 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Hybrid Deepfake Detection Utilizing MLP and LSTM
Apr 21, 2023
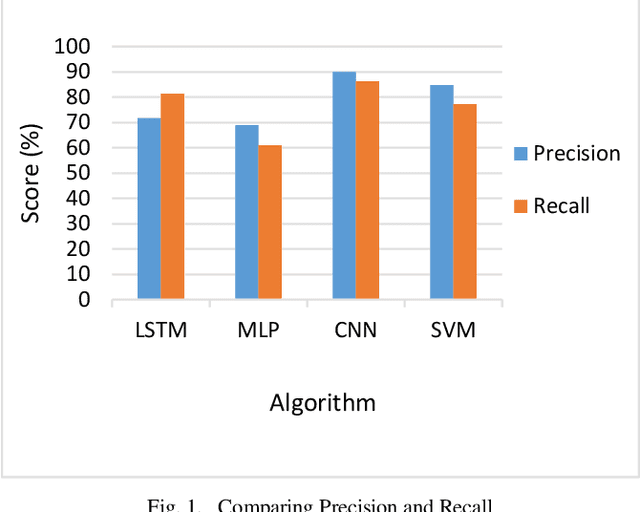
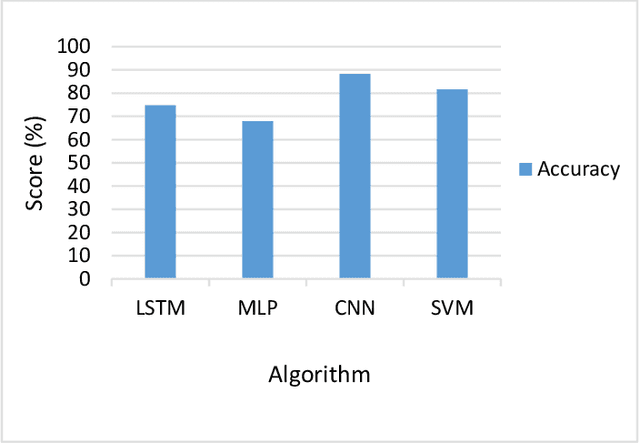
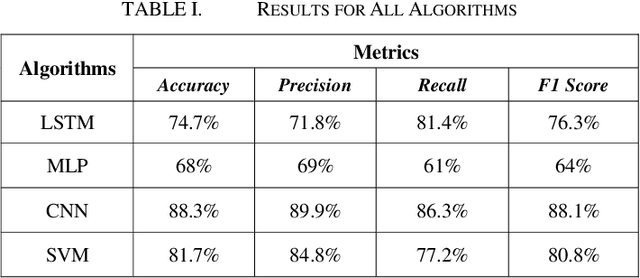
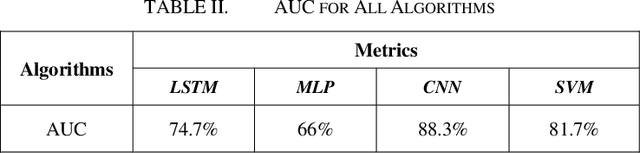
The growing reliance of society on social media for authentic information has done nothing but increase over the past years. This has only raised the potential consequences of the spread of misinformation. One of the growing methods in popularity is to deceive users using a deepfake. A deepfake is an invention that has come with the latest technological advancements, which enables nefarious online users to replace their face with a computer generated, synthetic face of numerous powerful members of society. Deepfake images and videos now provide the means to mimic important political and cultural figures to spread massive amounts of false information. Models that can detect these deepfakes to prevent the spread of misinformation are now of tremendous necessity. In this paper, we propose a new deepfake detection schema utilizing two deep learning algorithms: long short term memory and multilayer perceptron. We evaluate our model using a publicly available dataset named 140k Real and Fake Faces to detect images altered by a deepfake with accuracies achieved as high as 74.7%
