 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Isotonic Mechanism for Exponential Family Estimation
Apr 26, 2023
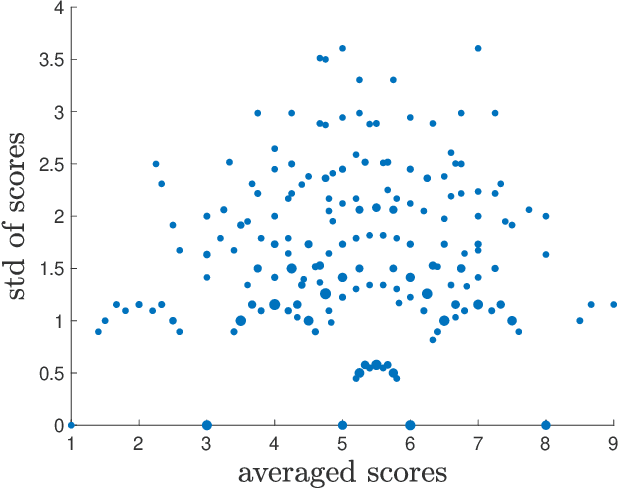
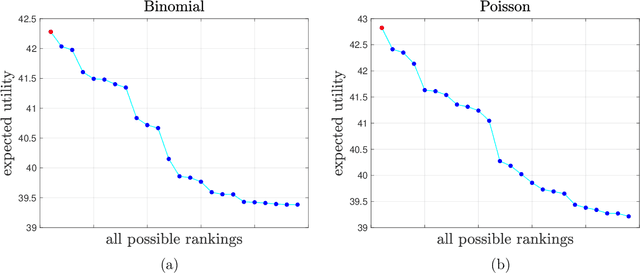
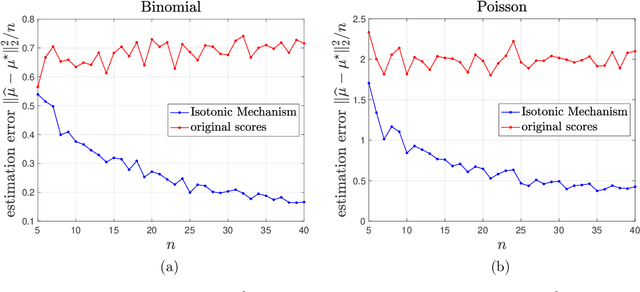
In 2023, the International Conference on Machine Learning (ICML) required authors with multiple submissions to rank their submissions based on perceived quality. In this paper, we aim to employ these author-specified rankings to enhance peer review in machine learning and artificial intelligence conferences by extending the Isotonic Mechanism (Su, 2021, 2022) to exponential family distributions. This mechanism generates adjusted scores closely align with the original scores while adhering to author-specified rankings. Despite its applicability to a broad spectrum of exponential family distributions, this mechanism's implementation does not necessitate knowledge of the specific distribution form. We demonstrate that an author is incentivized to provide accurate rankings when her utility takes the form of a convex additive function of the adjusted review scores. For a certain subclass of exponential family distributions, we prove that the author reports truthfully only if the question involves only pairwise comparisons between her submissions, thus indicating the optimality of ranking in truthful information elicitation. Lastly, we show that the adjusted scores improve dramatically the accuracy of the original scores and achieve nearly minimax optimality for estimating the true scores with statistical consistecy when true scores have bounded total variation.
