 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Conditional variational autoencoder with Gaussian process regression recognition for parametric models
May 16, 2023

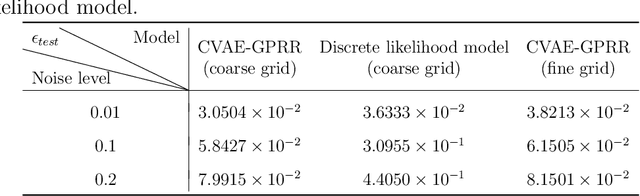

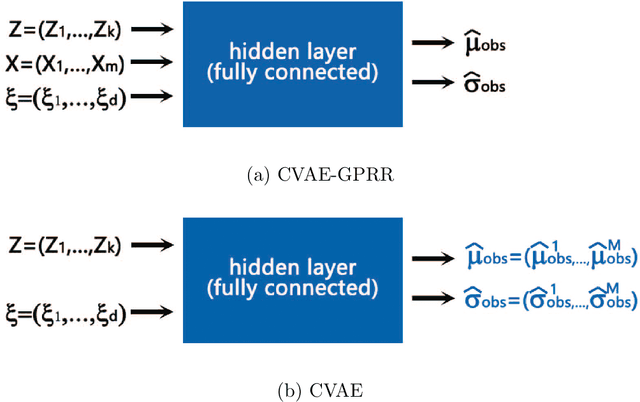
In this article, we present a data-driven method for parametric models with noisy observation data. Gaussian process regression based reduced order modeling (GPR-based ROM) can realize fast online predictions without using equations in the offline stage. However, GPR-based ROM does not perform well for complex systems since POD projection are naturally linear. Conditional variational autoencoder (CVAE) can address this issue via nonlinear neural networks but it has more model complexity, which poses challenges for training and tuning hyperparameters. To this end, we propose a framework of CVAE with Gaussian process regression recognition (CVAE-GPRR). The proposed method consists of a recognition model and a likelihood model. In the recognition model, we first extract low-dimensional features from data by POD to filter the redundant information with high frequency. And then a non-parametric model GPR is used to learn the map from parameters to POD latent variables, which can also alleviate the impact of noise. CVAE-GPRR can achieve the similar accuracy to CVAE but with fewer parameters. In the likelihood model, neural networks are used to reconstruct data. Besides the samples of POD latent variables and input parameters, physical variables are also added as the inputs to make predictions in the whole physical space. This can not be achieved by either GPR-based ROM or CVAE. Moreover, the numerical results show that CVAE-GPRR may alleviate the overfitting issue in CVAE.
Zero-shot-Learning Cross-Modality Data Translation Through Mutual Information Guided Stochastic Diffusion
Jan 31, 2023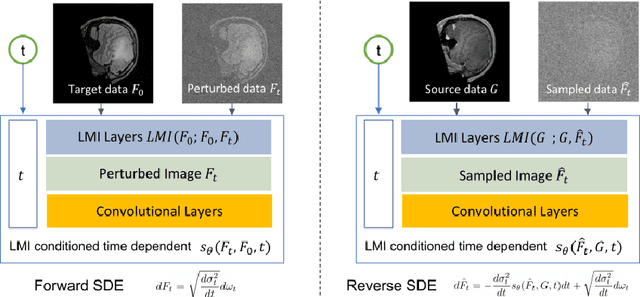
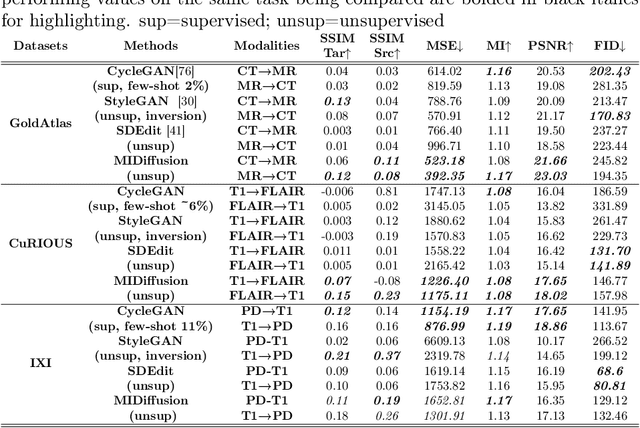

Cross-modality data translation has attracted great interest in image computing. Deep generative models (\textit{e.g.}, GANs) show performance improvement in tackling those problems. Nevertheless, as a fundamental challenge in image translation, the problem of Zero-shot-Learning Cross-Modality Data Translation with fidelity remains unanswered. This paper proposes a new unsupervised zero-shot-learning method named Mutual Information guided Diffusion cross-modality data translation Model (MIDiffusion), which learns to translate the unseen source data to the target domain. The MIDiffusion leverages a score-matching-based generative model, which learns the prior knowledge in the target domain. We propose a differentiable local-wise-MI-Layer ($LMI$) for conditioning the iterative denoising sampling. The $LMI$ captures the identical cross-modality features in the statistical domain for the diffusion guidance; thus, our method does not require retraining when the source domain is changed, as it does not rely on any direct mapping between the source and target domains. This advantage is critical for applying cross-modality data translation methods in practice, as a reasonable amount of source domain dataset is not always available for supervised training. We empirically show the advanced performance of MIDiffusion in comparison with an influential group of generative models, including adversarial-based and other score-matching-based models.
