 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
OurDB: Ouroboric Domain Bridging for Multi-Target Domain Adaptive Semantic Segmentation
Mar 18, 2024
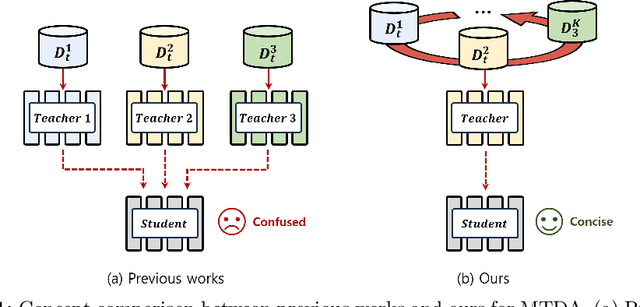
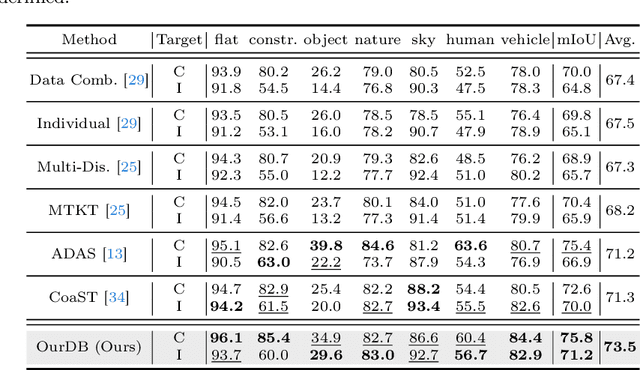
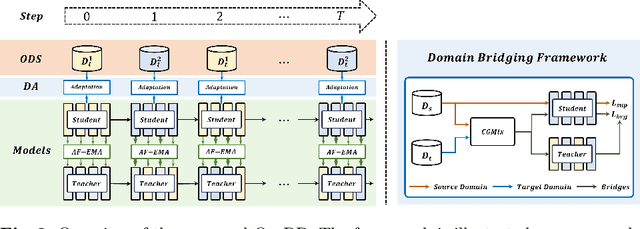
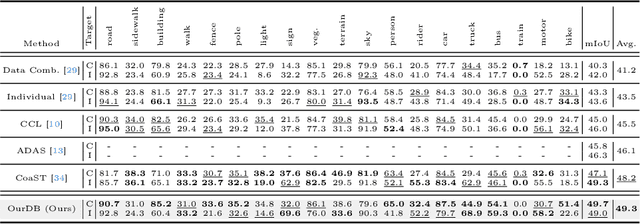
Multi-target domain adaptation (MTDA) for semantic segmentation poses a significant challenge, as it involves multiple target domains with varying distributions. The goal of MTDA is to minimize the domain discrepancies among a single source and multi-target domains, aiming to train a single model that excels across all target domains. Previous MTDA approaches typically employ multiple teacher architectures, where each teacher specializes in one target domain to simplify the task. However, these architectures hinder the student model from fully assimilating comprehensive knowledge from all target-specific teachers and escalate training costs with increasing target domains. In this paper, we propose an ouroboric domain bridging (OurDB) framework, offering an efficient solution to the MTDA problem using a single teacher architecture. This framework dynamically cycles through multiple target domains, aligning each domain individually to restrain the biased alignment problem, and utilizes Fisher information to minimize the forgetting of knowledge from previous target domains. We also propose a context-guided class-wise mixup (CGMix) that leverages contextual information tailored to diverse target contexts in MTDA. Experimental evaluations conducted on four urban driving datasets (i.e., GTA5, Cityscapes, IDD, and Mapillary) demonstrate the superiority of our method over existing state-of-the-art approaches.
