 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Local and Global Contextual Features Fusion for Pedestrian Intention Prediction
May 01, 2023
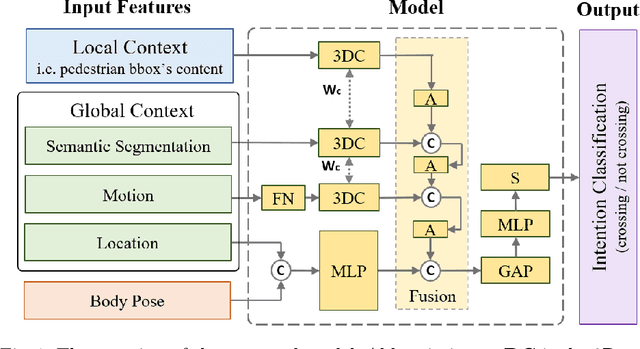

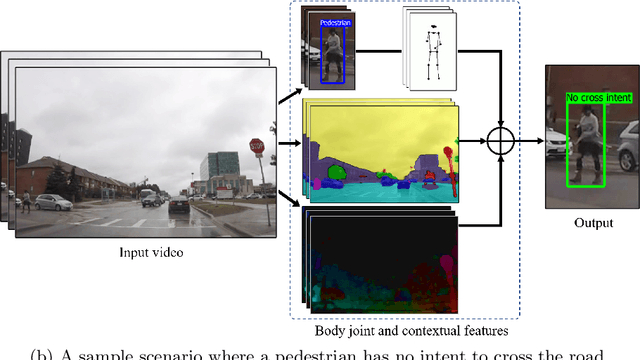
Autonomous vehicles (AVs) are becoming an indispensable part of future transportation. However, safety challenges and lack of reliability limit their real-world deployment. Towards boosting the appearance of AVs on the roads, the interaction of AVs with pedestrians including "prediction of the pedestrian crossing intention" deserves extensive research. This is a highly challenging task as involves multiple non-linear parameters. In this direction, we extract and analyse spatio-temporal visual features of both pedestrian and traffic contexts. The pedestrian features include body pose and local context features that represent the pedestrian's behaviour. Additionally, to understand the global context, we utilise location, motion, and environmental information using scene parsing technology that represents the pedestrian's surroundings, and may affect the pedestrian's intention. Finally, these multi-modality features are intelligently fused for effective intention prediction learning. The experimental results of the proposed model on the JAAD dataset show a superior result on the combined AUC and F1-score compared to the state-of-the-art.
Generative Recommendation: Towards Next-generation Recommender Paradigm
Apr 07, 2023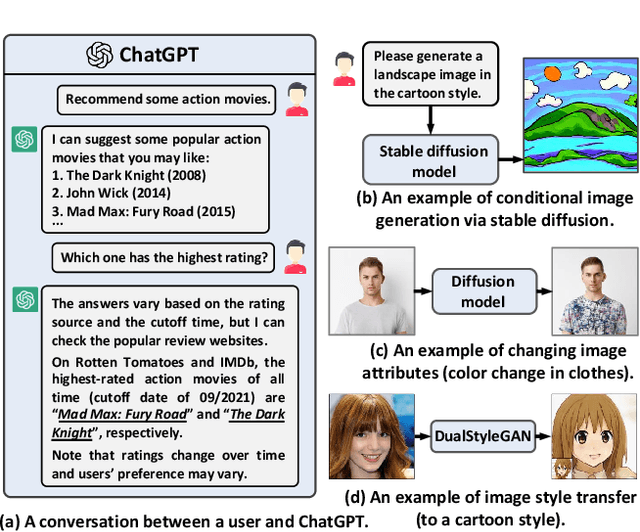
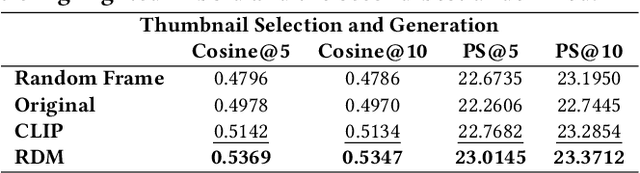
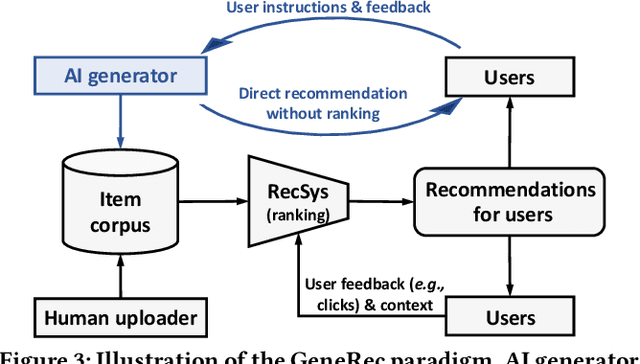
Recommender systems typically retrieve items from an item corpus for personalized recommendations. However, such a retrieval-based recommender paradigm faces two limitations: 1) the human-generated items in the corpus might fail to satisfy the users' diverse information needs, and 2) users usually adjust the recommendations via passive and inefficient feedback such as clicks. Nowadays, AI-Generated Content (AIGC) has revealed significant success across various domains, offering the potential to overcome these limitations: 1) generative AI can produce personalized items to meet users' specific information needs, and 2) the newly emerged ChatGPT significantly facilitates users to express information needs more precisely via natural language instructions. In this light, the boom of AIGC points the way towards the next-generation recommender paradigm with two new objectives: 1) generating personalized content