 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Self-supervised Image Denoising with Downsampled Invariance Loss and Conditional Blind-Spot Network
Apr 19, 2023

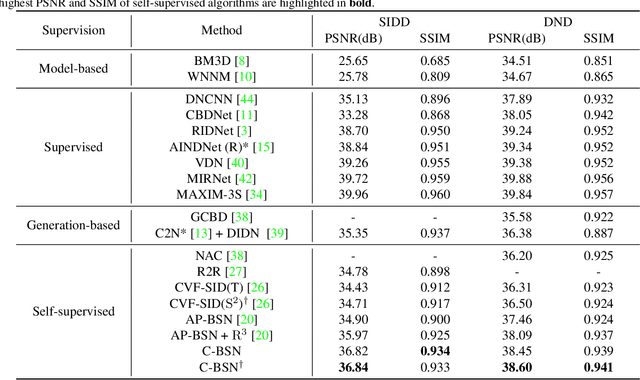
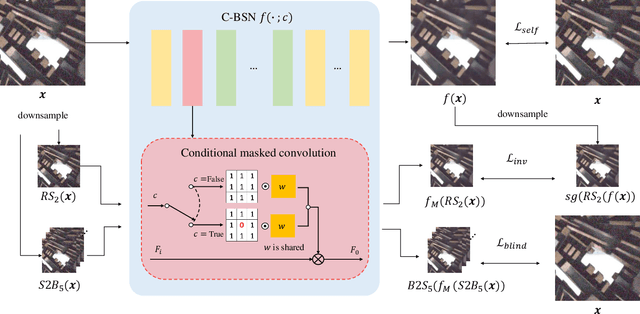

There have been many image denoisers using deep neural networks, which outperform conventional model-based methods by large margins. Recently, self-supervised methods have attracted attention because constructing a large real noise dataset for supervised training is an enormous burden. The most representative self-supervised denoisers are based on blind-spot networks, which exclude the receptive field's center pixel. However, excluding any input pixel is abandoning some information, especially when the input pixel at the corresponding output position is excluded. In addition, a standard blind-spot network fails to reduce real camera noise due to the pixel-wise correlation of noise, though it successfully removes independently distributed synthetic noise. Hence, to realize a more practical denoiser, we propose a novel self-supervised training framework that can remove real noise. For this, we derive the theoretic upper bound of a supervised loss where the network is guided by the downsampled blinded output. Also, we design a conditional blind-spot network (C-BSN), which selectively controls the blindness of the network to use the center pixel information. Furthermore, we exploit a random subsampler to decorrelate noise spatially, making the C-BSN free of visual artifacts that were often seen in downsample-based methods. Extensive experiments show that the proposed C-BSN achieves state-of-the-art performance on real-world datasets as a self-supervised denoiser and shows qualitatively pleasing results without any post-processing or refinement.
A baseline on continual learning methods for video action recognition
Apr 26, 2023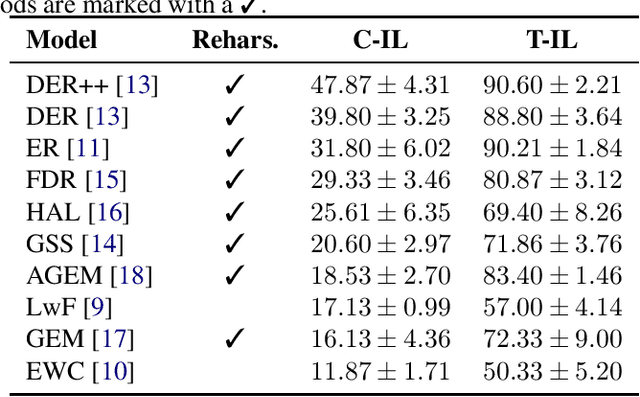
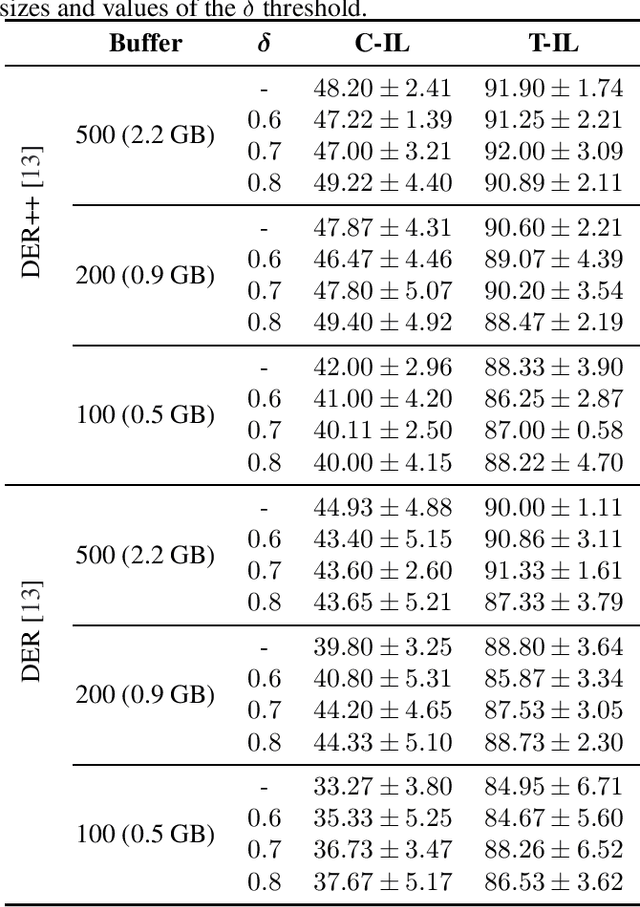
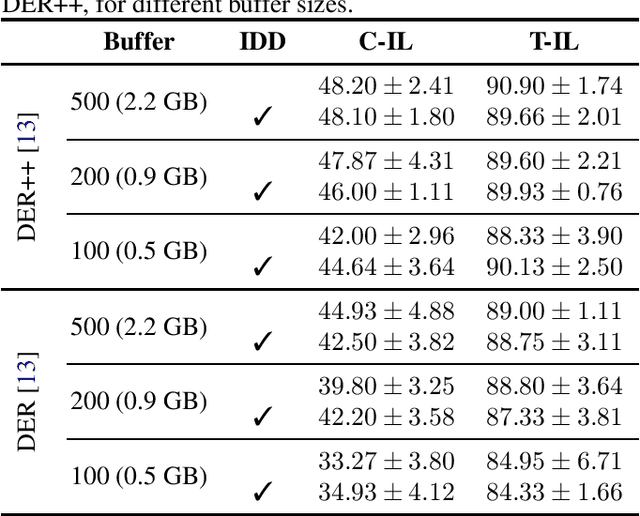
