 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrated Sensing and Communications: Recent Advances and Ten Open Challenges
Apr 29, 2023
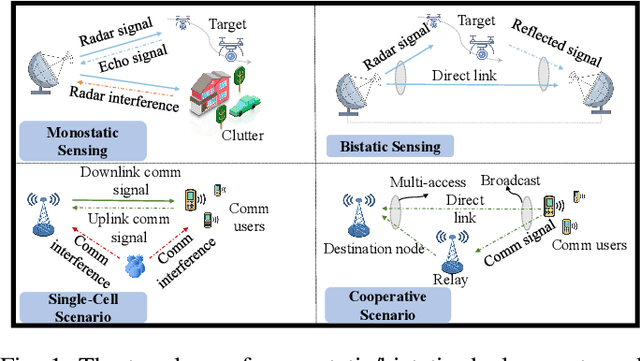
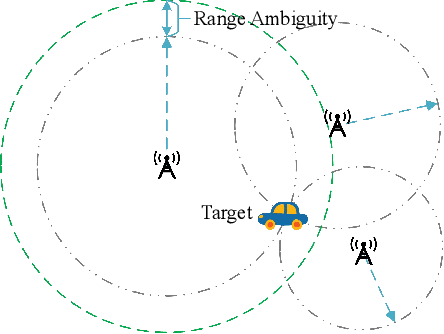
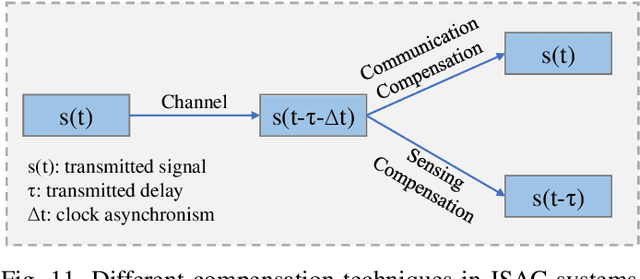
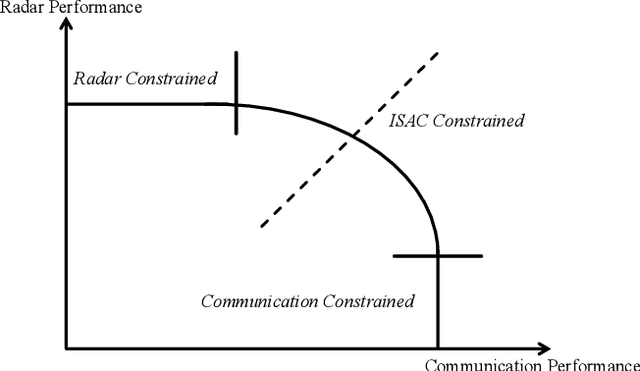
It is anticipated that integrated sensing and communications (ISAC) would be one of the key enablers of next-generation wireless networks (such as beyond 5G (B5G) and 6G) for supporting a variety of emerging applications. In this paper, we provide a comprehensive review of the recent advances in ISAC systems, with a particular focus on their foundations, system design, networking aspects and ISAC applications. Furthermore, we discuss the corresponding open questions of the above that emerged in each issue. Hence, we commence with the information theory of sensing and communications (S$\&$C), followed by the information-theoretic limits of ISAC systems by shedding light on the fundamental performance metrics. Next, we discuss their clock synchronization and phase offset problems, the associated Pareto-optimal signaling strategies, as well as the associated super-resolution ISAC system design. Moreover, we envision that ISAC ushers in a paradigm shift for the future cellular networks relying on network sensing, transforming the classic cellular architecture, cross-layer resource management methods, and transmission protocols. In ISAC applications, we further highlight the security and privacy issues of wireless sensing. Finally, we close by studying the recent advances in a representative ISAC use case, namely the multi-object multi-task (MOMT) recognition problem using wireless signals.
