 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Actively Discovering New Slots for Task-oriented Conversation
May 06, 2023
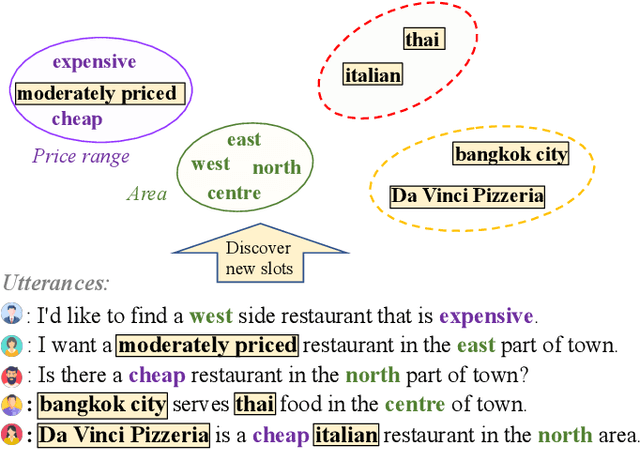
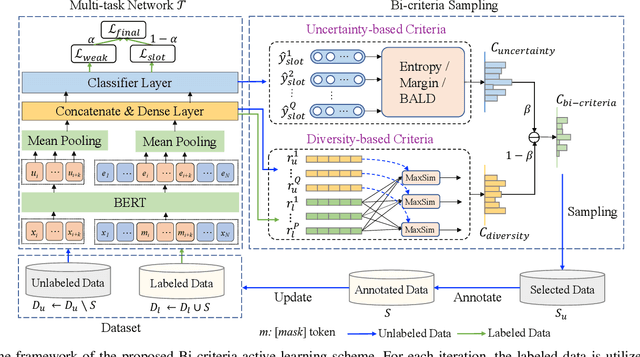
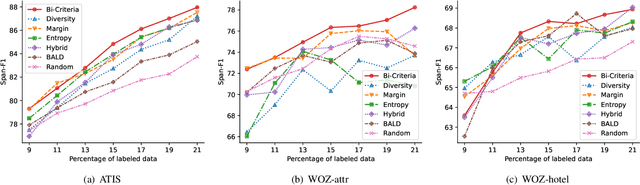
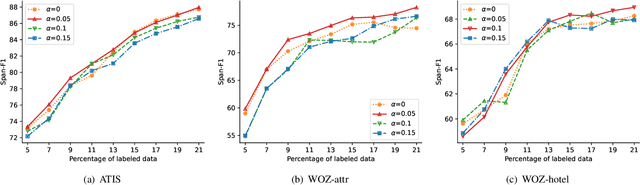
Existing task-oriented conversational search systems heavily rely on domain ontologies with pre-defined slots and candidate value sets. In practical applications, these prerequisites are hard to meet, due to the emerging new user requirements and ever-changing scenarios. To mitigate these issues for better interaction performance, there are efforts working towards detecting out-of-vocabulary values or discovering new slots under unsupervised or semi-supervised learning paradigm. However, overemphasizing on the conversation data patterns alone induces these methods to yield noisy and arbitrary slot results. To facilitate the pragmatic utility, real-world systems tend to provide a stringent amount of human labelling quota, which offers an authoritative way to obtain accurate and meaningful slot assignments. Nonetheless, it also brings forward the high requirement of utilizing such quota efficiently. Hence, we formulate a general new slot discovery task in an information extraction fashion and incorporate it into an active learning framework to realize human-in-the-loop learning. Specifically, we leverage existing language tools to extract value candidates where the corresponding labels are further leveraged as weak supervision signals. Based on these, we propose a bi-criteria selection scheme which incorporates two major strategies, namely, uncertainty-based sampling and diversity-based sampling to efficiently identify terms of interest. We conduct extensive experiments on several public datasets and compare with a bunch of competitive baselines to demonstrate the effectiveness of our method. We have made the code and data used in this paper publicly available.
