 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Augmenting Low-Resource Text Classification with Graph-Grounded Pre-training and Prompting
May 05, 2023
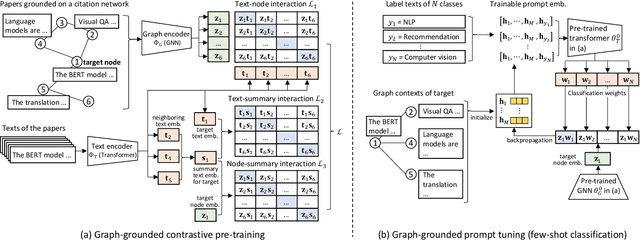
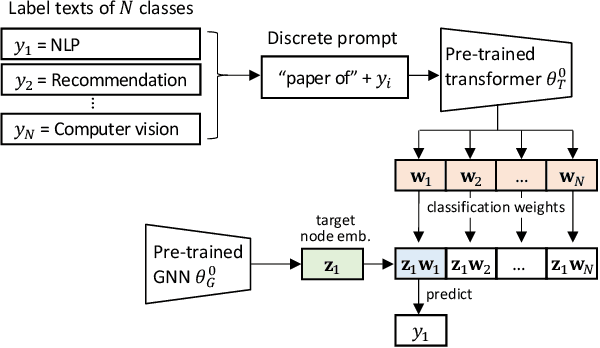
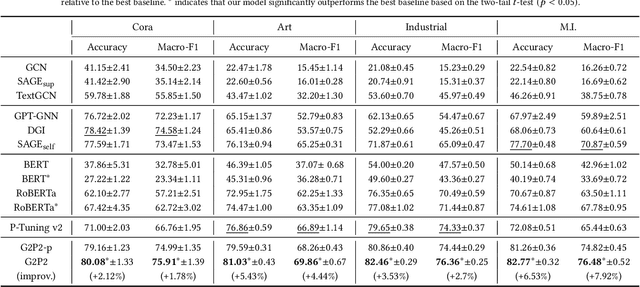
Text classification is a fundamental problem in information retrieval with many real-world applications, such as predicting the topics of online articles and the categories of e-commerce product descriptions. However, low-resource text classification, with few or no labeled samples, poses a serious concern for supervised learning. Meanwhile, many text data are inherently grounded on a network structure, such as a hyperlink/citation network for online articles, and a user-item purchase network for e-commerce products. These graph structures capture rich semantic relationships, which can potentially augment low-resource text classification. In this paper, we propose a novel model called Graph-Grounded Pre-training and Prompting (G2P2) to address low-resource text classification in a two-pronged approach. During pre-training, we propose three graph interaction-based contrastive strategies to jointly pre-train a graph-text model; during downstream classification, we explore prompting for the jointly pre-trained model to achieve low-resource classification. Extensive experiments on four real-world datasets demonstrate the strength of G2P2 in zero- and few-shot low-resource text classification tasks.
The geometry of financial institutions -- Wasserstein clustering of financial data
May 05, 2023The increasing availability of granular and big data on various objects of interest has made it necessary to develop methods for condensing this information into a representative and intelligible map. Financial regulation is a field that exemplifies this need, as regulators require diverse and often highly granular data from financial institutions to monitor and assess their activities. However, processing and analyzing such data can be a daunting task, especially given the challenges of dealing with missing values and identifying clusters based on specific features. To address these challenges, we propose a variant of Lloyd's algorithm that applies to probability distributions and uses generalized Wasserstein barycenters to construct a metric space which represents given data on various objects in condensed form. By applying our method to the financial regulation context, we demonstrate its usefulness in dealing with the specific challenges faced by regulators in this domain. We believe that our approach can also be applied more generally to other fields where large and complex data sets need to be represented in concise form.
Large Language Models in Sport Science & Medicine: Opportunities, Risks and Considerations
May 05, 2023
This paper explores the potential opportunities, risks, and challenges associated with the use of large language models (LLMs) in sports science and medicine. LLMs are large neural networks with transformer style architectures trained on vast amounts of textual data, and typically refined with human feedback. LLMs can perform a large range of natural language processing tasks. In sports science and medicine, LLMs have the potential to support and augment the knowledge of sports medicine practitioners, make recommendations for personalised training programs, and potentially distribute high-quality information to practitioners in developing countries. However, there are also potential risks associated with the use and development of LLMs, including biases in the dataset used to create the model, the risk of exposing confidential data, the risk of generating harmful output, and the need to align these models with human preferences through feedback. Further research is needed to fully understand the potential applications of LLMs in sports science and medicine and to ensure that their use is ethical and beneficial to athletes, clients, patients, practitioners, and the general public.
