 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Interpretability for Conditional Coordinated Behavior in Multi-Agent Reinforcement Learning
Apr 20, 2023
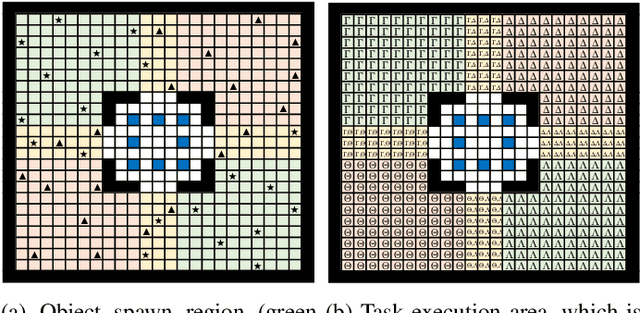
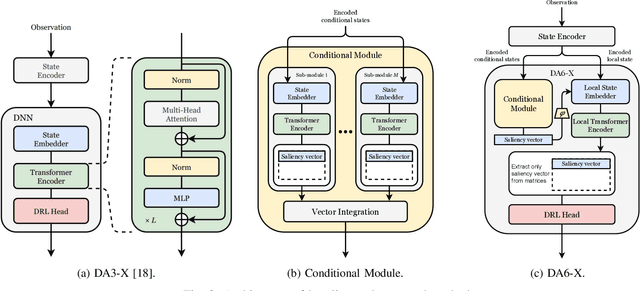
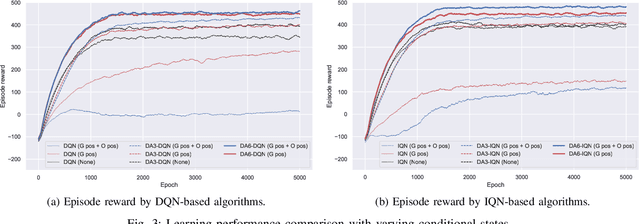
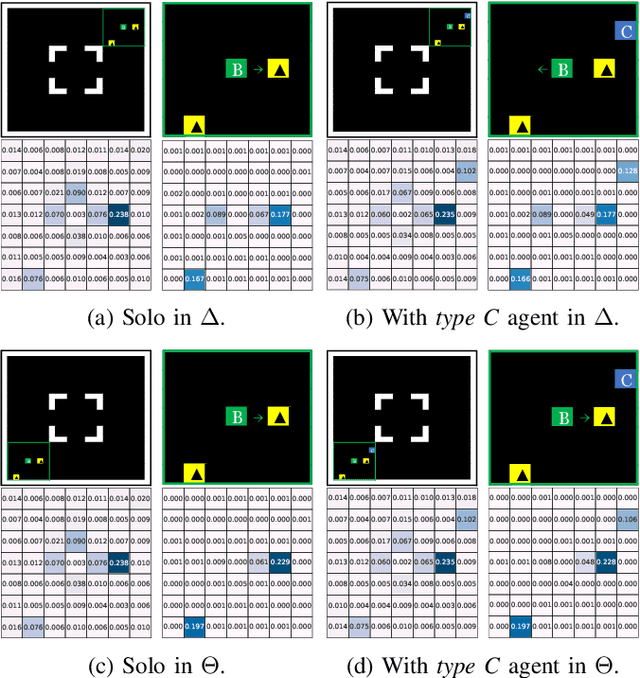
We propose a model-free reinforcement learning architecture, called distributed attentional actor architecture after conditional attention (DA6-X), to provide better interpretability of conditional coordinated behaviors. The underlying principle involves reusing the saliency vector, which represents the conditional states of the environment, such as the global position of agents. Hence, agents with DA6-X flexibility built into their policy exhibit superior performance by considering the additional information in the conditional states during the decision-making process. The effectiveness of the proposed method was experimentally evaluated by comparing it with conventional methods in an objects collection game. By visualizing the attention weights from DA6-X, we confirmed that agents successfully learn situation-dependent coordinated behaviors by correctly identifying various conditional states, leading to improved interpretability of agents along with superior performance.
