 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Segment Everything Everywhere All at Once
May 01, 2023
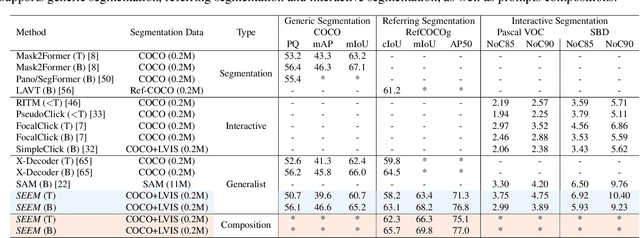
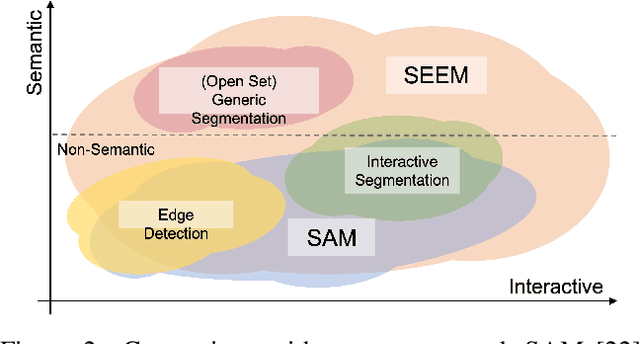
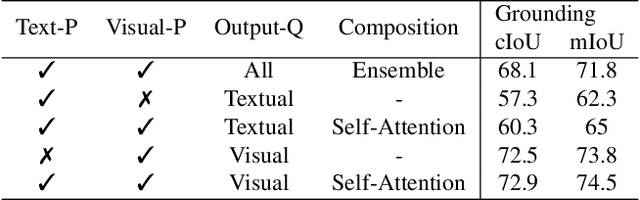
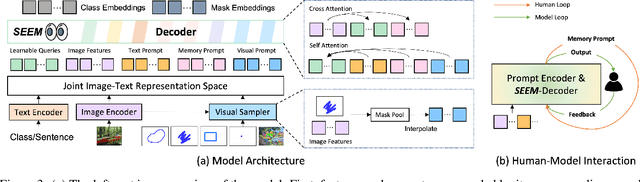
Despite the growing demand for interactive AI systems, there have been few comprehensive studies on human-AI interaction in visual understanding e.g. segmentation. Inspired by the development of prompt-based universal interfaces for LLMs, this paper presents SEEM, a promptable, interactive model for Segmenting Everything Everywhere all at once in an image. SEEM has four desiderata: i) Versatility: by introducing a versatile prompting engine for different types of prompts, including points, boxes, scribbles, masks, texts, and referred regions of another image; ii) Compositionality: by learning a joint visual-semantic space for visual and textual prompts to compose queries on the fly for inference as shown in Fig 1; iii)Interactivity: by incorporating learnable memory prompts to retain dialog history information via mask-guided cross-attention; and iv) Semantic-awareness: by using a text encoder to encode text queries and mask labels for open-vocabulary segmentation.