Probabilistic Contact State Estimation for Legged Robots using Inertial Information
Mar 04, 2023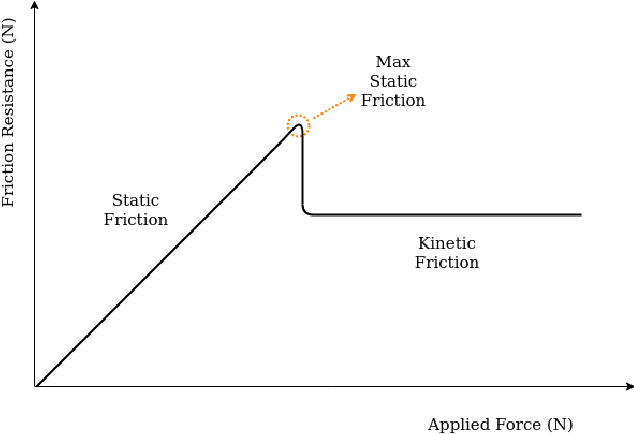
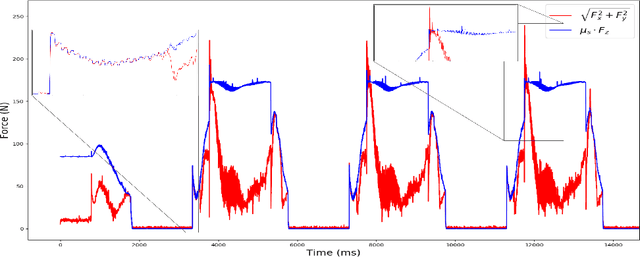
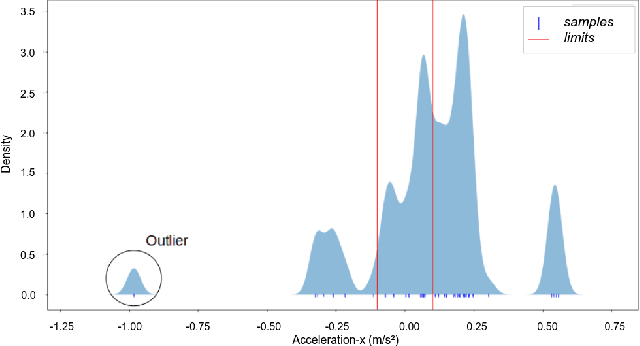
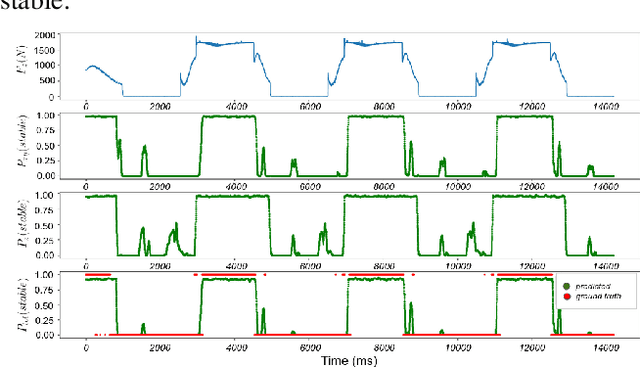
Legged robot navigation in unstructured and slippery terrains depends heavily on the ability to accurately identify the quality of contact between the robot's feet and the ground. Contact state estimation is regarded as a challenging problem and is typically addressed by exploiting force measurements, joint encoders and/or robot kinematics and dynamics. In contrast to most state of the art approaches, the current work introduces a novel probabilistic method for estimating the contact state based solely on proprioceptive sensing, as it is readily available by Inertial Measurement Units (IMUs) mounted on the robot's end effectors. Capitalizing on the uncertainty of IMU measurements, our method estimates the probability of stable contact. This is accomplished by approximating the multimodal probability density function over a batch of data points for each axis of the IMU with Kernel Density Estimation. The proposed method has been extensively assessed against both real and simulated scenarios on bipedal and quadrupedal robotic platforms such as ATLAS, TALOS and Unitree's GO1.
