 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
HGWaveNet: A Hyperbolic Graph Neural Network for Temporal Link Prediction
Apr 14, 2023
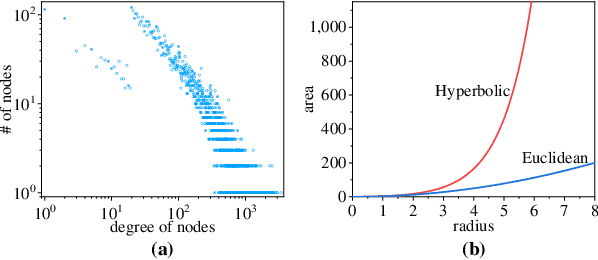
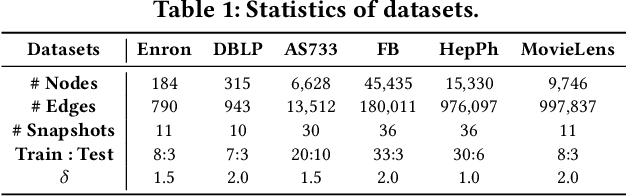
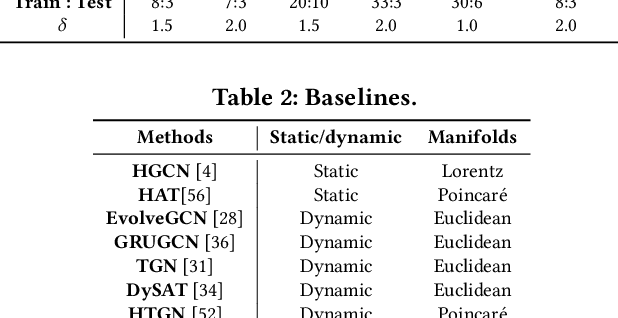
Temporal link prediction, aiming to predict future edges between paired nodes in a dynamic graph, is of vital importance in diverse applications. However, existing methods are mainly built upon uniform Euclidean space, which has been found to be conflict with the power-law distributions of real-world graphs and unable to represent the hierarchical connections between nodes effectively. With respect to the special data characteristic, hyperbolic geometry offers an ideal alternative due to its exponential expansion property. In this paper, we propose HGWaveNet, a novel hyperbolic graph neural network that fully exploits the fitness between hyperbolic spaces and data distributions for temporal link prediction. Specifically, we design two key modules to learn the spatial topological structures and temporal evolutionary information separately. On the one hand, a hyperbolic diffusion graph convolution (HDGC) module effectively aggregates information from a wider range of neighbors. On the other hand, the internal order of causal correlation between historical states is captured by hyperbolic dilated causal convolution (HDCC) modules. The whole model is built upon the hyperbolic spaces to preserve the hierarchical structural information in the entire data flow. To prove the superiority of HGWaveNet, extensive experiments are conducted on six real-world graph datasets and the results show a relative improvement by up to 6.67% on AUC for temporal link prediction over SOTA methods.
