 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Motion-state Alignment for Video Semantic Segmentation
Apr 18, 2023
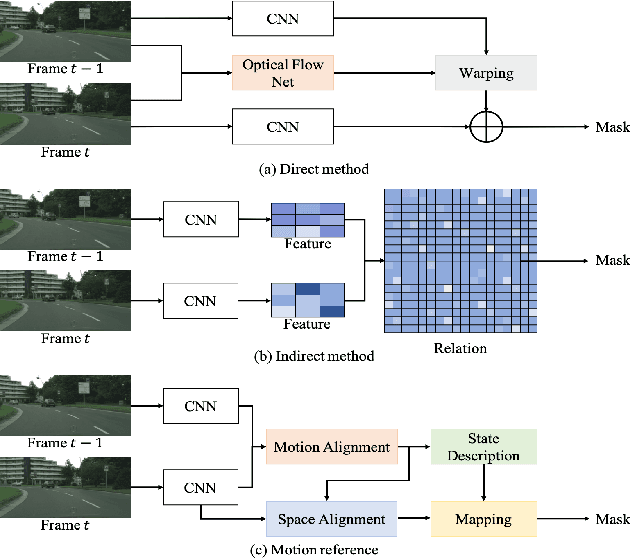
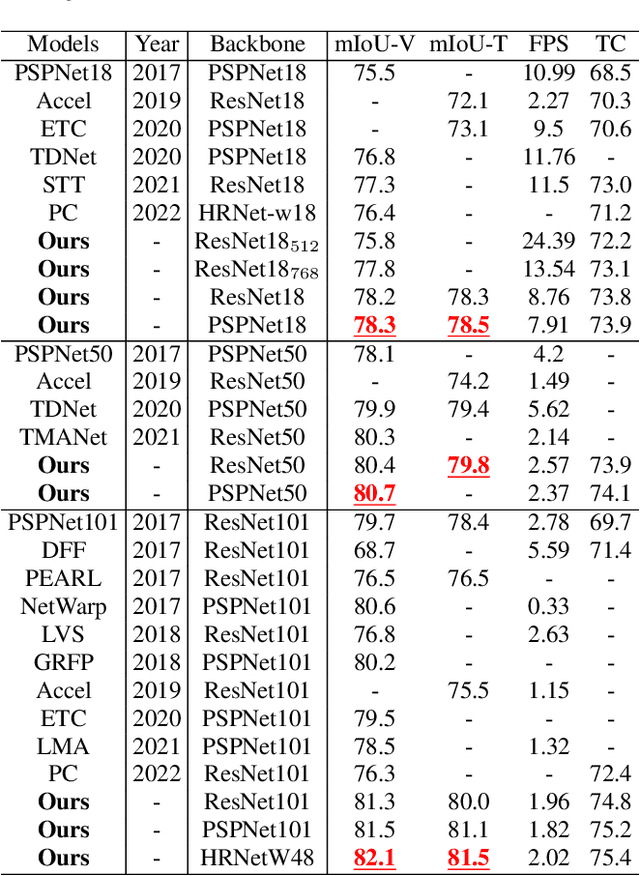
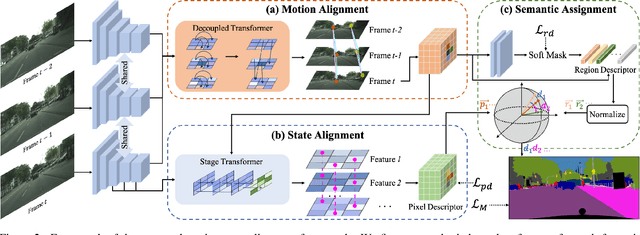
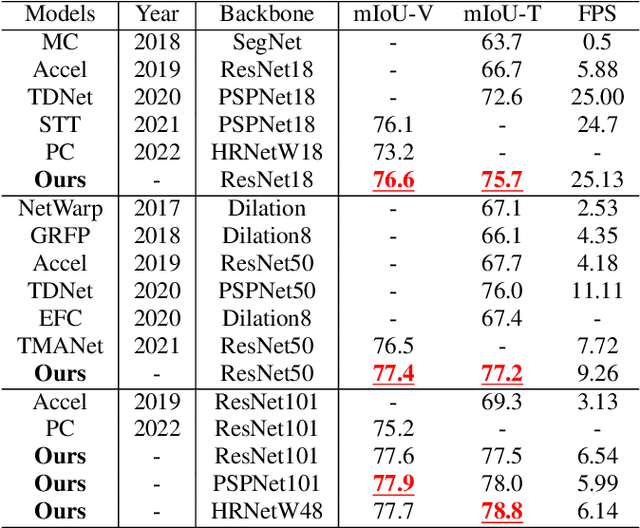
In recent years, video semantic segmentation has made great progress with advanced deep neural networks. However, there still exist two main challenges \ie, information inconsistency and computation cost. To deal with the two difficulties, we propose a novel motion-state alignment framework for video semantic segmentation to keep both motion and state consistency. In the framework, we first construct a motion alignment branch armed with an efficient decoupled transformer to capture dynamic semantics, guaranteeing region-level temporal consistency. Then, a state alignment branch composed of a stage transformer is designed to enrich feature spaces for the current frame to extract static semantics and achieve pixel-level state consistency. Next, by a semantic assignment mechanism, the region descriptor of each semantic category is gained from dynamic semantics and linked with pixel descriptors from static semantics. Benefiting from the alignment of these two kinds of effective information, the proposed method picks up dynamic and static semantics in a targeted way, so that video semantic regions are consistently segmented to obtain precise locations with low computational complexity. Extensive experiments on Cityscapes and CamVid datasets show that the proposed approach outperforms state-of-the-art methods and validates the effectiveness of the motion-state alignment framework.