Patch-DrosoNet: Classifying Image Partitions With Fly-Inspired Models For Lightweight Visual Place Recognition
May 09, 2023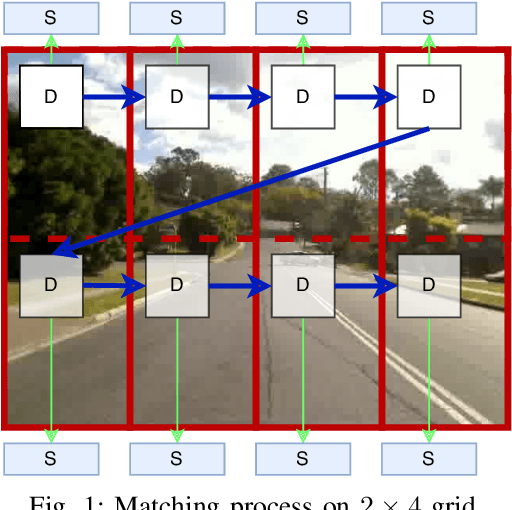
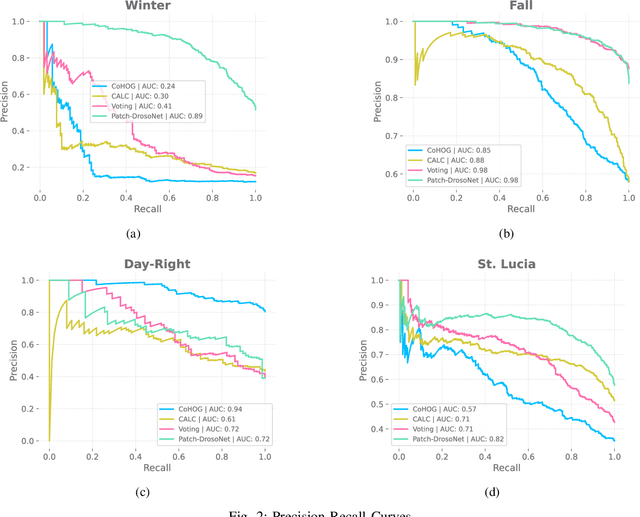
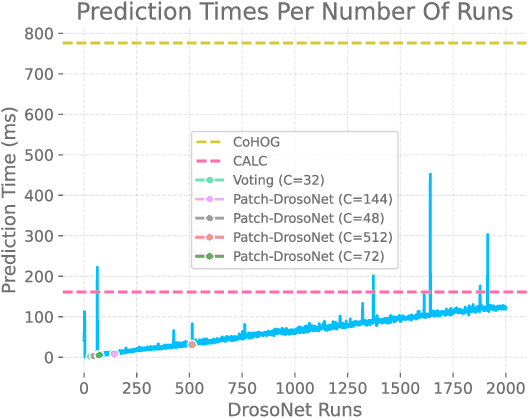
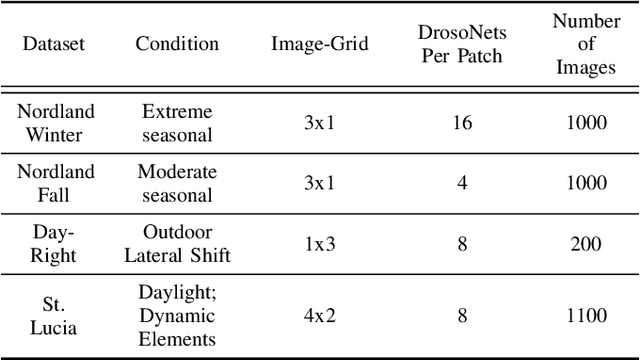
Visual place recognition (VPR) enables autonomous systems to localize themselves within an environment using image information. While Convolution Neural Networks (CNNs) currently dominate state-of-the-art VPR performance, their high computational requirements make them unsuitable for platforms with budget or size constraints. This has spurred the development of lightweight algorithms, such as DrosoNet, which employs a voting system based on multiple bio-inspired units. In this paper, we present a novel training approach for DrosoNet, wherein separate models are trained on distinct regions of a reference image, allowing them to specialize in the visual features of that specific section. Additionally, we introduce a convolutional-like prediction method, in which each DrosoNet unit generates a set of place predictions for each portion of the query image. These predictions are then combined using the previously introduced voting system. Our approach significantly improves upon the VPR performance of previous work while maintaining an extremely compact and lightweight algorithm, making it suitable for resource-constrained platforms.
