 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DNN-Compressed Domain Visual Recognition with Feature Adaptation
May 13, 2023
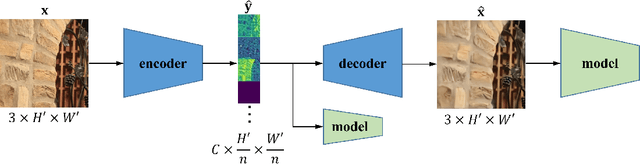
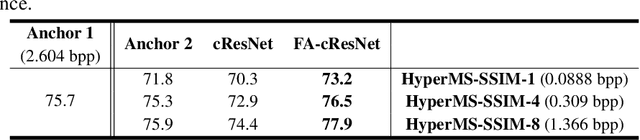
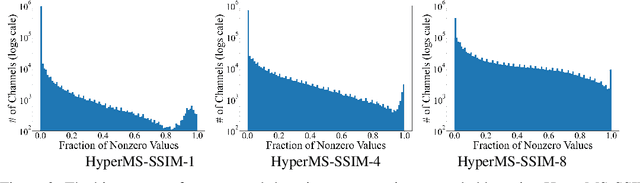

Learning-based image compression was shown to achieve a competitive performance with state-of-the-art transform-based codecs. This motivated the development of new learning-based visual compression standards such as JPEG-AI. Of particular interest to these emerging standards is the development of learning-based image compression systems targeting both humans and machines. This paper is concerned with learning-based compression schemes whose compressed-domain representations can be utilized to perform visual processing and computer vision tasks directly in the compressed domain. In our work, we adopt a learning-based compressed-domain classification framework for performing visual recognition using the compressed-domain latent representation at varying bit-rates. We propose a novel feature adaptation module integrating a lightweight attention model to adaptively emphasize and enhance the key features within the extracted channel-wise information. Also, we design an adaptation training strategy to utilize the pretrained pixel-domain weights. For comparison, in addition to the performance results that are obtained using our proposed latent-based compressed-domain method, we also present performance results using compressed but fully decoded images in the pixel domain as well as original uncompressed images. The obtained performance results show that our proposed compressed-domain classification model can distinctly outperform the existing compressed-domain classification models, and that it can also yield similar accuracy results with a much higher computational efficiency as compared to the pixel-domain models that are trained using fully decoded images.
GSB: Group Superposition Binarization for Vision Transformer with Limited Training Samples