MC-MLP:Multiple Coordinate Frames in all-MLP Architecture for Vision
Apr 08, 2023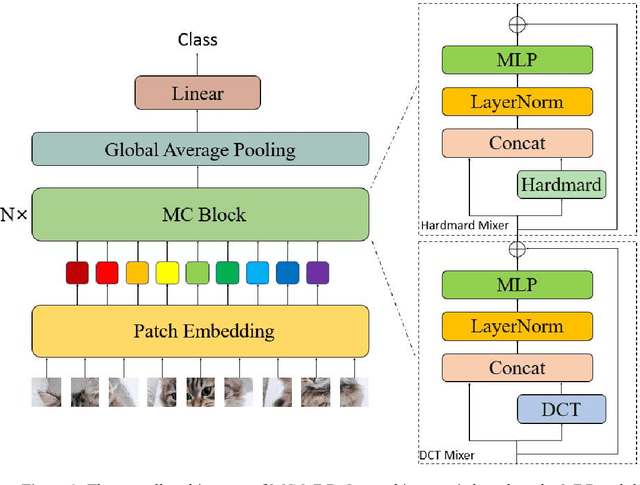
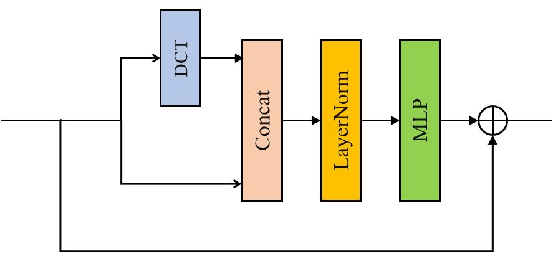
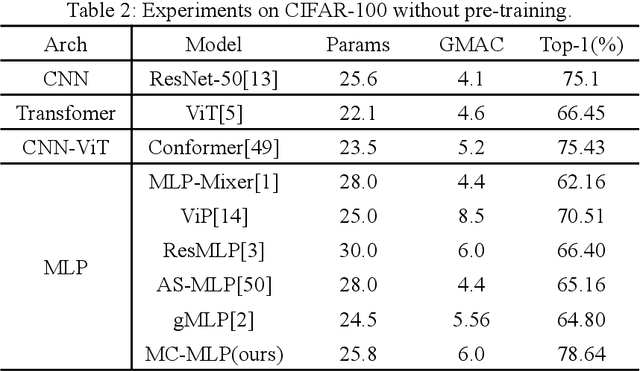
In deep learning, Multi-Layer Perceptrons (MLPs) have once again garnered attention from researchers. This paper introduces MC-MLP, a general MLP-like backbone for computer vision that is composed of a series of fully-connected (FC) layers. In MC-MLP, we propose that the same semantic information has varying levels of difficulty in learning, depending on the coordinate frame of features. To address this, we perform an orthogonal transform on the feature information, equivalent to changing the coordinate frame of features. Through this design, MC-MLP is equipped with multi-coordinate frame receptive fields and the ability to learn information across different coordinate frames. Experiments demonstrate that MC-MLP outperforms most MLPs in image classification tasks, achieving better performance at the same parameter level. The code will be available at: https://github.com/ZZM11/MC-MLP.
Overview of the TREC 2022 NeuCLIR Track
Apr 24, 2023
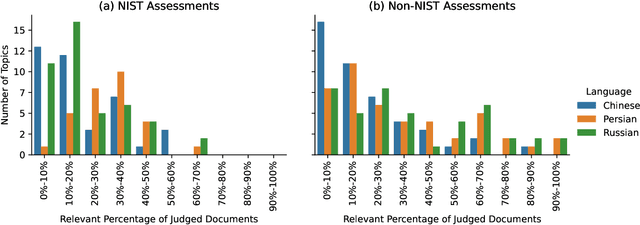
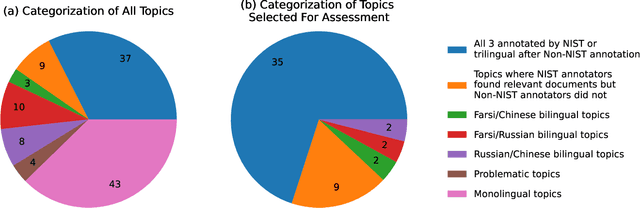
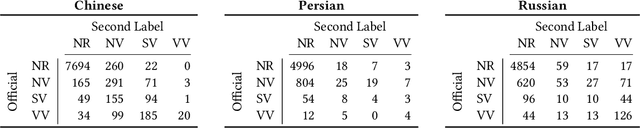
This is the first year of the TREC Neural CLIR (NeuCLIR) track, which aims to study the impact of neural approaches to cross-language information retrieval. The main task in this year's track was ad hoc ranked retrieval of Chinese, Persian, or Russian newswire documents using queries expressed in English. Topics were developed using standard TREC processes, except that topics developed by an annotator for one language were assessed by a different annotator when evaluating that topic on a different language. There were 172 total runs submitted by twelve teams.