ViT-Calibrator: Decision Stream Calibration for Vision Transformer
May 05, 2023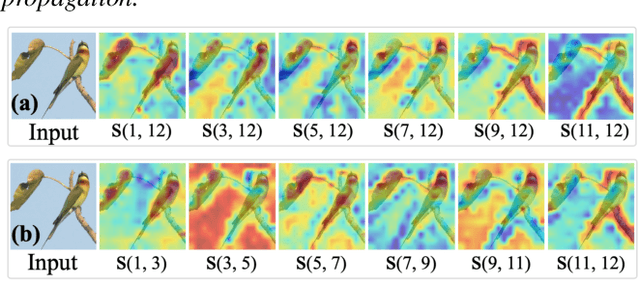
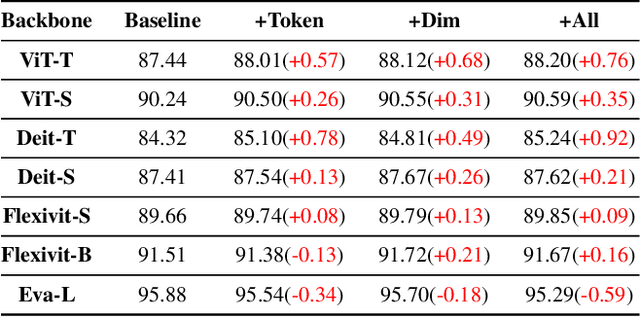
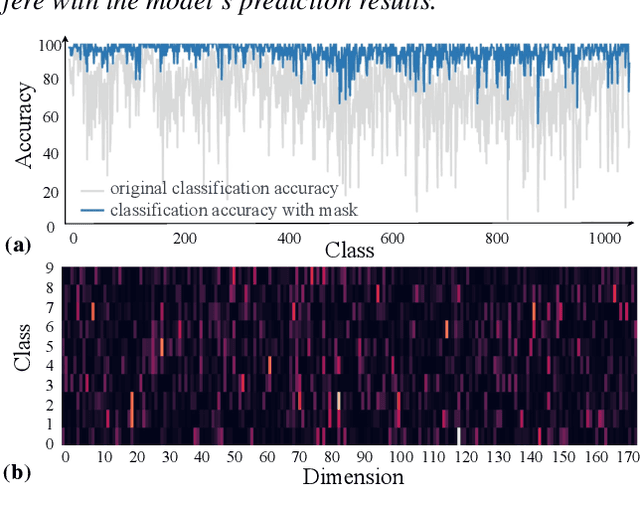
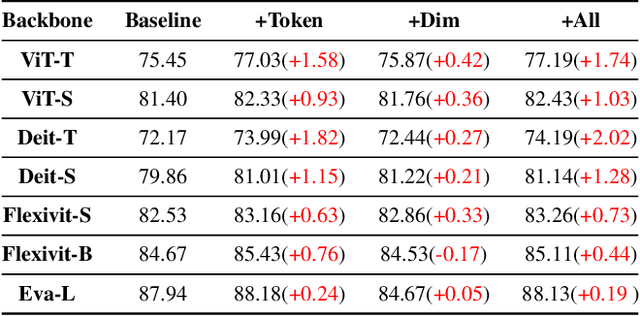
A surge of interest has emerged in utilizing Transformers in diverse vision tasks owing to its formidable performance. However, existing approaches primarily focus on optimizing internal model architecture designs that often entail significant trial and error with high burdens. In this work, we propose a new paradigm dubbed Decision Stream Calibration that boosts the performance of general Vision Transformers. To achieve this, we shed light on the information propagation mechanism in the learning procedure by exploring the correlation between different tokens and the relevance coefficient of multiple dimensions. Upon further analysis, it was discovered that 1) the final decision is associated with tokens of foreground targets, while token features of foreground target will be transmitted into the next layer as much as possible, and the useless token features of background area will be eliminated gradually in the forward propagation. 2) Each category is solely associated with specific sparse dimensions in the tokens. Based on the discoveries mentioned above, we designed a two-stage calibration scheme, namely ViT-Calibrator, including token propagation calibration stage and dimension propagation calibration stage. Extensive experiments on commonly used datasets show that the proposed approach can achieve promising results. The source codes are given in the supplements.