Continual learning has recently attracted attention from the research community, as it aims to solve long-standing limitations of classic supervisedly-trained models. However, most research on this subject has tackled continual learning in simple image classification scenarios. In this paper, we present a benchmark of state-of-the-art continual learning methods on video action recognition. Besides the increased complexity due to the temporal dimension, the video setting imposes stronger requirements on computing resources for top-performing rehearsal methods. To counteract the increased memory requirements, we present two method-agnostic variants for rehearsal methods, exploiting measures of either model confidence or data information to select memorable samples. Our experiments show that, as expected from the literature, rehearsal methods outperform other approaches; moreover, the proposed memory-efficient variants are shown to be effective at retaining a certain level of performance with a smaller buffer size.
Shades of meaning: Uncovering the geometry of ambiguous word representations through contextualised language models
Apr 26, 2023
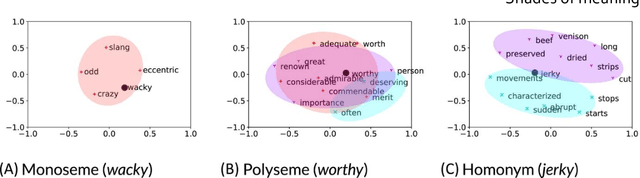
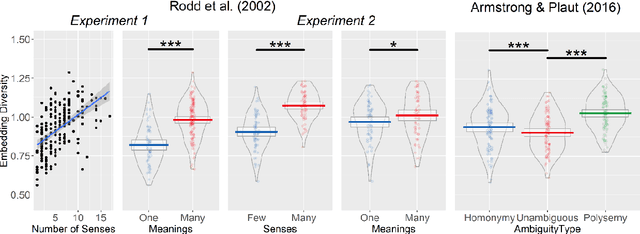
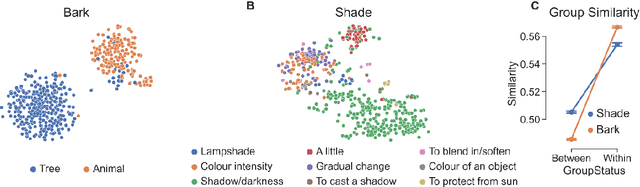
Lexical ambiguity presents a profound and enduring challenge to the language sciences. Researchers for decades have grappled with the problem of how language users learn, represent and process words with more than one meaning. Our work offers new insight into psychological understanding of lexical ambiguity through a series of simulations that capitalise on recent advances in contextual language models. These models have no grounded understanding of the meanings of words at all; they simply learn to predict words based on the surrounding context provided by other words. Yet, our analyses show that their representations capture fine-grained meaningful distinctions between unambiguous, homonymous, and polysemous words that align with lexicographic classifications and psychological theorising. These findings provide quantitative support for modern psychological conceptualisations of lexical ambiguity and raise new challenges for understanding of the way that contextual information shapes the meanings of words across different timescales.
