 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Activation Functions Not To Active: A Plausible Theory on Interpreting Neural Networks
May 09, 2023
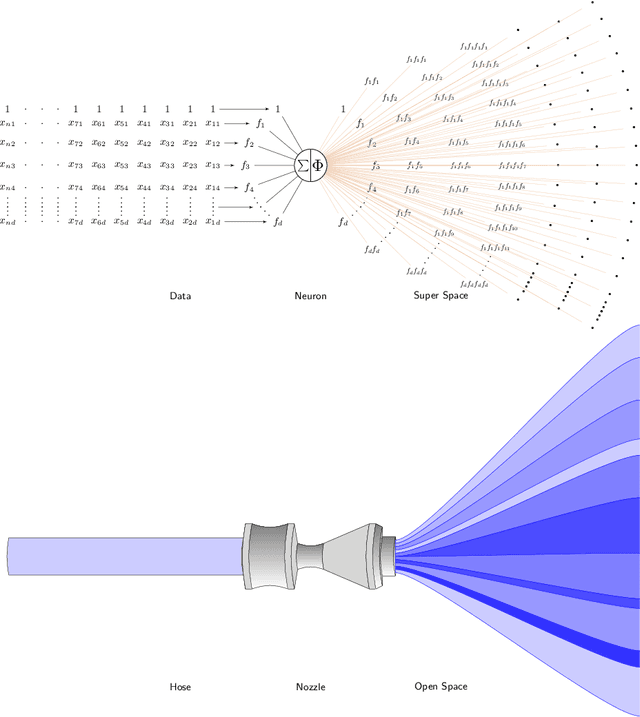

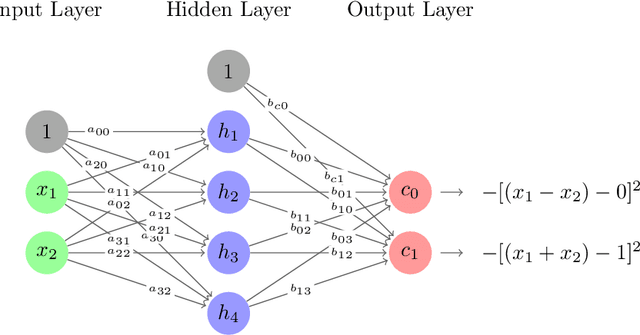
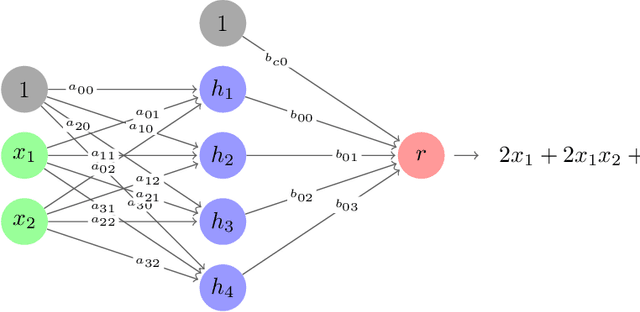
Researchers commonly believe that neural networks model a high-dimensional space but cannot give a clear definition of this space. What is this space? What is its dimension? And does it has finite dimensions? In this paper, we develop a plausible theory on interpreting neural networks in terms of the role of activation functions in neural networks and define a high-dimensional (more precisely, an infinite-dimensional) space that neural networks including deep-learning networks could create. We show that the activation function acts as a magnifying function that maps the low-dimensional linear space into an infinite-dimensional space, which can distinctly identify the polynomial approximation of any multivariate continuous function of the variable values being the same features of the given dataset. Given a dataset with each example of $d$ features $f_1$, $f_2$, $\cdots$, $f_d$, we believe that neural networks model a special space with infinite dimensions, each of which is a monomial $$\prod_{i_1, i_2, \cdots, i_d} f_1^{i_1} f_2^{i_2} \cdots f_d^{i_d}$$ for some non-negative integers ${i_1, i_2, \cdots, i_d} \in \mathbb{Z}_{0}^{+}=\{0,1,2,3,\ldots\} $. We term such an infinite-dimensional space a $\textit{ Super Space (SS)}$. We see such a dimension as the minimum information unit. Every neuron node previously through an activation layer in neural networks is a $\textit{ Super Plane (SP) }$, which is actually a polynomial of infinite degree. This $\textit{ Super Space }$ is something like a coordinate system, in which every multivalue function can be represented by a $\textit{ Super Plane }$. We also show that training NNs could at least be reduced to solving a system of nonlinear equations. %solve sets of nonlinear equations
PBNR: Prompt-based News Recommender System