Patterns of gender-specializing query reformulation
Apr 25, 2023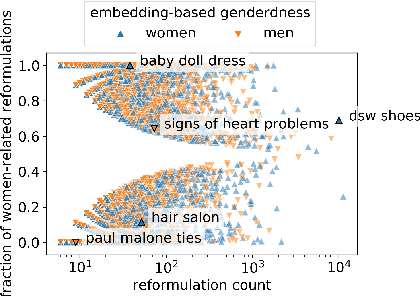
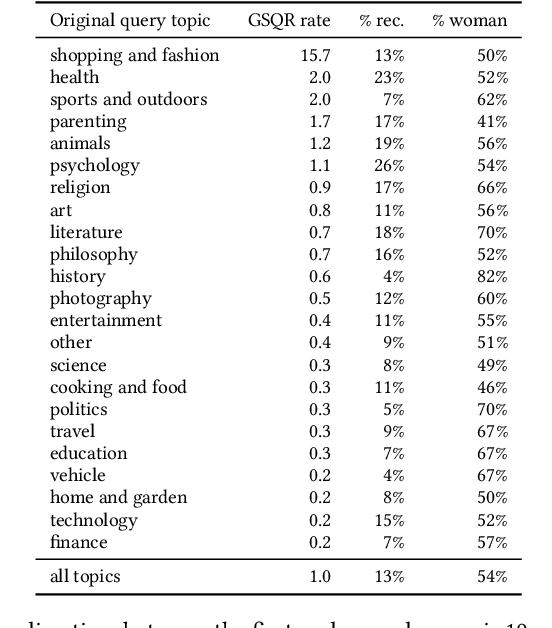
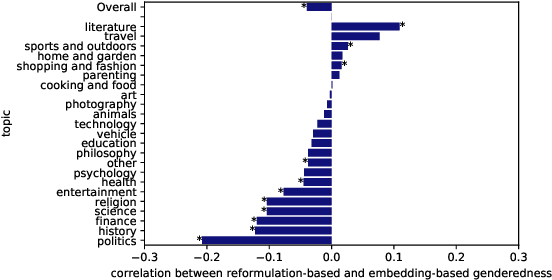
Users of search systems often reformulate their queries by adding query terms to reflect their evolving information need or to more precisely express their information need when the system fails to surface relevant content. Analyzing these query reformulations can inform us about both system and user behavior. In this work, we study a special category of query reformulations that involve specifying demographic group attributes, such as gender, as part of the reformulated query (e.g., "olympic 2021 soccer results" to "olympic 2021 women's soccer results"). There are many ways a query, the search results, and a demographic attribute such as gender may relate, leading us to hypothesize different causes for these reformulation patterns, such as under-representation on the original result page or based on the linguistic theory of markedness. This paper reports on an observational study of gender-specializing query reformulations -- their contexts and effects -- as a lens on the relationship between system results and gender, based on large-scale search log data from Bing. We find that these reformulations sometimes correct for and other times reinforce gender representation on the original result page, but typically yield better access to the ultimately-selected results. The prevalence of these reformulations -- and which gender they skew towards -- differ by topical context. However, we do not find evidence that either group under-representation or markedness alone adequately explains these reformulations. We hope that future research will use such reformulations as a probe for deeper investigation into gender (and other demographic) representation on the search result page.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 06, 2023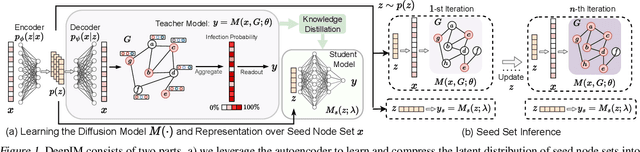