Leveraging Social Interactions to Detect Misinformation on Social Media
Apr 06, 2023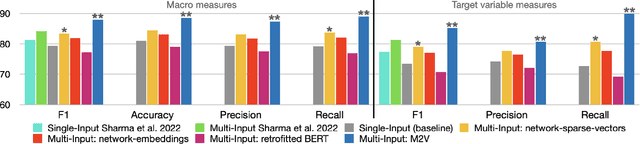
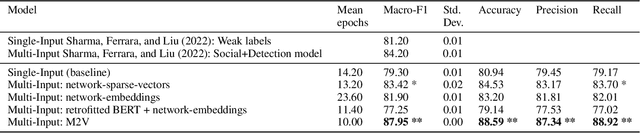
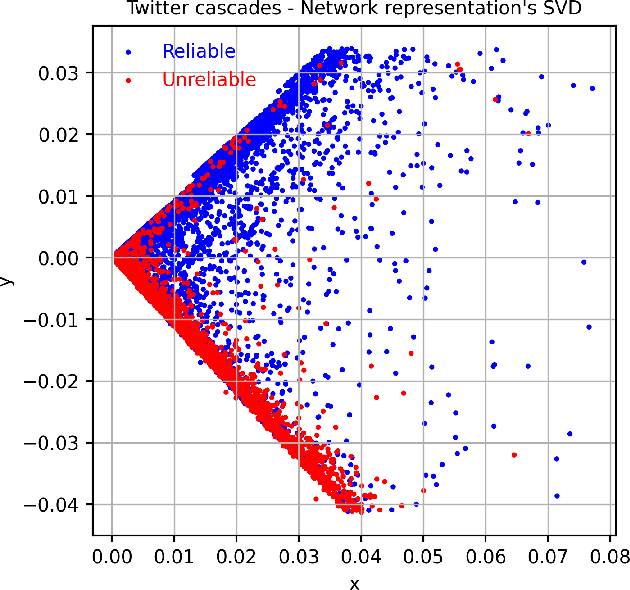
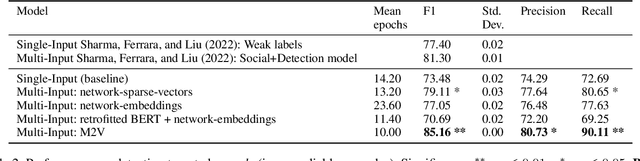
Detecting misinformation threads is crucial to guarantee a healthy environment on social media. We address the problem using the data set created during the COVID-19 pandemic. It contains cascades of tweets discussing information weakly labeled as reliable or unreliable, based on a previous evaluation of the information source. The models identifying unreliable threads usually rely on textual features. But reliability is not just what is said, but by whom and to whom. We additionally leverage on network information. Following the homophily principle, we hypothesize that users who interact are generally interested in similar topics and spreading similar kind of news, which in turn is generally reliable or not. We test several methods to learn representations of the social interactions within the cascades, combining them with deep neural language models in a Multi-Input (MI) framework. Keeping track of the sequence of the interactions during the time, we improve over previous state-of-the-art models.
