 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Temporal and Heterogeneous Graph Neural Network for Financial Time Series Prediction
May 09, 2023
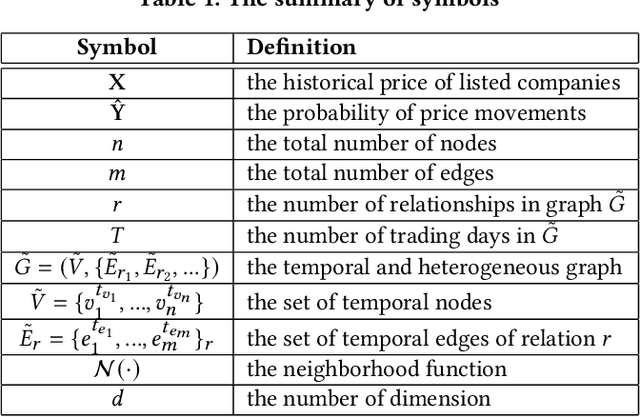
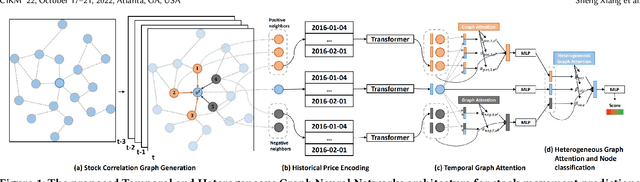
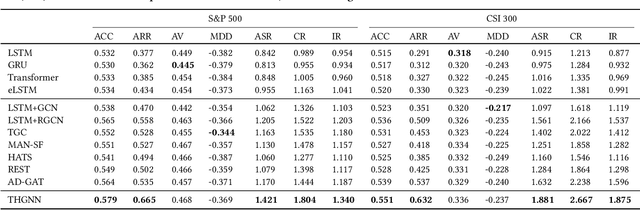
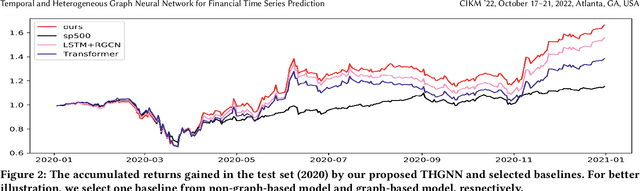
The price movement prediction of stock market has been a classical yet challenging problem, with the attention of both economists and computer scientists. In recent years, graph neural network has significantly improved the prediction performance by employing deep learning on company relations. However, existing relation graphs are usually constructed by handcraft human labeling or nature language processing, which are suffering from heavy resource requirement and low accuracy. Besides, they cannot effectively response to the dynamic changes in relation graphs. Therefore, in this paper, we propose a temporal and heterogeneous graph neural network-based (THGNN) approach to learn the dynamic relations among price movements in financial time series. In particular, we first generate the company relation graph for each trading day according to their historic price. Then we leverage a transformer encoder to encode the price movement information into temporal representations. Afterward, we propose a heterogeneous graph attention network to jointly optimize the embeddings of the financial time series data by transformer encoder and infer the probability of target movements. Finally, we conduct extensive experiments on the stock market in the United States and China. The results demonstrate the effectiveness and superior performance of our proposed methods compared with state-of-the-art baselines. Moreover, we also deploy the proposed THGNN in a real-world quantitative algorithm trading system, the accumulated portfolio return obtained by our method significantly outperforms other baselines.
