 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LEA: Beyond Evolutionary Algorithms via Learned Optimization Strategy
Apr 19, 2023
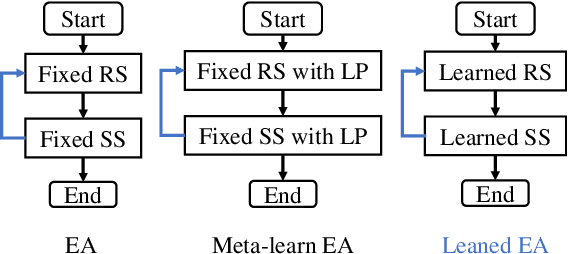
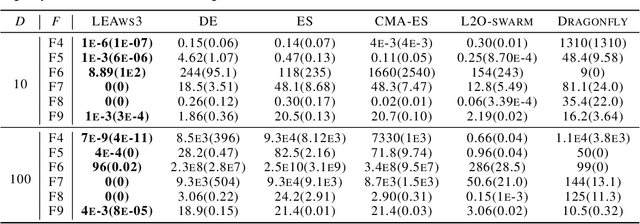
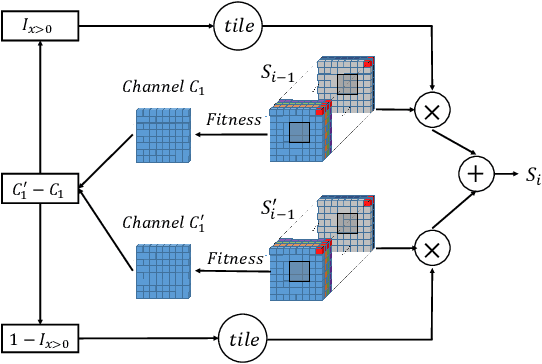
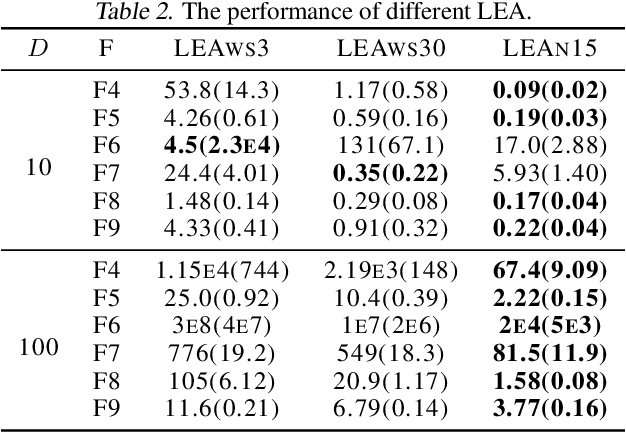
Evolutionary algorithms (EAs) have emerged as a powerful framework for expensive black-box optimization. Obtaining better solutions with less computational cost is essential and challenging for black-box optimization. The most critical obstacle is figuring out how to effectively use the target task information to form an efficient optimization strategy. However, current methods are weak due to the poor representation of the optimization strategy and the inefficient interaction between the optimization strategy and the target task. To overcome the above limitations, we design a learned EA (LEA) to realize the move from hand-designed optimization strategies to learned optimization strategies, including not only hyperparameters but also update rules. Unlike traditional EAs, LEA has high adaptability to the target task and can obtain better solutions with less computational cost. LEA is also able to effectively utilize the low-fidelity information of the target task to form an efficient optimization strategy. The experimental results on one synthetic case, CEC 2013, and two real-world cases show the advantages of learned optimization strategies over human-designed baselines. In addition, LEA is friendly to the acceleration provided by Graphics Processing Units and runs 102 times faster than unaccelerated EA when evolving 32 populations, each containing 6400 individuals.