Evading Watermark based Detection of AI-Generated Content
May 05, 2023
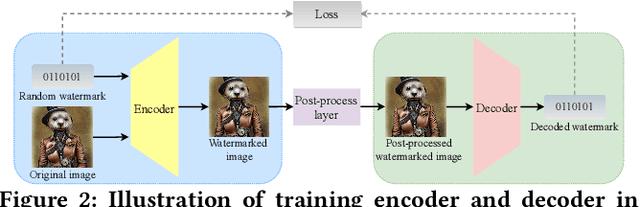
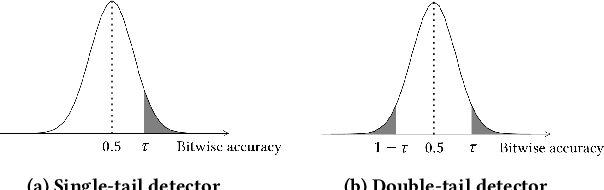
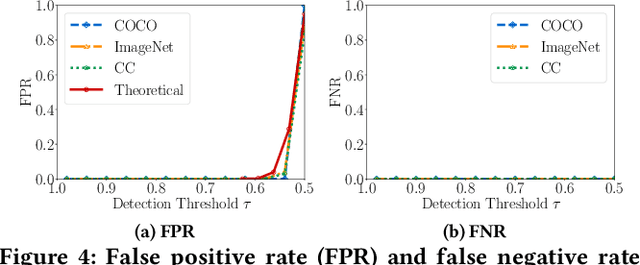
A generative AI model -- such as DALL-E, Stable Diffusion, and ChatGPT -- can generate extremely realistic-looking content, posing growing challenges to the authenticity of information. To address the challenges, watermark has been leveraged to detect AI-generated content. Specifically, a watermark is embedded into an AI-generated content before it is released. A content is detected as AI-generated if a similar watermark can be decoded from it. In this work, we perform a systematic study on the robustness of such watermark-based AI-generated content detection. We focus on AI-generated images. Our work shows that an attacker can post-process an AI-generated watermarked image via adding a small, human-imperceptible perturbation to it, such that the post-processed AI-generated image evades detection while maintaining its visual quality. We demonstrate the effectiveness of our attack both theoretically and empirically. Moreover, to evade detection, our adversarial post-processing method adds much smaller perturbations to the AI-generated images and thus better maintain their visual quality than existing popular image post-processing methods such as JPEG compression, Gaussian blur, and Brightness/Contrast. Our work demonstrates the insufficiency of existing watermark-based detection of AI-generated content, highlighting the urgent needs of new detection methods.
A Large Cross-Modal Video Retrieval Dataset with Reading Comprehension
May 05, 2023
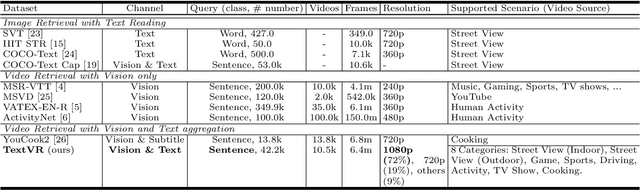
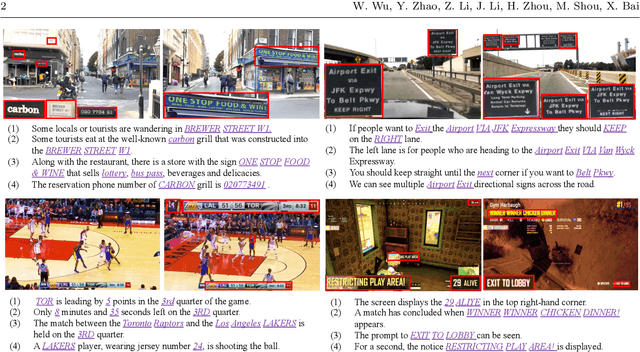
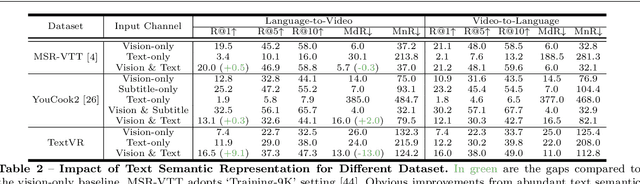
Most existing cross-modal language-to-video retrieval (VR) research focuses on single-modal input from video, i.e., visual representation, while the text is omnipresent in human environments and frequently critical to understand video. To study how to retrieve video with both modal inputs, i.e., visual and text semantic representations, we first introduce a large-scale and cross-modal Video Retrieval dataset with text reading comprehension, TextVR, which contains 42.2k sentence queries for 10.5k videos of 8 scenario domains, i.e., Street View (indoor), Street View (outdoor), Games, Sports, Driving, Activity, TV Show, and Cooking. The proposed TextVR requires one unified cross-modal model to recognize and comprehend texts, relate them to the visual context, and decide what text semantic information is vital for the video retrieval task. Besides, we present a detailed analysis of TextVR compared to the existing datasets and design a novel multimodal video retrieval baseline for the text-based video retrieval task. The dataset analysis and extensive experiments show that our TextVR benchmark provides many new technical challenges and insights from previous datasets for the video-and-language community. The project website and GitHub repo can be found at https://sites.google.com/view/loveucvpr23/guest-track and https://github.com/callsys/TextVR, respectively.