May 13, 2023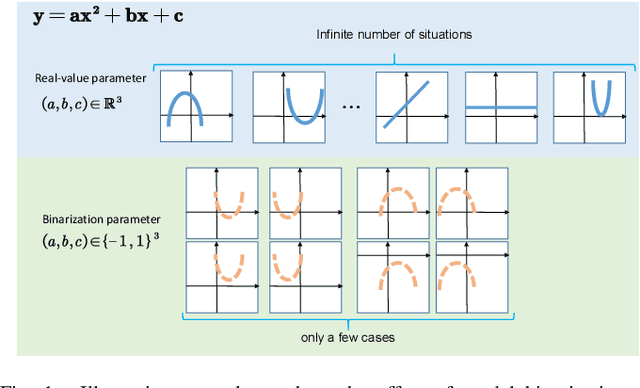
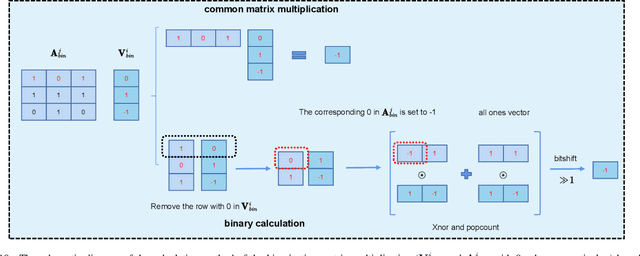
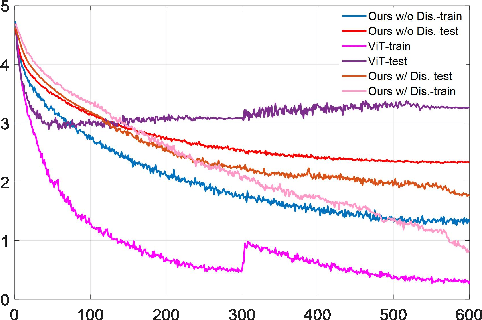
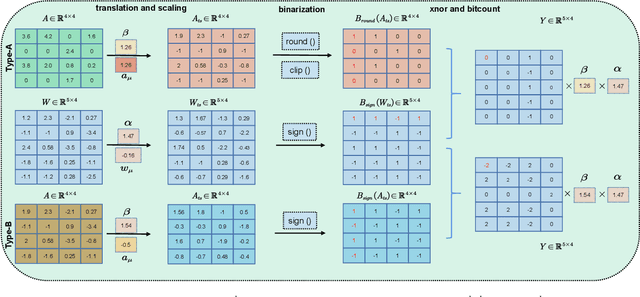
Affected by the massive amount of parameters, ViT usually suffers from serious overfitting problems with a relatively limited number of training samples. In addition, ViT generally demands heavy computing resources, which limit its deployment on resource-constrained devices. As a type of model-compression method,model binarization is potentially a good choice to solve the above problems. Compared with the full-precision one, the model with the binarization method replaces complex tensor multiplication with simple bit-wise binary operations and represents full-precision model parameters and activations with only 1-bit ones, which potentially solves the problem of model size and computational complexity, respectively. In this paper, we find that the decline of the accuracy of the binary ViT model is mainly due to the information loss of the Attention module and the Value vector. Therefore, we propose a novel model binarization technique, called Group Superposition Binarization (GSB), to deal with these issues. Furthermore, in order to further improve the performance of the binarization model, we have investigated the gradient calculation procedure in the binarization process and derived more proper gradient calculation equations for GSB to reduce the influence of gradient mismatch. Then, the knowledge distillation technique is introduced to alleviate the performance degradation caused by model binarization. Experiments on three datasets with limited numbers of training samples demonstrate that the proposed GSB model achieves state-of-the-art performance among the binary quantization schemes and exceeds its full-precision counterpart on some indicators.
An assessment of measuring local levels of homelessness through proxy social media signals
