 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Catch Missing Details: Image Reconstruction with Frequency Augmented Variational Autoencoder
May 04, 2023
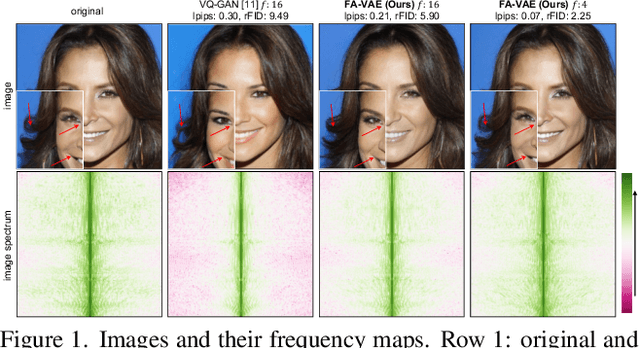
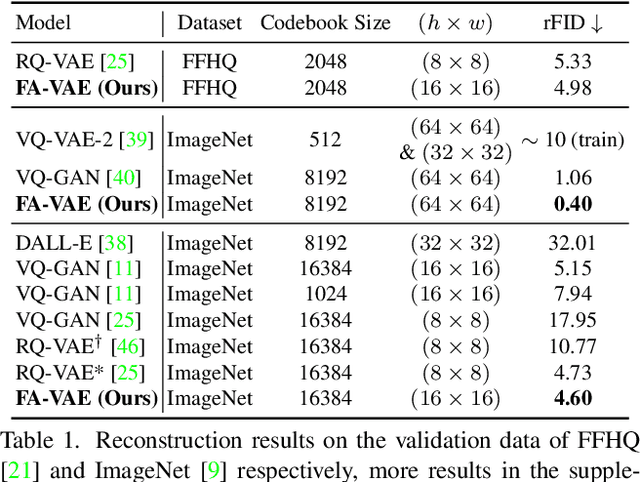
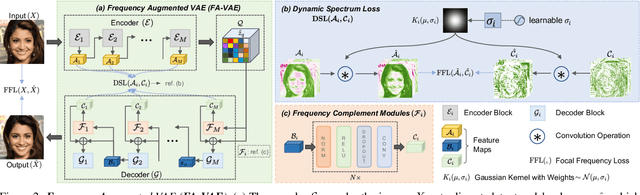
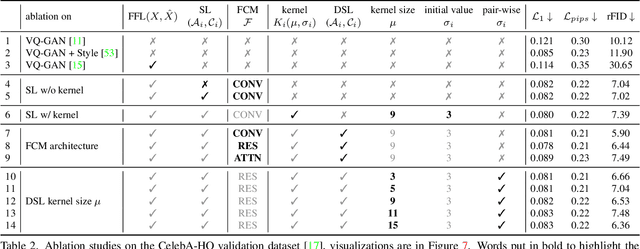
The popular VQ-VAE models reconstruct images through learning a discrete codebook but suffer from a significant issue in the rapid quality degradation of image reconstruction as the compression rate rises. One major reason is that a higher compression rate induces more loss of visual signals on the higher frequency spectrum which reflect the details on pixel space. In this paper, a Frequency Complement Module (FCM) architecture is proposed to capture the missing frequency information for enhancing reconstruction quality. The FCM can be easily incorporated into the VQ-VAE structure, and we refer to the new model as Frequency Augmented VAE (FA-VAE). In addition, a Dynamic Spectrum Loss (DSL) is introduced to guide the FCMs to balance between various frequencies dynamically for optimal reconstruction. FA-VAE is further extended to the text-to-image synthesis task, and a Cross-attention Autoregressive Transformer (CAT) is proposed to obtain more precise semantic attributes in texts. Extensive reconstruction experiments with different compression rates are conducted on several benchmark datasets, and the results demonstrate that the proposed FA-VAE is able to restore more faithfully the details compared to SOTA methods. CAT also shows improved generation quality with better image-text semantic alignment.