Regularizing Contrastive Predictive Coding for Speech Applications
Apr 26, 2023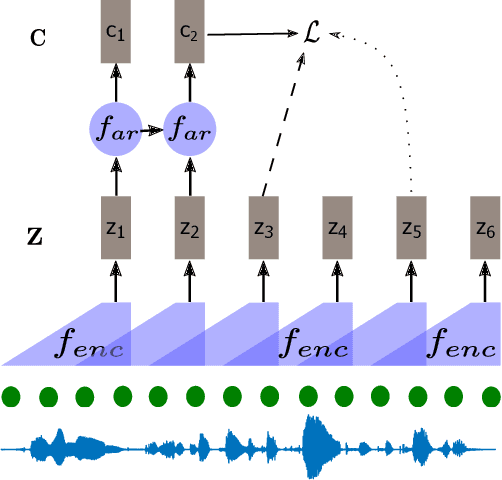
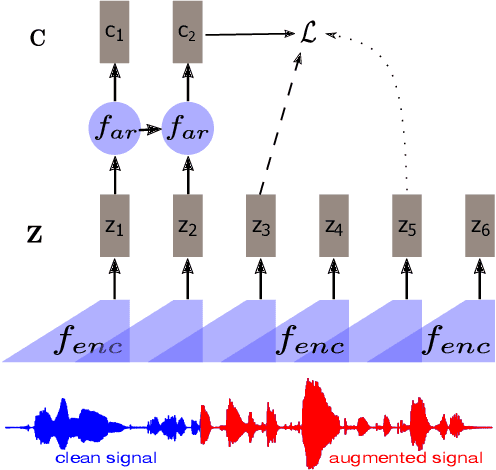
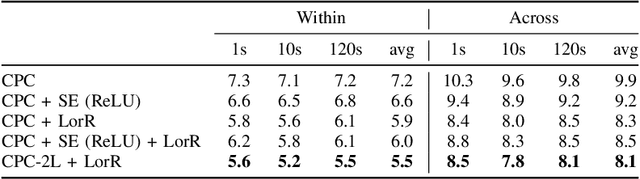
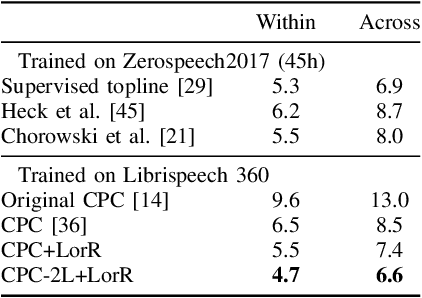
Self-supervised methods such as Contrastive predictive Coding (CPC) have greatly improved the quality of the unsupervised representations. These representations significantly reduce the amount of labeled data needed for downstream task performance, such as automatic speech recognition. CPC learns representations by learning to predict future frames given current frames. Based on the observation that the acoustic information, e.g., phones, changes slower than the feature extraction rate in CPC, we propose regularization techniques that impose slowness constraints on the features. Here we propose two regularization techniques: Self-expressing constraint and Left-or-Right regularization. We evaluate the proposed model on ABX and linear phone classification tasks, acoustic unit discovery, and automatic speech recognition. The regularized CPC trained on 100 hours of unlabeled data matches the performance of the baseline CPC trained on 360 hours of unlabeled data. We also show that our regularization techniques are complementary to data augmentation and can further boost the system's performance. In monolingual, cross-lingual, or multilingual settings, with/without data augmentation, regardless of the amount of data used for training, our regularized models outperformed the baseline CPC models on the ABX task.
Noise-Tolerance GPU-based Age Estimation Using ResNet-50
Apr 26, 2023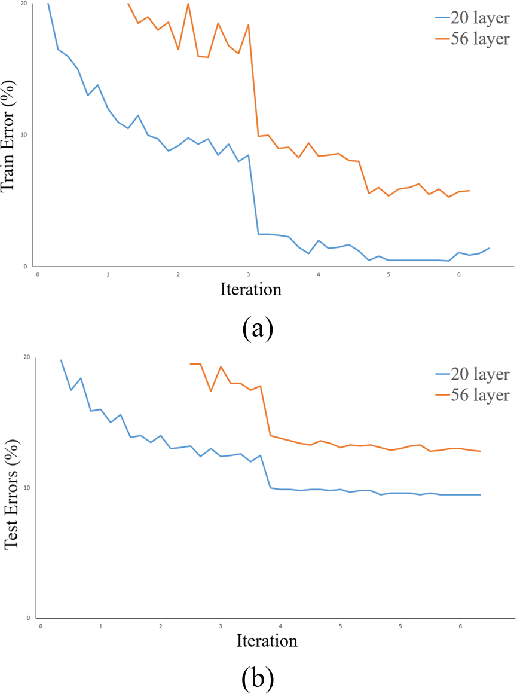
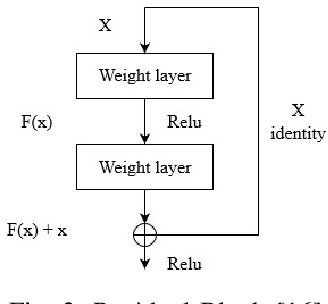
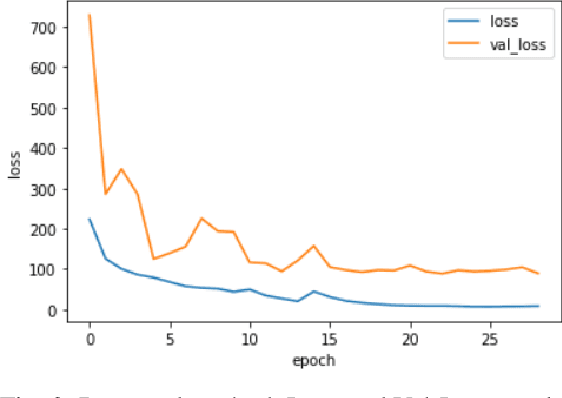
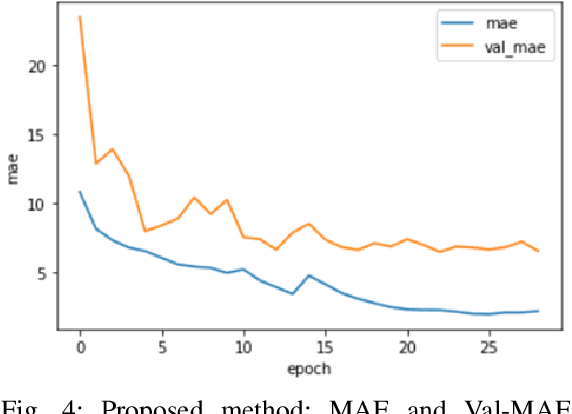
The human face contains important and understandable information such as personal identity, gender, age, and ethnicity. In recent years, a person's age has been studied as one of the important features of the face. The age estimation system consists of a combination of two modules, the presentation of the face image and the extraction of age characteristics, and then the detection of