Bridging Natural Language Processing and Psycholinguistics: computationally grounded semantic similarity datasets for Basque and Spanish
Apr 20, 2023

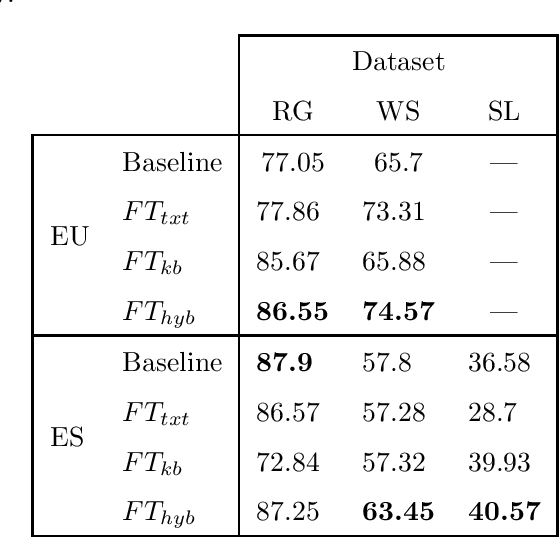
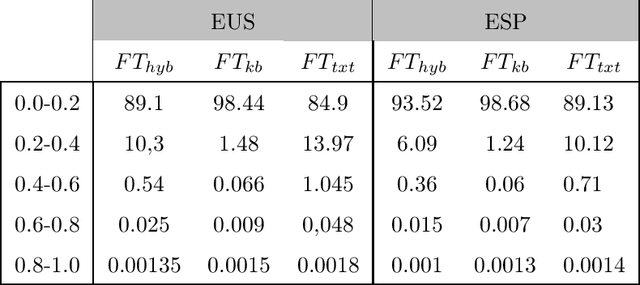
We present a computationally-grounded word similarity dataset based on two well-known Natural Language Processing resources; text corpora and knowledge bases. This dataset aims to fulfil a gap in psycholinguistic research by providing a variety of quantifications of semantic similarity in an extensive set of noun pairs controlled by variables that play a significant role in lexical processing. The dataset creation has consisted in three steps, 1) computing four key psycholinguistic features for each noun; concreteness, frequency, semantic and phonological neighbourhood density; 2) pairing nouns across these four variables; 3) for each noun pair, assigning three types of word similarity measurements, computed out of text, Wordnet and hybrid embeddings. The present dataset includes noun pairs' information in Basque and European Spanish, but further work intends to extend it to more languages.
Energy Efficiency Considerations for Popular AI Benchmarks
Apr 17, 2023
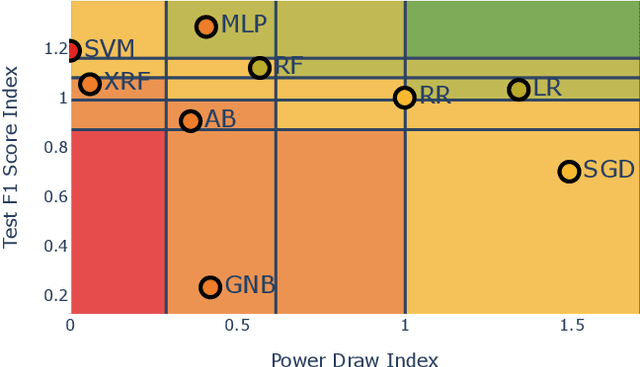
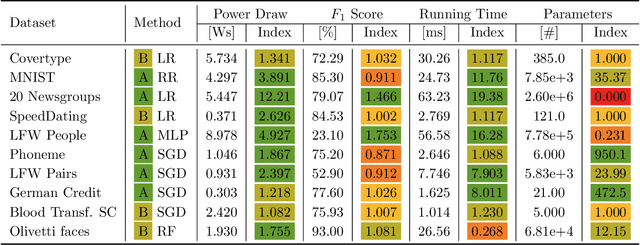
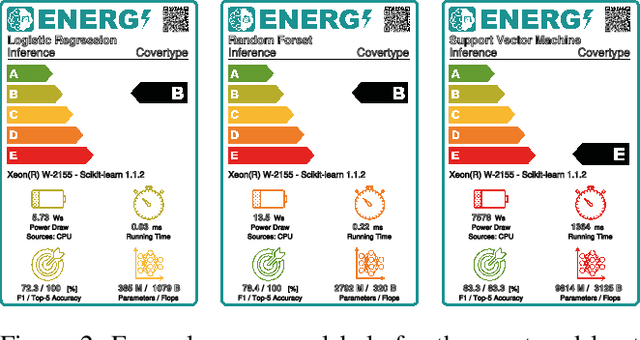
Advances in artificial intelligence need to become more resource-aware and sustainable. This requires clear assessment and reporting of energy efficiency trade-offs, like sacrificing fast running time for higher predictive performance. While first methods for investigating efficiency have been proposed, we still lack comprehensive results for popular methods and data sets. In this work, we attempt to fill this information gap by providing empiric insights for popular AI benchmarks, with a total of 100 experiments. Our findings are evidence of how different data sets all have their own efficiency landscape, and show that methods can be more or less likely to act efficiently.