AmGCL: Feature Imputation of Attribute Missing Graph via Self-supervised Contrastive Learning
May 05, 2023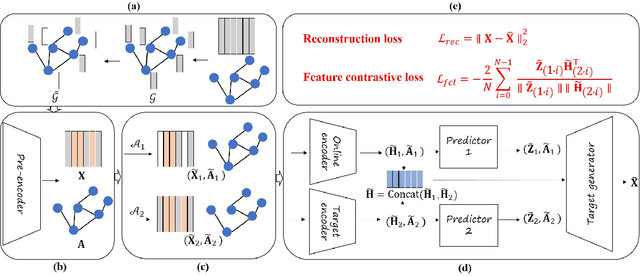
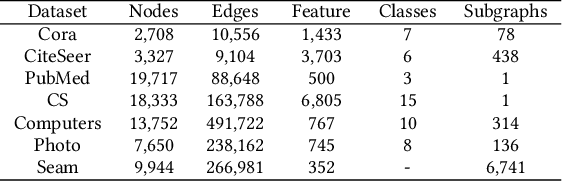
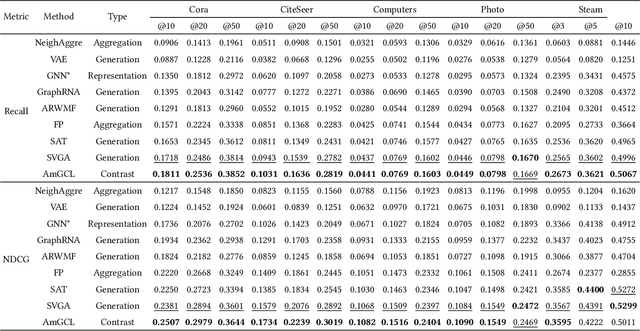
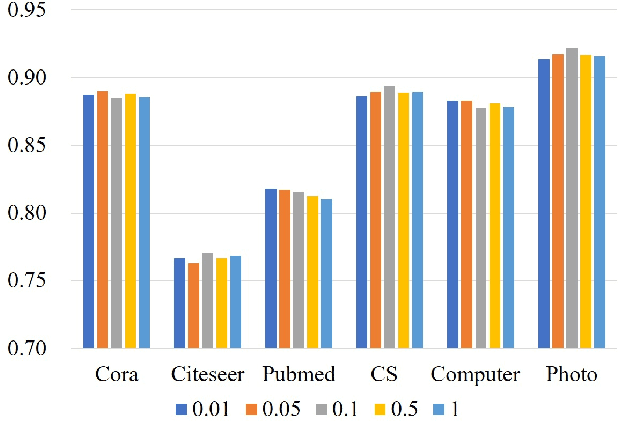
Attribute graphs are ubiquitous in multimedia applications, and graph representation learning (GRL) has been successful in analyzing attribute graph data. However, incomplete graph data and missing node attributes can have a negative impact on media knowledge discovery. Existing methods for handling attribute missing graph have limited assumptions or fail to capture complex attribute-graph dependencies. To address these challenges, we propose Attribute missing Graph Contrastive Learning (AmGCL), a framework for handling missing node attributes in attribute graph data. AmGCL leverages Dirichlet energy minimization-based feature precoding to encode in missing attributes and a self-supervised Graph Augmentation Contrastive Learning Structure (GACLS) to learn latent variables from the encoded-in data. Specifically, AmGCL utilizies feature reconstruction based on structure-attribute energy minimization while maximizes the lower bound of evidence for latent representation mutual information. Our experimental results on multiple real-world datasets demonstrate that AmGCL outperforms state-of-the-art methods in both feature imputation and node classification tasks, indicating the effectiveness of our proposed method in real-world attribute graph analysis tasks.