Detection of depression on social networks using transformers and ensembles
May 09, 2023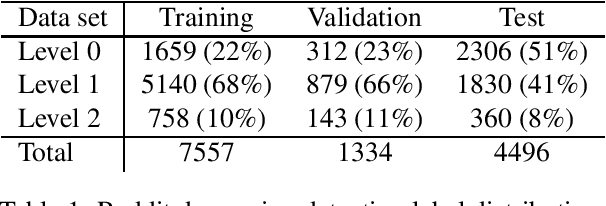
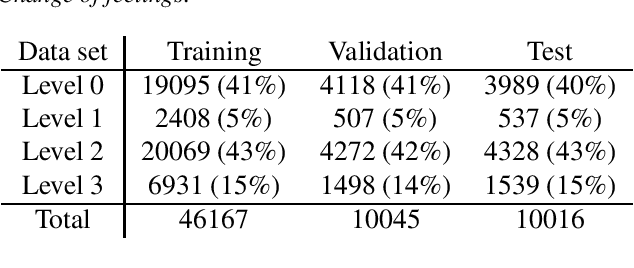
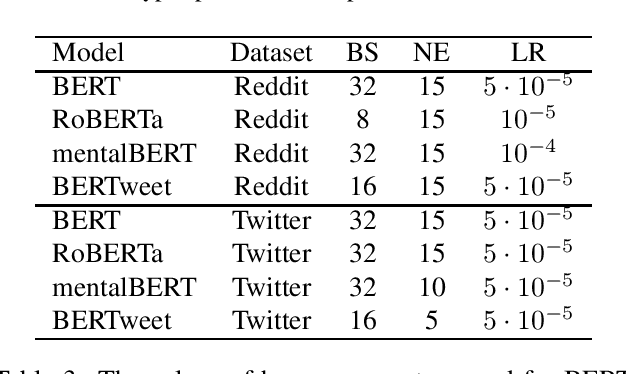
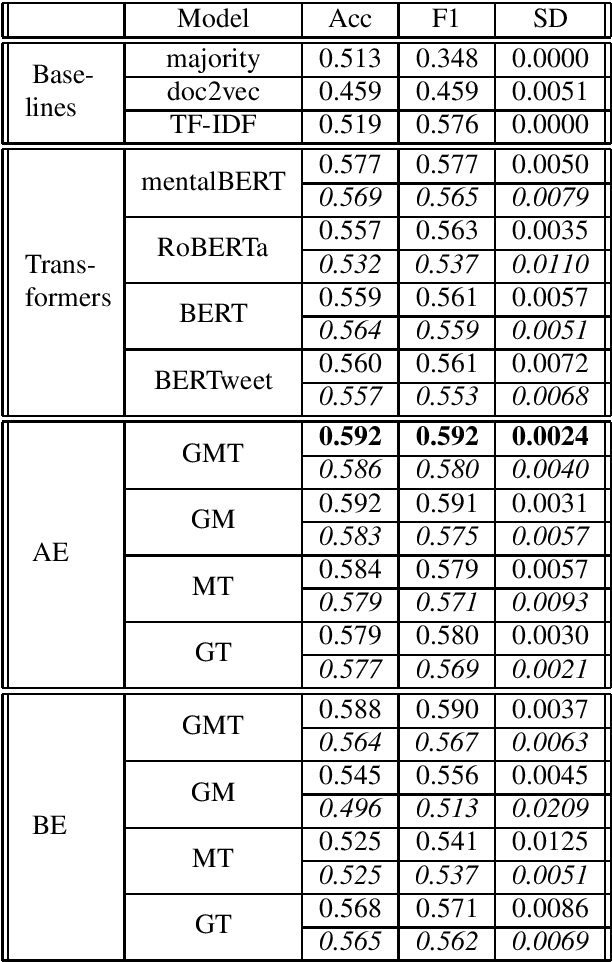
As the impact of technology on our lives is increasing, we witness increased use of social media that became an essential tool not only for communication but also for sharing information with community about our thoughts and feelings. This can be observed also for people with mental health disorders such as depression where they use social media for expressing their thoughts and asking for help. This opens a possibility to automatically process social media posts and detect signs of depression. We build several large pre-trained language model based classifiers for depression detection from social media posts. Besides fine-tuning BERT, RoBERTA, BERTweet, and mentalBERT were also construct two types of ensembles. We analyze the performance of our models on two data sets of posts from social platforms Reddit and Twitter, and investigate also the performance of transfer learning across the two data sets. The results show that transformer ensembles improve over the single transformer-based classifiers.