through generative AI, and 2) integrating user instructions to guide content generation. To this end, we propose a novel Generative Recommender paradigm named GeneRec, which adopts an AI generator to personalize content generation and leverages user instructions to acquire users' information needs. Specifically, we pre-process users' instructions and traditional feedback (e.g., clicks) via an instructor to output the generation guidance. Given the guidance, we instantiate the AI generator through an AI editor and an AI creator to repurpose existing items and create new items, respectively. Eventually, GeneRec can perform content retrieval, repurposing, and creation to meet users' information needs. Besides, to ensure the trustworthiness of the generated items, we emphasize various fidelity checks such as authenticity and legality checks. Lastly, we study the feasibility of implementing the AI editor and AI creator on micro-video generation, showing promising results.
F-RDW: Redirected Walking with Forecasting Future Position
Apr 07, 2023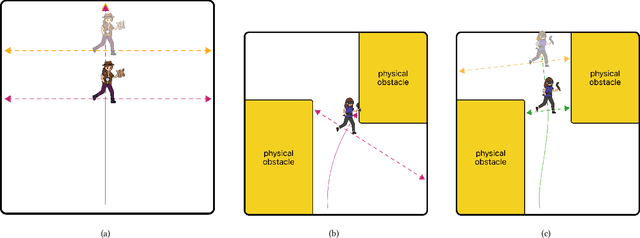

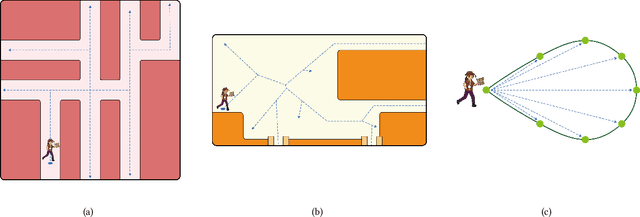
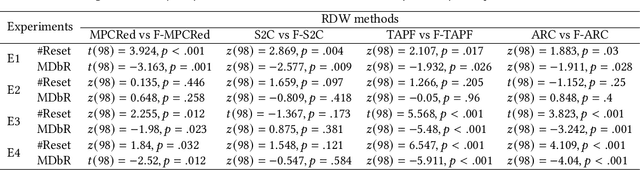
In order to serve better VR experiences to users, existing predictive methods of Redirected Walking (RDW) exploit future information to reduce the number of reset occurrences. However, such methods often impose a precondition during deployment, either in the virtual environment's layout or the user's walking direction, which constrains its universal applications. To tackle this challenge, we propose a novel mechanism F-RDW that is twofold: (1) forecasts the future information of a user in the virtual space without any assumptions, and (2) fuse this information while maneuvering existing RDW methods. The backbone of the first step is an LSTM-based model that ingests the user's spatial and eye-tracking data to predict the user's future position in the virtual space, and the following step feeds those predicted values into existing RDW methods (such as MPCRed, S2C, TAPF, and ARC) while respecting their internal mechanism in applicable ways.The results of our simulation test and user study demonstrate the significance of future information when using RDW in small physical spaces or complex environments. We prove that the proposed mechanism significantly reduces the number of resets and increases the traveled distance between resets, hence augmenting the redirection performance of all RDW methods explored in this work.