Robust Acoustic and Semantic Contextual Biasing in Neural Transducers for Speech Recognition
May 09, 2023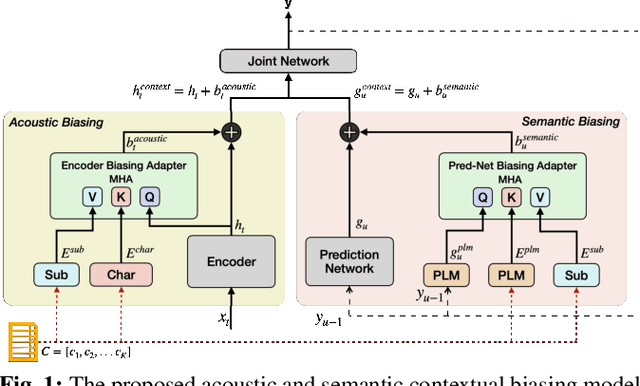
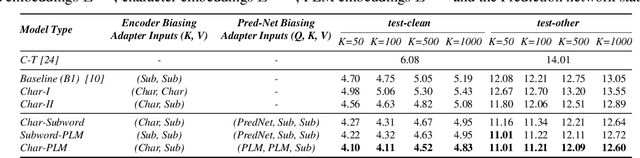

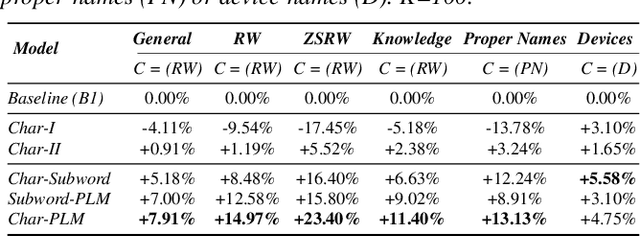
Attention-based contextual biasing approaches have shown significant improvements in the recognition of generic and/or personal rare-words in End-to-End Automatic Speech Recognition (E2E ASR) systems like neural transducers. These approaches employ cross-attention to bias the model towards specific contextual entities injected as bias-phrases to the model. Prior approaches typically relied on subword encoders for encoding the bias phrases. However, subword tokenizations are coarse and fail to capture granular pronunciation information which is crucial for biasing based on acoustic similarity. In this work, we propose to use lightweight character representations to encode fine-grained pronunciation features to improve contextual biasing guided by acoustic similarity between the audio and the contextual entities (termed acoustic biasing). We further integrate pretrained neural language model (NLM) based encoders to encode the utterance's semantic context along with contextual entities to perform biasing informed by the utterance's semantic context (termed semantic biasing). Experiments using a Conformer Transducer model on the Librispeech dataset show a 4.62% - 9.26% relative WER improvement on different biasing list sizes over the baseline contextual model when incorporating our proposed acoustic and semantic biasing approach. On a large-scale in-house dataset, we observe 7.91% relative WER improvement compared to our baseline model. On tail utterances, the improvements are even more pronounced with 36.80% and 23.40% relative WER improvements on Librispeech rare words and an in-house testset respectively.
Communication-Robust Multi-Agent Learning by Adaptable Auxiliary Multi-Agent Adversary Generation
May 09, 2023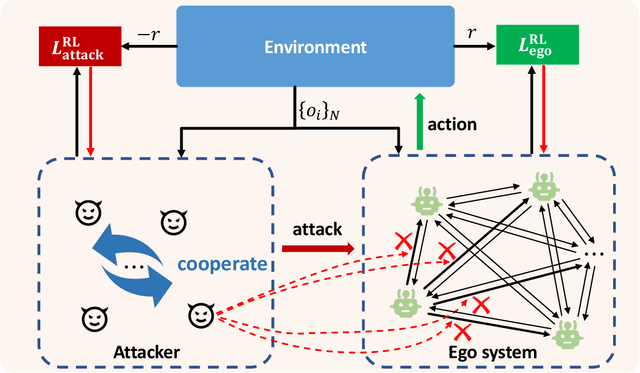
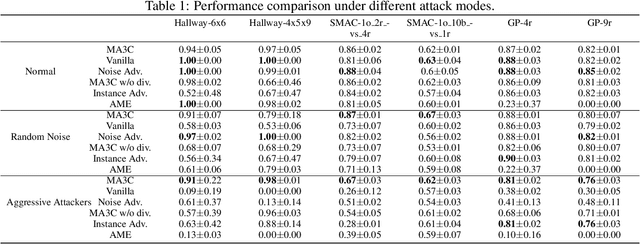
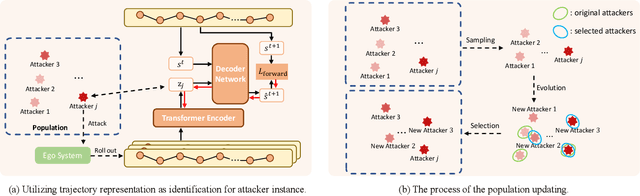
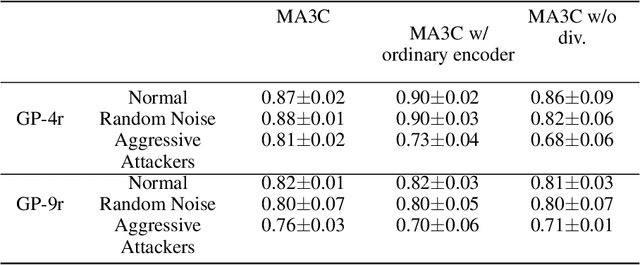
