation conditioned on multi-camera-view images is a popular scheme in the community as cheap devices and real-time processing. The recent work implemented this task by learning the content and position relationship via the vision Transformer (ViT). However, the quadratic complexity of ViT confines the relationship learning only in the latent layer, leaving the scale gap to impede the representation of fine-grained objects. And their plain fusion method of multi-view features does not conform to the information absorption intention in representing BEV features. To tackle these issues, we propose a novel cross-scale hierarchical Transformer with correspondence-augmented attention for semantic segmentation inferring. Specifically, we devise a hierarchical framework to refine the BEV feature representation, where the last size is only half of the final segmentation. To save the computation increase caused by this hierarchical framework, we exploit the cross-scale Transformer to learn feature relationships in a reversed-aligning way, and leverage the residual connection of BEV features to facilitate information transmission between scales. We propose correspondence-augmented attention to distinguish conducive and inconducive correspondences. It is implemented in a simple yet effective way, amplifying attention scores before the Softmax operation, so that the position-view-related and the position-view-disrelated attention scores are highlighted and suppressed. Extensive experiments demonstrate that our method has state-of-the-art performance in inferring BEV semantic segmentation conditioned on multi-camera-view images.
Graph Neural Networks for Text Classification: A Survey
Apr 23, 2023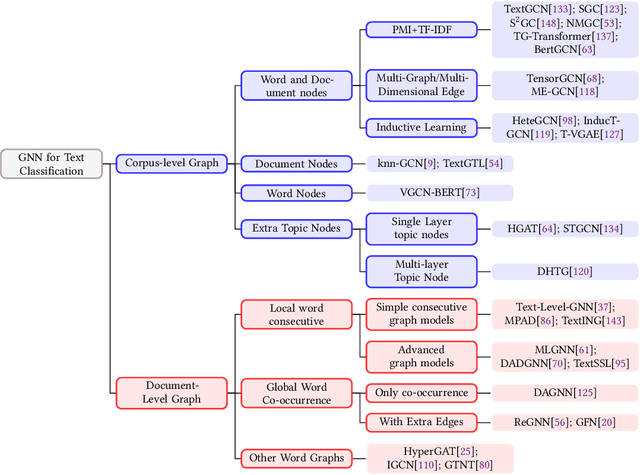
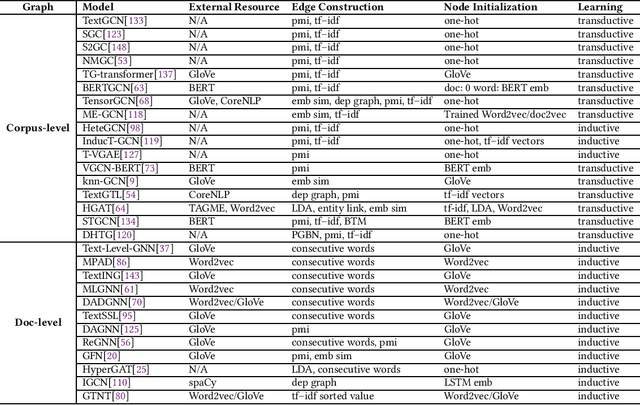
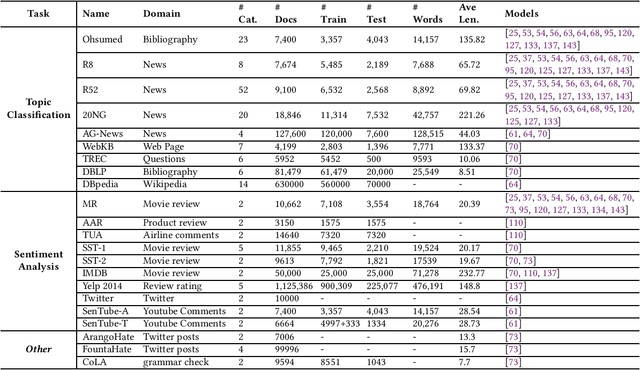
Text Classification is the most essential and fundamental problem in Natural Language Processing. While numerous recent text classification models applied the sequential deep learning technique, graph neural network-based models can directly deal with complex structured text data and exploit global information. Many real text classification applications can be naturally cast into a graph, which captures words, documents, and corpus global features. In this survey, we bring the coverage of methods up to 2023, including corpus-level and document-level graph neural networks. We discuss each of these methods in detail, dealing with the graph construction mechanisms and the graph-based learning process. As well as the technological survey, we look at issues behind and future directions addressed in text classification using graph neural networks. We also cover datasets, evaluation metrics, and experiment design and present a summary of published performance on the publicly available benchmarks. Note that we present a comprehensive comparison between different techniques and identify the pros and cons of various evaluation metrics in this survey.
