 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Bounding probabilities of causation through the causal marginal problem
Apr 04, 2023
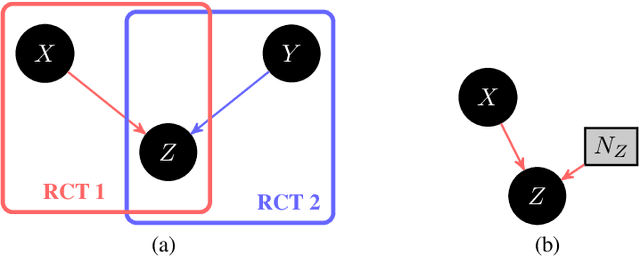
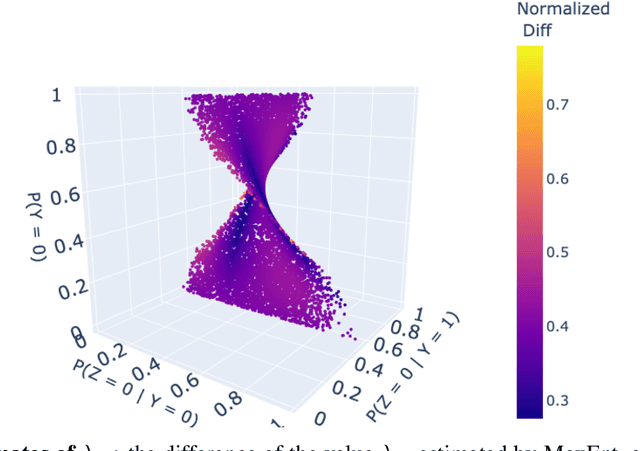
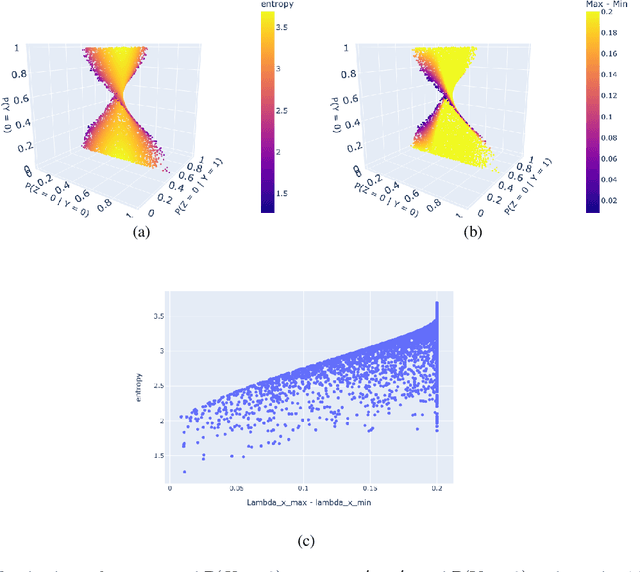
Probabilities of Causation play a fundamental role in decision making in law, health care and public policy. Nevertheless, their point identification is challenging, requiring strong assumptions such as monotonicity. In the absence of such assumptions, existing work requires multiple observations of datasets that contain the same treatment and outcome variables, in order to establish bounds on these probabilities. However, in many clinical trials and public policy evaluation cases, there exist independent datasets that examine the effect of a different treatment each on the same outcome variable. Here, we outline how to significantly tighten existing bounds on the probabilities of causation, by imposing counterfactual consistency between SCMs constructed from such independent datasets ('causal marginal problem'). Next, we describe a new information theoretic approach on falsification of counterfactual probabilities, using conditional mutual information to quantify counterfactual influence. The latter generalises to arbitrary discrete variables and number of treatments, and renders the causal marginal problem more interpretable. Since the question of 'tight enough' is left to the user, we provide an additional method of inference when the bounds are unsatisfactory: A maximum entropy based method that defines a metric for the space of plausible SCMs and proposes the entropy maximising SCM for inferring counterfactuals in the absence of more information.