Apr 16, 2023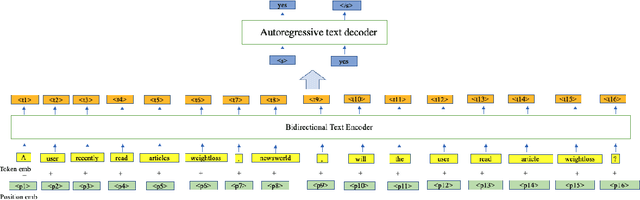

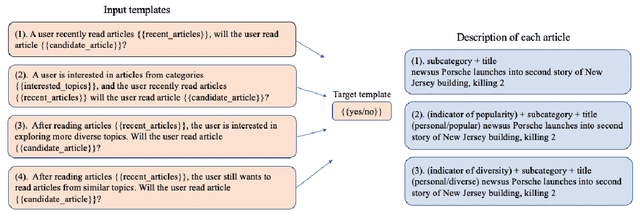
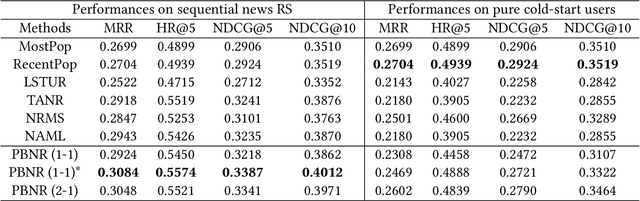
Online news platforms often use personalized news recommendation methods to help users discover articles that align with their interests. These methods typically predict a matching score between a user and a candidate article to reflect the user's preference for the article. Some previous works have used language model techniques, such as the attention mechanism, to capture users' interests based on their past behaviors, and to understand the content of articles. However, these existing model architectures require adjustments if additional information is taken into account. Pre-trained large language models, which can better capture word relationships and comprehend contexts, have seen a significant development in recent years, and these pre-trained models have the advantages of transfer learning and reducing the training time for downstream tasks. Meanwhile, prompt learning is a newly developed technique that leverages pre-trained language models by building task-specific guidance for output generations. To leverage textual information in news articles, this paper introduces the pre-trained large language model and prompt-learning to the community of news recommendation. The proposed model "prompt-based news recommendation" (PBNR) treats the personalized news recommendation as a text-to-text language task and designs personalized prompts to adapt to the pre-trained language model -- text-to-text transfer transformer (T5). Experimental studies using the Microsoft News dataset show that PBNR is capable of making accurate recommendations by taking into account various lengths of past behaviors of different users. PBNR can also easily adapt to new information without changing the model architecture and the training objective. Additionally, PBNR can make recommendations based on users' specific requirements, allowing human-computer interaction in the news recommendation field.