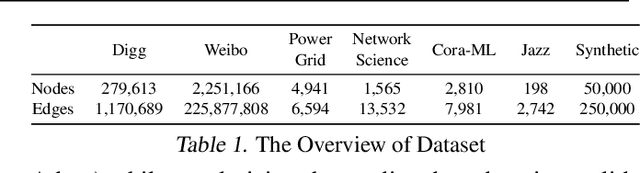
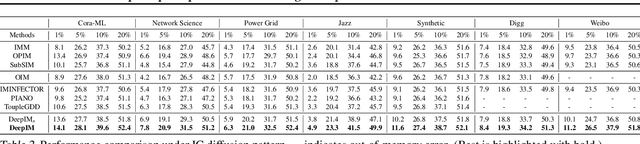
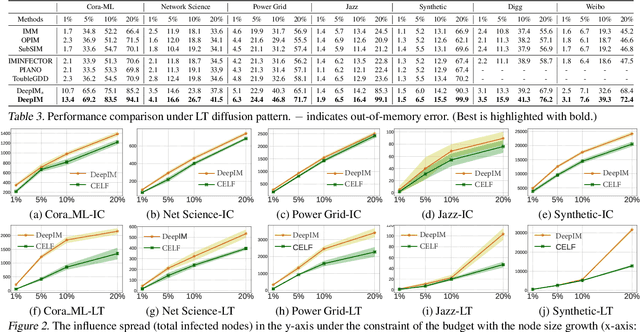
Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.
High-Fidelity and Freely Controllable Talking Head Video Generation
Apr 20, 2023
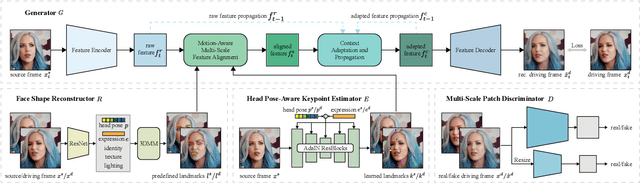
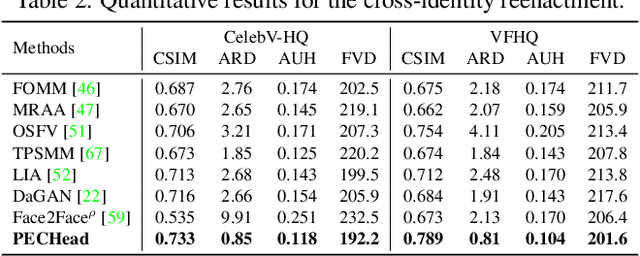
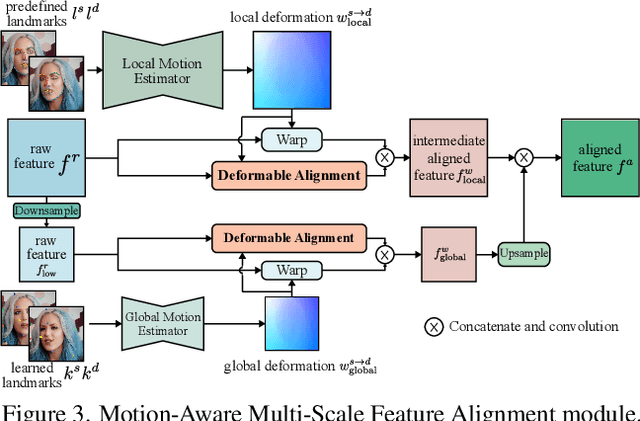
Talking head generation is to generate video based on a given source identity and target motion. However, current methods face several challenges that limit the quality and controllability of the generated videos. First, the generated face often has unexpected deformation and severe distortions. Second, the driving image does not explicitly disentangle movement-relevant information, such as poses and expressions, which restricts the manipulation of different attributes during generation. Third, the generated videos tend to have flickering artifacts due to the inconsistency of the extracted landmarks between adjacent frames. In this paper, we propose a novel model that produces high-fidelity talking head videos with free control over head pose and expression. Our method leverages both self-supervised learned landmarks and 3D face model-based landmarks to model the motion. We also introduce a novel motion-aware multi-scale feature alignment module to effectively transfer the motion without face distortion. Furthermore, we enhance the smoothness of the synthesized talking head videos with a feature context adaptation and propagation module. We evaluate our model on challenging datasets and demonstrate its state-of-the-art performance. More information is available at https://yuegao.me/PECHead.
