 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Fairness in Image Search: A Study of Occupational Stereotyping in Image Retrieval and its Debiasing
May 06, 2023



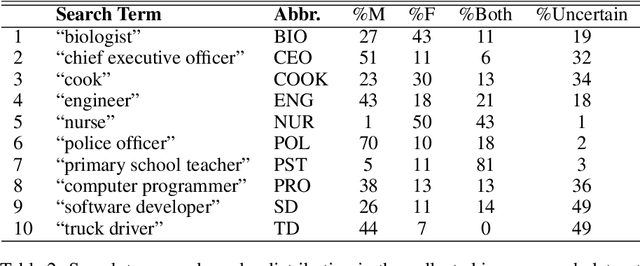
Multi-modal search engines have experienced significant growth and widespread use in recent years, making them the second most common internet use. While search engine systems offer a range of services, the image search field has recently become a focal point in the information retrieval community, as the adage goes, "a picture is worth a thousand words". Although popular search engines like Google excel at image search accuracy and agility, there is an ongoing debate over whether their search results can be biased in terms of gender, language, demographics, socio-cultural aspects, and stereotypes. This potential for bias can have a significant impact on individuals' perceptions and influence their perspectives. In this paper, we present our study on bias and fairness in web search, with a focus on keyword-based image search. We first discuss several kinds of biases that exist in search systems and why it is important to mitigate them. We narrow down our study to assessing and mitigating occupational stereotypes in image search, which is a prevalent fairness issue in image retrieval. For the assessment of stereotypes, we take gender as an indicator. We explore various open-source and proprietary APIs for gender identification from images. With these, we examine the extent of gender bias in top-tanked image search results obtained for several occupational keywords. To mitigate the bias, we then propose a fairness-aware re-ranking algorithm that optimizes (a) relevance of the search result with the keyword and (b) fairness w.r.t genders identified. We experiment on 100 top-ranked images obtained for 10 occupational keywords and consider random re-ranking and re-ranking based on relevance as baselines. Our experimental results show that the fairness-aware re-ranking algorithm produces rankings with better fairness scores and competitive relevance scores than the baselines.
An Information-Theoretic Approach to Transferability in Task Transfer Learning
Dec 20, 2022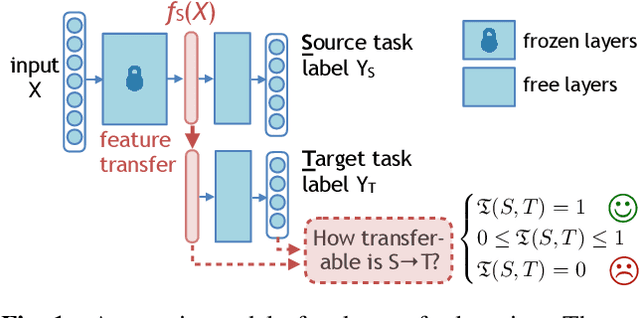
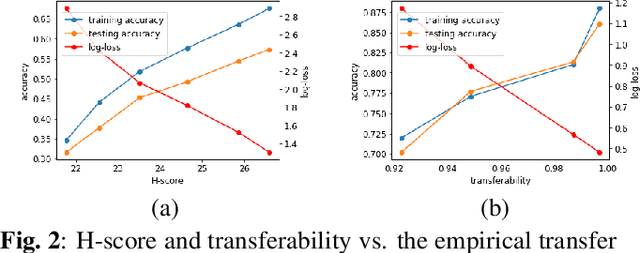
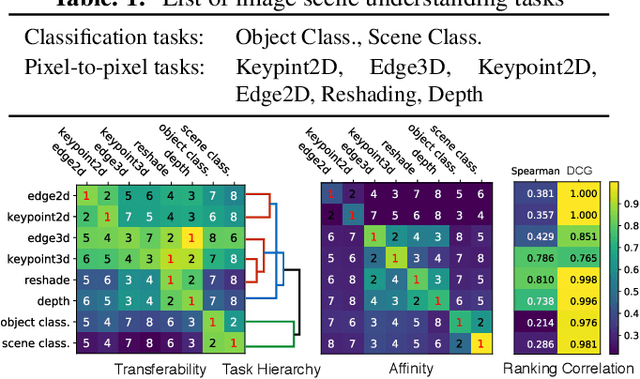
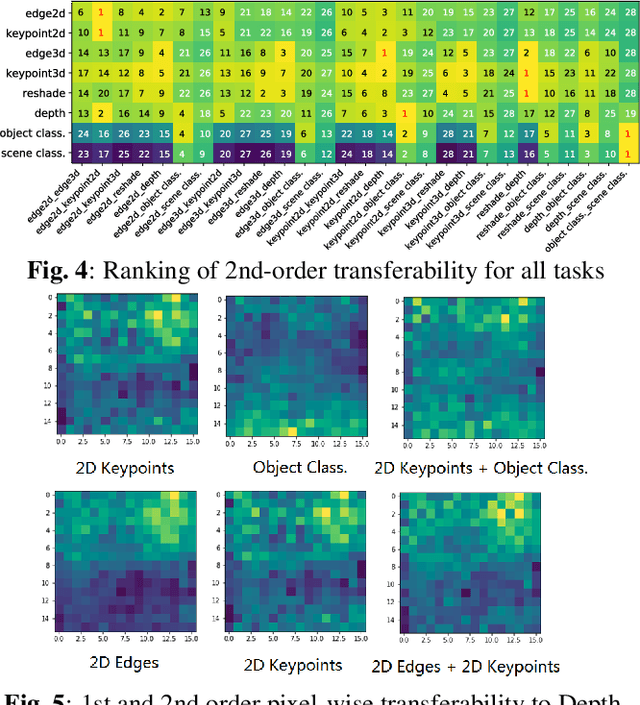
