 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Regularizing Self-training for Unsupervised Domain Adaptation via Structural Constraints
Apr 29, 2023

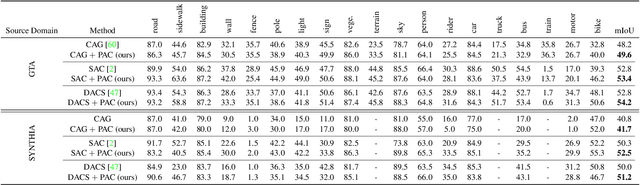
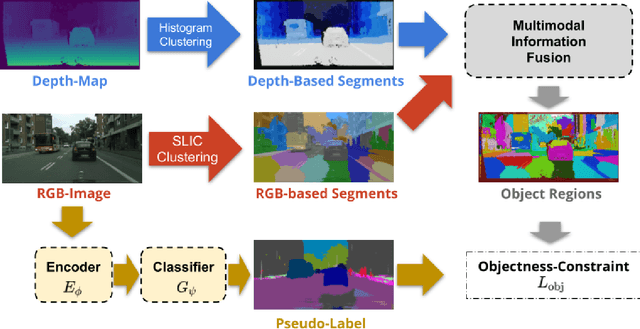
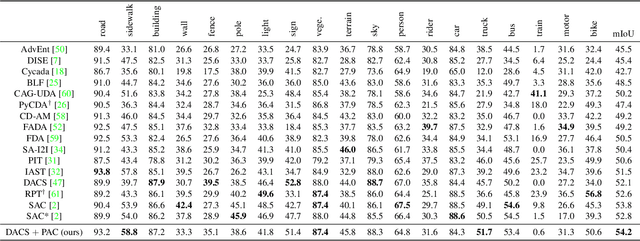
Self-training based on pseudo-labels has emerged as a dominant approach for addressing conditional distribution shifts in unsupervised domain adaptation (UDA) for semantic segmentation problems. A notable drawback, however, is that this family of approaches is susceptible to erroneous pseudo labels that arise from confirmation biases in the source domain and that manifest as nuisance factors in the target domain. A possible source for this mismatch is the reliance on only photometric cues provided by RGB image inputs, which may ultimately lead to sub-optimal adaptation. To mitigate the effect of mismatched pseudo-labels, we propose to incorporate structural cues from auxiliary modalities, such as depth, to regularise conventional self-training objectives. Specifically, we introduce a contrastive pixel-level objectness constraint that pulls the pixel representations within a region of an object instance closer, while pushing those from different object categories apart. To obtain object regions consistent with the true underlying object, we extract information from both depth maps and RGB-images in the form of multimodal clustering. Crucially, the objectness constraint is agnostic to the ground-truth semantic labels and, hence, appropriate for unsupervised domain adaptation. In this work, we show that our regularizer significantly improves top performing self-training methods (by up to $2$ points) in various UDA benchmarks for semantic segmentation. We include all code in the supplementary.
Adversarial Representation Learning for Robust Privacy Preservation in Audio
Apr 29, 2023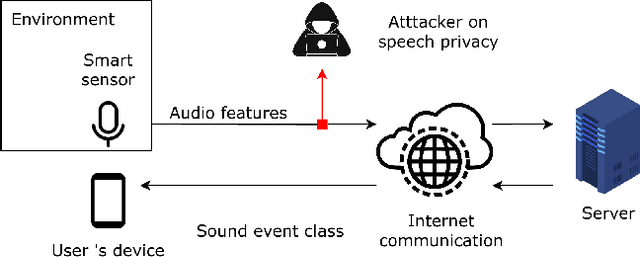

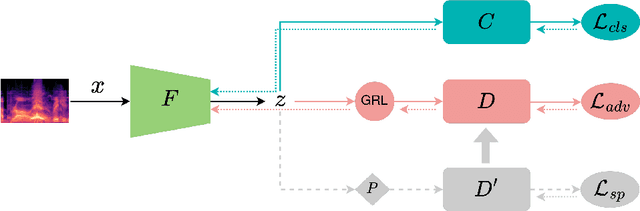

Sound event detection systems are widely used in various applications such as surveillance and environmental monitoring where data is automatically collected, processed, and sent to a cloud for sound recognition. However, this process may inadvertently reveal sensitive information about users or their surroundings, hence raising privacy concerns. In this study, we propose a novel adversarial training method for learning representations of audio recordings that effectively prevents the detection of speech activity from the latent features of the recordings. The proposed method trains a model to generate invariant latent representations of speech-containing audio recordings that cannot be distinguished from non-speech recordings by a speech classifier. The novelty of our work is in the optimization algorithm, where the speech classifier's weights are regularly replaced with the weights of classifiers trained in a supervised manner. This increases the discrimination power of the speech classifier constantly during the adversarial training, motivating the model to generate latent representations in which speech is not distinguishable, even using new speech classifiers trained outside the adversarial training loop. The proposed method is evaluated against a baseline approach with no privacy measures and a prior adversarial training method, demonstrating a significant reduction in privacy violations compared to the baseline approach. Additionally, we show that the prior adversarial method is practically ineffective for this purpose.
