 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Environmental sound conversion from vocal imitations and sound event labels
Apr 29, 2023
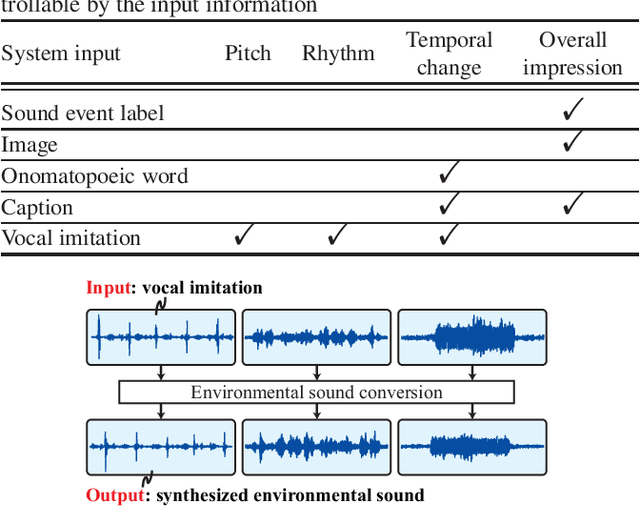
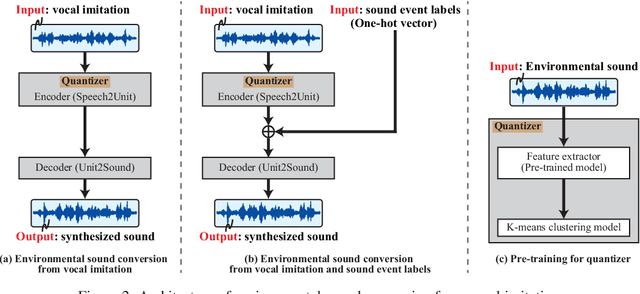
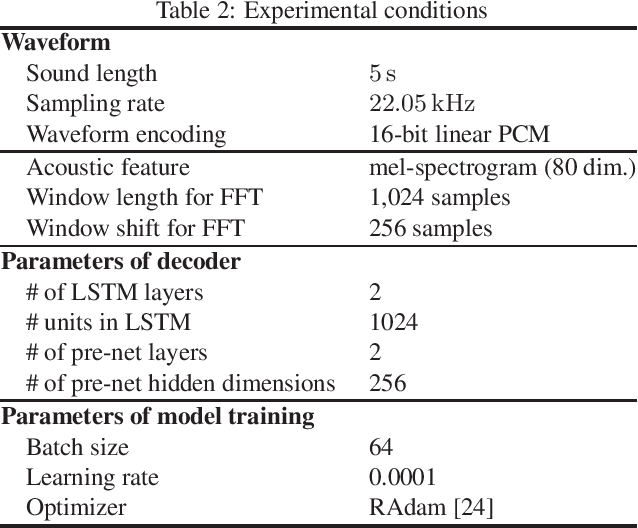
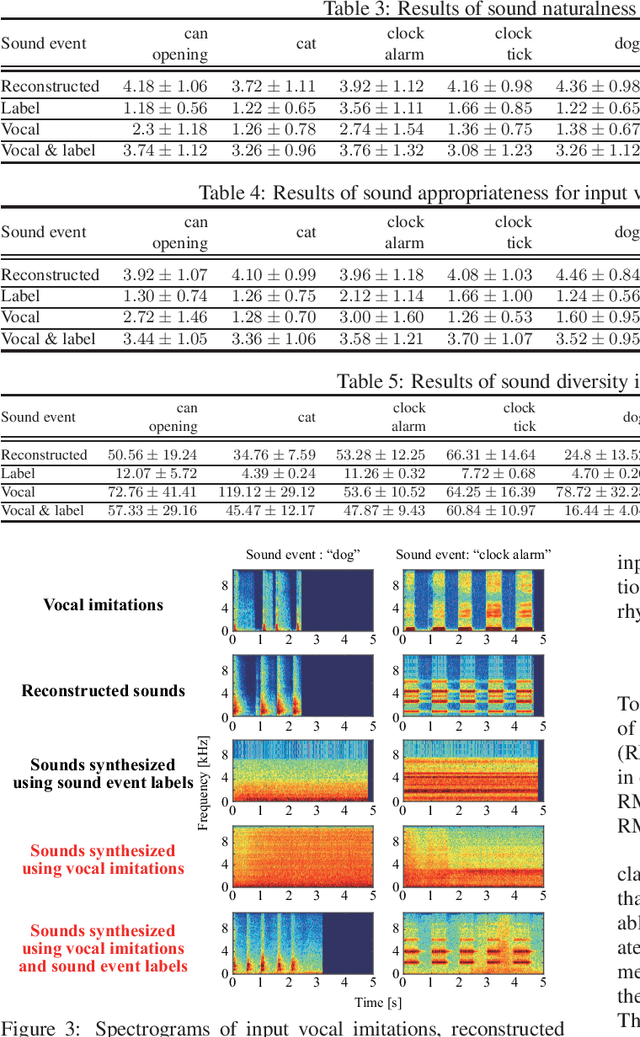
One way of expressing an environmental sound is using vocal imitations, which involve the process of replicating or mimicking the rhythms and pitches of sounds by voice. We can effectively express the features of environmental sounds, such as rhythms and pitches, using vocal imitations, which cannot be expressed by conventional input information, such as sound event labels, images, and texts, in an environmental sound synthesis model. Therefore, using vocal imitations as input for environmental sound synthesis will enable us to control the pitches and rhythms of sounds and generate diverse sounds. In this paper, we thus propose a framework for environmental sound conversion from vocal imitations to generate diverse sounds. We also propose a method of environmental sound synthesis from vocal imitations and sound event labels. Using sound event labels is expected to control the sound event class of the synthesized sound, which cannot be controlled by only vocal imitations. Our objective and subjective experimental results show that vocal imitations effectively control the pitches and rhythms of sounds and generate diverse sounds.