Towards Applying Powerful Large AI Models in Classroom Teaching: Opportunities, Challenges and Prospects
May 05, 2023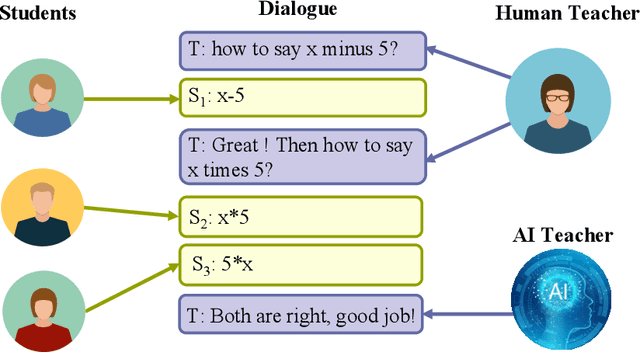
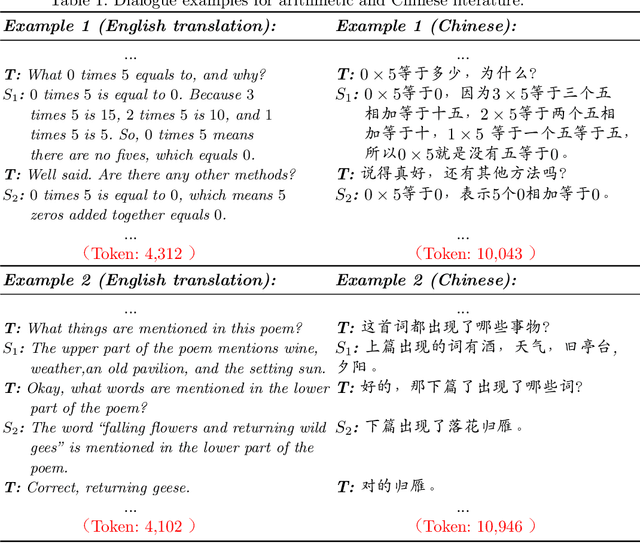
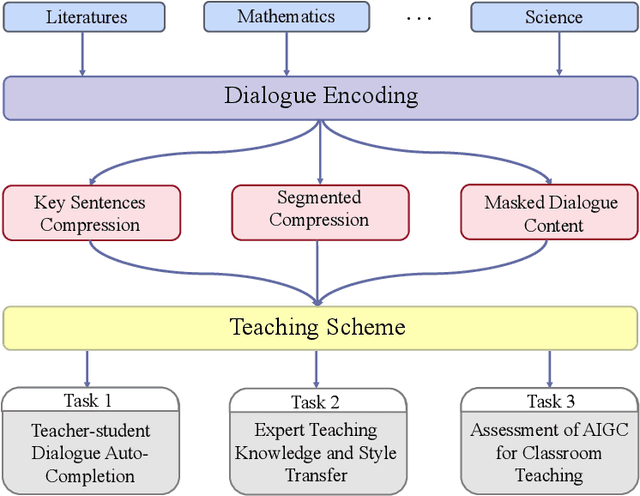
This perspective paper proposes a series of interactive scenarios that utilize Artificial Intelligence (AI) to enhance classroom teaching, such as dialogue auto-completion, knowledge and style transfer, and assessment of AI-generated content. By leveraging recent developments in Large Language Models (LLMs), we explore the potential of AI to augment and enrich teacher-student dialogues and improve the quality of teaching. Our goal is to produce innovative and meaningful conversations between teachers and students, create standards for evaluation, and improve the efficacy of AI-for-Education initiatives. In Section 3, we discuss the challenges of utilizing existing LLMs to effectively complete the educated tasks and present a unified framework for addressing diverse education dataset, processing lengthy conversations, and condensing information to better accomplish more downstream tasks. In Section 4, we summarize the pivoting tasks including Teacher-Student Dialogue Auto-Completion, Expert Teaching Knowledge and Style Transfer, and Assessment of AI-Generated Content (AIGC), providing a clear path for future research. In Section 5, we also explore the use of external and adjustable LLMs to improve the generated content through human-in-the-loop supervision and reinforcement learning. Ultimately, this paper seeks to highlight the potential for AI to aid the field of education and promote its further exploration.