May 15, 2023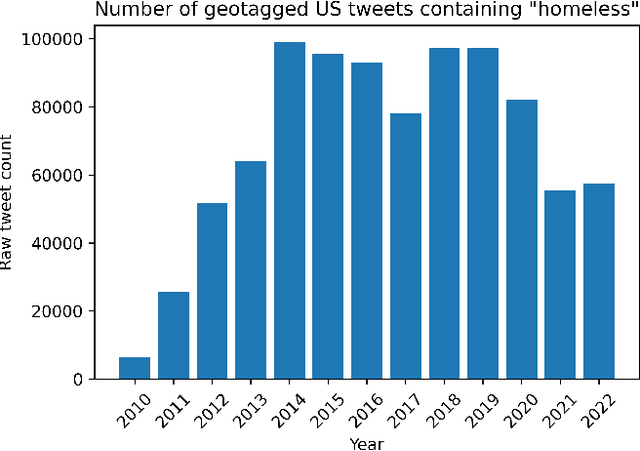
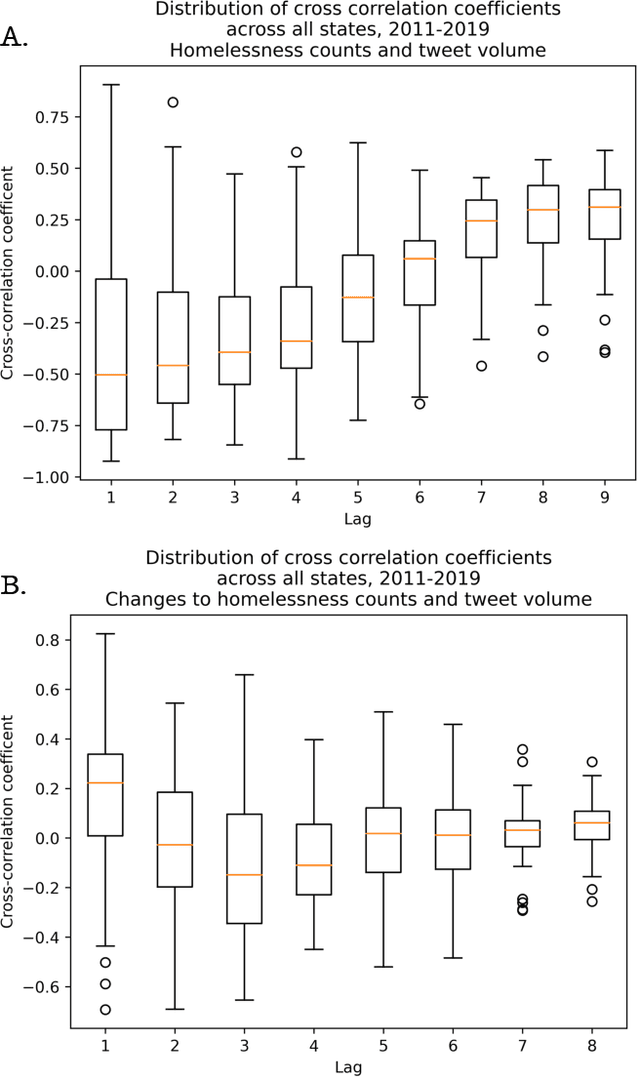
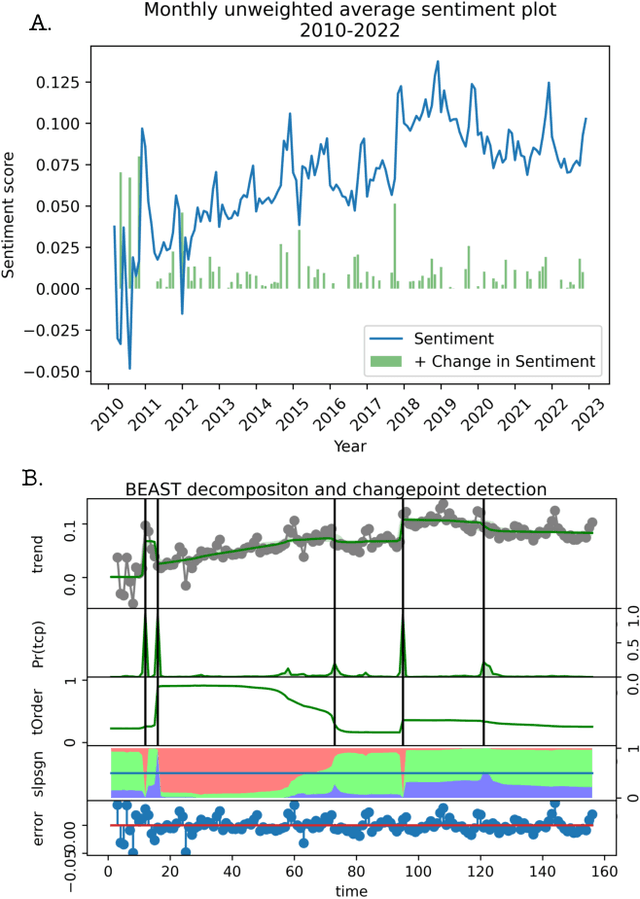
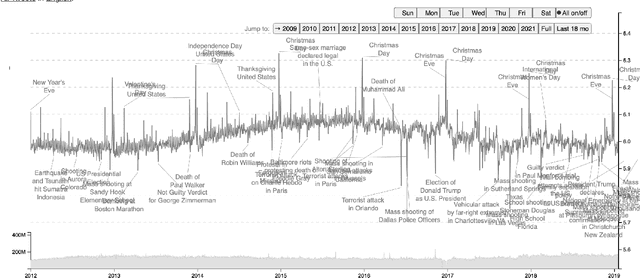
Recent studies suggest social media activity can function as a proxy for measures of state-level public health, detectable through natural language processing. We present results of our efforts to apply this approach to estimate homelessness at the state level throughout the US during the period 2010-2019 and 2022 using a dataset of roughly 1 million geotagged tweets containing the substring ``homeless.'' Correlations between homelessness-related tweet counts and ranked per capita homelessness volume, but not general-population densities, suggest a relationship between the likelihood of Twitter users to personally encounter or observe homelessness in their everyday lives and their likelihood to communicate about it online. An increase to the log-odds of ``homeless'' appearing in an English-language tweet, as well as an acceleration in the increase in average tweet sentiment, suggest that tweets about homelessness are also affected by trends at the nation-scale. Additionally, changes to the lexical content of tweets over time suggest that reversals to the polarity of national or state-level trends may be detectable through an increase in political or service-sector language over the semantics of charity or direct appeals. An analysis of user account type also revealed changes to Twitter-use patterns by accounts authored by individuals versus entities that may provide an additional signal to confirm changes to homelessness density in a given jurisdiction. While a computational approach to social media analysis may provide a low-cost, real-time dataset rich with information about nationwide and localized impacts of homelessness and homelessness policy, we find that practical issues abound, limiting the potential of social media as a proxy to complement other measures of homelessness.