Multimodal-driven Talking Face Generation, Face Swapping, Diffusion Model
May 04, 2023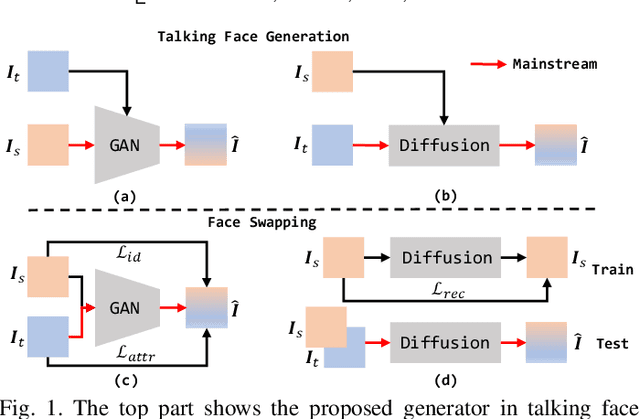
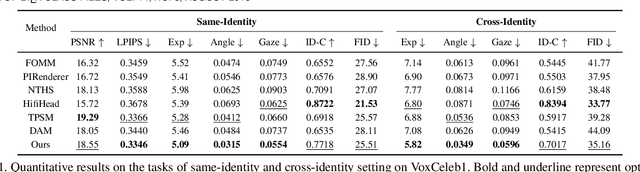
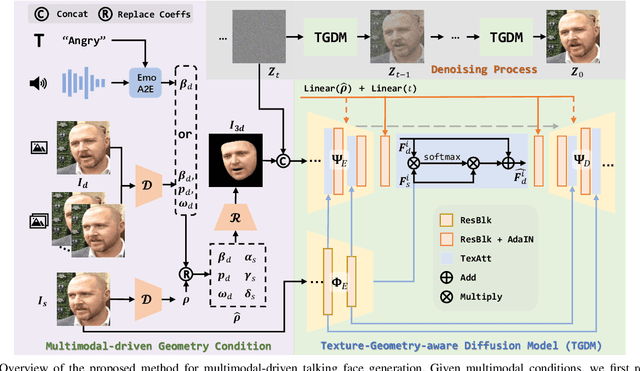
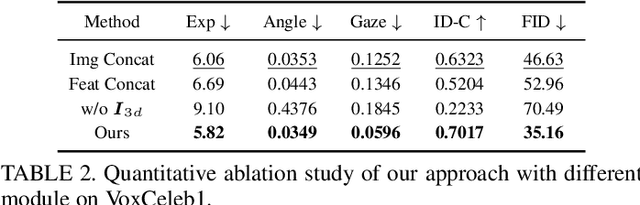
Multimodal-driven talking face generation refers to animating a portrait with the given pose, expression, and gaze transferred from the driving image and video, or estimated from the text and audio. However, existing methods ignore the potential of text modal, and their generators mainly follow the source-oriented feature rearrange paradigm coupled with unstable GAN frameworks. In this work, we first represent the emotion in the text prompt, which could inherit rich semantics from the CLIP, allowing flexible and generalized emotion control. We further reorganize these tasks as the target-oriented texture transfer and adopt the Diffusion Models. More specifically, given a textured face as the source and the rendered face projected from the desired 3DMM coefficients as the target, our proposed Texture-Geometry-aware Diffusion Model decomposes the complex transfer problem into multi-conditional denoising process, where a Texture Attention-based module accurately models the correspondences between appearance and geometry cues contained in source and target conditions, and incorporate extra implicit information for high-fidelity talking face generation. Additionally, TGDM can be gracefully tailored for face swapping. We derive a novel paradigm free of unstable seesaw-style optimization, resulting in simple, stable, and effective training and inference schemes. Extensive experiments demonstrate the superiority of our method.