the exact age or age group based on these characteristics. So far, various algorithms have been presented for age estimation, each of which has advantages and disadvantages. In this work, we implemented a deep residual neural network on the UTKFace data set. We validated our implementation by comparing it with the state-of-the-art implementations of different age estimation algorithms and the results show 28.3% improvement in MAE as one of the critical error validation metrics compared to the recent works and also 71.39% MAE improvements compared to the implemented AlexNet. In the end, we show that the performance degradation of our implemented network is lower than 1.5% when injecting 15 dB noise to the input data (5 times more than the normal environmental noise) which justifies the noise tolerance of our proposed method.
PaTeCon: A Pattern-Based Temporal Constraint Mining Method for Conflict Detection on Knowledge Graphs
Apr 23, 2023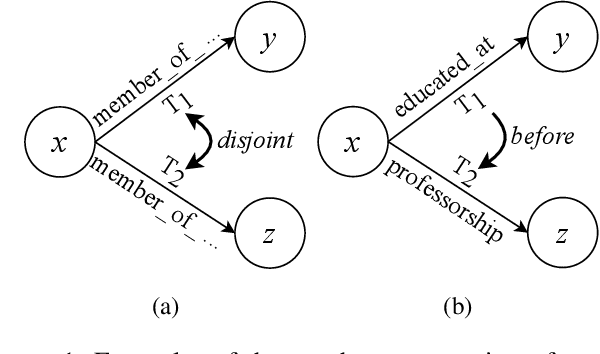

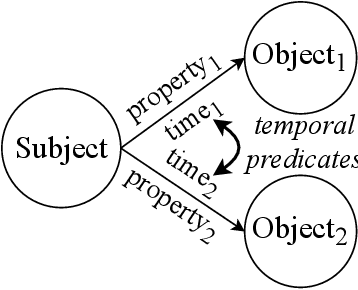

Temporal facts, the facts for characterizing events that hold in specific time periods, are attracting rising attention in the knowledge graph (KG) research communities. In terms of quality management, the introduction of time restrictions brings new challenges to maintaining the temporal consistency of KGs and detecting potential temporal conflicts. Previous studies rely on manually enumerated temporal constraints to detect conflicts, which are labor-intensive and may have granularity issues. We start from the common pattern of temporal facts and constraints and propose a pattern-based temporal constraint mining method, PaTeCon. PaTeCon uses automatically determined graph patterns and their relevant statistical information over the given KG instead of human experts to generate time constraints. Specifically, PaTeCon dynamically attaches class restriction to candidate constraints according to their measuring scores.We evaluate PaTeCon on two large-scale datasets based on Wikidata and Freebase respectively. The experimental results show that pattern-based automatic constraint mining is powerful in generating valuable temporal constraints.