Distributed Leader Follower Formation Control of Mobile Robots based on Bioinspired Neural Dynamics and Adaptive Sliding Innovation Filter
May 03, 2023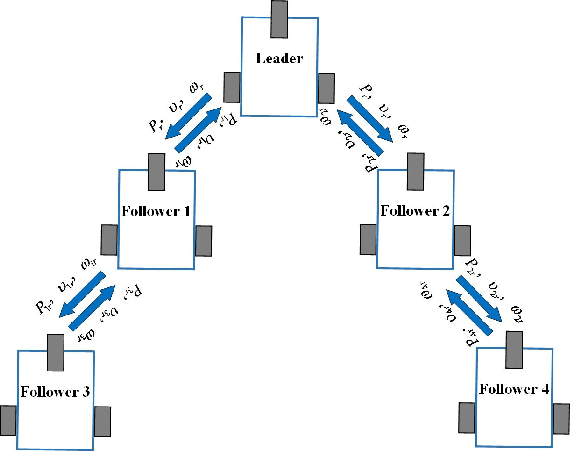
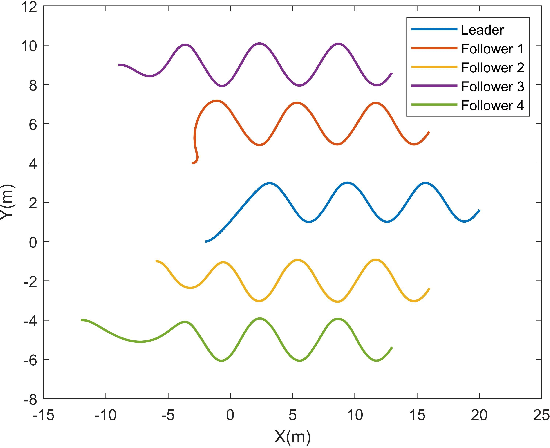
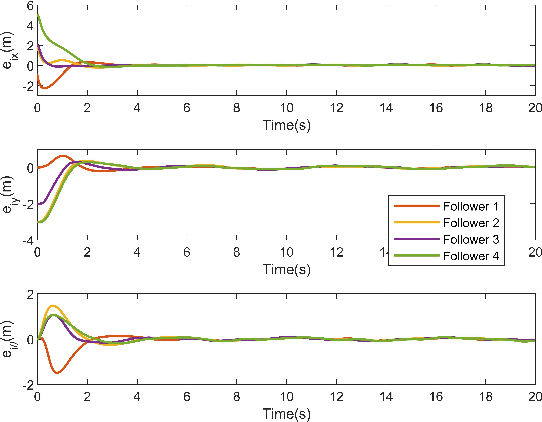
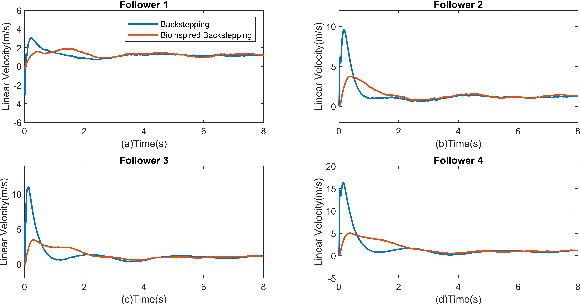
This paper investigated the distributed leader follower formation control problem for multiple differentially driven mobile robots. A distributed estimator is first introduced and it only requires the state information from each follower itself and its neighbors. Then, we propose a bioinspired neural dynamic based backstepping and sliding mode control hybrid formation control method with proof of its stability. The proposed control strategy resolves the impractical speed jump issue that exists in the conventional backstepping design. Additionally, considering the system and measurement noises, the proposed control strategy not only removes the chattering issue existing in the conventional sliding mode control but also provides smooth control input with extra robustness. After that, an adaptive sliding innovation filter is integrated with the proposed control to provide accurate state estimates that are robust to modeling uncertainties. Finally, we performed multiple simulations to demonstrate the efficiency and effectiveness of the proposed formation control strategy.