Semantic-Aware Sensing Information Transmission for Metaverse: A Contest Theoretic Approach
Nov 23, 2022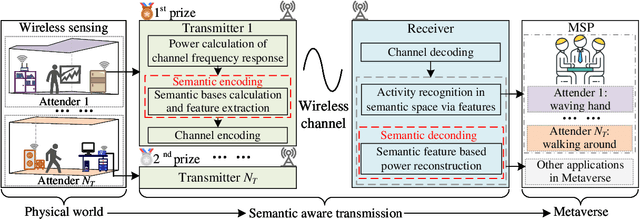
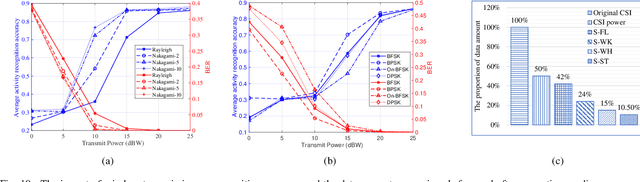
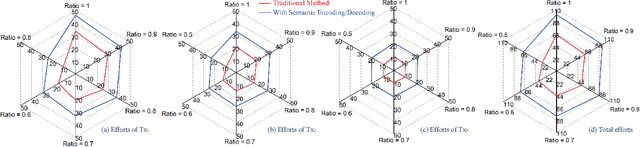
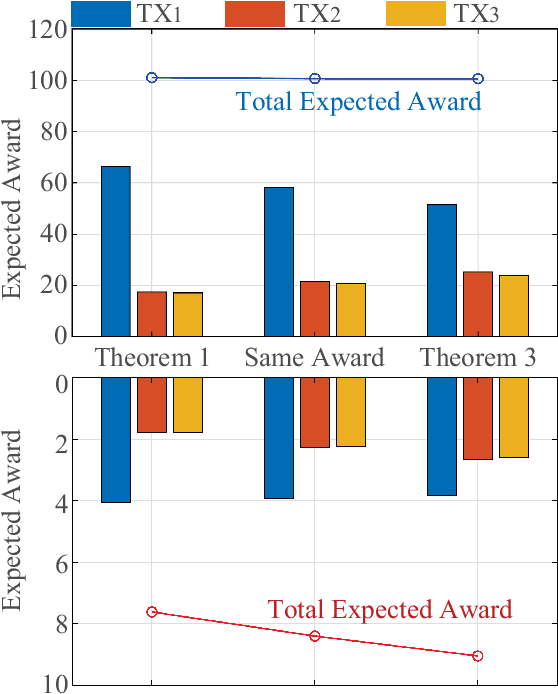
With the advancement of network and computer technologies, virtual cyberspace keeps evolving, and Metaverse is the main representative. As an irreplaceable technology that supports Metaverse, the sensing information transmission from the physical world to Metaverse is vital. Inspired by emerging semantic communication, in this paper, we propose a semantic transmission framework for transmitting sensing information from the physical world to Metaverse. Leveraging the in-depth understanding of sensing information, we define the semantic bases, through which the semantic encoding of sensing data is achieved for the first time. Consequently, the amount of sensing data that needs to be transmitted is dramatically reduced. Unlike conventional methods that undergo data degradation and require data recovery, our approach achieves the sensing goal without data recovery while maintaining performance. To further improve Metaverse service quality, we introduce contest theory to create an incentive mechanism that motivates users to upload data more frequently. Experimental results show that the average data amount after semantic encoding is reduced to about 27.87% of that before encoding, while ensuring the sensing performance. Additionally, the proposed contest theoretic based incentive mechanism increases the sum of data uploading frequency by 27.47% compared to the uniform award scheme.