Instruction-ViT: Multi-Modal Prompts for Instruction Learning in ViT
Apr 29, 2023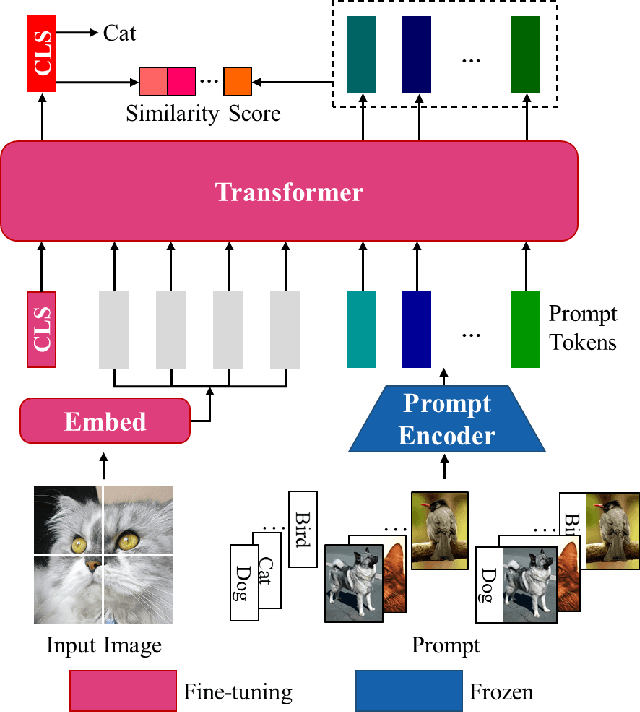
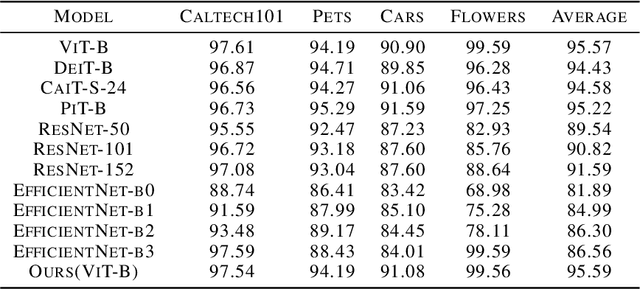


Prompts have been proven to play a crucial role in large language models, and in recent years, vision models have also been using prompts to improve scalability for multiple downstream tasks. In this paper, we focus on adapting prompt design based on instruction tuning into a visual transformer model for image classification which we called Instruction-ViT. The key idea is to implement multi-modal prompts (text or image prompt) related to category information to guide the fine-tuning of the model. Based on the experiments of several image captionining tasks, the performance and domain adaptability were improved. Our work provided an innovative strategy to fuse multi-modal prompts with better performance and faster adaptability for visual classification models.
Learning Semi-supervised Gaussian Mixture Models for Generalized Category Discovery
May 10, 2023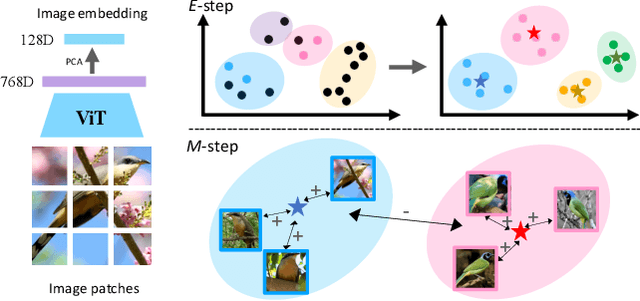
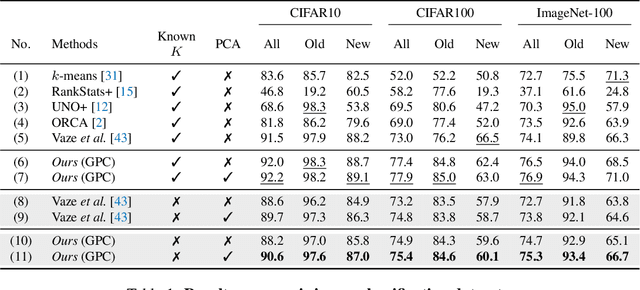

In this paper, we address the problem of generalized category discovery (GCD), \ie, given a set of images where part of them are labelled and the rest are not, the task is to automatically cluster the images in the unlabelled data, leveraging the information from the labelled data, while the unlabelled data contain images from the labelled classes and also new ones. GCD is similar to semi-supervised learning (SSL) but is more realistic and challenging, as SSL assumes all the unlabelled images are from the same classes as the labelled ones. We also do not assume the class number in the unlabelled data is known a-priori, making the GCD problem even harder. To tackle the problem of GCD without knowing the class number, we propose an EM-like framework that alternates between representation learning and class number estimation. We propose a semi-supervised variant of the Gaussian Mixture Model (GMM) with a stochastic splitting and merging mechanism to dynamically determine the prototypes by examining the cluster compactness and separability. With these prototypes, we leverage prototypical contrastive learning for representation learning on the partially labelled data subject to the constraints imposed by the labelled data. Our framework alternates between these two steps until convergence. The cluster assignment for an unlabelled instance can then be retrieved by identifying its nearest prototype. We comprehensively evaluate our framework on both generic image classification datasets and challenging fine-grained object recognition datasets, achieving state-of-the-art performance.