Prompt Tuning Inversion for Text-Driven Image Editing Using Diffusion Models
May 08, 2023
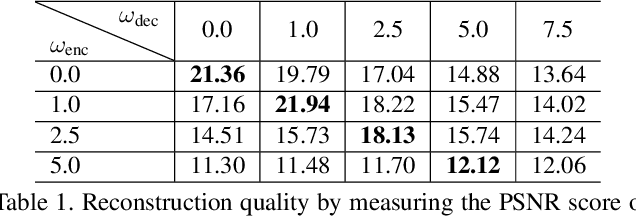
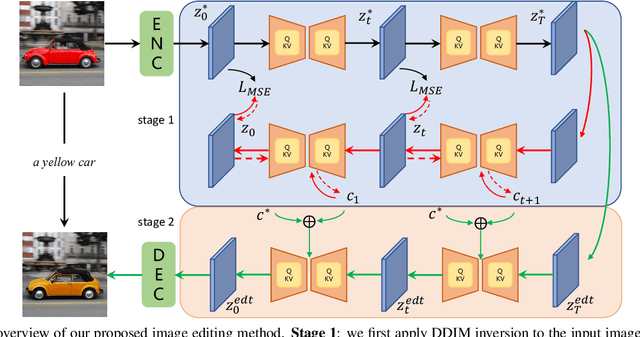
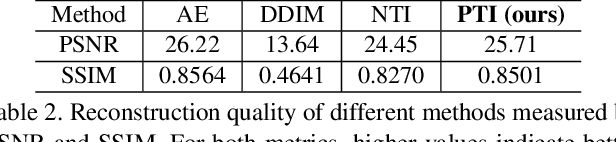
Recently large-scale language-image models (e.g., text-guided diffusion models) have considerably improved the image generation capabilities to generate photorealistic images in various domains. Based on this success, current image editing methods use texts to achieve intuitive and versatile modification of images. To edit a real image using diffusion models, one must first invert the image to a noisy latent from which an edited image is sampled with a target text prompt. However, most methods lack one of the following: user-friendliness (e.g., additional masks or precise descriptions of the input image are required), generalization to larger domains, or high fidelity to the input image. In this paper, we design an accurate and quick inversion technique, Prompt Tuning Inversion, for text-driven image editing. Specifically, our proposed editing method consists of a reconstruction stage and an editing stage. In the first stage, we encode the information of the input image into a learnable conditional embedding via Prompt Tuning Inversion. In the second stage, we apply classifier-free guidance to sample the edited image, where the conditional embedding is calculated by linearly interpolating between the target embedding and the optimized one obtained in the first stage. This technique ensures a superior trade-off between editability and high fidelity to the input image of our method. For example, we can change the color of a specific object while preserving its original shape and background under the guidance of only a target text prompt. Extensive experiments on ImageNet demonstrate the superior editing performance of our method compared to the state-of-the-art baselines.
Timely Tracking of a Remote Dynamic Source Via Multi-Hop Renewal Updates
Apr 04, 2023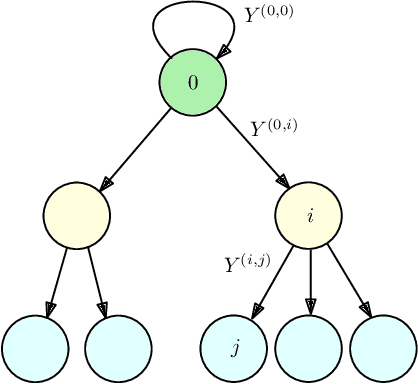
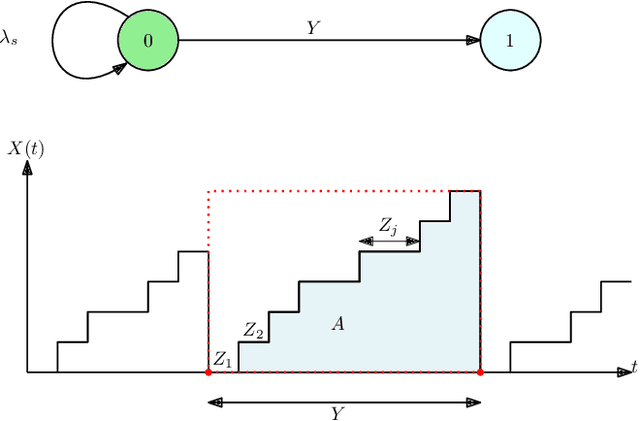

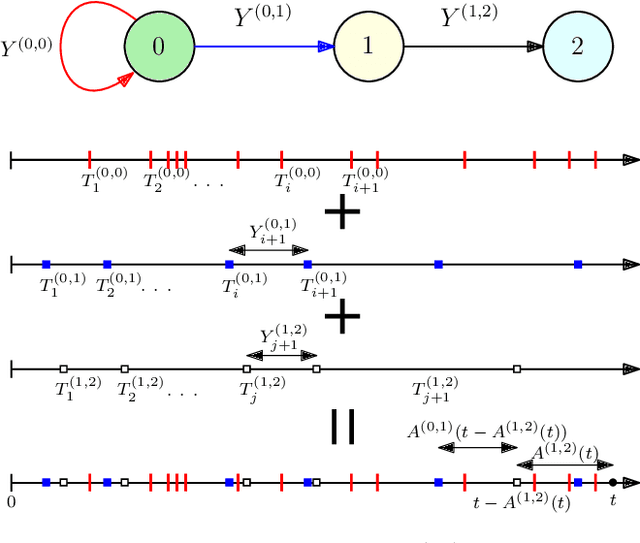
We study the version age of information in a multi-hop multi-cast cache-enabled network, where updates at the source are marked with incrementing version numbers, and the inter-update times on the links are not necessarily exponentially distributed. We focus on the set of non-arithmetic distributions, which includes continuous probability distributions as a subset, with finite first and second moments for inter-update times. We first characterize the instantaneous version age of