Task transfer learning is a popular technique in image processing applications that uses pre-trained models to reduce the supervision cost of related tasks. An important question is to determine task transferability, i.e. given a common input domain, estimating to what extent representations learned from a source task can help in learning a target task. Typically, transferability is either measured experimentally or inferred through task relatedness, which is often defined without a clear operational meaning. In this paper, we present a novel metric, H-score, an easily-computable evaluation function that estimates the performance of transferred representations from one task to another in classification problems using statistical and information theoretic principles. Experiments on real image data show that our metric is not only consistent with the empirical transferability measurement, but also useful to practitioners in applications such as source model selection and task transfer curriculum learning.
A Unified HDR Imaging Method with Pixel and Patch Level
Apr 17, 2023
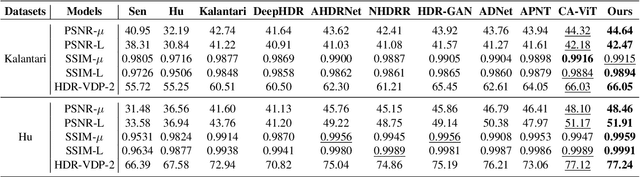
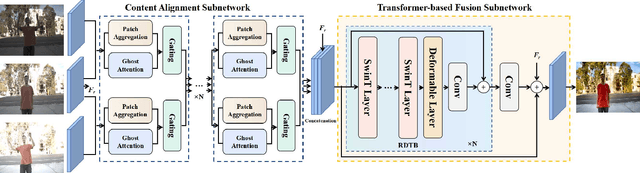
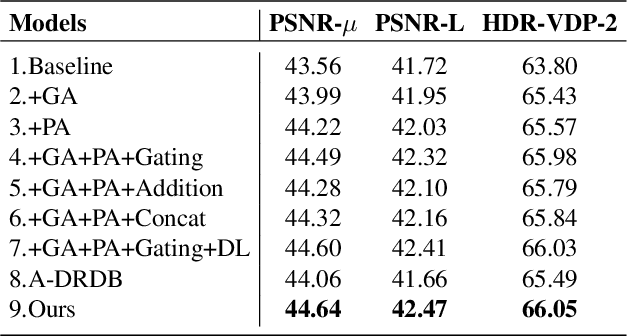
Mapping Low Dynamic Range (LDR) images with different exposures to High Dynamic Range (HDR) remains nontrivial and challenging on dynamic scenes due to ghosting caused by object motion or camera jitting. With the success of Deep Neural Networks (DNNs), several DNNs-based methods have been proposed to alleviate ghosting, they cannot generate approving results when motion and saturation occur. To generate visually pleasing HDR images in various cases, we propose a hybrid HDR deghosting network, called HyHDRNet, to learn the complicated relationship between reference and non-reference images. The proposed HyHDRNet consists of a content alignment subnetwork and a Transformer-based fusion subnetwork. Specifically, to effectively avoid ghosting from the source, the content alignment subnetwork uses patch aggregation and ghost attention to integrate similar content from other non-reference images with patch level and suppress undesired components with pixel level. To achieve mutual guidance between patch-level and pixel-level, we leverage a gating module to sufficiently swap useful information both in ghosted and saturated regions. Furthermore, to obtain a high-quality HDR image, the Transformer-based fusion subnetwork uses a Residual Deformable Transformer Block (RDTB) to adaptively merge information for different exposed regions. We examined the proposed method on four widely used public HDR image deghosting datasets. Experiments demonstrate that HyHDRNet outperforms state-of-the-art methods both quantitatively and qualitatively, achieving appealing HDR visualization with unified textures and colors.