DeepSTEP -- Deep Learning-Based Spatio-Temporal End-To-End Perception for Autonomous Vehicles
May 11, 2023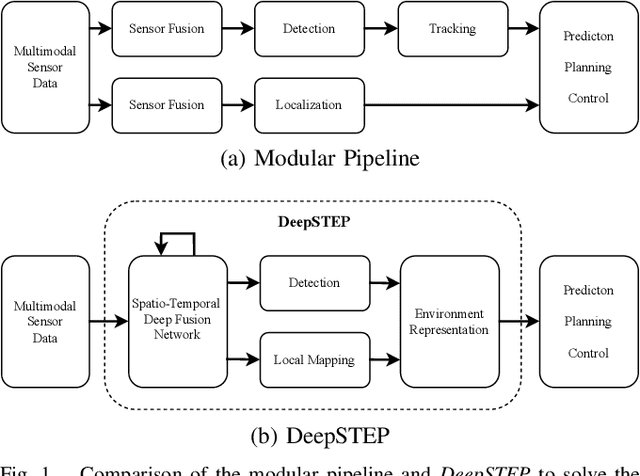
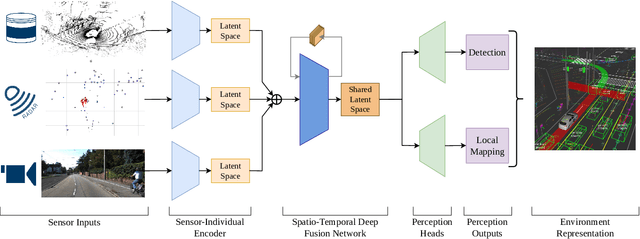
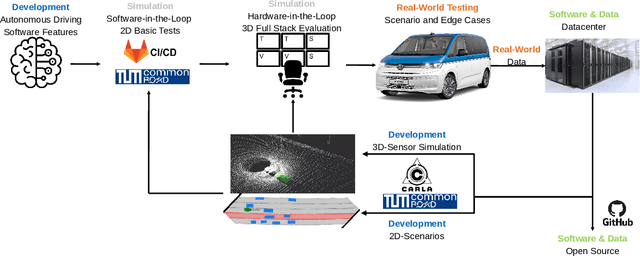
Autonomous vehicles demand high accuracy and robustness of perception algorithms. To develop efficient and scalable perception algorithms, the maximum information should be extracted from the available sensor data. In this work, we present our concept for an end-to-end perception architecture, named DeepSTEP. The deep learning-based architecture processes raw sensor data from the camera, LiDAR, and RaDAR, and combines the extracted data in a deep fusion network. The output of this deep fusion network is a shared feature space, which is used by perception head networks to fulfill several perception tasks, such as object detection or local mapping. DeepSTEP incorporates multiple ideas to advance state of the art: First, combining detection and localization into a single pipeline allows for efficient processing to reduce computational overhead and further improves overall performance. Second, the architecture leverages the temporal domain by using a self-attention mechanism that focuses on the most important features. We believe that our concept of DeepSTEP will advance the development of end-to-end perception systems. The network will be deployed on our research vehicle, which will be used as a platform for data collection, real-world testing, and validation. In conclusion, DeepSTEP represents a significant advancement in the field of perception for autonomous vehicles. The architecture's end-to-end design, time-aware attention mechanism, and integration of multiple perception tasks make it a promising solution for real-world deployment. This research is a work in progress and presents the first concept of establishing a novel perception pipeline.
