 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Unsupervised Information Refinement Training of Large Language Models for Retrieval-Augmented Generation
Feb 28, 2024
Retrieval-augmented generation (RAG) enhances large language models (LLMs) by incorporating additional information from retrieval. However, studies have shown that LLMs still face challenges in effectively using the retrieved information, even ignoring it or being misled by it. The key reason is that the training of LLMs does not clearly make LLMs learn how to utilize input retrieved texts with varied quality. In this paper, we propose a novel perspective that considers the role of LLMs in RAG as ``Information Refiner'', which means that regardless of correctness, completeness, or usefulness of retrieved texts, LLMs can consistently integrate knowledge within the retrieved texts and model parameters to generate the texts that are more concise, accurate, and complete than the retrieved texts. To this end, we propose an information refinement training method named InFO-RAG that optimizes LLMs for RAG in an unsupervised manner. InFO-RAG is low-cost and general across various tasks. Extensive experiments on zero-shot prediction of 11 datasets in diverse tasks including Question Answering, Slot-Filling, Language Modeling, Dialogue, and Code Generation show that InFO-RAG improves the performance of LLaMA2 by an average of 9.39\% relative points. InFO-RAG also shows advantages in in-context learning and robustness of RAG.
Jointly Optimizing Terahertz based Sensing and Communications in Vehicular Networks: A Dynamic Graph Neural Network Approach
Mar 17, 2024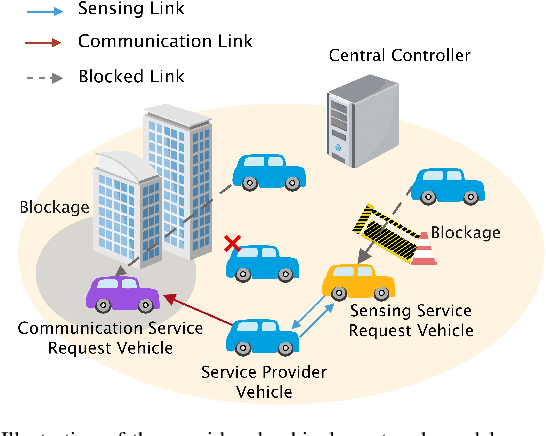
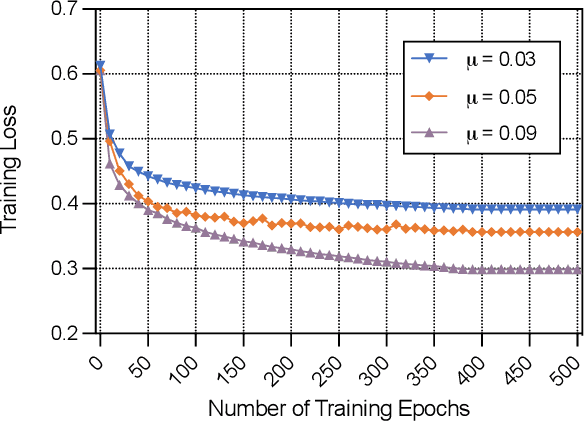

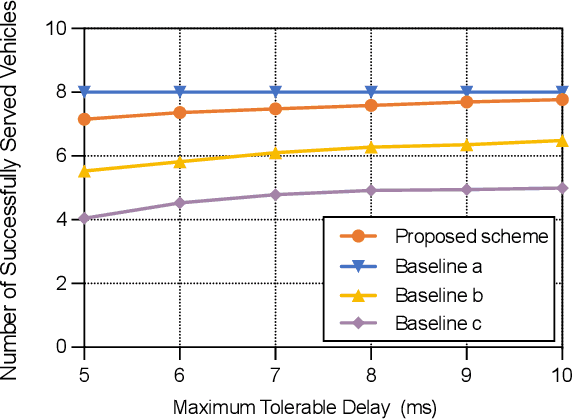
In this paper, the problem of vehicle service mode selection (sensing, communication, or both) and vehicle connections within terahertz (THz) enabled joint sensing and communications over vehicular networks is studied. The considered network consists of several service provider vehicles (SPVs) that can provide: 1) only sensing service, 2) only communication service, and 3) both services, sensing service request vehicles, and communication service request vehicles. Based on the vehicle network topology and their service accessibility, SPVs strategically select service request vehicles to provide sensing, communication, or both services. This problem is formulated as an optimization problem, aiming to maximize the number of successfully served vehicles by jointly determining the service mode of each SPV and its associated vehicles. To solve this problem, we propose a dynamic graph neural network (GNN) model that selects appropriate graph information aggregation functions according to the vehicle network topology, thus extracting more vehicle network information compared to traditional static GNNs that use fixed aggregation functions for different vehicle network topologies. Using the extracted vehicle network information, the service mode of each SPV and its served service request vehicles will be determined. Simulation results show that the proposed dynamic GNN based method can improve the number of successfully served vehicles by up to 17% and 28% compared to a GNN based algorithm with a fixed neural network model and a conventional optimization algorithm without using GNNs.