Diffusion Recommender Model
Apr 17, 2023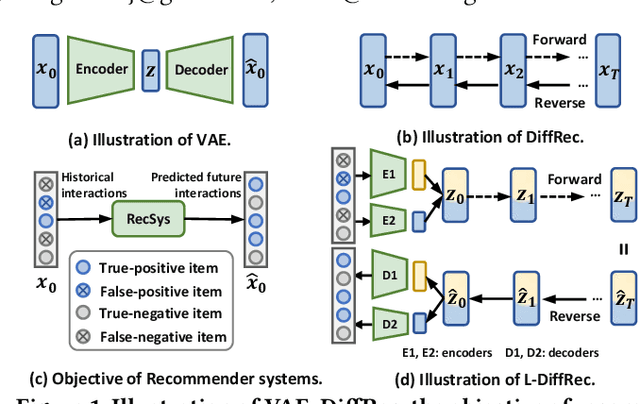
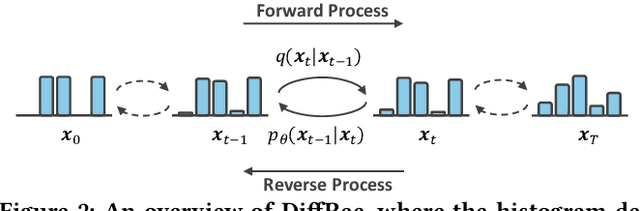
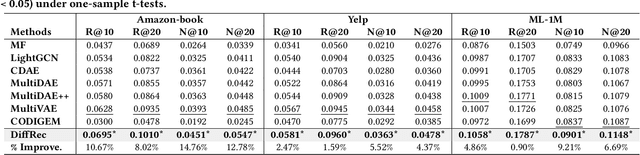
Generative models such as Generative Adversarial Networks (GANs) and Variational Auto-Encoders (VAEs) are widely utilized to model the generative process of user interactions. However, these generative models suffer from intrinsic limitations such as the instability of GANs and the restricted representation ability of VAEs. Such limitations hinder the accurate modeling of the complex user interaction generation procedure, such as noisy interactions caused by various interference factors. In light of the impressive advantages of Diffusion Models (DMs) over traditional generative models in image synthesis, we propose a novel Diffusion Recommender Model (named DiffRec) to learn the generative process in a denoising manner. To retain personalized information in user interactions, DiffRec reduces the added noises and avoids corrupting users' interactions into pure noises like in image synthesis. In addition, we extend traditional DMs to tackle the unique challenges in practical recommender systems: high resource costs for large-scale item prediction and temporal shifts of user preference. To this end, we propose two extensions of DiffRec: L-DiffRec clusters items for dimension compression and conducts the diffusion processes in the latent space; and T-DiffRec reweights user interactions based on the interaction timestamps to encode temporal information. We conduct extensive experiments on three datasets under multiple settings (e.g. clean training, noisy training, and temporal training). The empirical results and in-depth analysis validate the superiority of DiffRec with two extensions over competitive baselines.