Communication can promote coordination in cooperative Multi-Agent Reinforcement Learning (MARL). Nowadays, existing works mainly focus on improving the communication efficiency of agents, neglecting that real-world communication is much more challenging as there may exist noise or potential attackers. Thus the robustness of the communication-based policies becomes an emergent and severe issue that needs more exploration. In this paper, we posit that the ego system trained with auxiliary adversaries may handle this limitation and propose an adaptable method of Multi-Agent Auxiliary Adversaries Generation for robust Communication, dubbed MA3C, to obtain a robust communication-based policy. In specific, we introduce a novel message-attacking approach that models the learning of the auxiliary attacker as a cooperative problem under a shared goal to minimize the coordination ability of the ego system, with which every information channel may suffer from distinct message attacks. Furthermore, as naive adversarial training may impede the generalization ability of the ego system, we design an attacker population generation approach based on evolutionary learning. Finally, the ego system is paired with an attacker population and then alternatively trained against the continuously evolving attackers to improve its robustness, meaning that both the ego system and the attackers are adaptable. Extensive experiments on multiple benchmarks indicate that our proposed MA3C provides comparable or better robustness and generalization ability than other baselines.
MMViT: Multiscale Multiview Vision Transformers
Apr 28, 2023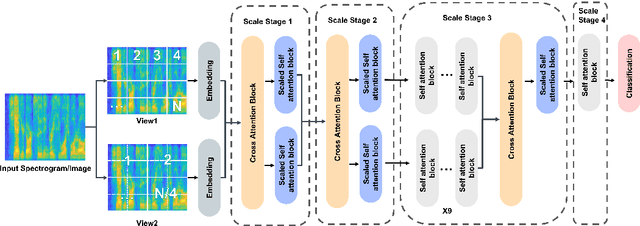
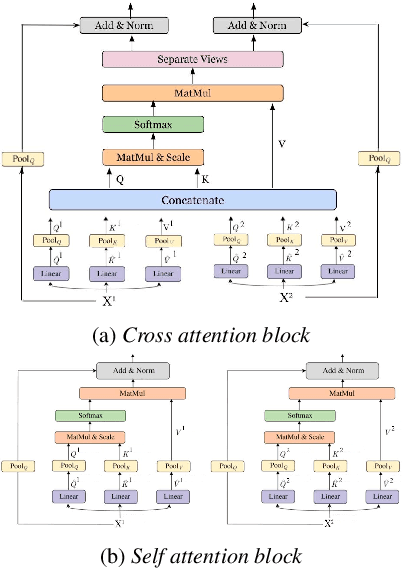
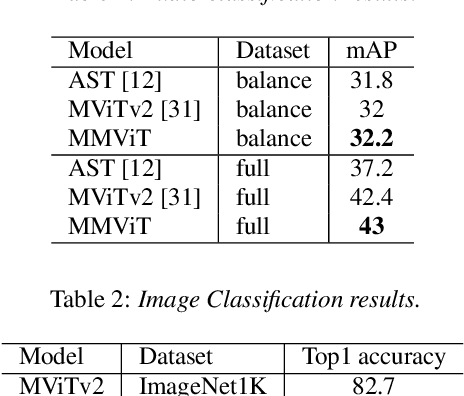
We present Multiscale Multiview Vision Transformers (MMViT), which introduces multiscale feature maps and multiview encodings to transformer models. Our model encodes different views of the input signal and builds several channel-resolution feature stages to process the multiple views of the input at different resolutions in parallel. At each scale stage, we use a cross-attention block to fuse information across different views. This enables the MMViT model to acquire complex high-dimensional representations of the input at different resolutions. The proposed model can serve as a backbone model in multiple domains. We demonstrate the effectiveness of MMViT on audio and image classification tasks, achieving state-of-the-art results.