Learning Action Embeddings for Off-Policy Evaluation
May 06, 2023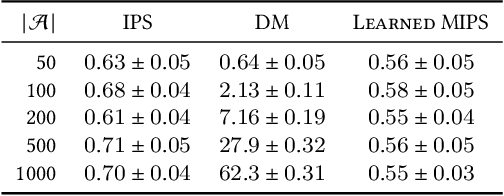
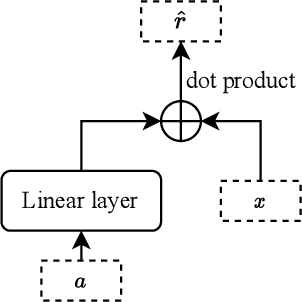
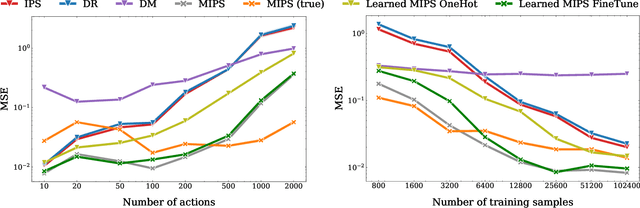
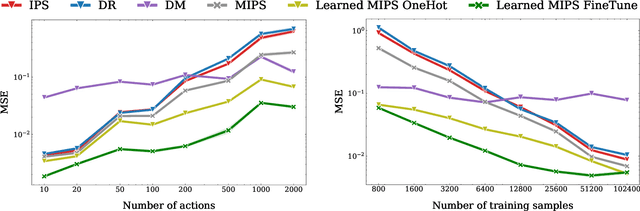
Off-policy evaluation (OPE) methods allow us to compute the expected reward of a policy by using the logged data collected by a different policy. OPE is a viable alternative to running expensive online A/B tests: it can speed up the development of new policies, and reduces the risk of exposing customers to suboptimal treatments. However, when the number of actions is large, or certain actions are under-explored by the logging policy, existing estimators based on inverse-propensity scoring (IPS) can have a high or even infinite variance. Saito and Joachims (arXiv:2202.06317v2 [cs.LG]) propose marginalized IPS (MIPS) that uses action embeddings instead, which reduces the variance of IPS in large action spaces. MIPS assumes that good action embeddings can be defined by the practitioner, which is difficult to do in many real-world applications. In this work, we explore learning action embeddings from logged data. In particular, we use intermediate outputs of a trained reward model to define action embeddings for MIPS. This approach extends MIPS to more applications, and in our experiments improves upon MIPS with pre-defined embeddings, as well as standard baselines, both on synthetic and real-world data. Our method does not make assumptions about the reward model class, and supports using additional action information to further improve the estimates. The proposed approach presents an appealing alternative to DR for combining the low variance of DM with the low bias of IPS.
SINCERE: Sequential Interaction Networks representation learning on Co-Evolving RiEmannian manifolds
May 06, 2023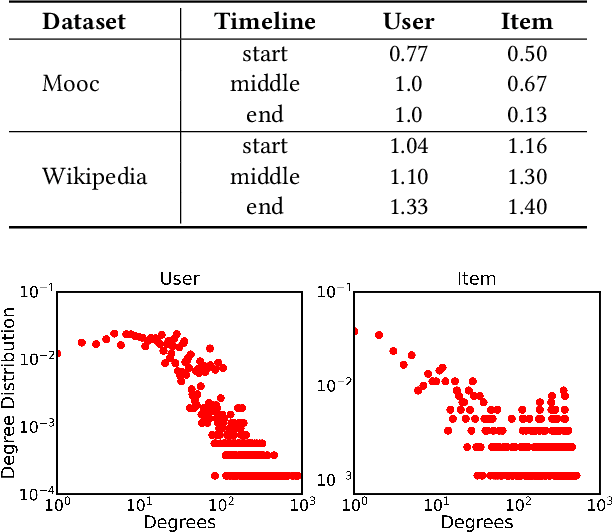
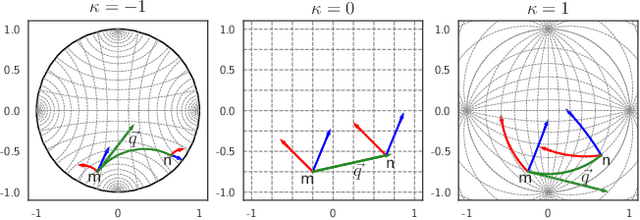
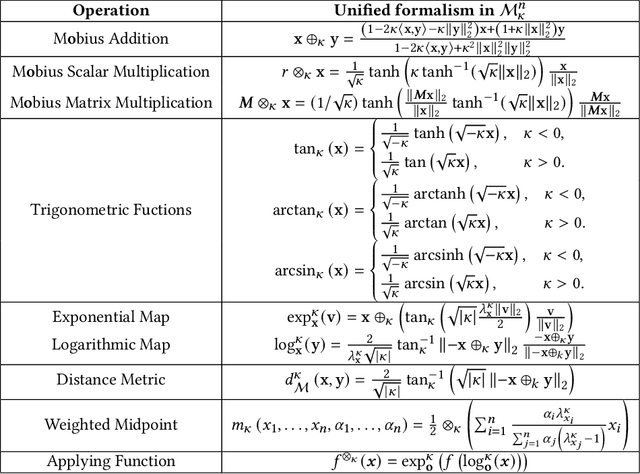
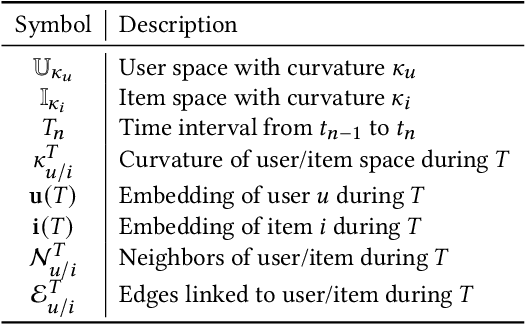