$\texttt{COSMIC}$: Mutual Information for Task-Agnostic Summarization Evaluation
Feb 29, 2024Assessing the quality of summarizers poses significant challenges. In response, we propose a novel task-oriented evaluation approach that assesses summarizers based on their capacity to produce summaries that are useful for downstream tasks, while preserving task outcomes. We theoretically establish a direct relationship between the resulting error probability of these tasks and the mutual information between source texts and generated summaries. We introduce $\texttt{COSMIC}$ as a practical implementation of this metric, demonstrating its strong correlation with human judgment-based metrics and its effectiveness in predicting downstream task performance. Comparative analyses against established metrics like $\texttt{BERTScore}$ and $\texttt{ROUGE}$ highlight the competitive performance of $\texttt{COSMIC}$.
CoMo: Controllable Motion Generation through Language Guided Pose Code Editing
Mar 20, 2024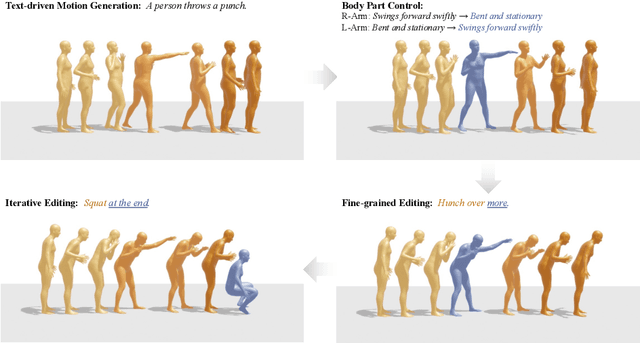
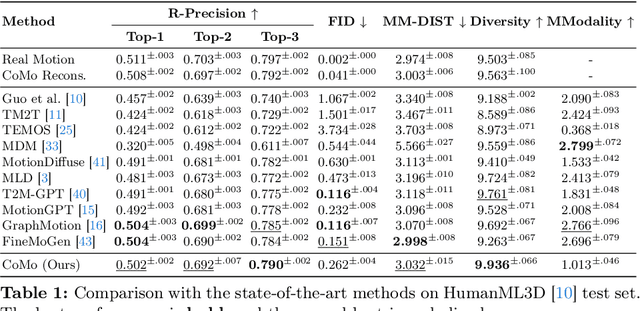
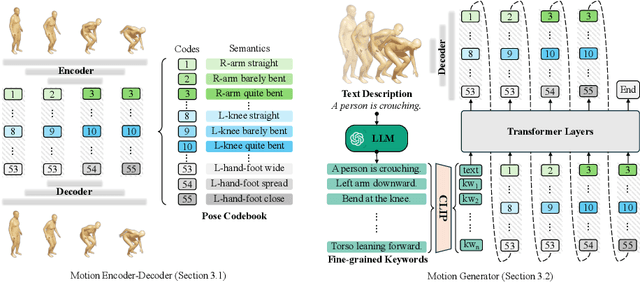
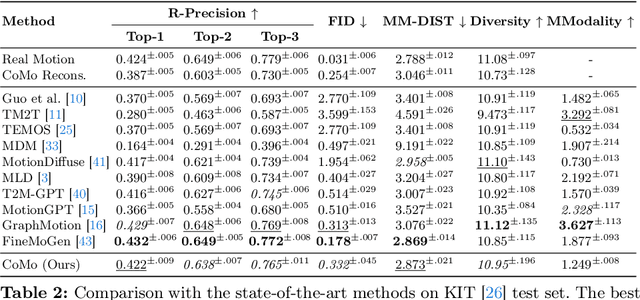
Text-to-motion models excel at efficient human motion generation, but existing approaches lack fine-grained controllability over the generation process. Consequently, modifying subtle postures within a motion or inserting new actions at specific moments remains a challenge, limiting the applicability of these methods in diverse scenarios. In light of these challenges, we introduce CoMo, a Controllable Motion generation model, adept at accurately generating and editing motions by leveraging the knowledge priors of large language models (LLMs). Specifically, CoMo decomposes motions into discrete and semantically meaningful pose codes, with each code encapsulating the semantics of a body part, representing