Assessing Working Memory Capacity of ChatGPT
Apr 30, 2023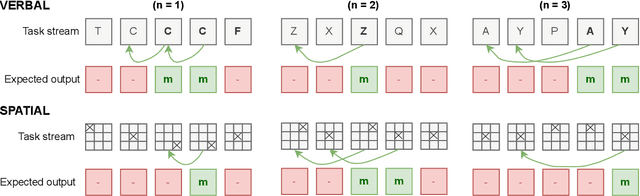

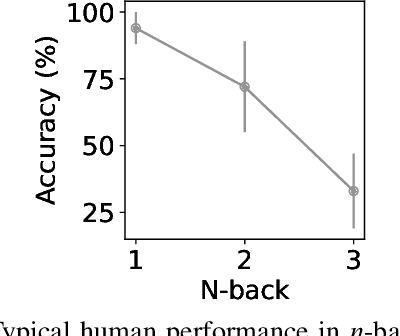

Working memory is a critical aspect of both human intelligence and artificial intelligence (AI), serving as a workspace for the temporary storage and manipulation of information. This paper investigates working memory capacity of ChatGPT, a state-of-the-art language model, by examining its performance on N-back tasks. We begin by discussing the importance of working memory to humans and AI, followed by the methods employed to assess working memory capacity of ChatGPT. Our study compares behavioral performance of ChatGPT on verbal and spatial N-back tasks to that of human participants reported in the literature, revealing notable similarities. Our findings offer crucial insights into the current progress in designing AI systems with human-level cognitive abilities and hold promise for informing future endeavors aimed at enhancing AI working memory and understanding human working memory through AI models.
Image Completion via Dual-path Cooperative Filtering
Apr 30, 2023

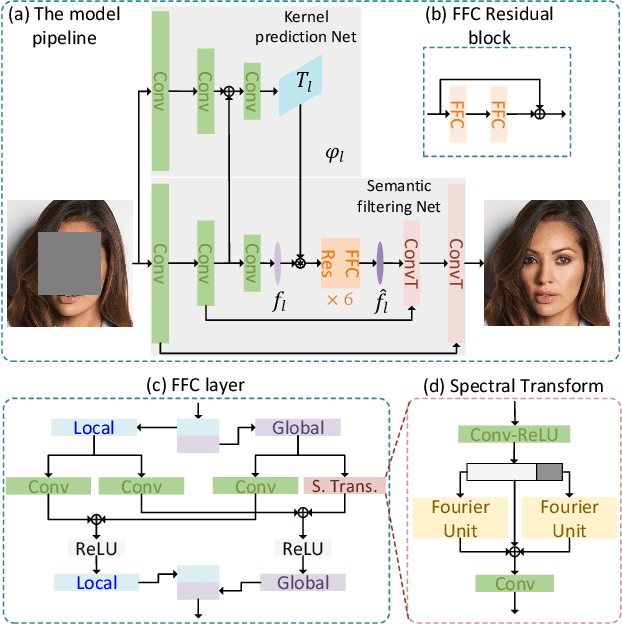
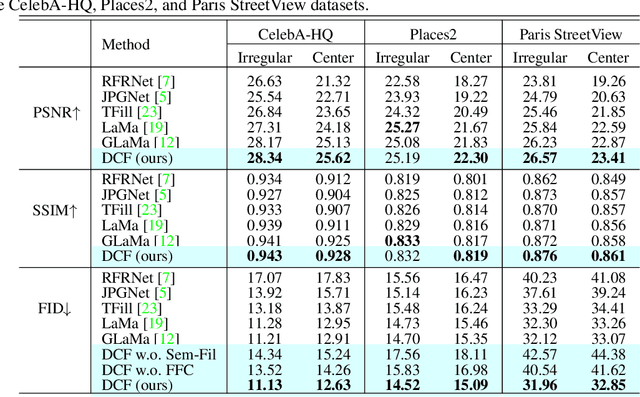
Given the recent advances with image-generating algorithms, deep image completion methods have made significant progress. However, state-of-art methods typically provide poor cross-scene generalization, and generated masked areas often contain blurry artifacts. Predictive filtering is a method for restoring images, which predicts the most effective kernels based on the input scene. Motivated by this approach, we address image completion as a filtering problem. Deep feature-level semantic filtering is introduced to fill in missing information, while preserving local structure and generating visually realistic content. In