Fusion-S2iGan: An Efficient and Effective Single-Stage Framework for Speech-to-Image Generation
May 17, 2023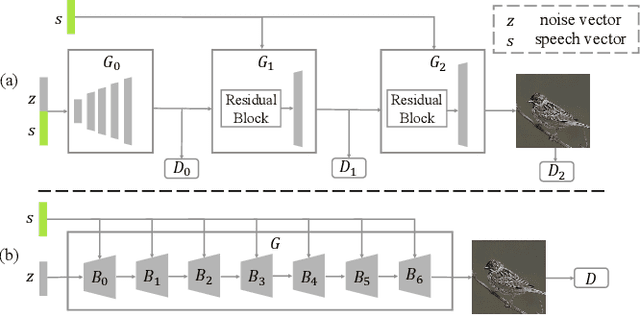
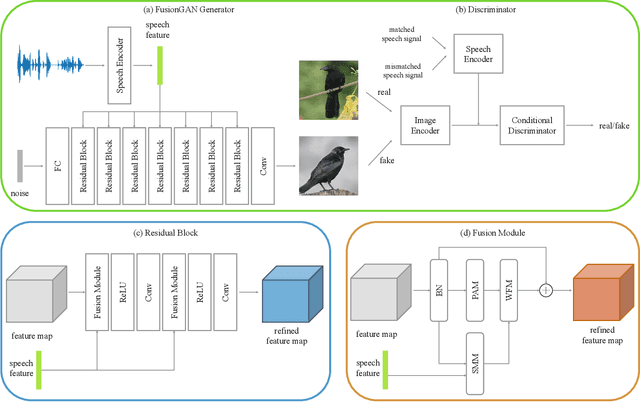
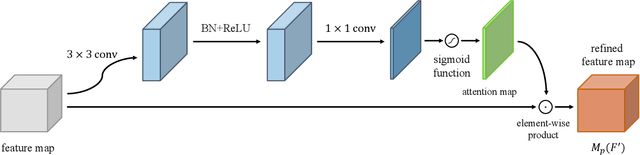
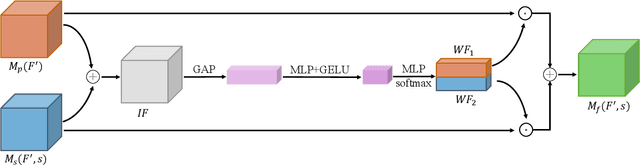
The goal of a speech-to-image transform is to produce a photo-realistic picture directly from a speech signal. Recently, various studies have focused on this task and have achieved promising performance. However, current speech-to-image approaches are based on a stacked modular framework that suffers from three vital issues: 1) Training separate networks is time-consuming as well as inefficient and the convergence of the final generative model strongly depends on the previous generators; 2) The quality of precursor images is ignored by this architecture; 3) Multiple discriminator networks are required to be trained. To this end, we propose an efficient and effective single-stage framework called Fusion-S2iGan to yield perceptually plausible and semantically consistent image samples on the basis of given spoken descriptions. Fusion-S2iGan introduces a visual+speech fusion module (VSFM), constructed with a pixel-attention module (PAM), a speech-modulation module (SMM) and a weighted-fusion module (WFM), to inject the speech embedding from a speech encoder into the generator while improving the quality of synthesized pictures. Fusion-S2iGan spreads the bimodal information over all layers of the generator network to reinforce the visual feature maps at various hierarchical levels in the architecture. We conduct a series of experiments on four benchmark data sets, i.e., CUB birds, Oxford-102, Flickr8k and Places-subset. The experimental results demonstrate the superiority of the presented Fusion-S2iGan compared to the state-of-the-art models with a multi-stage architecture and a performance level that is close to traditional text-to-image approaches.
