 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Generating Synthetic Documents for Cross-Encoder Re-Rankers: A Comparative Study of ChatGPT and Human Experts
May 03, 2023
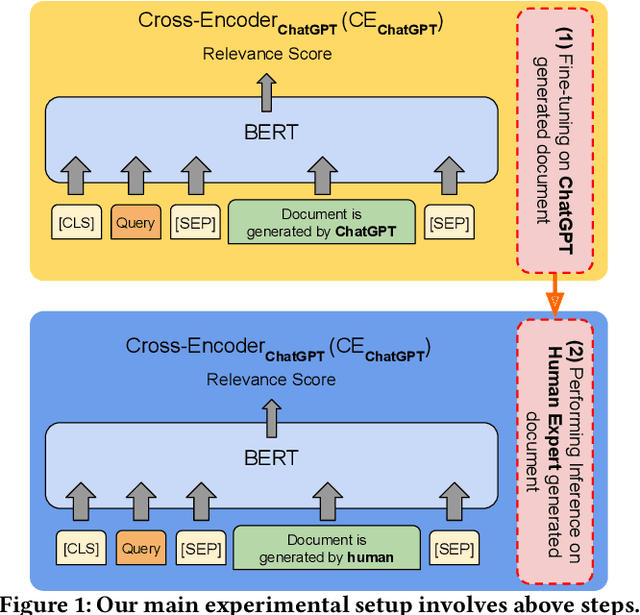
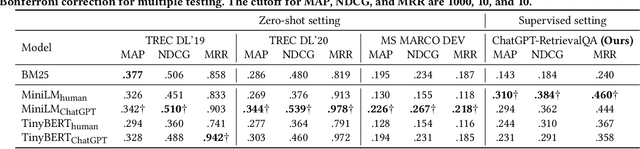
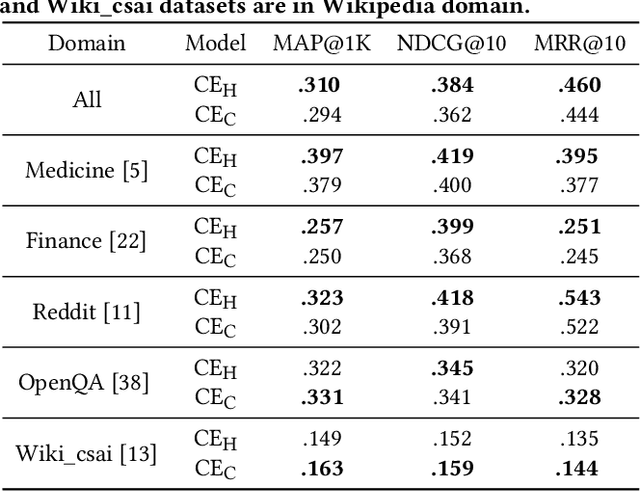
We investigate the usefulness of generative Large Language Models (LLMs) in generating training data for cross-encoder re-rankers in a novel direction: generating synthetic documents instead of synthetic queries. We introduce a new dataset, ChatGPT-RetrievalQA, and compare the effectiveness of models fine-tuned on LLM-generated and human-generated data. Data generated with generative LLMs can be used to augment training data, especially in domains with smaller amounts of labeled data. We build ChatGPT-RetrievalQA based on an existing dataset, human ChatGPT Comparison Corpus (HC3), consisting of public question collections with human responses and answers from ChatGPT. We fine-tune a range of cross-encoder re-rankers on either human-generated or ChatGPT-generated data. Our evaluation on MS MARCO DEV, TREC DL'19, and TREC DL'20 demonstrates that cross-encoder re-ranking models trained on ChatGPT responses are statistically significantly more effective zero-shot re-rankers than those trained on human responses. In a supervised setting, the human-trained re-rankers outperform the LLM-trained re-rankers. Our novel findings suggest that generative LLMs have high potential in generating training data for neural retrieval models. Further work is needed to determine the effect of factually wrong information in the generated responses and test our findings' generalizability with open-source LLMs. We release our data, code, and cross-encoders checkpoints for future work.