Source-Filter-Based Generative Adversarial Neural Vocoder for High Fidelity Speech Synthesis
Apr 26, 2023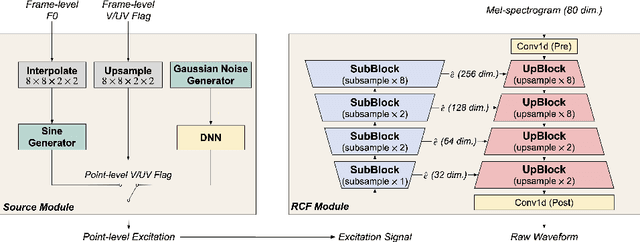
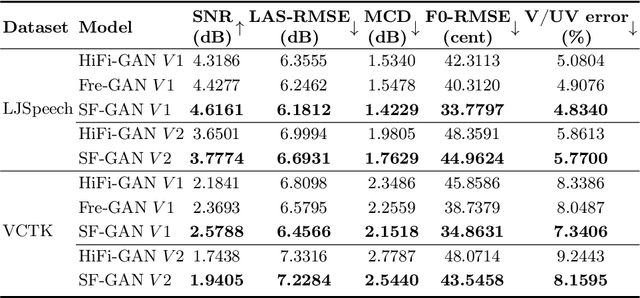
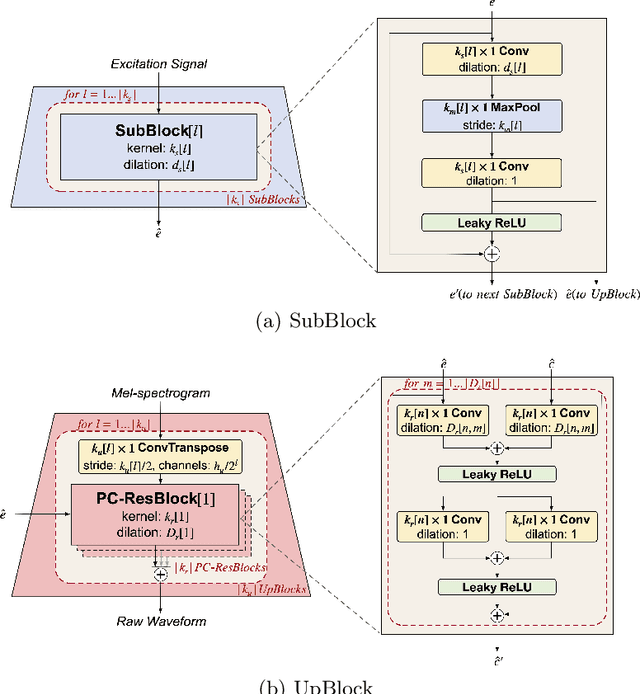
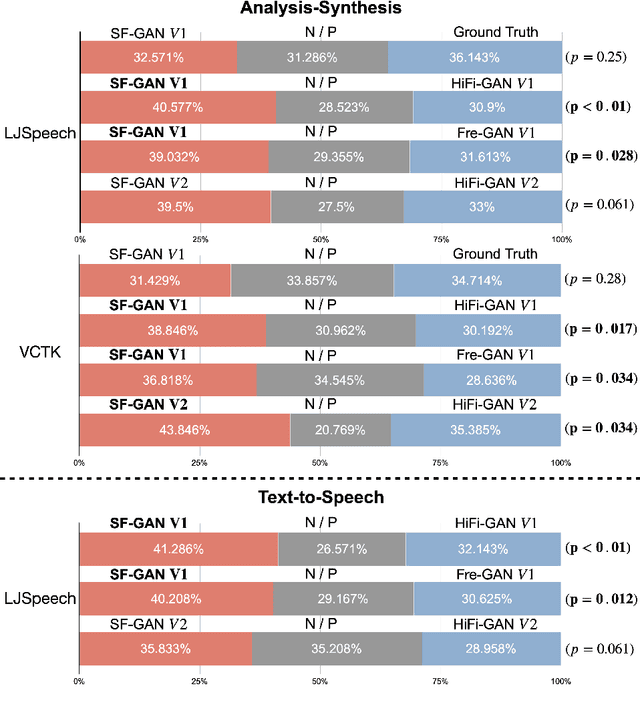
This paper proposes a source-filter-based generative adversarial neural vocoder named SF-GAN, which achieves high-fidelity waveform generation from input acoustic features by introducing F0-based source excitation signals to a neural filter framework. The SF-GAN vocoder is composed of a source module and a resolution-wise conditional filter module and is trained based on generative adversarial strategies. The source module produces an excitation signal from the F0 information, then the resolution-wise convolutional filter module combines the excitation signal with processed acoustic features at various temporal resolutions and finally reconstructs the raw waveform. The experimental results show that our proposed SF-GAN vocoder outperforms the state-of-the-art HiFi-GAN and Fre-GAN in both analysis-synthesis (AS) and text-to-speech (TTS) tasks, and the synthesized speech quality of SF-GAN is comparable to the ground-truth audio.
Deep Graph Representation Learning and Optimization for Influence Maximization
May 01, 2023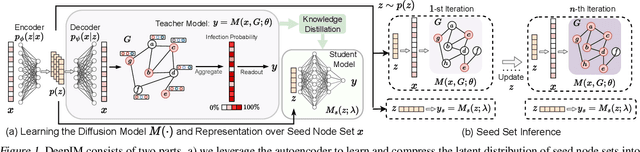
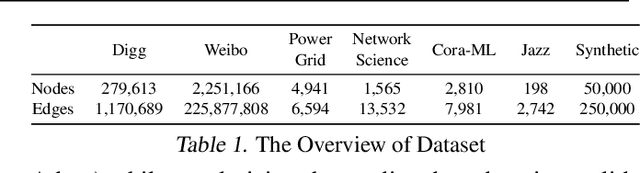
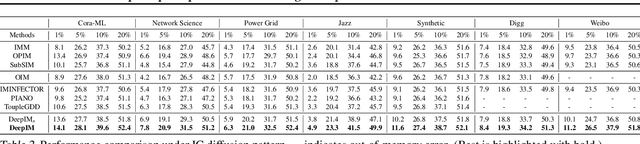