DCELANM-Net:Medical Image Segmentation based on Dual Channel Efficient Layer Aggregation Network with Learner
Apr 19, 2023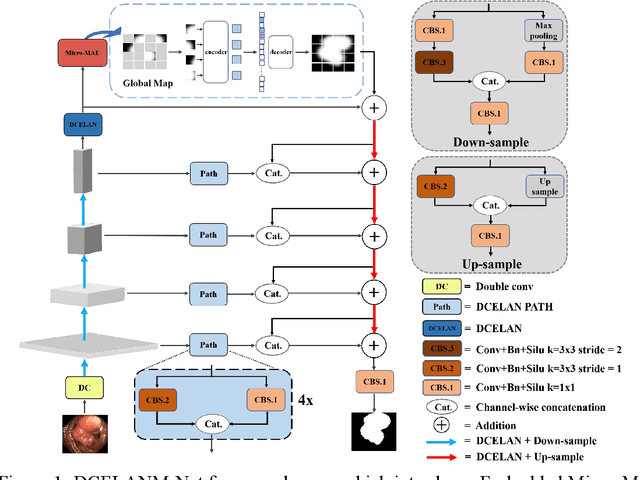

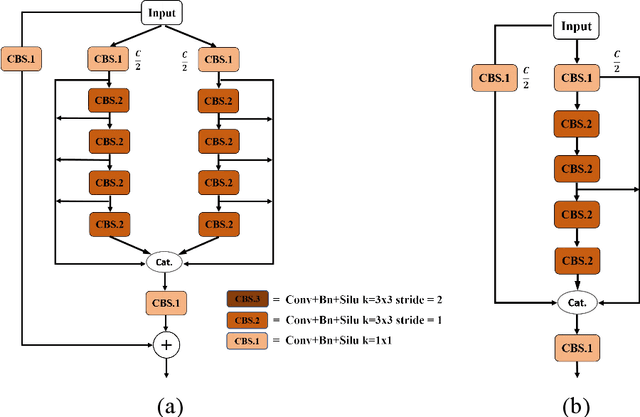
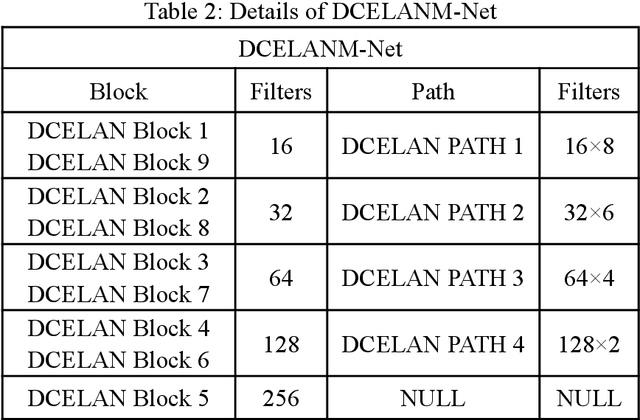
The DCELANM-Net structure, which this article offers, is a model that ingeniously combines a Dual Channel Efficient Layer Aggregation Network (DCELAN) and a Micro Masked Autoencoder (Micro-MAE). On the one hand, for the DCELAN, the features are more effectively fitted by deepening the network structure; the deeper network can successfully learn and fuse the features, which can more accurately locate the local feature information; and the utilization of each layer of channels is more effectively improved by widening the network structure and residual connections. We adopted Micro-MAE as the learner of the model. In addition to being straightforward in its methodology, it also offers a self-supervised learning method, which has the benefit of being incredibly scaleable for the model.
APPLeNet: Visual Attention Parameterized Prompt Learning for Few-Shot Remote Sensing Image Generalization using CLIP
Apr 12, 2023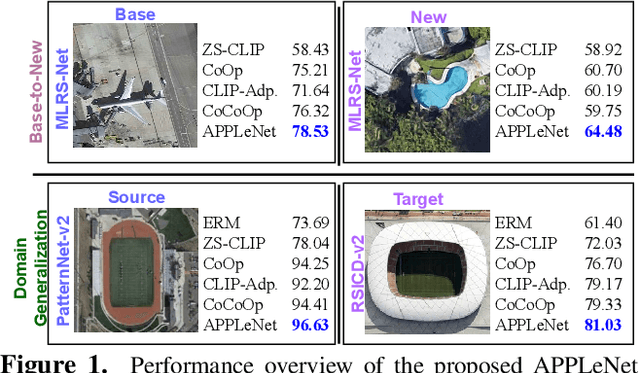

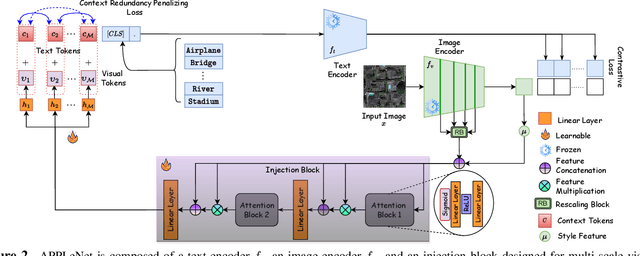
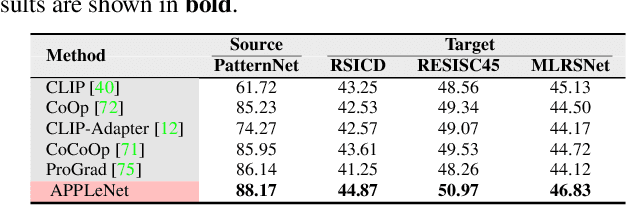
In recent years, the success of large-scale vision-language models (VLMs) such as CLIP has led to their increased usage in various computer vision tasks. These models enable zero-shot inference through carefully crafted instructional text prompts without task-specific supervision. However, the potential of VLMs for generalization tasks in remote sensing (RS) has not been fully realized. To address this research gap, we propose a novel image-conditioned prompt learning strategy called the Visual Attention Parameterized Prompts Learning Network (APPLeNet). APPLeNet emphasizes the importance of multi-scale feature learning in RS scene classification and disentangles visual style and content primitives for domain generalization tasks. To achieve this, APPLeNet combines visual content features obtained from different layers of the vision encoder and style properties obtained from feature statistics of domain-specific batches. An attention-driven injection