Attention Based Feature Fusion For Multi-Agent Collaborative Perception
May 03, 2023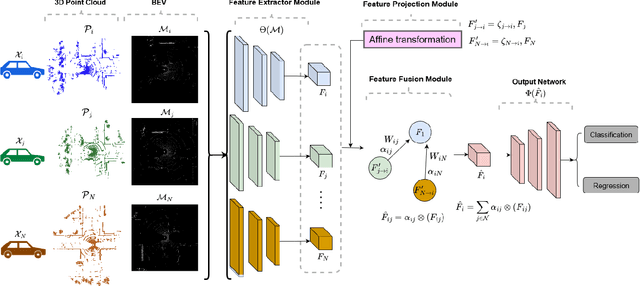
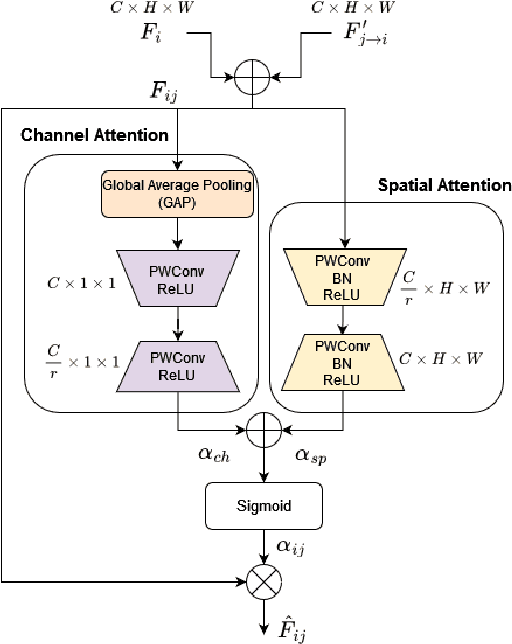

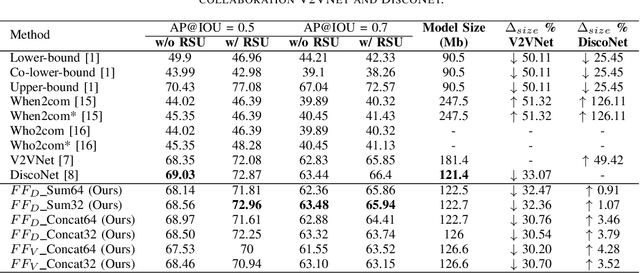
In the domain of intelligent transportation systems (ITS), collaborative perception has emerged as a promising approach to overcome the limitations of individual perception by enabling multiple agents to exchange information, thus enhancing their situational awareness. Collaborative perception overcomes the limitations of individual sensors, allowing connected agents to perceive environments beyond their line-of-sight and field of view. However, the reliability of collaborative perception heavily depends on the data aggregation strategy and communication bandwidth, which must overcome the challenges posed by limited network resources. To improve the precision of object detection and alleviate limited network resources, we propose an intermediate collaborative perception solution in the form of a graph attention network (GAT). The proposed approach develops an attention-based aggregation strategy to fuse intermediate representations exchanged among multiple connected agents. This approach adaptively highlights important regions in the intermediate feature maps at both the channel and spatial levels, resulting in improved object detection precision. We propose a feature fusion scheme using attention-based architectures and evaluate the results quantitatively in comparison to other state-of-the-art collaborative perception approaches. Our proposed approach is validated using the V2XSim dataset. The results of this work demonstrate the efficacy of the proposed approach for intermediate collaborative perception in improving object detection average precision while reducing network resource usage.
Mutual Information Regularized Offline Reinforcement Learning
Oct 14, 2022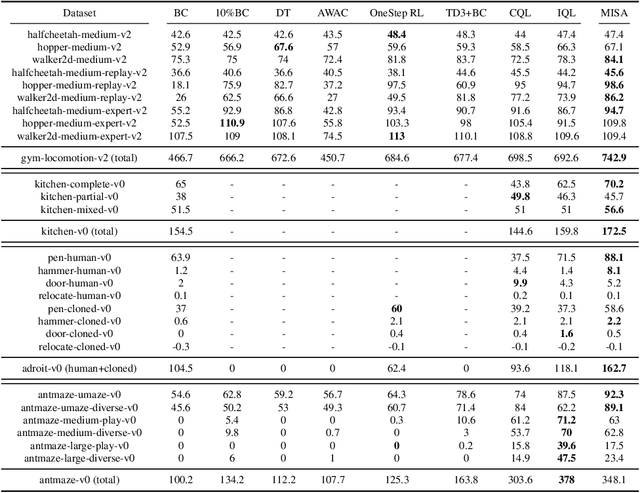
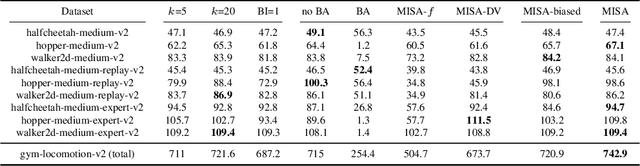

Offline reinforcement learning (RL) aims at learning an effective policy from offline datasets without active interactions with the environment. The major challenge of offline RL is the distribution shift that appears when out-of-distribution actions are queried, which makes the policy improvement direction biased by extrapolation errors. Most existing methods address this problem by penalizing the policy for deviating from the behavior policy during policy improvement or making conservative updates for value functions during policy evaluation. In this work, we propose a novel MISA framework to approach offline RL from the perspective of Mutual Information between States and Actions in the dataset by directly constraining the policy improvement direction. Intuitively, mutual information measures the mutual dependence of actions and states, which reflects how a behavior agent reacts to certain environment states during data collection. To effectively utilize this information to facilitate policy learning, MISA constructs lower bounds of mutual information parameterized by the policy and Q-values. We show that optimizing this lower bound is equivalent to maximizing the likelihood of a one-step improved policy on the offline dataset. In this way, we constrain the policy improvement direction to lie in the data manifold. The resulting algorithm simultaneously augments the policy evaluation and improvement by adding a mutual information regularization. MISA is a general offline RL framework that unifies conservative Q-learning (CQL) and behavior regularization methods (e.g., TD3+BC) as special cases. Our experiments show that MISA performs significantly better than existing methods and achieves new state-of-the-art on various tasks of the D4RL benchmark.