TransFlow: Transformer as Flow Learner
Apr 23, 2023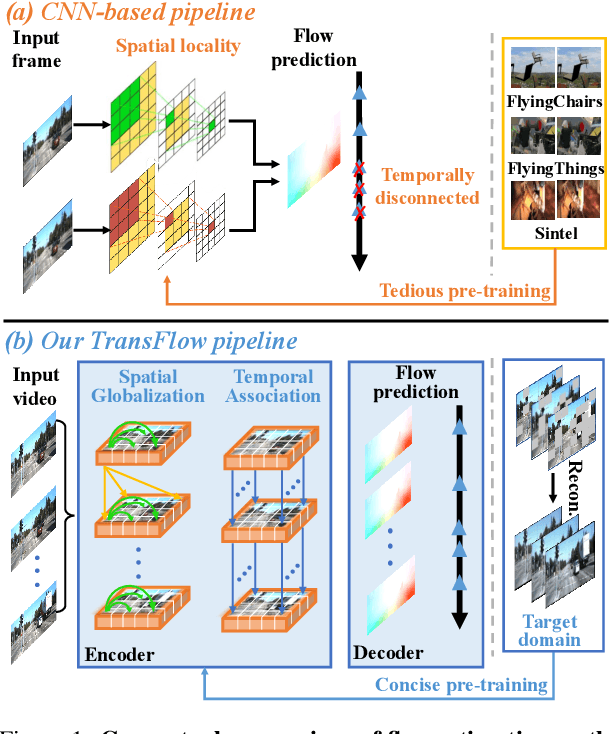
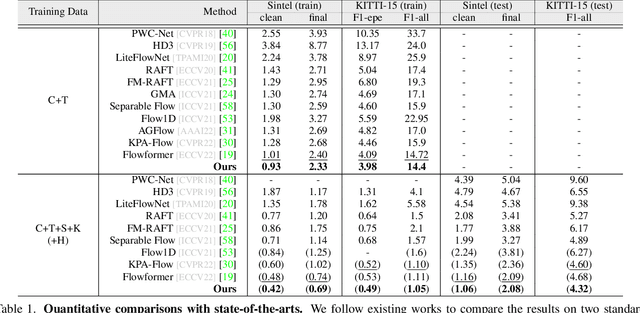
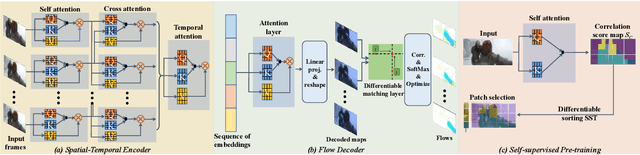
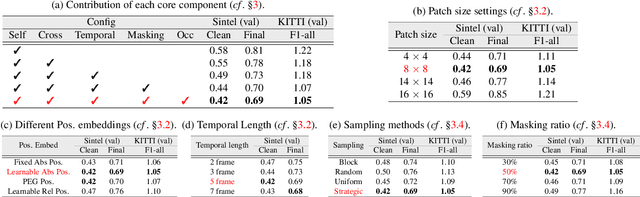
Optical flow is an indispensable building block for various important computer vision tasks, including motion estimation, object tracking, and disparity measurement. In this work, we propose TransFlow, a pure transformer architecture for optical flow estimation. Compared to dominant CNN-based methods, TransFlow demonstrates three advantages. First, it provides more accurate correlation and trustworthy matching in flow estimation by utilizing spatial self-attention and cross-attention mechanisms between adjacent frames to effectively capture global dependencies; Second, it recovers more compromised information (e.g., occlusion and motion blur) in flow estimation through long-range temporal association in dynamic scenes; Third, it enables a concise self-learning paradigm and effectively eliminate the complex and laborious multi-stage pre-training procedures. We achieve the state-of-the-art results on the Sintel, KITTI-15, as well as several downstream tasks, including video object detection, interpolation and stabilization. For its efficacy, we hope TransFlow could serve as a flexible baseline for optical flow estimation.