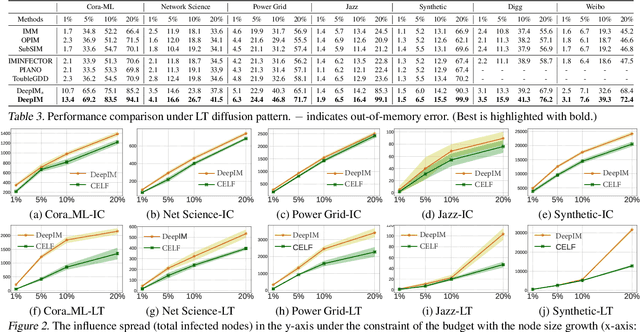
Influence maximization (IM) is formulated as selecting a set of initial users from a social network to maximize the expected number of influenced users. Researchers have made great progress in designing various traditional methods, and their theoretical design and performance gain are close to a limit. In the past few years, learning-based IM methods have emerged to achieve stronger generalization ability to unknown graphs than traditional ones. However, the development of learning-based IM methods is still limited by fundamental obstacles, including 1) the difficulty of effectively solving the objective function; 2) the difficulty of characterizing the diversified underlying diffusion patterns; and 3) the difficulty of adapting the solution under various node-centrality-constrained IM variants. To cope with the above challenges, we design a novel framework DeepIM to generatively characterize the latent representation of seed sets, and we propose to learn the diversified information diffusion pattern in a data-driven and end-to-end manner. Finally, we design a novel objective function to infer optimal seed sets under flexible node-centrality-based budget constraints. Extensive analyses are conducted over both synthetic and real-world datasets to demonstrate the overall performance of DeepIM. The code and data are available at: https://github.com/triplej0079/DeepIM.
