 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Using Auxiliary Information for Person Re-Identification -- A Tutorial Overview
Nov 15, 2022

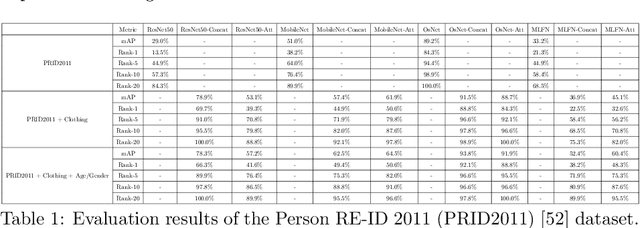
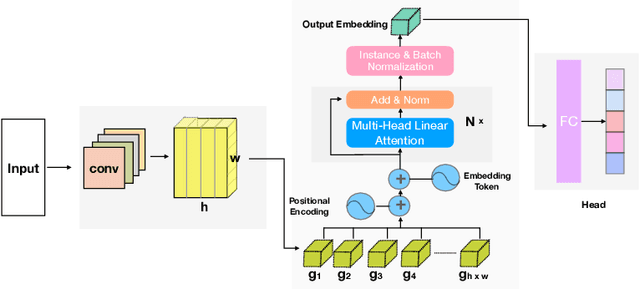
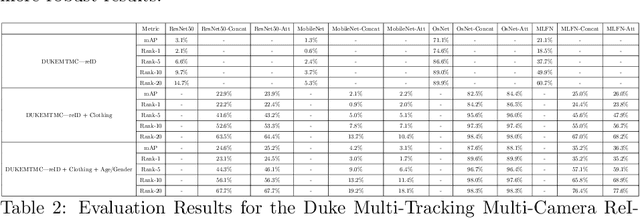
Person re-identification (re-id) is a pivotal task within an intelligent surveillance pipeline and there exist numerous re-id frameworks that achieve satisfactory performance in challenging benchmarks. However, these systems struggle to generate acceptable results when there are significant differences between the camera views, illumination conditions, or occlusions. This result can be attributed to the deficiency that exists within many recently proposed re-id pipelines where they are predominately driven by appearance-based features and little attention is paid to other auxiliary information that could aid the re-id. In this paper, we systematically review the current State-Of-The-Art (SOTA) methods in both uni-modal and multimodal person re-id. Extending beyond a conceptual framework, we illustrate how the existing SOTA methods can be extended to support these additional auxiliary information and quantitatively evaluate the utility of such auxiliary feature information, ranging from logos printed on the objects carried by the subject or printed on the clothes worn by the subject, through to his or her behavioural trajectories. To the best of our knowledge, this is the first work that explores the fusion of multiple information to generate a more discriminant person descriptor and the principal aim of this paper is to provide a thorough theoretical analysis regarding the implementation of such a framework. In addition, using model interpretation techniques, we validate the contributions from different combinations of the auxiliary information versus the original features that the SOTA person re-id models extract. We outline the limitations of the proposed approaches and propose future research directions that could be pursued to advance the area of multi-modal person re-id.