CB-Conformer: Contextual biasing Conformer for biased word recognition
Apr 25, 2023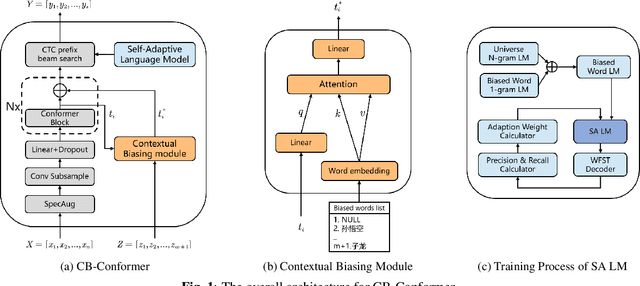
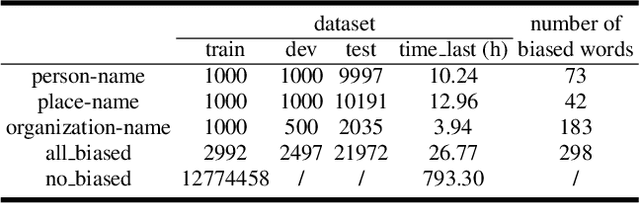
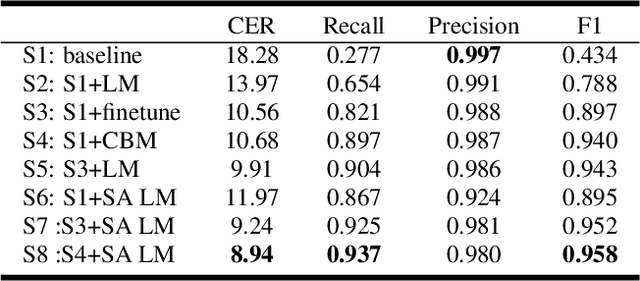
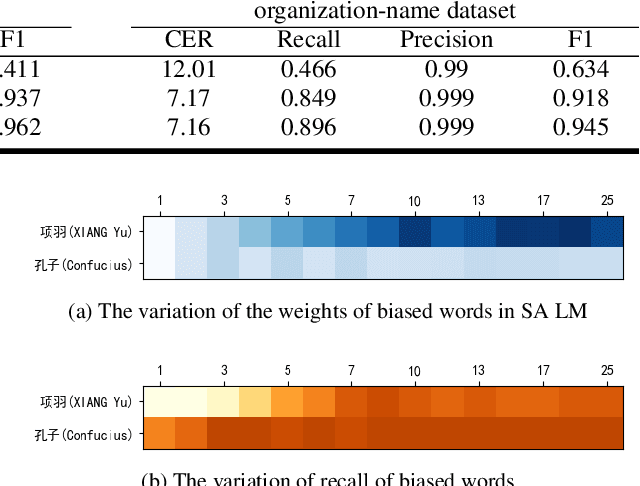
Due to the mismatch between the source and target domains, how to better utilize the biased word information to improve the performance of the automatic speech recognition model in the target domain becomes a hot research topic. Previous approaches either decode with a fixed external language model or introduce a sizeable biasing module, which leads to poor adaptability and slow inference. In this work, we propose CB-Conformer to improve biased word recognition by introducing the Contextual Biasing Module and the Self-Adaptive Language Model to vanilla Conformer. The Contextual Biasing Module combines audio fragments and contextual information, with only 0.2% model parameters of the original Conformer. The Self-Adaptive Language Model modifies the internal weights of biased words based on their recall and precision, resulting in a greater focus on biased words and more successful integration with the automatic speech recognition model than the standard fixed language model. In addition, we construct and release an open-source Mandarin biased-word dataset based on WenetSpeech. Experiments indicate that our proposed method brings a 15.34% character error rate reduction, a 14.13% biased word recall increase, and a 6.80% biased word F1-score increase compared with the base Conformer.