Class-aware Information for Logit-based Knowledge Distillation
Nov 27, 2022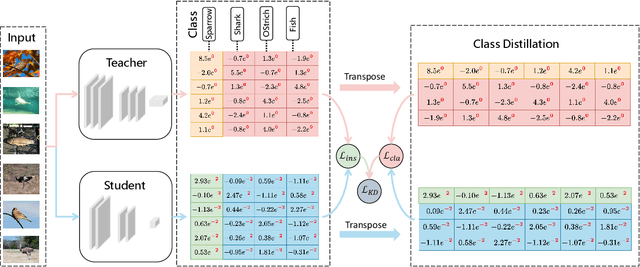
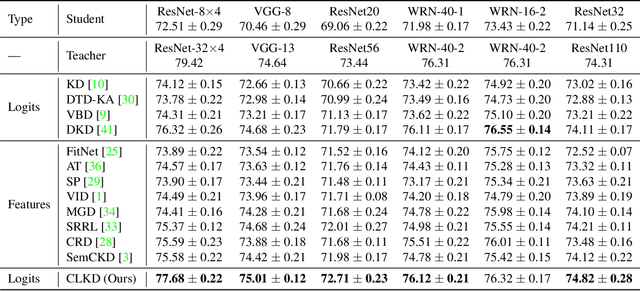
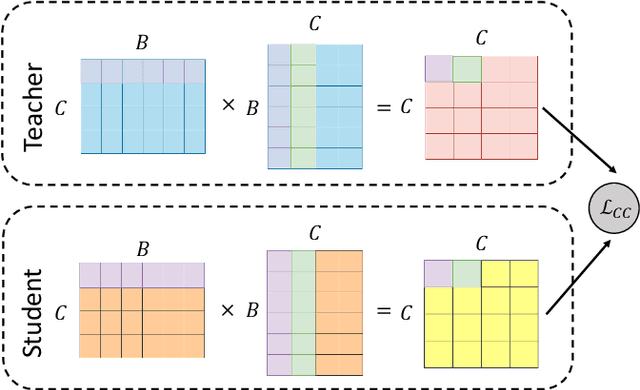
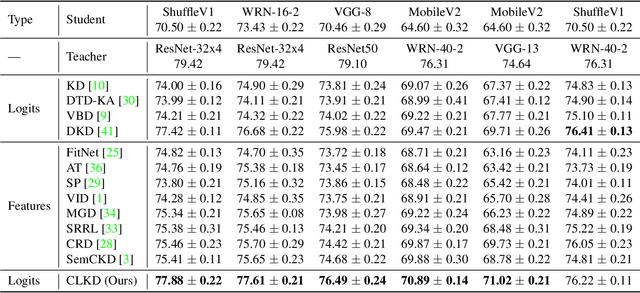
Knowledge distillation aims to transfer knowledge to the student model by utilizing the predictions/features of the teacher model, and feature-based distillation has recently shown its superiority over logit-based distillation. However, due to the cumbersome computation and storage of extra feature transformation, the training overhead of feature-based methods is much higher than that of logit-based distillation. In this work, we revisit the logit-based knowledge distillation, and observe that the existing logit-based distillation methods treat the prediction logits only in the instance level, while many other useful semantic information is overlooked. To address this issue, we propose a Class-aware Logit Knowledge Distillation (CLKD) method, that extents the logit distillation in both instance-level and class-level. CLKD enables the student model mimic higher semantic information from the teacher model, hence improving the distillation performance. We further introduce a novel loss called Class Correlation Loss to force the student learn the inherent class-level correlation of the teacher. Empirical comparisons demonstrate the superiority of the proposed method over several prevailing logit-based methods and feature-based methods, in which CLKD achieves compelling results on various visual classification tasks and outperforms the state-of-the-art baselines.
Differentiate ChatGPT-generated and Human-written Medical Texts
Apr 23, 2023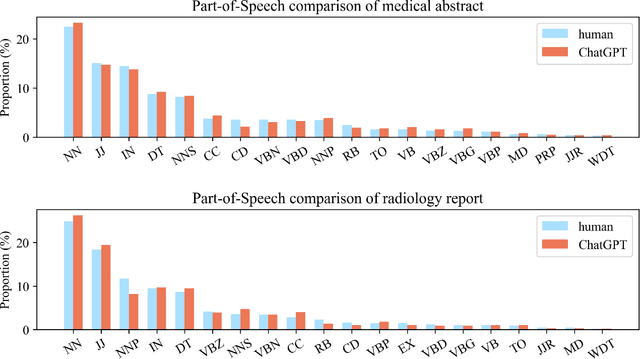

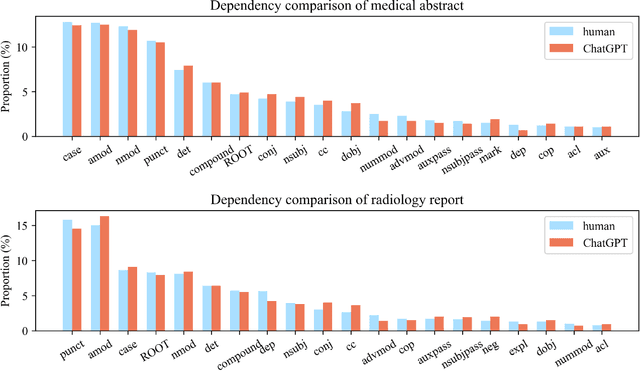
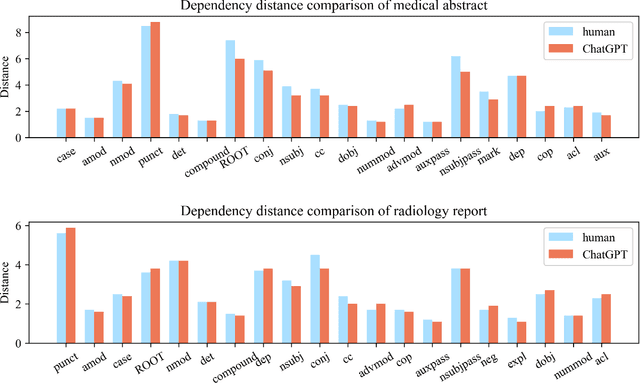
Background: Large language models such as ChatGPT are capable of generating grammatically perfect and human-like text content, and a large number of ChatGPT-generated texts have appeared on the Internet. However, medical texts such as clinical notes and diagnoses require rigorous validation, and erroneous medical content generated by ChatGPT could potentially lead to disinformation that poses significant harm to healthcare and the general public. Objective: This research is among the first studies on responsible and ethical AIGC (Artificial Intelligence Generated Content) in medicine. We focus on analyzing the differences between medical