Class based Influence Functions for Error Detection
May 02, 2023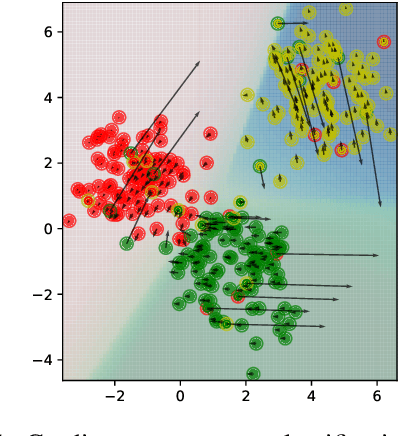

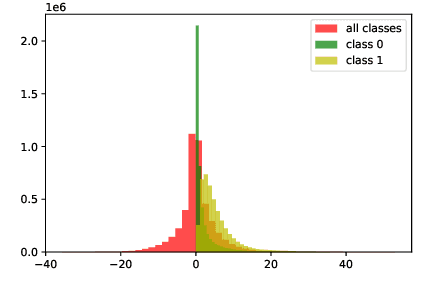

Influence functions (IFs) are a powerful tool for detecting anomalous examples in large scale datasets. However, they are unstable when applied to deep networks. In this paper, we provide an explanation for the instability of IFs and develop a solution to this problem. We show that IFs are unreliable when the two data points belong to two different classes. Our solution leverages class information to improve the stability of IFs. Extensive experiments show that our modification significantly improves the performance and stability of IFs while incurring no additional computational cost.
FactKG: Fact Verification via Reasoning on Knowledge Graphs
May 11, 2023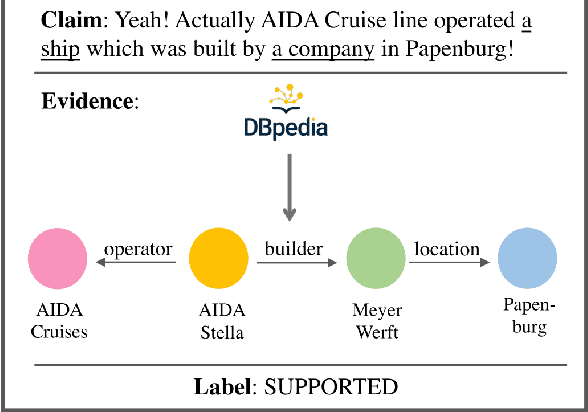

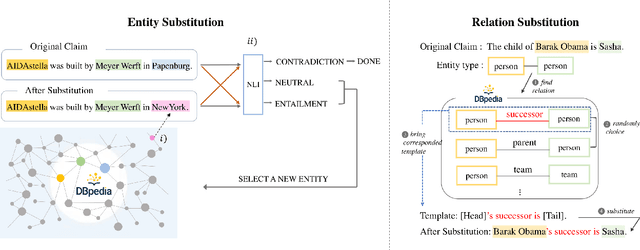
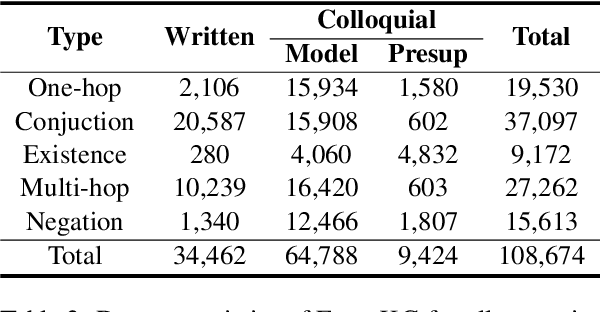
In real world applications, knowledge graphs (KG) are widely used in various domains (e.g. medical applications and dialogue agents). However, for fact verification, KGs have not been adequately utilized as a knowledge source. KGs can be a valuable knowledge source in fact verification due to their reliability and broad applicability. A KG consists of nodes and edges which makes it clear how concepts are linked together, allowing machines to reason over chains of topics. However, there are many challenges in understanding how these machine-readable concepts map to information in text. To enable the community to better use KGs, we introduce a new dataset, FactKG: Fact Verification via Reasoning on Knowledge Graphs. It consists of 108k natural language claims with five types of reasoning: One-hop, Conjunction, Existence, Multi-hop, and Negation. Furthermore, FactKG contains various linguistic patterns, including colloquial style claims as well as written style claims to increase practicality. Lastly, we develop a baseline approach and analyze FactKG over these reasoning types. We believe FactKG can advance both reliability and practicality in KG-based fact verification.