A Lightweight Constrained Generation Alternative for Query-focused Summarization
Apr 23, 2023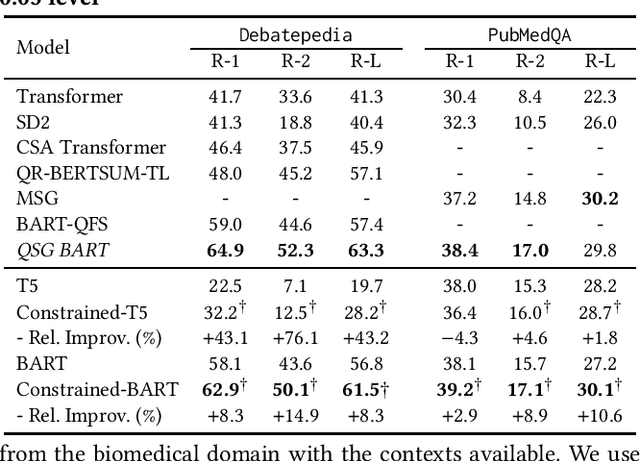
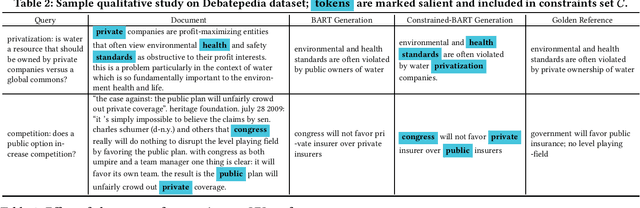
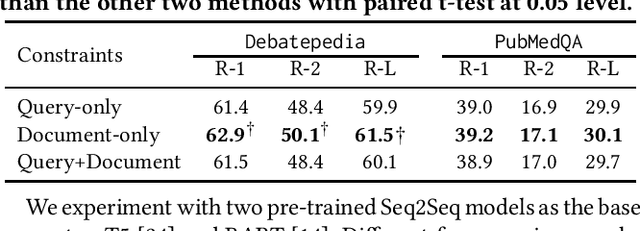
Query-focused summarization (QFS) aims to provide a summary of a document that satisfies information need of a given query and is useful in various IR applications, such as abstractive snippet generation. Current QFS approaches typically involve injecting additional information, e.g. query-answer relevance or fine-grained token-level interaction between a query and document, into a finetuned large language model. However, these approaches often require extra parameters \& training, and generalize poorly to new dataset distributions. To mitigate this, we propose leveraging a recently developed constrained generation model Neurological Decoding (NLD) as an alternative to current QFS regimes which rely on additional sub-architectures and training. We first construct lexical constraints by identifying important tokens from the document using a lightweight gradient attribution model, then subsequently force the generated summary to satisfy these constraints by directly manipulating the final vocabulary likelihood. This lightweight approach requires no additional parameters or finetuning as it utilizes both an off-the-shelf neural retrieval model to construct the constraints and a standard generative language model to produce the QFS. We demonstrate the efficacy of this approach on two public QFS collections achieving near parity with the state-of-the-art model with substantially reduced complexity.