elementary information such as "left knee slightly bent". Given textual inputs, CoMo autoregressively generates sequences of pose codes, which are then decoded into 3D motions. Leveraging pose codes as interpretable representations, an LLM can directly intervene in motion editing by adjusting the pose codes according to editing instructions. Experiments demonstrate that CoMo achieves competitive performance in motion generation compared to state-of-the-art models while, in human studies, CoMo substantially surpasses previous work in motion editing abilities.
Hyper Strategy Logic
Mar 20, 2024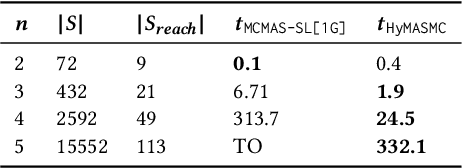
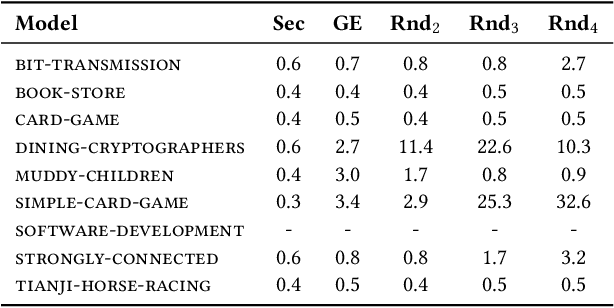

Strategy logic (SL) is a powerful temporal logic that enables strategic reasoning in multi-agent systems. SL supports explicit (first-order) quantification over strategies and provides a logical framework to express many important properties such as Nash equilibria, dominant strategies, etc. While in SL the same strategy can be used in multiple strategy profiles, each such profile is evaluated w.r.t. a path-property, i.e., a property that considers the single path resulting from a particular strategic interaction. In this paper, we present Hyper Strategy Logic (HyperSL), a strategy logic where the outcome of multiple strategy profiles can be compared w.r.t. a hyperproperty, i.e., a property that relates multiple paths. We show that HyperSL can capture important properties that cannot be expressed in SL, including non-interference, quantitative Nash equilibria, optimal adversarial planning, and reasoning under imperfect information. On the algorithmic side, we identify an expressive fragment of HyperSL with decidable model checking and present a model-checking algorithm. We contribute a prototype implementation of our algorithm and report on encouraging experimental results.