Sequential interaction networks (SIN) have been commonly adopted in many applications such as recommendation systems, search engines and social networks to describe the mutual influence between users and items/products. Efforts on representing SIN are mainly focused on capturing the dynamics of networks in Euclidean space, and recently plenty of work has extended to hyperbolic geometry for implicit hierarchical learning. Previous approaches which learn the embedding trajectories of users and items achieve promising results. However, there are still a range of fundamental issues remaining open. For example, is it appropriate to place user and item nodes in one identical space regardless of their inherent discrepancy? Instead of residing in a single fixed curvature space, how will the representation spaces evolve when new interaction occurs? To explore these issues for sequential interaction networks, we propose SINCERE, a novel method representing Sequential Interaction Networks on Co-Evolving RiEmannian manifolds. SIN- CERE not only takes the user and item embedding trajectories in respective spaces into account, but also emphasizes on the space evolvement that how curvature changes over time. Specifically, we introduce a fresh cross-geometry aggregation which allows us to propagate information across different Riemannian manifolds without breaking conformal invariance, and a curvature estimator which is delicately designed to predict global curvatures effectively according to current local Ricci curvatures. Extensive experiments on several real-world datasets demonstrate the promising performance of SINCERE over the state-of-the-art sequential interaction prediction methods.
How to select an objective function using information theory
Dec 10, 2022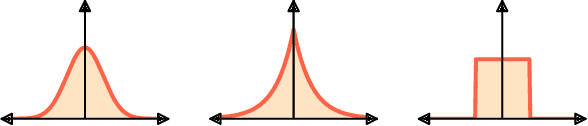
Science tests competing theories or models by evaluating the similarity of their predictions against observational experience. Thus, how we measure similarity fundamentally determines what we learn. In machine learning and scientific modeling, similarity metrics are used as objective functions. A classic example being mean squared error, which is the optimal measure of similarity when errors are normally distributed and independent and identically distributed (iid). In many cases, however, the error distribution is neither normal nor iid, so it is left to the scientist to determine an appropriate objective. Here, we review how information theory can guide that selection, then demonstrate the approach with a simple hydrologic model.