Training Natural Language Processing Models on Encrypted Text for Enhanced Privacy
May 03, 2023With the increasing use of cloud-based services for training and deploying machine learning models, data privacy has become a major concern. This is particularly important for natural language processing (NLP) models, which often process sensitive information such as personal communications and confidential documents. In this study, we propose a method for training NLP models on encrypted text data to mitigate data privacy concerns while maintaining similar performance to models trained on non-encrypted data. We demonstrate our method using two different architectures, namely Doc2Vec+XGBoost and Doc2Vec+LSTM, and evaluate the models on the 20 Newsgroups dataset. Our results indicate that both encrypted and non-encrypted models achieve comparable performance, suggesting that our encryption method is effective in preserving data privacy without sacrificing model accuracy. In order to replicate our experiments, we have provided a Colab notebook at the following address: https://t.ly/lR-TP
Gym-preCICE: Reinforcement Learning Environments for Active Flow Control
May 03, 2023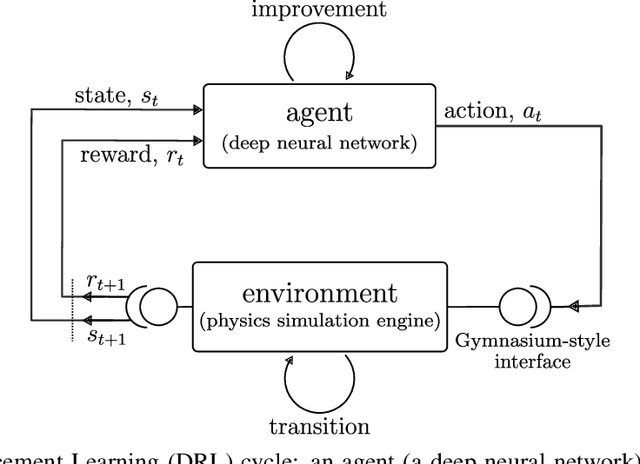
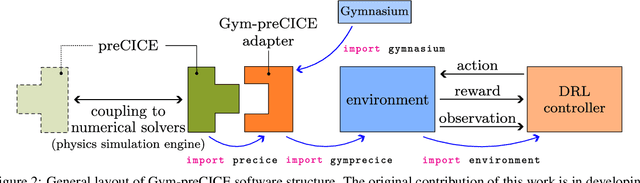
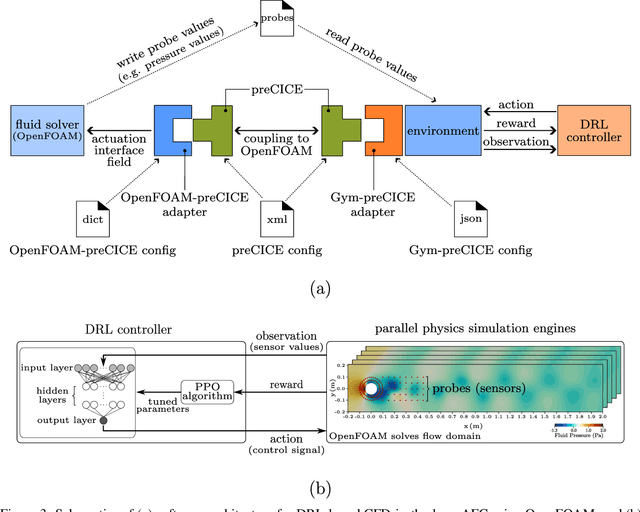
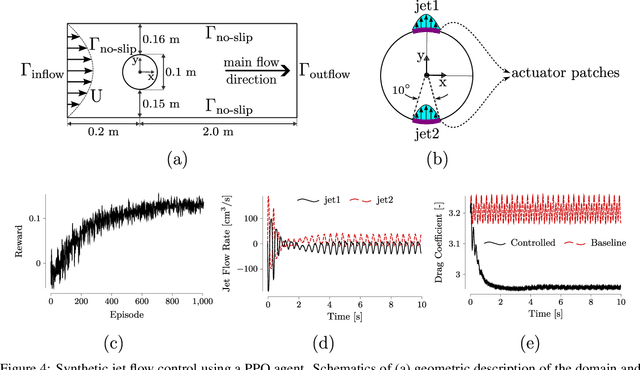
Active flow control (AFC) involves manipulating fluid flow over time to achieve a desired performance or efficiency. AFC, as a sequential optimisation task, can benefit from utilising Reinforcement Learning (RL) for dynamic optimisation. In this work, we introduce Gym-preCICE, a Python adapter fully compliant with Gymnasium (formerly known as OpenAI Gym) API to facilitate designing and developing RL environments for single- and multi-physics AFC applications. In an actor-environment setting, Gym-preCICE takes advantage of preCICE, an open-source coupling library for partitioned multi-physics simulations, to handle information exchange between a controller (actor) and an AFC simulation environment. The developed framework results in a seamless non-invasive integration of realistic physics-based simulation toolboxes with RL algorithms. Gym-preCICE provides a framework for designing RL environments to model AFC tasks, as well as a playground for applying RL algorithms in various AFC-related engineering applications.