Causalainer: Causal Explainer for Automatic Video Summarization
Apr 30, 2023
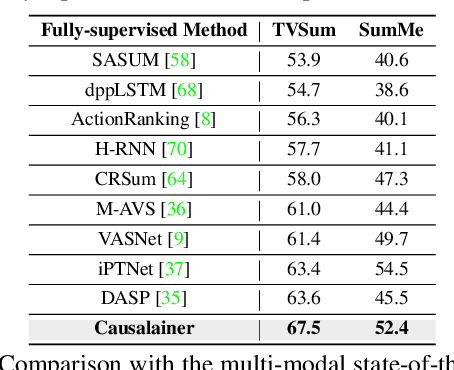
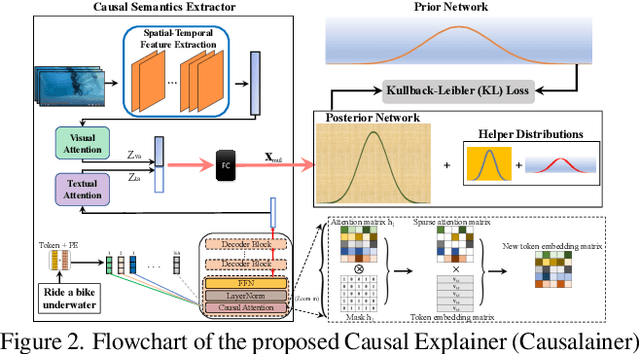
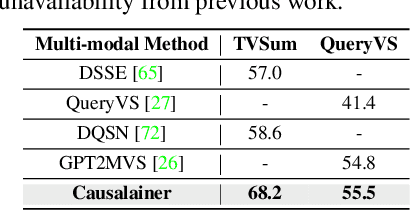
The goal of video summarization is to automatically shorten videos such that it conveys the overall story without losing relevant information. In many application scenarios, improper video summarization can have a large impact. For example in forensics, the quality of the generated video summary will affect an investigator's judgment while in journalism it might yield undesired bias. Because of this, modeling explainability is a key concern. One of the best ways to address the explainability challenge is to uncover the causal relations that steer the process and lead to the result. Current machine learning-based video summarization algorithms learn optimal parameters but do not uncover causal relationships. Hence, they suffer from a relative lack of explainability. In this work, a Causal Explainer, dubbed Causalainer, is proposed to address this issue. Multiple meaningful random variables and their joint distributions are introduced to characterize the behaviors of key components in the problem of video summarization. In addition, helper distributions are introduced to enhance the effectiveness of model training. In visual-textual input scenarios, the extra input can decrease the model performance. A causal semantics extractor is designed to tackle this issue by effectively distilling the mutual information from the visual and textual inputs. Experimental results on commonly used benchmarks demonstrate that the proposed method achieves state-of-the-art performance while being more explainable.
"Can't Take the Pressure?": Examining the Challenges of Blood Pressure Estimation via Pulse Wave Analysis
Apr 23, 2023
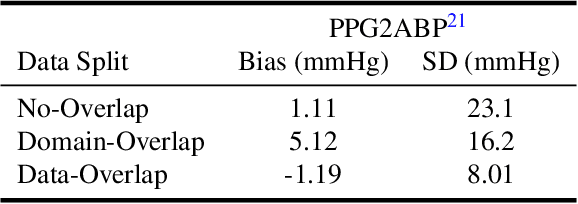


The use of observed wearable sensor data (e.g., photoplethysmograms [PPG]) to infer health measures (e.g., glucose level or blood pressure) is a very active area of research. Such technology can have a significant impact on health screening, chronic disease management and remote monitoring. A common approach is to collect sensor data and corresponding labels from a clinical grade device (e.g., blood pressure cuff), and train deep learning models to map one to the other. Although well intentioned, this approach often ignores a principled analysis of whether the input sensor data has enough information to predict the desired metric. We analyze the task of predicting blood pressure from PPG pulse wave analysis. Our review of the prior work reveals that many papers fall prey data leakage, and unrealistic constraints on the task and the preprocessing steps. We propose a set of tools to help determine if the input signal in question (e.g., PPG) is indeed a good predictor of the desired label (e.g., blood pressure). Using our proposed tools, we have found that blood pressure prediction using PPG has a high multi-valued mapping factor of 33.2% and low mutual information of 9.8%. In comparison, heart rate prediction using PPG, a well-established task, has a very low multi-valued mapping factor of 0.75% and high mutual information of 87.7%. We argue that these results provide a more realistic representation of the current progress towards to goal of wearable blood pressure measurement via PPG pulse wave analysis.