Context-Aware Classification of Legal Document Pages
Apr 25, 2023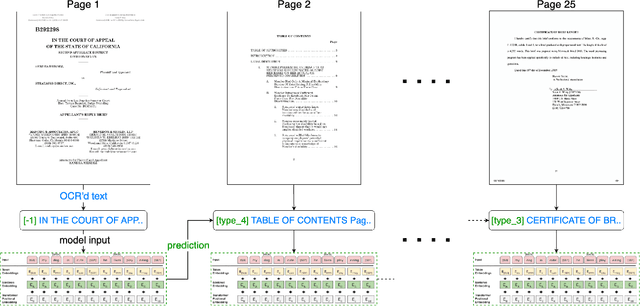
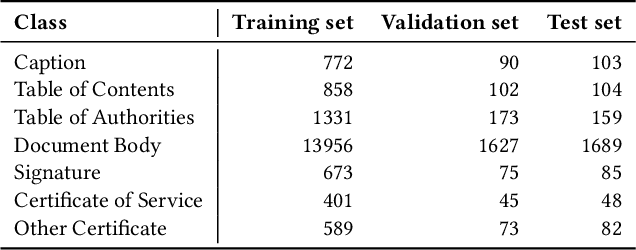


For many business applications that require the processing, indexing, and retrieval of professional documents such as legal briefs (in PDF format etc.), it is often essential to classify the pages of any given document into their corresponding types beforehand. Most existing studies in the field of document image classification either focus on single-page documents or treat multiple pages in a document independently. Although in recent years a few techniques have been proposed to exploit the context information from neighboring pages to enhance document page classification, they typically cannot be utilized with large pre-trained language models due to the constraint on input length. In this paper, we present a simple but effective approach that overcomes the above limitation. Specifically, we enhance the input with extra tokens carrying sequential information about previous pages - introducing recurrence - which enables the usage of pre-trained Transformer models like BERT for context-aware page classification. Our experiments conducted on two legal datasets in English and Portuguese respectively show that the proposed approach can significantly improve the performance of document page classification compared to the non-recurrent setup as well as the other context-aware baselines.
SkillQG: Learning to Generate Question for Reading Comprehension Assessment
May 08, 2023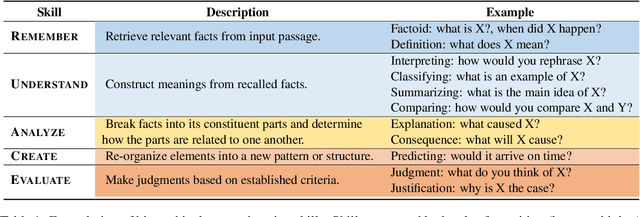
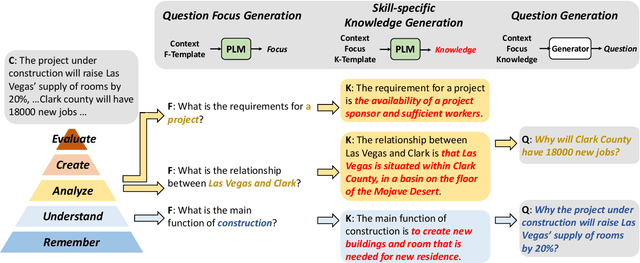
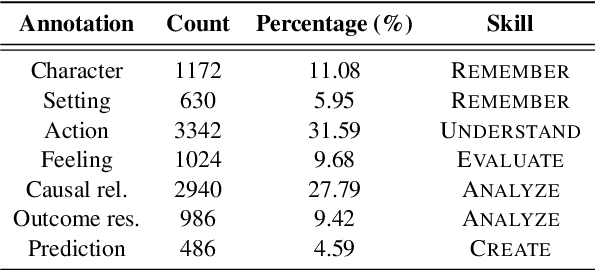
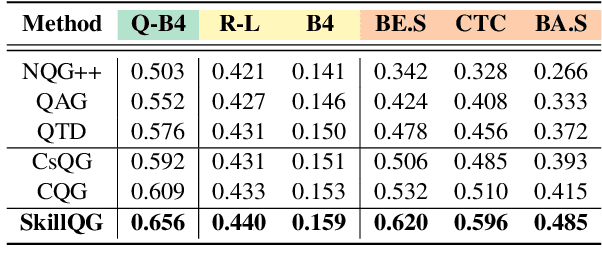