PI-FL: Personalized and Incentivized Federated Learning
Apr 27, 2023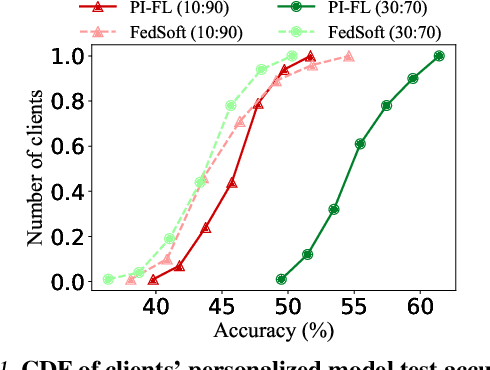
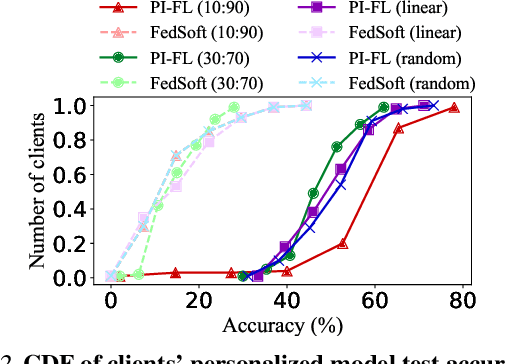
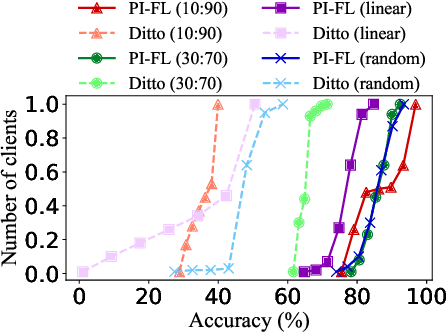
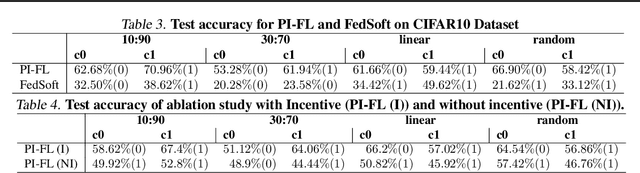
Personalized FL has been widely used to cater to heterogeneity challenges with non-IID data. A primary obstacle is considering the personalization process from the client's perspective to preserve their autonomy. Allowing the clients to participate in personalized FL decisions becomes significant due to privacy and security concerns, where the clients may not be at liberty to share private information necessary for producing good quality personalized models. Moreover, clients with high-quality data and resources are reluctant to participate in the FL process without reasonable incentive. In this paper, we propose PI-FL, a one-shot personalization solution complemented by a token-based incentive mechanism that rewards personalized training. PI-FL outperforms other state-of-the-art approaches and can generate good-quality personalized models while respecting clients' privacy.
An Equivariant Generative Framework for Molecular Graph-Structure Co-Design
Apr 12, 2023Designing molecules with desirable physiochemical properties and functionalities is a long-standing challenge in chemistry, material science, and drug discovery. Recently, machine learning-based generative models have emerged as promising approaches for \emph{de novo} molecule design. However, further refinement of methodology is highly desired as most existing methods lack unified modeling of 2D topology and 3D geometry information and fail to effectively learn the structure-property relationship for molecule design. Here we present MolCode, a roto-translation equivariant generative framework for \underline{Mol}ecular graph-structure \underline{Co-de}sign. In MolCode, 3D geometric information empowers the molecular 2D graph generation, which in turn helps guide the prediction of molecular 3D structure. Extensive experimental results show that MolCode outperforms previous methods on a series of challenging tasks including \emph{de novo} molecule design, targeted molecule discovery, and structure-based drug design. Particularly, MolCode not only consistently generates valid (99.95$\%$ Validity) and diverse (98.75$\%$ Uniqueness) molecular graphs/structures with desirable properties, but also generate drug-like molecules with high affinity to target proteins (61.8$\%$ high-affinity ratio), which demonstrates MolCode's potential applications in material design and drug discovery. Our extensive investigation reveals that the 2D topology and 3D geometry contain intrinsically complementary information in molecule design, and provide new insights into machine learning-based molecule representation and generation.
USTEP: Structuration des logs en flux gr{â}ce {à} un arbre de recherche {é}volutif
Apr 24, 2023Logs record valuable system information at runtime. They are widely used by data-driven approaches for development and monitoring purposes. Parsing log messages to structure their format is a classic preliminary step for log-mining tasks. As they appear upstream, parsing operations can become a processing time bottleneck for downstream applications. The quality of parsing also has a direct influence on their efficiency. Here, we propose USTEP, an online log parsing method based on an evolving tree structure. Evaluation results on a wide panel of datasets coming from different real-world systems demonstrate USTEP superiority in terms of both effectiveness and robustness when compared to other online methods.