TAP: A Comprehensive Data Repository for Traffic Accident Prediction in Road Networks
Apr 17, 2023
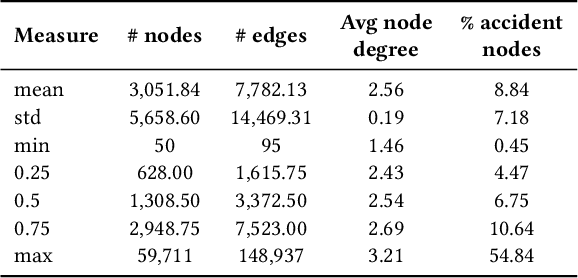
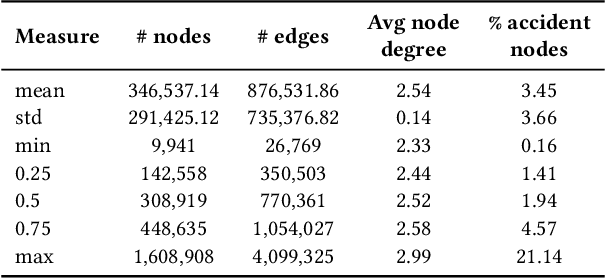
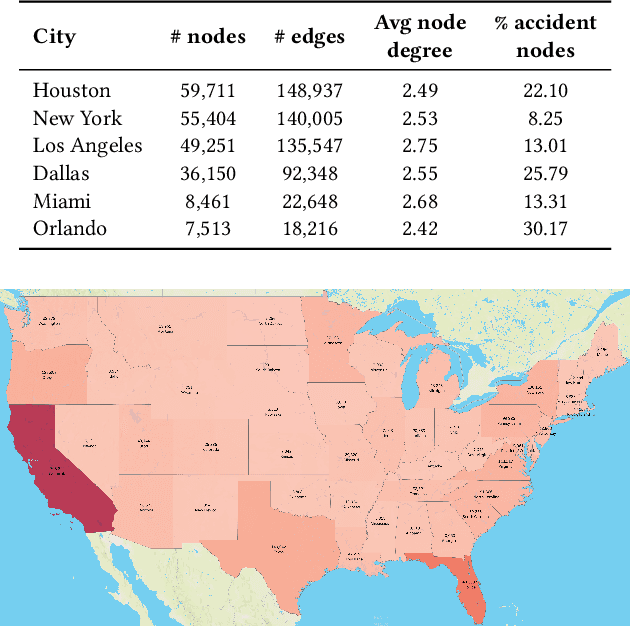
Road safety is a major global public health concern. Effective traffic crash prediction can play a critical role in reducing road traffic accidents. However, Existing machine learning approaches tend to focus on predicting traffic accidents in isolation, without considering the potential relationships between different accident locations within road networks. To incorporate graph structure information, graph-based approaches such as Graph Neural Networks (GNNs) can be naturally applied. However, applying GNNs to the accident prediction problem faces challenges due to the lack of suitable graph-structured traffic accident datasets. To bridge this gap, we have constructed a real-world graph-based Traffic Accident Prediction (TAP) data repository, along with two representative tasks: accident occurrence prediction and accident severity prediction. With nationwide coverage, real-world network topology, and rich geospatial features, this data repository can be used for a variety of traffic-related tasks. We further comprehensively evaluate eleven state-of-the-art GNN variants and two non-graph-based machine learning methods using the created datasets. Significantly facilitated by the proposed data, we develop a novel Traffic Accident Vulnerability Estimation via Linkage (TRAVEL) model, which is designed to capture angular and directional information from road networks. We demonstrate that the proposed model consistently outperforms the baselines. The data and code are available on GitHub (https://github.com/baixianghuang/travel).
Modelling Spatio-Temporal Interactions for Compositional Action Recognition
May 04, 2023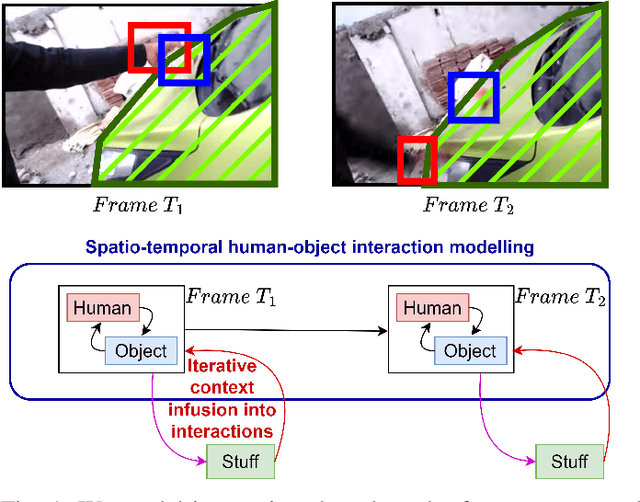