Fashionpedia-Ads: Do Your Favorite Advertisements Reveal Your Fashion Taste?
May 03, 2023
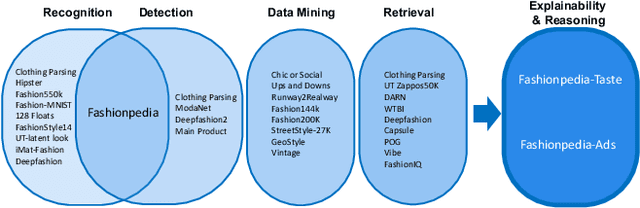


Consumers are exposed to advertisements across many different domains on the internet, such as fashion, beauty, car, food, and others. On the other hand, fashion represents second highest e-commerce shopping category. Does consumer digital record behavior on various fashion ad images reveal their fashion taste? Does ads from other domains infer their fashion taste as well? In this paper, we study the correlation between advertisements and fashion taste. Towards this goal, we introduce a new dataset, Fashionpedia-Ads, which asks subjects to provide their preferences on both ad (fashion, beauty, car, and dessert) and fashion product (social network and e-commerce style) images. Furthermore, we exhaustively collect and annotate the emotional, visual and textual information on the ad images from multi-perspectives (abstractive level, physical level, captions, and brands). We open-source Fashionpedia-Ads to enable future studies and encourage more approaches to interpretability research between advertisements and fashion taste.
HappyQuokka System for ICASSP 2023 Auditory EEG Challenge
May 03, 2023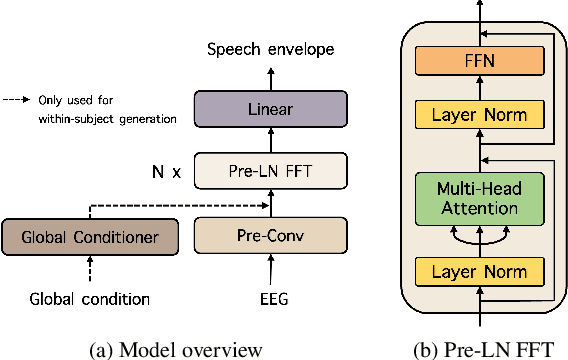
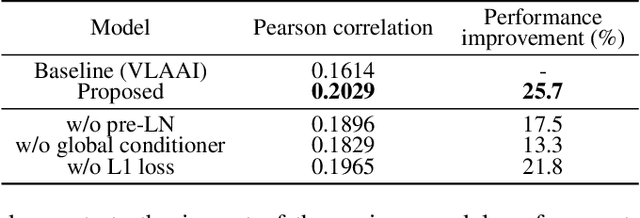
This report describes our submission to Task 2 of the Auditory EEG Decoding Challenge at ICASSP 2023 Signal Processing Grand Challenge (SPGC). Task 2 is a regression problem that focuses on reconstructing a speech envelope from an EEG signal. For the task, we propose a pre-layer normalized feed-forward transformer (FFT) architecture. For within-subjects generation, we additionally utilize an auxiliary global conditioner which provides our model with additional information about seen individuals. Experimental results show that our proposed method outperforms the VLAAI baseline and all other submitted systems. Notably, it demonstrates significant improvements on the within-subjects task, likely thanks to our use of the auxiliary global conditioner. In terms of evaluation metrics set by the challenge, we obtain Pearson correlation values of 0.1895 0.0869 for the within-subjects generation test and 0.0976 0.0444 for the heldout-subjects test. We release the training code for our model online.