A baseline on continual learning methods for video action recognition
Apr 26, 2023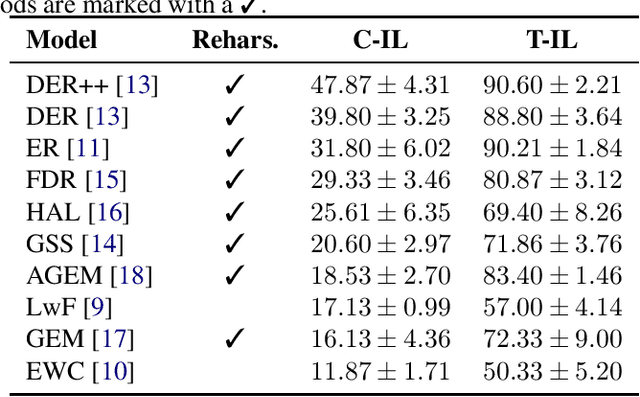
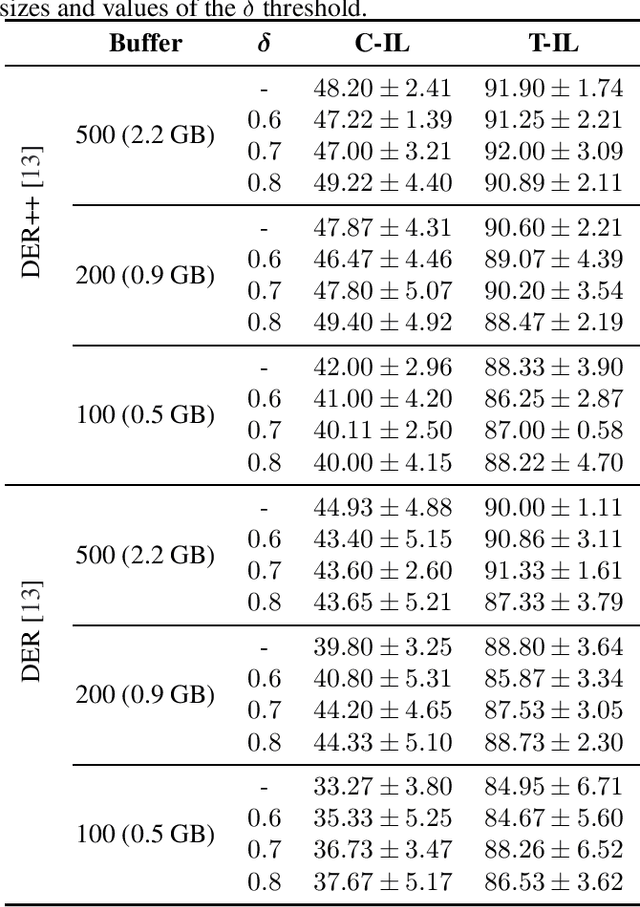
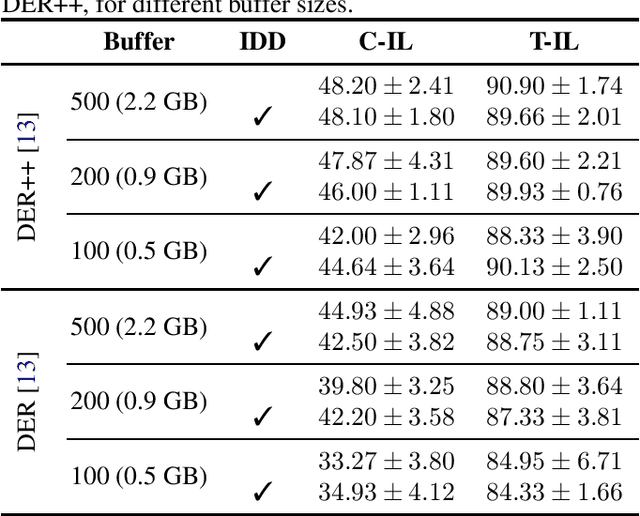
Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
Shades of meaning: Uncovering the geometry of ambiguous word representations through contextualised language models
Apr 26, 2023
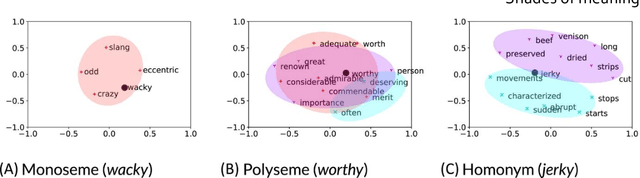
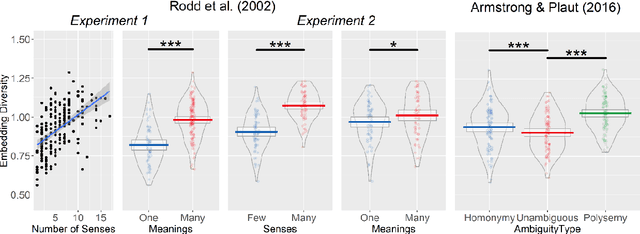
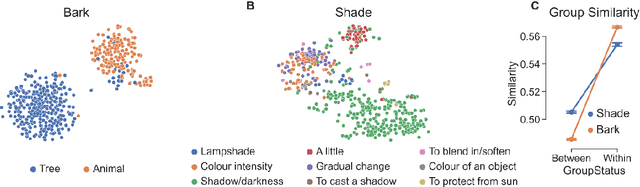
Lexical ambiguity presents a profound and enduring challenge to the language sciences. Researchers for decades have grappled with the problem of how language users learn, represent and process words with more than one meaning. Our work offers new insight into psychological understanding of lexical ambiguity through a series of simulations that capitalise on recent advances in contextual language models. These models have no grounded understanding of the meanings of words at all; they simply learn to predict words based on the surrounding context provided by other words. Yet, our analyses show that their representations capture fine-grained meaningful distinctions between unambiguous, homonymous, and polysemous words that align with lexicographic classifications and psychological theorising. These findings provide quantitative support for modern psychological conceptualisations of lexical ambiguity and raise new challenges for understanding of the way that contextual information shapes the meanings of words across different timescales.