Multipath-based SLAM for Non-Ideal Reflective Surfaces Exploiting Multiple-Measurement Data Association
Apr 16, 2023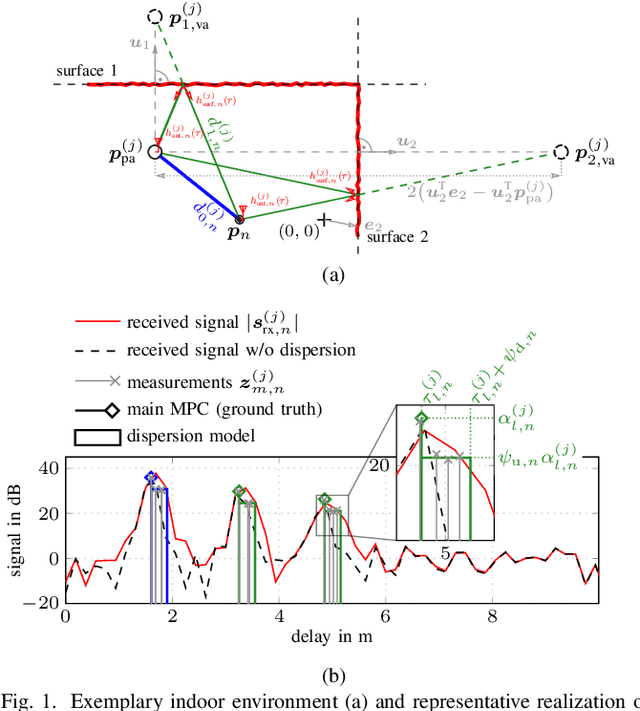
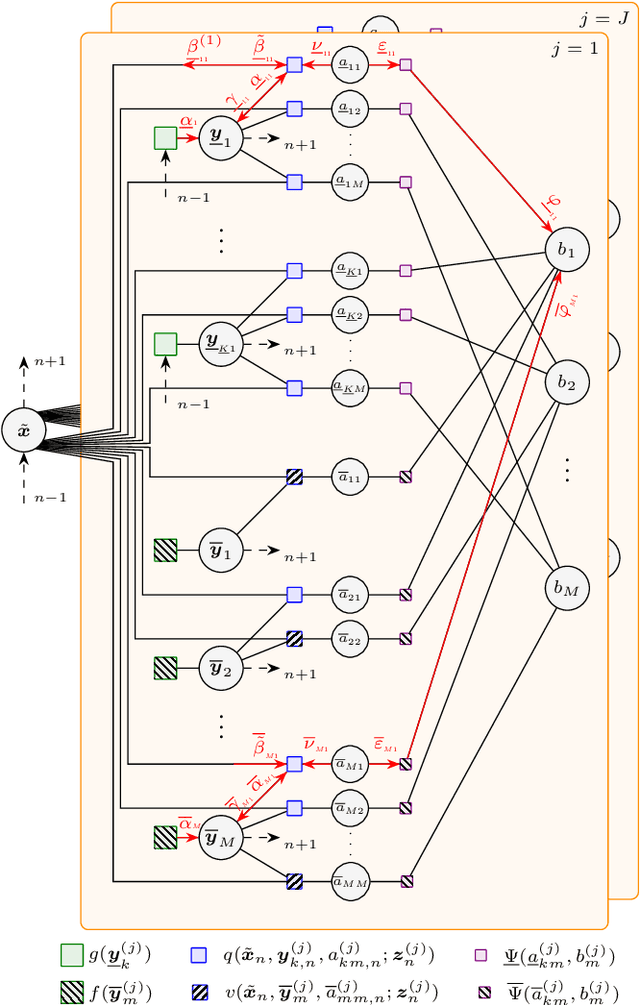
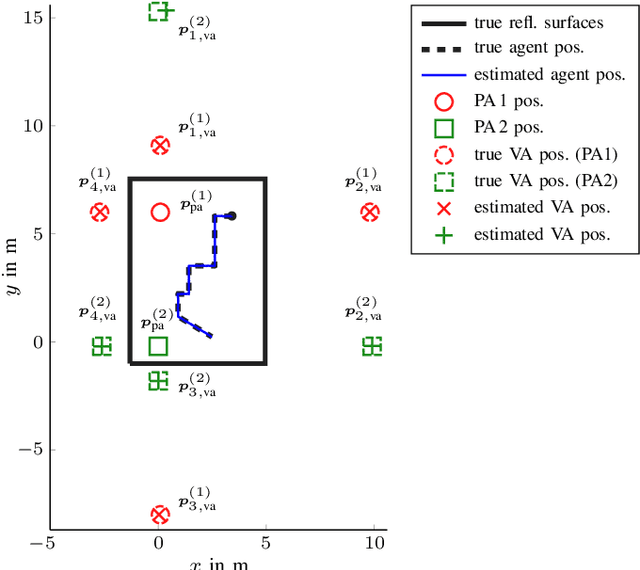
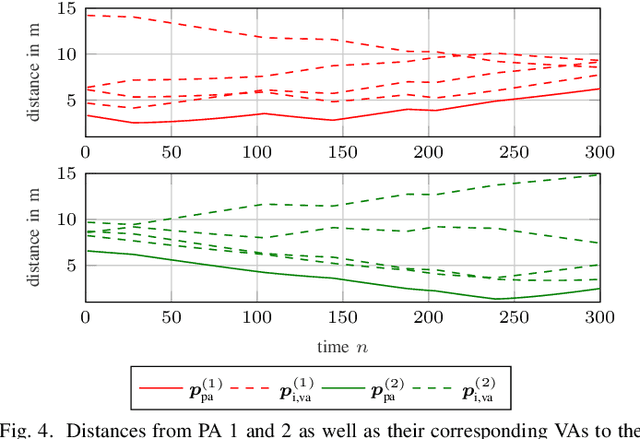
Multipath-based simultaneous localization and mapping (SLAM) is a promising approach to obtain position information of transmitters and receivers as well as information regarding the propagation environments in future mobile communication systems. Usually, specular reflections of the radio signals occurring at flat surfaces are modeled by virtual anchors (VAs) that are mirror images of the physical anchors (PAs). In existing methods for multipath-based SLAM, each VA is assumed to generate only a single measurement. However, due to imperfections of the measurement equipment such as non-calibrated antennas or model mismatch due to roughness of the reflective surfaces, there are potentially multiple multipath components (MPCs) that are associated to one single VA. In this paper, we introduce a Bayesian particle-based sum-product algorithm (SPA) for multipath-based SLAM that can cope with multiple-measurements being associated to a single VA. Furthermore, we introduce a novel statistical measurement model that is strongly related to the radio signal. It introduces additional dispersion parameters into the likelihood function to capture additional MPCs-related measurements. We demonstrate that the proposed SLAM method can robustly fuse multiple measurements per VA based on numerical simulations.