Outage and DMT Analysis of Partition-based Schemes for RIS-aided MIMO Fading Channels
May 07, 2023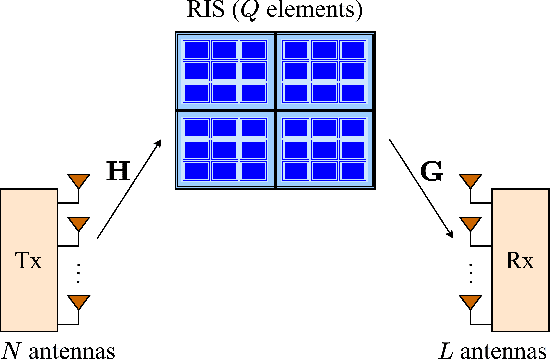
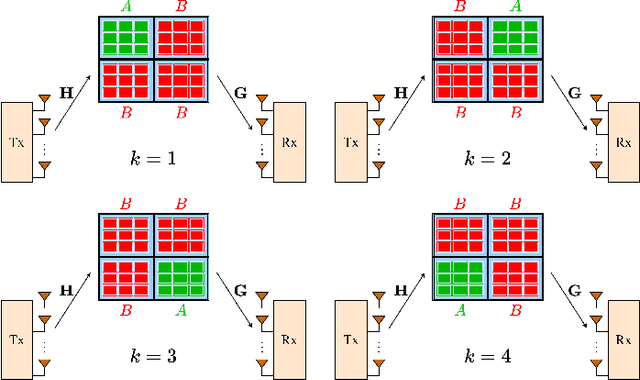
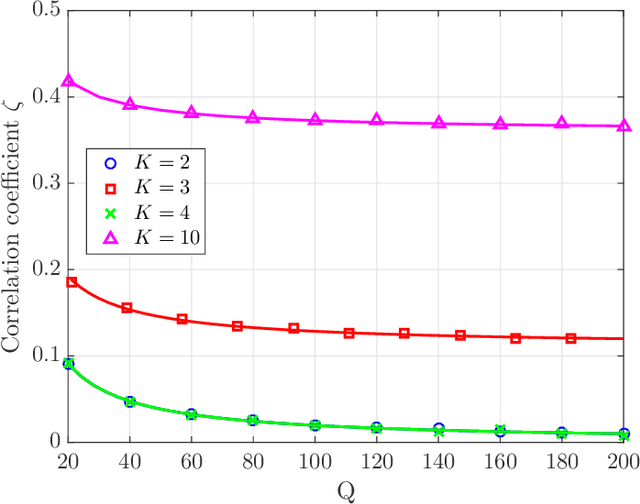
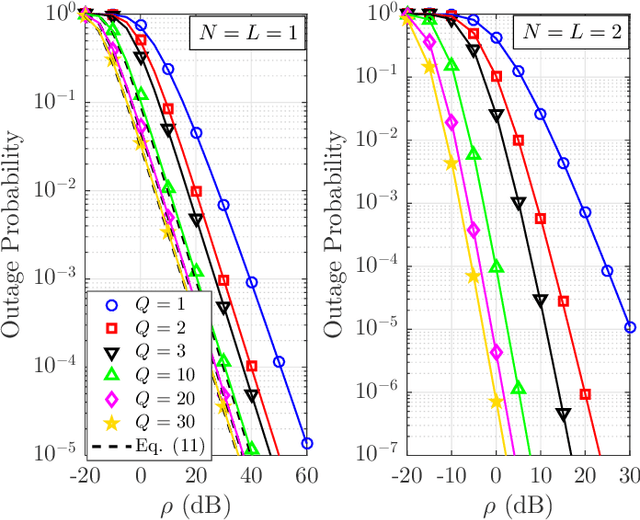
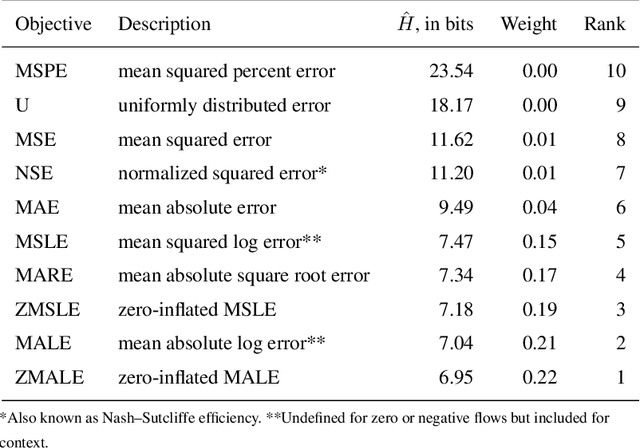
In this paper, we investigate the performance of multiple-input multiple-output (MIMO) fading channels assisted by a reconfigurable intelligent surface (RIS), through the employment of partition-based RIS schemes. The proposed schemes are implemented without requiring any channel state information knowledge at the transmitter side; this characteristic makes them attractive for practical applications. In particular, the RIS elements are partitioned into sub-surfaces, which are periodically modified in an efficient way to assist the communication. Under this framework, we propose two low-complexity partition-based schemes, where each sub-surface is adjusted by following an amplitude-based or a phase-based approach. Specifically, the activate-reflect (AR) scheme activates each sub-surface consecutively, by changing the reflection amplitude of the corresponding elements. On the other hand, the flip-reflect (FR) scheme adjusts periodically the phase shift of the elements at each sub-surface. Through the sequential reconfiguration of each sub-surface, an equivalent parallel channel in the time domain is produced. We analyze the performance of each scheme in terms of outage probability and provide expressions for the achieved diversity-multiplexing tradeoff. Our results show that the asymptotic performance of the considered network under the partition-based schemes can be significantly enhanced in terms of diversity gain compared to the conventional case, where a single partition is considered. Moreover, the FR scheme always achieves the maximum multiplexing gain, while for the AR scheme this maximum gain can be achieved only under certain conditions with respect to the number of elements in each sub-surface.