How to select an objective function using information theory
Dec 10, 2022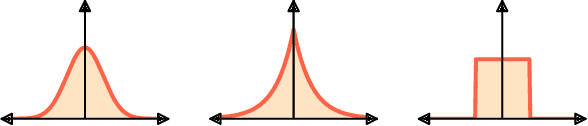
Science tests competing theories or models by evaluating the similarity of their predictions against observational experience. Thus, how we measure similarity fundamentally determines what we learn. In machine learning and scientific modeling, similarity metrics are used as objective functions. A classic example being mean squared error, which is the optimal measure of similarity when errors are normally distributed and independent and identically distributed (iid). In many cases, however, the error distribution is neither normal nor iid, so it is left to the scientist to determine an appropriate objective. Here, we review how information theory can guide that selection, then demonstrate the approach with a simple hydrologic model.
Multimodal Grounding for Embodied AI via Augmented Reality Headsets for Natural Language Driven Task Planning
Apr 26, 2023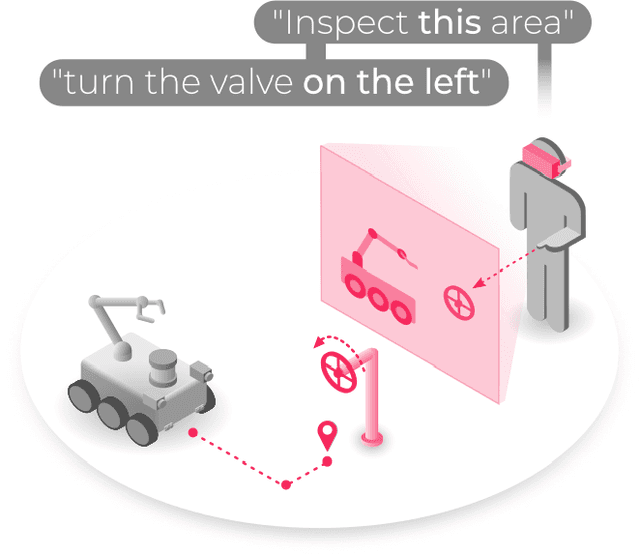


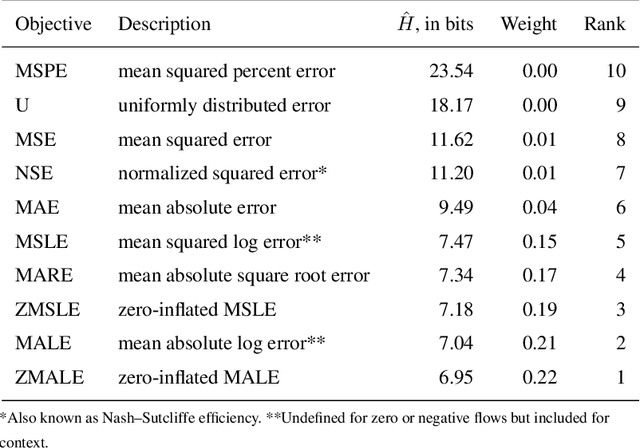
Recent advances in generative modeling have spurred a resurgence in the field of Embodied Artificial Intelligence (EAI). EAI systems typically deploy large language models to physical systems capable of interacting with their environment. In our exploration of EAI for industrial domains, we successfully demonstrate the feasibility of co-located, human-robot teaming. Specifically, we construct an experiment where an Augmented Reality (AR) headset mediates information exchange between an EAI agent and human operator for a variety of inspection tasks. To our knowledge the use of an AR headset for multimodal grounding and the application of EAI to industrial tasks are novel contributions within Embodied AI research. In addition, we highlight potential pitfalls in EAI's construction by providing quantitative and qualitative analysis on prompt robustness.
