 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Beyond Homophily: Reconstructing Structure for Graph-agnostic Clustering
May 03, 2023
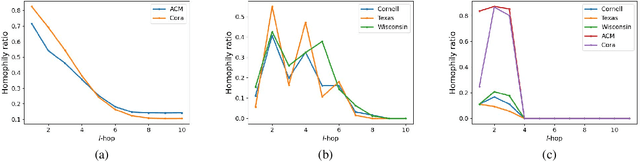
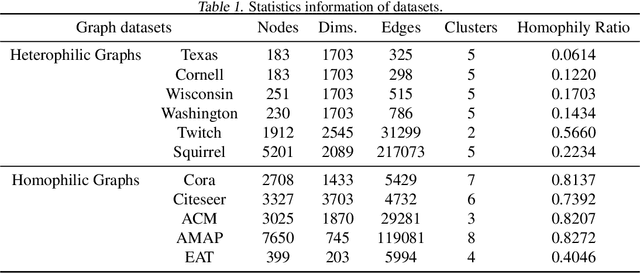
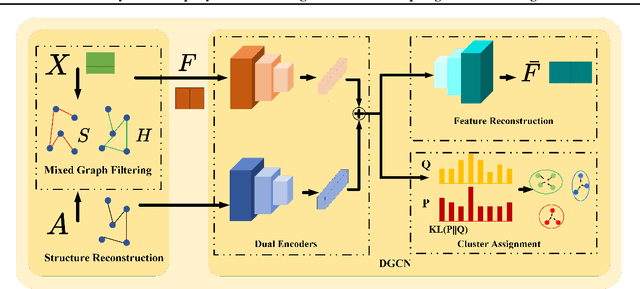
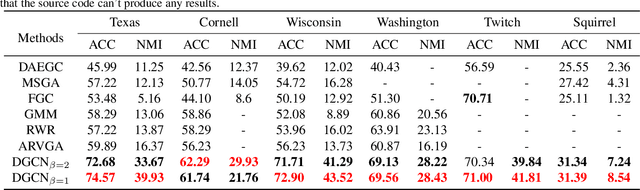
Graph neural networks (GNNs) based methods have achieved impressive performance on node clustering task. However, they are designed on the homophilic assumption of graph and clustering on heterophilic graph is overlooked. Due to the lack of labels, it is impossible to first identify a graph as homophilic or heterophilic before a suitable GNN model can be found. Hence, clustering on real-world graph with various levels of homophily poses a new challenge to the graph research community. To fill this gap, we propose a novel graph clustering method, which contains three key components: graph reconstruction, a mixed filter, and dual graph clustering network. To be graph-agnostic, we empirically construct two graphs which are high homophily and heterophily from each data. The mixed filter based on the new graphs extracts both low-frequency and high-frequency information. To reduce the adverse coupling between node attribute and topological structure, we separately map them into two subspaces in dual graph clustering network. Extensive experiments on 11 benchmark graphs demonstrate our promising performance. In particular, our method dominates others on heterophilic graphs.
Understanding Differential Search Index for Text Retrieval
May 03, 2023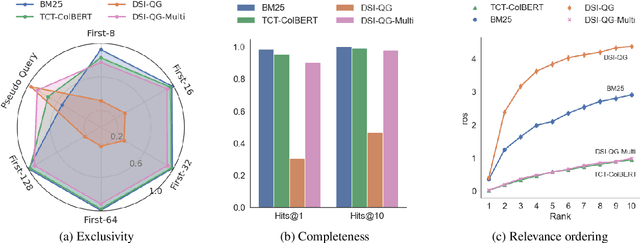
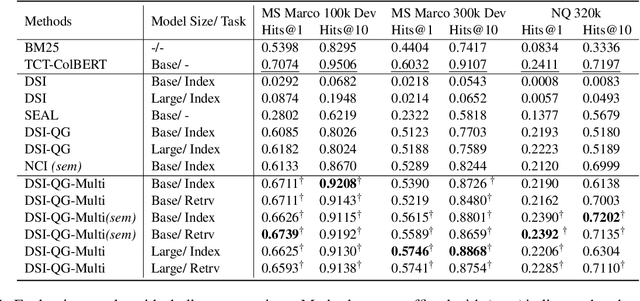
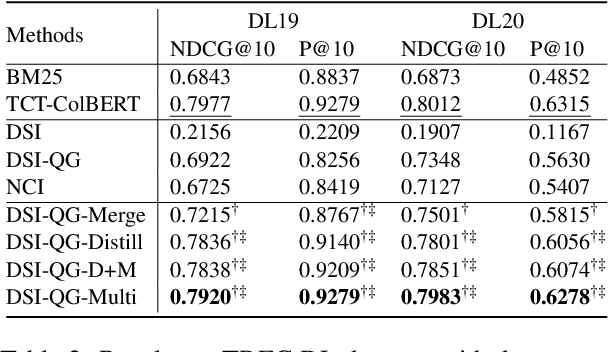

The Differentiable Search Index (DSI) is a novel information retrieval (IR) framework that utilizes a differentiable function to generate a sorted list of document identifiers in response to a given query. However, due to the black-box nature of the end-to-end neural architecture, it remains to be understood to what extent DSI possesses the basic indexing and retrieval abilities. To mitigate this gap, in this study, we define and examine three important abilities that a functioning IR framework should possess, namely, exclusivity, completeness, and relevance ordering. Our analytical experimentation shows that while DSI demonstrates proficiency in memorizing the unidirectional mapping from pseudo queries to document identifiers, it falls short in distinguishing relevant documents from random ones, thereby negatively impacting its retrieval effectiveness. To address this issue, we propose a multi-task distillation approach to enhance the retrieval quality without altering the structure of the model and successfully endow it with improved indexing abilities. Through experiments conducted on various datasets, we demonstrate that our proposed method outperforms previous DSI baselines.