Source-Filter-Based Generative Adversarial Neural Vocoder for High Fidelity Speech Synthesis
Apr 26, 2023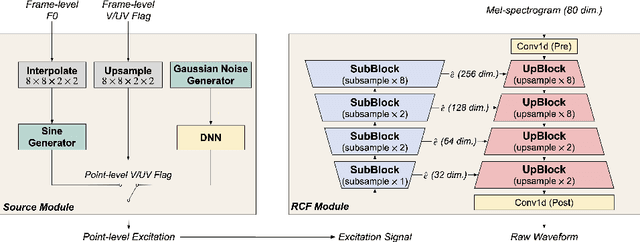
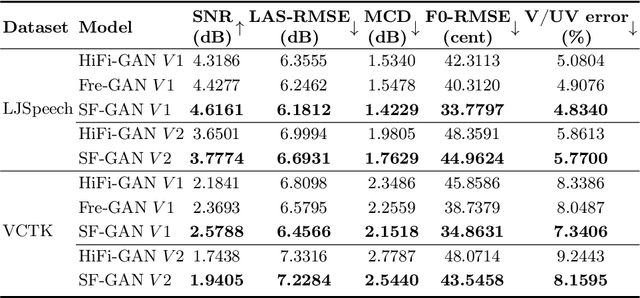
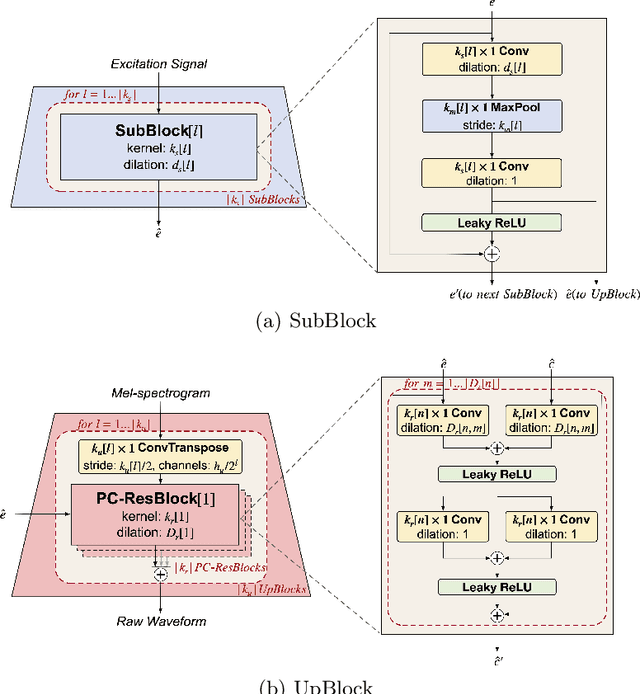
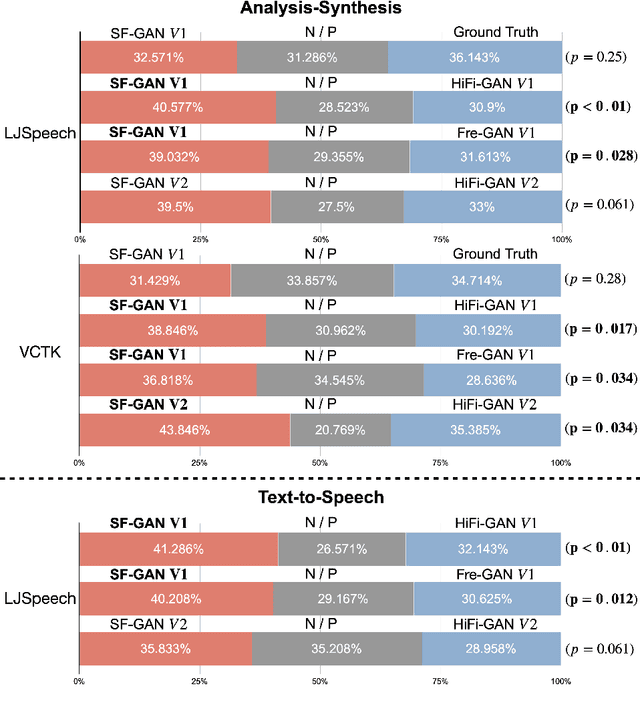
This paper proposes a source-filter-based generative adversarial neural vocoder named SF-GAN, which achieves high-fidelity waveform generation from input acoustic features by introducing F0-based source excitation signals to a neural filter framework. The SF-GAN vocoder is composed of a source module and a resolution-wise conditional filter module and is trained based on generative adversarial strategies. The source module produces an excitation signal from the F0 information, then the resolution-wise convolutional filter module combines the excitation signal with processed acoustic features at various temporal resolutions and finally reconstructs the raw waveform. The experimental results show that our proposed SF-GAN vocoder outperforms the state-of-the-art HiFi-GAN and Fre-GAN in both analysis-synthesis (AS) and text-to-speech (TTS) tasks, and the synthesized speech quality of SF-GAN is comparable to the ground-truth audio.
Is ChatGPT a Good Recommender? A Preliminary Study
Apr 20, 2023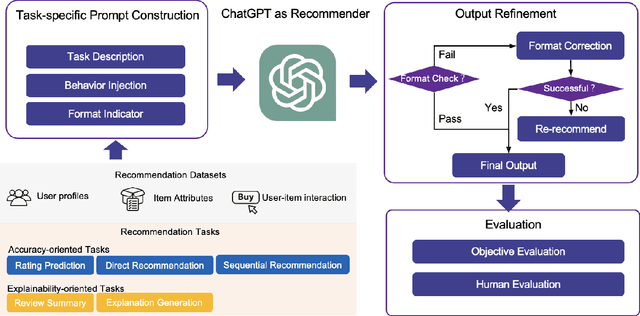
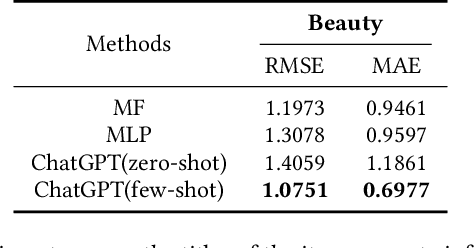
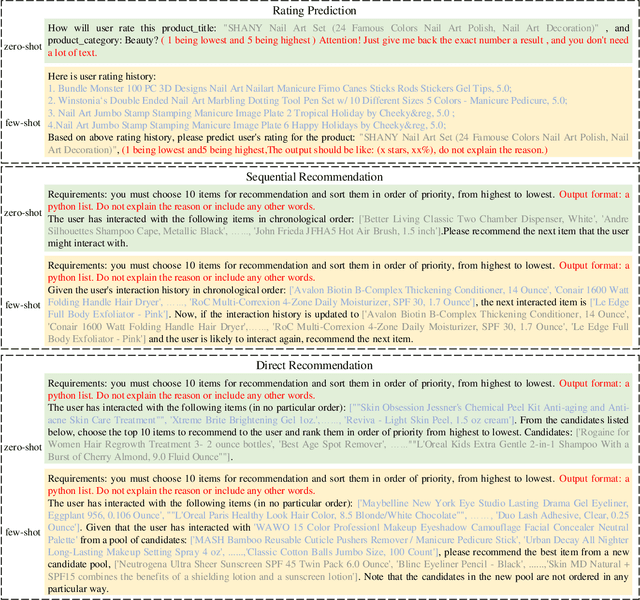
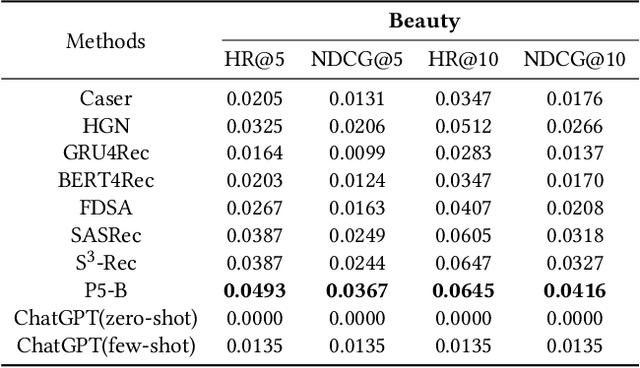