SETA: Semantic-Aware Token Augmentation for Domain Generalization
Mar 18, 2024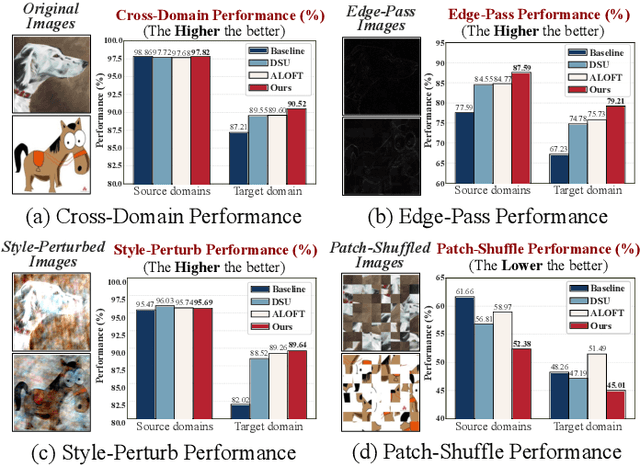
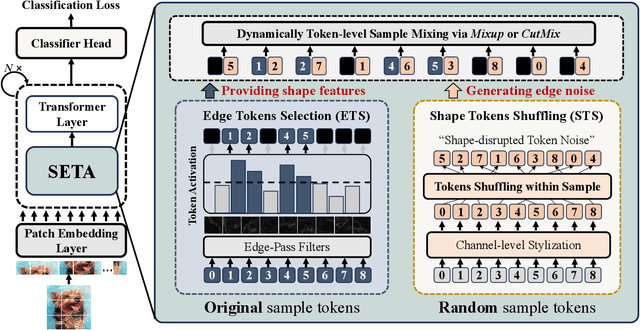
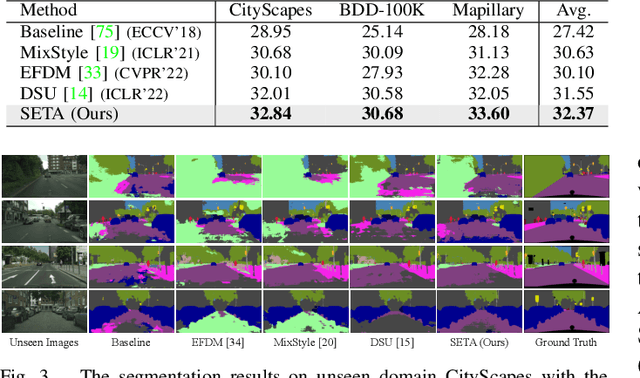
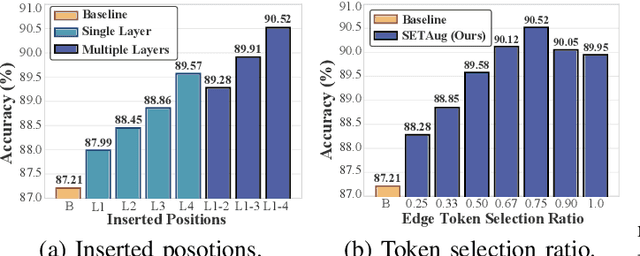
Domain generalization (DG) aims to enhance the model robustness against domain shifts without accessing target domains. A prevalent category of methods for DG is data augmentation, which focuses on generating virtual samples to simulate domain shifts. However, existing augmentation techniques in DG are mainly tailored for convolutional neural networks (CNNs), with limited exploration in token-based architectures, i.e., vision transformer (ViT) and multi-layer perceptrons (MLP) models. In this paper, we study the impact of prior CNN-based augmentation methods on token-based models, revealing their performance is suboptimal due to the lack of incentivizing the model to learn holistic shape information. To tackle the issue, we propose the SEmantic-aware Token Augmentation (SETA) method. SETA transforms token features by perturbing local edge cues while preserving global shape features, thereby enhancing the model learning of shape information. To further enhance the generalization ability of the model, we introduce two stylized variants of our method combined with two state-of-the-art style augmentation methods in DG. We provide a theoretical insight into our method, demonstrating its effectiveness in reducing the generalization risk bound. Comprehensive experiments on five benchmarks prove that our method achieves SOTA performances across various ViT and MLP architectures. Our code is available at https://github.com/lingeringlight/SETA.