WiSwarm: Age-of-Information-based Wireless Networking for Collaborative Teams of UAVs
Dec 06, 2022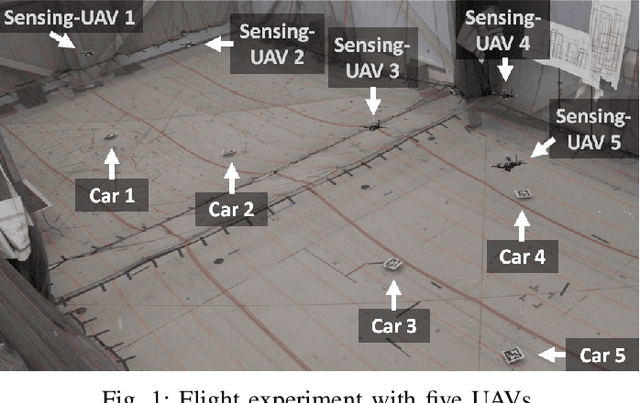
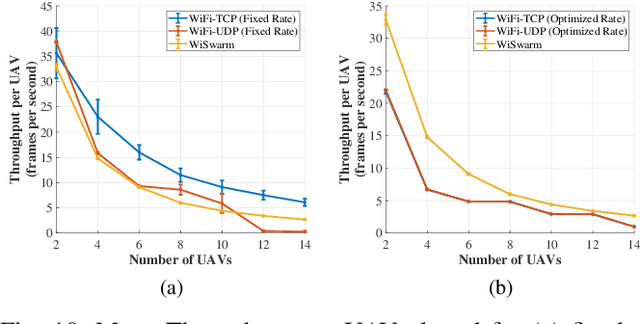
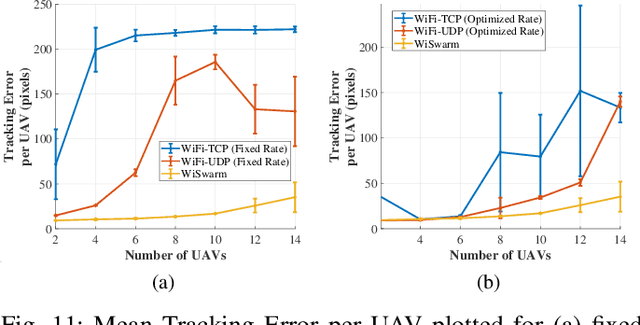

The Age-of-Information (AoI) metric has been widely studied in the theoretical communication networks and queuing systems literature. However, experimental evaluation of its applicability to complex real-world time-sensitive systems is largely lacking. In this work, we develop, implement, and evaluate an AoI-based application layer middleware that enables the customization of WiFi networks to the needs of time-sensitive applications. By controlling the storage and flow of information in the underlying WiFi network, our middleware can: (i) prevent packet collisions; (ii) discard stale packets that are no longer useful; and (iii) dynamically prioritize the transmission of the most relevant information. To demonstrate the benefits of our middleware, we implement a mobility tracking application using a swarm of UAVs communicating with a central controller via WiFi. Our experimental results show that, when compared to WiFi-UDP/WiFi-TCP, the middleware can improve information freshness by a factor of 109x/48x and tracking accuracy by a factor of 4x/6x, respectively. Most importantly, our results also show that the performance gains of our approach increase as the system scales and/or the traffic load increases.