module is further introduced to generate visual tokens from this information. We also introduce an anti-correlation regularizer to ensure discrimination among the token embeddings, as this visual information is combined with the textual tokens. To validate APPLeNet, we curated four available RS benchmarks and introduced experimental protocols and datasets for three domain generalization tasks. Our results consistently outperform the relevant literature and code is available at https://github.com/mainaksingha01/APPLeNet
Large Language Models as Master Key: Unlocking the Secrets of Materials Science with GPT
Apr 12, 2023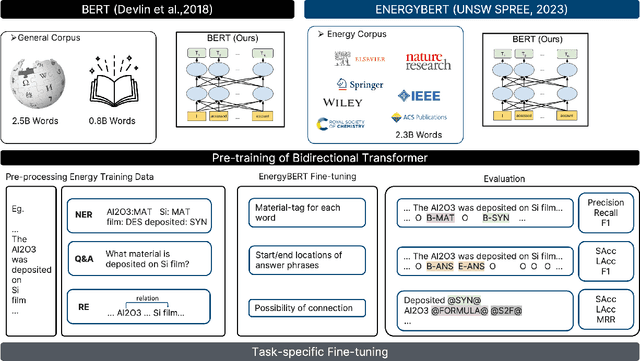
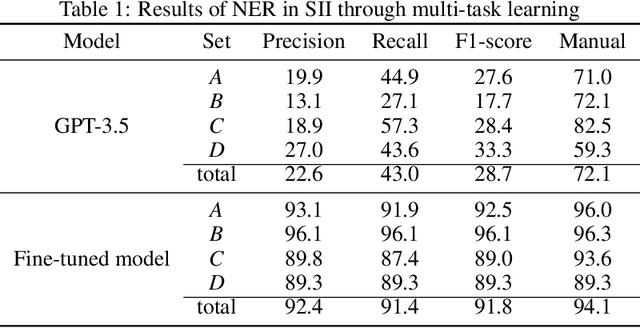
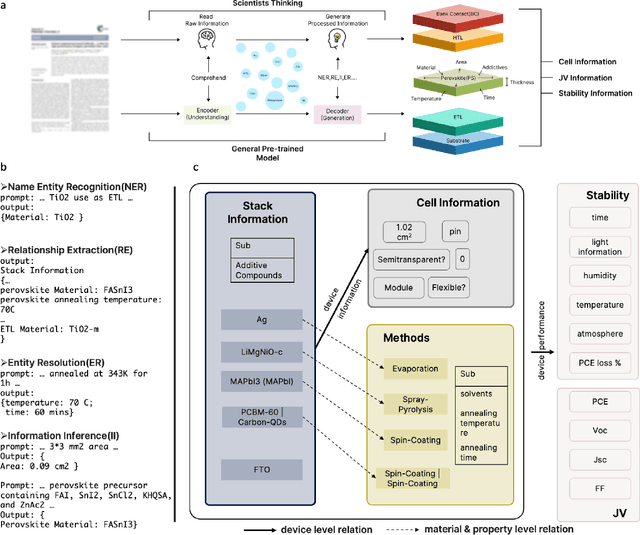
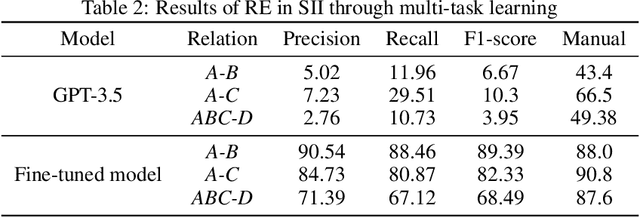
The amount of data has growing significance in exploring cutting-edge materials and a number of datasets have been generated either by hand or automated approaches. However, the materials science field struggles to effectively utilize the abundance of data, especially in applied disciplines where materials are evaluated based on device performance rather than their properties. This article presents a new natural language processing (NLP) task called structured information inference (SII) to address the complexities of information extraction at the device level in materials science. We accomplished this task by tuning GPT-3 on an existing perovskite solar cell FAIR (Findable, Accessible, Interoperable, Reusable) dataset with 91.8% F1-score and extended the dataset with data published since its release. The produced data is formatted and normalized, enabling its direct utilization as input in subsequent data analysis. This feature empowers materials scientists to develop models by selecting high-quality review articles within their domain. Additionally, we designed experiments to predict the electrical performance of solar cells and design materials or devices with targeted parameters using large language models (LLMs). Our results demonstrate comparable performance to traditional machine learning methods without feature selection, highlighting the potential of LLMs to acquire scientific knowledge and design new materials akin to materials scientists.