An Equivariant Generative Framework for Molecular Graph-Structure Co-Design
Apr 12, 2023Designing molecules with desirable physiochemical properties and functionalities is a long-standing challenge in chemistry, material science, and drug discovery. Recently, machine learning-based generative models have emerged as promising approaches for \emph{de novo} molecule design. However, further refinement of methodology is highly desired as most existing methods lack unified modeling of 2D topology and 3D geometry information and fail to effectively learn the structure-property relationship for molecule design. Here we present MolCode, a roto-translation equivariant generative framework for \underline{Mol}ecular graph-structure \underline{Co-de}sign. In MolCode, 3D geometric information empowers the molecular 2D graph generation, which in turn helps guide the prediction of molecular 3D structure. Extensive experimental results show that MolCode outperforms previous methods on a series of challenging tasks including \emph{de novo} molecule design, targeted molecule discovery, and structure-based drug design. Particularly, MolCode not only consistently generates valid (99.95$\%$ Validity) and diverse (98.75$\%$ Uniqueness) molecular graphs/structures with desirable properties, but also generate drug-like molecules with high affinity to target proteins (61.8$\%$ high-affinity ratio), which demonstrates MolCode's potential applications in material design and drug discovery. Our extensive investigation reveals that the 2D topology and 3D geometry contain intrinsically complementary information in molecule design, and provide new insights into machine learning-based molecule representation and generation.
SDVRF: Sparse-to-Dense Voxel Region Fusion for Multi-modal 3D Object Detection
May 02, 2023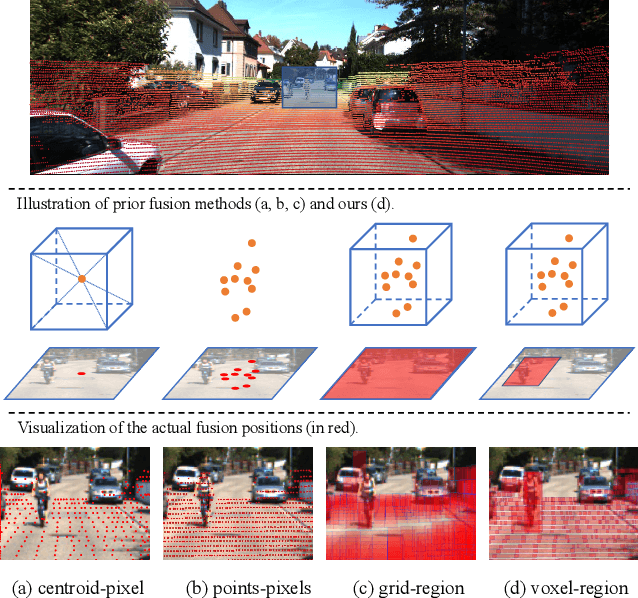
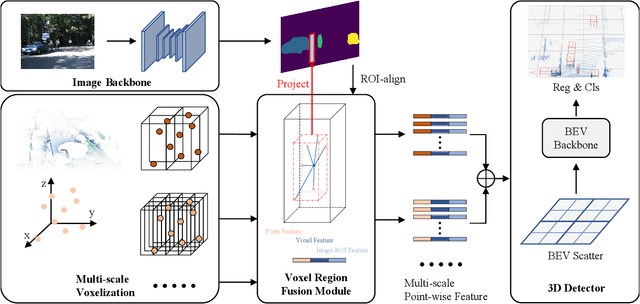
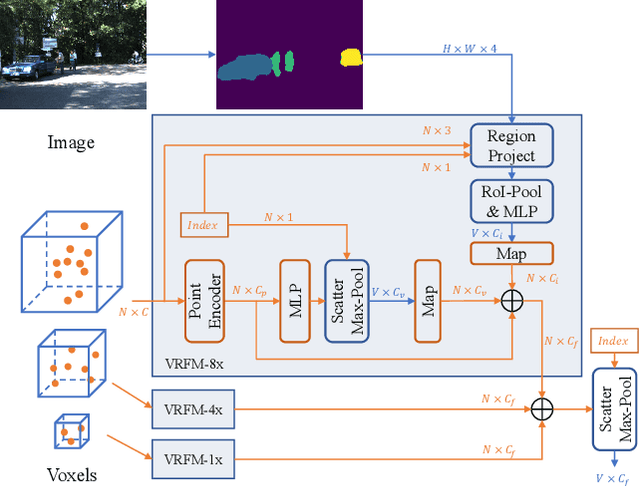

In the perception task of autonomous driving, multi-modal methods have become a trend due to the complementary characteristics of LiDAR point clouds and image data. However, the performance of previous methods is usually limited by the sparsity of the point cloud or the noise problem caused by the misalignment between LiDAR and the camera. To solve these two problems, we present a new concept, Voxel Region (VR), which is obtained