MFBE: Leveraging Multi-Field Information of FAQs for Efficient Dense Retrieval
Feb 23, 2023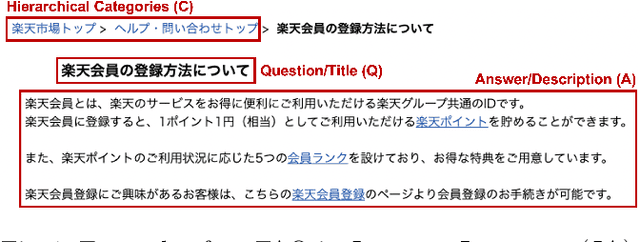
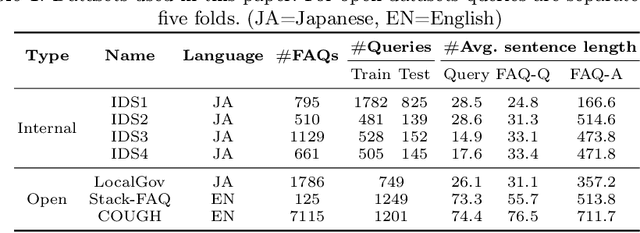
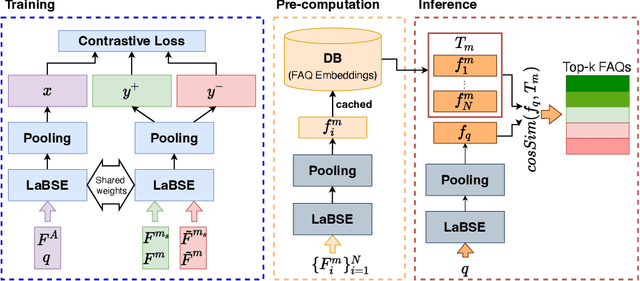
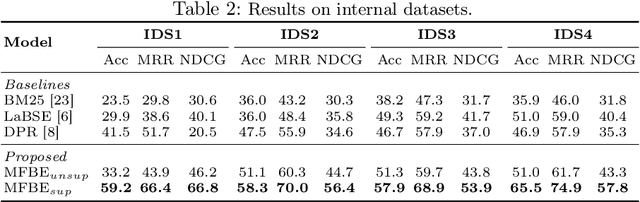
In the domain of question-answering in NLP, the retrieval of Frequently Asked Questions (FAQ) is an important sub-area which is well researched and has been worked upon for many languages. Here, in response to a user query, a retrieval system typically returns the relevant FAQs from a knowledge-base. The efficacy of such a system depends on its ability to establish semantic match between the query and the FAQs in real-time. The task becomes challenging due to the inherent lexical gap between queries and FAQs, lack of sufficient context in FAQ titles, scarcity of labeled data and high retrieval latency. In this work, we propose a bi-encoder-based query-FAQ matching model that leverages multiple combinations of FAQ fields (like, question, answer, and category) both during model training and inference. Our proposed Multi-Field Bi-Encoder (MFBE) model benefits from the additional context resulting from multiple FAQ fields and performs well even with minimal labeled data. We empirically support this claim through experiments on proprietary as well as open-source public datasets in both unsupervised and supervised settings. Our model achieves around 27% and 20% better top-1 accuracy for the FAQ retrieval task on internal and open datasets, respectively over the best performing baseline.