* 13 pages, 9 figures
Recognizing Entity Types via Properties
Apr 16, 2023The mainstream approach to the development of ontologies is merging ontologies encoding different information, where one of the major difficulties is that the heterogeneity motivates the ontology merging but also limits high-quality merging performance. Thus, the entity type (etype) recognition task is proposed to deal with such heterogeneity, aiming to infer the class of entities and etypes by exploiting the information encoded in ontologies. In this paper, we introduce a property-based approach that allows recognizing etypes on the basis of the properties used to define them. From an epistemological point of view, it is in fact properties that characterize entities and etypes, and this definition is independent of the specific labels and hierarchical schemas used to define them. The main contribution consists of a set of property-based metrics for measuring the contextual similarity between etypes and entities, and a machine learning-based etype recognition algorithm exploiting the proposed similarity metrics. Compared with the state-of-the-art, the experimental results show the validity of the similarity metrics and the superiority of the proposed etype recognition algorithm.
Inadmissibility of the corrected Akaike information criterion
Nov 17, 2022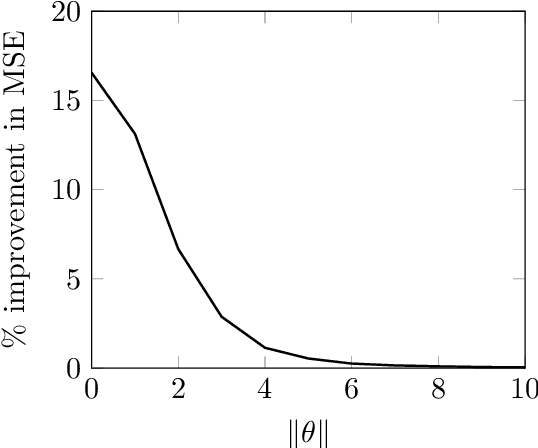
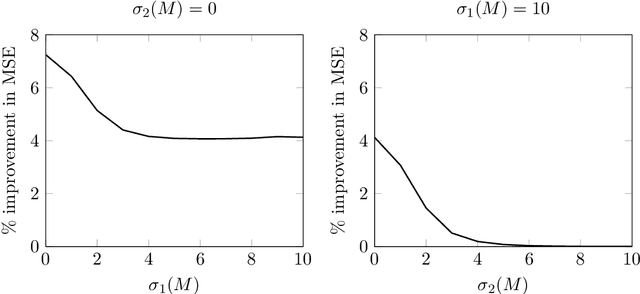
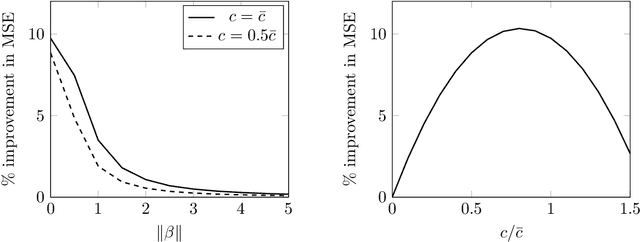
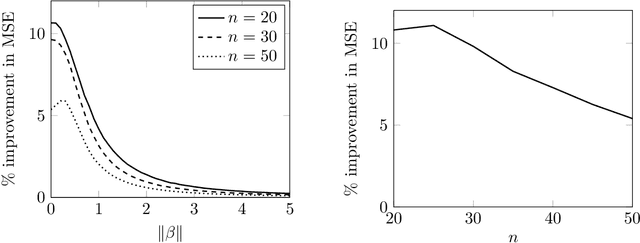
