 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Correcting misinformation on social media with a large language model
Mar 17, 2024
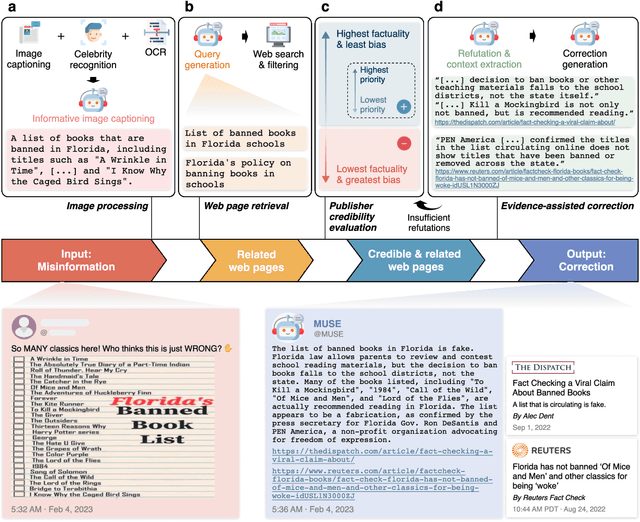
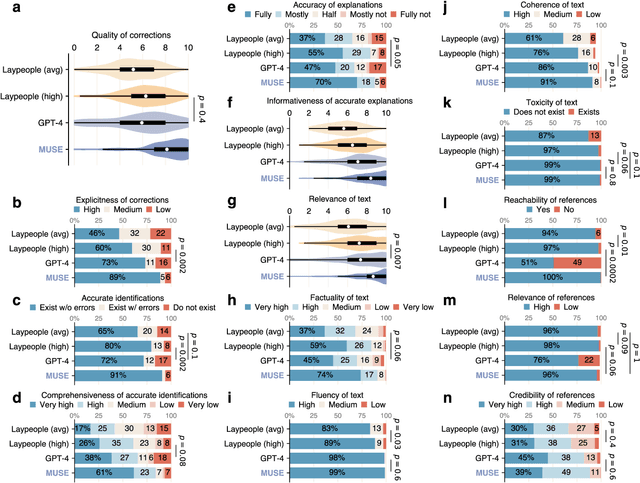
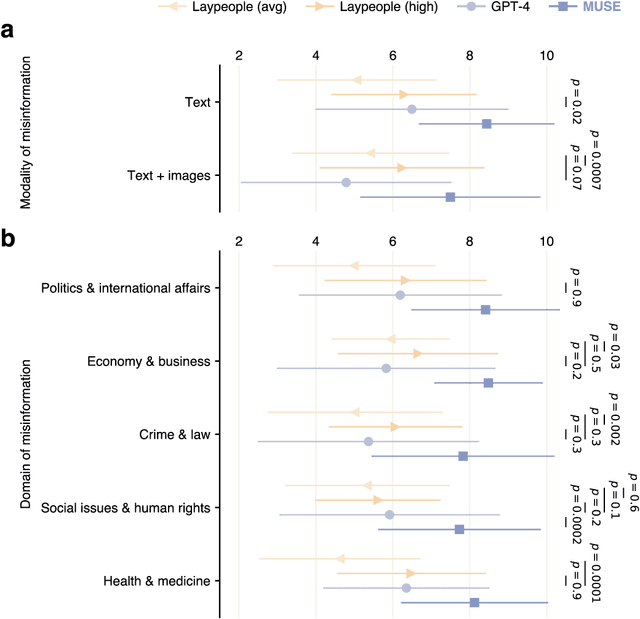
Misinformation undermines public trust in science and democracy, particularly on social media where inaccuracies can spread rapidly. Experts and laypeople have shown to be effective in correcting misinformation by manually identifying and explaining inaccuracies. Nevertheless, this approach is difficult to scale, a concern as technologies like large language models (LLMs) make misinformation easier to produce. LLMs also have versatile capabilities that could accelerate misinformation correction; however, they struggle due to a lack of recent information, a tendency to produce plausible but false content and references, and limitations in addressing multimodal information. To address these issues, we propose MUSE, an LLM augmented with access to and credibility evaluation of up-to-date information. By retrieving contextual evidence and refutations, MUSE can provide accurate and trustworthy explanations and references. It also describes visuals and conducts multimodal searches for correcting multimodal misinformation. We recruit fact-checking and journalism experts to evaluate corrections to real social media posts across 13 dimensions, ranging from the factuality of explanation to the relevance of references. The results demonstrate MUSE's ability to correct misinformation promptly after appearing on social media; overall, MUSE outperforms GPT-4 by 37% and even high-quality corrections from laypeople by 29%. This work underscores the potential of LLMs to combat real-world misinformation effectively and efficiently.