Energy-Efficient Lane Changes Planning and Control for Connected Autonomous Vehicles on Urban Roads
Apr 17, 2023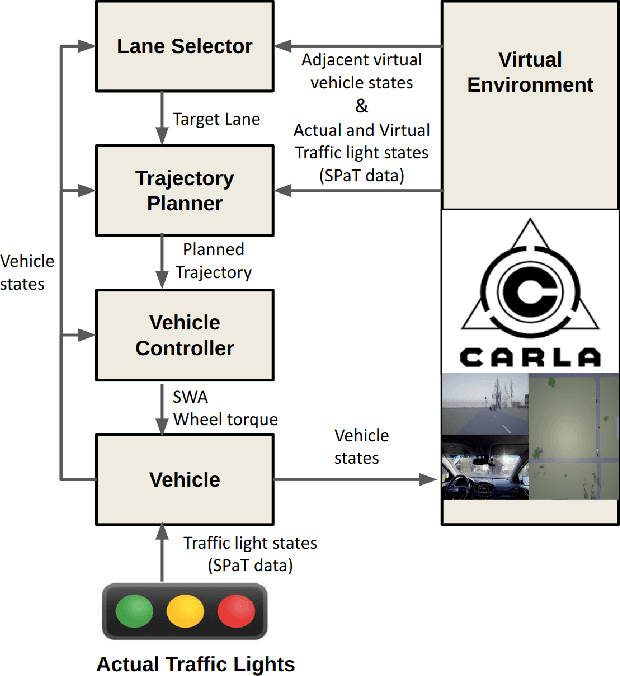
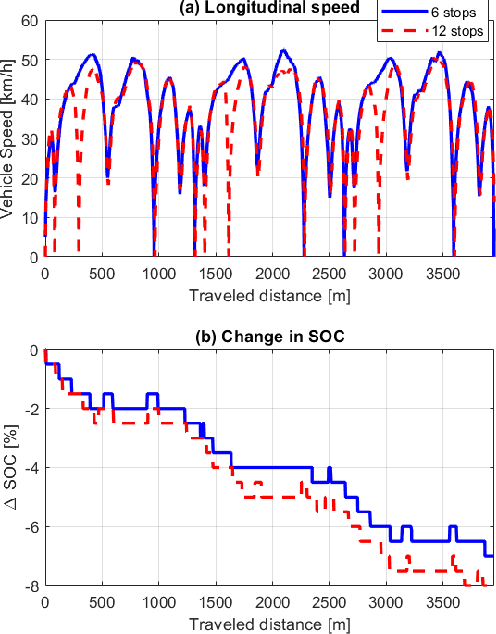
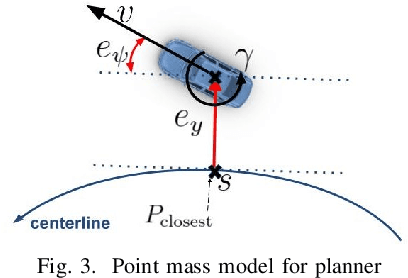
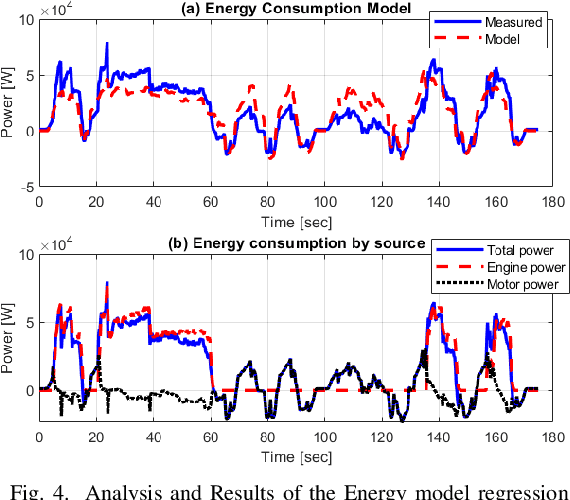
This paper presents a novel energy-efficient motion planning algorithm for Connected Autonomous Vehicles (CAVs) on urban roads. The approach consists of two components: a decision-making algorithm and an optimization-based trajectory planner. The decision-making algorithm leverages Signal Phase and Timing (SPaT) information from connected traffic lights to select a lane with the aim of reducing energy consumption. The algorithm is based on a heuristic rule which is learned from human driving data. The optimization-based trajectory planner generates a safe, smooth, and energy-efficient trajectory toward the selected lane. The proposed strategy is experimentally evaluated in a Vehicle-in-the-Loop (VIL) setting, where a real test vehicle receives SPaT information from both actual and virtual traffic lights and autonomously drives on a testing site, while the surrounding vehicles are simulated. The results demonstrate that the use of SPaT information in autonomous driving leads to improved energy efficiency, with the proposed strategy saving 37.1% energy consumption compared to a lane-keeping algorithm.