SparseGNV: Generating Novel Views of Indoor Scenes with Sparse Input Views
May 11, 2023
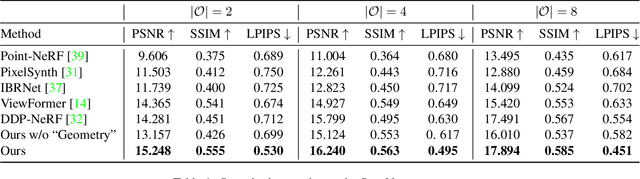
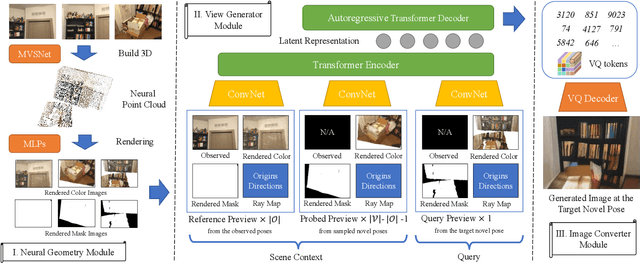

We study to generate novel views of indoor scenes given sparse input views. The challenge is to achieve both photorealism and view consistency. We present SparseGNV: a learning framework that incorporates 3D structures and image generative models to generate novel views with three modules. The first module builds a neural point cloud as underlying geometry, providing contextual information and guidance for the target novel view. The second module utilizes a transformer-based network to map the scene context and the guidance into a shared latent space and autoregressively decodes the target view in the form of discrete image tokens. The third module reconstructs the tokens into the image of the target view. SparseGNV is trained across a large indoor scene dataset to learn generalizable priors. Once trained, it can efficiently generate novel views of an unseen indoor scene in a feed-forward manner. We evaluate SparseGNV on both real-world and synthetic indoor scenes and demonstrate that it outperforms state-of-the-art methods based on either neural radiance fields or conditional image generation.