DesignEdit: Multi-Layered Latent Decomposition and Fusion for Unified & Accurate Image Editing
Mar 21, 2024
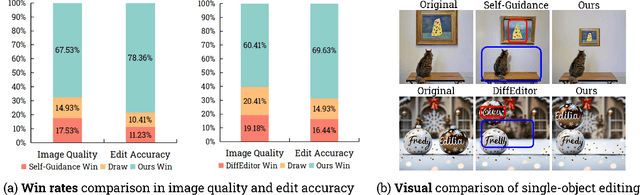

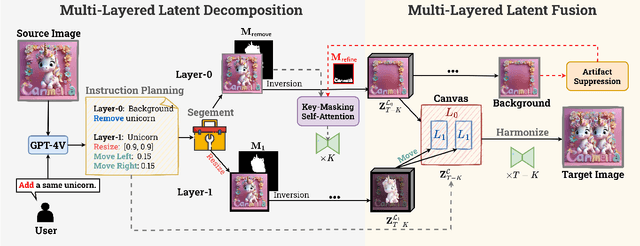
Recently, how to achieve precise image editing has attracted increasing attention, especially given the remarkable success of text-to-image generation models. To unify various spatial-aware image editing abilities into one framework, we adopt the concept of layers from the design domain to manipulate objects flexibly with various operations. The key insight is to transform the spatial-aware image editing task into a combination of two sub-tasks: multi-layered latent decomposition and multi-layered latent fusion. First, we segment the latent representations of the source images into multiple layers, which include several object layers and one incomplete background layer that necessitates reliable inpainting. To avoid extra tuning, we further explore the inner inpainting ability within the self-attention mechanism. We introduce a key-masking self-attention scheme that can propagate the surrounding context information into the masked region while mitigating its impact on the regions outside the mask. Second, we propose an instruction-guided latent fusion that pastes the multi-layered latent representations onto a canvas latent. We also introduce an artifact suppression scheme in the latent space to enhance the inpainting quality. Due to the inherent modular advantages of such multi-layered representations, we can achieve accurate image editing, and we demonstrate that our approach consistently surpasses the latest spatial editing methods, including Self-Guidance and DiffEditor. Last, we show that our approach is a unified framework that supports various accurate image editing tasks on more than six different editing tasks.