by projecting the sparse local point clouds in each voxel dynamically. And we propose a novel fusion method, named Sparse-to-Dense Voxel Region Fusion (SDVRF). Specifically, more pixels of the image feature map inside the VR are gathered to supplement the voxel feature extracted from sparse points and achieve denser fusion. Meanwhile, different from prior methods, which project the size-fixed grids, our strategy of generating dynamic regions achieves better alignment and avoids introducing too much background noise. Furthermore, we propose a multi-scale fusion framework to extract more contextual information and capture the features of objects of different sizes. Experiments on the KITTI dataset show that our method improves the performance of different baselines, especially on classes of small size, including Pedestrian and Cyclist.
Human-machine knowledge hybrid augmentation method for surface defect detection based few-data learning
May 02, 2023
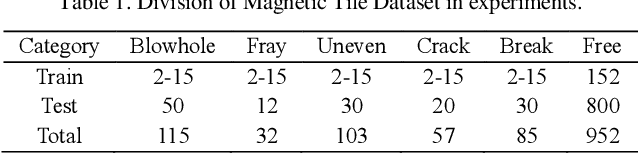
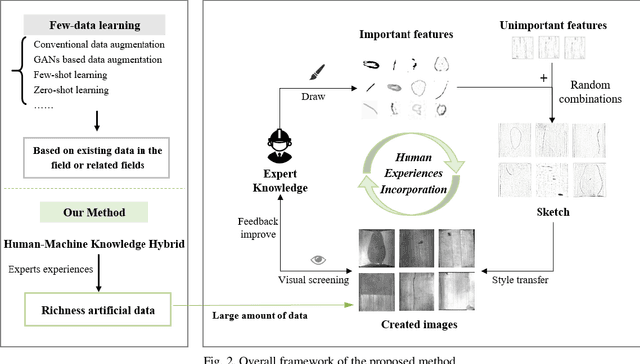

Visual-based defect detection is a crucial but challenging task in industrial quality control. Most mainstream methods rely on large amounts of existing or related domain data as auxiliary information. However, in actual industrial production, there are often multi-batch, low-volume manufacturing scenarios with rapidly changing task demands, making it difficult to obtain sufficient and diverse defect data. This paper proposes a parallel solution that uses a human-machine knowledge hybrid augmentation method to help the model extract unknown important features. Specifically, by incorporating experts' knowledge of abnormality to create data with rich features, positions, sizes, and backgrounds, we can quickly accumulate an amount of data from scratch and provide it to the model as prior knowledge for few-data learning. The proposed method was evaluated on the magnetic tile dataset and achieved F1-scores of 60.73%, 70.82%, 77.09%, and 82.81% when using 2, 5, 10, and 15 training images, respectively. Compared to the traditional augmentation method's F1-score of 64.59%, the proposed method achieved an 18.22% increase in the best result, demonstrating its feasibility and effectiveness in few-data industrial defect detection.
Are demographically invariant models and representations in medical imaging fair?