Disentangled Generation with Information Bottleneck for Few-Shot Learning
Nov 29, 2022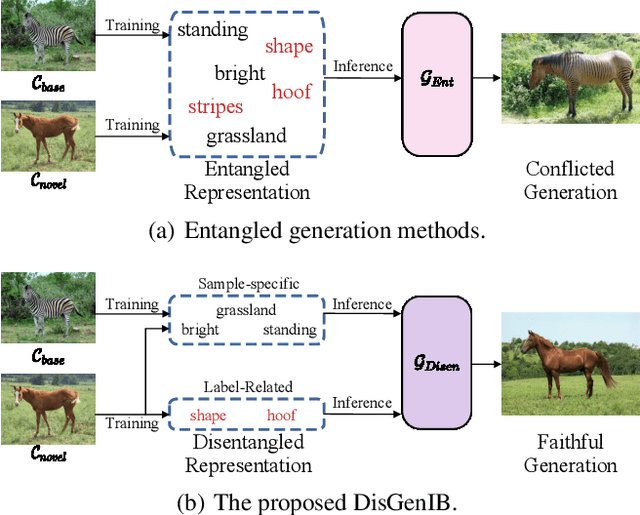
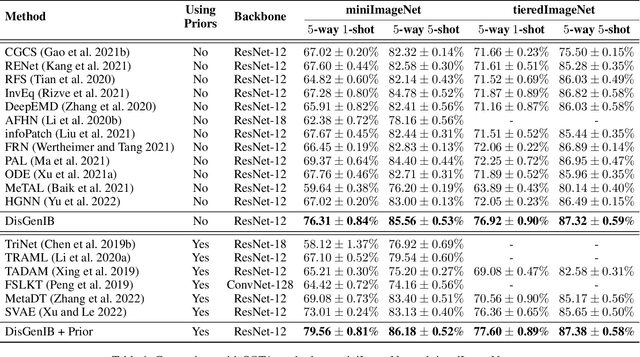
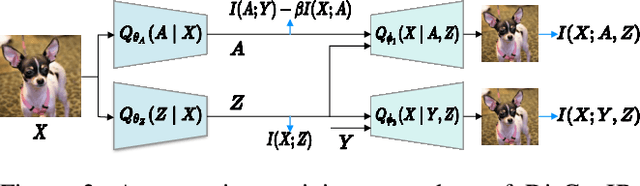
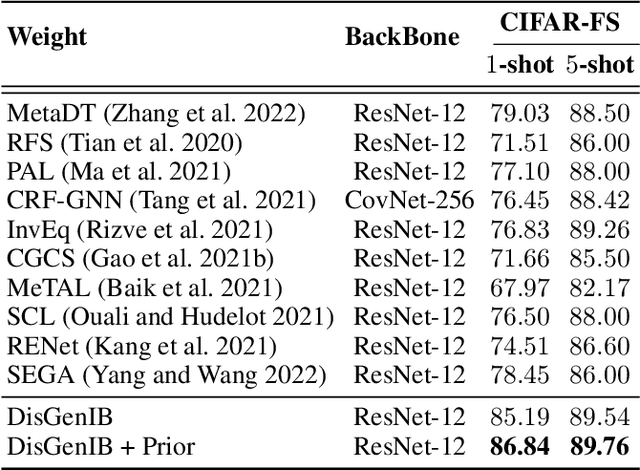
Few-shot learning (FSL), which aims to classify unseen classes with few samples, is challenging due to data scarcity. Although various generative methods have been explored for FSL, the entangled generation process of these methods exacerbates the distribution shift in FSL, thus greatly limiting the quality of generated samples. To these challenges, we propose a novel Information Bottleneck (IB) based Disentangled Generation Framework for FSL, termed as DisGenIB, that can simultaneously guarantee the discrimination and diversity of generated samples. Specifically, we formulate a novel framework with information bottleneck that applies for both disentangled representation learning and sample generation. Different from existing IB-based methods that can hardly exploit priors, we demonstrate our DisGenIB can effectively utilize priors to further facilitate disentanglement. We further prove in theory that some previous generative and disentanglement methods are special cases of our DisGenIB, which demonstrates the generality of the proposed DisGenIB. Extensive experiments on challenging FSL benchmarks confirm the effectiveness and superiority of DisGenIB, together with the validity of our theoretical analyses. Our codes will be open-source upon acceptance.