An Asynchronous Decentralized Algorithm for Wasserstein Barycenter Problem
Apr 23, 2023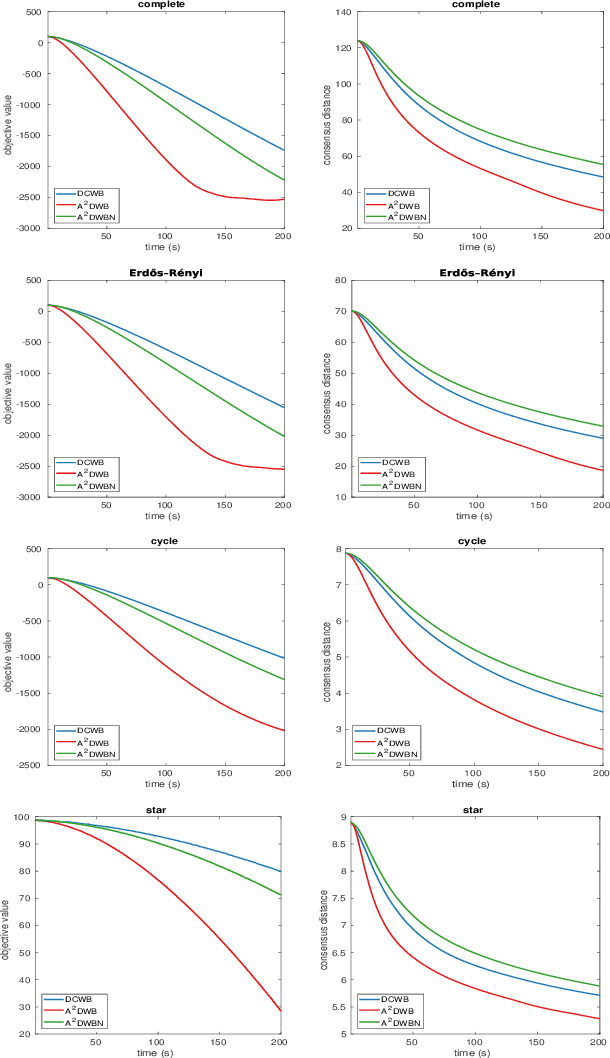
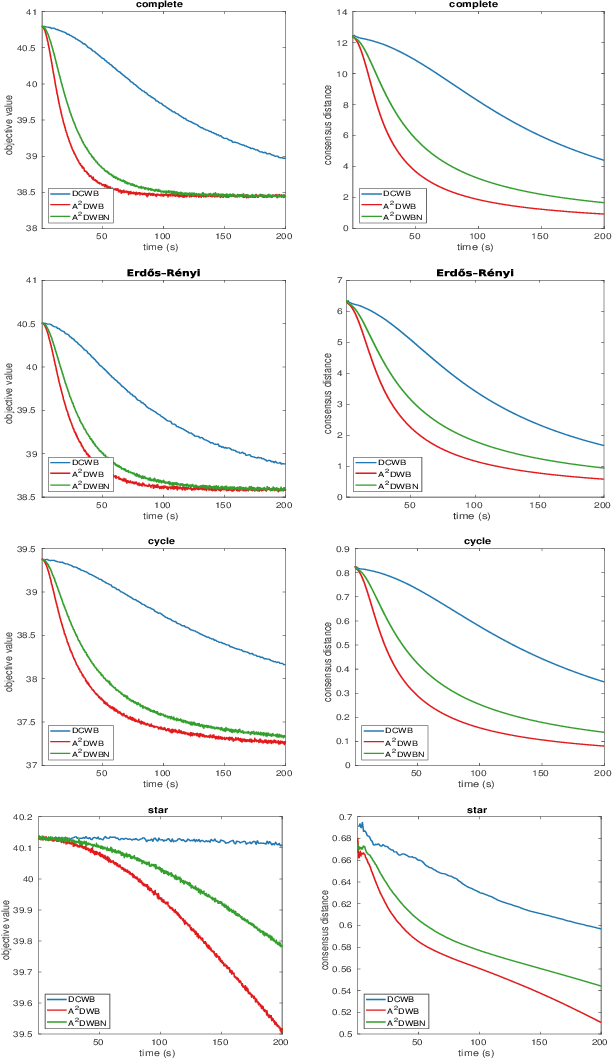
Wasserstein Barycenter Problem (WBP) has recently received much attention in the field of artificial intelligence. In this paper, we focus on the decentralized setting for WBP and propose an asynchronous decentralized algorithm (A$^2$DWB). A$^2$DWB is induced by a novel stochastic block coordinate descent method to optimize the dual of entropy regularized WBP. To our knowledge, A$^2$DWB is the first asynchronous decentralized algorithm for WBP. Unlike its synchronous counterpart, it updates local variables in a manner that only relies on the stale neighbor information, which effectively alleviate the waiting overhead, and thus substantially improve the time efficiency. Empirical results validate its superior performance compared to the latest synchronous algorithm.