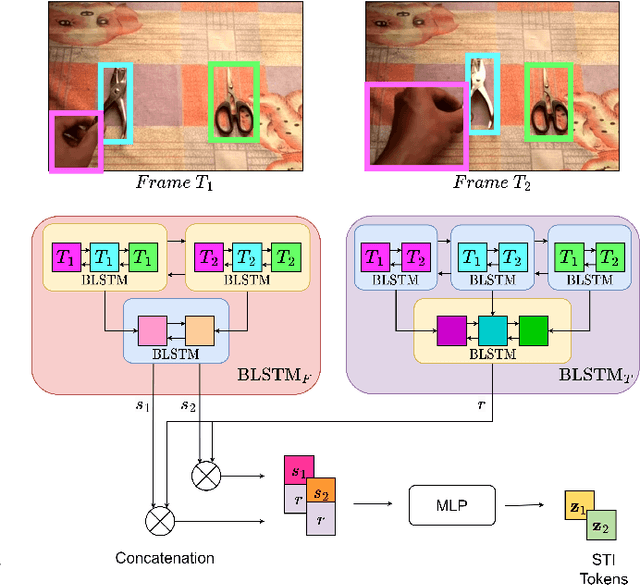
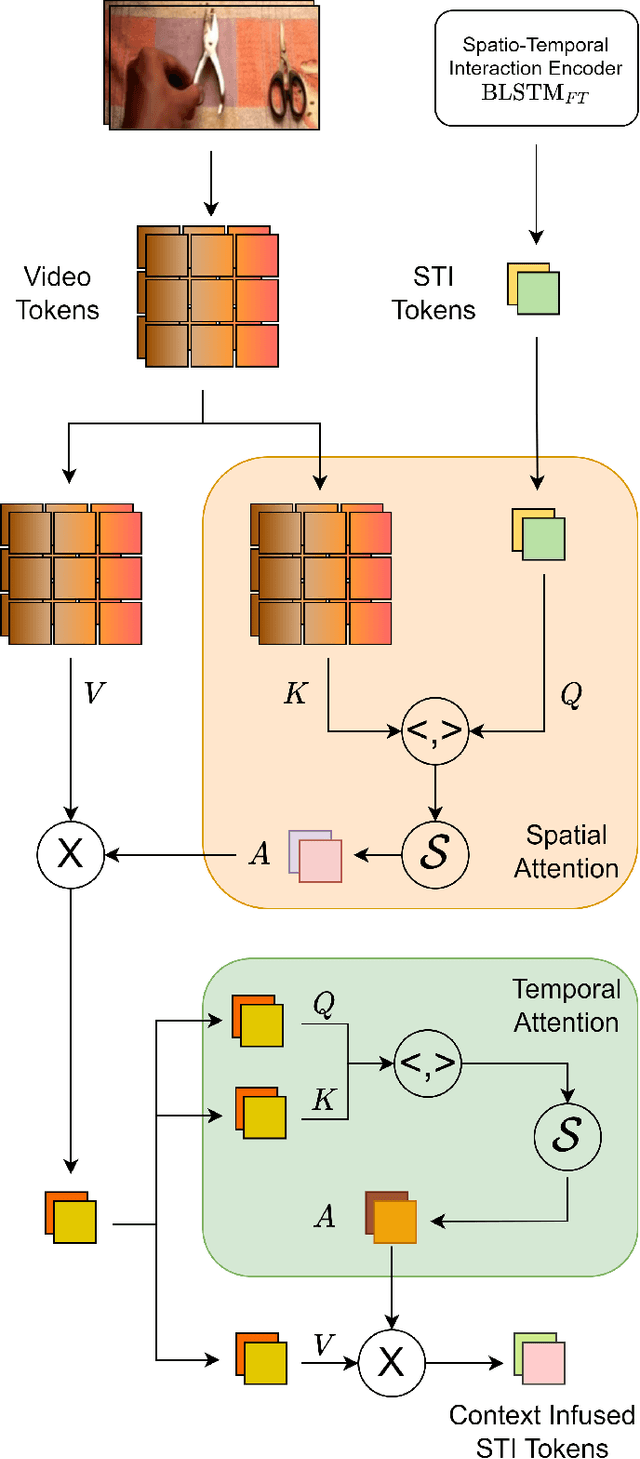
Humans have the natural ability to recognize actions even if the objects involved in the action or the background are changed. Humans can abstract away the action from the appearance of the objects and their context which is referred to as compositionality of actions. Compositional action recognition deals with imparting human-like compositional generalization abilities to action-recognition models. In this regard, extracting the interactions between humans and objects forms the basis of compositional understanding. These interactions are not affected by the appearance biases of the objects or the context. But the context provides additional cues about the interactions between things and stuff. Hence we need to infuse context into the human-object interactions for compositional action recognition. To this end, we first design a spatial-temporal interaction encoder that captures the human-object (things) interactions. The encoder learns the spatio-temporal interaction tokens disentangled from the background context. The interaction tokens are then infused with contextual information from the video tokens to model the interactions between things and stuff. The final context-infused spatio-temporal interaction tokens are used for compositional action recognition. We show the effectiveness of our interaction-centric approach on the compositional Something-Else dataset where we obtain a new state-of-the-art result of 83.8% top-1 accuracy outperforming recent important object-centric methods by a significant margin. Our approach of explicit human-object-stuff interaction modeling is effective even for standard action recognition datasets such as Something-Something-V2 and Epic-Kitchens-100 where we obtain comparable or better performance than state-of-the-art.