Inferring the past: a combined CNN-LSTM deep learning framework to fuse satellites for historical inundation mapping
May 01, 2023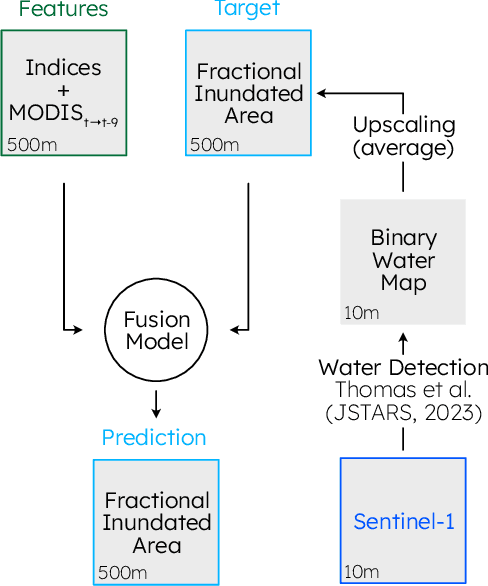
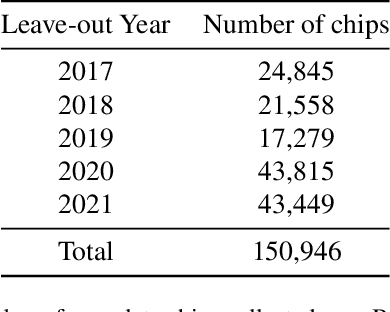
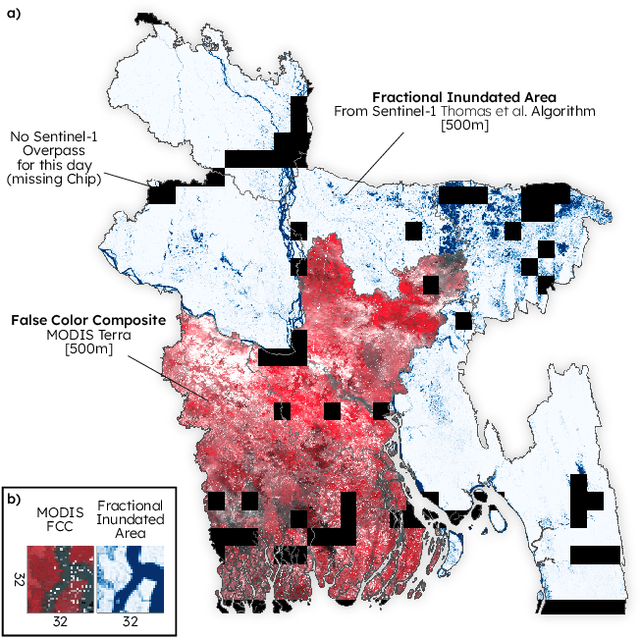
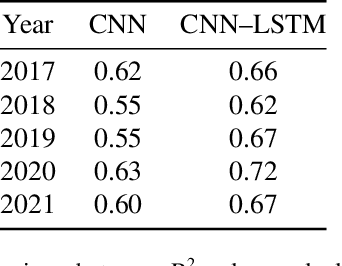
Mapping floods using satellite data is crucial for managing and mitigating flood risks. Satellite imagery enables rapid and accurate analysis of large areas, providing critical information for emergency response and disaster management. Historical flood data derived from satellite imagery can inform long-term planning, risk management strategies, and insurance-related decisions. The Sentinel-1 satellite is effective for flood detection, but for longer time series, other satellites such as MODIS can be used in combination with deep learning models to accurately identify and map past flood events. We here develop a combined CNN--LSTM deep learning framework to fuse Sentinel-1 derived fractional flooded area with MODIS data in order to infer historical floods over Bangladesh. The results show how our framework outperforms a CNN-only approach and takes advantage of not only space, but also time in order to predict the fractional inundated area. The model is applied to historical MODIS data to infer the past 20 years of inundation extents over Bangladesh and compared to a thresholding algorithm and a physical model. Our fusion model outperforms both models in consistency and capacity to predict peak inundation extents.