Inadmissibility of the corrected Akaike information criterion
Nov 17, 2022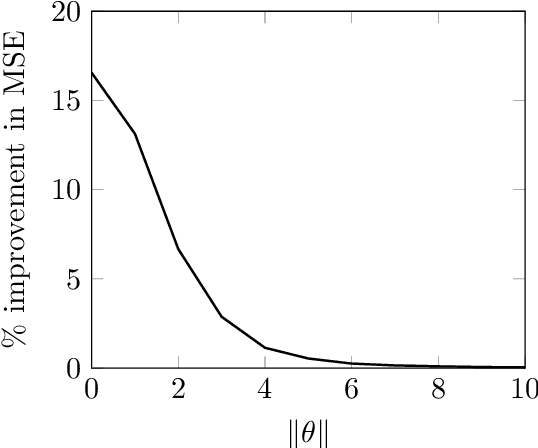
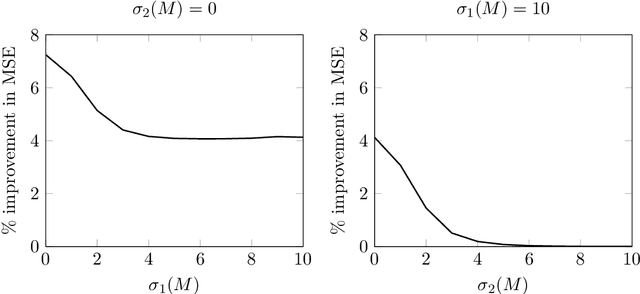
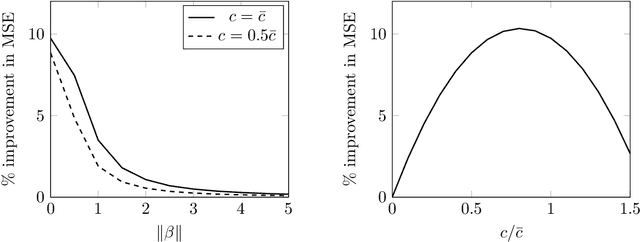
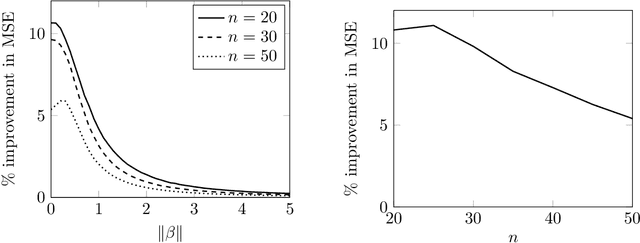
For the multivariate linear regression model with unknown covariance, the corrected Akaike information criterion is the minimum variance unbiased estimator of the expected Kullback--Leibler discrepancy. In this study, based on the loss estimation framework, we show its inadmissibility as an estimator of the Kullback--Leibler discrepancy itself, instead of the expected Kullback--Leibler discrepancy. We provide improved estimators of the Kullback--Leibler discrepancy that work well in reduced-rank situations and examine their performance numerically.
Domain-agnostic segmentation of thalamic nuclei from joint structural and diffusion MRI
May 05, 2023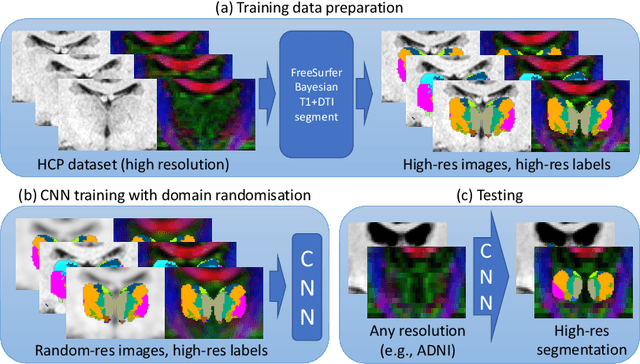
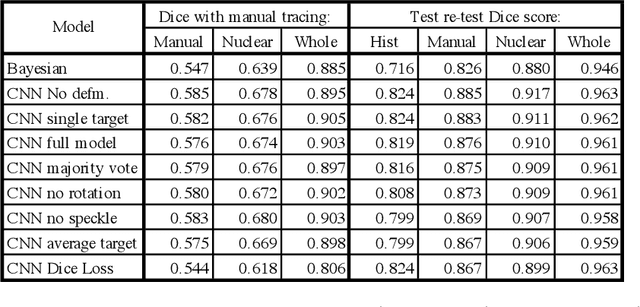
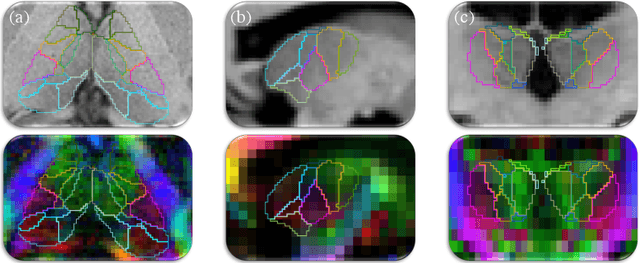

The human thalamus is a highly connected subcortical grey-matter structure within the brain. It comprises dozens of nuclei with different function and connectivity, which are affected differently by disease. For this reason, there is growing interest in studying the thalamic nuclei in vivo with MRI. Tools are available to segment the thalamus from 1 mm T1 scans, but the contrast of the lateral and internal boundaries is too faint to produce reliable segmentations. Some tools have attempted to incorporate information from diffusion MRI in the segmentation to refine these boundaries, but do not generalise well across diffusion MRI acquisitions. Here we present the first CNN that can segment thalamic nuclei from T1 and diffusion data of any resolution without retraining or fine tuning. Our method builds on a public histological atlas of the thalamic nuclei and silver standard segmentations on high-quality diffusion data obtained with a recent Bayesian adaptive segmentation tool. We combine these with an approximate degradation model for fast domain randomisation during training. Our CNN produces a segmentation at 0.7 mm isotropic resolution, irrespective of the resolution of the input. Moreover, it uses a parsimonious model of the diffusion signal at each voxel (fractional anisotropy and principal eigenvector) that is compatible with virtually any set of directions and b-values, including huge amounts of legacy data. We show results of our proposed method on three heterogeneous datasets acquired on dozens of different scanners. An implementation of the method is publicly available at https://freesurfer.net/fswiki/ThalamicNucleiDTI.