PRSeg: A Lightweight Patch Rotate MLP Decoder for Semantic Segmentation
May 01, 2023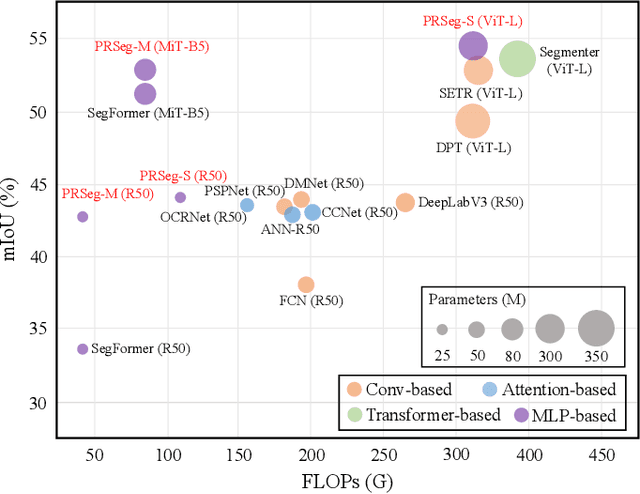
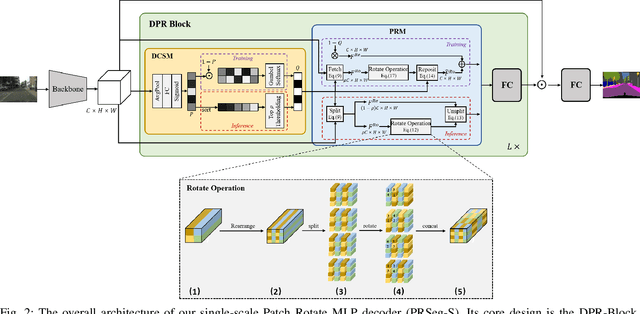
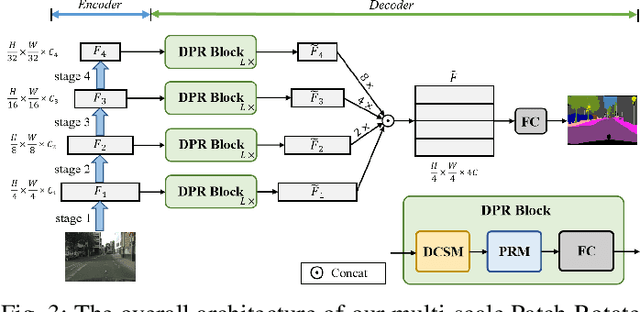

The lightweight MLP-based decoder has become increasingly promising for semantic segmentation. However, the channel-wise MLP cannot expand the receptive fields, lacking the context modeling capacity, which is critical to semantic segmentation. In this paper, we propose a parametric-free patch rotate operation to reorganize the pixels spatially. It first divides the feature map into multiple groups and then rotates the patches within each group. Based on the proposed patch rotate operation, we design a novel segmentation network, named PRSeg, which includes an off-the-shelf backbone and a lightweight Patch Rotate MLP decoder containing multiple Dynamic Patch Rotate Blocks (DPR-Blocks). In each DPR-Block, the fully connected layer is performed following a Patch Rotate Module (PRM) to exchange spatial information between pixels. Specifically, in PRM, the feature map is first split into the reserved part and rotated part along the channel dimension according to the predicted probability of the Dynamic Channel Selection Module (DCSM), and our proposed patch rotate operation is only performed on the rotated part. Extensive experiments on ADE20K, Cityscapes and COCO-Stuff 10K datasets prove the effectiveness of our approach. We expect that our PRSeg can promote the development of MLP-based decoder in semantic segmentation.
What Do Self-Supervised Vision Transformers Learn?