TransFlow: Transformer as Flow Learner
Apr 23, 2023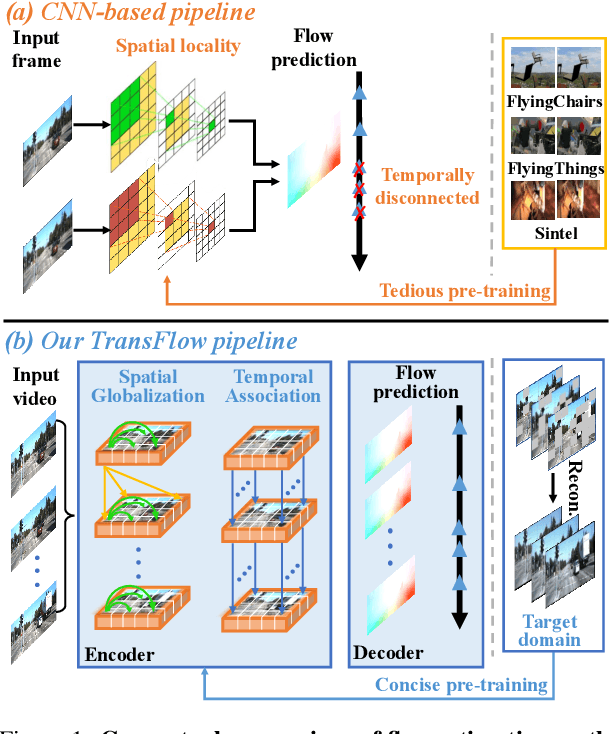
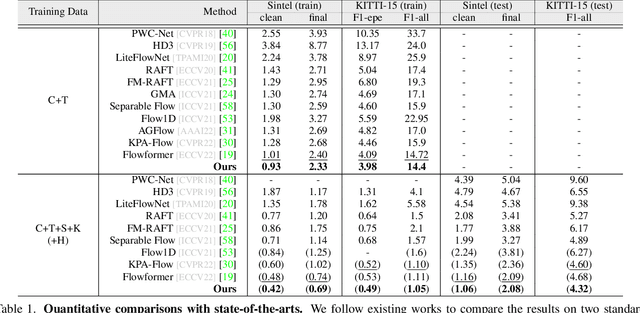
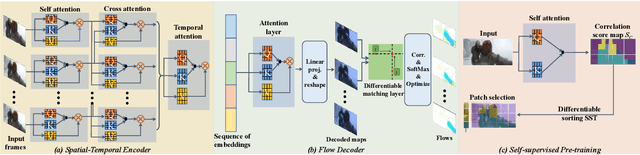
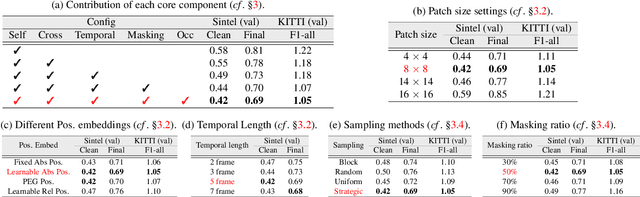
Optical flow is an indispensable building block for various important computer vision tasks, including motion estimation, object tracking, and disparity measurement. In this work, we propose TransFlow, a pure transformer architecture for optical flow estimation. Compared to dominant CNN-based methods, TransFlow demonstrates three advantages. First, it provides more accurate correlation and trustworthy matching in flow estimation by utilizing spatial self-attention and cross-attention mechanisms between adjacent frames to effectively capture global dependencies; Second, it recovers more compromised information (e.g., occlusion and motion blur) in flow estimation through long-range temporal association in dynamic scenes; Third, it enables a concise self-learning paradigm and effectively eliminate the complex and laborious multi-stage pre-training procedures. We achieve the state-of-the-art results on the Sintel, KITTI-15, as well as several downstream tasks, including video object detection, interpolation and stabilization. For its efficacy, we hope TransFlow could serve as a flexible baseline for optical flow estimation.