Watch This Space: Securing Satellite Communication through Resilient Transmitter Fingerprinting
May 11, 2023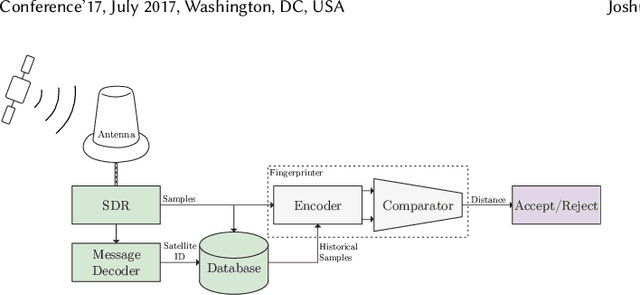
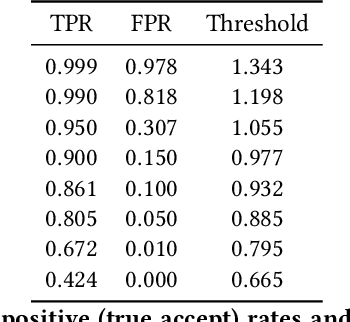
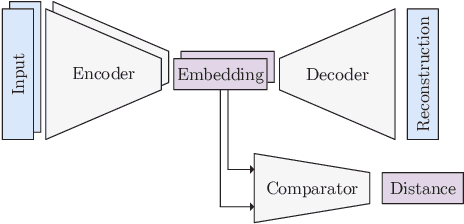
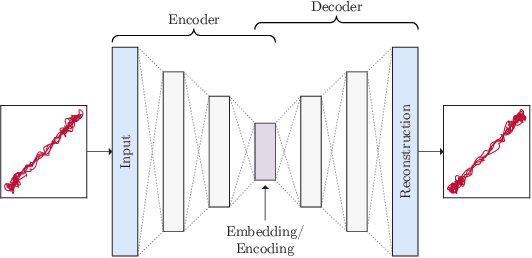
Due to an increase in the availability of cheap off-the-shelf radio hardware, spoofing and replay attacks on satellite ground systems have become more accessible than ever. This is particularly a problem for legacy systems, many of which do not offer cryptographic security and cannot be patched to support novel security measures. In this paper we explore radio transmitter fingerprinting in satellite systems. We introduce the SatIQ system, proposing novel techniques for authenticating transmissions using characteristics of transmitter hardware expressed as impairments on the downlinked signal. We look in particular at high sample rate fingerprinting, making fingerprints difficult to forge without similarly high sample rate transmitting hardware, thus raising the budget for attacks. We also examine the difficulty of this approach with high levels of atmospheric noise and multipath scattering, and analyze potential solutions to this problem. We focus on the Iridium satellite constellation, for which we collected 1010464 messages at a sample rate of 25 MS/s. We use this data to train a fingerprinting model consisting of an autoencoder combined with a Siamese neural network, enabling the model to learn an efficient encoding of message headers that preserves identifying information. We demonstrate the system's robustness under attack by replaying messages using a Software-Defined Radio, achieving an Equal Error Rate of 0.120, and ROC AUC of 0.946. Finally, we analyze its stability over time by introducing a time gap between training and testing data, and its extensibility by introducing new transmitters which have not been seen before. We conclude that our techniques are useful for building systems that are stable over time, can be used immediately with new transmitters without retraining, and provide robustness against spoofing and replay by raising the required budget for attacks.