Toeplitz Neural Network for Sequence Modeling
May 08, 2023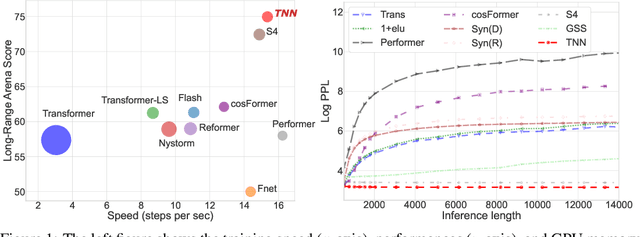

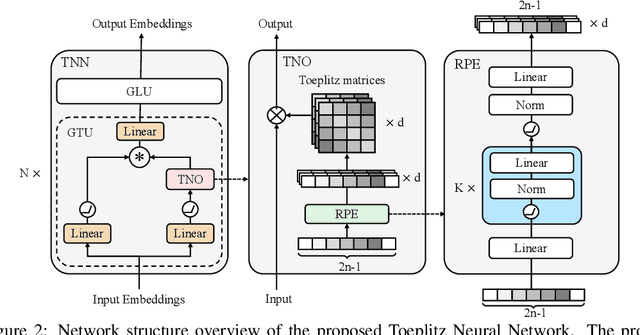
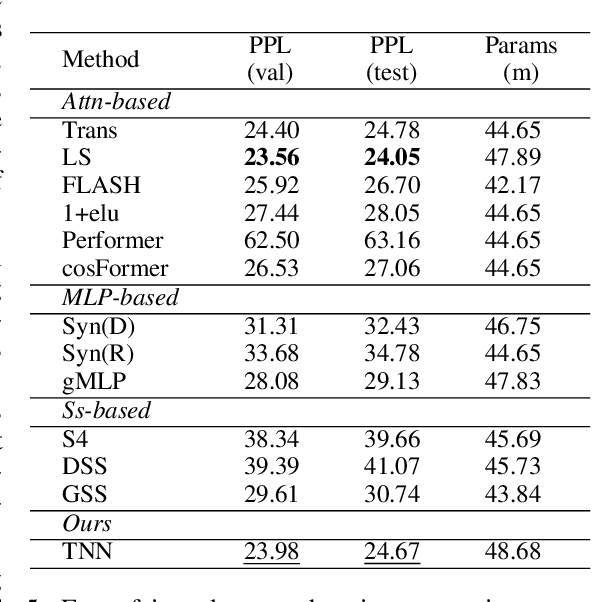
Sequence modeling has important applications in natural language processing and computer vision. Recently, the transformer-based models have shown strong performance on various sequence modeling tasks, which rely on attention to capture pairwise token relations, and position embedding to inject positional information. While showing good performance, the transformer models are inefficient to scale to long input sequences, mainly due to the quadratic space-time complexity of attention. To overcome this inefficiency, we propose to model sequences with a relative position encoded Toeplitz matrix and use a Toeplitz matrix-vector production trick to reduce the space-time complexity of the sequence modeling to log linear. A lightweight sub-network called relative position encoder is proposed to generate relative position coefficients with a fixed budget of parameters, enabling the proposed Toeplitz neural network to deal with varying sequence lengths. In addition, despite being trained on 512-token sequences, our model can extrapolate input sequence length up to 14K tokens in inference with consistent performance. Extensive experiments on autoregressive and bidirectional language modeling, image modeling, and the challenging Long-Range Arena benchmark show that our method achieves better performance than its competitors in most downstream tasks while being significantly faster. The code is available at https://github.com/OpenNLPLab/Tnn.