Epistemic considerations when AI answers questions for us
Apr 23, 2023
In this position paper, we argue that careless reliance on AI to answer our questions and to judge our output is a violation of Grice's Maxim of Quality as well as a violation of Lemoine's legal Maxim of Innocence, performing an (unwarranted) authority fallacy, and while lacking assessment signals, committing Type II errors that result from fallacies of the inverse. What is missing in the focus on output and results of AI-generated and AI-evaluated content is, apart from paying proper tribute, the demand to follow a person's thought process (or a machine's decision processes). In deliberately avoiding Neural Networks that cannot explain how they come to their conclusions, we introduce logic-symbolic inference to handle any possible epistemics any human or artificial information processor may have. Our system can deal with various belief systems and shows how decisions may differ for what is true, false, realistic, unrealistic, literal, or anomalous. As is, stota AI such as ChatGPT is a sorcerer's apprentice.
A tutorial on the Bayesian statistical approach to inverse problems
Apr 15, 2023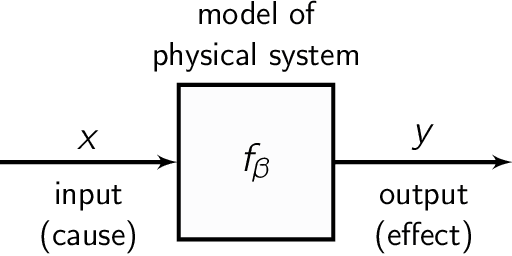
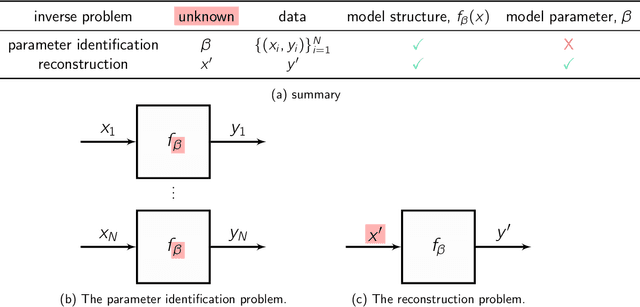

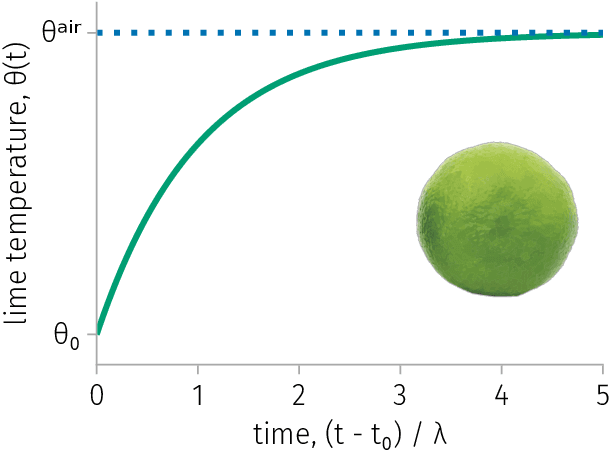
Inverse problems are ubiquitous in the sciences and engineering. Two categories of inverse problems concerning a physical system are (1) estimate parameters in a model of the system from observed input-output pairs and (2) given a model of the system, reconstruct the input to it that caused some observed output. Applied inverse problems are challenging because a solution may (i) not exist, (ii) not be unique, or (iii) be sensitive to measurement noise contaminating the data. Bayesian statistical inversion (BSI) is an approach to tackle ill-posed and/or ill-conditioned inverse problems. Advantageously, BSI provides a "solution" that (i) quantifies uncertainty by assigning a probability to each possible value of the unknown parameter/input and (ii) incorporates prior information and beliefs about the parameter/input. Herein, we provide a tutorial of BSI for inverse problems, by way of illustrative examples dealing with heat transfer from ambient air to a cold lime fruit. First, we use BSI to infer a parameter in a dynamic model of the lime temperature from measurements of the lime temperature over time. Second, we use BSI to reconstruct the initial condition of the lime from a measurement of its temperature later in time. We demonstrate the incorporation of prior information, visualize the posterior distributions of the parameter/initial condition, and show posterior samples of lime temperature trajectories from the model. Our tutorial aims to reach a wide range of scientists and engineers.