Voxel-wise classification for porosity investigation of additive manufactured parts with 3D unsupervised and (deeply) supervised neural networks
May 13, 2023
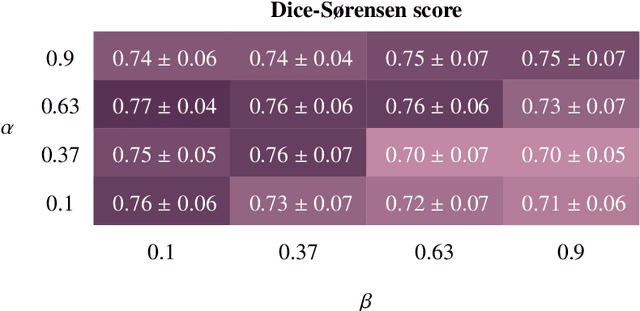


Additive Manufacturing (AM) has emerged as a manufacturing process that allows the direct production of samples from digital models. To ensure that quality standards are met in all manufactured samples of a batch, X-ray computed tomography (X-CT) is often used combined with automated anomaly detection. For the latter, deep learning (DL) anomaly detection techniques are increasingly, as they can be trained to be robust to the material being analysed and resilient towards poor image quality. Unfortunately, most recent and popular DL models have been developed for 2D image processing, thereby disregarding valuable volumetric information. This study revisits recent supervised (UNet, UNet++, UNet 3+, MSS-UNet) and unsupervised (VAE, ceVAE, gmVAE, vqVAE) DL models for porosity analysis of AM samples from X-CT images and extends them to accept 3D input data with a 3D-patch pipeline for lower computational requirements, improved efficiency and generalisability. The supervised models were trained using the Focal Tversky loss to address class imbalance that arises from the low porosity in the training datasets. The output of the unsupervised models is post-processed to reduce misclassifications caused by their inability to adequately represent the object surface. The findings were cross-validated in a 5-fold fashion and include: a performance benchmark of the DL models, an evaluation of the post-processing algorithm, an evaluation of the effect of training supervised models with the output of unsupervised models. In a final performance benchmark on a test set with poor image quality, the best performing supervised model was MSS-UNet with an average precision of 0.808 $\pm$ 0.013, while the best unsupervised model was the post-processed ceVAE with 0.935 $\pm$ 0.001. The VAE/ceVAE models demonstrated superior capabilities, particularly when leveraging post-processing techniques.
Instruction-ViT: Multi-Modal Prompts for Instruction Learning in ViT
Apr 29, 2023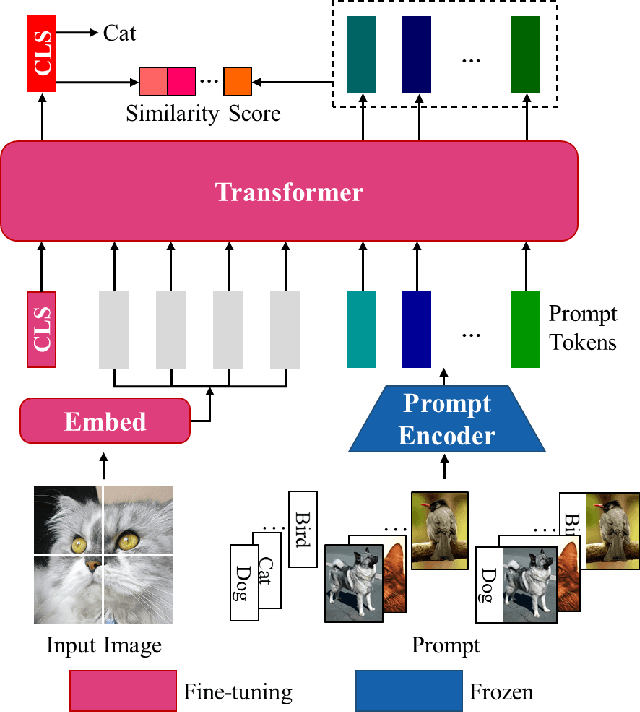
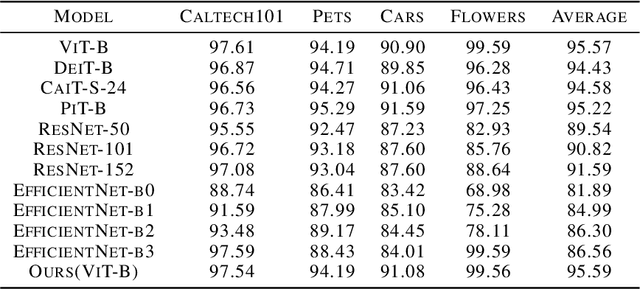


Prompts have been proven to play a crucial role in large language models, and in recent years, vision models have also been using prompts to improve scalability for multiple downstream tasks. In this paper, we focus on adapting prompt design based on instruction tuning into a visual transformer model for image classification which we called Instruction-ViT. The key idea is to implement multi-modal prompts (text or image prompt) related to category information to guide the fine-tuning of the model. Based on the experiments of several image captionining tasks, the performance and domain adaptability were improved. Our work provided an innovative strategy to fuse multi-modal prompts with better performance and faster adaptability for visual classification models.