HiQ -- A Declarative, Non-intrusive, Dynamic and Transparent Observability and Optimization System
Apr 26, 2023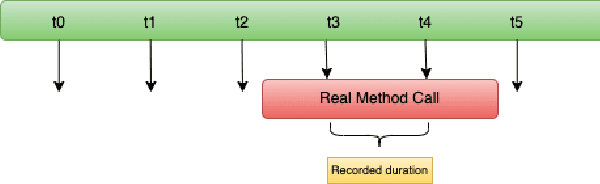
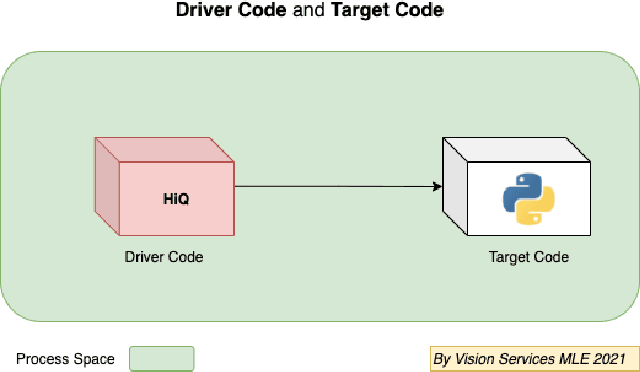
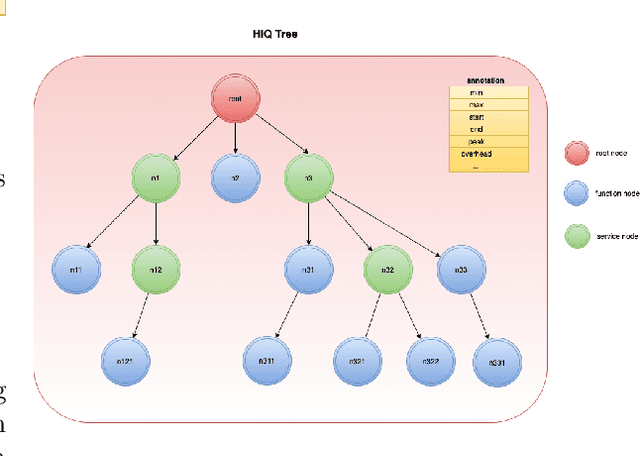
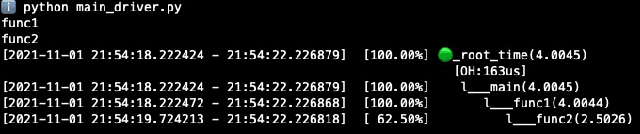
This paper proposes a non-intrusive, declarative, dynamic and transparent system called `HiQ` to track Python program runtime information without compromising on the run-time system performance and losing insight. HiQ can be used for monolithic and distributed systems, offline and online applications. HiQ is developed when we optimize our large deep neural network (DNN) models which are written in Python, but it can be generalized to any Python program or distributed system, or even other languages like Java. We have implemented the system and adopted it in our deep learning model life cycle management system to catch the bottleneck while keeping our production code clean and highly performant. The implementation is open-sourced at: [https://github.com/oracle/hiq](https://github.com/oracle/hiq).
Controlling Posterior Collapse by an Inverse Lipschitz Constraint on the Decoder Network
Apr 25, 2023
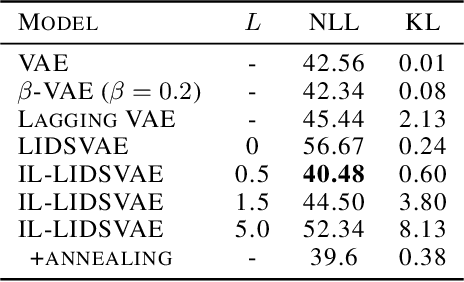
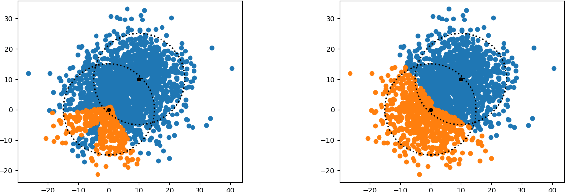
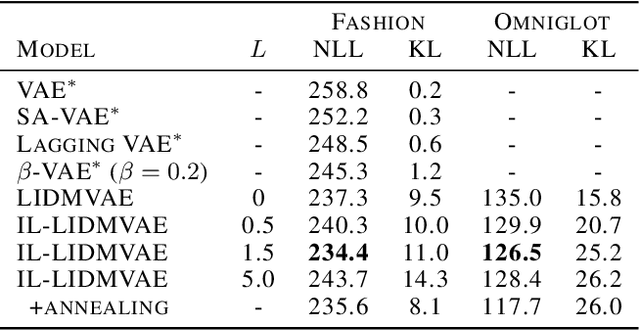
Variational autoencoders (VAEs) are one of the deep generative models that have experienced enormous success over the past decades. However, in practice, they suffer from a problem called posterior collapse, which occurs when the encoder coincides, or collapses, with the prior taking no information from the latent structure of the input data into consideration. In this work, we introduce an inverse Lipschitz neural network into the decoder and, based on this architecture, provide a new method that can control in a simple and clear manner the degree of posterior collapse for a wide range of VAE models equipped with a concrete theoretical guarantee. We also illustrate the effectiveness of our method through several numerical experiments.