Conditioning Covert Geo-Location (CGL) Detection on Semantic Class Information
Nov 27, 2022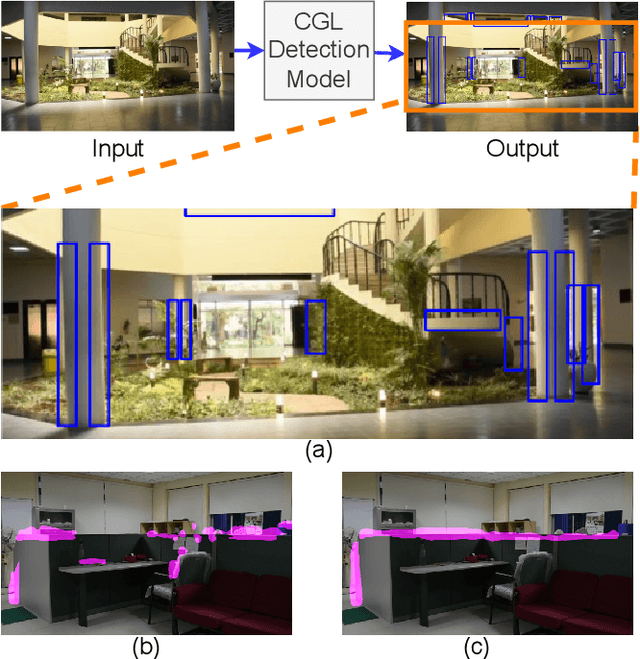
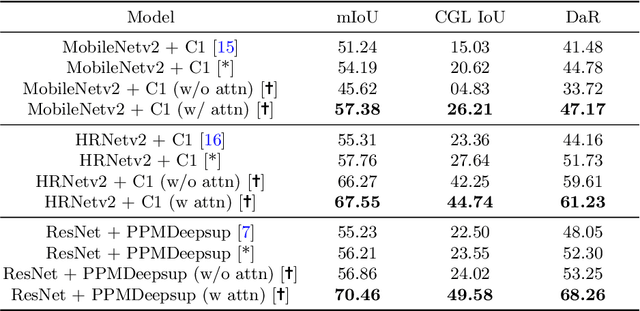
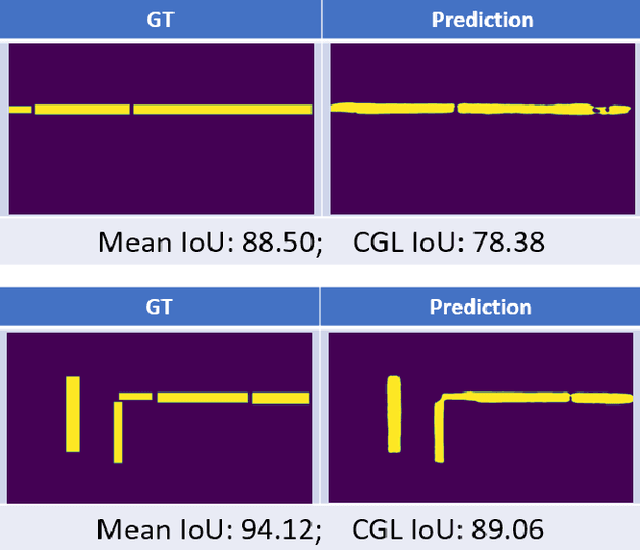
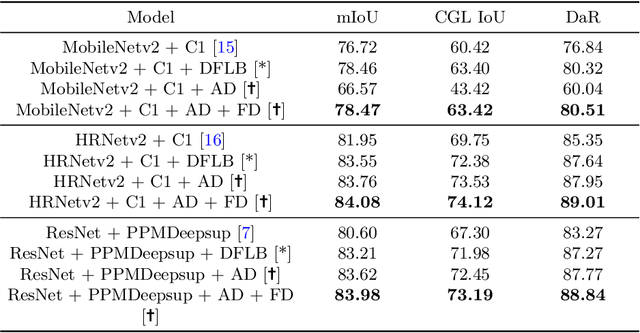
The primary goal of artificial intelligence is to mimic humans. Therefore, to advance toward this goal, the AI community attempts to imitate qualities/skills possessed by humans and imbibes them into machines with the help of datasets/tasks. Earlier, many tasks which require knowledge about the objects present in an image are satisfactorily solved by vision models. Recently, with the aim to incorporate knowledge about non-object image regions (hideouts, turns, and other obscured regions), a task for identification of potential hideouts termed Covert Geo-Location (CGL) detection was proposed by Saha et al. It involves identification of image regions which have the potential to either cause an imminent threat or appear as target zones to be accessed for further investigation to identify any occluded objects. Only certain occluding items belonging to certain semantic classes can give rise to CGLs. This fact was overlooked by Saha et al. and no attempts were made to utilize semantic class information, which is crucial for CGL detection. In this paper, we propose a multitask-learning-based approach to achieve 2 goals - i) extraction of features having semantic class information; ii) robust training of the common encoder, exploiting large standard annotated datasets as training set for the auxiliary task (semantic segmentation). To explicitly incorporate class information in the features extracted by the encoder, we have further employed attention mechanism