Towards Explainable and Safe Conversational Agents for Mental Health: A Survey
Apr 25, 2023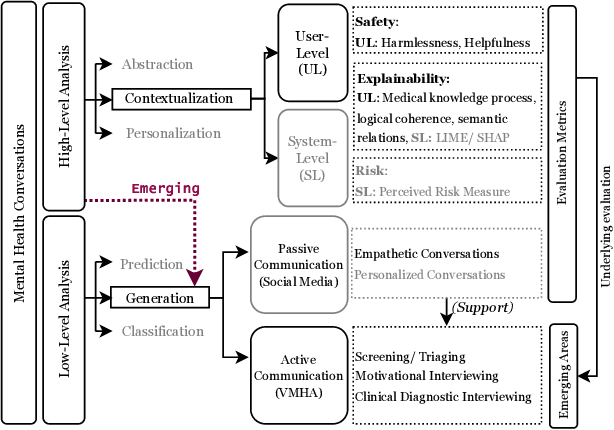
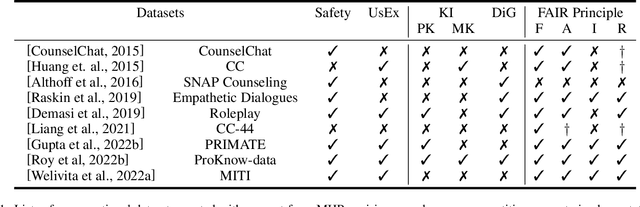
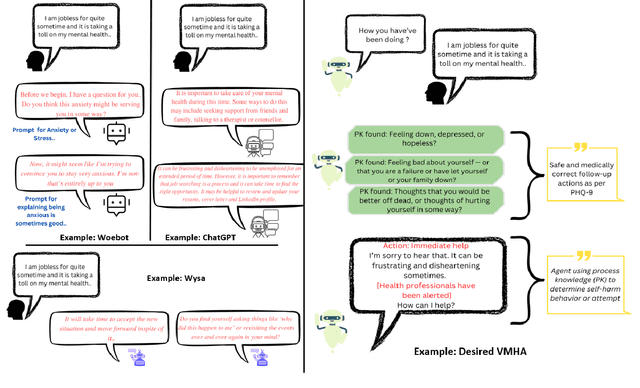
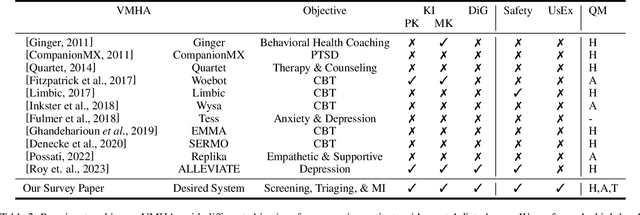
Virtual Mental Health Assistants (VMHAs) are seeing continual advancements to support the overburdened global healthcare system that gets 60 million primary care visits, and 6 million Emergency Room (ER) visits annually. These systems are built by clinical psychologists, psychiatrists, and Artificial Intelligence (AI) researchers for Cognitive Behavioral Therapy (CBT). At present, the role of VMHAs is to provide emotional support through information, focusing less on developing a reflective conversation with the patient. A more comprehensive, safe and explainable approach is required to build responsible VMHAs to ask follow-up questions or provide a well-informed response. This survey offers a systematic critical review of the existing conversational agents in mental health, followed by new insights into the improvements of VMHAs with contextual knowledge, datasets, and their emerging role in clinical decision support. We also provide new directions toward enriching the user experience of VMHAs with explainability, safety, and wholesome trustworthiness. Finally, we provide evaluation metrics and practical considerations for VMHAs beyond the current literature to build trust between VMHAs and patients in active communications.