texts written by human experts and generated by ChatGPT, and designing machine learning workflows to effectively detect and differentiate medical texts generated by ChatGPT. Methods: We first construct a suite of datasets containing medical texts written by human experts and generated by ChatGPT. In the next step, we analyze the linguistic features of these two types of content and uncover differences in vocabulary, part-of-speech, dependency, sentiment, perplexity, etc. Finally, we design and implement machine learning methods to detect medical text generated by ChatGPT. Results: Medical texts written by humans are more concrete, more diverse, and typically contain more useful information, while medical texts generated by ChatGPT pay more attention to fluency and logic, and usually express general terminologies rather than effective information specific to the context of the problem. A BERT-based model can effectively detect medical texts generated by ChatGPT, and the F1 exceeds 95%.
Investigating Imbalances Between SAR and Optical Utilization for Multi-Modal Urban Mapping
Apr 11, 2023
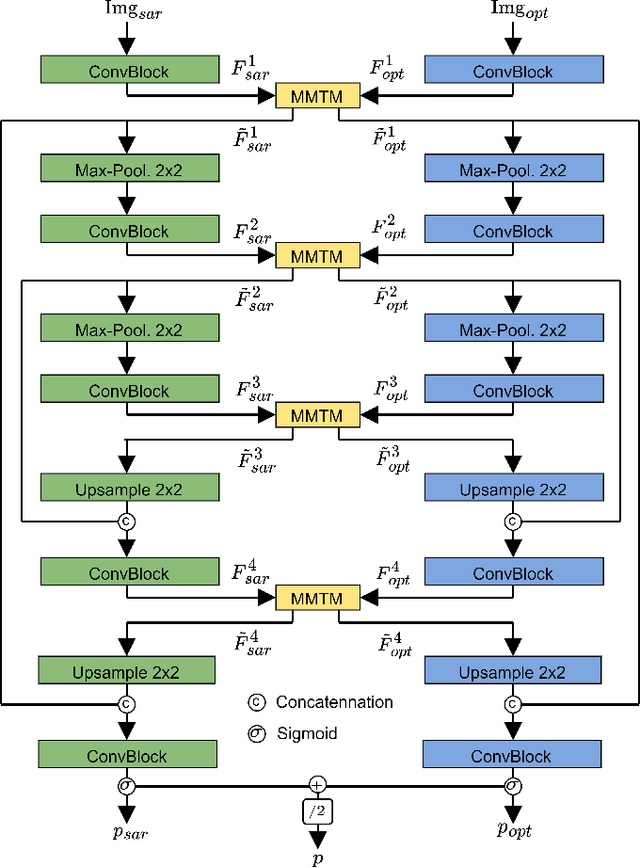
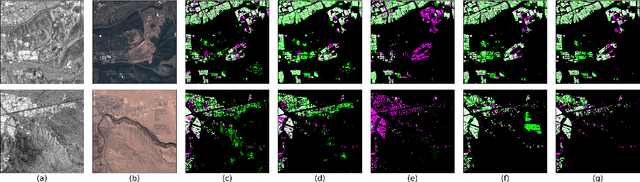
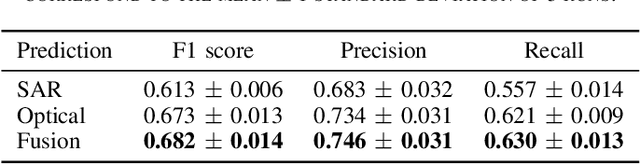
Accurate urban maps provide essential information to support sustainable urban development. Recent urban mapping methods use multi-modal deep neural networks to fuse Synthetic Aperture Radar (SAR) and optical data. However, multi-modal networks may rely on just one modality due to the greedy nature of learning. In turn, the imbalanced utilization of modalities can negatively affect the generalization ability of a network. In this paper, we investigate the utilization of SAR and optical data for urban mapping. To that end, a dual-branch network architecture using intermediate fusion modules to share information between the uni-modal branches is utilized. A cut-off mechanism in the fusion modules enables the stopping of information flow between the branches, which is used to estimate the network's dependence on SAR and optical data. While our experiments on the SEN12 Global Urban Mapping dataset show that good performance can be achieved with conventional SAR-optical data fusion (F1 score = 0.682 $\pm$ 0.014), we also observed a clear under-utilization of optical data. Therefore, future work is required to investigate whether a more balanced utilization of SAR and optical data can lead to performance improvements.