Tensor network compressibility of convolutional models
Mar 21, 2024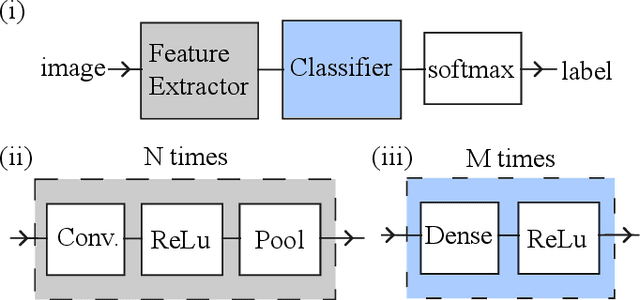

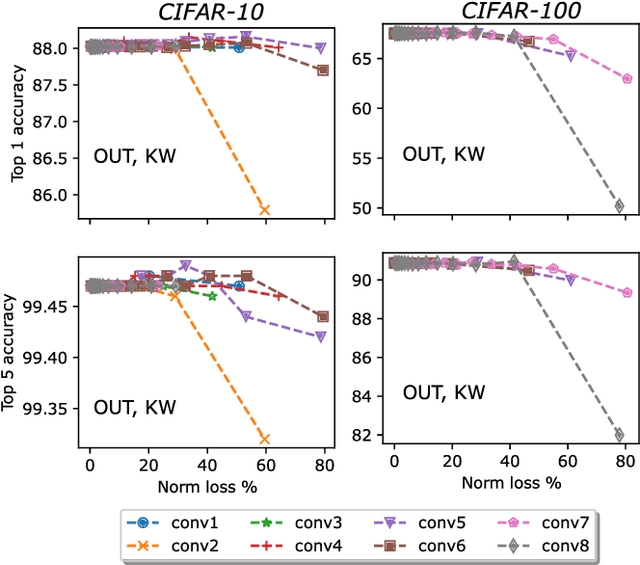
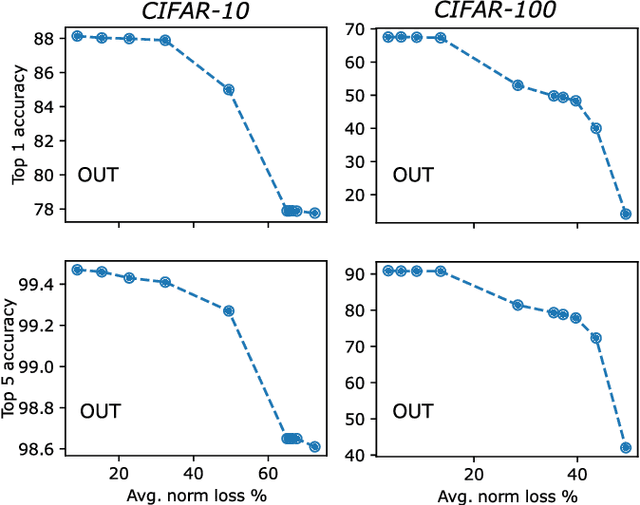
Convolutional neural networks (CNNs) represent one of the most widely used neural network architectures, showcasing state-of-the-art performance in computer vision tasks. Although larger CNNs generally exhibit higher accuracy, their size can be effectively reduced by "tensorization" while maintaining accuracy. Tensorization consists of replacing the convolution kernels with compact decompositions such as Tucker, Canonical Polyadic decompositions, or quantum-inspired decompositions such as matrix product states, and directly training the factors in the decompositions to bias the learning towards low-rank decompositions. But why doesn't tensorization seem to impact the accuracy adversely? We explore this by assessing how truncating the convolution kernels of dense (untensorized) CNNs impact their accuracy. Specifically, we truncated the kernels of (i) a vanilla four-layer CNN and (ii) ResNet-50 pre-trained for image classification on CIFAR-10 and CIFAR-100 datasets. We found that kernels (especially those inside deeper layers) could often be truncated along several cuts resulting in significant loss in kernel norm but not in classification accuracy. This suggests that such ``correlation compression'' (underlying tensorization) is an intrinsic feature of how information is encoded in dense CNNs. We also found that aggressively truncated models could often recover the pre-truncation accuracy after only a few epochs of re-training, suggesting that compressing the internal correlations of convolution layers does not often transport the model to a worse minimum. Our results can be applied to tensorize and compress CNN models more effectively.