PaTeCon: A Pattern-Based Temporal Constraint Mining Method for Conflict Detection on Knowledge Graphs
Apr 23, 2023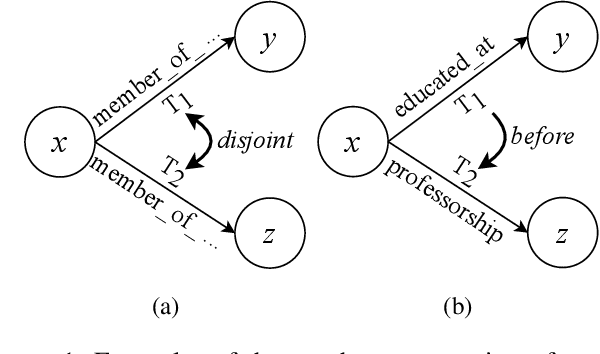

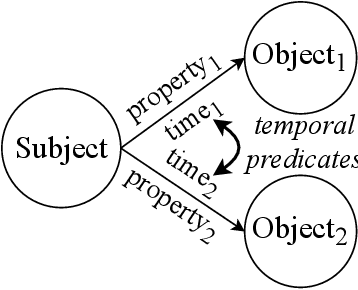

Temporal facts, the facts for characterizing events that hold in specific time periods, are attracting rising attention in the knowledge graph (KG) research communities. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs and detecting potential temporal conflicts. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. We start from the common pattern of temporal facts and constraints and propose a pattern-based temporal constraint mining method, PaTeCon. PaTeCon uses automatically determined graph patterns and their relevant statistical information over the given KG instead of human experts to generate time constraints. Specifically, PaTeCon dynamically attaches class restriction to candidate constraints according to their measuring scores.We evaluate PaTeCon on two large-scale datasets based on Wikidata and Freebase respectively. The experimental results show that pattern-based automatic constraint mining is powerful in generating valuable temporal constraints.
Epistemic considerations when AI answers questions for us
Apr 23, 2023
In this position paper, we argue that careless reliance on AI to answer our questions and to judge our output is a violation of Grice's Maxim of Quality as well as a violation of Lemoine's legal Maxim of Innocence, performing an (unwarranted) authority fallacy, and while lacking assessment signals, committing Type II errors that result from fallacies of the inverse. What is missing in the focus on output and results of AI-generated and AI-evaluated content is, apart from paying proper tribute, the demand to follow a person's thought process (or a machine's decision processes). In deliberately avoiding Neural Networks that cannot explain how they come to their conclusions, we introduce logic-symbolic inference to handle any possible epistemics any human or artificial information processor may have. Our system can deal with various belief systems and shows how decisions may differ for what is true, false, realistic, unrealistic, literal, or anomalous. As is, stota AI such as ChatGPT is a sorcerer's apprentice.
Zoom is what you need: An empirical study of the power of zoom and spatial biases in image classification
Apr 11, 2023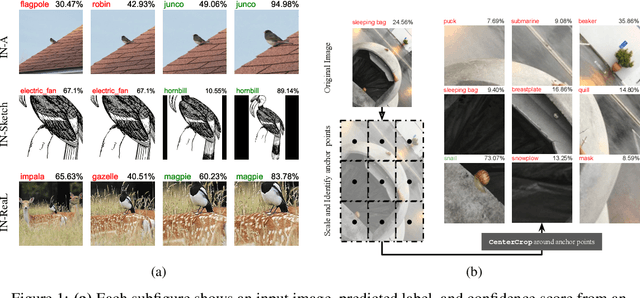



Image classifiers are information-discarding machines, by design. Yet, how these models discard information remains mysterious. We hypothesize that one way for image classifiers to reach high accuracy is to first zoom to the most discriminative region in the image and then extract features from there to predict image labels. We study six popular networks ranging from AlexNet to CLIP and find that proper framing of the input image can lead to the correct classification of 98.91% of ImageNet images. Furthermore, we explore the potential and limits of zoom transforms in image classification and uncover positional biases in various datasets, especially a strong center bias in two popular datasets: ImageNet-A and ObjectNet. Finally, leveraging our insights into the potential of zoom, we propose a state-of-the-art test-time augmentation (TTA) technique that improves classification accuracy by forcing models to explicitly perform zoom-in operations before making predictions. Our method is more interpretable, accurate, and faster than MEMO, a state-of-the-art TTA method. Additionally, we propose ImageNet-Hard, a new benchmark where zooming in alone often does not help state-of-the-art models better label images.
TodyNet: Temporal Dynamic Graph Neural Network for Multivariate Time Series Classification
Apr 11, 2023Multivariate time series classification (MTSC) is an important data mining task, which can be effectively solved by popular deep learning technology. Unfortunately, the existing deep learning-based methods neglect the hidden dependencies in different dimensions and also rarely consider the unique dynamic features of time series, which lack sufficient feature extraction capability to obtain satisfactory classification accuracy. To address this problem, we propose a novel temporal dynamic graph neural network (TodyNet) that can extract hidden spatio-temporal dependencies without undefined graph structure. It enables information flow among isolated but implicit interdependent variables and captures the associations between different time slots by dynamic graph mechanism, which further improves the classification performance of the model. Meanwhile, the hierarchical representations of graphs cannot be learned due to the limitation of GNNs. Thus, we also design a temporal graph pooling layer to obtain a global graph-level representation for graph learning with learnable temporal parameters. The dynamic graph, graph information propagation, and temporal convolution are jointly learned in an end-to-end framework. The experiments on 26 UEA benchmark datasets illustrate that the proposed TodyNet outperforms existing deep learning-based methods in the MTSC tasks.