What Matters for Active Texture Recognition With Vision-Based Tactile Sensors
Mar 20, 2024
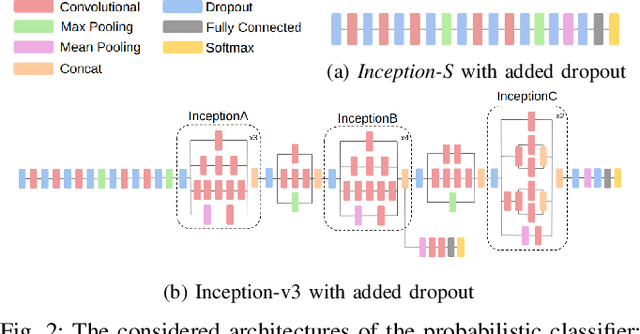
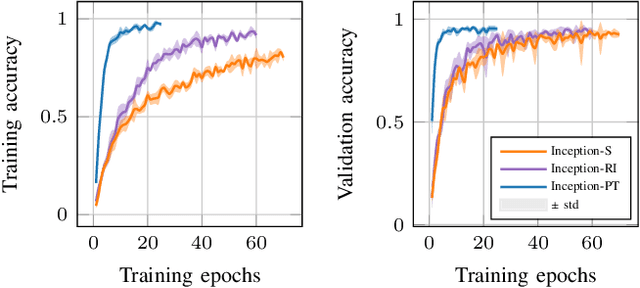
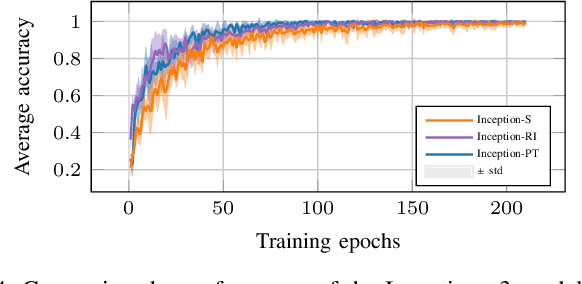
This paper explores active sensing strategies that employ vision-based tactile sensors for robotic perception and classification of fabric textures. We formalize the active sampling problem in the context of tactile fabric recognition and provide an implementation of information-theoretic exploration strategies based on minimizing predictive entropy and variance of probabilistic models. Through ablation studies and human experiments, we investigate which components are crucial for quick and reliable texture recognition. Along with the active sampling strategies, we evaluate neural network architectures, representations of uncertainty, influence of data augmentation, and dataset variability. By evaluating our method on a previously published Active Clothing Perception Dataset and on a real robotic system, we establish that the choice of the active exploration strategy has only a minor influence on the recognition accuracy, whereas data augmentation and dropout rate play a significantly larger role. In a comparison study, while humans achieve 66.9% recognition accuracy, our best approach reaches 90.0% in under 5 touches, highlighting that vision-based tactile sensors are highly effective for fabric texture recognition.
Compress3D: a Compressed Latent Space for 3D Generation from a Single Image
Mar 20, 2024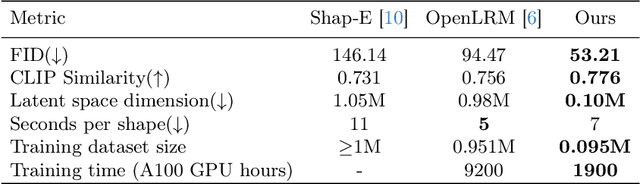
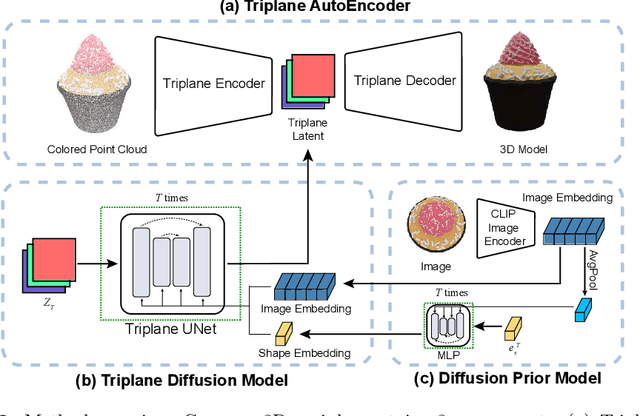

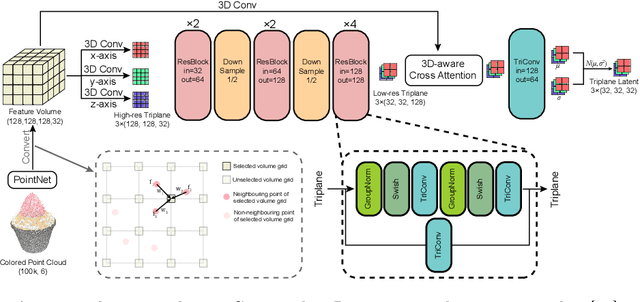
3D generation has witnessed significant advancements, yet efficiently producing high-quality 3D assets from a single image remains challenging. In this paper, we present a triplane autoencoder, which encodes 3D models into a compact triplane latent space to effectively compress both the 3D geometry and texture information. Within the autoencoder framework, we introduce a 3D-aware cross-attention mechanism, which utilizes low-resolution latent representations to query features from a high-resolution 3D feature volume, thereby enhancing the representation capacity of the latent space. Subsequently, we train a diffusion model on this refined latent space. In contrast to solely relying on image embedding for 3D generation, our proposed method advocates for the simultaneous utilization of both image embedding and shape embedding as conditions. Specifically, the shape embedding is estimated via a diffusion prior model conditioned on the image embedding. Through comprehensive experiments, we demonstrate that our method outperforms state-of-the-art algorithms, achieving superior performance while requiring less training data and time. Our approach enables the generation of high-quality 3D assets in merely 7 seconds on a single A100 GPU.