Deep Unsupervised Learning for 3D ALS Point Clouds Change Detection
May 05, 2023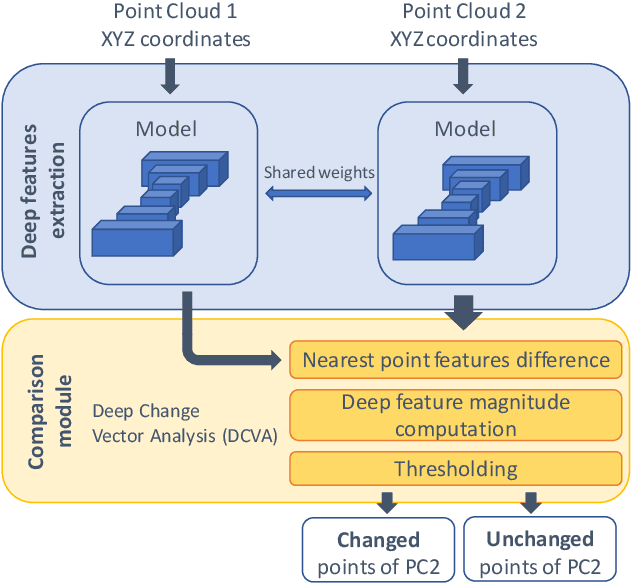


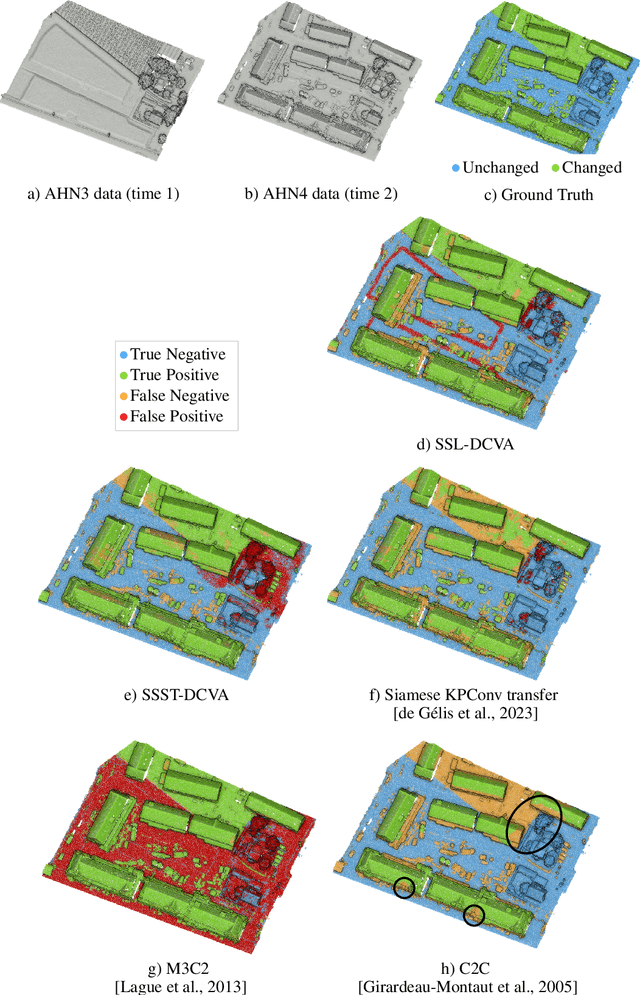
Change detection from traditional optical images has limited capability to model the changes in the height or shape of objects. Change detection using 3D point cloud aerial LiDAR survey data can fill this gap by providing critical depth information. While most existing machine learning based 3D point cloud change detection methods are supervised, they severely depend on the availability of annotated training data, which is in practice a critical point. To circumnavigate this dependence, we propose an unsupervised 3D point cloud change detection method mainly based on self-supervised learning using deep clustering and contrastive learning. The proposed method also relies on an adaptation of deep change vector analysis to 3D point cloud via nearest point comparison. Experiments conducted on a publicly available real dataset show that the proposed method obtains higher performance in comparison to the traditional unsupervised methods, with a gain of about 9% in mean accuracy (to reach more than 85%). Thus, it appears to be a relevant choice in scenario where prior knowledge (labels) is not ensured.