particular, a Dual-path Cooperative Filtering (DCF) model is proposed, where one path predicts dynamic kernels, and the other path extracts multi-level features by using Fast Fourier Convolution to yield semantically coherent reconstructions. Experiments on three challenging image completion datasets show that our proposed DCF outperforms state-of-art methods.
Disentangled Contrastive Collaborative Filtering
May 07, 2023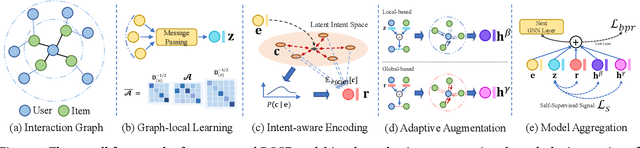
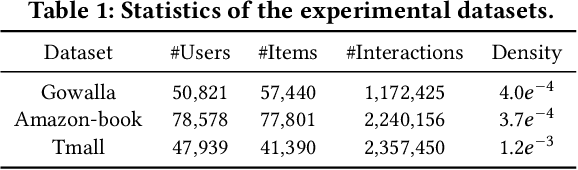
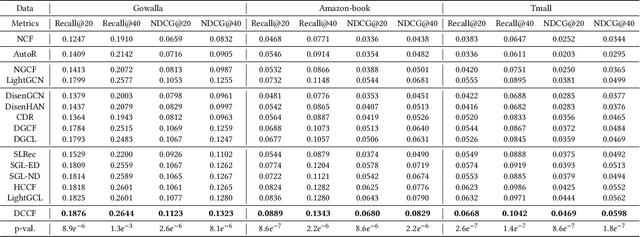
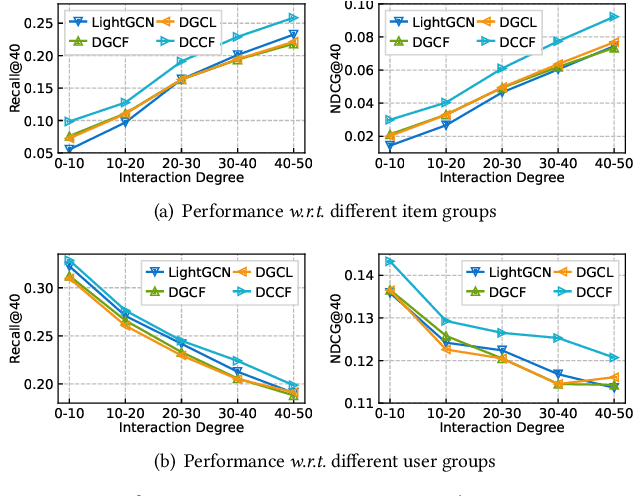
Recent studies show that graph neural networks (GNNs) are prevalent to model high-order relationships for collaborative filtering (CF). Towards this research line, graph contrastive learning (GCL) has exhibited powerful performance in addressing the supervision label shortage issue by learning augmented user and item representations. While many of them show their effectiveness, two key questions still remain unexplored: i) Most existing GCL-based CF models are still limited by ignoring the fact that user-item interaction behaviors are often driven by diverse latent intent factors (e.g., shopping for family party, preferred color or brand of products); ii) Their introduced non-adaptive augmentation techniques are vulnerable to noisy information, which raises concerns about the model's robustness and the risk of incorporating misleading self-supervised signals. In light of these limitations, we propose a Disentangled Contrastive Collaborative Filtering framework (DCCF) to realize intent disentanglement with self-supervised augmentation in an adaptive fashion. With the learned disentangled representations with global context, our DCCF is able to not only distill finer-grained latent factors from the entangled self-supervision signals but