May 01, 2023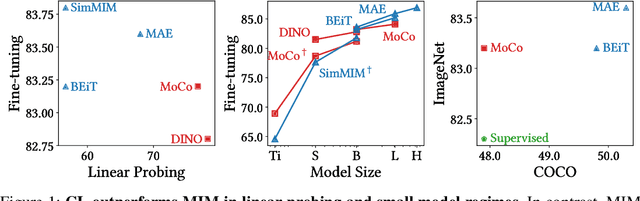
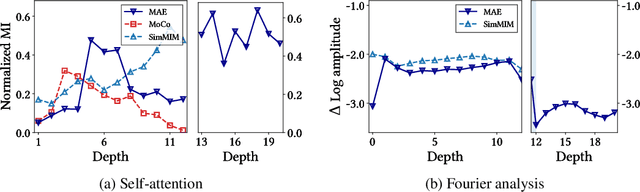
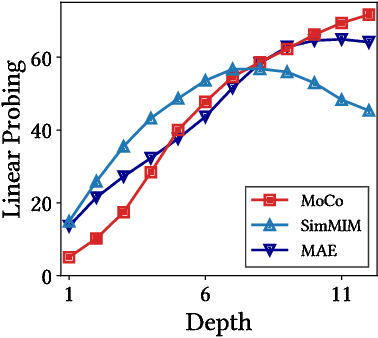
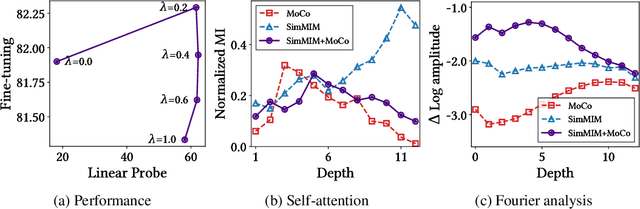
We present a comparative study on how and why contrastive learning (CL) and masked image modeling (MIM) differ in their representations and in their performance of downstream tasks. In particular, we demonstrate that self-supervised Vision Transformers (ViTs) have the following properties: (1) CL trains self-attentions to capture longer-range global patterns than MIM, such as the shape of an object, especially in the later layers of the ViT architecture. This CL property helps ViTs linearly separate images in their representation spaces. However, it also makes the self-attentions collapse into homogeneity for all query tokens and heads. Such homogeneity of self-attention reduces the diversity of representations, worsening scalability and dense prediction performance. (2) CL utilizes the low-frequency signals of the representations, but MIM utilizes high-frequencies. Since low- and high-frequency information respectively represent shapes and textures, CL is more shape-oriented and MIM more texture-oriented. (3) CL plays a crucial role in the later layers, while MIM mainly focuses on the early layers. Upon these analyses, we find that CL and MIM can complement each other and observe that even the simplest harmonization can help leverage the advantages of both methods. The code is available at https://github.com/naver-ai/cl-vs-mim.
RISnet: A Scalable Approach for Reconfigurable Intelligent Surface Optimization with Partial CSI
May 01, 2023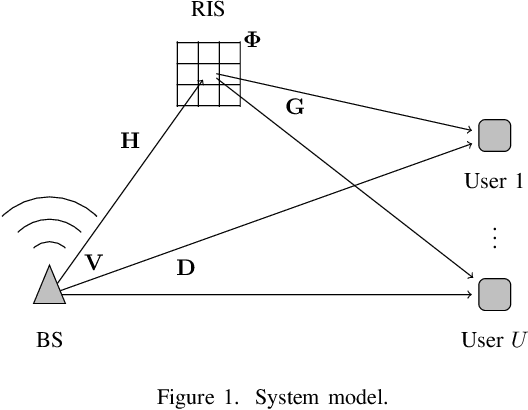


The reconfigurable intelligent surface (RIS) is a promising technology that enables wireless communication systems to achieve improved performance by intelligently manipulating wireless channels. In this paper, we consider the sum-rate maximization problem in a downlink multi-user multi-input-single-output (MISO) channel via space-division multiple access (SDMA). Two major challenges of this problem are the high dimensionality due to the large number of RIS elements and the difficulty to obtain the full channel state information (CSI), which is assumed known in many algorithms proposed in the literature. Instead, we propose a hybrid machine learning approach using the weighted minimum mean squared error (WMMSE) precoder at the base station (BS) and a dedicated neural network (NN) architecture, RISnet, for RIS configuration. The RISnet has a good scalability to optimize 1296 RIS elements and requires partial CSI of only 16 RIS elements as input. We show it achieves a high performance with low requirement for channel estimation for geometric channel models obtained with ray-tracing simulation. The unsupervised learning lets the RISnet find an optimized RIS configuration by itself. Numerical results show that a trained model configures the RIS with low computational effort, considerably outperforms the baselines, and can work with discrete phase shifts.