The Short Text Matching Model Enhanced with Knowledge via Contrastive Learning
Apr 08, 2023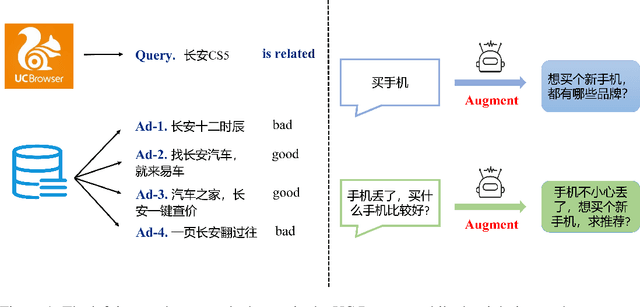
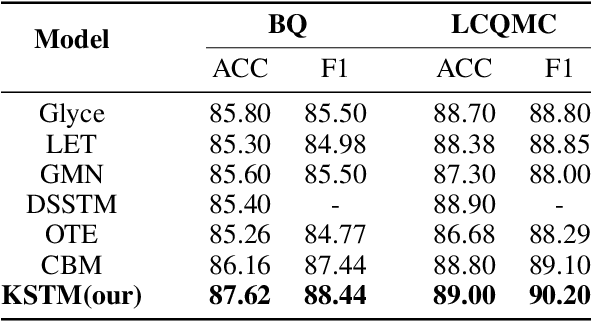
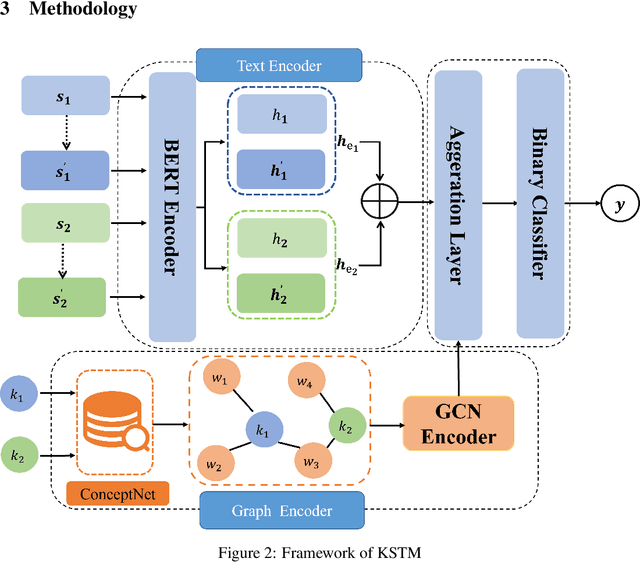
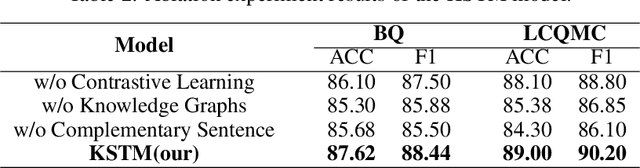
In recent years, short Text Matching tasks have been widely applied in the fields ofadvertising search and recommendation. The difficulty lies in the lack of semantic information and word ambiguity caused by the short length of the text. Previous works have introduced complement sentences or knowledge bases to provide additional feature information. However, these methods have not fully interacted between the original sentence and the complement sentence, and have not considered the noise issue that may arise from the introduction of external knowledge bases. Therefore, this paper proposes a short Text Matching model that combines contrastive learning and external knowledge. The model uses a generative model to generate corresponding complement sentences and uses the contrastive learning method to guide the model to obtain more semantically meaningful encoding of the original sentence. In addition, to avoid noise, we use keywords as the main semantics of the original sentence to