FALQU: Finding Answers to Legal Questions
Apr 12, 2023
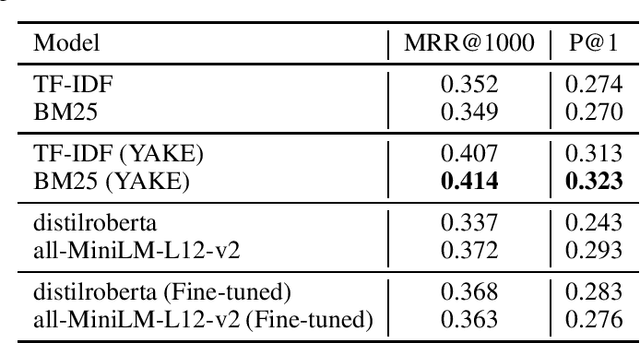

This paper presents a new test collection for Legal IR, FALQU: Finding Answers to Legal Questions, where questions and answers were obtained from Law Stack Exchange (LawSE), a Q&A website for legal professionals, and others with experience in law. Much in line with Stack overflow, Law Stack Exchange has a variety of questions on different topics such as copyright, intellectual property, and criminal laws, making it an interesting source for dataset construction. Questions are also not limited to one country. Often, users of different nationalities may ask questions about laws in different countries and expertise. Therefore, questions in FALQU represent real-world users' information needs thus helping to avoid lab-generated questions. Answers on the other side are given by experts in the field. FALQU is the first test collection, to the best of our knowledge, to use LawSE, considering more diverse questions than the questions from the standard legal bar and judicial exams. It contains 9880 questions and 34,145 answers to legal questions. Alongside our new test collection, we provide different baseline systems that include traditional information retrieval models such as TF-IDF and BM25, and deep neural network search models. The results obtained from the BM25 model achieved the highest effectiveness.
Co-GRU Enhanced End-to-End Design for Long-haul Coherent Transmission Systems
Apr 28, 2023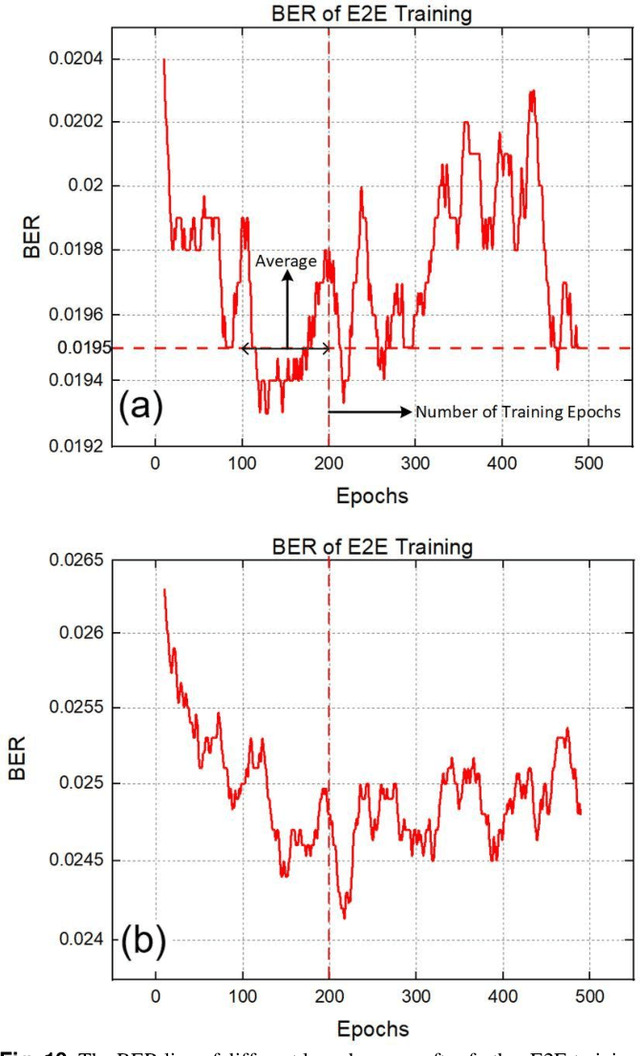
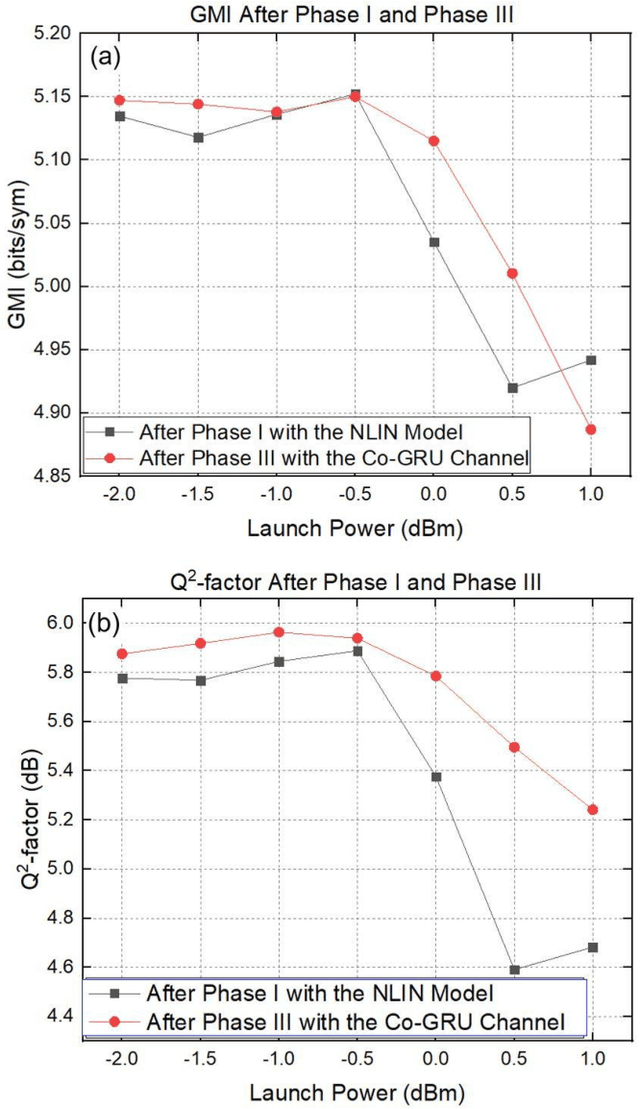