information at each node for an arbitrary network. We then explicate the recursive equations for instantaneous version age of information in multi-hop networks and employ semi-martingale representation of renewal processes to derive closed form expressions for the expected version age of information at an end user. We show that the expected age in a multi-hop network exhibits an additive structure. Further, we show that the expected age at each user is proportional to the variance of inter-update times at all links between a user and the source. Thus, end user nodes should request packet updates at constant intervals.
Mutual Information Regularized Offline Reinforcement Learning
Oct 14, 2022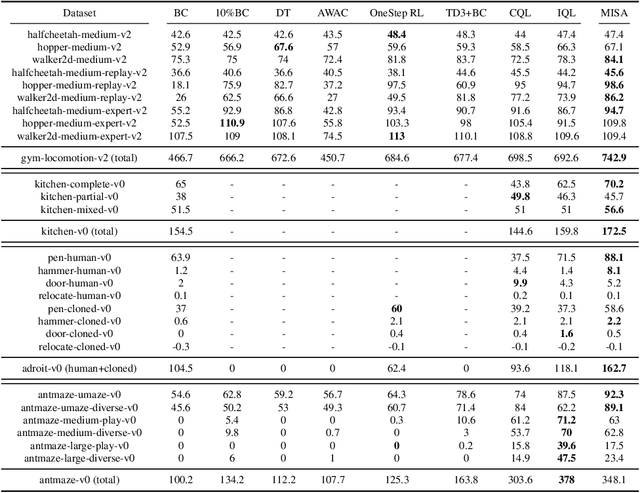
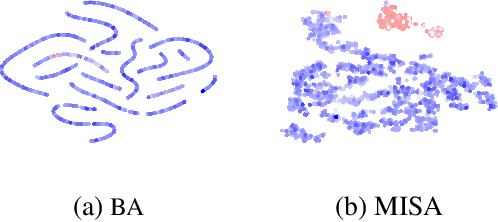
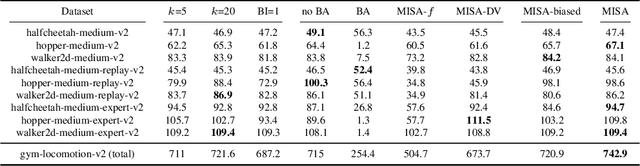

Offline reinforcement learning (RL) aims at learning an effective policy from offline datasets without active interactions with the environment. The major challenge of offline RL is the distribution shift that appears when out-of-distribution actions are queried, which makes the policy improvement direction biased by extrapolation errors. Most existing methods address this problem by penalizing the policy for deviating from the behavior policy during policy improvement or making conservative updates for value functions during policy evaluation. In this work, we propose a novel MISA framework to approach offline RL from the perspective of Mutual Information between States and Actions in the dataset by directly constraining the policy improvement direction. Intuitively, mutual information measures the mutual dependence of actions and states, which reflects how a behavior agent reacts to certain environment states during data collection. To effectively utilize this information to facilitate policy learning, MISA constructs lower bounds of mutual information parameterized by the policy and Q-values. We show that optimizing this lower bound is equivalent to maximizing the likelihood of a one-step improved policy on the offline dataset. In this way, we constrain the policy improvement direction to lie in the data manifold. The resulting algorithm simultaneously augments the policy evaluation and improvement by adding a mutual information regularization. MISA is a general offline RL framework that unifies conservative Q-learning (CQL) and behavior regularization methods (e.g., TD3+BC) as special cases. Our experiments show that MISA performs significantly better than existing methods and achieves new state-of-the-art on various tasks of the D4RL benchmark.