MMC: Multi-Modal Colorization of Images using Textual Descriptions
Apr 25, 2023
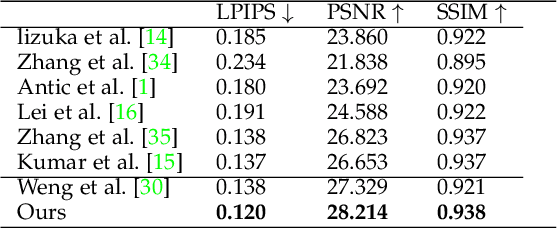
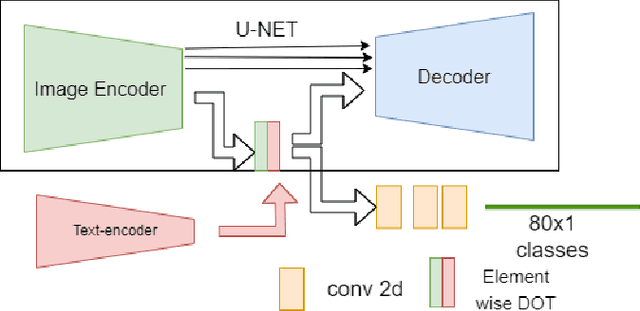
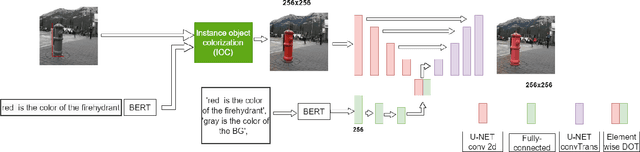
Handling various objects with different colors is a significant challenge for image colorization techniques. Thus, for complex real-world scenes, the existing image colorization algorithms often fail to maintain color consistency. In this work, we attempt to integrate textual descriptions as an auxiliary condition, along with the grayscale image that is to be colorized, to improve the fidelity of the colorization process. To do so, we have proposed a deep network that takes two inputs (grayscale image and the respective encoded text description) and tries to predict the relevant color components. Also, we have predicted each object in the image and have colorized them with their individual description to incorporate their specific attributes in the colorization process. After that, a fusion model fuses all the image objects (segments) to generate the final colorized image. As the respective textual descriptions contain color information of the objects present in the image, text encoding helps to improve the overall quality of predicted colors. In terms of performance, the proposed method outperforms existing colorization techniques in terms of LPIPS, PSNR and SSIM metrics.
USA-Net: Unified Semantic and Affordance Representations for Robot Memory
Apr 25, 2023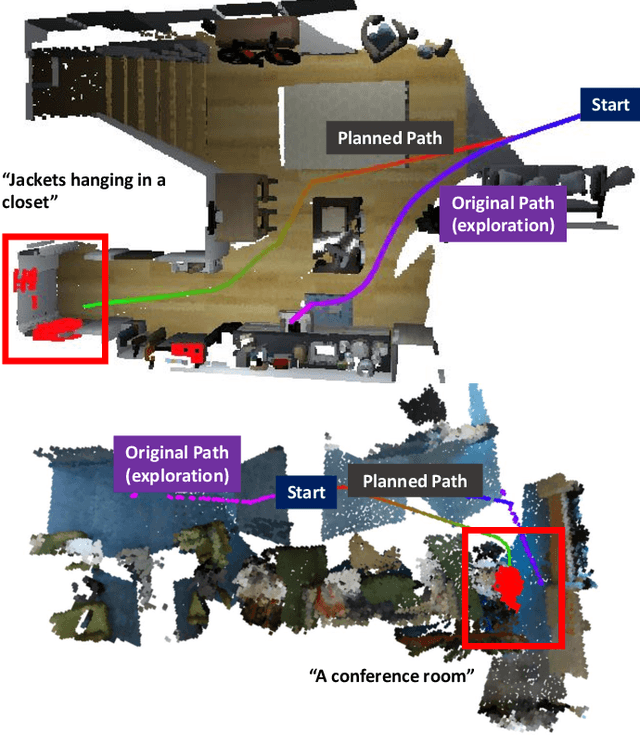
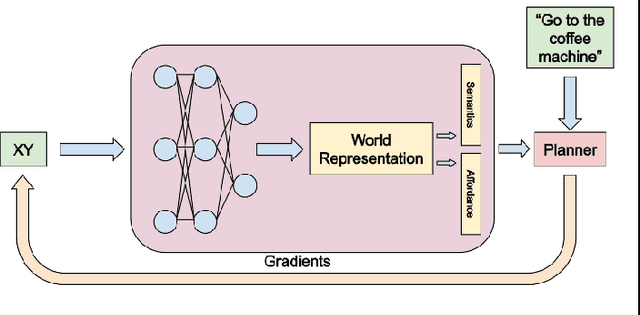