We present $\textbf{$\texttt{SkillQG}$}$: a question generation framework with controllable comprehension types for assessing and improving machine reading comprehension models. Existing question generation systems widely differentiate questions by $\textit{literal}$ information such as question words and answer types to generate semantically relevant questions for a given context. However, they rarely consider the $\textit{comprehension}$ nature of questions, i.e. the different comprehension capabilities embodied by different questions. In comparison, our $\texttt{SkillQG}$ is able to tailor a fine-grained assessment and improvement to the capabilities of question answering models built on it. Specifically, we first frame the comprehension type of questions based on a hierarchical skill-based schema, then formulate $\texttt{SkillQG}$ as a skill-conditioned question generator. Furthermore, to improve the controllability of generation, we augment the input text with question focus and skill-specific knowledge, which are constructed by iteratively prompting the pre-trained language models. Empirical results demonstrate that $\texttt{SkillQG}$ outperforms baselines in terms of quality, relevance, and skill-controllability while showing a promising performance boost in downstream question answering task.
APR: Online Distant Point Cloud Registration Through Aggregated Point Cloud Reconstruction
May 08, 2023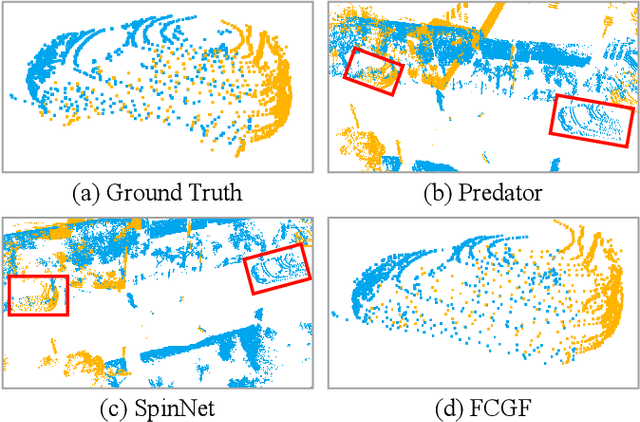
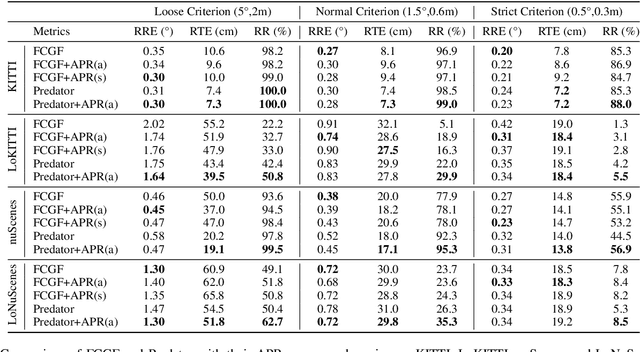
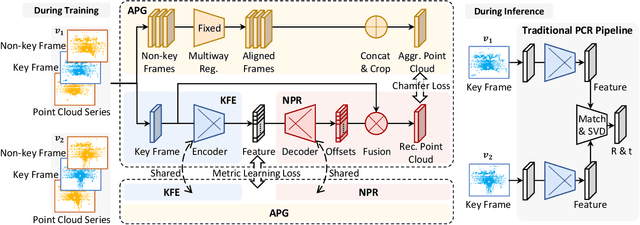
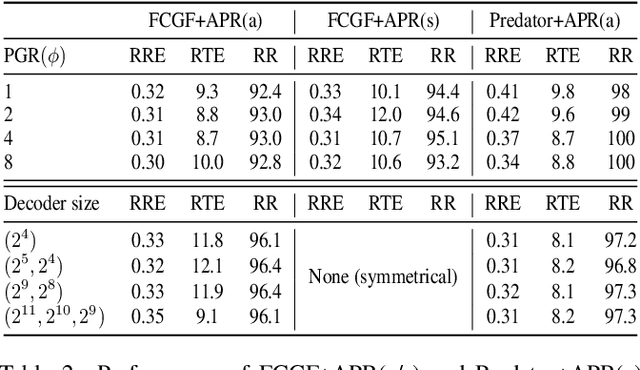
For many driving safety applications, it is of great importance to accurately register LiDAR point clouds generated on distant moving vehicles. However, such point clouds have extremely different point density and sensor perspective on the same object, making registration on such point clouds very hard. In this paper, we propose a novel feature extraction framework, called APR, for online distant point cloud registration. Specifically, APR leverages an autoencoder design, where the autoencoder reconstructs a denser aggregated point cloud with several frames