retrieve corresponding knowledge words in the knowledge base, and construct a knowledge graph. The graph encoding model is used to integrate the knowledge base information into the model. Our designed model achieves state-of-the-art performance on two publicly available Chinese Text Matching datasets, demonstrating the effectiveness of our model.
Quantum Gaussian Process Regression for Bayesian Optimization
Apr 25, 2023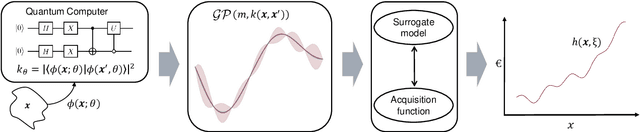
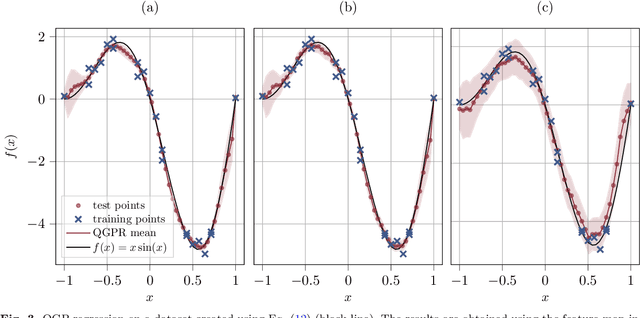
Gaussian process regression is a well-established Bayesian machine learning method. We propose a new approach to Gaussian process regression using quantum kernels based on parameterized quantum circuits. By employing a hardware-efficient feature map and careful regularization of the Gram matrix, we demonstrate that the variance information of the resulting quantum Gaussian process can be preserved. We also show that quantum Gaussian processes can be used as a surrogate model for Bayesian optimization, a task that critically relies on the variance of the surrogate model. To demonstrate the performance of this quantum Bayesian optimization algorithm, we apply it to the hyperparameter optimization of a machine learning model which performs regression on a real-world dataset. We benchmark the quantum Bayesian optimization against its classical counterpart and show that quantum version can match its performance.