Development of a Vision System to Enhance the Reliability of the Pick-and-Place Robot for Autonomous Testing of Camera Module used in Smartphones
May 08, 2023
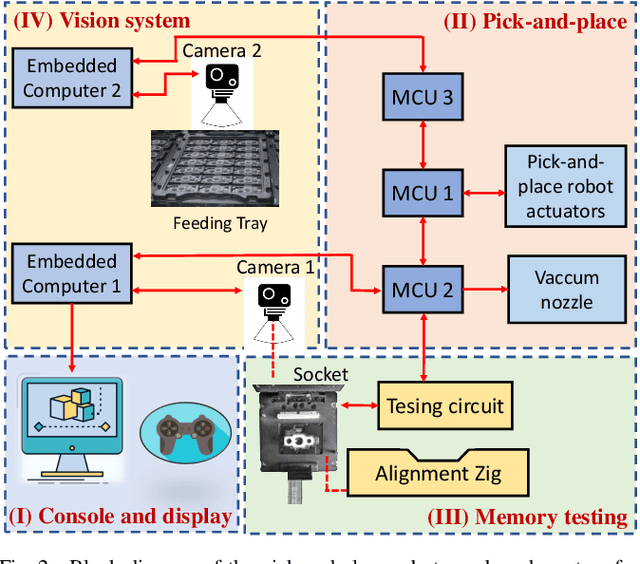

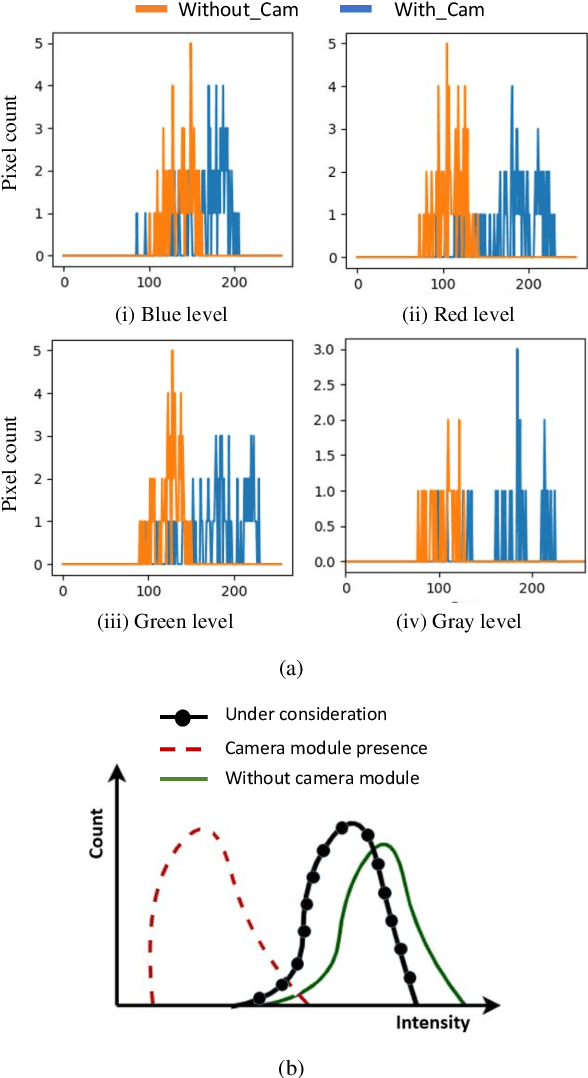
Pick-and-place robots are commonly used in modern industrial manufacturing. For complex devices/parts like camera modules used in smartphones, which contain optical parts, electrical components and interfacing connectors, the placement operation may not absolutely accurate, which may cause damage in the device under test during the mechanical movement to make good contact for electrical functions inspection. In this paper, we proposed an effective vision system including hardware and algorithm to enhance the reliability of the pick-and-place robot for autonomous testing memory of camera modules. With limited hardware based on camera and raspberry PI and using simplify image processing algorithm based on histogram information, the vision system can confirm the presence of the camera modules in feeding tray and the placement accuracy of the camera module in test socket. Through that, the system can work with more flexibility and avoid damaging the device under test. The system was experimentally quantified through testing approximately 2000 camera modules in a stable light condition. Experimental results demonstrate that the system achieves accuracy of more than 99.92%. With its simplicity and effectiveness, the proposed vision system can be considered as a useful solution for using in pick-and-place systems in industry.