NuGraph2: A Graph Neural Network for Neutrino Physics Event Reconstruction
Mar 18, 2024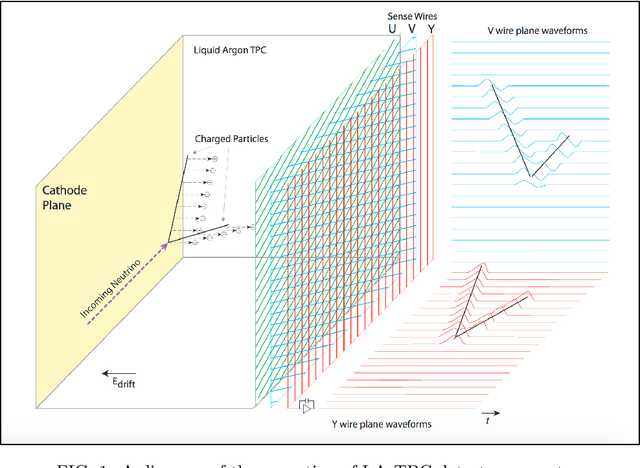
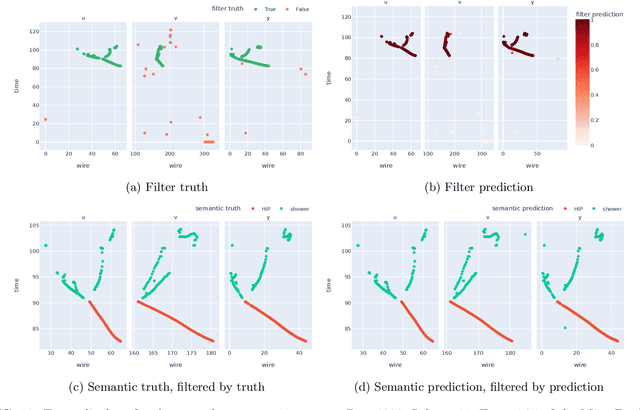
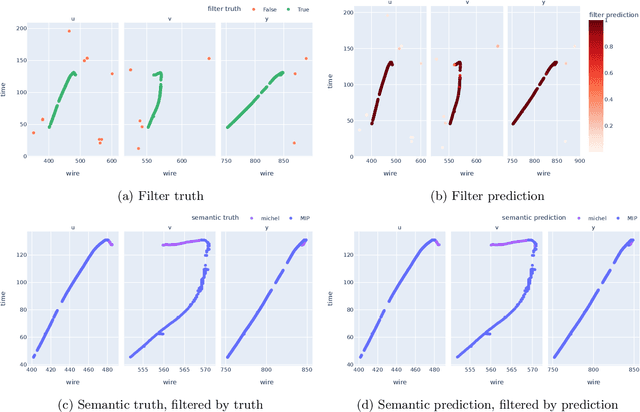
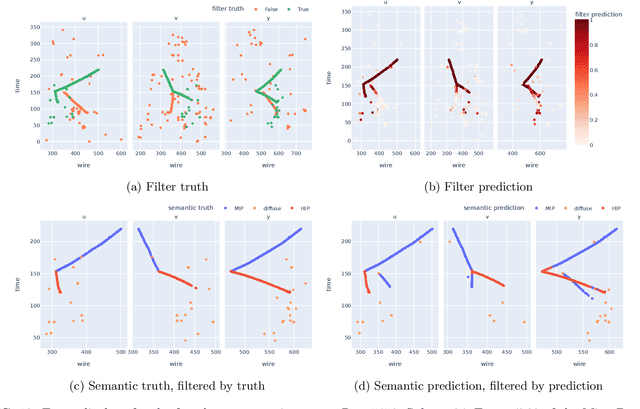
Liquid Argon Time Projection Chamber (LArTPC) detector technology offers a wealth of high-resolution information on particle interactions, and leveraging that information to its full potential requires sophisticated automated reconstruction techniques. This article describes NuGraph2, a Graph Neural Network (GNN) for low-level reconstruction of simulated neutrino interactions in a LArTPC detector. Simulated neutrino interactions in the MicroBooNE detector geometry are described as heterogeneous graphs, with energy depositions on each detector plane forming nodes on planar subgraphs. The network utilizes a multi-head attention message-passing mechanism to perform background filtering and semantic labelling on these graph nodes, identifying those associated with the primary physics interaction with 98.0\% efficiency and labelling them according to particle type with 94.9\% efficiency. The network operates directly on detector observables across multiple 2D representations, but utilizes a 3D-context-aware mechanism to encourage consistency between these representations. Model inference takes 0.12 s/event on a CPU, and 0.005 s/event batched on a GPU. This architecture is designed to be a general-purpose solution for particle reconstruction in neutrino physics, with the potential for deployment across a broad range of detector technologies, and offers a core convolution engine that can be leveraged for a variety of tasks beyond the two described in this article.