Similarity-Aware Multimodal Prompt Learning for Fake News Detection
Apr 20, 2023
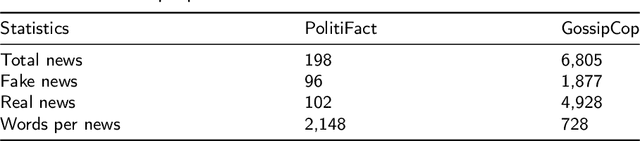
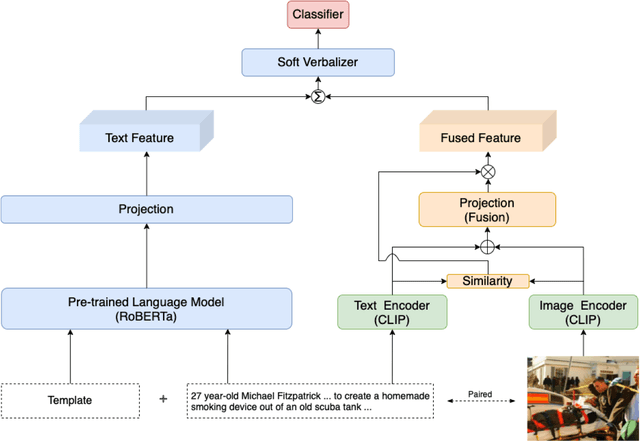
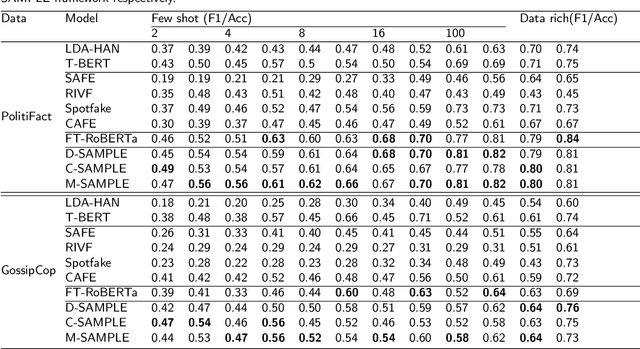
The standard paradigm for fake news detection mainly utilizes text information to model the truthfulness of news. However, the discourse of online fake news is typically subtle and it requires expert knowledge to use textual information to debunk fake news. Recently, studies focusing on multimodal fake news detection have outperformed text-only methods. Recent approaches utilizing the pre-trained model to extract unimodal features, or fine-tuning the pre-trained model directly, have become a new paradigm for detecting fake news. Again, this paradigm either requires a large number of training instances, or updates the entire set of pre-trained model parameters, making real-world fake news detection impractical. Furthermore, traditional multimodal methods fuse the cross-modal features directly without considering that the uncorrelated semantic representation might inject noise into the multimodal features. This paper proposes a Similarity-Aware Multimodal Prompt Learning (SAMPLE) framework. First, we incorporate prompt learning into multimodal fake news detection. Prompt learning, which only tunes prompts with a frozen language model, can reduce memory usage significantly and achieve comparable performances, compared with fine-tuning. We analyse three prompt templates with a soft verbalizer to detect fake news. In addition, we introduce the similarity-aware fusing method to adaptively fuse the intensity of multimodal representation and mitigate the noise injection via uncorrelated cross-modal features. For evaluation, SAMPLE surpasses the F1 and the accuracies of previous works on two benchmark multimodal datasets, demonstrating the effectiveness of the proposed method in detecting fake news. In addition, SAMPLE also is superior to other approaches regardless of few-shot and data-rich settings.