For the multivariate linear regression model with unknown covariance, the corrected Akaike information criterion is the minimum variance unbiased estimator of the expected Kullback--Leibler discrepancy. In this study, based on the loss estimation framework, we show its inadmissibility as an estimator of the Kullback--Leibler discrepancy itself, instead of the expected Kullback--Leibler discrepancy. We provide improved estimators of the Kullback--Leibler discrepancy that work well in reduced-rank situations and examine their performance numerically.
Are demographically invariant models and representations in medical imaging fair?
May 02, 2023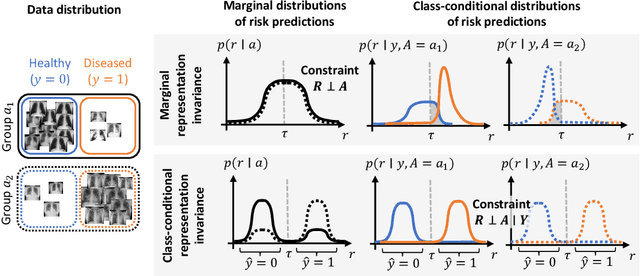
Medical imaging models have been shown to encode information about patient demographics (age, race, sex) in their latent representation, raising concerns about their potential for discrimination. Here, we ask whether it is feasible and desirable to train models that do not encode demographic attributes. We consider different types of invariance with respect to demographic attributes - marginal, class-conditional, and counterfactual model invariance - and lay out their equivalence to standard notions of algorithmic fairness. Drawing on existing theory, we find that marginal and class-conditional invariance can be considered overly restrictive approaches for achieving certain fairness notions, resulting in significant predictive performance losses. Concerning counterfactual model invariance, we note that defining medical image counterfactuals with respect to demographic attributes is fraught with complexities. Finally, we posit that demographic encoding may even be considered advantageous if it enables learning a task-specific encoding of demographic features that does not rely on human-constructed categories such as 'race' and 'gender'. We conclude that medical imaging models may need to encode demographic attributes, lending further urgency to calls for comprehensive model fairness assessments in terms of predictive performance.