U-NEED: A Fine-grained Dataset for User Needs-Centric E-commerce Conversational Recommendation
May 05, 2023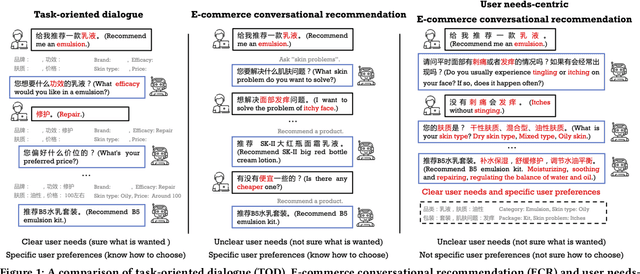
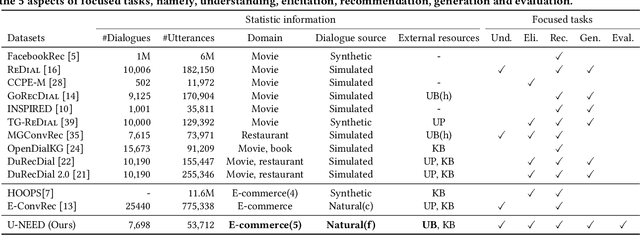
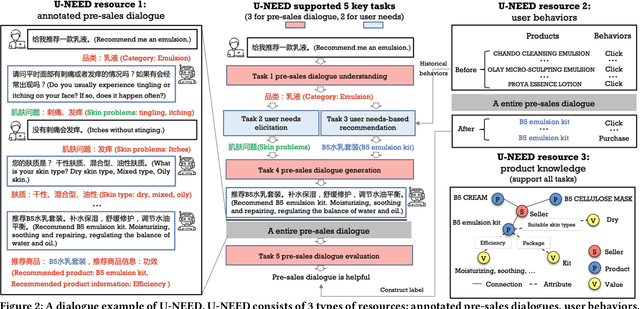
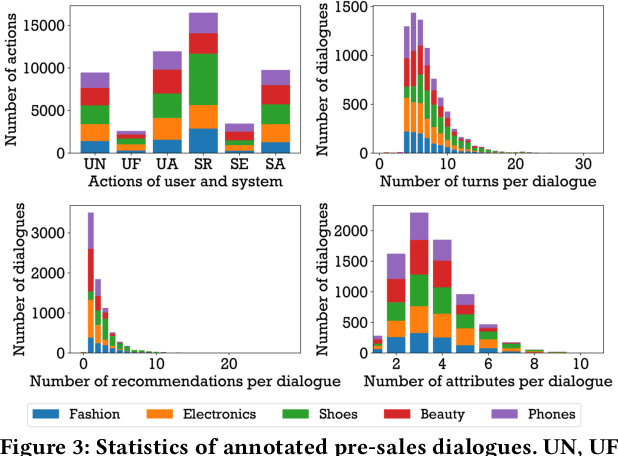
Conversational recommender systems (CRSs) aim to understand the information needs and preferences expressed in a dialogue to recommend suitable items to the user. Most of the existing conversational recommendation datasets are synthesized or simulated with crowdsourcing, which has a large gap with real-world scenarios. To bridge the gap, previous work contributes a dataset E-ConvRec, based on pre-sales dialogues between users and customer service staff in E-commerce scenarios. However, E-ConvRec only supplies coarse-grained annotations and general tasks for making recommendations in pre-sales dialogues. Different from that, we use real user needs as a clue to explore the E-commerce conversational recommendation in complex pre-sales dialogues, namely user needs-centric E-commerce conversational recommendation (UNECR). In this paper, we construct a user needs-centric E-commerce conversational recommendation dataset (U-NEED) from real-world E-commerce scenarios. U-NEED consists of 3 types of resources: (i) 7,698 fine-grained annotated pre-sales dialogues in 5 top categories (ii) 333,879 user behaviors and (iii) 332,148 product knowledge tuples. To facilitate the research of UNECR, we propose 5 critical tasks: (i) pre-sales dialogue understanding (ii) user needs elicitation (iii) user needs-based recommendation (iv) pre-sales dialogue generation and (v) pre-sales dialogue evaluation. We establish baseline methods and evaluation metrics for each task. We report experimental results of 5 tasks on U-NEED. We also report results in 3 typical categories. Experimental results indicate that the challenges of UNECR in various categories are different.