instead of the original single input point cloud. Our design forces the encoder to extract features with rich local geometry information based on one single input point cloud. Such features are then used for online distant point cloud registration. We conduct extensive experiments against state-of-the-art (SOTA) feature extractors on KITTI and nuScenes datasets. Results show that APR outperforms all other extractors by a large margin, increasing average registration recall of SOTA extractors by 7.1% on LoKITTI and 4.6% on LoNuScenes. Code is available at https://github.com/liuQuan98/APR.
Cybernetic Environment: A Historical Reflection on System, Design, and Machine Intelligence
May 03, 2023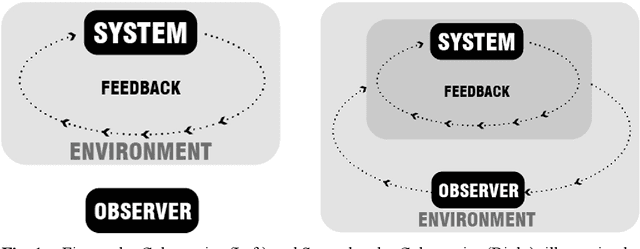
Taking on a historical lens, this paper traces the development of cybernetics and systems thinking back to the 1950s, when a group of interdisciplinary scholars converged to create a new theoretical model based on machines and systems for understanding matters of meaning, information, consciousness, and life. By presenting a genealogy of research in the landscape architecture discipline, the paper argues that landscape architects have been an important part of the development of cybernetics by materializing systems based on cybernetic principles in the environment through ecologically based landscape design. The landscape discipline has developed a design framework that provides transformative insights into understanding machine intelligence. The paper calls for a new paradigm of environmental engagement to understand matters of design and machine intelligence.
* 8 pages, theory/history
Geo-Information Harvesting from Social Media Data
Nov 01, 2022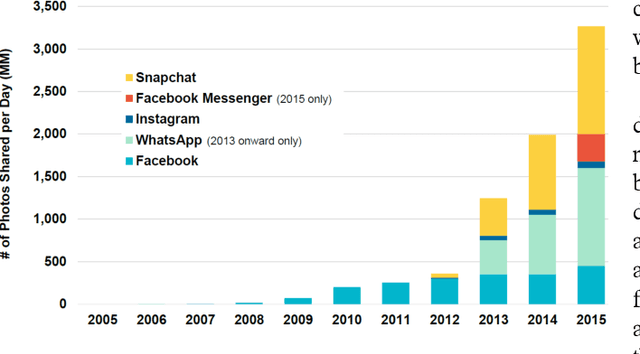

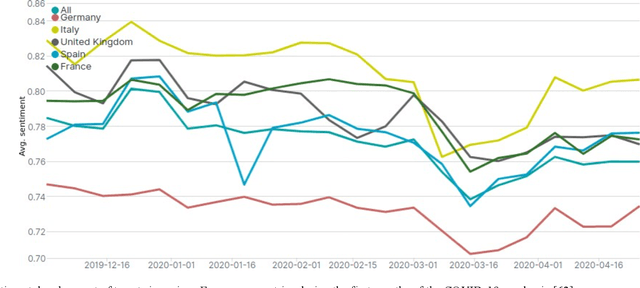
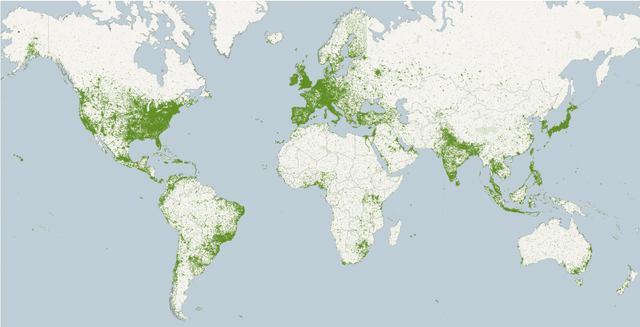