Recommendation systems have witnessed significant advancements and have been widely used over the past decades. However, most traditional recommendation methods are task-specific and therefore lack efficient generalization ability. Recently, the emergence of ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. Nonetheless, the application of ChatGPT in the recommendation domain has not been thoroughly investigated. In this paper, we employ ChatGPT as a general-purpose recommendation model to explore its potential for transferring extensive linguistic and world knowledge acquired from large-scale corpora to recommendation scenarios. Specifically, we design a set of prompts and evaluate ChatGPT's performance on five recommendation scenarios. Unlike traditional recommendation methods, we do not fine-tune ChatGPT during the entire evaluation process, relying only on the prompts themselves to convert recommendation tasks into natural language tasks. Further, we explore the use of few-shot prompting to inject interaction information that contains user potential interest to help ChatGPT better understand user needs and interests. Comprehensive experimental results on Amazon Beauty dataset show that ChatGPT has achieved promising results in certain tasks and is capable of reaching the baseline level in others. We conduct human evaluations on two explainability-oriented tasks to more accurately evaluate the quality of contents generated by different models. And the human evaluations show ChatGPT can truly understand the provided information and generate clearer and more reasonable results. We hope that our study can inspire researchers to further explore the potential of language models like ChatGPT to improve recommendation performance and contribute to the advancement of the recommendation systems field.
Similarity-Aware Multimodal Prompt Learning for Fake News Detection
Apr 20, 2023
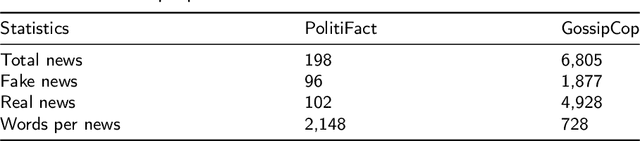
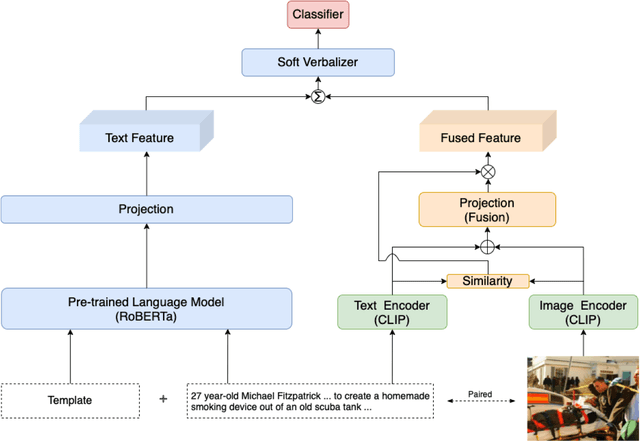
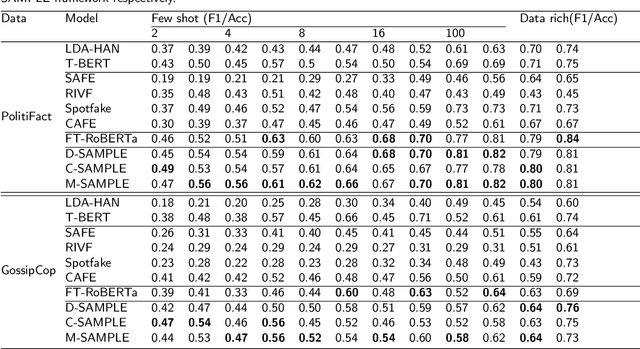
The standard paradigm for fake news detection mainly utilizes text information to model the truthfulness of news. However, the discourse of online fake news is typically subtle and it requires expert knowledge to use textual information to debunk fake news. Recently, studies focusing on multimodal fake news detection have outperformed text-only methods. Recent approaches utilizing the pre-trained model to extract unimodal features, or fine-tuning the pre-trained model directly, have become a new paradigm for detecting fake news. Again, this paradigm either requires a large number of training instances, or updates the entire set of pre-trained model parameters, making real-world fake news detection impractical. Furthermore, traditional multimodal methods fuse the cross-modal features directly without considering that the uncorrelated semantic representation might inject noise into the multimodal features. This paper proposes a Similarity-Aware Multimodal Prompt Learning (SAMPLE) framework. First, we incorporate prompt