LOGO-Former: Local-Global Spatio-Temporal Transformer for Dynamic Facial Expression Recognition
May 05, 2023
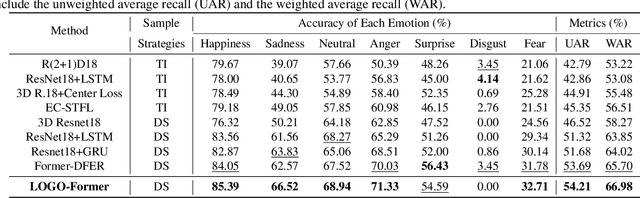
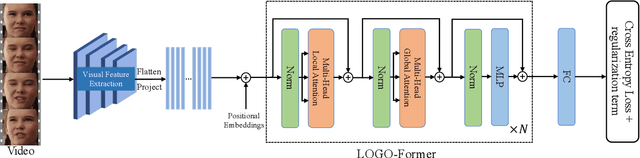
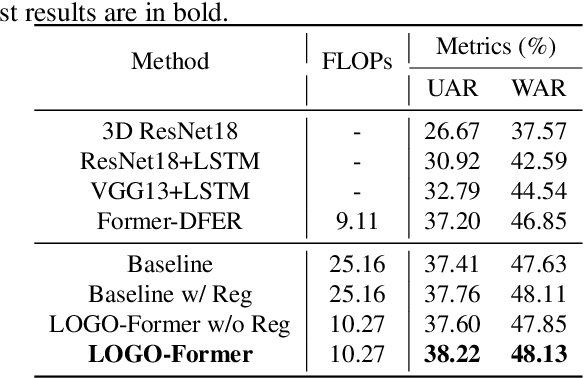
Previous methods for dynamic facial expression recognition (DFER) in the wild are mainly based on Convolutional Neural Networks (CNNs), whose local operations ignore the long-range dependencies in videos. Transformer-based methods for DFER can achieve better performances but result in higher FLOPs and computational costs. To solve these problems, the local-global spatio-temporal Transformer (LOGO-Former) is proposed to capture discriminative features within each frame and model contextual relationships among frames while balancing the complexity. Based on the priors that facial muscles move locally and facial expressions gradually change, we first restrict both the space attention and the time attention to a local window to capture local interactions among feature tokens. Furthermore, we perform the global attention by querying a token with features from each local window iteratively to obtain long-range information of the whole video sequence. In addition, we propose the compact loss regularization term to further encourage the learned features have the minimum intra-class distance and the maximum inter-class distance. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39K) indicate that our method provides an effective way to make use of the spatial and temporal dependencies for DFER.
Towards the Neuromorphic Computing for Offroad Robot Environment Perception and Navigation
May 05, 2023My research objective is to explicitly bridge the gap between high computational performance and low power dissipation of robot on-board hardware by designing a bio-inspired tapered whisker neuromorphic computing (also called reservoir computing) system for offroad robot environment perception and navigation, that centres the interaction between a robot's body and its environment. Mobile robots performing tasks in unknown environments need to traverse a variety of complex terrains, and they must be able to reliably and quickly identify and characterize these terrains to avoid getting into potentially challenging or catastrophic circumstances. To solve this problem, I drew inspiration from animals like rats and seals, just relying on whiskers to perceive surroundings information and survive in dark and narrow environments. Additionally, I looked to the human cochlear which can separate different frequencies of sound. Based on these insights, my work addresses this need by exploring the physical whisker-based reservoir computing for quick and cost-efficient mobile robots environment perception and navigation step by step. This research could help us understand how the compliance of the biological counterparts helps robots to dynamically interact with the environment and provides a new solution compared with current methods for robot environment perception and navigation with limited computational resources, such as Mars.