Text-Enhanced Data-free Approach for Federated Class-Incremental Learning
Mar 21, 2024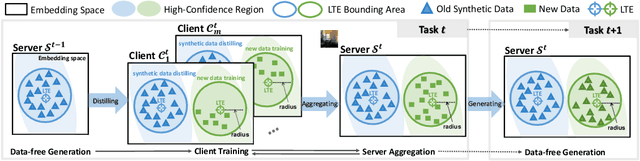
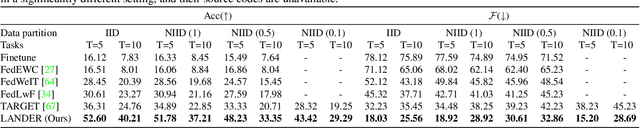
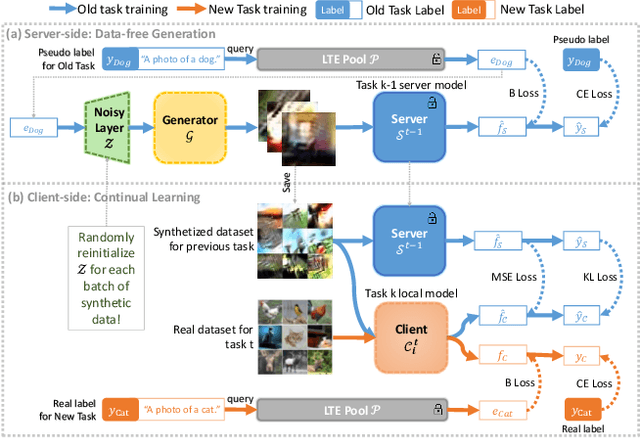
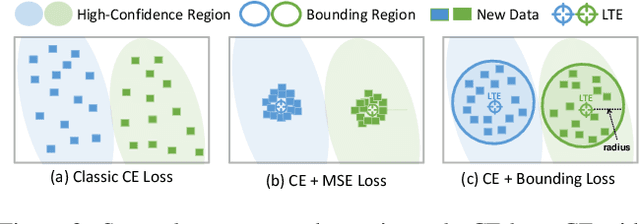
Federated Class-Incremental Learning (FCIL) is an underexplored yet pivotal issue, involving the dynamic addition of new classes in the context of federated learning. In this field, Data-Free Knowledge Transfer (DFKT) plays a crucial role in addressing catastrophic forgetting and data privacy problems. However, prior approaches lack the crucial synergy between DFKT and the model training phases, causing DFKT to encounter difficulties in generating high-quality data from a non-anchored latent space of the old task model. In this paper, we introduce LANDER (Label Text Centered Data-Free Knowledge Transfer) to address this issue by utilizing label text embeddings (LTE) produced by pretrained language models. Specifically, during the model training phase, our approach treats LTE as anchor points and constrains the feature embeddings of corresponding training samples around them, enriching the surrounding area with more meaningful information. In the DFKT phase, by using these LTE anchors, LANDER can synthesize more meaningful samples, thereby effectively addressing the forgetting problem. Additionally, instead of tightly constraining embeddings toward the anchor, the Bounding Loss is introduced to encourage sample embeddings to remain flexible within a defined radius. This approach preserves the natural differences in sample embeddings and mitigates the embedding overlap caused by heterogeneous federated settings. Extensive experiments conducted on CIFAR100, Tiny-ImageNet, and ImageNet demonstrate that LANDER significantly outperforms previous methods and achieves state-of-the-art performance in FCIL. The code is available at https://github.com/tmtuan1307/lander.
Improving Robustness to Model Inversion Attacks via Sparse Coding Architectures
Mar 21, 2024Recent model inversion attack algorithms permit adversaries to reconstruct a neural network's private training data just by repeatedly querying the network and inspecting its outputs. In this work, we develop a novel network architecture that leverages sparse-coding layers to obtain superior robustness to this class of attacks. Three decades of computer science research has studied sparse coding in the context of image denoising, object recognition, and adversarial misclassification settings, but to the best of our knowledge, its connection to state-of-the-art privacy vulnerabilities remains unstudied. However, sparse coding architectures suggest an advantageous means to defend against model inversion attacks because they allow us to control the amount of irrelevant private information encoded in a network's intermediate representations in a manner that can be computed efficiently during training and that is known to have little effect on classification accuracy. Specifically, compared to networks trained with a variety of state-of-the-art defenses, our sparse-coding architectures maintain comparable or higher classification accuracy while degrading state-of-the-art training data reconstructions by factors of 1.1 to 18.3 across a variety of reconstruction quality metrics (PSNR, SSIM, FID). This performance advantage holds across 5 datasets ranging from CelebA faces to medical images and CIFAR-10, and across various state-of-the-art SGD-based and GAN-based inversion attacks, including Plug-&-Play attacks. We provide a cluster-ready PyTorch codebase to promote research and standardize defense evaluations.