Multi-Graph Convolution Network for Pose Forecasting
Apr 11, 2023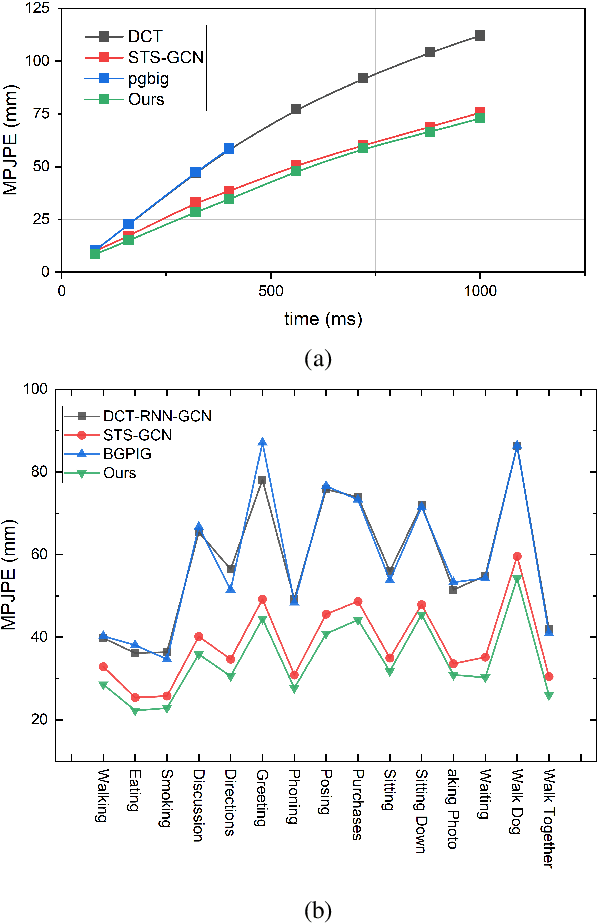
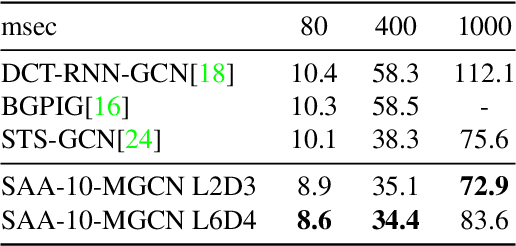
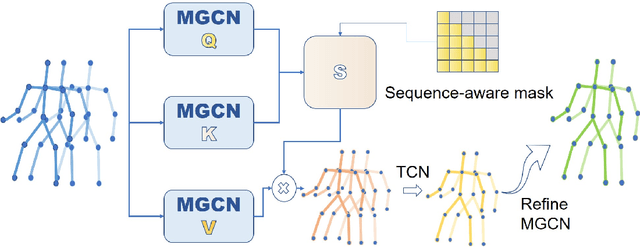
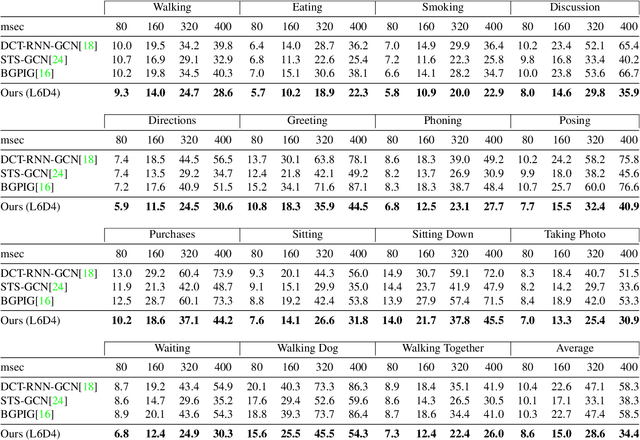
Recently, there has been a growing interest in predicting human motion, which involves forecasting future body poses based on observed pose sequences. This task is complex due to modeling spatial and temporal relationships. The most commonly used models for this task are autoregressive models, such as recurrent neural networks (RNNs) or variants, and Transformer Networks. However, RNNs have several drawbacks, such as vanishing or exploding gradients. Other researchers have attempted to solve the communication problem in the spatial dimension by integrating Graph Convolutional Networks (GCN) and Long Short-Term Memory (LSTM) models. These works deal with temporal and spatial information separately, which limits the effectiveness. To fix this problem, we propose a novel approach called the multi-graph convolution network (MGCN) for 3D human pose forecasting. This model simultaneously captures spatial and temporal information by introducing an augmented graph for pose sequences. Multiple frames give multiple parts, joined together in a single graph instance. Furthermore, we also explore the influence of natural structure and sequence-aware attention to our model. In our experimental evaluation of the large-scale benchmark datasets, Human3.6M, AMSS and 3DPW, MGCN outperforms the state-of-the-art in pose prediction.