Local Life: Stay Informed Around You, A Scalable Geoparsing and Geotagging Approach to Serve Local News Worldwide
May 11, 2023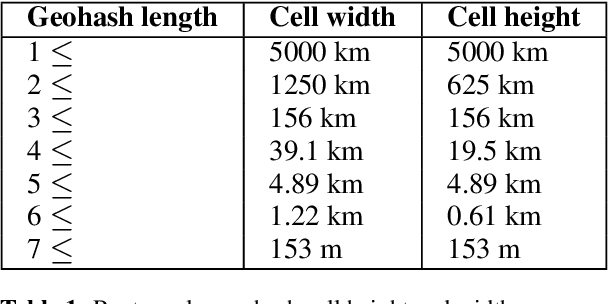
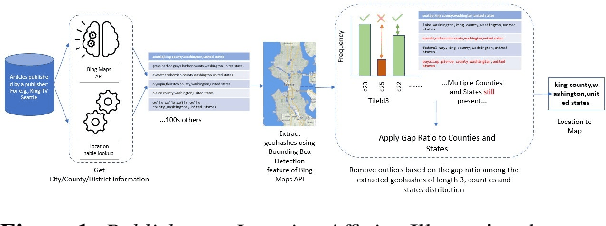
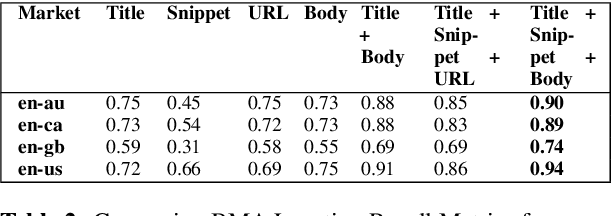
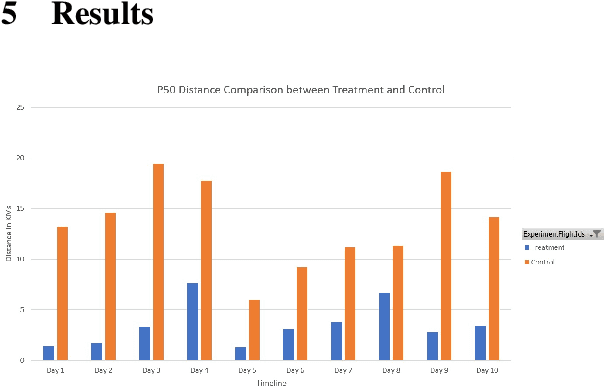
Local news has become increasingly important in the news industry due to its various benefits. It offers local audiences information that helps them participate in their communities and interests. It also serves as a reliable source of factual reporting that can prevent misinformation. Moreover, it can influence national audiences as some local stories may have wider implications for politics, environment or crime. Hence, detecting the exact geolocation and impact scope of local news is crucial for news recommendation systems. There are two fundamental things required in this process, (1) classify whether an article belongs to local news, and (2) identify the geolocation of the article and its scope of influence to recommend it to appropriate users. In this paper, we focus on the second step and propose (1) an efficient approach to determine the location and radius of local news articles, (2) a method to reconcile the user's location with the article's location, and (3) a metric to evaluate the quality of the local news feed. We demonstrate that our technique is scalable and effective in serving hyperlocal news to users worldwide.