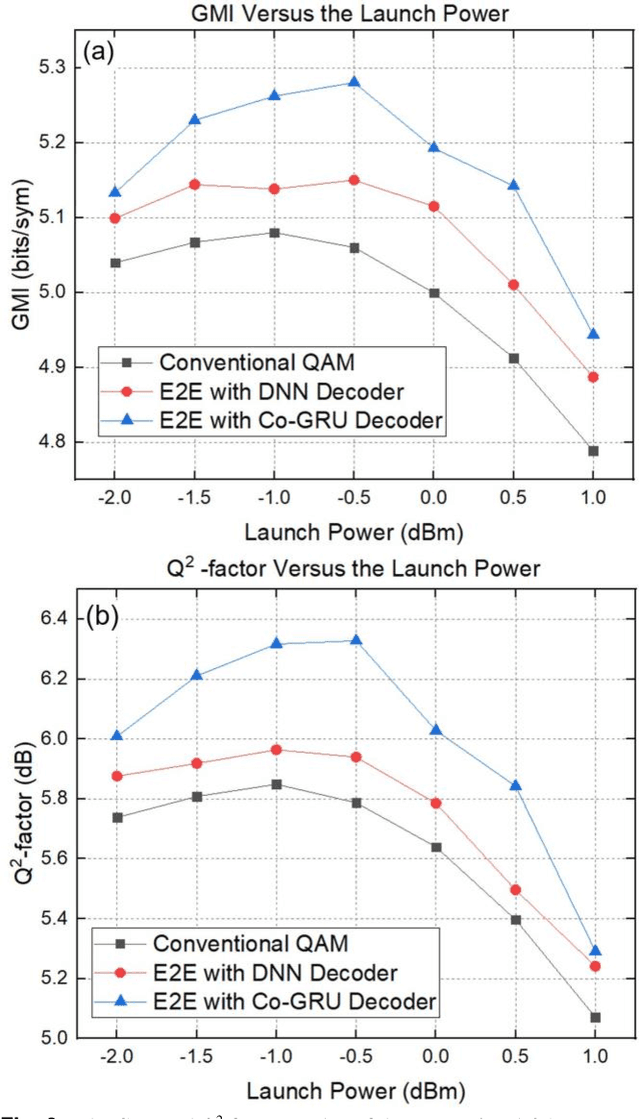
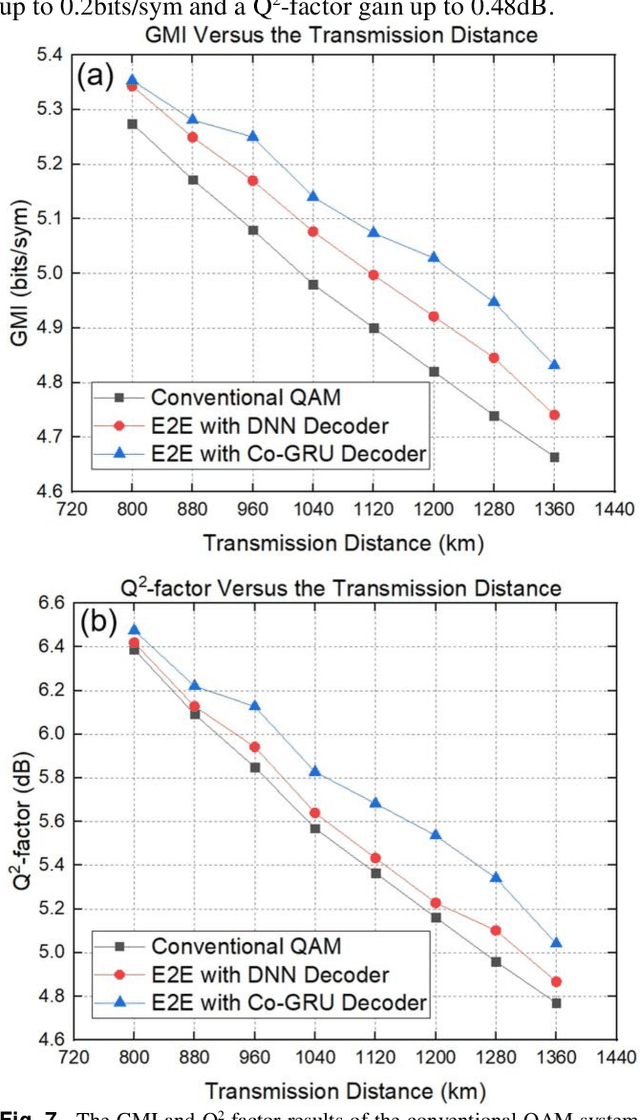
In recent years, the end-to-end (E2E) scheme based on deep learning (DL), jointly optimizes the encoder and decoder parameters located of the system. Since the center-oriented Gated Recurrent Unit (Co-GRU) network structure satisfying gradient BP while having the ability to learn and compensate for intersymbol interference (ISI) with low computation cost, it is adopted for both the channel modeling and decoder implementation in the E2E design scheme proposed. Meanwhile, to obtain the constellation with the symmetrical distribution characteristic, the encoder and decoder are first E2E joint trained through NLIN model, and further trained on the Co-GRU channel replacing the SSFM channel as well as the subsequent digital signal processing (DSP) step. After the E2EDL process, the performance of the encoder and decoder trained is tested on the SSFM channel. For the E2E system with the Co-GRU based decoder, the gain of general mutual information (GMI) and the Q2-factor relative to the conventional QAM system, are respectively improved up to 0.2 bits/sym and 0.48dB for the long-haul 5-channel dual-polarization coherent system with 960 transmission distance at around the optimal launch power point. The work paves the way for the further study of the application for the Co-GRU structure in the data-driven E2E design of the experimental system, both for the channel modeling and the decoder performance improvement.
MASK-CNN-Transformer For Real-Time Multi-Label Weather Recognition
Apr 28, 2023Weather recognition is an essential support for many practical life applications, including traffic safety, environment, and meteorology. However, many existing related works cannot comprehensively describe weather conditions due to their complex co-occurrence dependencies. This paper proposes a novel multi-label weather recognition model considering these dependencies. The proposed model called MASK-Convolutional Neural Network-Transformer (MASK-CT) is based on the Transformer, the convolutional process, and the MASK mechanism. The model employs multiple convolutional layers to extract features from weather images and a Transformer encoder to calculate the probability of each weather condition based on the extracted features. To improve the generalization ability of MASK-CT, a MASK mechanism is used during the training phase. The effect of the MASK mechanism is explored and discussed. The Mask mechanism randomly withholds some information from one-pair training instances (one image and its corresponding label). There are two types of MASK methods. Specifically, MASK-I is designed and deployed on the image before feeding it into the weather feature extractor and MASK-II is applied to the image label. The Transformer encoder is then utilized on the randomly masked image features and labels. The experimental results from various real-world weather recognition datasets demonstrate that the proposed MASK-CT model outperforms state-of-the-art methods. Furthermore, the high-speed dynamic real-time weather recognition capability of the MASK-CT is evaluated.