May 02, 2023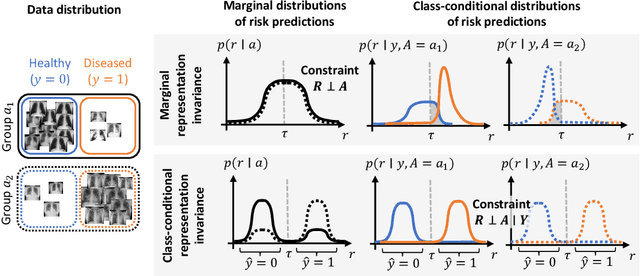
Medical imaging models have been shown to encode information about patient demographics (age, race, sex) in their latent representation, raising concerns about their potential for discrimination. Here, we ask whether it is feasible and desirable to train models that do not encode demographic attributes. We consider different types of invariance with respect to demographic attributes - marginal, class-conditional, and counterfactual model invariance - and lay out their equivalence to standard notions of algorithmic fairness. Drawing on existing theory, we find that marginal and class-conditional invariance can be considered overly restrictive approaches for achieving certain fairness notions, resulting in significant predictive performance losses. Concerning counterfactual model invariance, we note that defining medical image counterfactuals with respect to demographic attributes is fraught with complexities. Finally, we posit that demographic encoding may even be considered advantageous if it enables learning a task-specific encoding of demographic features that does not rely on human-constructed categories such as 'race' and 'gender'. We conclude that medical imaging models may need to encode demographic attributes, lending further urgency to calls for comprehensive model fairness assessments in terms of predictive performance.
ContactArt: Learning 3D Interaction Priors for Category-level Articulated Object and Hand Poses Estimation
May 02, 2023
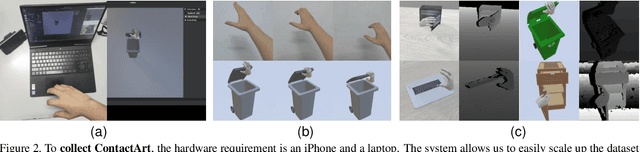
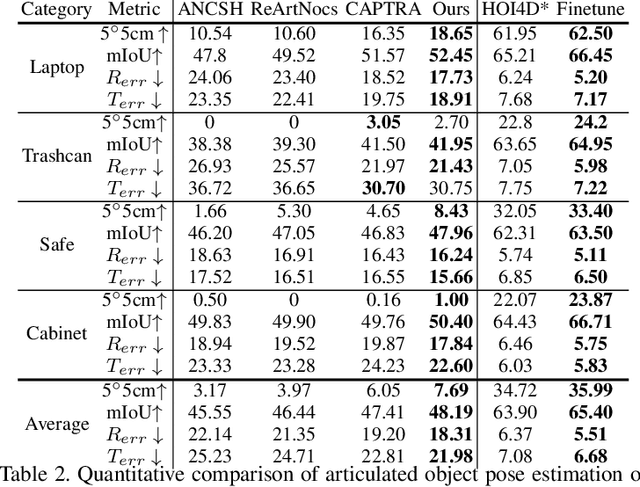
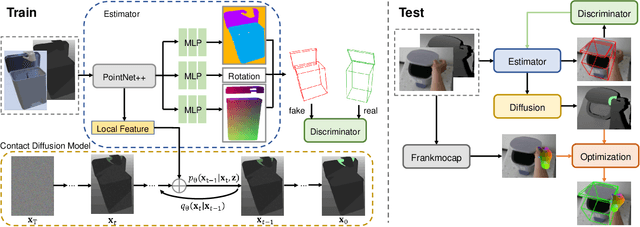
We propose a new dataset and a novel approach to learning hand-object interaction priors for hand and articulated object pose estimation. We first collect a dataset using visual teleoperation, where the human operator can directly play within a physical simulator to manipulate the articulated objects. We record the data and obtain free and accurate annotations on object poses and contact information from the simulator. Our system only requires an iPhone to record human hand motion, which can be easily scaled up and largely lower the costs of data and annotation collection. With this data, we learn 3D interaction priors including a discriminator (in a GAN) capturing the distribution of how object parts are arranged, and a diffusion model which generates the contact regions on articulated objects, guiding the hand pose estimation. Such structural and contact priors can easily transfer to real-world data with barely any domain gap. By using our data and learned priors, our method significantly improves the performance on joint hand and articulated object poses estimation over the existing state-of-the-art methods. The project is available at https://zehaozhu.github.io/ContactArt/ .