In order for robots to follow open-ended instructions like "go open the brown cabinet over the sink", they require an understanding of both the scene geometry and the semantics of their environment. Robotic systems often handle these through separate pipelines, sometimes using very different representation spaces, which can be suboptimal when the two objectives conflict. In this work, we present USA-Net, a simple method for constructing a world representation that encodes both the semantics and spatial affordances of a scene in a differentiable map. This allows us to build a gradient-based planner which can navigate to locations in the scene specified using open-ended vocabulary. We use this planner to consistently generate trajectories which are both shorter 5-10% shorter and 10-30% closer to our goal query in CLIP embedding space than paths from comparable grid-based planners which don't leverage gradient information. To our knowledge, this is the first end-to-end differentiable planner optimizes for both semantics and affordance in a single implicit map. Code and visuals are available at our website: https://usa.bolte.cc/
Attention-Enhanced Deep Learning for Device-Free Through-the-Wall Presence Detection Using Indoor WiFi System
Apr 25, 2023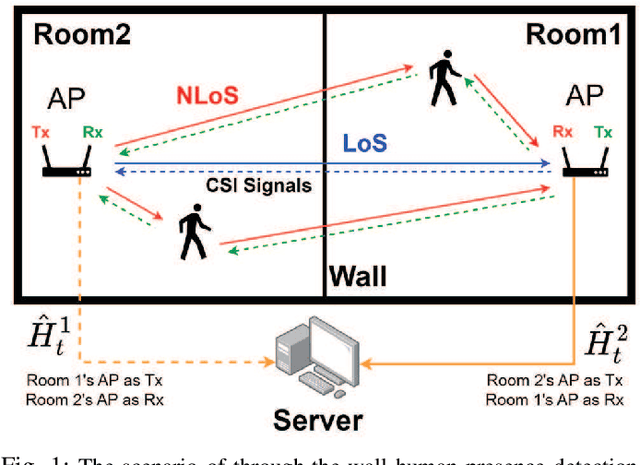
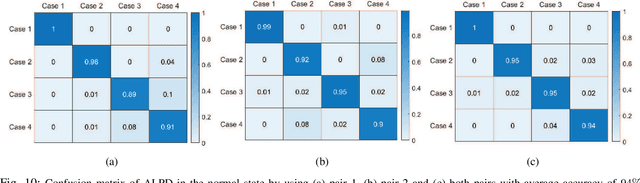
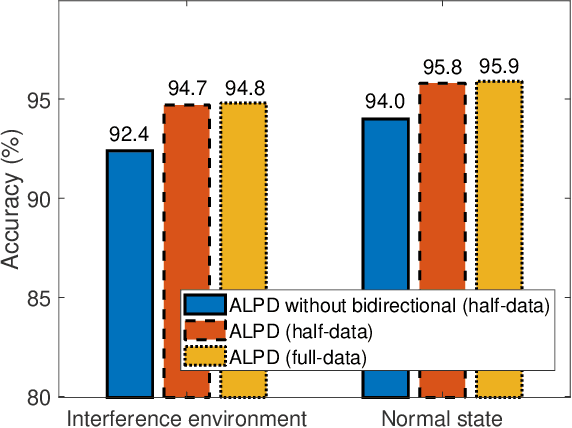
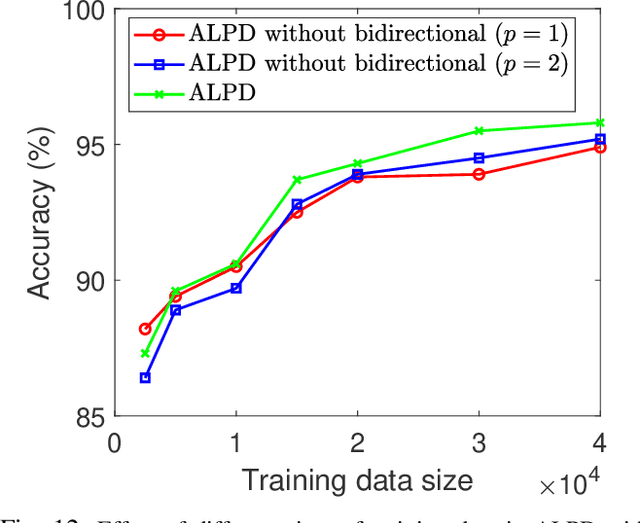
Accurate detection of human presence in indoor environments is important for various applications, such as energy management and security. In this paper, we propose a novel system for human presence detection using the channel state information (CSI) of WiFi signals. Our system named attention-enhanced deep learning for presence detection (ALPD) employs an attention mechanism to automatically select informative subcarriers from the CSI data and a bidirectional long short-term memory (LSTM) network to capture temporal dependencies in CSI. Additionally, we utilize a static feature to improve the accuracy of