learning into multimodal fake news detection. Prompt learning, which only tunes prompts with a frozen language model, can reduce memory usage significantly and achieve comparable performances, compared with fine-tuning. We analyse three prompt templates with a soft verbalizer to detect fake news. In addition, we introduce the similarity-aware fusing method to adaptively fuse the intensity of multimodal representation and mitigate the noise injection via uncorrelated cross-modal features. For evaluation, SAMPLE surpasses the F1 and the accuracies of previous works on two benchmark multimodal datasets, demonstrating the effectiveness of the proposed method in detecting fake news. In addition, SAMPLE also is superior to other approaches regardless of few-shot and data-rich settings.
Neural Invertible Variable-degree Optical Aberrations Correction
Apr 12, 2023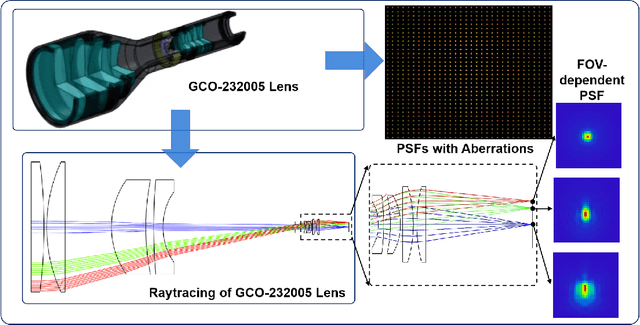
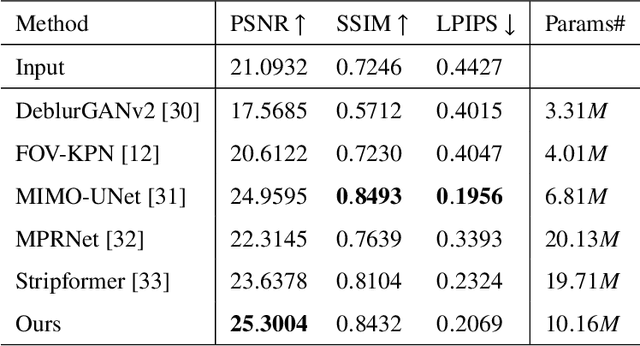
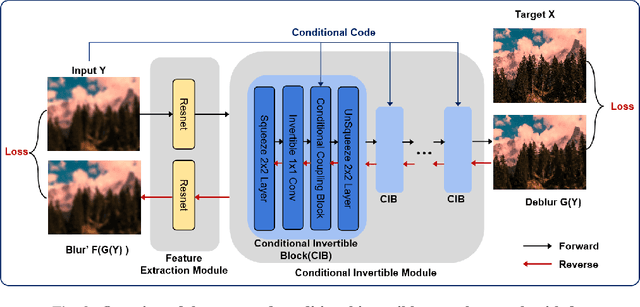
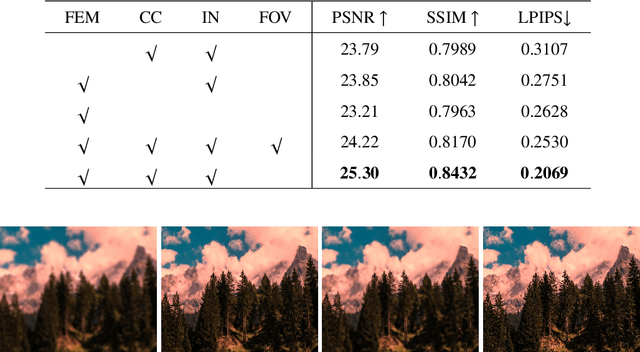
Optical aberrations of optical systems cause significant degradation of imaging quality. Aberration correction by sophisticated lens designs and special glass materials generally incurs high cost of manufacturing and the increase in the weight of optical systems, thus recent work has shifted to aberration correction with deep learning-based post-processing. Though real-world optical aberrations vary in degree, existing methods cannot eliminate variable-degree