HGWaveNet: A Hyperbolic Graph Neural Network for Temporal Link Prediction
Apr 14, 2023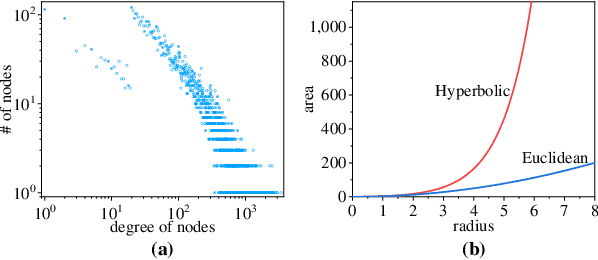
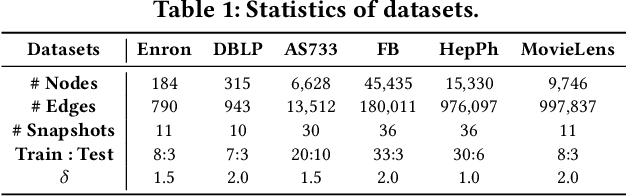
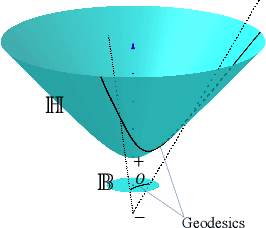
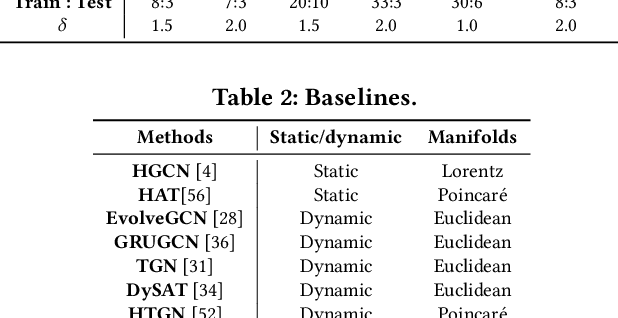
Temporal link prediction, aiming to predict future edges between paired nodes in a dynamic graph, is of vital importance in diverse applications. However, existing methods are mainly built upon uniform Euclidean space, which has been found to be conflict with the power-law distributions of real-world graphs and unable to represent the hierarchical connections between nodes effectively. With respect to the special data characteristic, hyperbolic geometry offers an ideal alternative due to its exponential expansion property. In this paper, we propose HGWaveNet, a novel hyperbolic graph neural network that fully exploits the fitness between hyperbolic spaces and data distributions for temporal link prediction. Specifically, we design two key modules to learn the spatial topological structures and temporal evolutionary information separately. On the one hand, a hyperbolic diffusion graph convolution (HDGC) module effectively aggregates information from a wider range of neighbors. On the other hand, the internal order of causal correlation between historical states is captured by hyperbolic dilated causal convolution (HDCC) modules. The whole model is built upon the hyperbolic spaces to preserve the hierarchical structural information in the entire data flow. To prove the superiority of HGWaveNet, extensive experiments are conducted on six real-world graph datasets and the results show a relative improvement by up to 6.67% on AUC for temporal link prediction over SOTA methods.