human presence detection in static states. We evaluate the proposed ALPD system by deploying a pair of WiFi access points (APs) for collecting CSI dataset, which is further compared with several benchmarks. The results demonstrate that our ALPD system outperforms the benchmarks in terms of accuracy, especially in the presence of interference. Moreover, bidirectional transmission data is beneficial to training improving stability and accuracy, as well as reducing the costs of data collection for training. Overall, our proposed ALPD system shows promising results for human presence detection using WiFi CSI signals.
Multi-Speaker Multi-Lingual VQTTS System for LIMMITS 2023 Challenge
Apr 25, 2023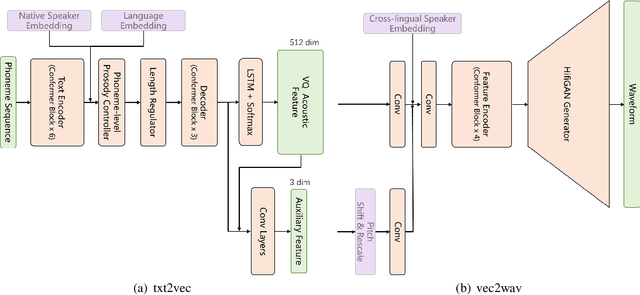
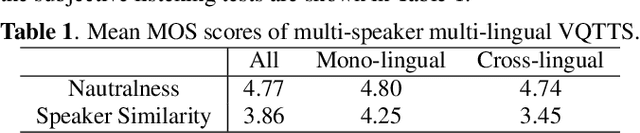
In this paper, we describe the systems developed by the SJTU X-LANCE team for LIMMITS 2023 Challenge, and we mainly focus on the winning system on naturalness for track 1. The aim of this challenge is to build a multi-speaker multi-lingual text-to-speech (TTS) system for Marathi, Hindi and Telugu. Each of the languages has a male and a female speaker in the given dataset. In track 1, only 5 hours data from each speaker can be selected to train the TTS model. Our system is based on the recently proposed VQTTS that utilizes VQ acoustic feature rather than mel-spectrogram. We introduce additional speaker embeddings and language embeddings to VQTTS for controlling the speaker and language information. In the cross-lingual evaluations where we need to synthesize speech in a cross-lingual speaker's voice, we provide a native speaker's embedding to the acoustic model and the target speaker's embedding to the vocoder. In the subjective MOS listening test on naturalness, our system achieves 4.77 which ranks first.