Out-of-Distribution Detection Using Peer-Class Generated by Large Language Model
Mar 20, 2024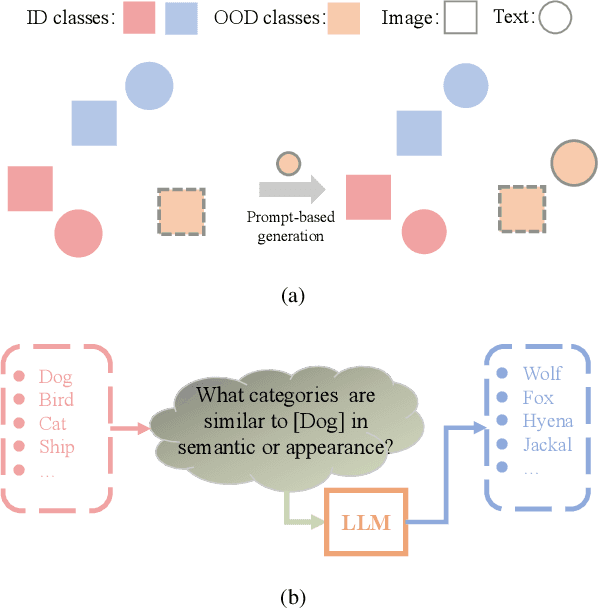
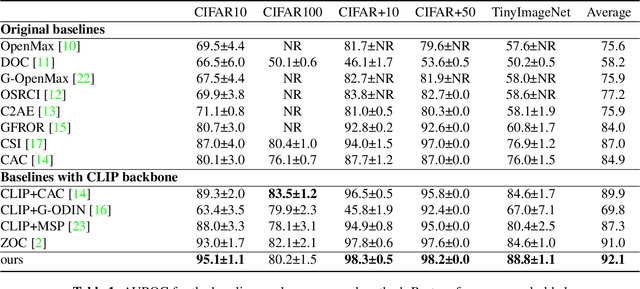
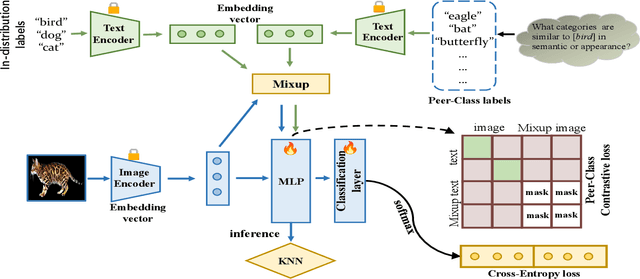

Out-of-distribution (OOD) detection is a critical task to ensure the reliability and security of machine learning models deployed in real-world applications. Conventional methods for OOD detection that rely on single-modal information, often struggle to capture the rich variety of OOD instances. The primary difficulty in OOD detection arises when an input image has numerous similarities to a particular class in the in-distribution (ID) dataset, e.g., wolf to dog, causing the model to misclassify it. Nevertheless, it may be easy to distinguish these classes in the semantic domain. To this end, in this paper, a novel method called ODPC is proposed, in which specific prompts to generate OOD peer classes of ID semantics are designed by a large language model as an auxiliary modality to facilitate detection. Moreover, a contrastive loss based on OOD peer classes is devised to learn compact representations of ID classes and improve the clarity of boundaries between different classes. The extensive experiments on five benchmark datasets show that the method we propose can yield state-of-the-art results.