DisenBooth: Disentangled Parameter-Efficient Tuning for Subject-Driven Text-to-Image Generation
May 05, 2023
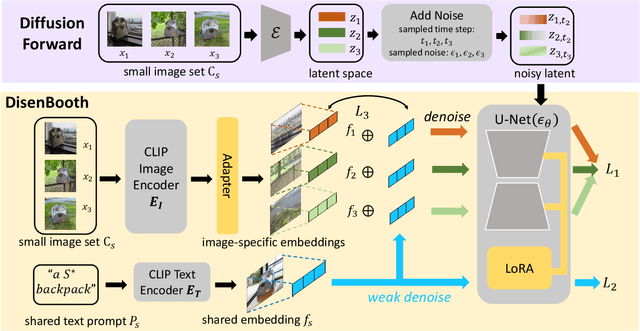
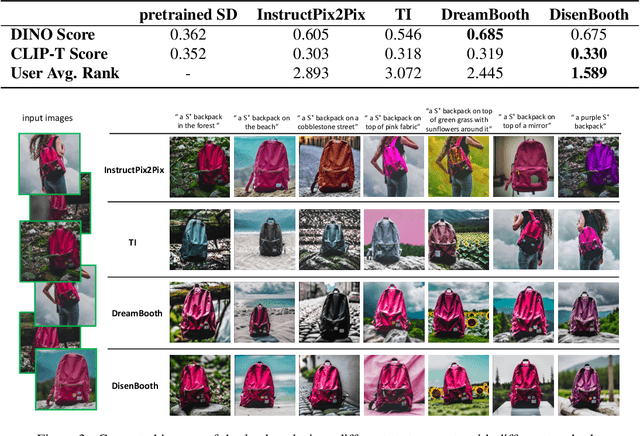

Given a small set of images of a specific subject, subject-driven text-to-image generation aims to generate customized images of the subject according to new text descriptions, which has attracted increasing attention in the community recently. Current subject-driven text-to-image generation methods are mainly based on finetuning a pretrained large-scale text-to-image generation model. However, these finetuning methods map the images of the subject into an embedding highly entangled with subject-identity-unrelated information, which may result in the inconsistency between the generated images and the text descriptions and the changes in the subject identity. To tackle the problem, we propose DisenBooth, a disentangled parameter-efficient tuning framework for subject-driven text-to-image generation. DisenBooth enables generating new images that simultaneously preserve the subject identity and conform to the text descriptions, by disentangling the embedding into an identity-related and an identity-unrelated part. Specifically, DisenBooth is based on the pretrained diffusion models and conducts finetuning in the diffusion denoising process, where a shared identity embedding and an image-specific identity-unrelated embedding are utilized jointly for denoising each image. To make the two embeddings disentangled, two auxiliary objectives are proposed. Additionally, to improve the finetuning efficiency, a parameter-efficient finetuning strategy is adopted. Extensive experiments show that our DisenBooth can faithfully learn well-disentangled identity-related and identity-unrelated embeddings. With the shared identity embedding, DisenBooth demonstrates superior subject-driven text-to-image generation ability. Additionally, DisenBooth provides a more flexible and controllable framework with different combinations of the disentangled embeddings.
Algorithms for Social Justice: Affirmative Action in Social Networks
May 05, 2023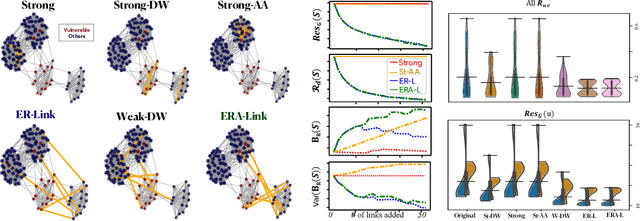
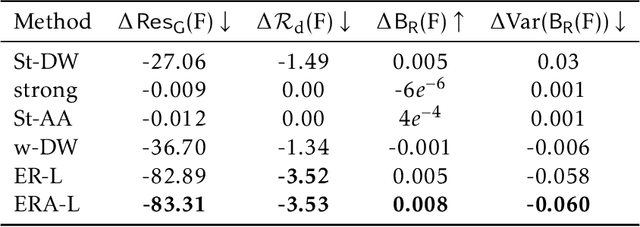
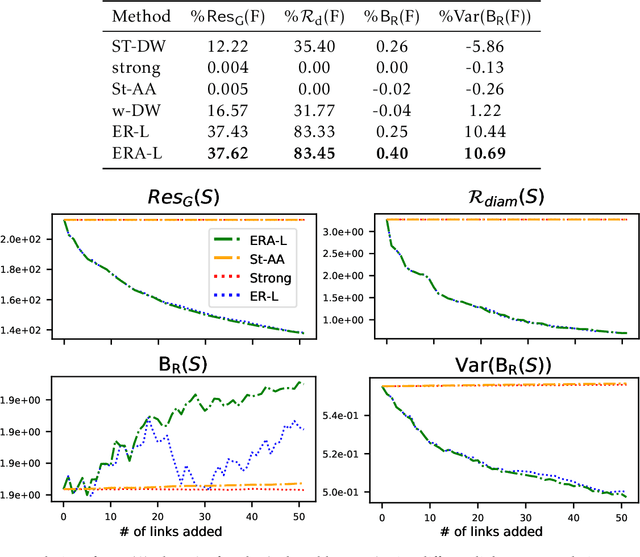
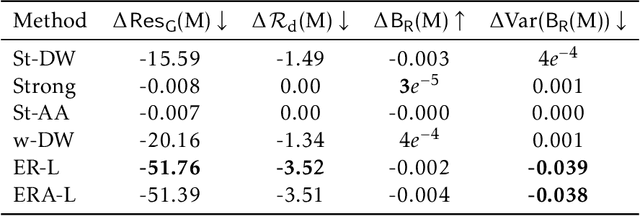
Link recommendation algorithms contribute to shaping human relations of billions of users worldwide in social networks. To maximize relevance, they typically propose connecting users that are similar to each other. This has been found to create information silos, exacerbating the isolation suffered by vulnerable salient groups and perpetuating societal stereotypes. To mitigate these limitations, a significant body of work has been devoted to the implementation of fair link recommendation methods. However, most approaches do not question the ultimate goal of link recommendation algorithms, namely the monetization of users' engagement in intricate business models of data trade. This paper advocates for a diversification of players and purposes of social network platforms, aligned with the pursue of social justice. To illustrate this conceptual goal, we present ERA-Link, a novel link recommendation algorithm based on spectral graph theory that counteracts the systemic societal discrimination suffered by vulnerable groups by explicitly implementing affirmative action. We propose four principled evaluation measures, derived from effective resistance, to quantitatively analyze the behavior of the proposed method and compare it to three alternative approaches. Experiments with synthetic and real-world networks illustrate how ERA-Link generates better outcomes according to all evaluation measures, not only for the vulnerable group but for the whole network. In other words, ERA-Link recommends connections that mitigate the structural discrimination of a vulnerable group, improves social cohesion and increases the social capital of all network users. Furthermore, by promoting the access to a diversity of users, ERA-Link facilitates innovation opportunities.