RGB-T Tracking Based on Mixed Attention
Apr 11, 2023
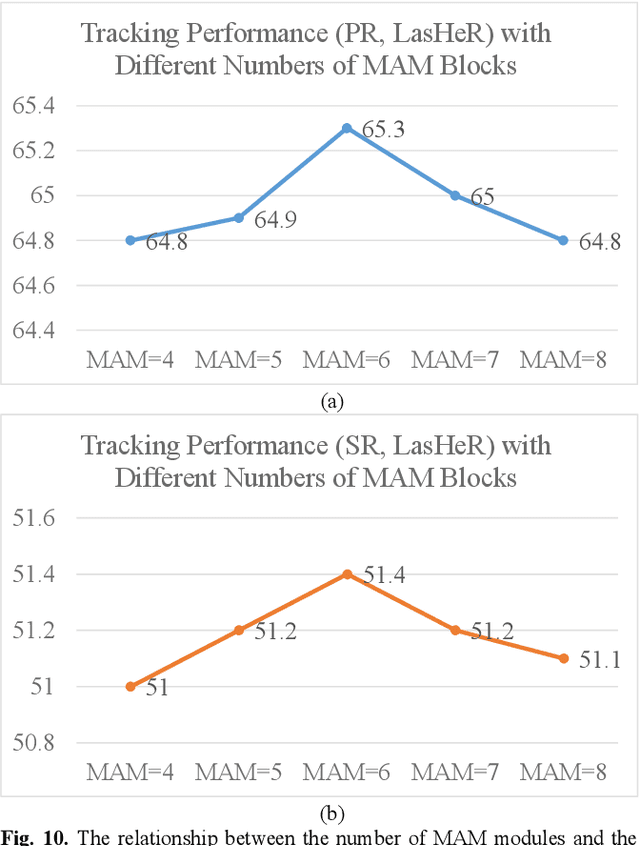
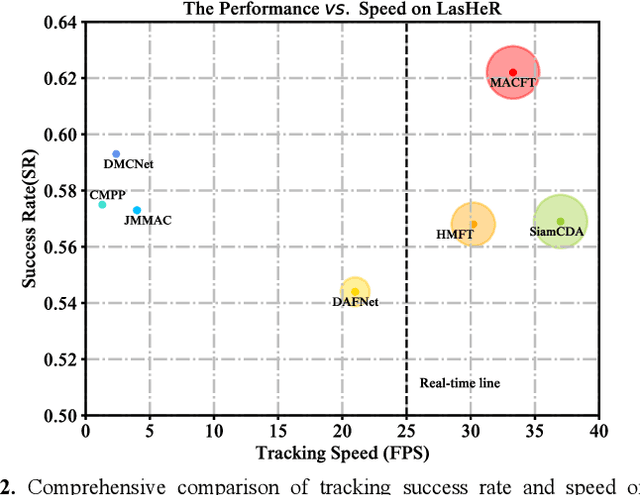
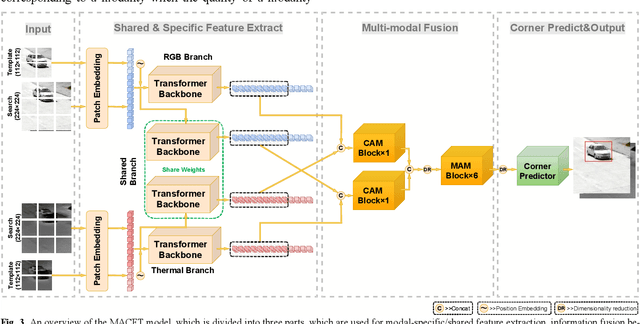
RGB-T tracking involves the use of images from both visible and thermal modalities. The primary objective is to adaptively leverage the relatively dominant modality in varying conditions to achieve more robust tracking compared to single-modality tracking. An RGB-T tracker based on mixed attention mechanism to achieve complementary fusion of modalities (referred to as MACFT) is proposed in this paper. In the feature extraction stage, we utilize different transformer backbone branches to extract specific and shared information from different modalities. By performing mixed attention operations in the backbone to enable information interaction and self-enhancement between the template and search images, it constructs a robust feature representation that better understands the high-level semantic features of the target. Then, in the feature fusion stage, a modality-adaptive fusion is achieved through a mixed attention-based modality fusion network, which suppresses the low-quality modality noise while enhancing the information of the dominant modality. Evaluation on multiple RGB-T public datasets demonstrates that our proposed tracker outperforms other RGB-T trackers on general evaluation metrics while also being able to adapt to longterm tracking scenarios.