Machine Perception-Driven Image Compression: A Layered Generative Approach
Apr 14, 2023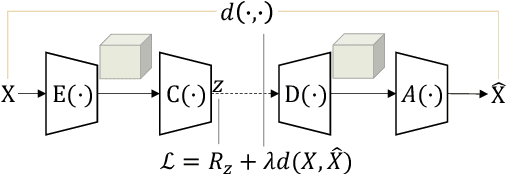
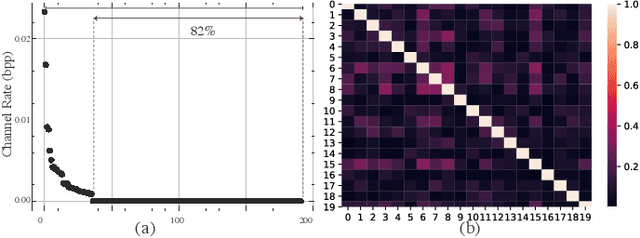
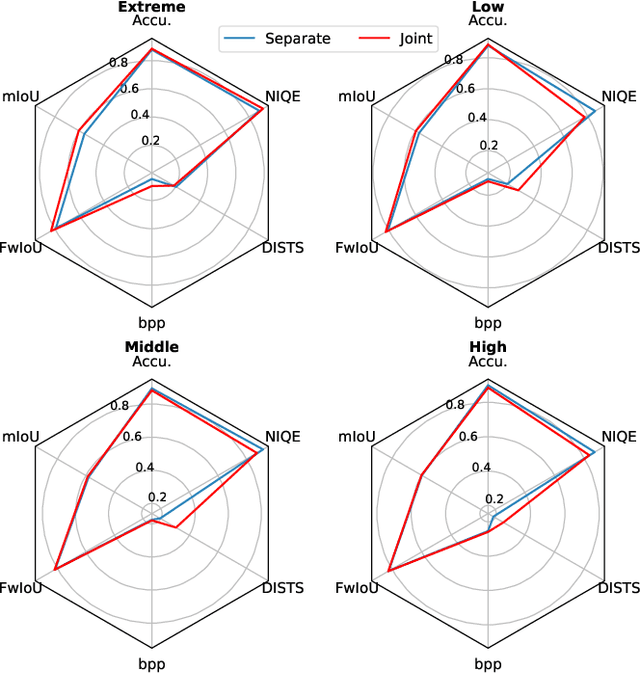
In this age of information, images are a critical medium for storing and transmitting information. With the rapid growth of image data amount, visual compression and visual data perception are two important research topics attracting a lot attention. However, those two topics are rarely discussed together and follow separate research path. Due to the compact compressed domain representation offered by learning-based image compression methods, there exists possibility to have one stream targeting both efficient data storage and compression, and machine perception tasks. In this paper, we propose a layered generative image compression model achieving high human vision-oriented image reconstructed quality, even at extreme compression ratios. To obtain analysis efficiency and flexibility, a task-agnostic learning-based compression model is proposed, which effectively supports various compressed domain-based analytical tasks while reserves outstanding reconstructed perceptual quality, compared with traditional and learning-based codecs. In addition, joint optimization schedule is adopted to acquire best balance point among compression ratio, reconstructed image quality, and downstream perception performance. Experimental results verify that our proposed compressed domain-based multi-task analysis method can achieve comparable analysis results against the RGB image-based methods with up to 99.6% bit rate saving (i.e., compared with taking original RGB image as the analysis model input). The practical ability of our model is further justified from model size and information fidelity aspects.
Privacy-Preserving Representations are not Enough -- Recovering Scene Content from Camera Poses
May 08, 2023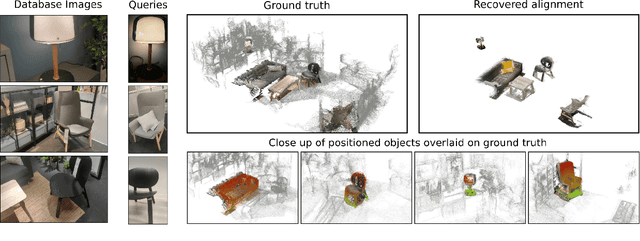



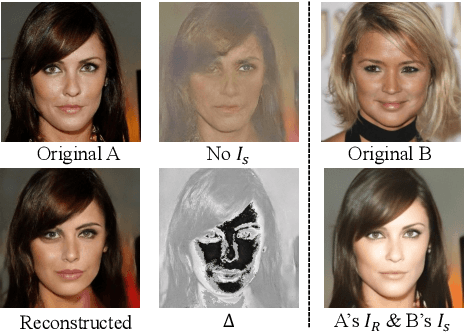
Visual localization is the task of estimating the camera pose from which a given image was taken and is central to several 3D computer vision applications. With the rapid growth in the popularity of AR/VR/MR devices and cloud-based applications, privacy issues are becoming a very important aspect of the localization process. Existing work on privacy-preserving localization aims to defend against an attacker who has access to a cloud-based service. In this paper, we show that an attacker can learn about details of a scene without any access by simply querying a localization service. The attack is based on the observation that modern visual localization algorithms are robust to variations in appearance and geometry. While this is in general a desired property, it also leads to algorithms localizing objects that are similar enough to those present in a scene. An attacker can thus query a server with a large enough set of images of objects, \eg, obtained from the Internet, and some of them will be localized. The attacker can thus learn about object placements from the camera poses returned by the service (which is the minimal information returned by such a service). In this paper, we develop a proof-of-concept version of this attack and demonstrate its practical feasibility. The attack does not place any requirements on the localization algorithm used, and thus also applies to privacy-preserving representations. Current work on privacy-preserving representations alone is thus insufficient.