Joint Token Pruning and Squeezing Towards More Aggressive Compression of Vision Transformers
Apr 21, 2023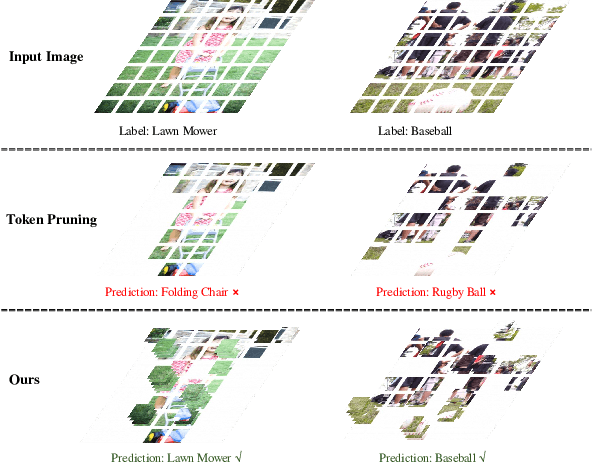
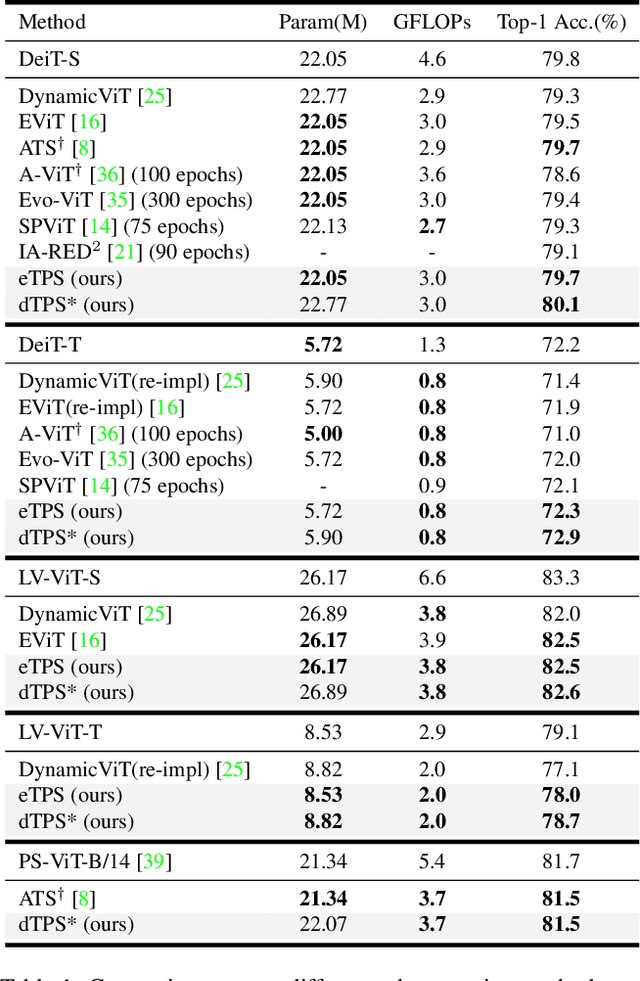
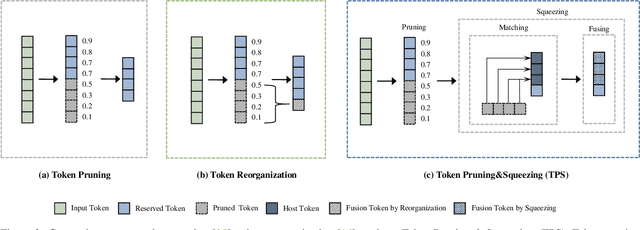
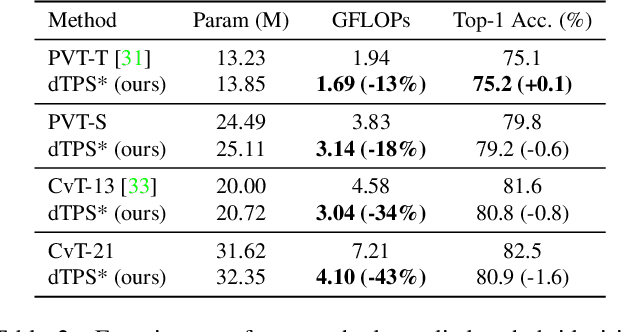
Although vision transformers (ViTs) have shown promising results in various computer vision tasks recently, their high computational cost limits their practical applications. Previous approaches that prune redundant tokens have demonstrated a good trade-off between performance and computation costs. Nevertheless, errors caused by pruning strategies can lead to significant information loss. Our quantitative experiments reveal that the impact of pruned tokens on performance should be noticeable. To address this issue, we propose a novel joint Token Pruning & Squeezing module (TPS) for compressing vision transformers with higher efficiency. Firstly, TPS adopts pruning to get the reserved and pruned subsets. Secondly, TPS squeezes the information of pruned tokens into partial reserved tokens via the unidirectional nearest-neighbor matching and similarity-based fusing steps. Compared to state-of-the-art methods, our approach outperforms them under all token pruning intensities. Especially while shrinking DeiT-tiny&small computational budgets to 35%, it improves the accuracy by 1%-6% compared with baselines on ImageNet classification. The proposed method can accelerate the throughput of DeiT-small beyond DeiT-tiny, while its accuracy surpasses DeiT-tiny by 4.78%. Experiments on various transformers demonstrate the effectiveness of our method, while analysis experiments prove our higher robustness to the errors of the token pruning policy. Code is available at https://github.com/megvii-research/TPS-CVPR2023.