Enhancing Large Language Models with Climate Resources
Mar 31, 2023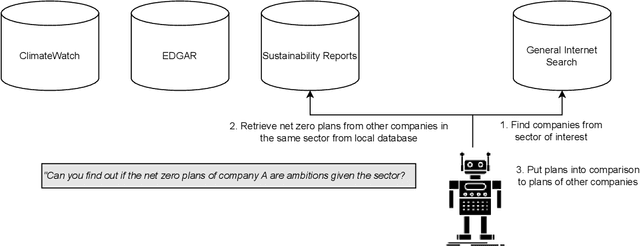
Large language models (LLMs) have significantly transformed the landscape of artificial intelligence by demonstrating their ability in generating human-like text across diverse topics. However, despite their impressive capabilities, LLMs lack recent information and often employ imprecise language, which can be detrimental in domains where accuracy is crucial, such as climate change. In this study, we make use of recent ideas to harness the potential of LLMs by viewing them as agents that access multiple sources, including databases containing recent and precise information about organizations, institutions, and companies. We demonstrate the effectiveness of our method through a prototype agent that retrieves emission data from ClimateWatch (https://www.climatewatchdata.org/) and leverages general Google search. By integrating these resources with LLMs, our approach overcomes the limitations associated with imprecise language and delivers more reliable and accurate information in the critical domain of climate change. This work paves the way for future advancements in LLMs and their application in domains where precision is of paramount importance.
Efficient View Synthesis and 3D-based Multi-Frame Denoising with Multiplane Feature Representations
Mar 31, 2023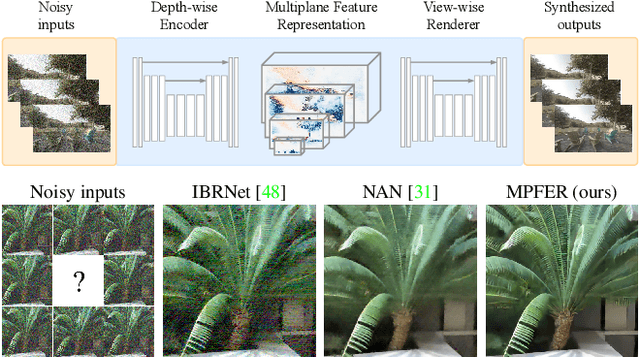
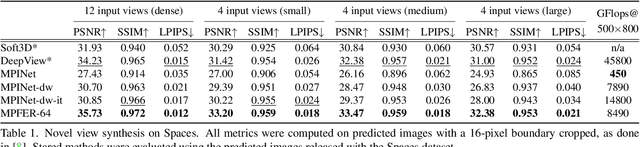
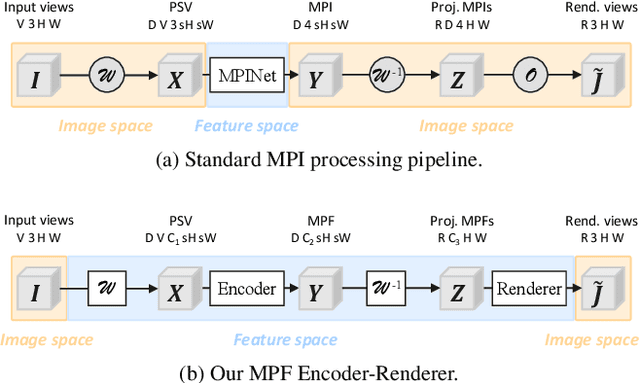
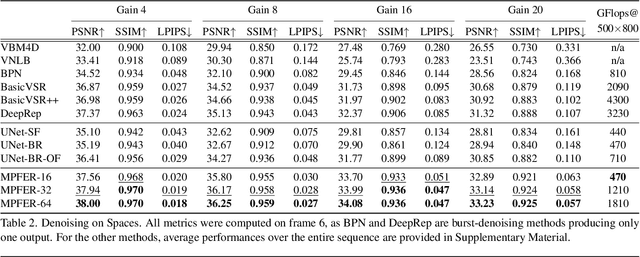
While current multi-frame restoration methods combine information from multiple input images using 2D alignment techniques, recent advances in novel view synthesis are paving the way for a new paradigm relying on volumetric scene representations. In this work, we introduce the first 3D-based multi-frame denoising method that significantly outperforms its 2D-based counterparts with lower computational requirements. Our method extends the multiplane image (MPI) framework for novel view