Physics-Informed Learning Using Hamiltonian Neural Networks with Output Error Noise Models
May 02, 2023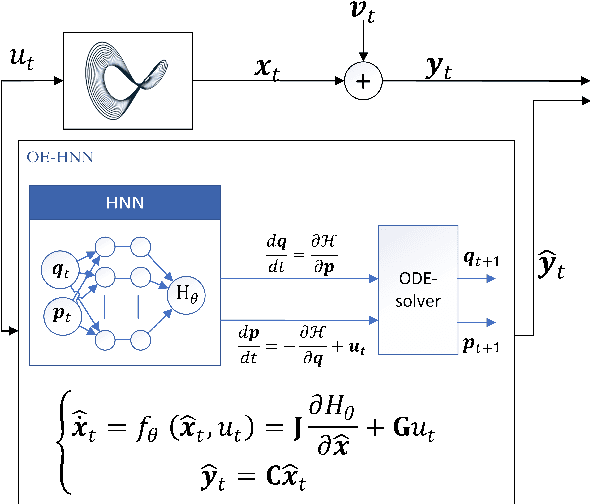

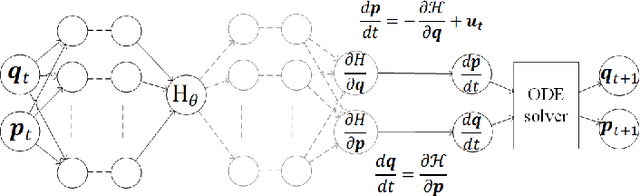
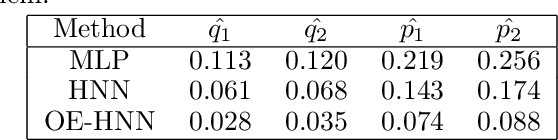
In order to make data-driven models of physical systems interpretable and reliable, it is essential to include prior physical knowledge in the modeling framework. Hamiltonian Neural Networks (HNNs) implement Hamiltonian theory in deep learning and form a comprehensive framework for modeling autonomous energy-conservative systems. Despite being suitable to estimate a wide range of physical system behavior from data, classical HNNs are restricted to systems without inputs and require noiseless state measurements and information on the derivative of the state to be available. To address these challenges, this paper introduces an Output Error Hamiltonian Neural Network (OE-HNN) modeling approach to address the modeling of physical systems with inputs and noisy state measurements. Furthermore, it does not require the state derivatives to be known. Instead, the OE-HNN utilizes an ODE-solver embedded in the training process, which enables the OE-HNN to learn the dynamics from noisy state measurements. In addition, extending HNNs based on the generalized Hamiltonian theory enables to include external inputs into the framework which are important for engineering applications. We demonstrate via simulation examples that the proposed OE-HNNs results in superior modeling performance compared to classical HNNs.