Dual Residual Attention Network for Image Denoising
May 07, 2023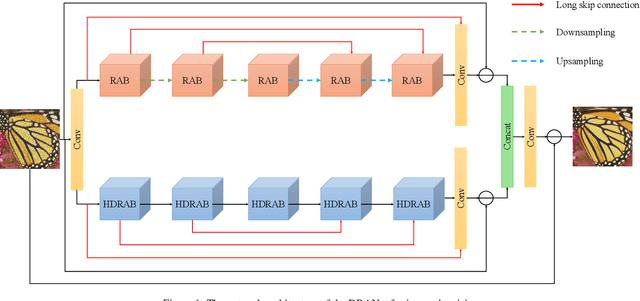


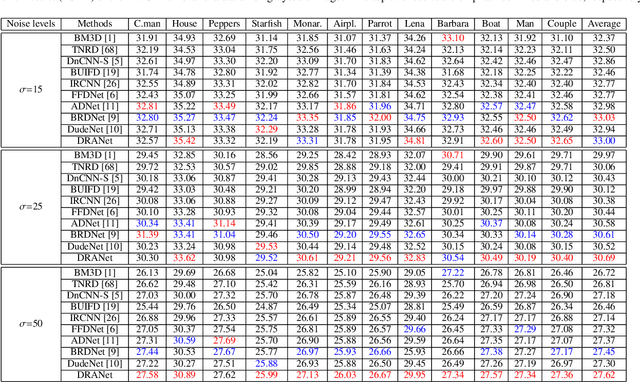
In image denoising, deep convolutional neural networks (CNNs) can obtain favorable performance on removing spatially invariant noise. However, many of these networks cannot perform well on removing the real noise (i.e. spatially variant noise) generated during image acquisition or transmission, which severely sets back their application in practical image denoising tasks. Instead of continuously increasing the network depth, many researchers have revealed that expanding the width of networks can also be a useful way to improve model performance. It also has been verified that feature filtering can promote the learning ability of the models. Therefore, in this paper, we propose a novel Dual-branch Residual Attention Network (DRANet) for image denoising, which has both the merits of a wide model architecture and attention-guided feature learning. The proposed DRANet includes two different parallel branches, which can capture complementary features to enhance the learning ability of the model. We designed a new residual attention block (RAB) and a novel hybrid dilated residual attention block (HDRAB) for the upper and the lower branches, respectively. The RAB and HDRAB can capture rich local features through multiple skip connections between different convolutional layers, and the unimportant features are dropped by the residual attention modules. Meanwhile, the long skip connections in each branch, and the global feature fusion between the two parallel branches can capture the global features as well. Moreover, the proposed DRANet uses downsampling operations and dilated convolutions to increase the size of the receptive field, which can enable DRANet to capture more image context information. Extensive experiments demonstrate that compared with other state-of-the-art denoising methods, our DRANet can produce competitive denoising performance both on synthetic and real-world noise removal.
An Empirical Study and Improvement for Speech Emotion Recognition
Apr 08, 2023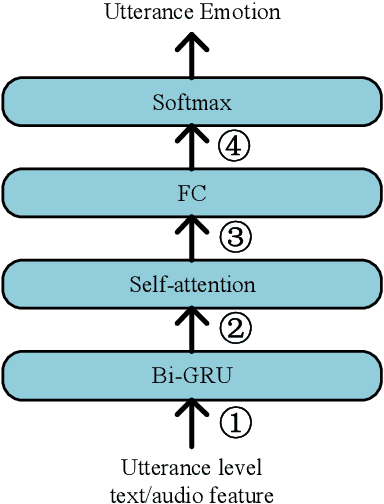

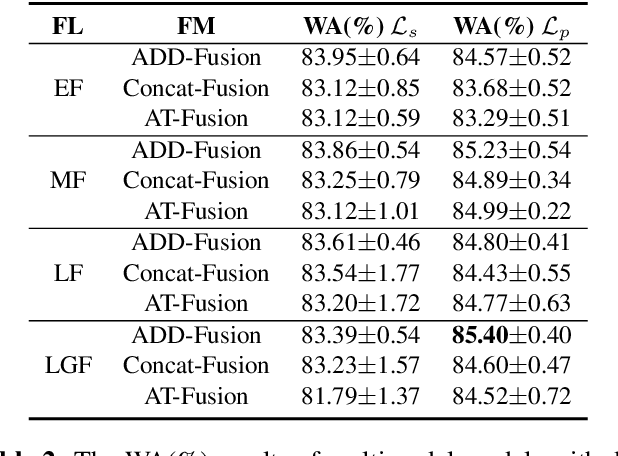
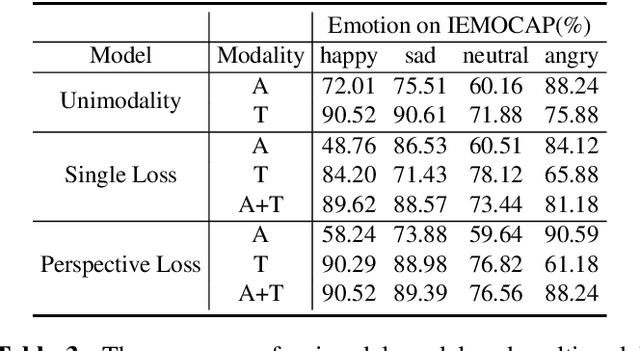
Multimodal speech emotion recognition aims to detect speakers' emotions from audio and text. Prior works mainly focus on exploiting advanced networks to model and fuse different modality information to facilitate performance, while neglecting the effect of different fusion strategies on emotion recognition. In this work, we consider a simple yet important problem: how to fuse audio and text modality information is more helpful for this multimodal task. Further, we propose a multimodal emotion recognition model improved by perspective loss. Empirical results show our method obtained new state-of-the-art results on the IEMOCAP dataset. The in-depth analysis explains why the improved model can achieve improvements and outperforms baselines.