A statistical approach to detect sensitive features in a group fairness setting
May 11, 2023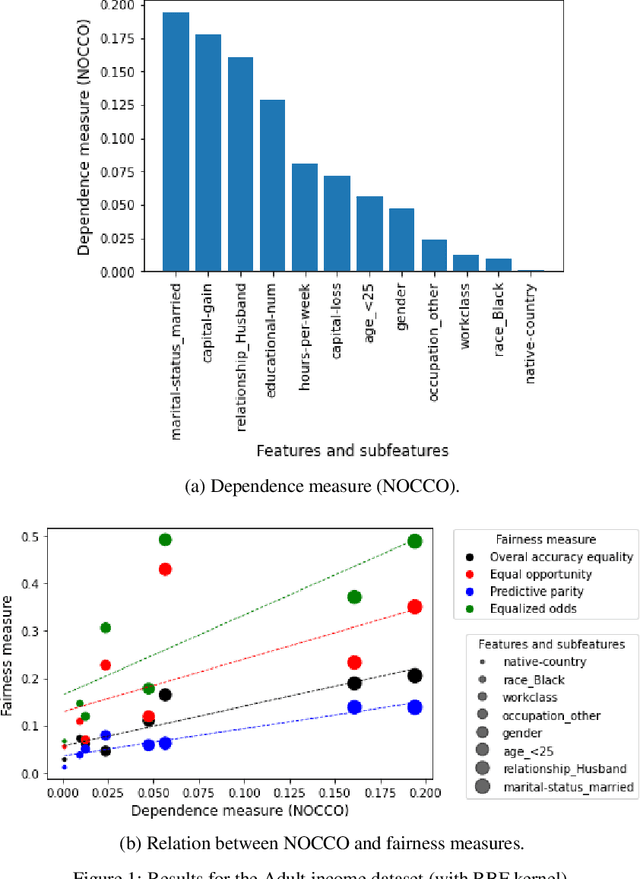
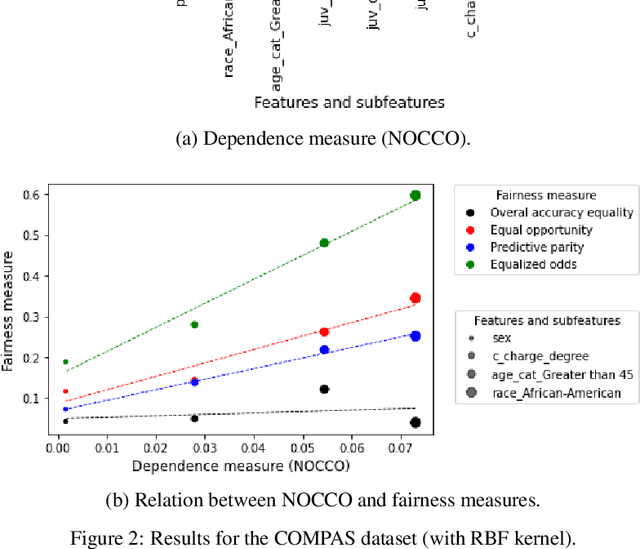
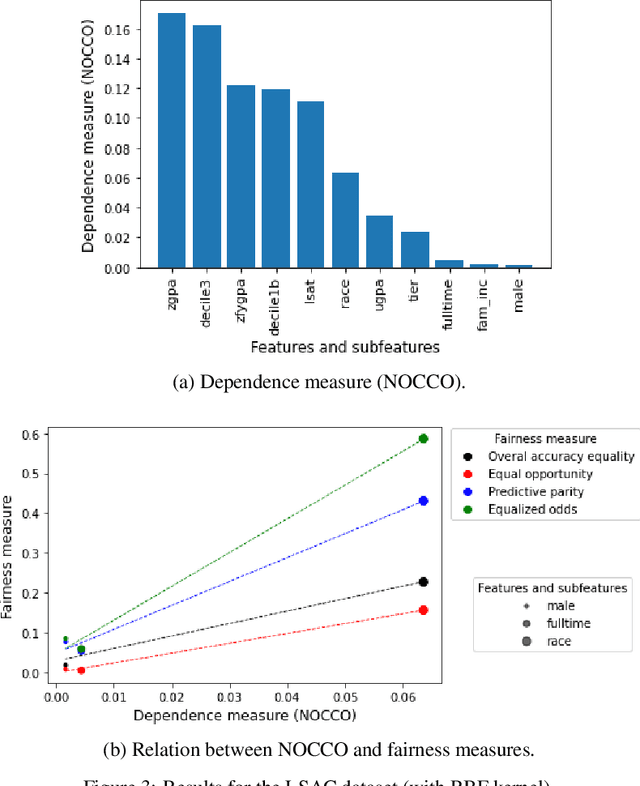
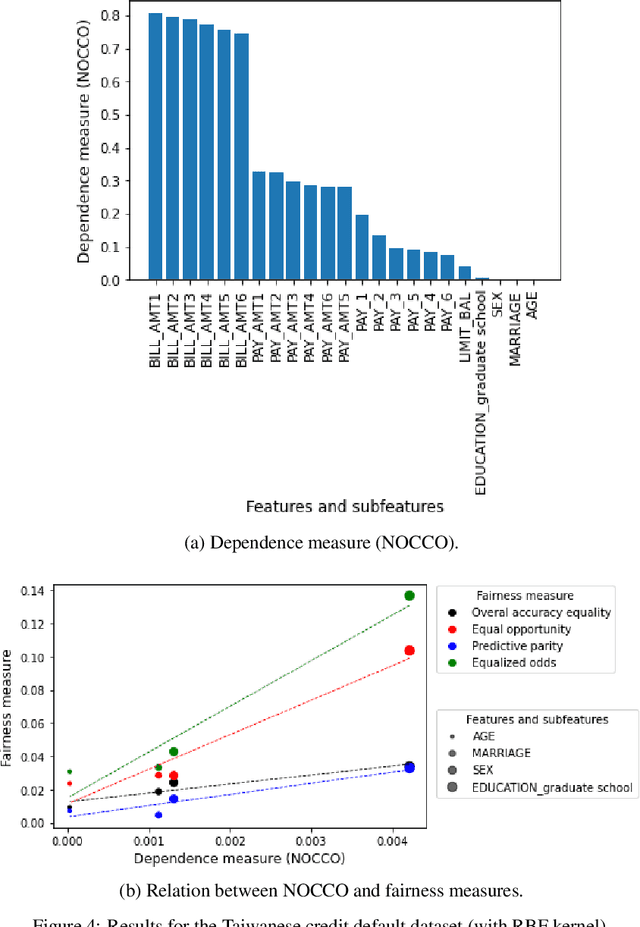
The use of machine learning models in decision support systems with high societal impact raised concerns about unfair (disparate) results for different groups of people. When evaluating such unfair decisions, one generally relies on predefined groups that are determined by a set of features that are considered sensitive. However, such an approach is subjective and does not guarantee that these features are the only ones to be considered as sensitive nor that they entail unfair (disparate) outcomes. In this paper, we propose a preprocessing step to address the task of automatically recognizing sensitive features that does not require a trained model to verify unfair results. Our proposal is based on the Hilber-Schmidt independence criterion, which measures the statistical dependence of variable distributions. We hypothesize that if the dependence between the label vector and a candidate is high for a sensitive feature, then the information provided by this feature will entail disparate performance measures between groups. Our empirical results attest our hypothesis and show that several features considered as sensitive in the literature do not necessarily entail disparate (unfair) results.