FlexCap: Generating Rich, Localized, and Flexible Captions in Images
Mar 18, 2024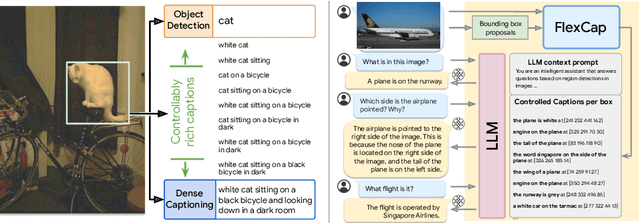

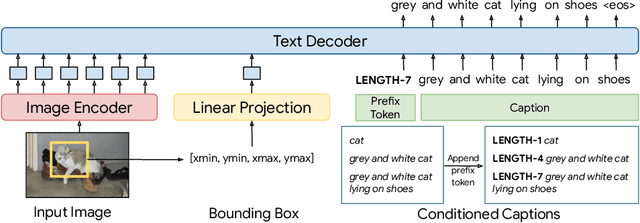

We introduce a versatile $\textit{flexible-captioning}$ vision-language model (VLM) capable of generating region-specific descriptions of varying lengths. The model, FlexCap, is trained to produce length-conditioned captions for input bounding boxes, and this allows control over the information density of its output, with descriptions ranging from concise object labels to detailed captions. To achieve this we create large-scale training datasets of image region descriptions of varying length, starting from captioned images. This flexible-captioning capability has several valuable applications. First, FlexCap demonstrates superior performance in dense captioning tasks on the Visual Genome dataset. Second, a visual question answering (VQA) system can be built by employing FlexCap to generate localized descriptions as inputs to a large language model. The resulting system achieves state-of-the-art zero-shot performance on a number of VQA datasets. We also demonstrate a $\textit{localize-then-describe}$ approach with FlexCap can be better at open-ended object detection than a $\textit{describe-then-localize}$ approach with other VLMs. We highlight a novel characteristic of FlexCap, which is its ability to extract diverse visual information through prefix conditioning. Finally, we qualitatively demonstrate FlexCap's broad applicability in tasks such as image labeling, object attribute recognition, and visual dialog. Project webpage: https://flex-cap.github.io .
A Deep Learning Method for Beat-Level Risk Analysis and Interpretation of Atrial Fibrillation Patients during Sinus Rhythm
Mar 18, 2024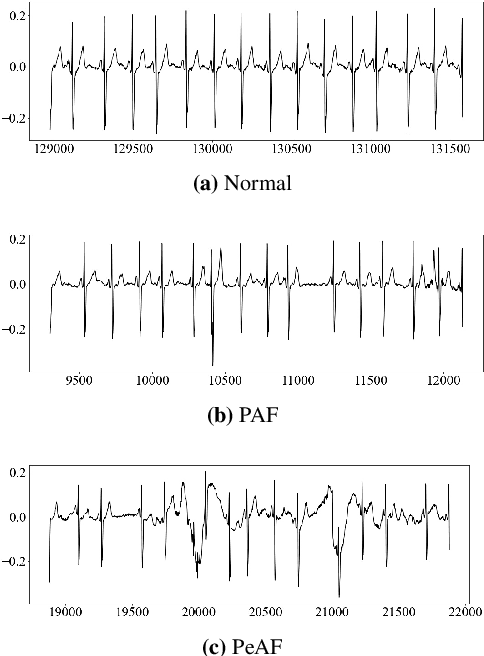
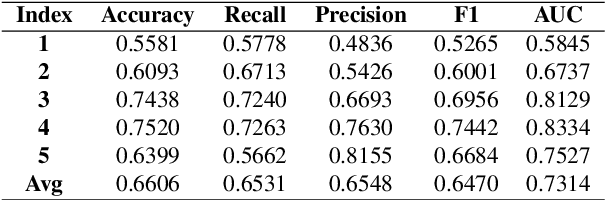
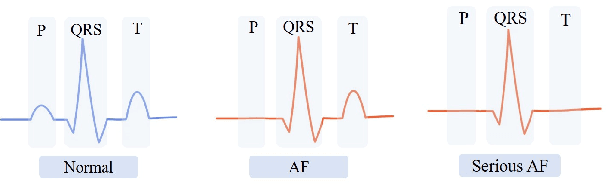

Atrial Fibrillation (AF) is a common cardiac arrhythmia. Many AF patients experience complications such as stroke and other cardiovascular issues. Early detection of AF is crucial. Existing algorithms can only distinguish ``AF rhythm in AF patients'' from ``sinus rhythm in normal individuals'' . However, AF patients do not always exhibit AF rhythm, posing a challenge for diagnosis when the AF rhythm is absent. To address this, this paper proposes a novel artificial intelligence (AI) algorithm to distinguish ``sinus rhythm in AF patients'' and ``sinus rhythm in normal individuals'' in beat-level. We introduce beat-level risk interpreters, trend risk interpreters, addressing the interpretability issues of deep learning models and the difficulty in explaining AF risk trends. Additionally, the beat-level information fusion decision is presented to enhance model accuracy. The experimental results demonstrate that the average AUC for single beats used as testing data from CPSC 2021 dataset is 0.7314. By employing 150 beats for information fusion decision algorithm, the average AUC can reach 0.7591. Compared to previous segment-level algorithms, we utilized beats as input, reducing data dimensionality and making the model more lightweight, facilitating deployment on portable medical devices. Furthermore, we draw new and interesting findings through average beat analysis and subgroup analysis, considering varying risk levels.