Time-Selective RNN for Device-Free Multi-Room Human Presence Detection Using WiFi CSI
Apr 25, 2023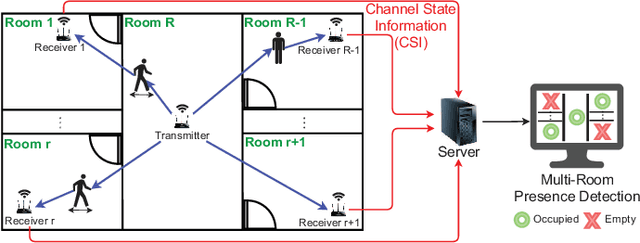
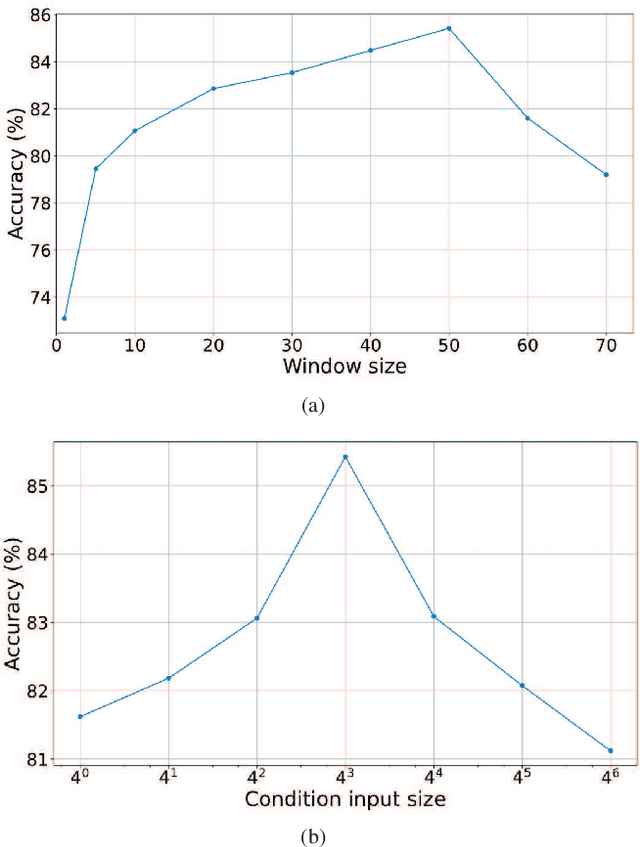
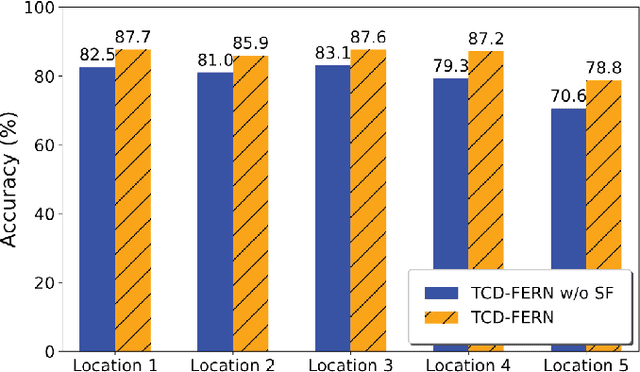
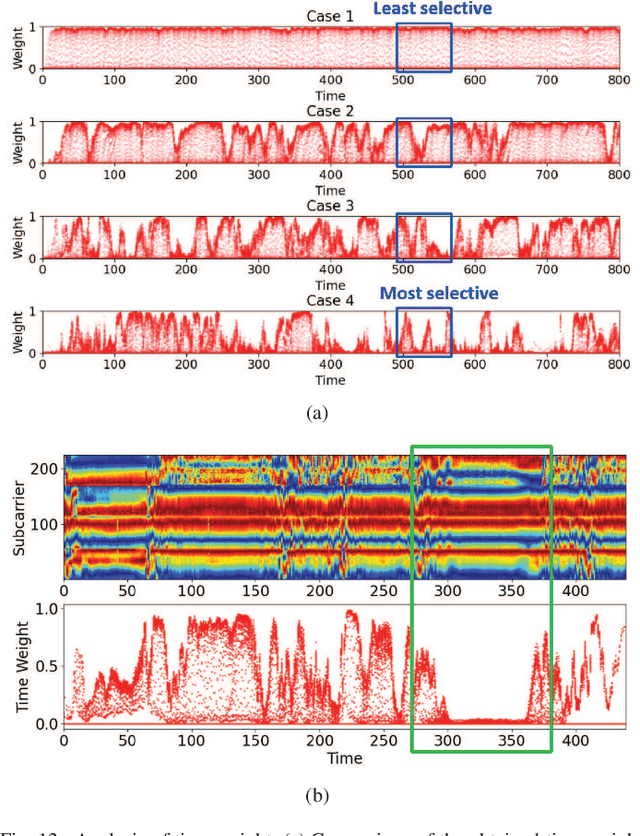
Human presence detection is a crucial technology for various applications, including home automation, security, and healthcare. While camera-based systems have traditionally been used for this purpose, they raise privacy concerns. To address this issue, recent research has explored the use of channel state information (CSI) approaches that can be extracted from commercial WiFi access points (APs) and provide detailed channel characteristics. In this thesis, we propose a device-free human presence detection system for multi-room scenarios using a time-selective conditional dual feature extract recurrent Network (TCD-FERN). Our system is designed to capture significant time features with the condition on current human features using a dynamic and static (DaS) data preprocessing technique to extract moving and spatial features of people and differentiate between line-of-sight (LoS) path blocking and non-blocking cases. To mitigate the feature attenuation problem caused by room partitions, we employ a voting scheme. We conduct evaluation and real-time experiments to demonstrate that our proposed TCD-FERN system can achieve human presence detection for multi-room scenarios using fewer commodity WiFi APs.