A Fused Gromov-Wasserstein Framework for Unsupervised Knowledge Graph Entity Alignment
May 11, 2023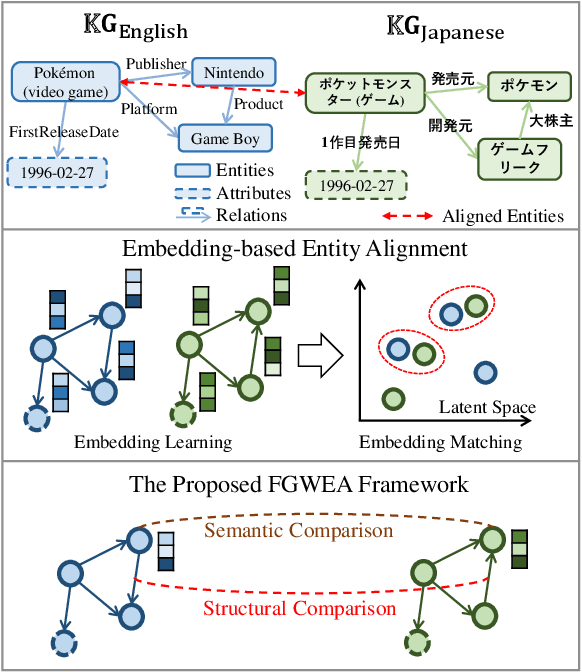
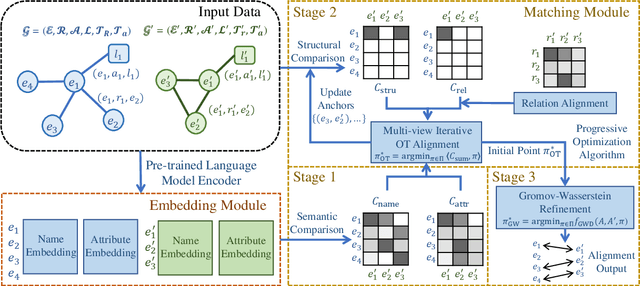
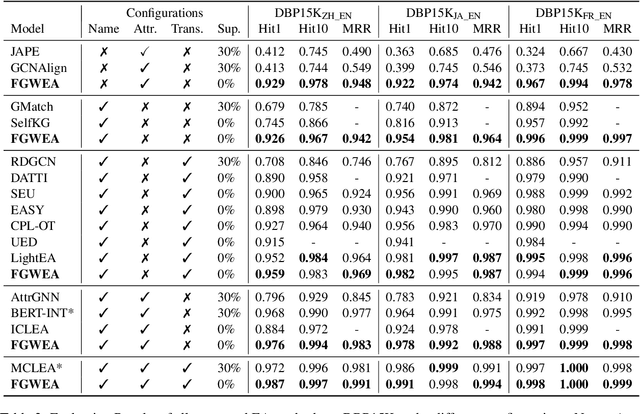
Entity alignment is the task of identifying corresponding entities across different knowledge graphs (KGs). Although recent embedding-based entity alignment methods have shown significant advancements, they still struggle to fully utilize KG structural information. In this paper, we introduce FGWEA, an unsupervised entity alignment framework that leverages the Fused Gromov-Wasserstein (FGW) distance, allowing for a comprehensive comparison of entity semantics and KG structures within a joint optimization framework. To address the computational challenges associated with optimizing FGW, we devise a three-stage progressive optimization algorithm. It starts with a basic semantic embedding matching, proceeds to approximate cross-KG structural and relational similarity matching based on iterative updates of high-confidence entity links, and ultimately culminates in a global structural comparison between KGs. We perform extensive experiments on four entity alignment datasets covering 14 distinct KGs across five languages. Without any supervision or hyper-parameter tuning, FGWEA surpasses 21 competitive baselines, including cutting-edge supervised entity alignment methods. Our code is available at https://github.com/squareRoot3/FusedGW-Entity-Alignment.