AI-based Radio and Computing Resource Allocation and Path Planning in NOMA NTNs: AoI Minimization under CSI Uncertainty
May 01, 2023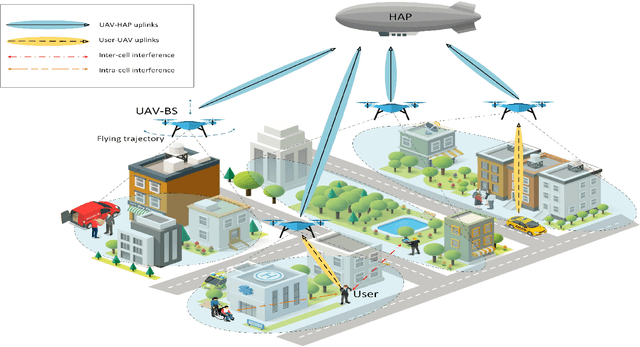
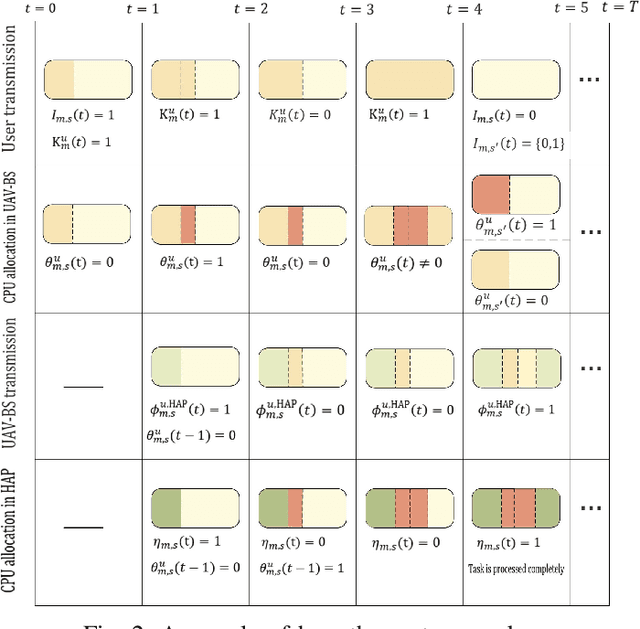
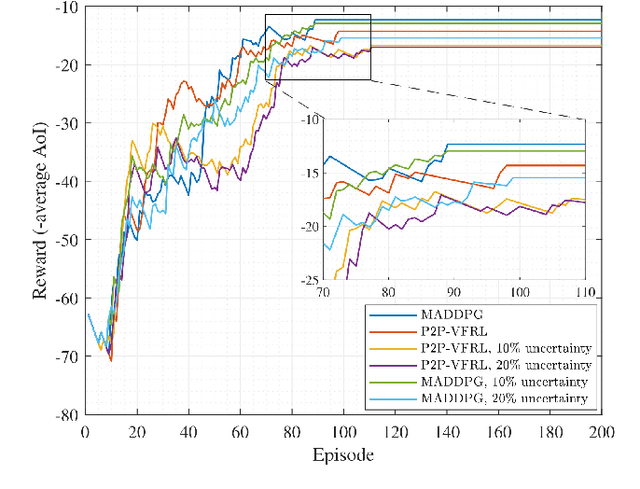
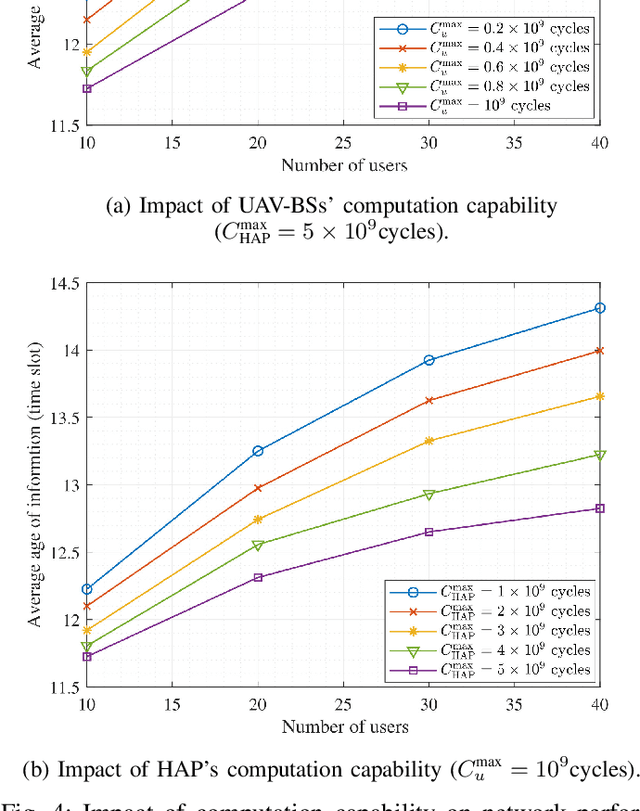
In this paper, we develop a hierarchical aerial computing framework composed of high altitude platform (HAP) and unmanned aerial vehicles (UAVs) to compute the fully offloaded tasks of terrestrial mobile users which are connected through an uplink non-orthogonal multiple access (UL-NOMA). In particular, the problem is formulated to minimize the AoI of all users with elastic tasks, by adjusting UAVs trajectory and resource allocation on both UAVs and HAP, which is restricted by the channel state information (CSI) uncertainty and multiple resource constraints of UAVs and HAP. In order to solve this non-convex optimization problem, two methods of multi-agent deep deterministic policy gradient (MADDPG) and federated reinforcement learning (FRL) are proposed to design the UAVs trajectory and obtain channel, power, and CPU allocations. It is shown that task scheduling significantly reduces the average AoI. This improvement is more pronounced for larger task sizes. On the one hand, it is shown that power allocation has a marginal effect on the average AoI compared to using full transmission power for all users. On the other hand, compared with traditional transmissions (fixed method) simulation result shows that our scheduling scheme has a lower average AoI.