On the use of Silver Standard Data for Zero-shot Classification Tasks in Information Extraction
Mar 06, 2024The superior performance of supervised classification methods in the information extraction (IE) area heavily relies on a large amount of gold standard data. Recent zero-shot classification methods converted the task to other NLP tasks (e.g., textual entailment) and used off-the-shelf models of these NLP tasks to directly perform inference on the test data without using a large amount of IE annotation data. A potentially valuable by-product of these methods is the large-scale silver standard data, i.e., pseudo-labeled data by the off-the-shelf models of other NLP tasks. However, there is no further investigation into the use of these data. In this paper, we propose a new framework, Clean-LaVe, which aims to utilize silver standard data to enhance the zero-shot performance. Clean-LaVe includes four phases: (1) Obtaining silver data; (2) Identifying relatively clean data from silver data; (3) Finetuning the off-the-shelf model using clean data; (4) Inference on the test data. The experimental results show that Clean-LaVe can outperform the baseline by 5% and 6% on TACRED and Wiki80 dataset in the zero-shot relation classification task, and by 3%-7% on Smile (Korean and Polish) in the zero-shot cross-lingual relation classification task, and by 8% on ACE05-E+ in the zero-shot event argument classification task. The code is share in https://github.com/wjw136/Clean_LaVe.git.
Learning Neural Volumetric Pose Features for Camera Localization
Mar 19, 2024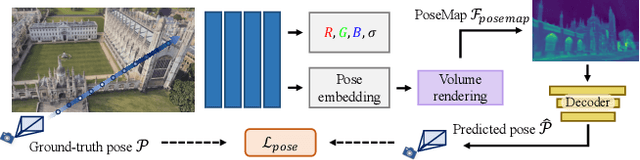

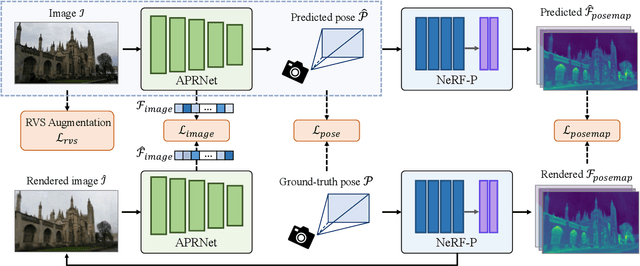
We introduce a novel neural volumetric pose feature, termed PoseMap, designed to enhance camera localization by encapsulating the information between images and the associated camera poses. Our framework leverages an Absolute Pose Regression (APR) architecture, together with an augmented NeRF module. This integration not only facilitates the generation of novel views to enrich the training dataset but also enables the learning of effective pose features. Additionally, we extend our architecture for self-supervised online alignment, allowing our method to be used and fine-tuned for unlabelled images within a unified framework. Experiments demonstrate that our method achieves 14.28% and 20.51% performance gain on average in indoor and outdoor benchmark scenes, outperforming existing APR methods with state-of-the-art accuracy.