HyperLLaVA: Dynamic Visual and Language Expert Tuning for Multimodal Large Language Models
Mar 20, 2024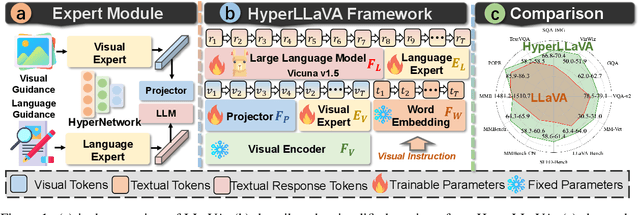
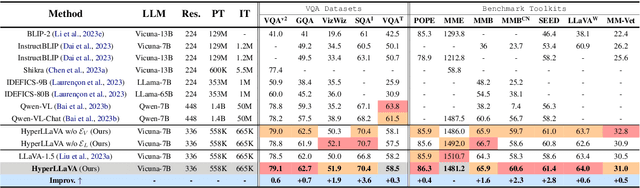
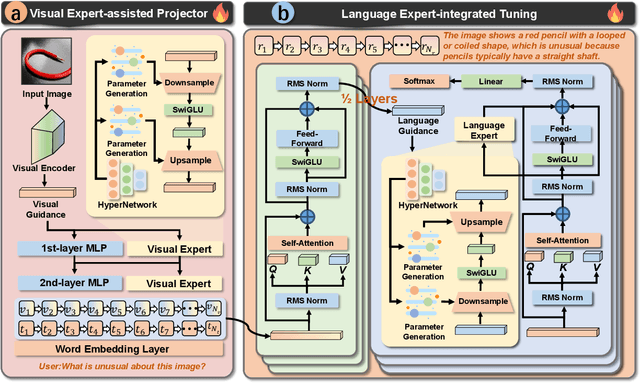
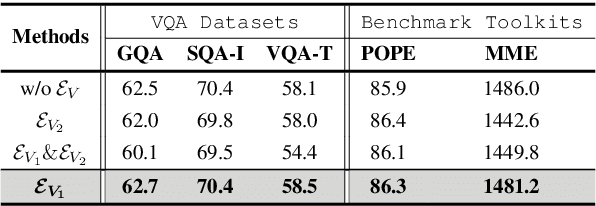
Recent advancements indicate that scaling up Multimodal Large Language Models (MLLMs) effectively enhances performance on downstream multimodal tasks. The prevailing MLLM paradigm, \emph{e.g.}, LLaVA, transforms visual features into text-like tokens using a \emph{static} vision-language mapper, thereby enabling \emph{static} LLMs to develop the capability to comprehend visual information through visual instruction tuning. Although promising, the \emph{static} tuning strategy~\footnote{The static tuning refers to the trained model with static parameters.} that shares the same parameters may constrain performance across different downstream multimodal tasks. In light of this, we introduce HyperLLaVA, which involves adaptive tuning of the projector and LLM parameters, in conjunction with a dynamic visual expert and language expert, respectively. These experts are derived from HyperNetworks, which generates adaptive parameter shifts through visual and language guidance, enabling dynamic projector and LLM modeling in two-stage training. Our experiments demonstrate that our solution significantly surpasses LLaVA on existing MLLM benchmarks, including MME, MMBench, SEED-Bench, and LLaVA-Bench. ~\footnote{Our project is available on the link https://github.com/DCDmllm/HyperLLaVA}.