Disentangled Generation with Information Bottleneck for Few-Shot Learning
Nov 29, 2022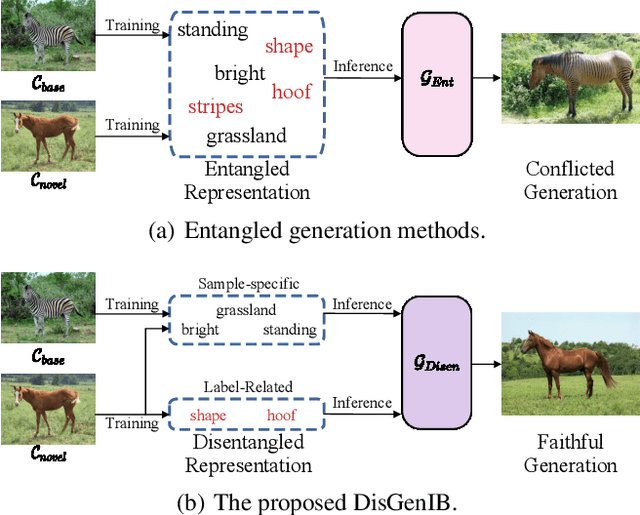
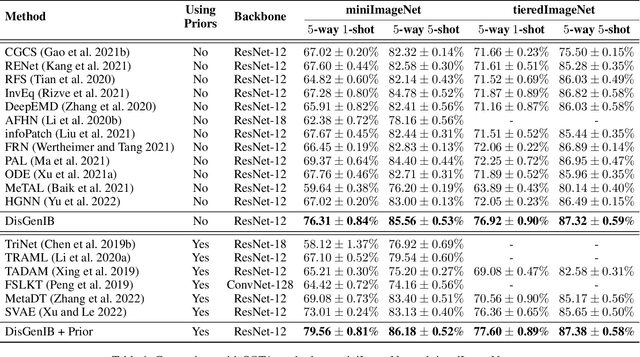
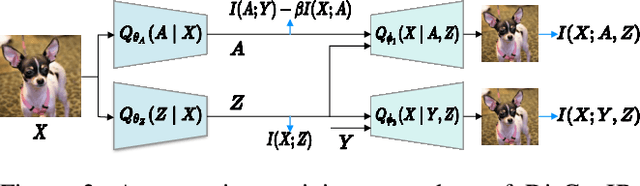
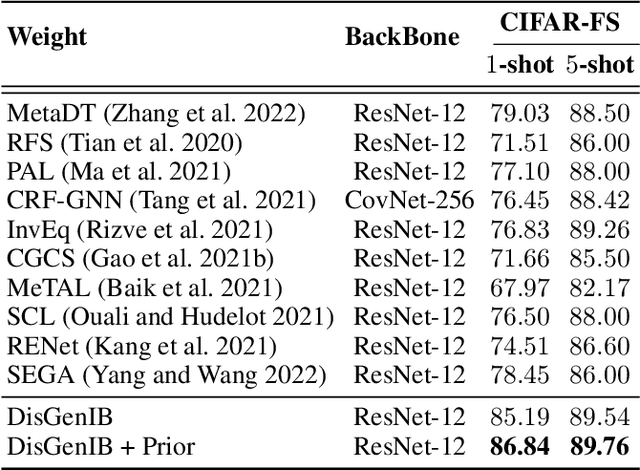
Few-shot learning (FSL), which aims to classify unseen classes with few samples, is challenging due to data scarcity. Although various generative methods have been explored for FSL, the entangled generation process of these methods exacerbates the distribution shift in FSL, thus greatly limiting the quality of generated samples. To these challenges, we propose a novel Information Bottleneck (IB) based Disentangled Generation Framework for FSL, termed as DisGenIB, that can simultaneously guarantee the discrimination and diversity of generated samples. Specifically, we formulate a novel framework with information bottleneck that applies for both disentangled representation learning and sample generation. Different from existing IB-based methods that can hardly exploit priors, we demonstrate our DisGenIB can effectively utilize priors to further facilitate disentanglement. We further prove in theory that some previous generative and disentanglement methods are special cases of our DisGenIB, which demonstrates the generality of the proposed DisGenIB. Extensive experiments on challenging FSL benchmarks confirm the effectiveness and superiority of DisGenIB, together with the validity of our theoretical analyses. Our codes will be open-source upon acceptance.
InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval
Jan 04, 2023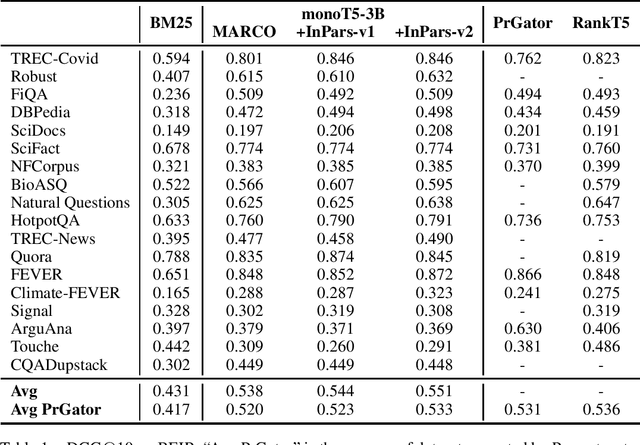