As unconventional sources of geo-information, massive imagery and text messages from open platforms and social media form a temporally quasi-seamless, spatially multi-perspective stream, but with unknown and diverse quality. Due to its complementarity to remote sensing data, geo-information from these sources offers promising perspectives, but harvesting is not trivial due to its data characteristics. In this article, we address key aspects in the field, including data availability, analysis-ready data preparation and data management, geo-information extraction from social media text messages and images, and the fusion of social media and remote sensing data. We then showcase some exemplary geographic applications. In addition, we present the first extensive discussion of ethical considerations of social media data in the context of geo-information harvesting and geographic applications. With this effort, we wish to stimulate curiosity and lay the groundwork for researchers who intend to explore social media data for geo-applications. We encourage the community to join forces by sharing their code and data.
Learning to Reason and Memorize with Self-Notes
May 01, 2023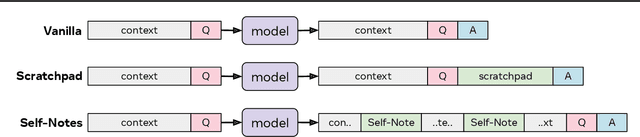
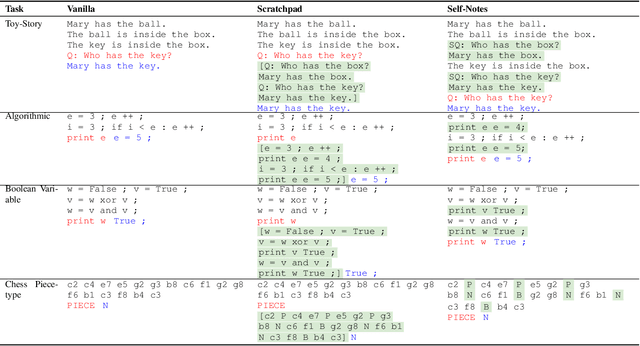
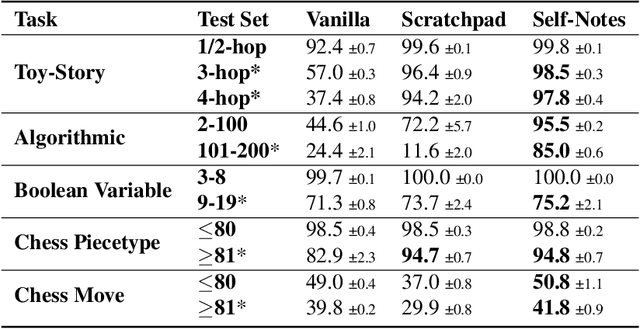
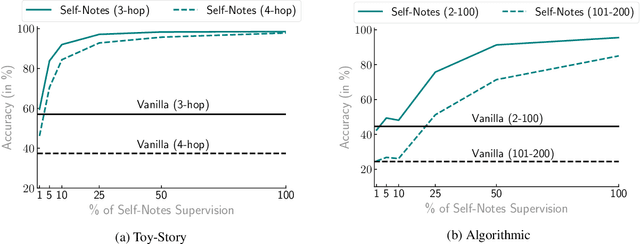
Large language models have been shown to struggle with limited context memory and multi-step reasoning. We propose a simple method for solving both of these problems by allowing the model to take Self-Notes. Unlike recent scratchpad approaches, the model can deviate from the input context at any time to explicitly think. This allows the model to recall information and perform reasoning on the fly as it reads the context, thus extending its memory and enabling multi-step reasoning. Our experiments on multiple tasks demonstrate that our method can successfully generalize to longer and more complicated instances from their training setup by taking Self-Notes at inference time.