Loss and Reward Weighing for increased learning in Distributed Reinforcement Learning
Apr 25, 2023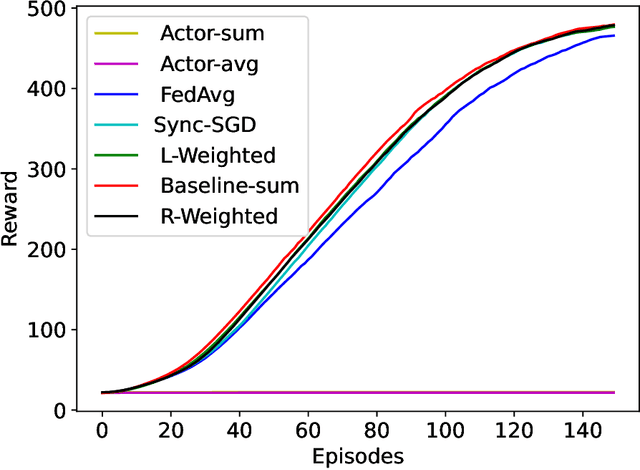
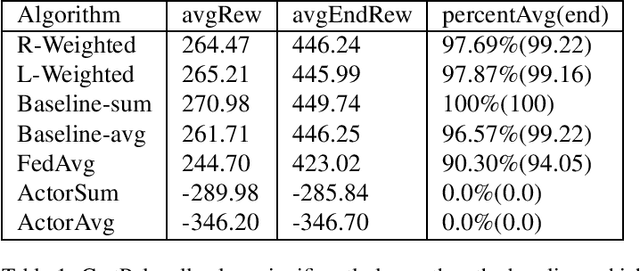
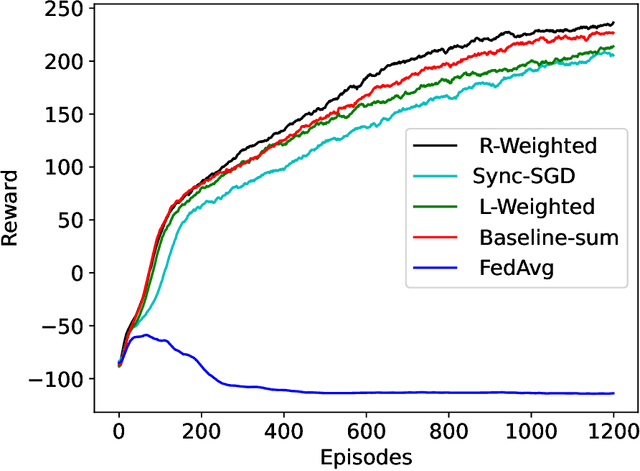
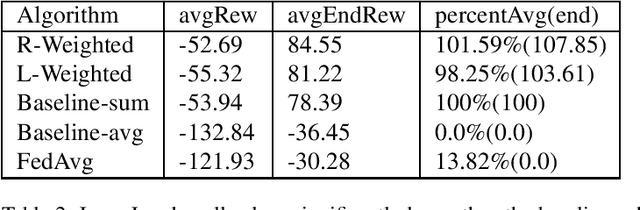
This paper introduces two learning schemes for distributed agents in Reinforcement Learning (RL) environments, namely Reward-Weighted (R-Weighted) and Loss-Weighted (L-Weighted) gradient merger. The R/L weighted methods replace standard practices for training multiple agents, such as summing or averaging the gradients. The core of our methods is to scale the gradient of each actor based on how high the reward (for R-Weighted) or the loss (for L-Weighted) is compared to the other actors. During training, each agent operates in differently initialized versions of the same environment, which gives different gradients from different actors. In essence, the R-Weights and L-Weights of each agent inform the other agents of its potential, which again reports which environment should be prioritized for learning. This approach of distributed learning is possible because environments that yield higher rewards, or low losses, have more critical information than environments that yield lower rewards or higher losses. We empirically demonstrate that the R-Weighted methods work superior to the state-of-the-art in multiple RL environments.