Human Attention-Guided Explainable Artificial Intelligence for Computer Vision Models
May 05, 2023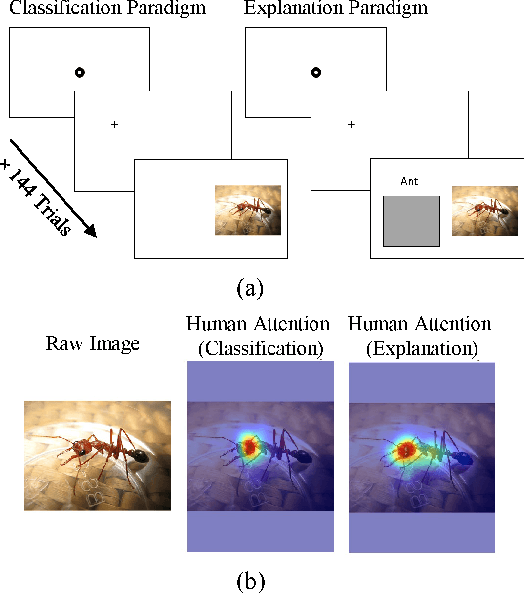
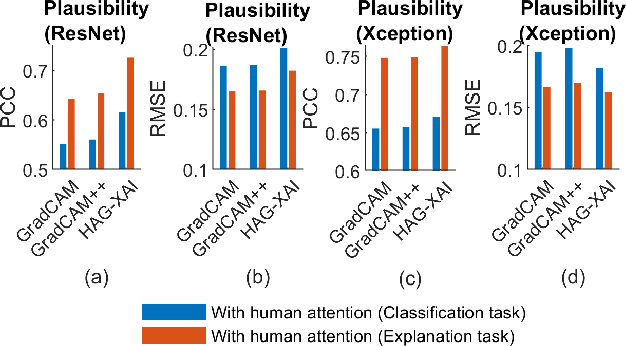
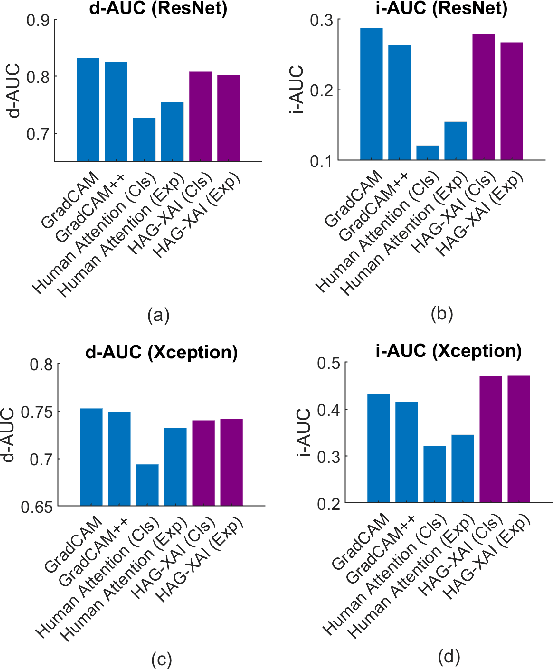
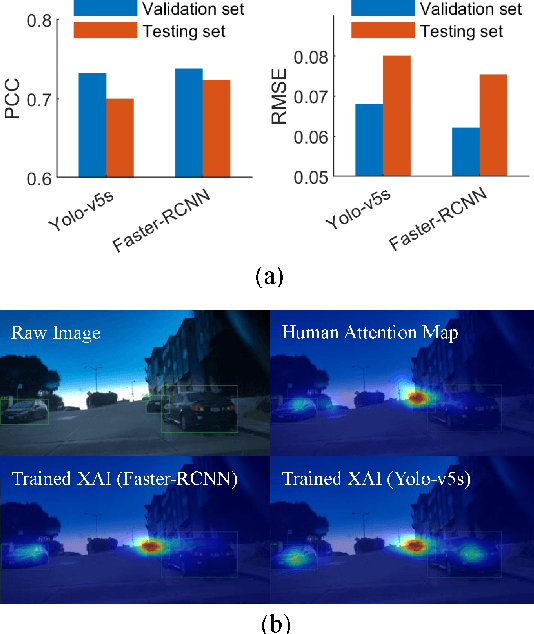
We examined whether embedding human attention knowledge into saliency-based explainable AI (XAI) methods for computer vision models could enhance their plausibility and faithfulness. We first developed new gradient-based XAI methods for object detection models to generate object-specific explanations by extending the current methods for image classification models. Interestingly, while these gradient-based methods worked well for explaining image classification models, when being used for explaining object detection models, the resulting saliency maps generally had lower faithfulness than human attention maps when performing the same task. We then developed Human Attention-Guided XAI (HAG-XAI) to learn from human attention how to best combine explanatory information from the models to enhance explanation plausibility by using trainable activation functions and smoothing kernels to maximize XAI saliency map's similarity to human attention maps. While for image classification models, HAG-XAI enhanced explanation plausibility at the expense of faithfulness, for object detection models it enhanced plausibility and faithfulness simultaneously and outperformed existing methods. The learned functions were model-specific, well generalizable to other databases.