Physics-inspired Neuroacoustic Computing Based on Tunable Nonlinear Multiple-scattering
Apr 17, 2023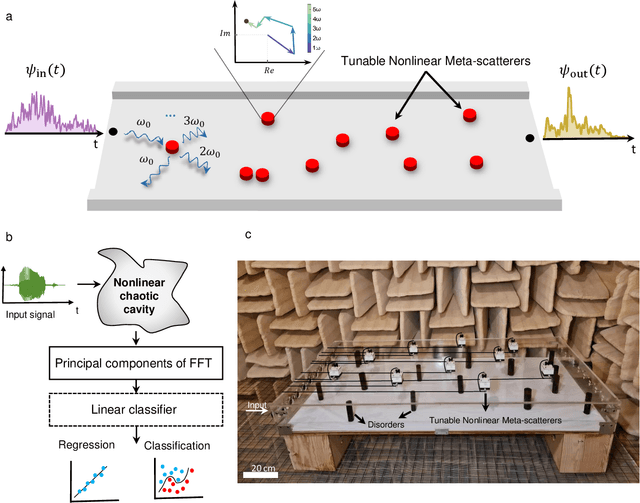
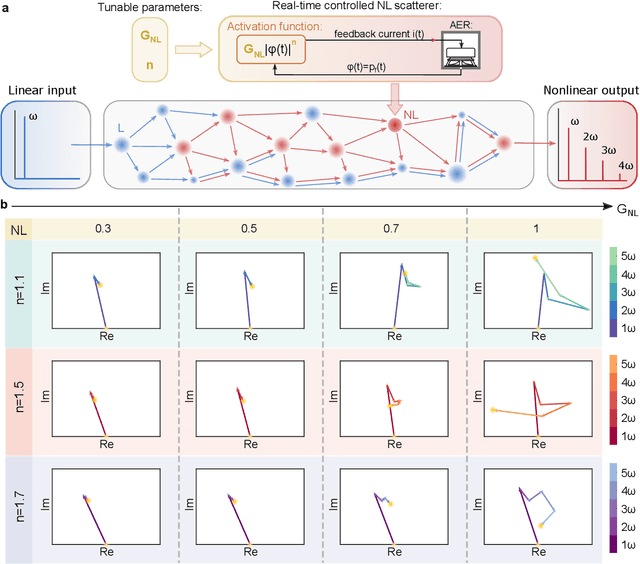
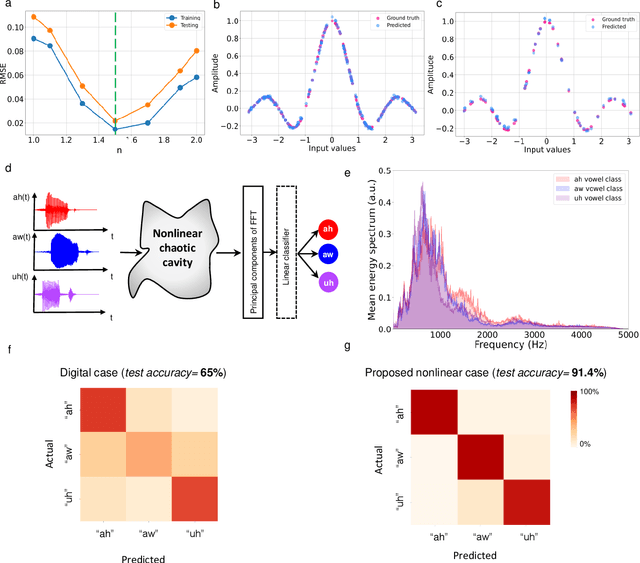
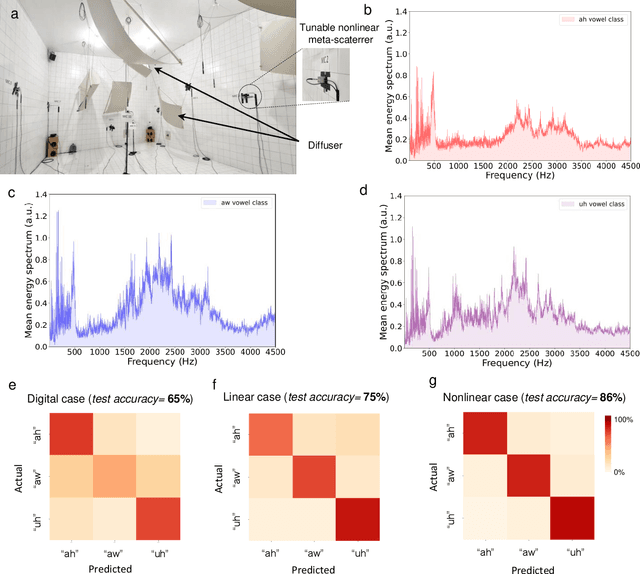
Waves, such as light and sound, inherently bounce and mix due to multiple scattering induced by the complex material objects that surround us. This scattering process severely scrambles the information carried by waves, challenging conventional communication systems, sensing paradigms, and wave-based computing schemes. Here, we show that instead of being a hindrance, multiple scattering can be beneficial to enable and enhance analog nonlinear information mapping, allowing for the direct physical implementation of computational paradigms such as reservoir computing and extreme learning machines. We propose a physics-inspired version of such computational architectures for speech and vowel recognition that operate directly in the native domain of the input signal, namely on real-sounds, without any digital pre-processing or encoding conversion and backpropagation training computation. We first implement it in a proof-of-concept prototype, a nonlinear chaotic acoustic cavity containing multiple tunable and power-efficient nonlinear meta-scatterers. We prove the efficiency of the acoustic-based computing system for vowel recognition tasks with high testing classification accuracy (91.4%). Finally, we demonstrate the high performance of vowel recognition in the natural environment of a reverberation room. Our results open the way for efficient acoustic learning machines that operate directly on the input sound, and leverage physics to enable Natural Language Processing (NLP).