Towards a Benchmark for Scientific Understanding in Humans and Machines
Apr 21, 2023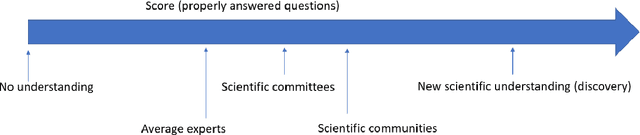
Scientific understanding is a fundamental goal of science, allowing us to explain the world. There is currently no good way to measure the scientific understanding of agents, whether these be humans or Artificial Intelligence systems. Without a clear benchmark, it is challenging to evaluate and compare different levels of and approaches to scientific understanding. In this Roadmap, we propose a framework to create a benchmark for scientific understanding, utilizing tools from philosophy of science. We adopt a behavioral notion according to which genuine understanding should be recognized as an ability to perform certain tasks. We extend this notion by considering a set of questions that can gauge different levels of scientific understanding, covering information retrieval, the capability to arrange information to produce an explanation, and the ability to infer how things would be different under different circumstances. The Scientific Understanding Benchmark (SUB), which is formed by a set of these tests, allows for the evaluation and comparison of different approaches. Benchmarking plays a crucial role in establishing trust, ensuring quality control, and providing a basis for performance evaluation. By aligning machine and human scientific understanding we can improve their utility, ultimately advancing scientific understanding and helping to discover new insights within machines.
RGB-D Inertial Odometry for a Resource-Restricted Robot in Dynamic Environments
Apr 21, 2023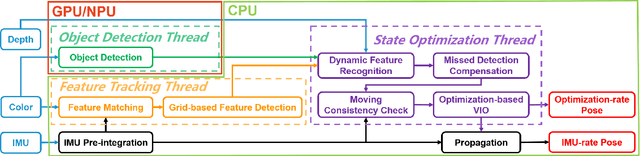

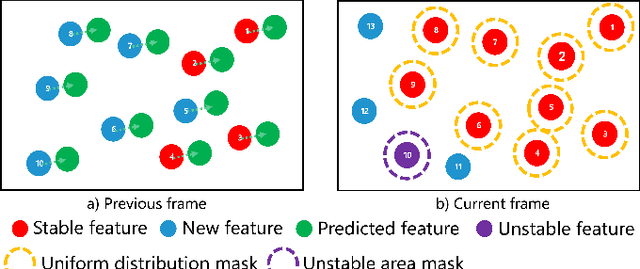
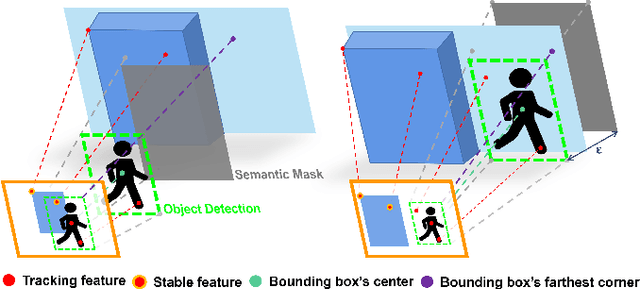
Current simultaneous localization and mapping (SLAM) algorithms perform well in static environments but easily fail in dynamic environments. Recent works introduce deep learning-based semantic information to SLAM systems to reduce the influence of dynamic objects. However, it is still challenging to apply a robust localization in dynamic environments for resource-restricted robots. This paper proposes a real-time RGB-D inertial odometry system for resource-restricted robots in dynamic environments named Dynamic-VINS. Three main threads run in parallel: object detection, feature tracking, and state optimization. The proposed Dynamic-VINS combines object detection and depth