in a novel manner. We have also proposed a better evaluation metric for CGL detection that gives more weightage to recognition rather than precise localization. Experimental evaluations performed on the CGL dataset, demonstrate a significant increase in performance of about 3% to 14% mIoU and 3% to 16% DaR on split 1, and 1% mIoU and 1% to 2% DaR on split 2 over SOTA, serving as a testimony to the superiority of our approach.
Distributed Information-based Source Seeking
Sep 20, 2022

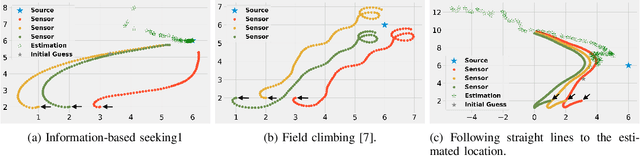
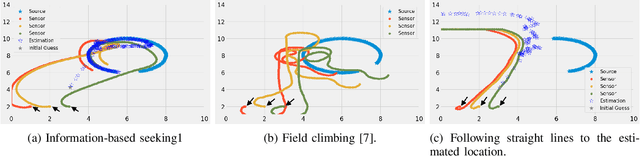
In this paper, we design an information-based multi-robot source seeking algorithm where a group of mobile sensors localizes and moves close to a single source using only local range-based measurements. In the algorithm, the mobile sensors perform source identification/localization to estimate the source location; meanwhile, they move to new locations to maximize the Fisher information about the source contained in the sensor measurements. In doing so, they improve the source location estimate and move closer to the source. Our algorithm is superior in convergence speed compared with traditional field climbing algorithms, is flexible in the measurement model and the choice of information metric, and is robust to measurement model errors. Moreover, we provide a fully distributed version of our algorithm, where each sensor decides its own actions and only shares information with its neighbors through a sparse communication network. We perform intensive simulation experiments to test our algorithms on large-scale systems and physical experiments on small ground vehicles with light sensors, demonstrating success in seeking a light source.