Physics-Informed Representation Learning for Emergent Organization in Complex Dynamical Systems
Apr 25, 2023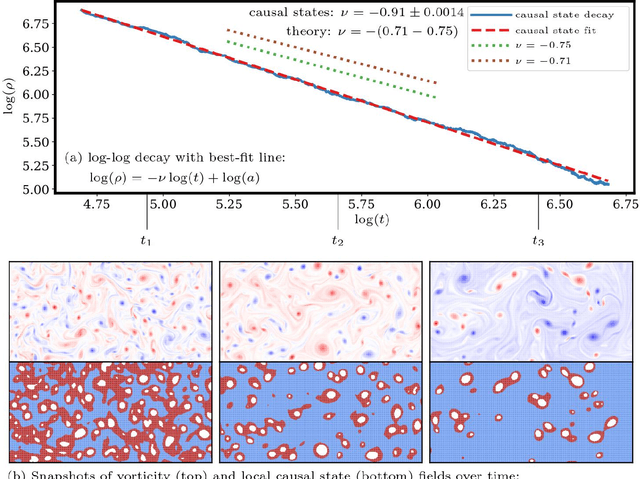
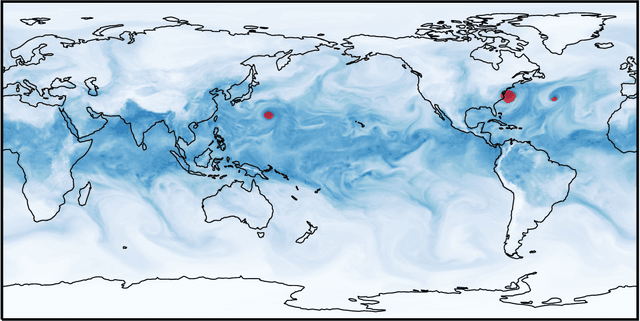
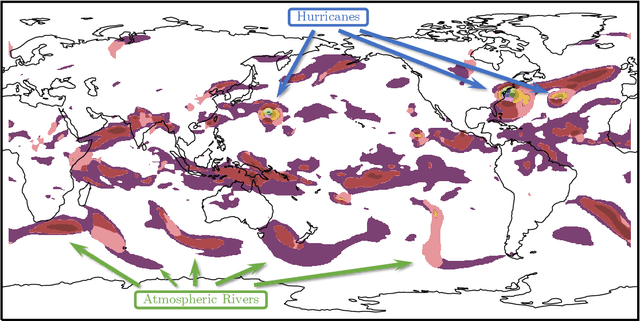
Nonlinearly interacting system components often introduce instabilities that generate phenomena with new properties and at different space-time scales than the components. This is known as spontaneous self-organization and is ubiquitous in systems far from thermodynamic equilibrium. We introduce a theoretically-grounded framework for emergent organization that, via data-driven algorithms, is constructive in practice. Its building blocks are spacetime lightcones that capture how information propagates across a system through local interactions. We show that predictive equivalence classes of lightcones, local causal states, capture organized behaviors and coherent structures in complex spatiotemporal systems. Using our unsupervised physics-informed machine learning algorithm and a high-performance computing implementation, we demonstrate the applicability of the local causal states for real-world domain science problems. We show that the local causal states capture vortices and their power-law decay behavior in two-dimensional turbulence. We then show that known (hurricanes and atmospheric rivers) and novel extreme weather events can be identified on a pixel-level basis and tracked through time in high-resolution climate data.