Efficient View Synthesis and 3D-based Multi-Frame Denoising with Multiplane Feature Representations
Apr 05, 2023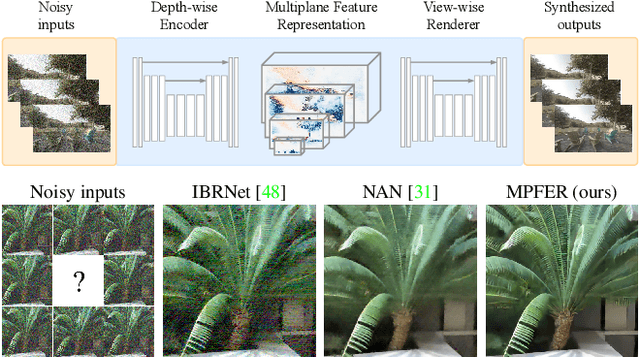
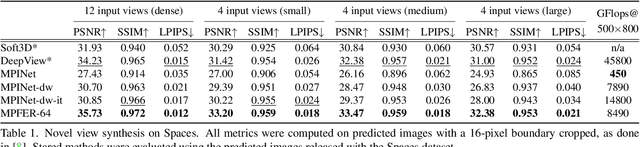
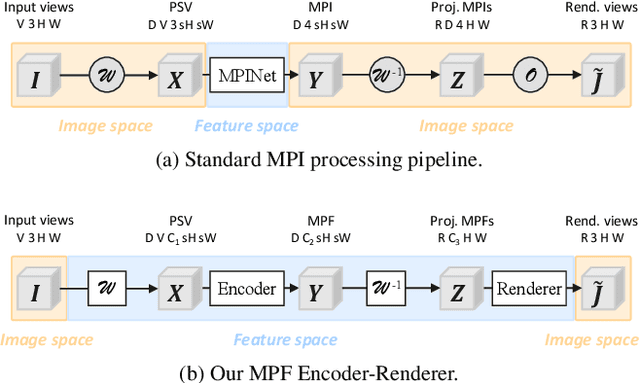
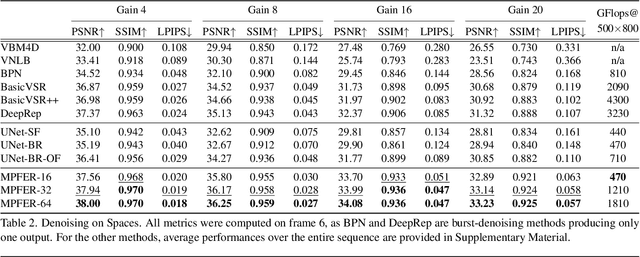
While current multi-frame restoration methods combine information from multiple input images using 2D alignment techniques, recent advances in novel view synthesis are paving the way for a new paradigm relying on volumetric scene representations. In this work, we introduce the first 3D-based multi-frame denoising method that significantly outperforms its 2D-based counterparts with lower computational requirements. Our method extends the multiplane image (MPI) framework for novel view synthesis by introducing a learnable encoder-renderer pair manipulating multiplane representations in feature space. The encoder fuses information across views and operates in a depth-wise manner while the renderer fuses information across depths and operates in a view-wise manner. The two modules are trained end-to-end and learn to separate depths in an unsupervised way, giving rise to Multiplane Feature (MPF) representations. Experiments on the Spaces and Real Forward-Facing datasets as well as on raw burst data validate our approach for view synthesis, multi-frame denoising, and view synthesis under noisy conditions.