Network Visualization of ChatGPT Research: a study based on term and keyword co-occurrence network analysis
Apr 01, 2023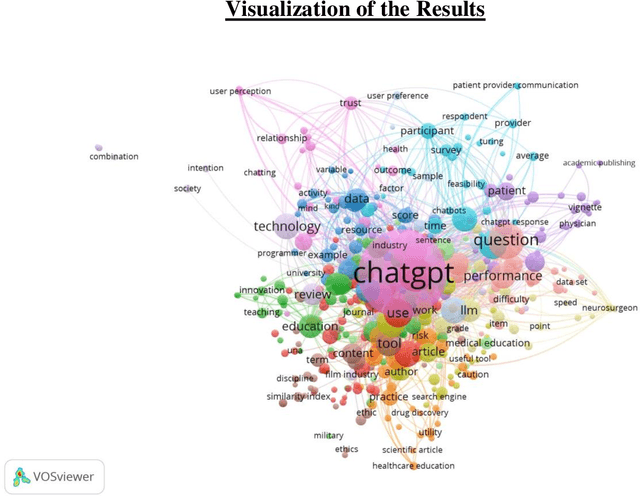
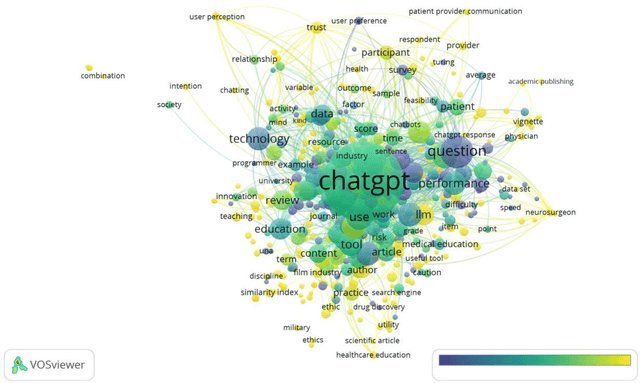
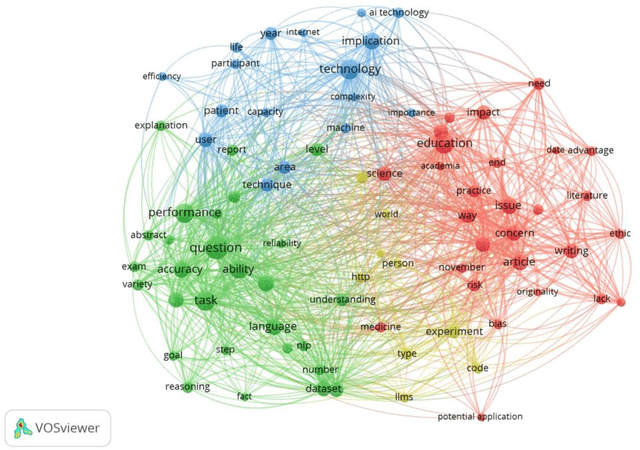
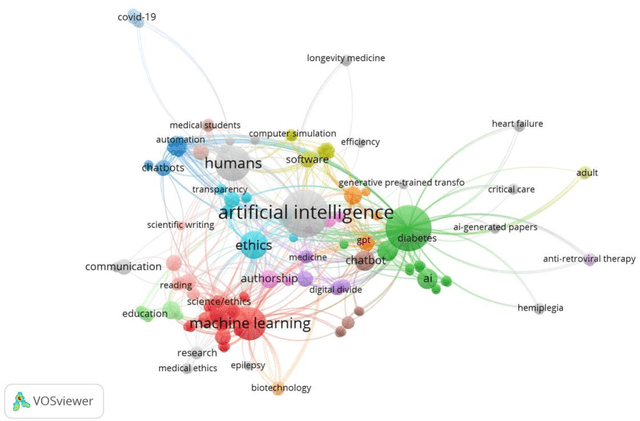
The main objective of this paper is to identify the major research areas of ChatGPT through term and keyword co-occurrence network mapping techniques. For conducting the present study, total of 577 publications were retrieved from the Lens database for the network visualization. The findings of the study showed that chatgpt occurrence in maximum number of times followed by its related terms such as artificial intelligence, large language model, gpt, study etc. This study will be helpful to library and information science as well as computer or information technology professionals.