Constructing a Knowledge Graph from Textual Descriptions of Software Vulnerabilities in the National Vulnerability Database
Apr 30, 2023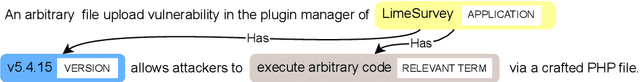
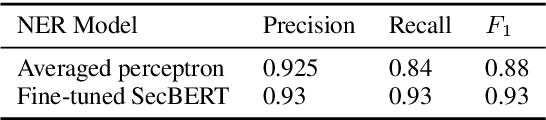

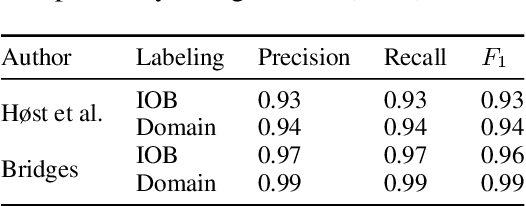
Knowledge graphs have shown promise for several cybersecurity tasks, such as vulnerability assessment and threat analysis. In this work, we present a new method for constructing a vulnerability knowledge graph from information in the National Vulnerability Database (NVD). Our approach combines named entity recognition (NER), relation extraction (RE), and entity prediction using a combination of neural models, heuristic rules, and knowledge graph embeddings. We demonstrate how our method helps to fix missing entities in knowledge graphs used for cybersecurity and evaluate the performance.
ProgSG: Cross-Modality Representation Learning for Programs in Electronic Design Automation
May 18, 2023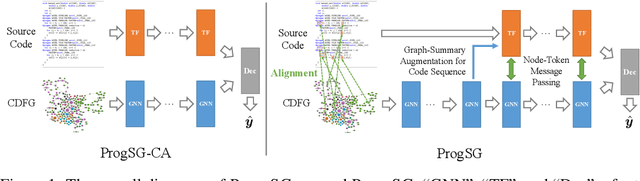
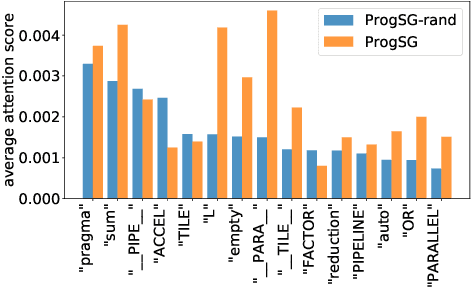
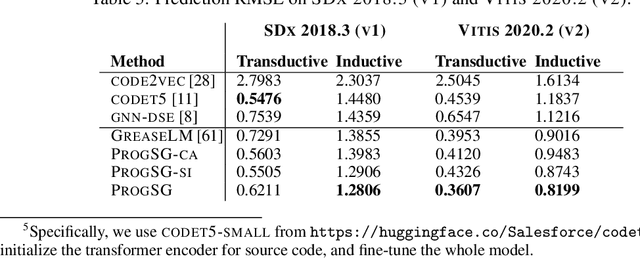
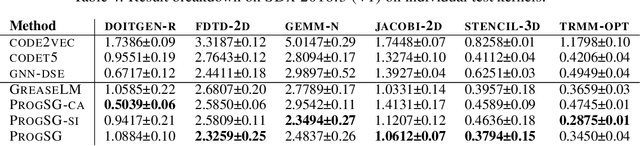
Recent years have witnessed the growing popularity of domain-specific accelerators (DSAs), such as Google's TPUs, for accelerating various applications such as deep learning, search, autonomous driving, etc. To facilitate DSA designs, high-level synthesis (HLS) is used, which allows a developer to compile a high-level description in the form of software code in C and C++ into a design in low-level hardware description languages (such as VHDL or Verilog) and eventually synthesized into a DSA on an ASIC (application-specific integrated circuit) or FPGA (field-programmable gate arrays). However, existing HLS tools still require microarchitecture decisions, expressed in terms of pragmas (such as directives for parallelization and pipelining). To enable more people to design DSAs, it is desirable to automate such decisions with the help of deep learning for predicting the quality of HLS designs. This requires us a deeper understanding of the program, which is a combination of original code and pragmas. Naturally, these programs can be considered as sequence data, for which large language models (LLM) can help. In addition, these programs can be compiled and converted into a control data flow graph (CDFG), and the compiler also provides fine-grained alignment between the code tokens and the CDFG nodes. However, existing works either fail to leverage both modalities or combine the two in shallow or coarse ways. We propose ProgSG allowing the source code sequence modality and the graph modalities to interact with each other in a deep and fine-grained way. To alleviate the scarcity of labeled designs, a pre-training method is proposed based on a suite of compiler's data flow analysis tasks. Experimental results on two benchmark datasets show the superiority of ProgSG over baseline methods that either only consider one modality or combine the two without utilizing the alignment information.