Ensemble Modeling with Contrastive Knowledge Distillation for Sequential Recommendation
May 04, 2023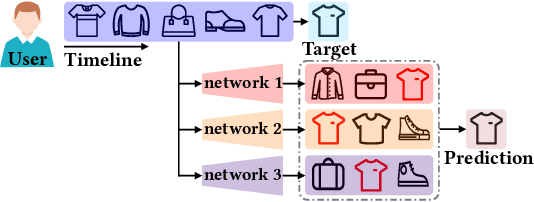
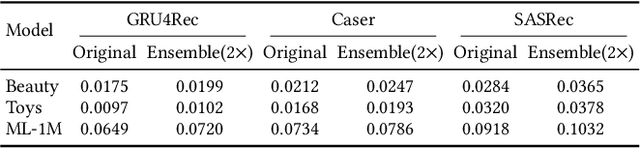
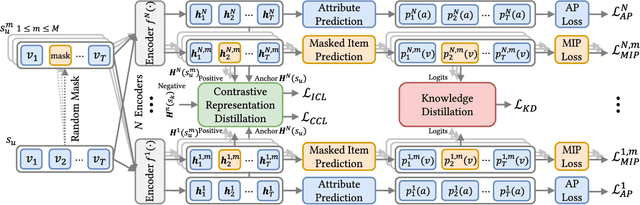
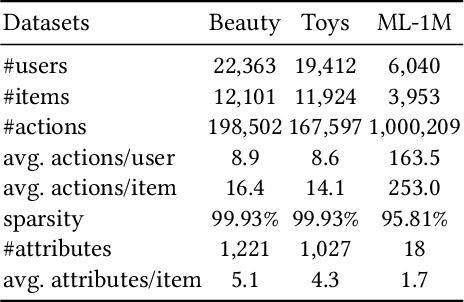
Sequential recommendation aims to capture users' dynamic interest and predicts the next item of users' preference. Most sequential recommendation methods use a deep neural network as sequence encoder to generate user and item representations. Existing works mainly center upon designing a stronger sequence encoder. However, few attempts have been made with training an ensemble of networks as sequence encoders, which is more powerful than a single network because an ensemble of parallel networks can yield diverse prediction results and hence better accuracy. In this paper, we present Ensemble Modeling with contrastive Knowledge Distillation for sequential recommendation (EMKD). Our framework adopts multiple parallel networks as an ensemble of sequence encoders and recommends items based on the output distributions of all these networks. To facilitate knowledge transfer between parallel networks, we propose a novel contrastive knowledge distillation approach, which performs knowledge transfer from the representation level via Intra-network Contrastive Learning (ICL) and Cross-network Contrastive Learning (CCL), as well as Knowledge Distillation (KD) from the logits level via minimizing the Kullback-Leibler divergence between the output distributions of the teacher network and the student network. To leverage contextual information, we train the primary masked item prediction task alongside the auxiliary attribute prediction task as a multi-task learning scheme. Extensive experiments on public benchmark datasets show that EMKD achieves a significant improvement compared with the state-of-the-art methods. Besides, we demonstrate that our ensemble method is a generalized approach that can also improve the performance of other sequential recommenders. Our code is available at this link: https://github.com/hw-du/EMKD.
Toward the Automated Construction of Probabilistic Knowledge Graphs for the Maritime Domain
May 04, 2023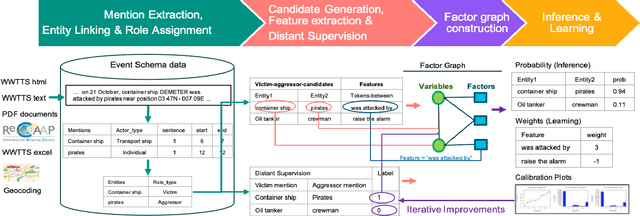
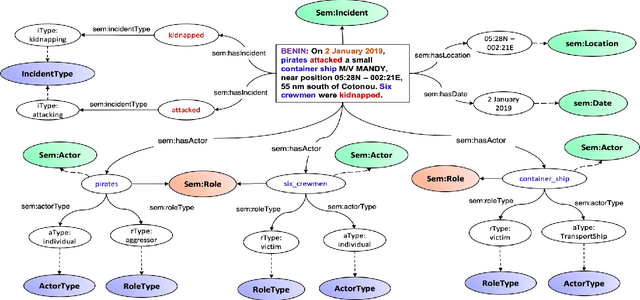
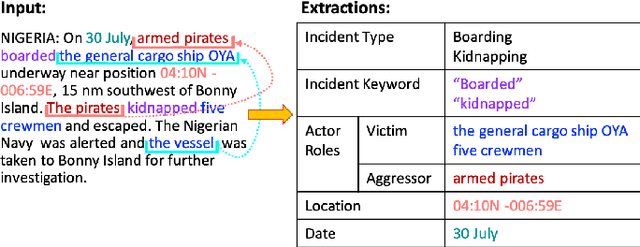
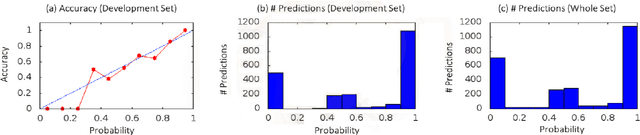