A task of anomaly detection for a smart satellite Internet of things system
Mar 21, 2024When the equipment is working, real-time collection of environmental sensor data for anomaly detection is one of the key links to prevent industrial process accidents and network attacks and ensure system security. However, under the environment with specific real-time requirements, the anomaly detection for environmental sensors still faces the following difficulties: (1) The complex nonlinear correlation characteristics between environmental sensor data variables lack effective expression methods, and the distribution between the data is difficult to be captured. (2) it is difficult to ensure the real-time monitoring requirements by using complex machine learning models, and the equipment cost is too high. (3) Too little sample data leads to less labeled data in supervised learning. This paper proposes an unsupervised deep learning anomaly detection system. Based on the generative adversarial network and self-attention mechanism, considering the different feature information contained in the local subsequences, it automatically learns the complex linear and nonlinear dependencies between environmental sensor variables, and uses the anomaly score calculation method combining reconstruction error and discrimination error. It can monitor the abnormal points of real sensor data with high real-time performance and can run on the intelligent satellite Internet of things system, which is suitable for the real working environment. Anomaly detection outperforms baseline methods in most cases and has good interpretability, which can be used to prevent industrial accidents and cyber-attacks for monitoring environmental sensors.
Rolling bearing fault diagnosis method based on generative adversarial enhanced multi-scale convolutional neural network model
Mar 21, 2024In order to solve the problem that current convolutional neural networks can not capture the correlation features between the time domain signals of rolling bearings effectively, and the model accuracy is limited by the number and quality of samples, a rolling bearing fault diagnosis method based on generative adversarial enhanced multi-scale convolutional neural network model is proposed. Firstly, Gram angular field coding technique is used to encode the time domain signal of the rolling bearing and generate the feature map to retain the complete information of the vibration signal. Then, the re-sulting data is divided into a training set, a validation set, and a test set. Among them, the training set is input into the gradient penalty Wasserstein distance generation adversarial network to complete the training, and a new sample with similar features to the training sample is obtained, and then the original training set is expanded. Next, multi-scale convolution is used to extract the fault features of the extended training set, and the feature graph is normalized by example to overcome the influence of the difference in feature distribution. Finally, the attention mechanism is applied to the adaptive weighting of normalized features and the extraction of deep features, and the fault diagnosis is completed by the softmax classifier. Compared with ResNet method, the experimental results show that the proposed method has better generalization performance and anti-noise performance.
CasSR: Activating Image Power for Real-World Image Super-Resolution
Mar 18, 2024
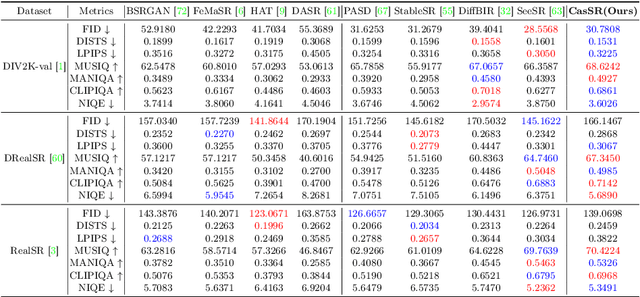


The objective of image super-resolution is to generate clean and high-resolution images from degraded versions. Recent advancements in diffusion modeling have led to the emergence of various image super-resolution techniques that leverage pretrained text-to-image (T2I) models. Nevertheless, due to the prevalent severe degradation in low-resolution images and the inherent characteristics of diffusion models, achieving high-fidelity image restoration remains challenging. Existing methods often exhibit issues including semantic loss, artifacts, and the introduction of spurious content not present in the original image. To tackle this challenge, we propose Cascaded diffusion for Super-Resolution, CasSR , a novel method designed to produce highly detailed and realistic images. In particular, we develop a cascaded controllable diffusion model that aims to optimize the extraction of information from low-resolution images. This model generates a preliminary reference image to facilitate initial information extraction and degradation mitigation. Furthermore, we propose a multi-attention mechanism to enhance the T2I model's capability in maximizing the restoration of the original image content. Through a comprehensive blend of qualitative and quantitative analyses, we substantiate the efficacy and superiority of our approach.