Environmental sound conversion from vocal imitations and sound event labels
Apr 29, 2023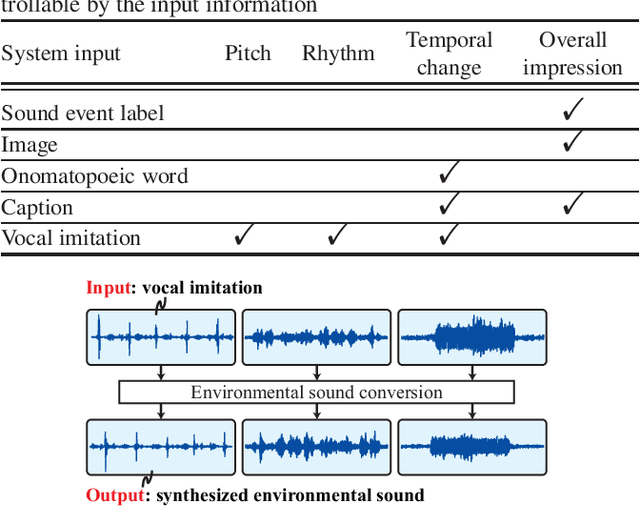
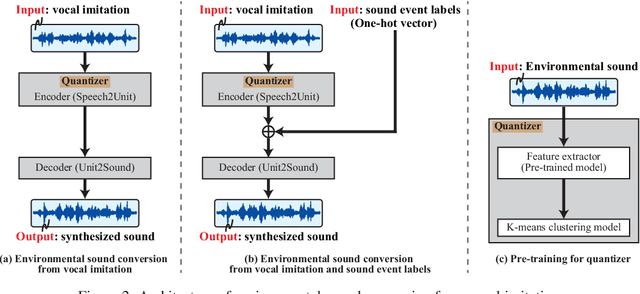
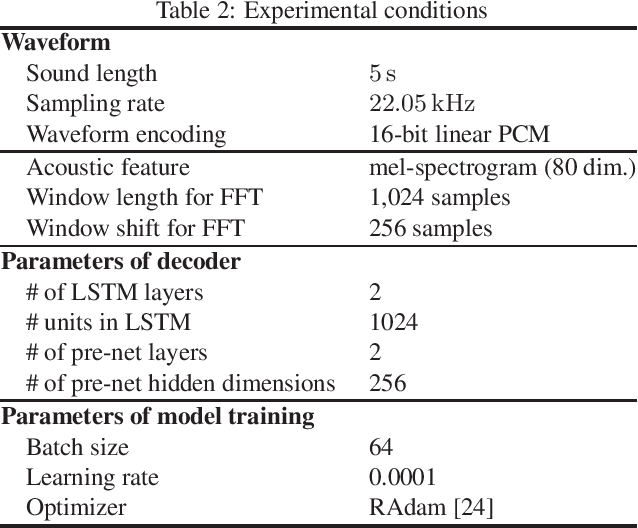
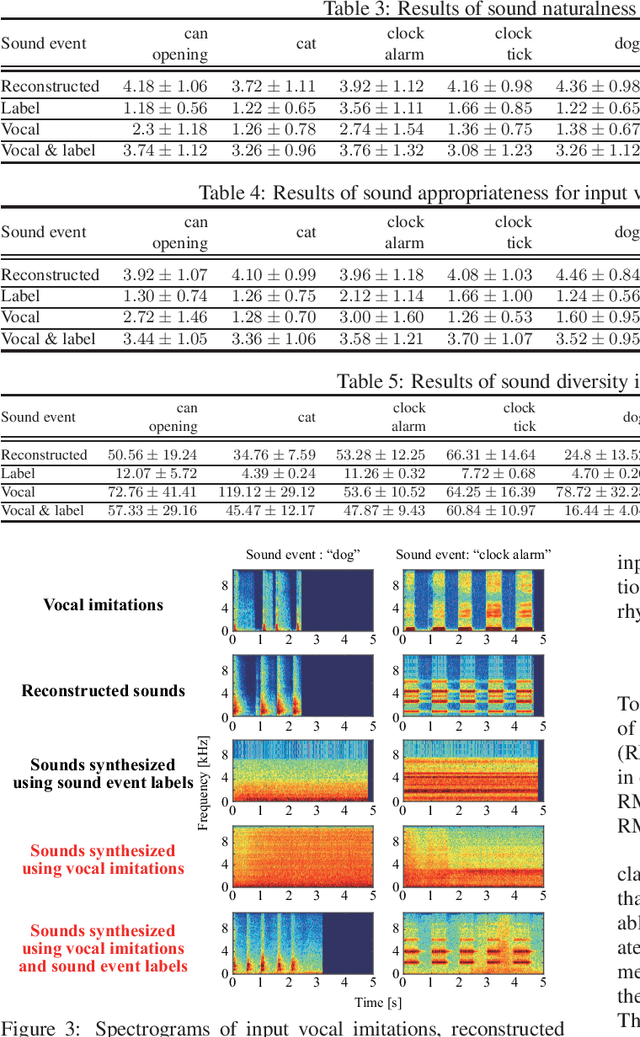
One way of expressing an environmental sound is using vocal imitations, which involve the process of replicating or mimicking the rhythms and pitches of sounds by voice. We can effectively express the features of environmental sounds, such as rhythms and pitches, using vocal imitations, which cannot be expressed by conventional input information, such as sound event labels, images, and texts, in an environmental sound synthesis model. Therefore, using vocal imitations as input for environmental sound synthesis will enable us to control the pitches and rhythms of sounds and generate diverse sounds. In this paper, we thus propose a framework for environmental sound conversion from vocal imitations to generate diverse sounds. We also propose a method of environmental sound synthesis from vocal imitations and sound event labels. Using sound event labels is expected to control the sound event class of the synthesized sound, which cannot be controlled by only vocal imitations. Our objective and subjective experimental results show that vocal imitations effectively control the pitches and rhythms of sounds and generate diverse sounds.