KGS: Causal Discovery Using Knowledge-guided Greedy Equivalence Search
Apr 11, 2023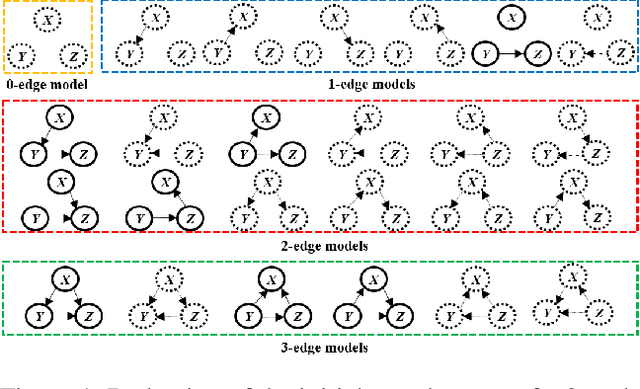
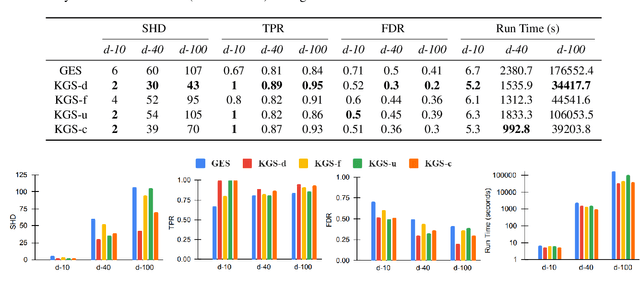
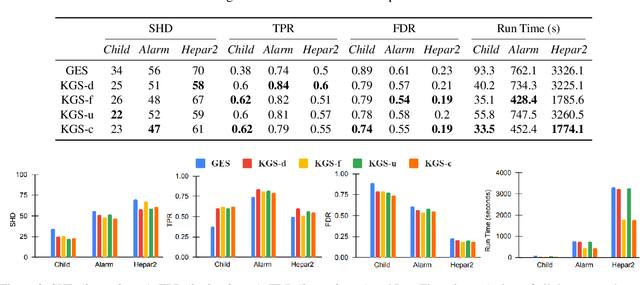
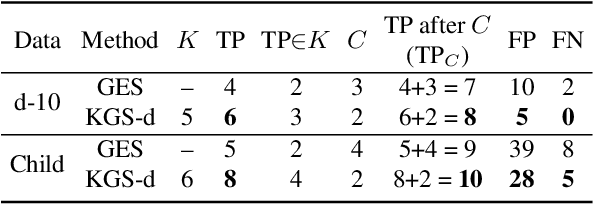
Learning causal relationships solely from observational data provides insufficient information about the underlying causal mechanism and the search space of possible causal graphs. As a result, often the search space can grow exponentially for approaches such as Greedy Equivalence Search (GES) that uses a score-based approach to search the space of equivalence classes of graphs. Prior causal information such as the presence or absence of a causal edge can be leveraged to guide the discovery process towards a more restricted and accurate search space. In this study, we present KGS, a knowledge-guided greedy score-based causal discovery approach that uses observational data and structural priors (causal edges) as constraints to learn the causal graph. KGS is a novel application of knowledge constraints that can leverage any of the following prior edge information between any two variables: the presence of a directed edge, the absence of an edge, and the presence of an undirected edge. We extensively evaluate KGS across multiple settings in both synthetic and benchmark real-world datasets. Our experimental results demonstrate that structural priors of any type and amount are helpful and guide the search process towards an improved performance and early convergence.