Leveraging Deep Learning Techniques on Collaborative Filtering Recommender Systems
Apr 18, 2023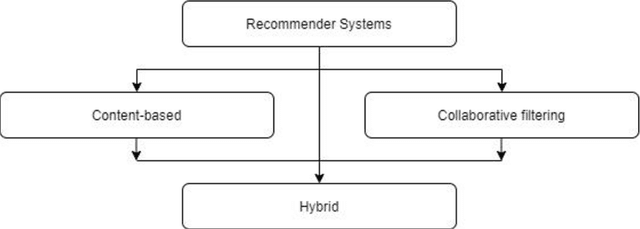


With the exponentially increasing volume of online data, searching and finding required information have become an extensive and time-consuming task. Recommender Systems as a subclass of information retrieval and decision support systems by providing personalized suggestions helping users access what they need more efficiently. Among the different techniques for building a recommender system, Collaborative Filtering (CF) is the most popular and widespread approach. However, cold start and data sparsity are the fundamental challenges ahead of implementing an effective CF-based recommender. Recent successful developments in enhancing and implementing deep learning architectures motivated many studies to propose deep learning-based solutions for solving the recommenders' weak points. In this research, unlike the past similar works about using deep learning architectures in recommender systems that covered different techniques generally, we specifically provide a comprehensive review of deep learning-based collaborative filtering recommender systems. This in-depth filtering gives a clear overview of the level of popularity, gaps, and ignored areas on leveraging deep learning techniques to build CF-based systems as the most influential recommenders.
Look ATME: The Discriminator Mean Entropy Needs Attention
Apr 18, 2023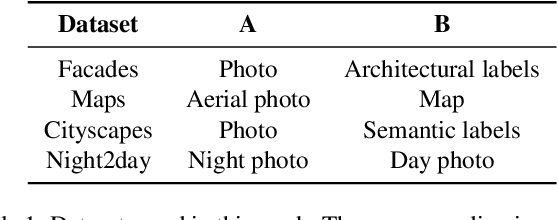
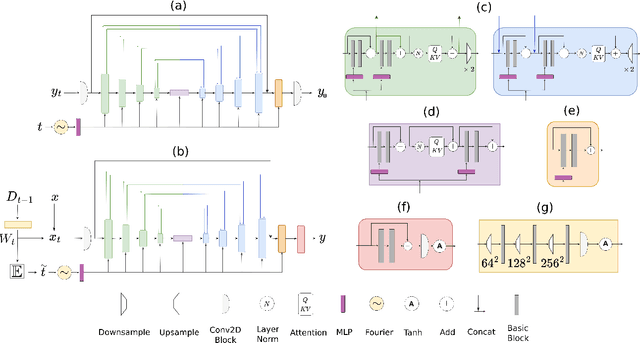

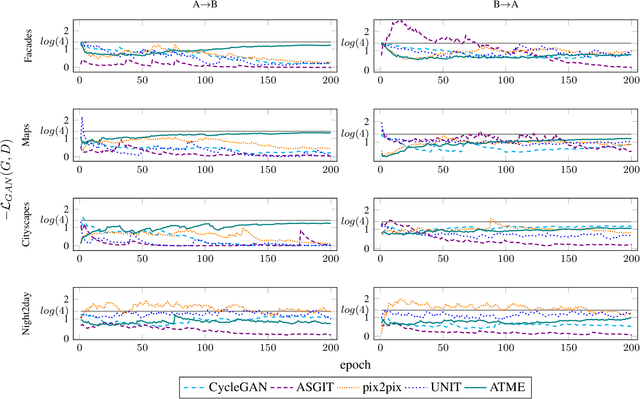
Generative adversarial networks (GANs) are successfully used for image synthesis but are known to face instability during training. In contrast, probabilistic diffusion models (DMs) are stable and generate high-quality images, at the cost of an expensive sampling procedure. In this paper, we introduce a simple method to allow GANs to stably converge to their theoretical optimum, while bringing in the denoising machinery from DMs. These models are combined into a simpler model (ATME) that only requires a forward pass during inference, making