A Study of Biologically Plausible Neural Network: The Role and Interactions of Brain-Inspired Mechanisms in Continual Learning
Apr 13, 2023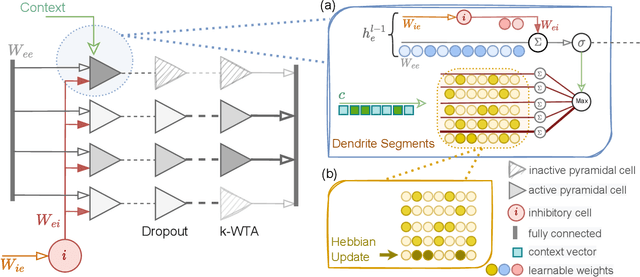
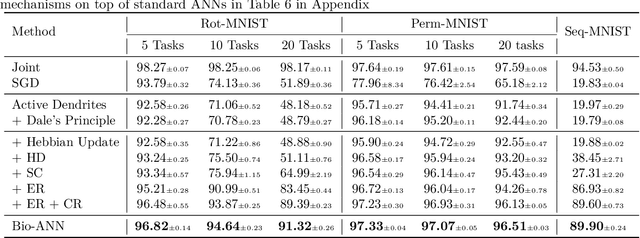
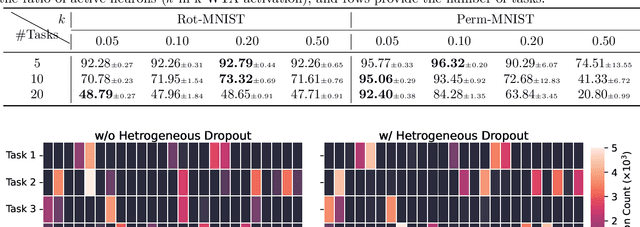
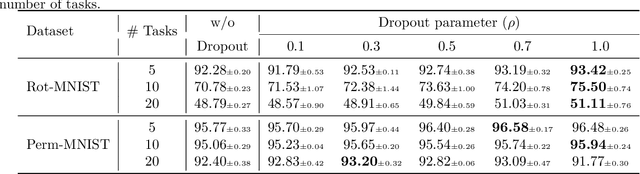
Humans excel at continually acquiring, consolidating, and retaining information from an ever-changing environment, whereas artificial neural networks (ANNs) exhibit catastrophic forgetting. There are considerable differences in the complexity of synapses, the processing of information, and the learning mechanisms in biological neural networks and their artificial counterparts, which may explain the mismatch in performance. We consider a biologically plausible framework that constitutes separate populations of exclusively excitatory and inhibitory neurons that adhere to Dale's principle, and the excitatory pyramidal neurons are augmented with dendritic-like structures for context-dependent processing of stimuli. We then conduct a comprehensive study on the role and interactions of different mechanisms inspired by the brain, including sparse non-overlapping representations, Hebbian learning, synaptic consolidation, and replay of past activations that accompanied the learning event. Our study suggests that the employing of multiple complementary mechanisms in a biologically plausible architecture, similar to the brain, may be effective in enabling continual learning in ANNs.