MIMO Channel as a Neural Function: Implicit Neural Representations for Extreme CSI Compression in Massive MIMO Systems
Mar 20, 2024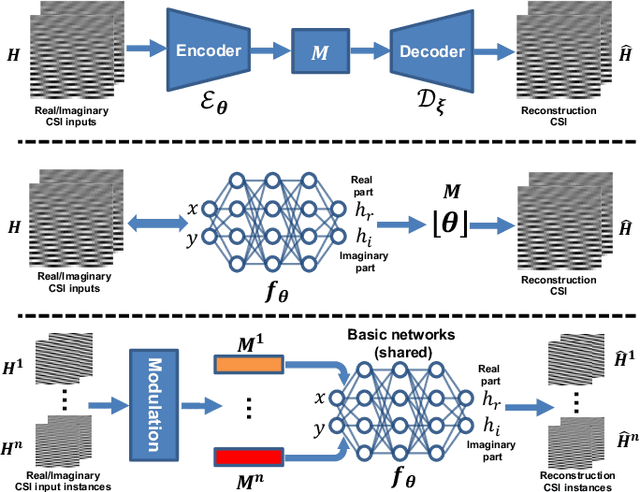
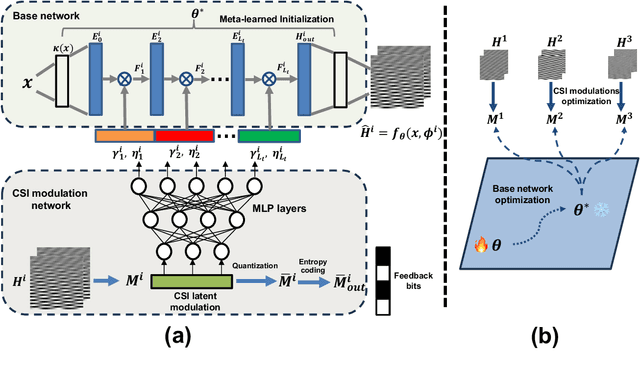
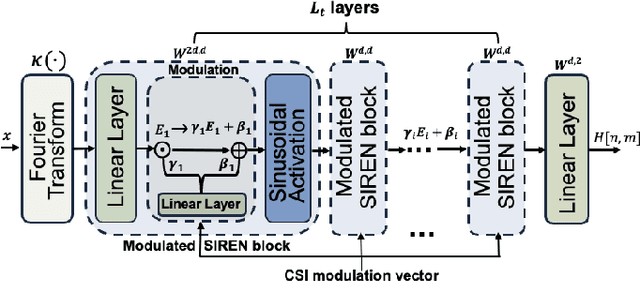
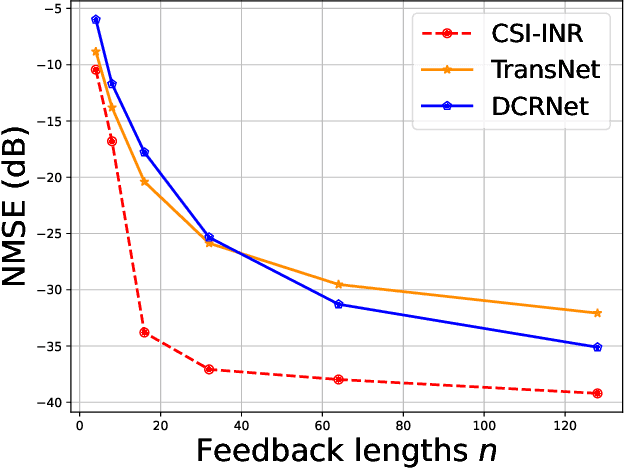
Acquiring and utilizing accurate channel state information (CSI) can significantly improve transmission performance, thereby holding a crucial role in realizing the potential advantages of massive multiple-input multiple-output (MIMO) technology. Current prevailing CSI feedback approaches improve precision by employing advanced deep-learning methods to learn representative CSI features for a subsequent compression process. Diverging from previous works, we treat the CSI compression problem in the context of implicit neural representations. Specifically, each CSI matrix is viewed as a neural function that maps the CSI coordinates (antenna number and subchannel) to the corresponding channel gains. Instead of transmitting the parameters of the implicit neural functions directly, we transmit modulations based on the CSI matrix derived through a meta-learning algorithm. Modulations are then applied to a shared base network to generate the elements of the CSI matrix. Modulations corresponding to the CSI matrix are quantized and entropy-coded to further reduce the communication bandwidth, thus achieving extreme CSI compression ratios. Numerical results show that our proposed approach achieves state-of-the-art performance and showcases flexibility in feedback strategies.