information for dynamic feature recognition and achieves performance comparable to semantic segmentation. Dynamic-VINS adopts grid-based feature detection and proposes a fast and efficient method to extract high-quality FAST feature points. IMU is applied to predict motion for feature tracking and moving consistency check. The proposed method is evaluated on both public datasets and real-world applications and shows competitive localization accuracy and robustness in dynamic environments. Yet, to the best of our knowledge, it is the best-performance real-time RGB-D inertial odometry for resource-restricted platforms in dynamic environments for now. The proposed system is open source at: https://github.com/HITSZ-NRSL/Dynamic-VINS.git
Classical-to-Quantum Sequence Encoding in Genomics
Apr 21, 2023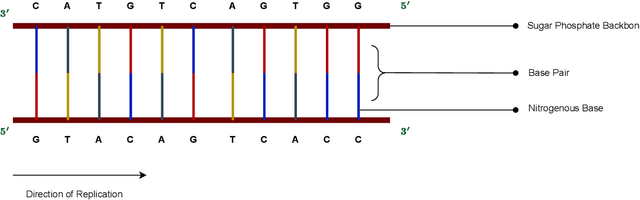
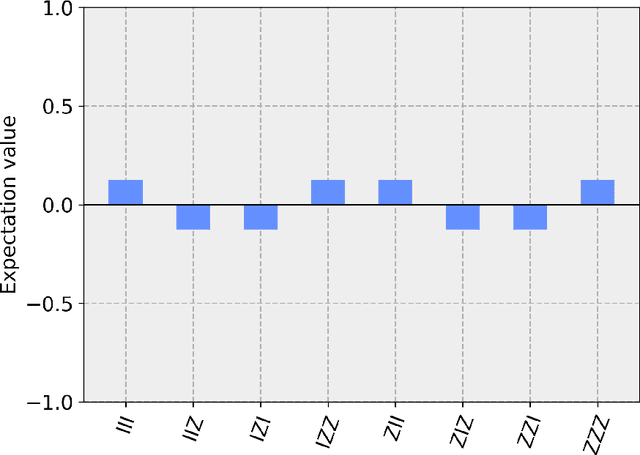
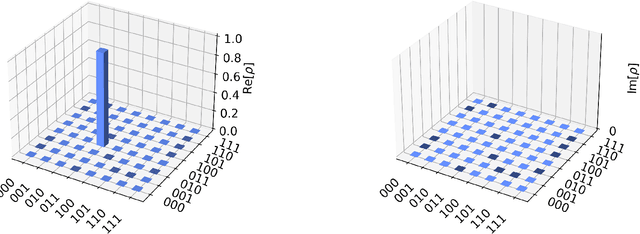
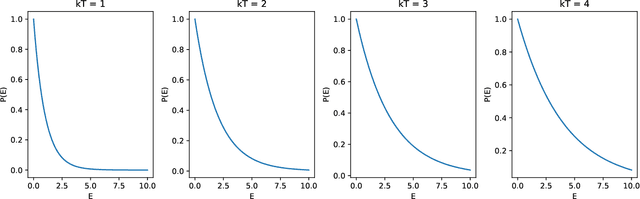
DNA sequencing allows for the determination of the genetic code of an organism, and therefore is an indispensable tool that has applications in Medicine, Life Sciences, Evolutionary Biology, Food Sciences and Technology, and Agriculture. In this paper, we present several novel methods of performing classical-to-quantum data encoding inspired by various mathematical fields, and we demonstrate these ideas within Bioinformatics. In particular, we introduce algorithms that draw inspiration from diverse fields such as Electrical and Electronic Engineering, Information Theory, Differential Geometry, and Neural Network architectures. We provide a complete overview of the existing data encoding schemes and show how to use them in Genomics. The algorithms provided utilise lossless compression, wavelet-based encoding, and information entropy. Moreover, we propose a contemporary method for testing encoded DNA sequences using Quantum Boltzmann Machines. To evaluate the effectiveness of our algorithms, we discuss a potential dataset that serves as a sandbox environment for testing against real-world scenarios. Our research contributes to developing classical-to-quantum data encoding methods in the science of Bioinformatics by introducing innovative algorithms that utilise diverse fields and advanced techniques. Our findings offer insights into the potential of Quantum Computing in Bioinformatics and have implications for future research in this area.