International maritime crime is becoming increasingly sophisticated, often associated with wider criminal networks. Detecting maritime threats by means of fusing data purely related to physical movement (i.e., those generated by physical sensors, or hard data) is not sufficient. This has led to research and development efforts aimed at combining hard data with other types of data (especially human-generated or soft data). Existing work often assumes that input soft data is available in a structured format, or is focused on extracting certain relevant entities or concepts to accompany or annotate hard data. Much less attention has been given to extracting the rich knowledge about the situations of interest implicitly embedded in the large amount of soft data existing in unstructured formats (such as intelligence reports and news articles). In order to exploit the potentially useful and rich information from such sources, it is necessary to extract not only the relevant entities and concepts but also their semantic relations, together with the uncertainty associated with the extracted knowledge (i.e., in the form of probabilistic knowledge graphs). This will increase the accuracy of and confidence in, the extracted knowledge and facilitate subsequent reasoning and learning. To this end, we propose Maritime DeepDive, an initial prototype for the automated construction of probabilistic knowledge graphs from natural language data for the maritime domain. In this paper, we report on the current implementation of Maritime DeepDive, together with preliminary results on extracting probabilistic events from maritime piracy incidents. This pipeline was evaluated on a manually crafted gold standard, yielding promising results.
Contextual information integration for stance detection via cross-attention
Nov 03, 2022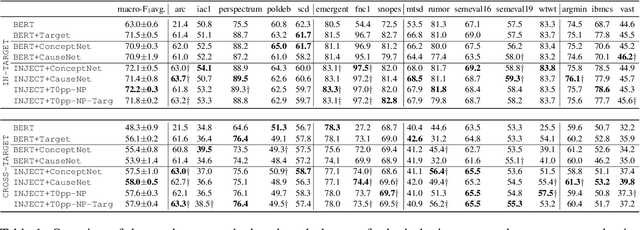
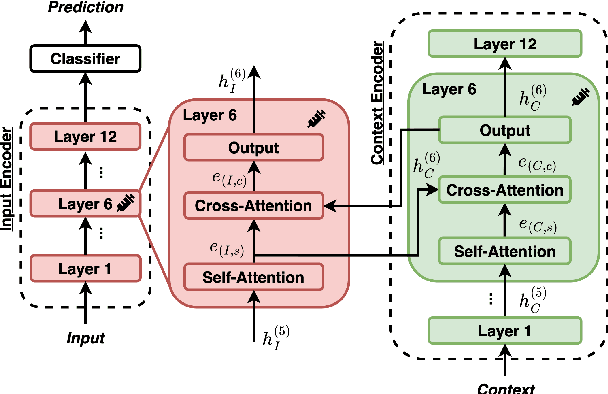
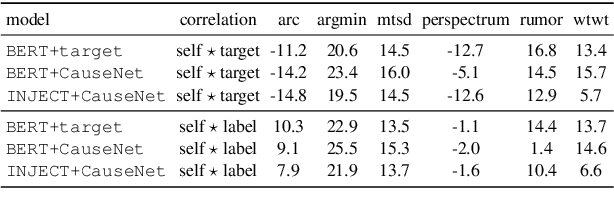
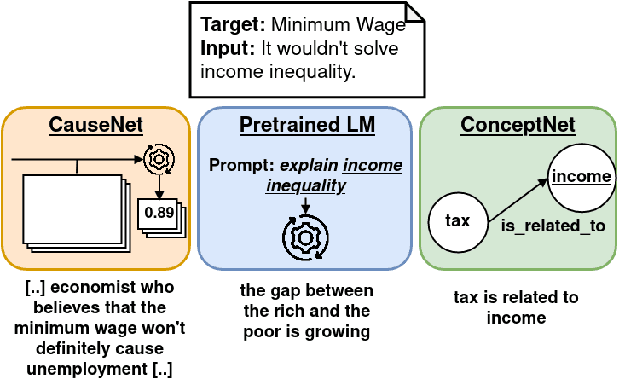
Stance detection deals with the identification of an author's stance towards a target and is applied on various text domains like social media and news. In many cases, inferring the stance is challenging due to insufficient access to contextual information. Complementary context can be found in knowledge bases but integrating the context into pretrained language models is non-trivial due to their graph structure. In contrast, we explore an approach to integrate contextual information as text which aligns better with transformer architectures. Specifically, we train a model consisting of dual encoders which exchange information via cross-attention. This architecture allows for integrating contextual information from heterogeneous sources. We evaluate context extracted from structured knowledge sources and from prompting large language models. Our approach is able to outperform competitive baselines (1.9pp on average) on a large and diverse stance detection benchmark, both (1) in-domain, i.e. for seen targets, and (2) out-of-domain, i.e. for targets unseen during training. Our analysis shows that it is able to regularize for spurious label correlations with target-specific cue words.