The Era of Semantic Decoding
Mar 21, 2024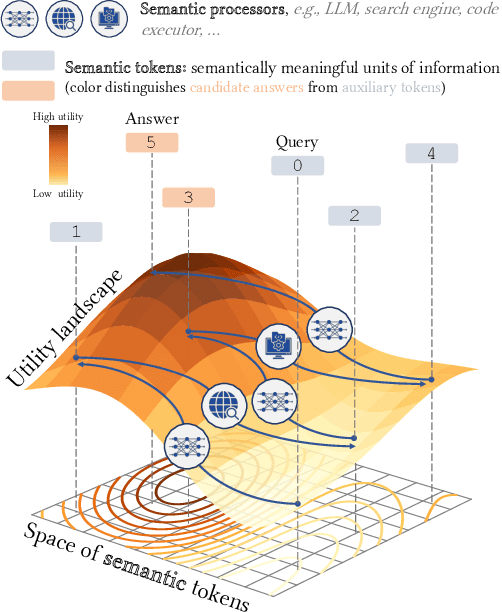
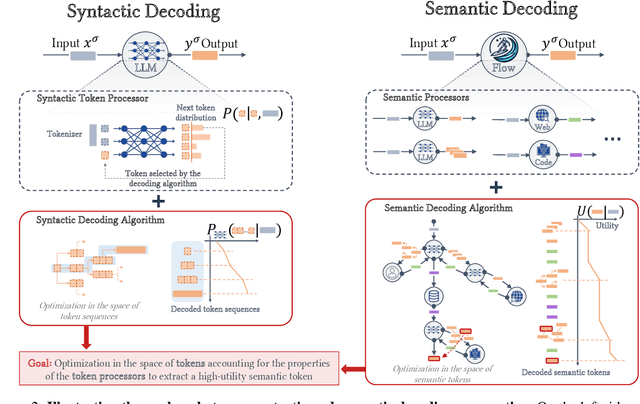
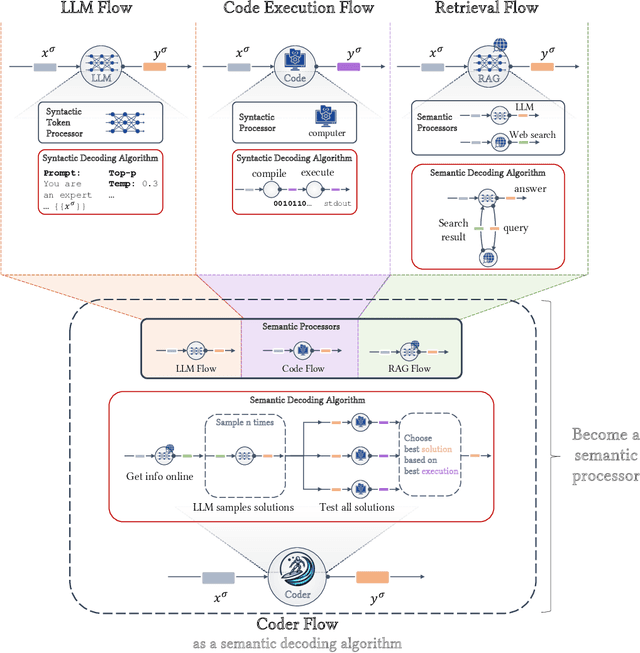
Recent work demonstrated great promise in the idea of orchestrating collaborations between LLMs, human input, and various tools to address the inherent limitations of LLMs. We propose a novel perspective called semantic decoding, which frames these collaborative processes as optimization procedures in semantic space. Specifically, we conceptualize LLMs as semantic processors that manipulate meaningful pieces of information that we call semantic tokens (known thoughts). LLMs are among a large pool of other semantic processors, including humans and tools, such as search engines or code executors. Collectively, semantic processors engage in dynamic exchanges of semantic tokens to progressively construct high-utility outputs. We refer to these orchestrated interactions among semantic processors, optimizing and searching in semantic space, as semantic decoding algorithms. This concept draws a direct parallel to the well-studied problem of syntactic decoding, which involves crafting algorithms to best exploit auto-regressive language models for extracting high-utility sequences of syntactic tokens. By focusing on the semantic level and disregarding syntactic details, we gain a fresh perspective on the engineering of AI systems, enabling us to imagine systems with much greater complexity and capabilities. In this position paper, we formalize the transition from syntactic to semantic tokens as well as the analogy between syntactic and semantic decoding. Subsequently, we explore the possibilities of optimizing within the space of semantic tokens via semantic decoding algorithms. We conclude with a list of research opportunities and questions arising from this fresh perspective. The semantic decoding perspective offers a powerful abstraction for search and optimization directly in the space of meaningful concepts, with semantic tokens as the fundamental units of a new type of computation.