Beyond Appearance: a Semantic Controllable Self-Supervised Learning Framework for Human-Centric Visual Tasks
Mar 30, 2023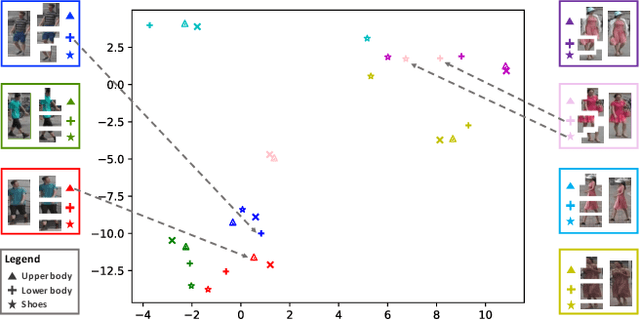
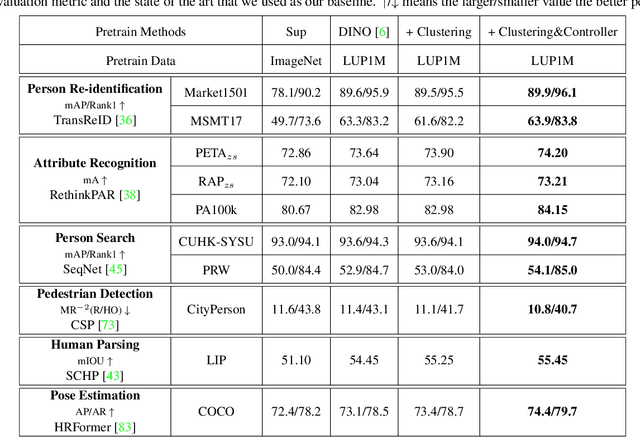
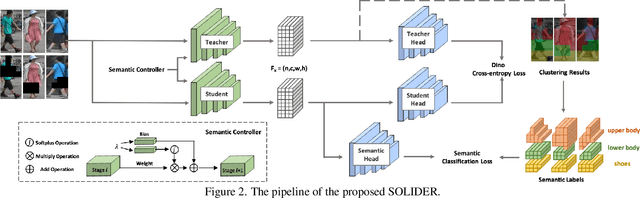
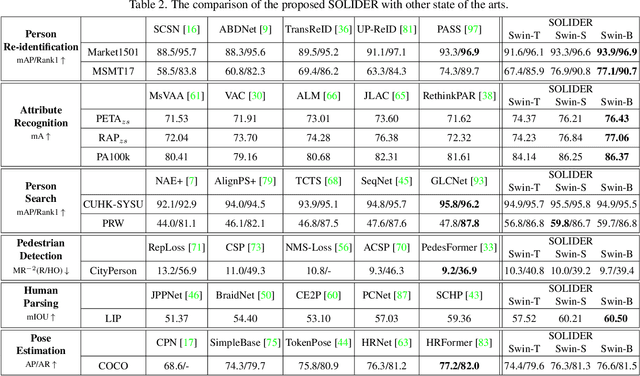
Human-centric visual tasks have attracted increasing research attention due to their widespread applications. In this paper, we aim to learn a general human representation from massive unlabeled human images which can benefit downstream human-centric tasks to the maximum extent. We call this method SOLIDER, a Semantic cOntrollable seLf-supervIseD lEaRning framework. Unlike the existing self-supervised learning methods, prior knowledge from human images is utilized in SOLIDER to build pseudo semantic labels and import more semantic information into the learned representation. Meanwhile, we note that different downstream tasks always require different ratios of semantic information and appearance information. For example, human parsing requires more semantic information, while person re-identification needs more appearance information for identification purpose. So a single learned representation cannot fit for all requirements. To solve this problem, SOLIDER introduces a conditional network with a semantic controller. After the model is trained, users can send values to the controller to produce representations with different ratios of semantic information, which can fit different needs of downstream tasks. Finally, SOLIDER is verified on six downstream human-centric visual tasks. It outperforms state of the arts and builds new baselines for these tasks. The code is released in https://github.com/tinyvision/SOLIDER.