HiPool: Modeling Long Documents Using Graph Neural Networks
May 05, 2023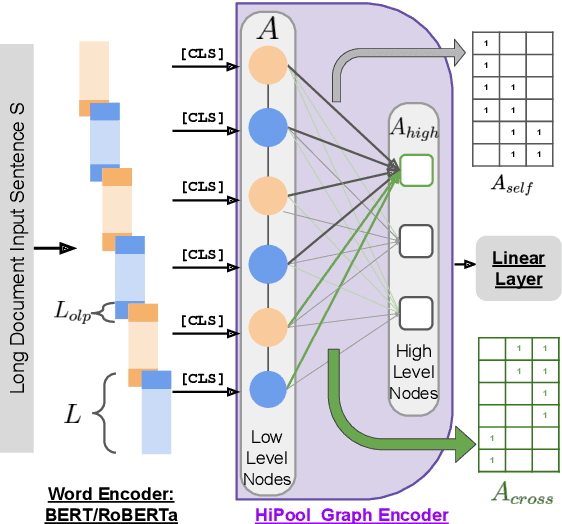
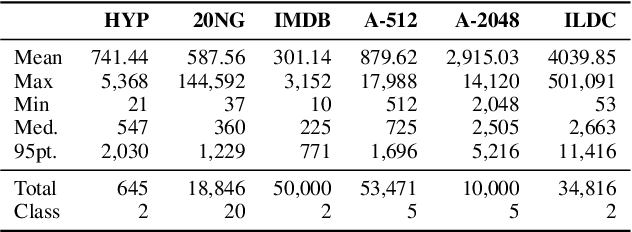
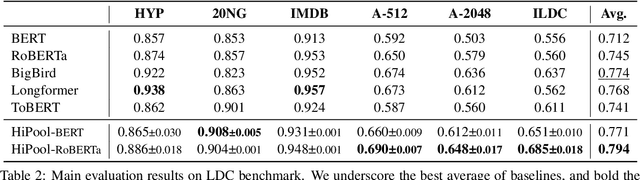
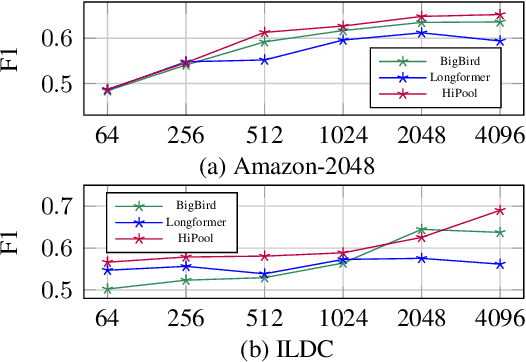
Encoding long sequences in Natural Language Processing (NLP) is a challenging problem. Though recent pretraining language models achieve satisfying performances in many NLP tasks, they are still restricted by a pre-defined maximum length, making them challenging to be extended to longer sequences. So some recent works utilize hierarchies to model long sequences. However, most of them apply sequential models for upper hierarchies, suffering from long dependency issues. In this paper, we alleviate these issues through a graph-based method. We first chunk the sequence with a fixed length to model the sentence-level information. We then leverage graphs to model intra- and cross-sentence correlations with a new attention mechanism. Additionally, due to limited standard benchmarks for long document classification (LDC), we propose a new challenging benchmark, totaling six datasets with up to 53k samples and 4034 average tokens' length. Evaluation shows our model surpasses competitive baselines by 2.6% in F1 score, and 4.8% on the longest sequence dataset. Our method is shown to outperform hierarchical sequential models with better performance and scalability, especially for longer sequences.