Recently, InPars introduced a method to efficiently use large language models (LLMs) in information retrieval tasks: via few-shot examples, an LLM is induced to generate relevant queries for documents. These synthetic query-document pairs can then be used to train a retriever. However, InPars and, more recently, Promptagator, rely on proprietary LLMs such as GPT-3 and FLAN to generate such datasets. In this work we introduce InPars-v2, a dataset generator that uses open-source LLMs and existing powerful rerankers to select synthetic query-document pairs for training. A simple BM25 retrieval pipeline followed by a monoT5 reranker finetuned on InPars-v2 data achieves new state-of-the-art results on the BEIR benchmark. To allow researchers to further improve our method, we open source the code, synthetic data, and finetuned models: https://github.com/zetaalphavector/inPars/tree/master/tpu
Uncovering ChatGPT's Capabilities in Recommender Systems
May 03, 2023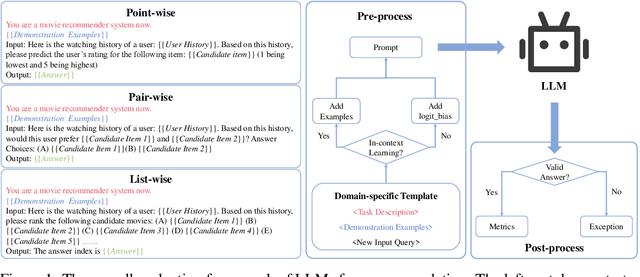
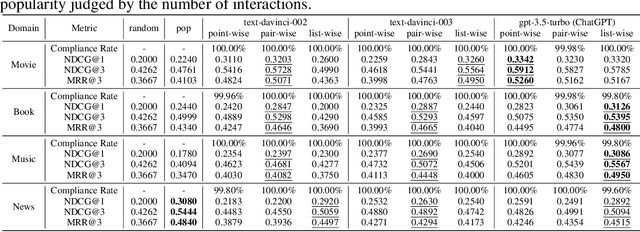

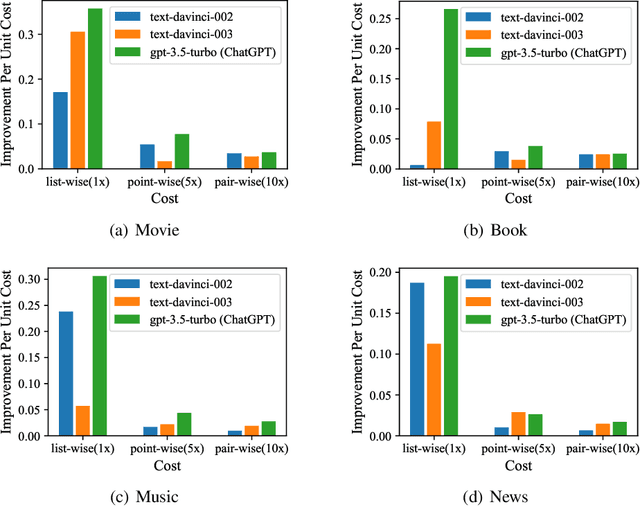
The debut of ChatGPT has recently attracted the attention of the natural language processing (NLP) community and beyond. Existing studies have demonstrated that ChatGPT shows significant improvement in a range of downstream NLP tasks, but the capabilities and limitations of ChatGPT in terms of recommendations remain unclear. In this study, we aim to conduct an empirical analysis of ChatGPT's recommendation ability from an Information Retrieval (IR) perspective, including point-wise, pair-wise, and list-wise ranking. To achieve this goal, we re-formulate the above three recommendation policies into a domain-specific prompt format. Through extensive experiments on four datasets from different domains, we demonstrate that ChatGPT outperforms other large language models across all three ranking policies. Based on the analysis of unit cost improvements, we identify that