Investigating Vision Foundational Models for Tactile Representation Learning
Apr 30, 2023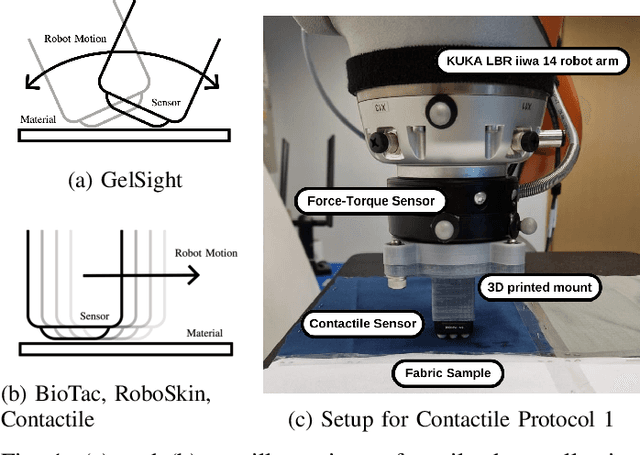
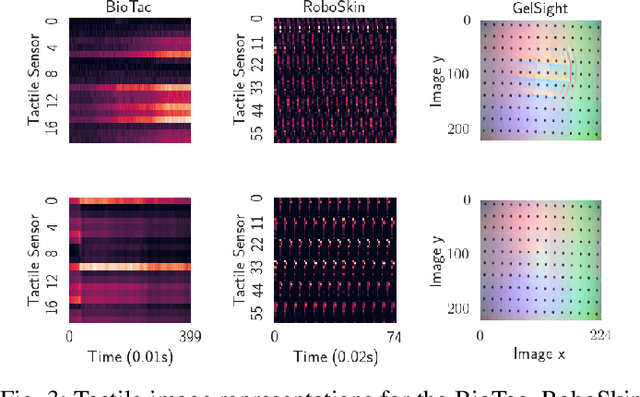
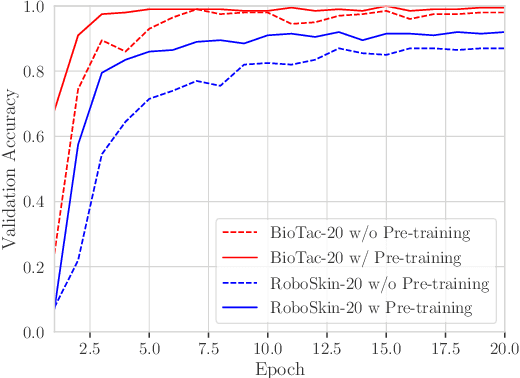
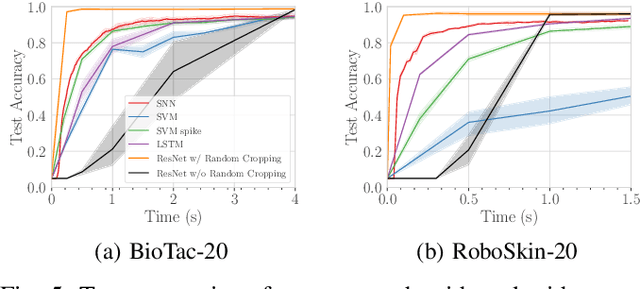
Tactile representation learning (TRL) equips robots with the ability to leverage touch information, boosting performance in tasks such as environment perception and object manipulation. However, the heterogeneity of tactile sensors results in many sensor- and task-specific learning approaches. This limits the efficacy of existing tactile datasets, and the subsequent generalisability of any learning outcome. In this work, we investigate the applicability of vision foundational models to sensor-agnostic TRL, via a simple yet effective transformation technique to feed the heterogeneous sensor readouts into the model. Our approach recasts TRL as a computer vision (CV) problem, which permits the application of various CV techniques for tackling TRL-specific challenges. We evaluate our approach on multiple benchmark tasks, using datasets collected from four different tactile sensors. Empirically, we demonstrate significant improvements in task performance, model robustness, as well as cross-sensor and cross-task knowledge transferability with limited data requirements.