aberrations well, especially for the severe degrees of degradation. Also, previous methods use a single feed-forward neural network and suffer from information loss in the output. To address the issues, we propose a novel aberration correction method with an invertible architecture by leveraging its information-lossless property. Within the architecture, we develop conditional invertible blocks to allow the processing of aberrations with variable degrees. Our method is evaluated on both a synthetic dataset from physics-based imaging simulation and a real captured dataset. Quantitative and qualitative experimental results demonstrate that our method outperforms compared methods in correcting variable-degree optical aberrations.
Networked Signal and Information Processing
Oct 25, 2022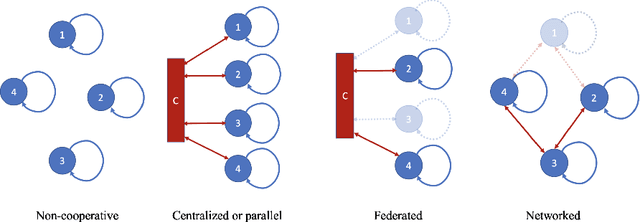
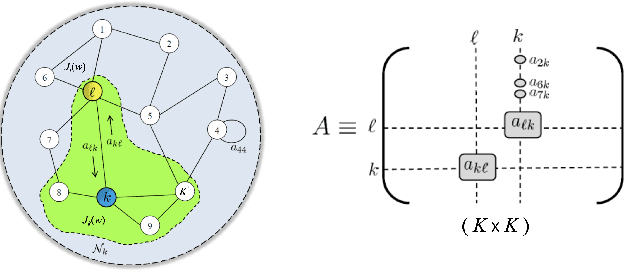

The article reviews significant advances in networked signal and information processing, which have enabled in the last 25 years extending decision making and inference, optimization, control, and learning to the increasingly ubiquitous environments of distributed agents. As these interacting agents cooperate, new collective behaviors emerge from local decisions and actions. Moreover, and significantly, theory and applications show that networked agents, through cooperation and sharing, are able to match the performance of cloud or federated solutions, while preserving privacy, increasing resilience, and saving resources.