Mission-Aware Value of Information Censoring for Distributed Filtering
Nov 20, 2022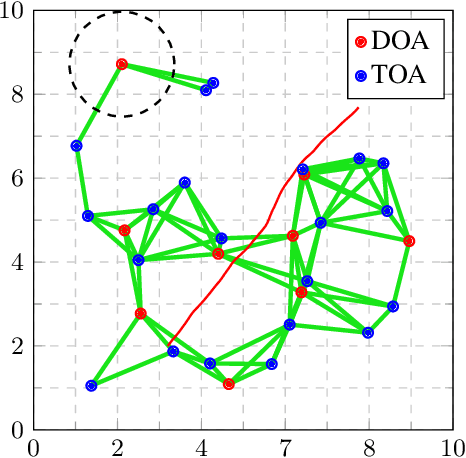
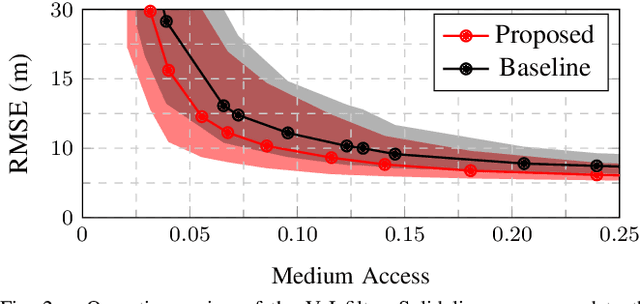
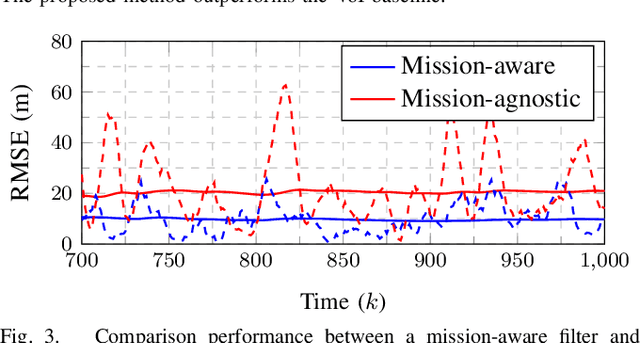
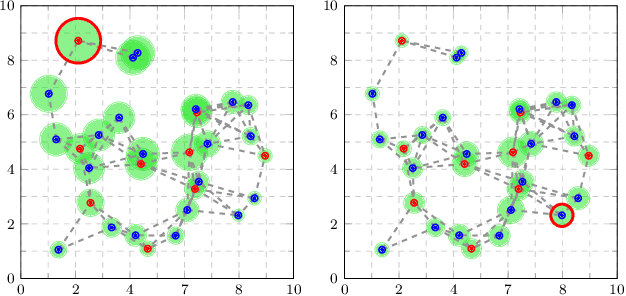
In this paper, we study the problem of distributed estimation with an emphasis on communication-efficiency. The proposed algorithm is based on a windowed maximum a posteriori (MAP) estimation problem, wherein each agent in the network locally computes a Kalman-like filter estimate that approximates the centralized MAP solution. Information sharing among agents is restricted to their neighbors only, with guarantees on overall estimate consistency provided via logarithmic opinion pooling. The problem is efficiently distributed using the alternating direction method of multipliers (ADMM), whose overall communication usage is further reduced by a value of information (VoI) censoring mechanism, wherein agents only transmit their primal-dual iterates when deemed valuable to do so. The proposed censoring mechanism is mission-aware, enabling a globally efficient use of communication resources while guaranteeing possibly different local estimation requirements. To illustrate the validity of the approach we perform simulations in a target tracking scenario.