ChatGPT with list-wise ranking achieves the best trade-off between cost and performance compared to point-wise and pair-wise ranking. Moreover, ChatGPT shows the potential for mitigating the cold start problem and interpretable recommendation. To facilitate further explorations in this area, the full code and detailed original results are open-sourced at https://github.com/rainym00d/LLM4RS.
ProgDTD: Progressive Learned Image Compression with Double-Tail-Drop Training
May 03, 2023Progressive compression allows images to start loading as low-resolution versions, becoming clearer as more data is received. This increases user experience when, for example, network connections are slow. Today, most approaches for image compression, both classical and learned ones, are designed to be non-progressive. This paper introduces ProgDTD, a training method that transforms learned, non-progressive image compression approaches into progressive ones. The design of ProgDTD is based on the observation that the information stored within the bottleneck of a compression model commonly varies in importance. To create a progressive compression model, ProgDTD modifies the training steps to enforce the model to store the data in the bottleneck sorted by priority. We achieve progressive compression by transmitting the data in order of its sorted index. ProgDTD is designed for CNN-based learned image compression models, does not need additional parameters, and has a customizable range of progressiveness. For evaluation, we apply ProgDTDto the hyperprior model, one of the most common structures in learned image compression. Our experimental results show that ProgDTD performs comparably to its non-progressive counterparts and other state-of-the-art progressive models in terms of MS-SSIM and accuracy.