Image-text Retrieval via Preserving Main Semantics of Vision
Apr 28, 2023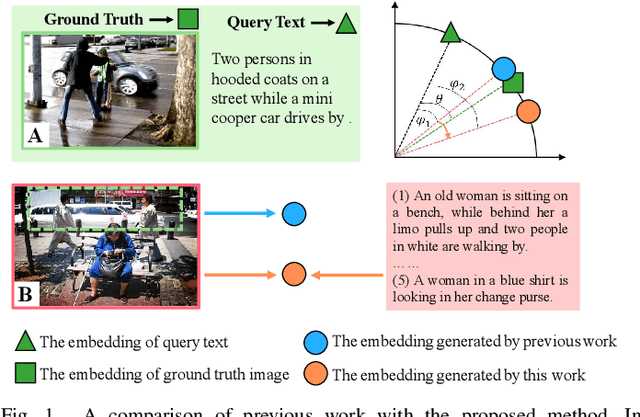
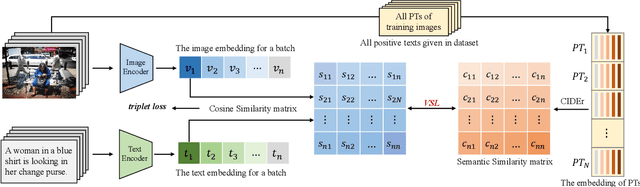

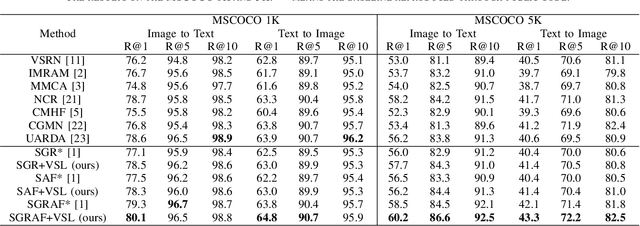
Image-text retrieval is one of the major tasks of cross-modal retrieval. Several approaches for this task map images and texts into a common space to create correspondences between the two modalities. However, due to the content (semantics) richness of an image, redundant secondary information in an image may cause false matches. To address this issue, this paper presents a semantic optimization approach, implemented as a Visual Semantic Loss (VSL), to assist the model in focusing on an image's main content. This approach is inspired by how people typically annotate the content of an image by describing its main content. Thus, we leverage the annotated texts corresponding to an image to assist the model in capturing the main content of the image, reducing the negative impact of secondary content. Extensive experiments on two benchmark datasets (MSCOCO and Flickr30K) demonstrate the superior performance of our method. The code is available at: https://github.com/ZhangXu0963/VSL.
Controllable Data Augmentation for Context-Dependent Text-to-SQL
Apr 28, 2023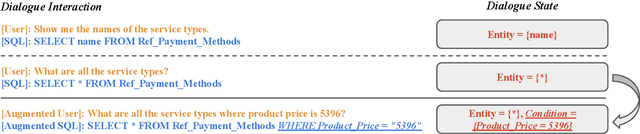
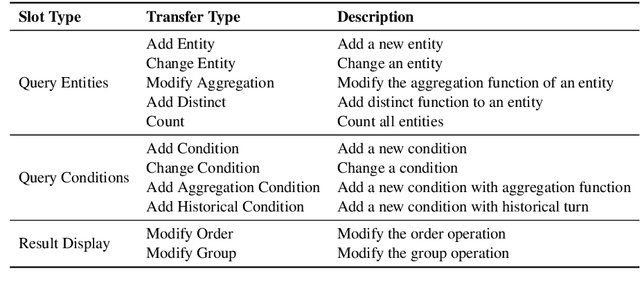
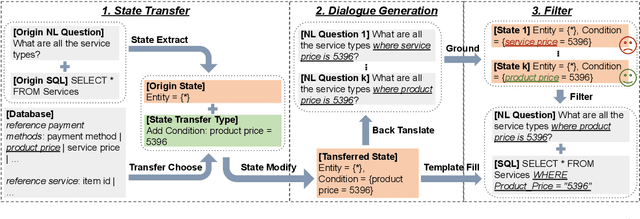

The limited scale of annotated data constraints existing context-dependent text-to-SQL models because of the complexity of labeling. The data augmentation method is a commonly used method to solve this problem. However, the data generated by current augmentation methods often lack diversity. In this paper, we introduce ConDA, which generates interactive questions and corresponding SQL results. We designed the SQL dialogue state to enhance the data diversity through the state transition. Meanwhile, we also present a filter method to ensure the data quality by a grounding model. Additionally, we utilize a grounding model to identify and filter low-quality questions that mismatch the state information. Experimental results on the SParC and CoSQL datasets show that ConDA boosts the baseline model to achieve an average improvement of $3.3\%$ on complex questions. Moreover, we analyze the augmented data, which reveals that the data generated by ConDA are of high quality in both SQL template hardness and types, turns, and question consistency.