predictions cheaper and more accurate than DMs and popular GANs. ATME breaks an information asymmetry existing in most GAN models in which the discriminator has spatial knowledge of where the generator is failing. To restore the information symmetry, the generator is endowed with knowledge of the entropic state of the discriminator, which is leveraged to allow the adversarial game to converge towards equilibrium. We demonstrate the power of our method in several image-to-image translation tasks, showing superior performance than state-of-the-art methods at a lesser cost. Code is available at https://github.com/DLR-MI/atme
Attributed Multi-order Graph Convolutional Network for Heterogeneous Graphs
Apr 18, 2023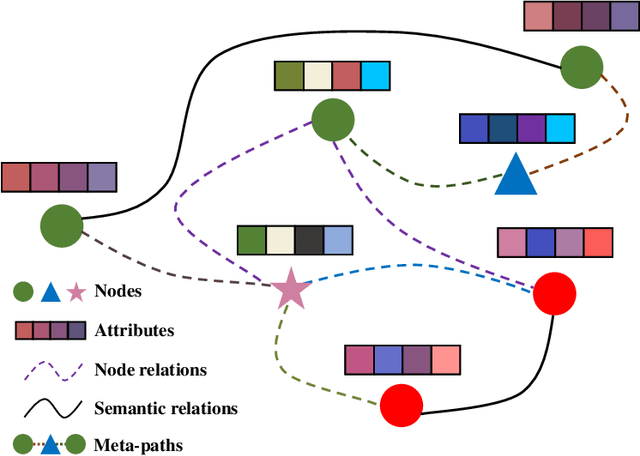
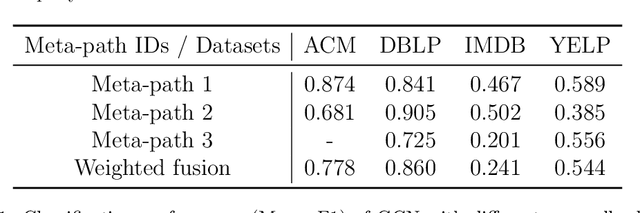
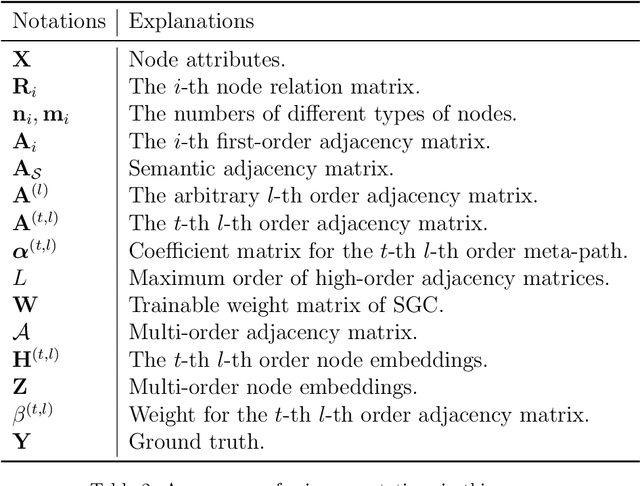
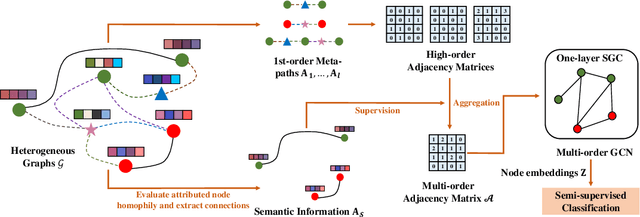
Heterogeneous graph neural networks aim to discover discriminative node embeddings and relations from multi-relational networks.One challenge of heterogeneous graph learning is the design of learnable meta-paths, which significantly influences the quality of learned embeddings.Thus, in this paper, we propose an Attributed Multi-Order Graph Convolutional Network (AMOGCN), which automatically studies meta-paths containing multi-hop neighbors from an adaptive aggregation of multi-order adjacency matrices. The proposed model first builds different orders of adjacency matrices from manually designed node connections. After that, an intact multi-order adjacency matrix is attached from the automatic fusion of various orders of adjacency matrices. This process is supervised by the node semantic information, which is extracted from the node homophily evaluated by attributes. Eventually, we utilize a one-layer simplifying graph convolutional network with the learned multi-order adjacency matrix, which is equivalent to the cross-hop node information propagation with multi-layer graph neural networks. Substantial experiments reveal that AMOGCN gains superior semi-supervised classification performance compared with state-of-the-art competitors.