A Unified Framework for Model Editing
Mar 21, 2024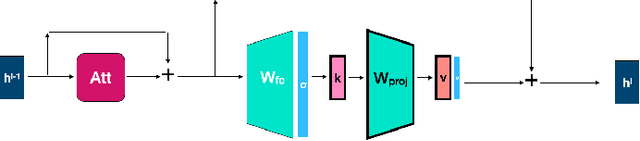
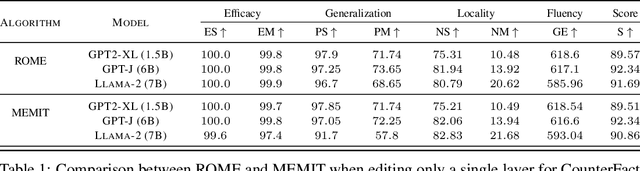
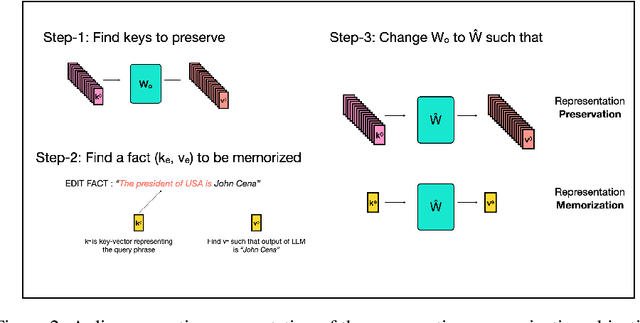
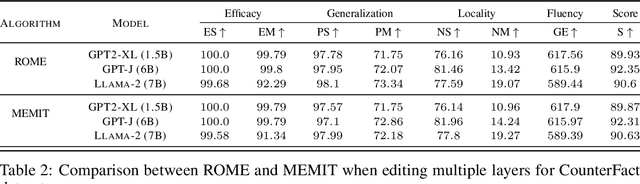
Model editing is a growing area focused on updating the knowledge embedded within models. Among the various methodologies, ROME and MEMIT stand out as leading "locate-and-edit" model editing techniques. While MEMIT enables batched editing of memories, ROME is limited to changing one fact at a time. This paper introduces a unifying framework that brings ROME and MEMIT under a single conceptual umbrella, optimizing for the same goal, which we call the "preservation-memorization" objective. This objective aims to preserve the representations of certain selected vectors while memorizing the representations of new factual information. Specifically, ROME optimizes this objective using an equality constraint, whereas MEMIT employs a more flexible least-square constraint. In addition to making batched edits, MEMIT also edits the model at multiple layers. We disentangle the distribution of edits to multiple layers from the optimization objective of MEMIT and show that these edit-distribution algorithms should be considered separate entities worthy of their own line of research. Finally, we present EMMET - an Equality-constrained Mass Model Editing algorithm for Transformers, a new batched memory-editing algorithm. With EMMET, we present a closed form solution for the equality-constrained version of the preservation-memorization objective. We show that EMMET is able to perform batched-edits on par with MEMIT up to a batch-size of 256 and discuss the challenges in stabilizing EMMET. By articulating the "locate-and-edit" model editing algorithms under a simple conceptual framework of "preservation-memorization", we aim to bridge the gap between intuition and mathematics and hope to simplify the journey for future researchers in model editing.