DD-CISENet: Dual-Domain Cross-Iteration Squeeze and Excitation Network for Accelerated MRI Reconstruction
Apr 28, 2023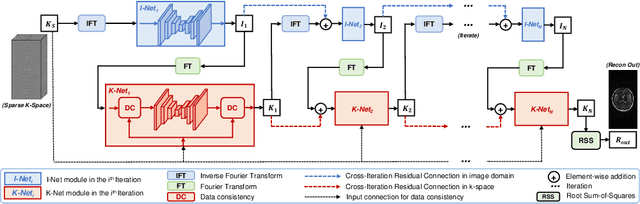
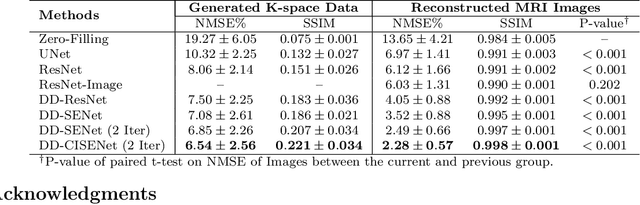
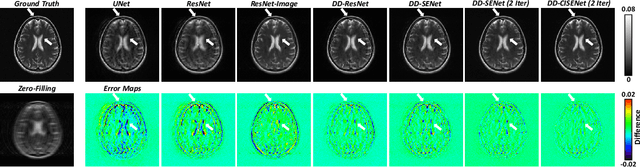
Magnetic resonance imaging (MRI) is widely employed for diagnostic tests in neurology. However, the utility of MRI is largely limited by its long acquisition time. Acquiring fewer k-space data in a sparse manner is a potential solution to reducing the acquisition time, but it can lead to severe aliasing reconstruction artifacts. In this paper, we present a novel Dual-Domain Cross-Iteration Squeeze and Excitation Network (DD-CISENet) for accelerated sparse MRI reconstruction. The information of k-spaces and MRI images can be iteratively fused and maintained using the Cross-Iteration Residual connection (CIR) structures. This study included 720 multi-coil brain MRI cases adopted from the open-source fastMRI Dataset. Results showed that the average reconstruction error by DD-CISENet was 2.28 $\pm$ 0.57%, which outperformed existing deep learning methods including image-domain prediction (6.03 $\pm$ 1.31, p < 0.001), k-space synthesis (6.12 $\pm$ 1.66, p < 0.001), and dual-domain feature fusion approaches (4.05 $\pm$ 0.88, p < 0.001).
Domain Adaptive Multiple Instance Learning for Instance-level Prediction of Pathological Images
Apr 07, 2023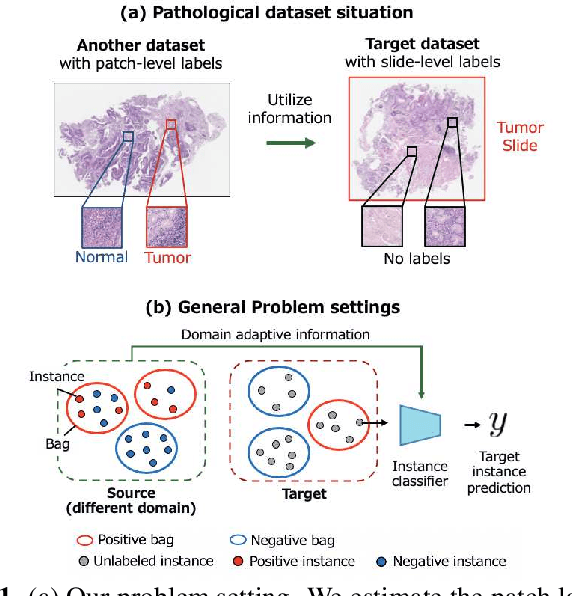
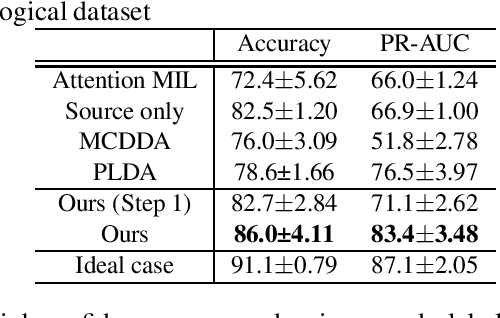
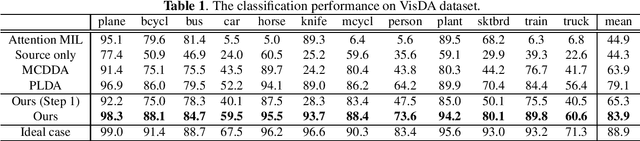
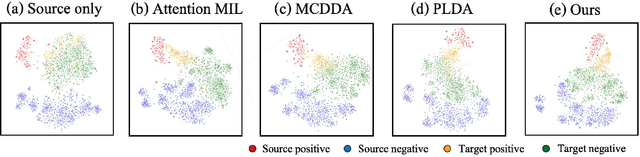
Pathological image analysis is an important process for detecting abnormalities such as cancer from cell images. However, since the image size is generally very large, the cost of providing detailed annotations is high, which makes it difficult to apply machine learning techniques. One way to improve the performance of identifying abnormalities while keeping the annotation cost low is to use only labels for each slide, or to use information from another dataset that has already been labeled. However, such weak supervisory information often does not provide sufficient performance. In this paper, we proposed a new task setting to improve the classification performance of the target dataset without increasing annotation costs. And to solve this problem, we propose a pipeline that uses multiple instance learning (MIL) and domain adaptation (DA) methods. Furthermore, in order to combine the supervisory information of both methods effectively, we propose a method to create pseudo-labels with high confidence. We conducted experiments on the pathological image dataset we created for this study and showed that the proposed method significantly improves the classification performance compared to existing methods.