Graph Convolutional Networks based on Manifold Learning for Semi-Supervised Image Classification
Apr 24, 2023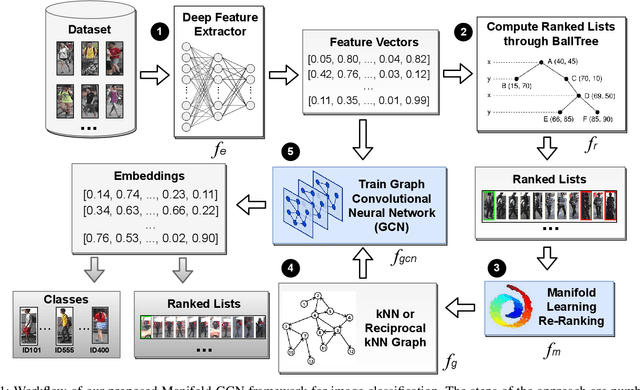
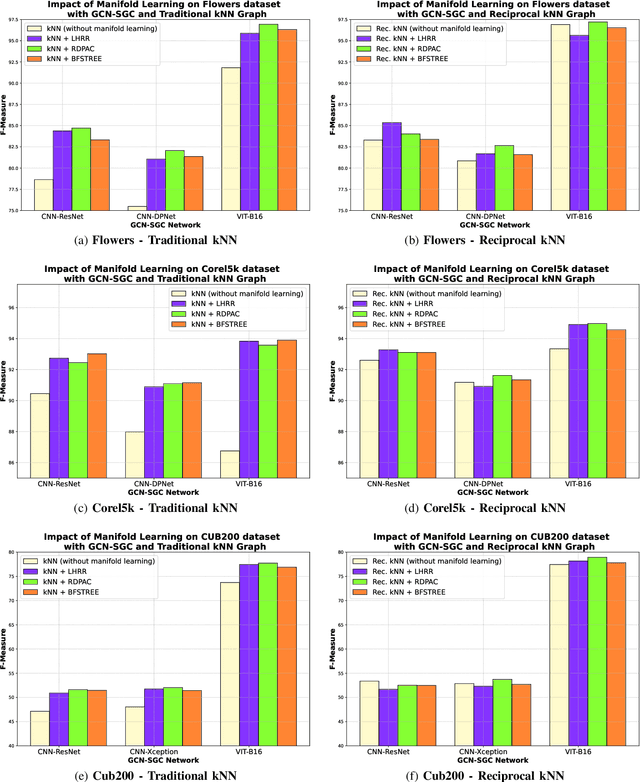
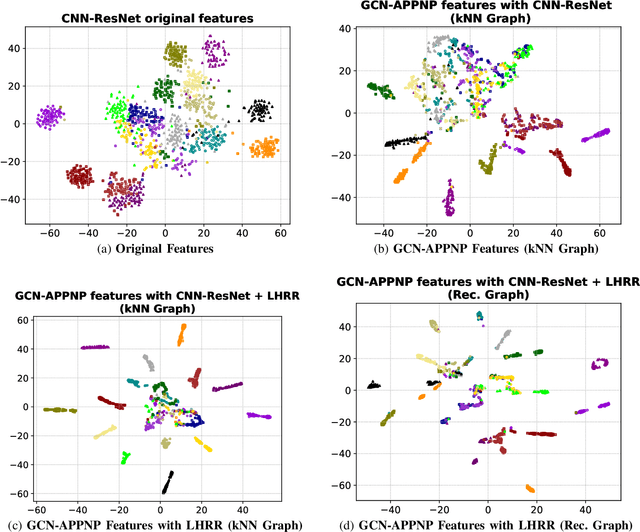
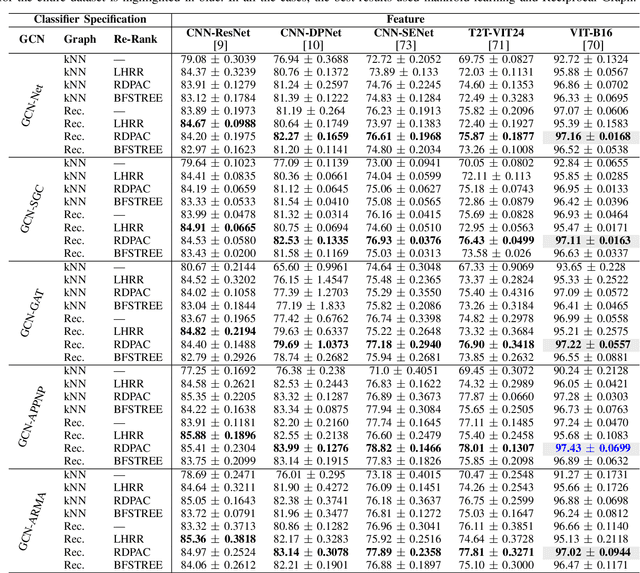
Due to a huge volume of information in many domains, the need for classification methods is imperious. In spite of many advances, most of the approaches require a large amount of labeled data, which is often not available, due to costs and difficulties of manual labeling processes. In this scenario, unsupervised and semi-supervised approaches have been gaining increasing attention. The GCNs (Graph Convolutional Neural Networks) represent a promising solution since they encode the neighborhood information and have achieved state-of-the-art results on scenarios with limited labeled data. However, since GCNs require graph-structured data, their use for semi-supervised image classification is still scarce in the literature. In this work, we propose a novel approach, the Manifold-GCN, based on GCNs for semi-supervised image classification. The main hypothesis of this paper is that the use of manifold learning to model the graph structure can further improve the GCN classification. To the best of our knowledge, this is the first framework that allows the combination of GCNs with different types of manifold learning approaches for image classification. All manifold learning algorithms employed are completely unsupervised, which is especially useful for scenarios where the availability of labeled data is a concern. A broad experimental evaluation was conducted considering 5 GCN models, 3 manifold learning approaches, 3 image datasets, and 5 deep features. The results reveal that our approach presents better accuracy than traditional and recent state-of-the-art methods with very efficient run times for both training and testing.