Human-machine knowledge hybrid augmentation method for surface defect detection based few-data learning
May 02, 2023
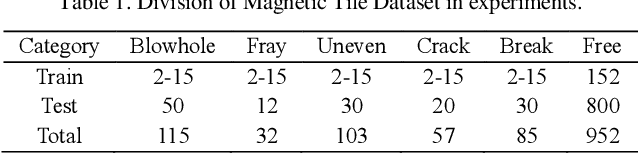
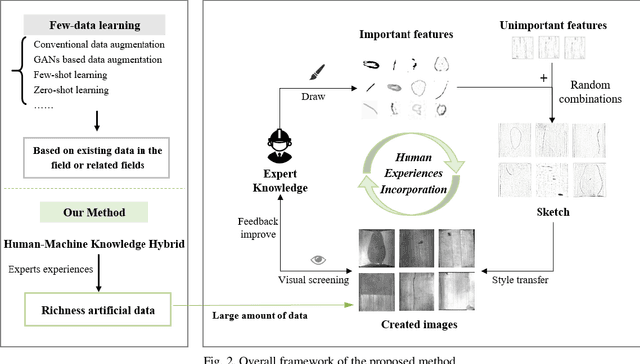

Visual-based defect detection is a crucial but challenging task in industrial quality control. Most mainstream methods rely on large amounts of existing or related domain data as auxiliary information. However, in actual industrial production, there are often multi-batch, low-volume manufacturing scenarios with rapidly changing task demands, making it difficult to obtain sufficient and diverse defect data. This paper proposes a parallel solution that uses a human-machine knowledge hybrid augmentation method to help the model extract unknown important features. Specifically, by incorporating experts' knowledge of abnormality to create data with rich features, positions, sizes, and backgrounds, we can quickly accumulate an amount of data from scratch and provide it to the model as prior knowledge for few-data learning. The proposed method was evaluated on the magnetic tile dataset and achieved F1-scores of 60.73%, 70.82%, 77.09%, and 82.81% when using 2, 5, 10, and 15 training images, respectively. Compared to the traditional augmentation method's F1-score of 64.59%, the proposed method achieved an 18.22% increase in the best result, demonstrating its feasibility and effectiveness in few-data industrial defect detection.
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
May 02, 2023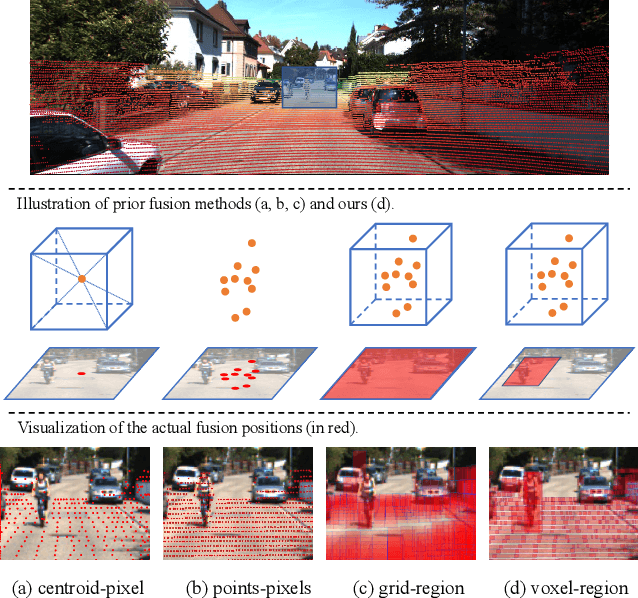
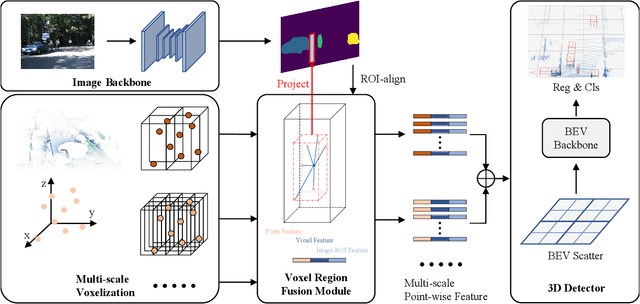
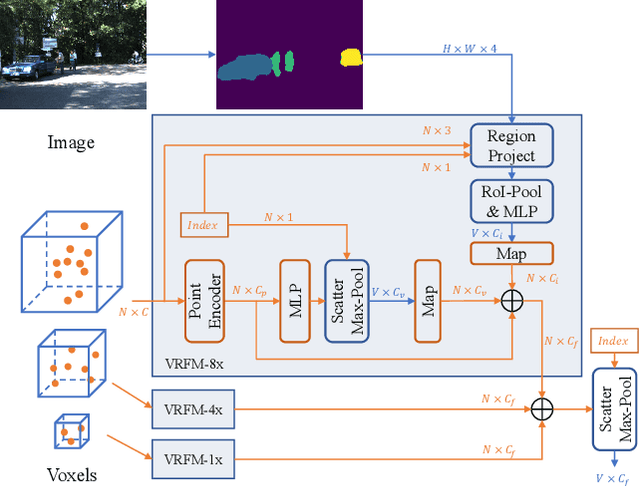

In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.