VTPNet for 3D deep learning on point cloud
May 10, 2023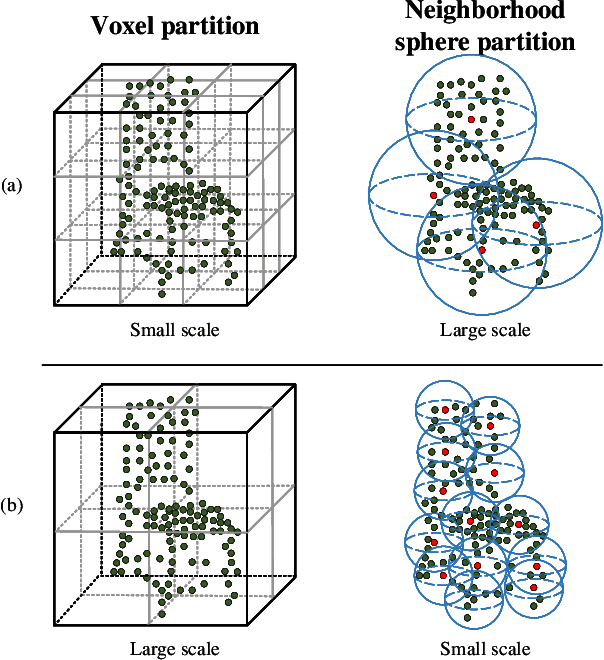
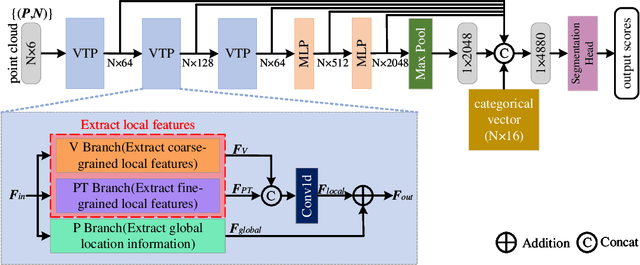
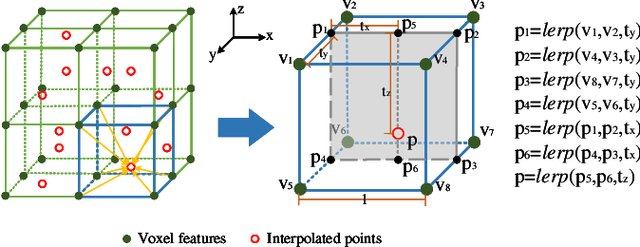

Recently, Transformer-based methods for point cloud learning have achieved good results on various point cloud learning benchmarks. However, since the attention mechanism needs to generate three feature vectors of query, key, and value to calculate attention features, most of the existing Transformer-based point cloud learning methods usually consume a large amount of computational time and memory resources when calculating global attention. To address this problem, we propose a Voxel-Transformer-Point (VTP) Block for extracting local and global features of point clouds. VTP combines the advantages of voxel-based, point-based and Transformer-based methods, which consists of Voxel-Based Branch (V branch), Point-Based Transformer Branch (PT branch) and Point-Based Branch (P branch). The V branch extracts the coarse-grained features of the point cloud through low voxel resolution; the PT branch obtains the fine-grained features of the point cloud by calculating the self-attention in the local neighborhood and the inter-neighborhood cross-attention; the P branch uses a simplified MLP network to generate the global location information of the point cloud. In addition, to enrich the local features of point clouds at different scales, we set the voxel scale in the V branch and the neighborhood sphere scale in the PT branch to one large and one small (large voxel scale \& small neighborhood sphere scale or small voxel scale \& large neighborhood sphere scale). Finally, we use VTP as the feature extraction network to construct a VTPNet for point cloud learning, and performs shape classification, part segmentation, and semantic segmentation tasks on the ModelNet40, ShapeNet Part, and S3DIS datasets. The experimental results indicate that VTPNet has good performance in 3D point cloud learning.