Multimodal Neural Databases
May 02, 2023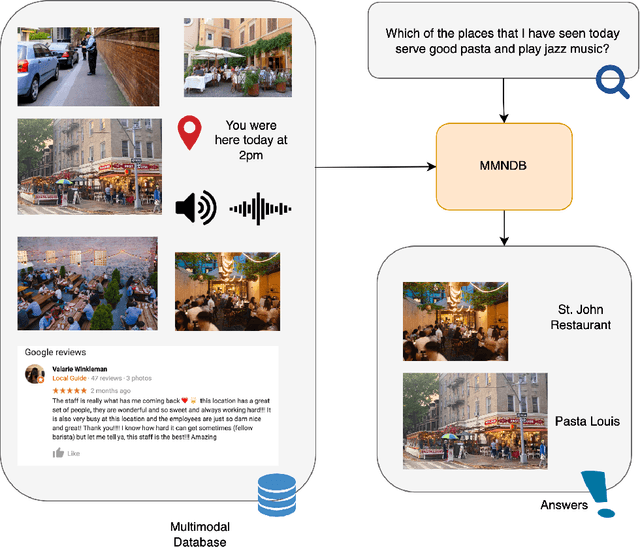
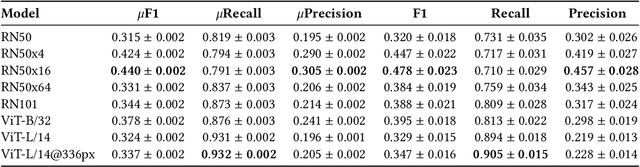
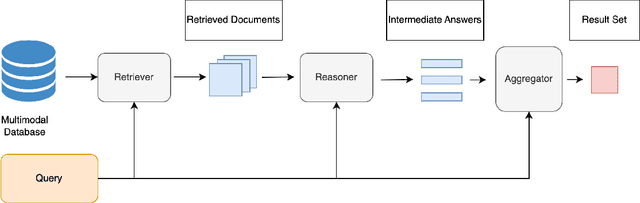
The rise in loosely-structured data available through text, images, and other modalities has called for new ways of querying them. Multimedia Information Retrieval has filled this gap and has witnessed exciting progress in recent years. Tasks such as search and retrieval of extensive multimedia archives have undergone massive performance improvements, driven to a large extent by recent developments in multimodal deep learning. However, methods in this field remain limited in the kinds of queries they support and, in particular, their inability to answer database-like queries. For this reason, inspired by recent work on neural databases, we propose a new framework, which we name Multimodal Neural Databases (MMNDBs). MMNDBs can answer complex database-like queries that involve reasoning over different input modalities, such as text and images, at scale. In this paper, we present the first architecture able to fulfill this set of requirements and test it with several baselines, showing the limitations of currently available models. The results show the potential of these new techniques to process unstructured data coming from different modalities, paving the way for future research in the area. Code to replicate the experiments will be released at https://github.com/GiovanniTRA/MultimodalNeuralDatabases
Mitigating Approximate Memorization in Language Models via Dissimilarity Learned Policy
May 02, 2023Large Language models (LLMs) are trained on large amounts of data, which can include sensitive information that may compromise personal privacy. LLMs showed to memorize parts of the training data and emit those data verbatim when an adversary prompts appropriately. Previous research has primarily focused on data preprocessing and differential privacy techniques to address memorization or prevent verbatim memorization exclusively, which can give a false sense of privacy. However, these methods rely on explicit and implicit assumptions about the structure of the data to be protected, which often results in an incomplete solution to the problem. To address this, we propose a novel framework that utilizes a reinforcement learning approach (PPO) to fine-tune LLMs to mitigate approximate memorization. Our approach utilizes a negative similarity score, such as BERTScore or SacreBLEU, as a reward signal to learn a dissimilarity policy. Our results demonstrate that this framework effectively mitigates approximate memorization while maintaining high levels of coherence and fluency in the generated samples. Furthermore, our framework is robust in mitigating approximate memorization across various circumstances, including longer context, which is known to increase memorization in LLMs.