Learning Restoration is Not Enough: Transfering Identical Mapping for Single-Image Shadow Removal
May 18, 2023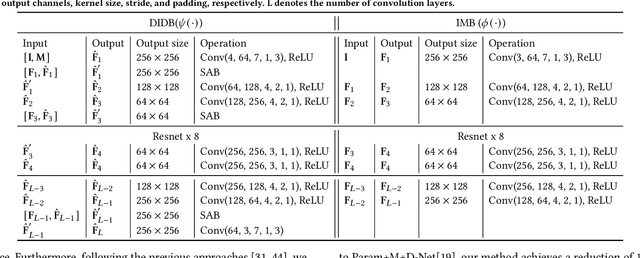

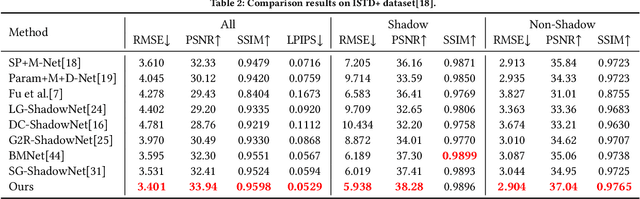
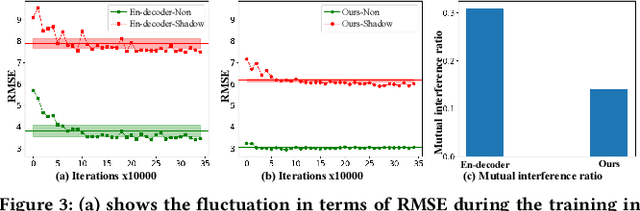
Shadow removal is to restore shadow regions to their shadow-free counterparts while leaving non-shadow regions unchanged. State-of-the-art shadow removal methods train deep neural networks on collected shadow & shadow-free image pairs, which are desired to complete two distinct tasks via shared weights, i.e., data restoration for shadow regions and identical mapping for non-shadow regions. We find that these two tasks exhibit poor compatibility, and using shared weights for these two tasks could lead to the model being optimized towards only one task instead of both during the training process. Note that such a key issue is not identified by existing deep learning-based shadow removal methods. To address this problem, we propose to handle these two tasks separately and leverage the identical mapping results to guide the shadow restoration in an iterative manner. Specifically, our method consists of three components: an identical mapping branch (IMB) for non-shadow regions processing, an iterative de-shadow branch (IDB) for shadow regions restoration based on identical results, and a smart aggregation block (SAB). The IMB aims to reconstruct an image that is identical to the input one, which can benefit the restoration of the non-shadow regions without explicitly distinguishing between shadow and non-shadow regions. Utilizing the multi-scale features extracted by the IMB, the IDB can effectively transfer information from non-shadow regions to shadow regions progressively, facilitating the process of shadow removal. The SAB is designed to adaptive integrate features from both IMB and IDB. Moreover, it generates a finely tuned soft shadow mask that guides the process of removing shadows. Extensive experiments demonstrate our method outperforms all the state-of-the-art shadow removal approaches on the widely used shadow removal datasets.