MaskSAM: Towards Auto-prompt SAM with Mask Classification for Medical Image Segmentation
Mar 21, 2024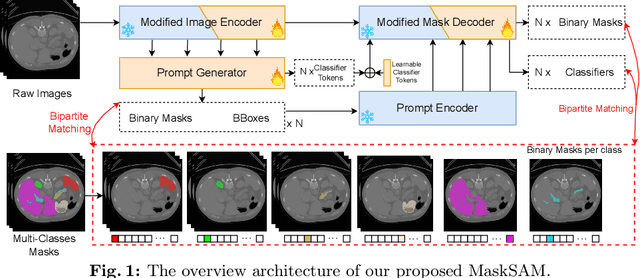
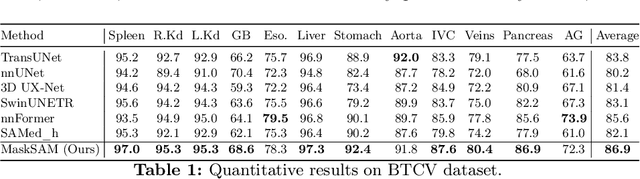
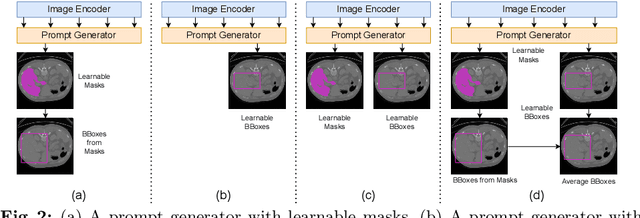
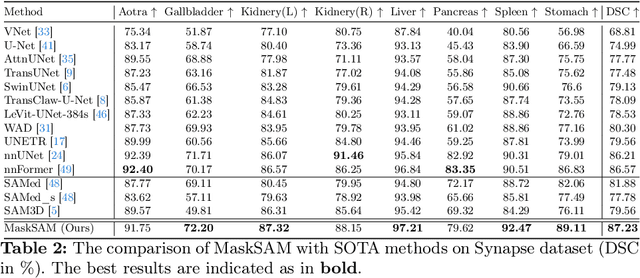
Segment Anything Model~(SAM), a prompt-driven foundation model for natural image segmentation, has demonstrated impressive zero-shot performance. However, SAM does not work when directly applied to medical image segmentation tasks, since SAM lacks the functionality to predict semantic labels for predicted masks and needs to provide extra prompts, such as points or boxes, to segment target regions. Meanwhile, there is a huge gap between 2D natural images and 3D medical images, so the performance of SAM is imperfect for medical image segmentation tasks. Following the above issues, we propose MaskSAM, a novel mask classification prompt-free SAM adaptation framework for medical image segmentation. We design a prompt generator combined with the image encoder in SAM to generate a set of auxiliary classifier tokens, auxiliary binary masks, and auxiliary bounding boxes. Each pair of auxiliary mask and box prompts, which can solve the requirements of extra prompts, is associated with class label predictions by the sum of the auxiliary classifier token and the learnable global classifier tokens in the mask decoder of SAM to solve the predictions of semantic labels. Meanwhile, we design a 3D depth-convolution adapter for image embeddings and a 3D depth-MLP adapter for prompt embeddings. We inject one of them into each transformer block in the image encoder and mask decoder to enable pre-trained 2D SAM models to extract 3D information and adapt to 3D medical images. Our method achieves state-of-the-art performance on AMOS2022, 90.52% Dice, which improved by 2.7% compared to nnUNet. Our method surpasses nnUNet by 1.7% on ACDC and 1.0% on Synapse datasets.