also alleviate the augmentation-induced noise. Finally, the cross-view contrastive learning task is introduced to enable adaptive augmentation with our parameterized interaction mask generator. Experiments on various public datasets demonstrate the superiority of our method compared to existing solutions. Our model implementation is released at the link https://github.com/HKUDS/DCCF.
Robust Natural Language Watermarking through Invariant Features
May 03, 2023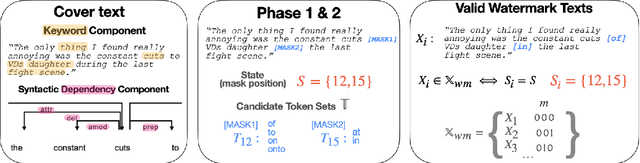
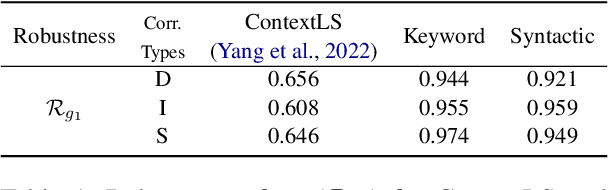
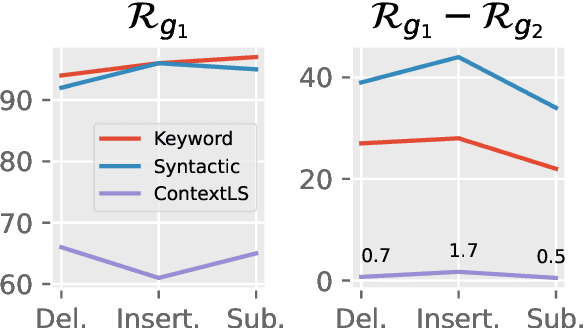
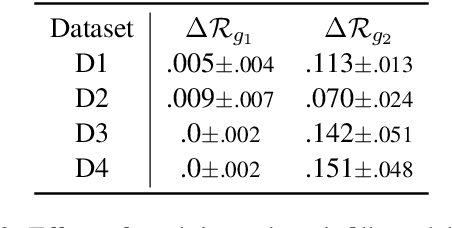
Recent years have witnessed a proliferation of valuable original natural language contents found in subscription-based media outlets, web novel platforms, and outputs of large language models. Without proper security measures, however, these contents are susceptible to illegal piracy and potential misuse. This calls for a secure watermarking system to guarantee copyright protection through leakage tracing or ownership identification. To effectively combat piracy and protect copyrights, a watermarking framework should be able not only to embed adequate bits of information but also extract the watermarks in a robust manner despite possible corruption. In this work, we explore ways to advance both payload and robustness by following a well-known proposition from image watermarking and identify features in natural language that are invariant to minor corruption. Through a systematic analysis of the possible sources of errors, we further propose a corruption-resistant infill model. Our full method improves upon the previous work on robustness by +16.8% point on average on four datasets, three corruption types, and two corruption ratios. Code available at https://github.com/bangawayoo/nlp-watermarking.