Differentially Private Attention Computation
May 08, 2023Large language models (LLMs) have had a profound impact on numerous aspects of daily life including natural language processing, content generation, research methodologies and so on. However, one crucial issue concerning the inference results of large language models is security and privacy. In many scenarios, the results generated by LLMs could possibly leak many confidential or copyright information. A recent beautiful and breakthrough work [Vyas, Kakade and Barak 2023] focus on such privacy issue of the LLMs from theoretical perspective. It is well-known that computing the attention matrix is one of the major task during the LLMs computation. Thus, how to give a provable privately guarantees of computing the attention matrix is an important research direction. Previous work [Alman and Song 2023, Brand, Song and Zhou 2023] have proposed provable tight result for fast computation of attention without considering privacy concerns. One natural mathematical formulation to quantity the privacy in theoretical computer science graduate school textbook is differential privacy. Inspired by [Vyas, Kakade and Barak 2023], in this work, we provide a provable result for showing how to differentially private approximate the attention matrix. From technique perspective, our result replies on a pioneering work in the area of differential privacy by [Alabi, Kothari, Tankala, Venkat and Zhang 2022].
Privacy-preserving Adversarial Facial Features
May 08, 2023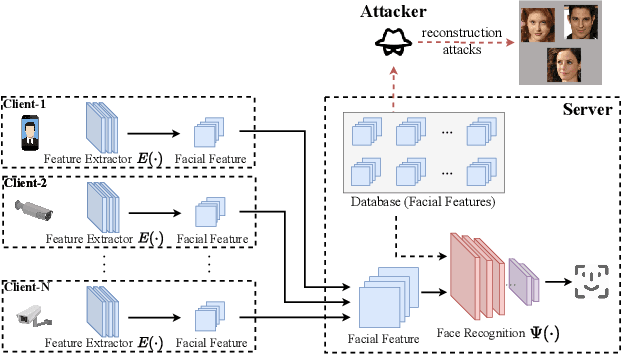

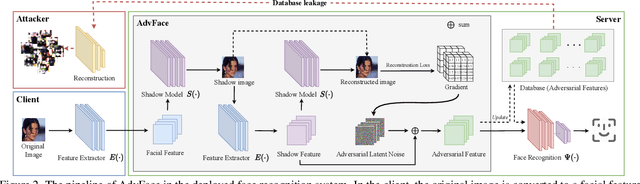

Face recognition service providers protect face privacy by extracting compact and discriminative facial features (representations) from images, and storing the facial features for real-time recognition. However, such features can still be exploited to recover the appearance of the original face by building a reconstruction network. Although several privacy-preserving methods have been proposed, the enhancement of face privacy protection is at the expense of accuracy degradation. In this paper, we propose an adversarial features-based face privacy protection (AdvFace) approach to generate privacy-preserving adversarial features, which can disrupt the mapping from adversarial features to facial images to defend against reconstruction attacks. To this end, we design a shadow model which simulates the attackers' behavior to capture the mapping function from facial features to images and generate adversarial latent noise to disrupt the mapping. The adversarial features rather than the original features are stored in the server's database to prevent leaked features from exposing facial information. Moreover, the AdvFace requires no changes to the face recognition network and can be implemented as a privacy-enhancing plugin in deployed face recognition systems. Extensive experimental results demonstrate that AdvFace outperforms the state-of-the-art face privacy-preserving methods in defending against reconstruction attacks while maintaining face recognition accuracy.