Is ChatGPT a Good Recommender? A Preliminary Study
Apr 20, 2023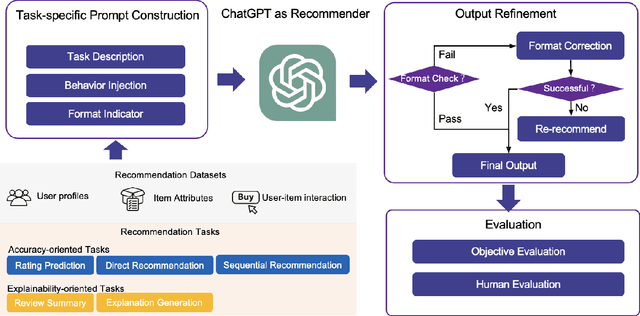
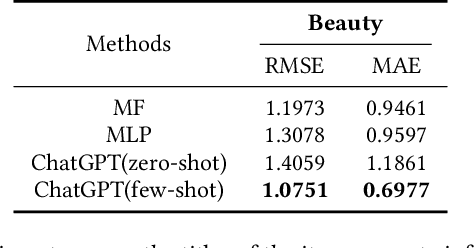
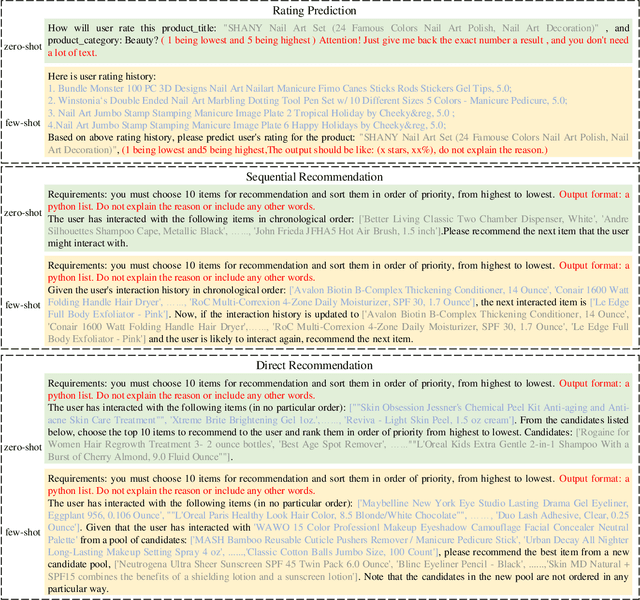
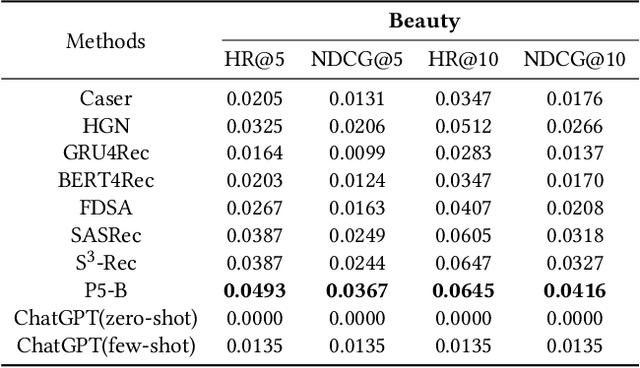
Recommendation systems have witnessed significant advancements and have been widely used over the past decades. However, most traditional recommendation methods are task-specific and therefore lack efficient generalization ability. Recently, the emergence of ChatGPT has significantly advanced NLP tasks by enhancing the capabilities of conversational models. Nonetheless, the application of ChatGPT in the recommendation domain has not been thoroughly investigated. In this paper, we employ ChatGPT as a general-purpose recommendation model to explore its potential for transferring extensive linguistic and world knowledge acquired from large-scale corpora to recommendation scenarios. Specifically, we design a set of prompts and evaluate ChatGPT's performance on five recommendation scenarios. Unlike traditional recommendation methods, we do not fine-tune ChatGPT during the entire evaluation process, relying only on the prompts themselves to convert recommendation tasks into natural language tasks. Further, we explore the use of few-shot prompting to inject interaction information that contains user potential interest to help ChatGPT better understand user needs and interests. Comprehensive experimental results on Amazon Beauty dataset show that ChatGPT has achieved promising results in certain tasks and is capable of reaching the baseline level in others. We conduct human evaluations on two explainability-oriented tasks to more accurately evaluate the quality of contents generated by different models. And the human evaluations show ChatGPT can truly understand the provided information and generate clearer and more reasonable results. We hope that our study can inspire researchers to further explore the potential of language models like ChatGPT to improve recommendation performance and contribute to the advancement of the recommendation systems field.