An Evidential Real-Time Multi-Mode Fault Diagnosis Approach Based on Broad Learning System
Apr 29, 2023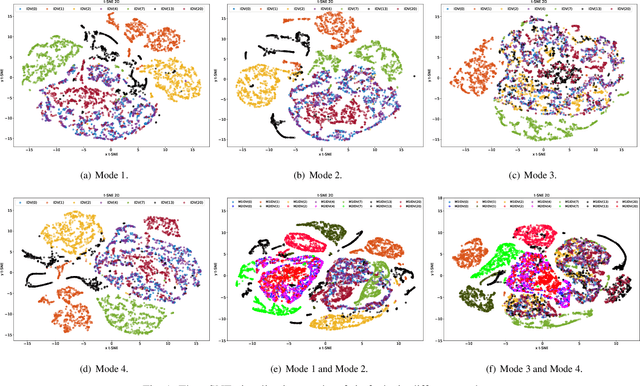
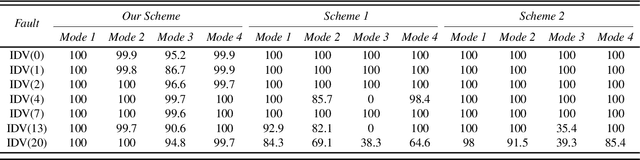
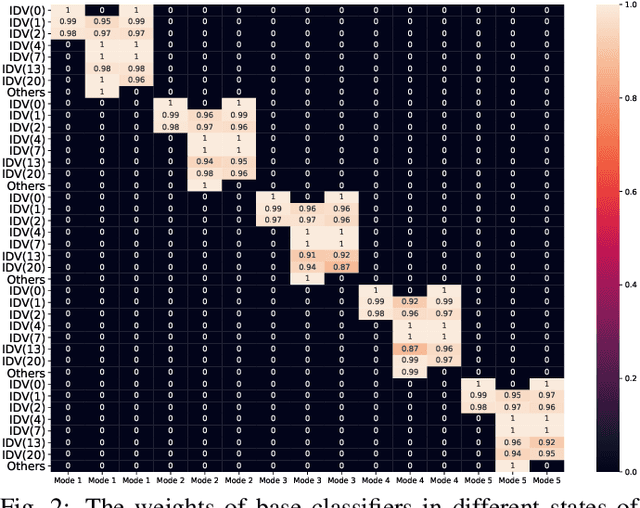
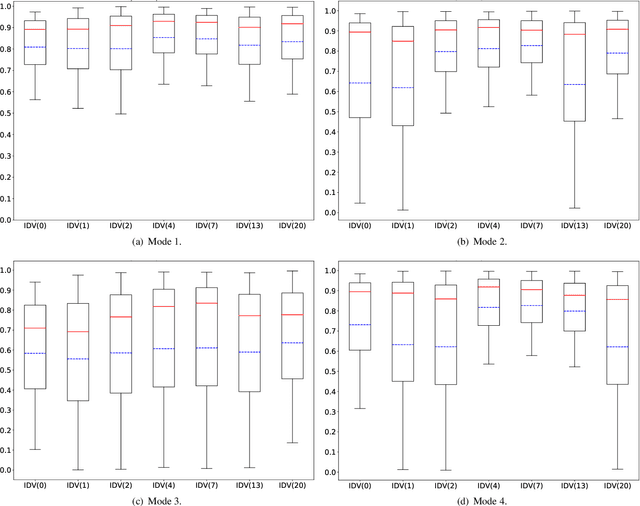
Fault diagnosis is a crucial area of research in the industry due to diverse operating conditions that exhibit non-Gaussian, multi-mode, and center-drift characteristics. Currently, data-driven approaches are the main focus in the field, but they pose challenges for continuous fault classification and parameter updates of fault classifiers, particularly in multiple operating modes and real-time settings. Therefore, a pressing issue is to achieve real-time multi-mode fault diagnosis for industrial systems. To address this problem, this paper proposes a novel approach that utilizes an evidence reasoning (ER) algorithm to fuse information and merge outputs from different base classifiers. These base classifiers are developed using a broad learning system (BLS) to improve good fault diagnosis performance. Moreover, in this approach, the pseudo-label learning method is employed to update model parameters in real-time. To demonstrate the effectiveness of the proposed approach, we perform experiments using the multi-mode Tennessee Eastman process dataset.