Infinite-ID: Identity-preserved Personalization via ID-semantics Decoupling Paradigm
Mar 18, 2024
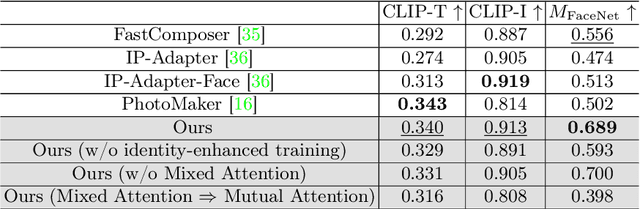
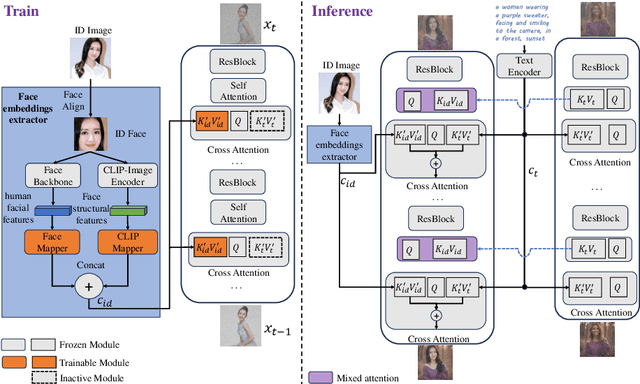

Drawing on recent advancements in diffusion models for text-to-image generation, identity-preserved personalization has made significant progress in accurately capturing specific identities with just a single reference image. However, existing methods primarily integrate reference images within the text embedding space, leading to a complex entanglement of image and text information, which poses challenges for preserving both identity fidelity and semantic consistency. To tackle this challenge, we propose Infinite-ID, an ID-semantics decoupling paradigm for identity-preserved personalization. Specifically, we introduce identity-enhanced training, incorporating an additional image cross-attention module to capture sufficient ID information while deactivating the original text cross-attention module of the diffusion model. This ensures that the image stream faithfully represents the identity provided by the reference image while mitigating interference from textual input. Additionally, we introduce a feature interaction mechanism that combines a mixed attention module with an AdaIN-mean operation to seamlessly merge the two streams. This mechanism not only enhances the fidelity of identity and semantic consistency but also enables convenient control over the styles of the generated images. Extensive experimental results on both raw photo generation and style image generation demonstrate the superior performance of our proposed method.
ThermoNeRF: Multimodal Neural Radiance Fields for Thermal Novel View Synthesis
Mar 18, 2024

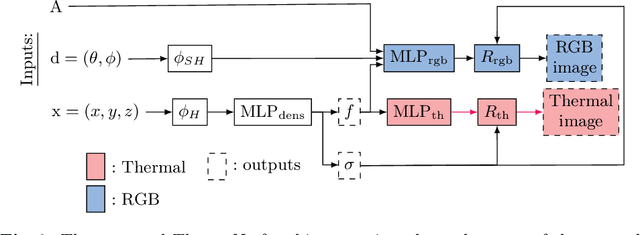
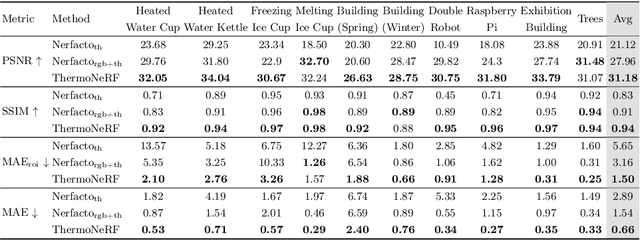
Thermal scene reconstruction exhibit great potential for applications across a broad spectrum of fields, including building energy consumption analysis and non-destructive testing. However, existing methods typically require dense scene measurements and often rely on RGB images for 3D geometry reconstruction, with thermal information being projected post-reconstruction. This two-step strategy, adopted due to the lack of texture in thermal images, can lead to disparities between the geometry and temperatures of the reconstructed objects and those of the actual scene. To address this challenge, we propose ThermoNeRF, a novel multimodal approach based on Neural Radiance Fields, capable of rendering new RGB and thermal views of a scene jointly. To overcome the lack of texture in thermal images, we use paired RGB and thermal images to learn scene density, while distinct networks estimate color and temperature information. Furthermore, we introduce ThermoScenes, a new dataset to palliate the lack of available RGB+thermal datasets for scene reconstruction. Experimental results validate that ThermoNeRF achieves accurate thermal image synthesis, with an average mean absolute error of 1.5$^\circ$C, an improvement of over 50% compared to using concatenated RGB+thermal data with Nerfacto, a state-of-the-art NeRF method.