synthesis by introducing a learnable encoder-renderer pair manipulating multiplane representations in feature space. The encoder fuses information across views and operates in a depth-wise manner while the renderer fuses information across depths and operates in a view-wise manner. The two modules are trained end-to-end and learn to separate depths in an unsupervised way, giving rise to Multiplane Feature (MPF) representations. Experiments on the Spaces and Real Forward-Facing datasets as well as on raw burst data validate our approach for view synthesis, multi-frame denoising, and view synthesis under noisy conditions.
Noise-Tolerance GPU-based Age Estimation Using ResNet-50
Apr 26, 2023
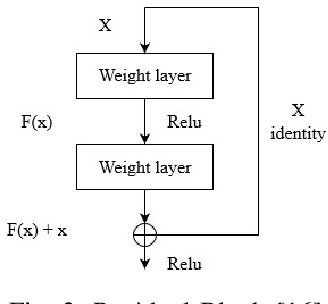
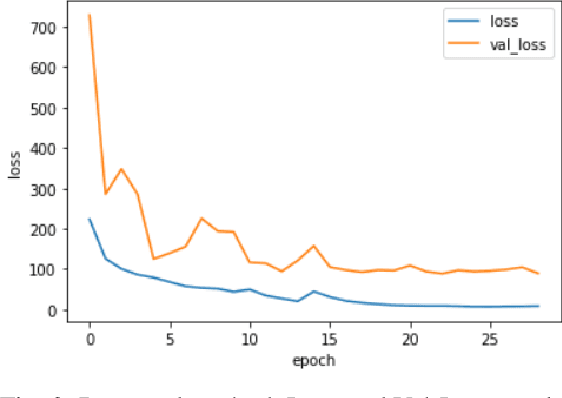
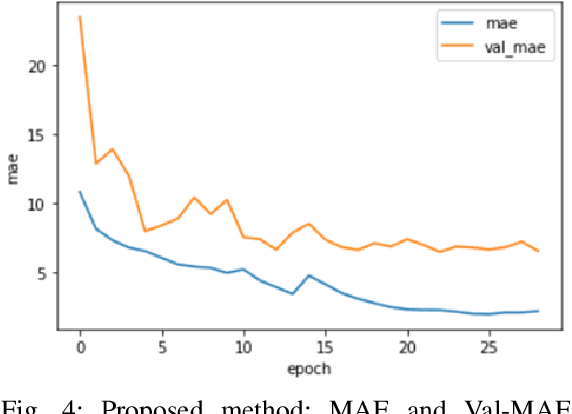
The human face contains important and understandable information such as personal identity, gender, age, and ethnicity. In recent years, a person's age has been studied as one of the important features of the face. The age estimation system consists of a combination of two modules, the presentation of the face image and the extraction of age characteristics, and then the detection of the exact age or age group based on these characteristics. So far, various algorithms have been presented for age estimation, each of which has advantages and disadvantages. In this work, we implemented a deep residual neural network on the UTKFace data set. We validated our implementation by comparing it with the state-of-the-art implementations of different age estimation algorithms and the results show 28.3% improvement in MAE as one of the critical error validation metrics compared to the recent works and also 71.39% MAE improvements compared to the implemented AlexNet. In the end, we show that the performance degradation of our implemented network is lower than 1.5% when injecting 15 dB noise to the input data (5 times more than the normal environmental noise) which justifies the noise tolerance of our proposed method.