Handling Heavy Occlusion in Dense Crowd Tracking by Focusing on the Heads
Apr 27, 2023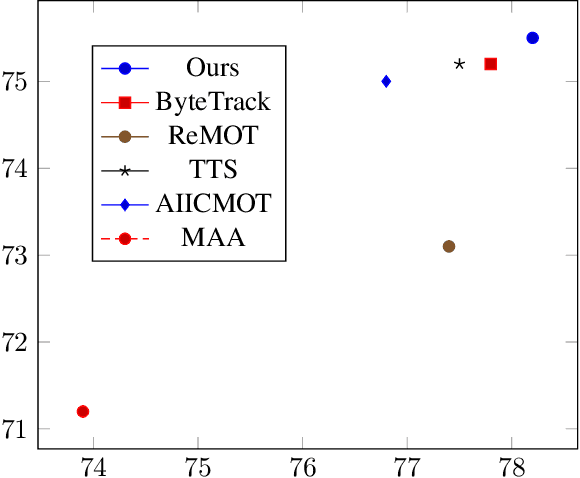

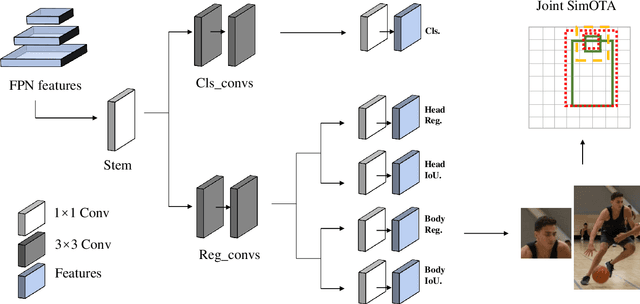
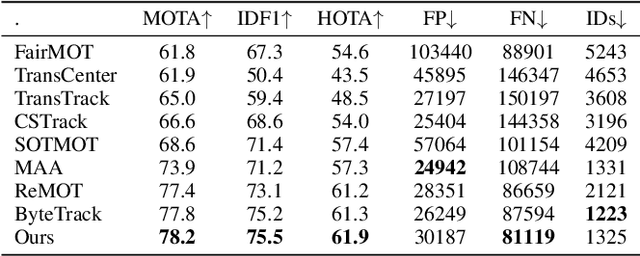
With the rapid development of deep learning, object detection and tracking play a vital role in today's society. Being able to identify and track all the pedestrians in the dense crowd scene with computer vision approaches is a typical challenge in this field, also known as the Multiple Object Tracking (MOT) challenge. Modern trackers are required to operate on more and more complicated scenes. According to the MOT20 challenge result, the pedestrian is 4 times denser than the MOT17 challenge. Hence, improving the ability to detect and track in extremely crowded scenes is the aim of this work. In light of the occlusion issue with the human body, the heads are usually easier to identify. In this work, we have designed a joint head and body detector in an anchor-free style to boost the detection recall and precision performance of pedestrians in both small and medium sizes. Innovatively, our model does not require information on the statistical head-body ratio for common pedestrians detection for training. Instead, the proposed model learns the ratio dynamically. To verify the effectiveness of the proposed model, we evaluate the model with extensive experiments on different datasets, including MOT20, Crowdhuman, and HT21 datasets. As a result, our proposed method significantly improves both the recall and precision rate on small & medium sized pedestrians and achieves state-of-the-art results in these challenging datasets.
SAR2EO: A High-resolution Image Translation Framework with Denoising Enhancement
Apr 08, 2023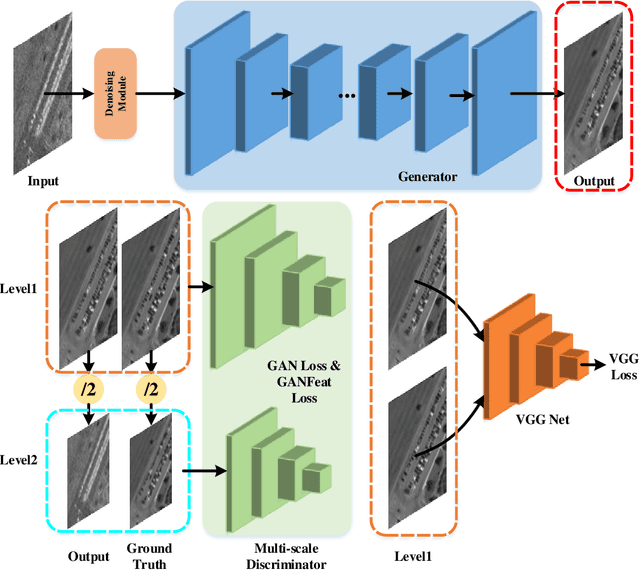
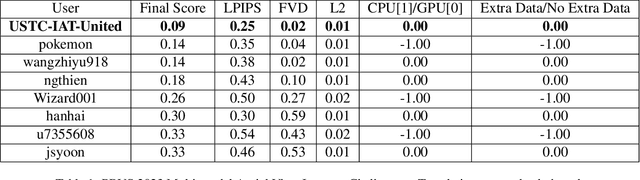


Synthetic Aperture Radar (SAR) to electro-optical (EO) image translation is a fundamental task in remote sensing that can enrich the dataset by fusing information from different sources. Recently, many methods have been proposed to tackle this task, but they are still difficult to complete the conversion from low-resolution images to high-resolution images. Thus, we propose a framework, SAR2EO, aiming at addressing this challenge. Firstly, to generate high-quality EO images, we adopt the coarse-to-fine generator, multi-scale discriminators, and improved adversarial loss in the pix2pixHD model to increase the synthesis quality. Secondly, we introduce a denoising module to remove the noise in SAR images, which helps to suppress the noise while preserving the structural information of the images. To validate the effectiveness of the proposed framework, we conduct experiments on the dataset of the Multi-modal Aerial View Imagery Challenge (MAVIC), which consists of large-scale SAR and EO image pairs. The experimental results demonstrate the superiority of our proposed framework, and we win the first place in the MAVIC held in CVPR PBVS 2023.