Learning Task-Specific Strategies for Accelerated MRI
Apr 25, 2023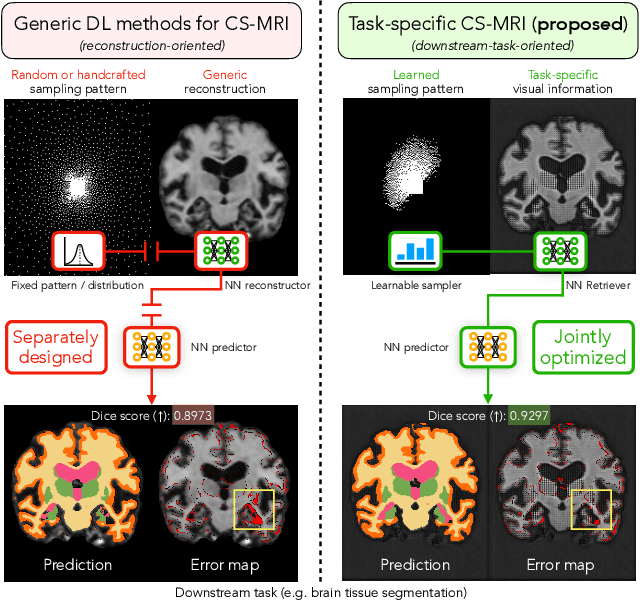
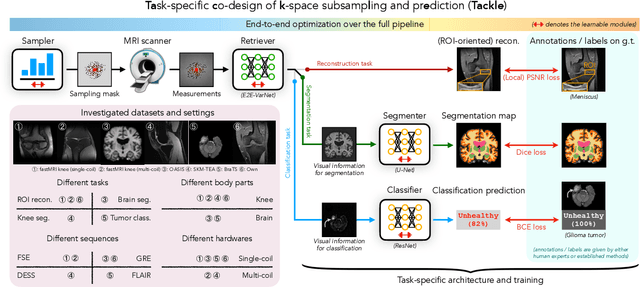

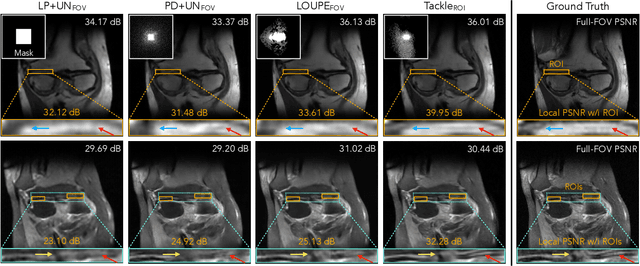
Compressed sensing magnetic resonance imaging (CS-MRI) seeks to recover visual information from subsampled measurements for diagnostic tasks. Traditional CS-MRI methods often separately address measurement subsampling, image reconstruction, and task prediction, resulting in suboptimal end-to-end performance. In this work, we propose TACKLE as a unified framework for designing CS-MRI systems tailored to specific tasks. Leveraging recent co-design techniques, TACKLE jointly optimizes subsampling, reconstruction, and prediction strategies to enhance the performance on the downstream task. Our results on multiple public MRI datasets show that the proposed framework achieves improved performance on various tasks over traditional CS-MRI methods. We also evaluate the generalization ability of TACKLE by experimentally collecting a new dataset using different acquisition setups from the training data. Without additional fine-tuning, TACKLE functions robustly and leads to both numerical and visual improvements.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 01, 2023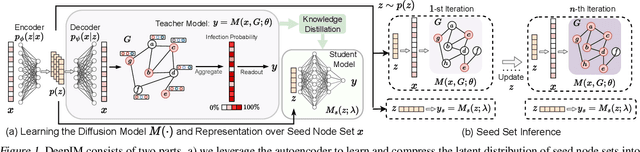
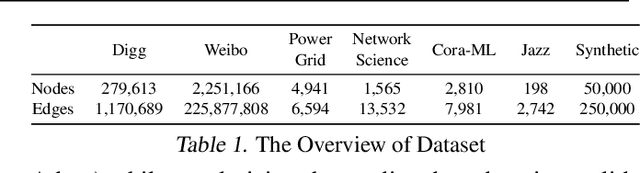
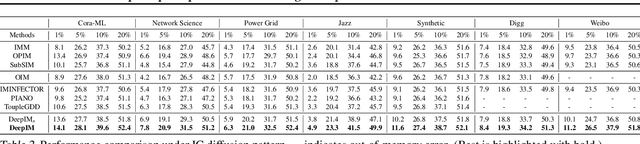
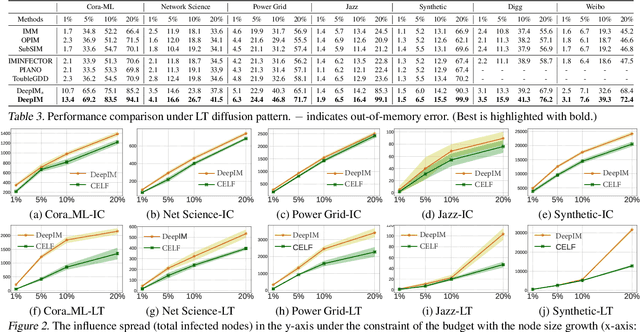
Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.