Dexterous In-Hand Manipulation of Slender Cylindrical Objects through Deep Reinforcement Learning with Tactile Sensing
Apr 11, 2023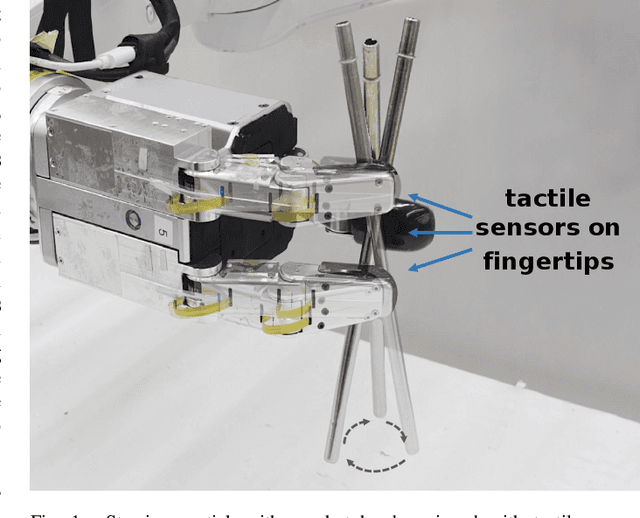
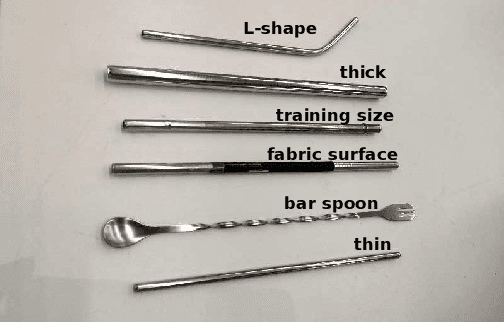

Continuous in-hand manipulation is an important physical interaction skill, where tactile sensing provides indispensable contact information to enable dexterous manipulation of small objects. This work proposed a framework for end-to-end policy learning with tactile feedback and sim-to-real transfer, which achieved fine in-hand manipulation that controls the pose of a thin cylindrical object, such as a long stick, to track various continuous trajectories through multiple contacts of three fingertips of a dexterous robot hand with tactile sensor arrays. We estimated the central contact position between the stick and each fingertip from the high-dimensional tactile information and showed that the learned policies achieved effective manipulation performance with the processed tactile feedback. The policies were trained with deep reinforcement learning in simulation and successfully transferred to real-world experiments, using coordinated model calibration and domain randomization. We evaluated the effectiveness of tactile information via comparative studies and validated the sim-to-real performance through real-world experiments.
Privacy-Preserving Matrix Factorization for Recommendation Systems using Gaussian Mechanism
Apr 11, 2023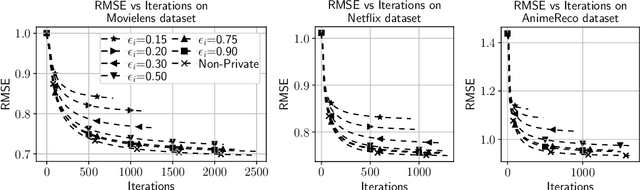
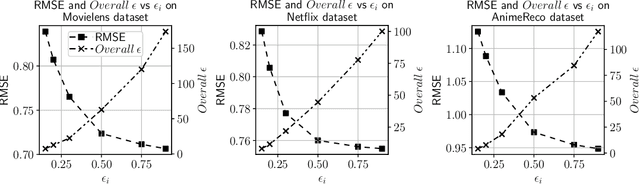
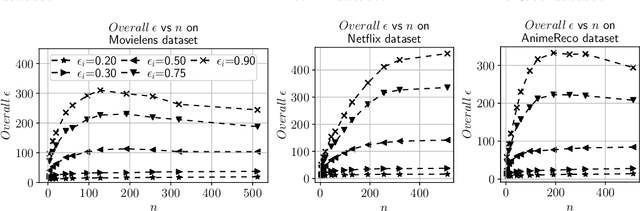
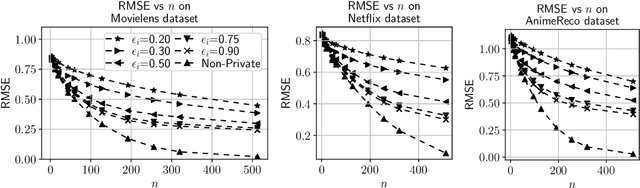
Building a recommendation system involves analyzing user data, which can potentially leak sensitive information about users. Anonymizing user data is often not sufficient for preserving user privacy. Motivated by this, we propose a privacy-preserving recommendation system based on the differential privacy framework and matrix factorization, which is one of the most popular algorithms for recommendation systems. As differential privacy is a powerful and robust mathematical framework for designing privacy-preserving machine learning algorithms, it is possible to prevent adversaries from extracting sensitive user information even if the adversary possesses their publicly available (auxiliary) information. We implement differential privacy via the Gaussian mechanism in the form of output perturbation and release user profiles that satisfy privacy definitions. We employ R\'enyi Differential Privacy for a tight characterization of the overall privacy loss. We perform extensive experiments on real data to demonstrate that our proposed algorithm can offer excellent utility for some parameter choices, while guaranteeing strict privacy.