AfriQA: Cross-lingual Open-Retrieval Question Answering for African Languages
May 11, 2023
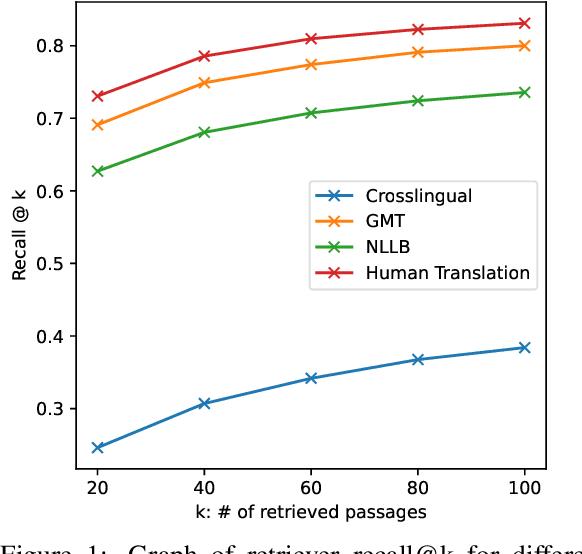

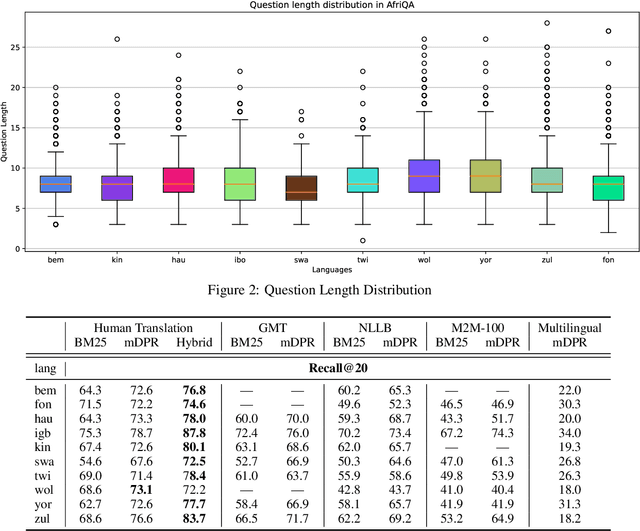
African languages have far less in-language content available digitally, making it challenging for question answering systems to satisfy the information needs of users. Cross-lingual open-retrieval question answering (XOR QA) systems -- those that retrieve answer content from other languages while serving people in their native language -- offer a means of filling this gap. To this end, we create AfriQA, the first cross-lingual QA dataset with a focus on African languages. AfriQA includes 12,000+ XOR QA examples across 10 African languages. While previous datasets have focused primarily on languages where cross-lingual QA augments coverage from the target language, AfriQA focuses on languages where cross-lingual answer content is the only high-coverage source of answer content. Because of this, we argue that African languages are one of the most important and realistic use cases for XOR QA. Our experiments demonstrate the poor performance of automatic translation and multilingual retrieval methods. Overall, AfriQA proves challenging for state-of-the-art QA models. We hope that the dataset enables the development of more equitable QA technology.