Channel State Information Based User Censoring in Irregular Repetition Slotted Aloha
Feb 24, 2023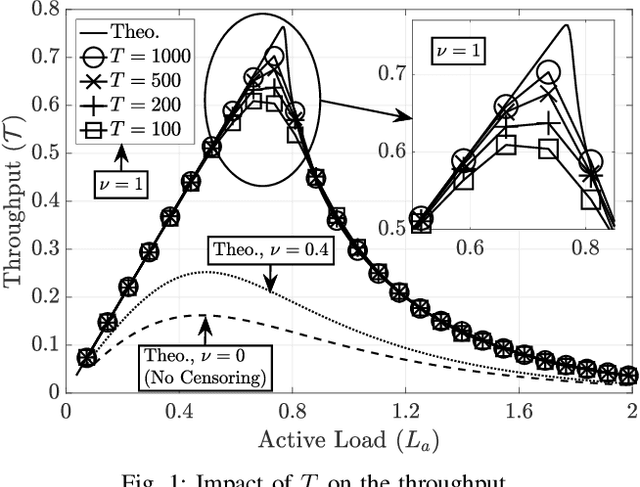
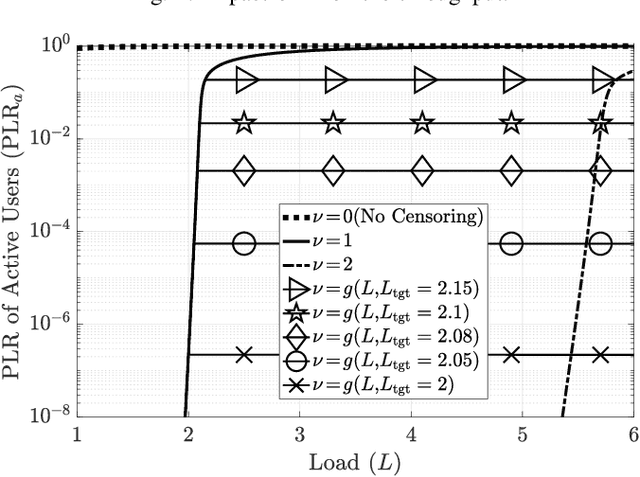
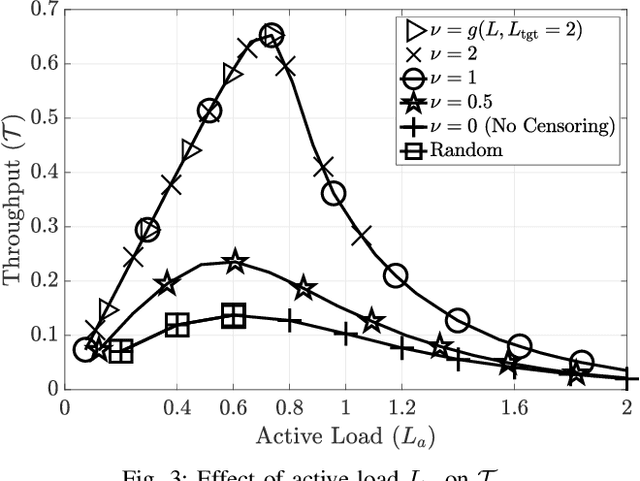
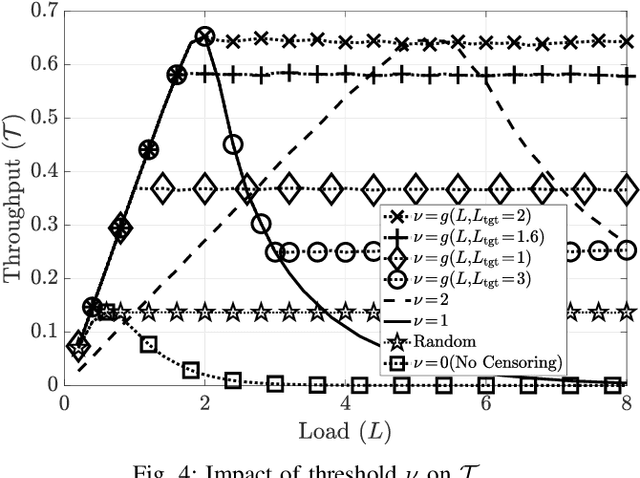
Irregular repetition slotted aloha (IRSA) is a massive random access protocol which can be used to serve a large number of users while achieving a packet loss rate (PLR) close to zero. However, if the number of users is too high, then the system is interference limited and the PLR is close to one. In this paper, we propose a variant of IRSA in the interference limited regime, namely Censored-IRSA (C-IRSA), wherein users with poor channel states censor themselves from transmitting their packets. We theoretically analyze the throughput performance of C-IRSA via density evolution. Using this, we derive closed-form expressions for the optimal choice of the censor threshold which maximizes the throughput while achieving zero PLR among uncensored users. Through extensive numerical simulations, we show that C-IRSA can achieve a 4$\times$ improvement in the peak throughput compared to conventional IRSA.